Cassandra-아키텍처
Cassandra의 설계 목표는 단일 장애 지점없이 여러 노드에서 빅 데이터 워크로드를 처리하는 것입니다. Cassandra는 노드 전체에 피어 투 피어 분산 시스템을 가지고 있으며 데이터는 클러스터의 모든 노드에 분산됩니다.
클러스터의 모든 노드는 동일한 역할을합니다. 각 노드는 독립적이며 동시에 다른 노드와 상호 연결됩니다.
클러스터의 각 노드는 데이터가 실제로 클러스터에있는 위치에 관계없이 읽기 및 쓰기 요청을 수락 할 수 있습니다.
노드가 다운되면 네트워크의 다른 노드에서 읽기 / 쓰기 요청을 처리 할 수 있습니다.
Cassandra의 데이터 복제
Cassandra에서 클러스터에있는 하나 이상의 노드는 주어진 데이터에 대한 복제본 역할을합니다. 일부 노드가 오래된 값으로 응답 한 것으로 감지되면 Cassandra는 가장 최근 값을 클라이언트에 반환합니다. 가장 최근 값을 반환 한 후 Cassandra는read repair 백그라운드에서 오래된 값을 업데이트합니다.
다음 그림은 Cassandra가 클러스터의 노드간에 데이터 복제를 사용하여 단일 장애 지점을 방지하는 방법을 개략적으로 보여줍니다.
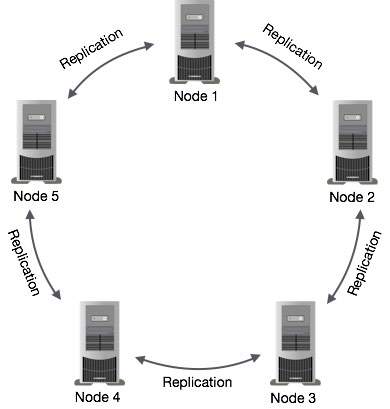
Note − 카산드라는 Gossip Protocol 백그라운드에서 노드가 서로 통신하고 클러스터에서 결함이있는 노드를 감지 할 수 있습니다.
카산드라의 구성 요소
Cassandra의 주요 구성 요소는 다음과 같습니다.
Node − 데이터가 저장되는 곳입니다.
Data center − 관련 노드의 모음입니다.
Cluster − 클러스터는 하나 이상의 데이터 센터를 포함하는 구성 요소입니다.
Commit log− 커밋 로그는 Cassandra의 크래시 복구 메커니즘입니다. 모든 쓰기 작업은 커밋 로그에 기록됩니다.
Mem-table− 메모리 테이블은 메모리 상주 데이터 구조입니다. 커밋 로그 후 데이터가 mem-table에 기록됩니다. 때로는 단일 열 패밀리의 경우 여러 mem-table이 있습니다.
SSTable − 내용이 임계 값에 도달하면 메모리 테이블에서 데이터가 플러시되는 디스크 파일입니다.
Bloom filter− 이는 요소가 집합의 구성원인지 여부를 테스트하기위한 빠르고 비 결정적 알고리즘 일뿐입니다. 특별한 종류의 캐시입니다. 블룸 필터는 모든 쿼리 후에 액세스됩니다.
카산드라 쿼리 언어
사용자는 CQL (Cassandra Query Language)을 사용하여 노드를 통해 Cassandra에 액세스 할 수 있습니다. CQL은 데이터베이스를 처리합니다.(Keyspace)테이블의 컨테이너로. 프로그래머는cqlsh: CQL 또는 별도의 응용 프로그램 언어 드라이버로 작업하라는 메시지가 표시됩니다.
클라이언트는 읽기-쓰기 작업을 위해 모든 노드에 접근합니다. 해당 노드 (코디네이터)는 클라이언트와 데이터를 보유한 노드간에 프록시를 수행합니다.
쓰기 작업
노드의 모든 쓰기 활동은 commit logs노드에 기록됩니다. 나중에 데이터가 캡처되어mem-table. 메모리 테이블이 가득 차면 데이터가 SStable데이터 파일. 모든 쓰기는 클러스터 전체에서 자동으로 분할되고 복제됩니다. Cassandra는 정기적으로 SSTable을 통합하여 불필요한 데이터를 삭제합니다.
읽기 작업
읽기 작업 중에 Cassandra는 mem-table에서 값을 가져오고 블룸 필터를 확인하여 필요한 데이터를 보유하는 적절한 SSTable을 찾습니다.