Cassandra-셸 명령
Cassandra는 CQL 명령 외에도 문서화 된 셸 명령을 제공합니다. 다음은 Cassandra 문서화 된 셸 명령입니다.
도움
HELP 명령은 모든 cqlsh 명령에 대한 개요 및 간략한 설명을 표시합니다. 다음은 help 명령의 사용법입니다.
cqlsh> help
Documented shell commands:
===========================
CAPTURE COPY DESCRIBE EXPAND PAGING SOURCE
CONSISTENCY DESC EXIT HELP SHOW TRACING.
CQL help topics:
================
ALTER CREATE_TABLE_OPTIONS SELECT
ALTER_ADD CREATE_TABLE_TYPES SELECT_COLUMNFAMILY
ALTER_ALTER CREATE_USER SELECT_EXPR
ALTER_DROP DELETE SELECT_LIMIT
ALTER_RENAME DELETE_COLUMNS SELECT_TABLE포착
이 명령은 명령의 출력을 캡처하여 파일에 추가합니다. 예를 들어, 출력을 다음과 같은 이름의 파일로 캡처하는 다음 코드를 살펴보십시오.Outputfile.
cqlsh> CAPTURE '/home/hadoop/CassandraProgs/Outputfile'터미널에 명령을 입력하면 주어진 파일에 출력이 캡처됩니다. 다음은 사용 된 명령과 출력 파일의 스냅 샷입니다.
cqlsh:tutorialspoint> select * from emp;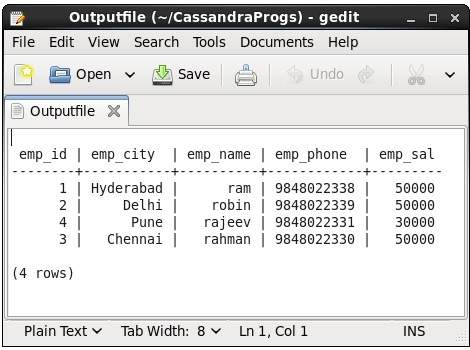
다음 명령을 사용하여 캡처를 끌 수 있습니다.
cqlsh:tutorialspoint> capture off;일관성
이 명령은 현재 일관성 수준을 표시하거나 새 일관성 수준을 설정합니다.
cqlsh:tutorialspoint> CONSISTENCY
Current consistency level is 1.부
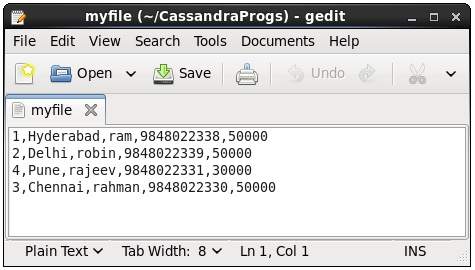
이 명령은 Cassandra에서 파일로 데이터를 복사합니다. 다음은 테이블을 복사하는 예입니다.emp 파일에 myfile.
cqlsh:tutorialspoint> COPY emp (emp_id, emp_city, emp_name, emp_phone,emp_sal) TO ‘myfile’;
4 rows exported in 0.034 seconds.주어진 파일을 열어 확인하면 아래와 같이 복사 된 데이터를 찾을 수 있습니다.
설명
이 명령은 Cassandra의 현재 클러스터와 해당 개체를 설명합니다. 이 명령의 변형은 아래에 설명되어 있습니다.
Describe cluster −이 명령은 클러스터에 대한 정보를 제공합니다.
cqlsh:tutorialspoint> describe cluster;
Cluster: Test Cluster
Partitioner: Murmur3Partitioner
Range ownership:
-658380912249644557 [127.0.0.1]
-2833890865268921414 [127.0.0.1]
-6792159006375935836 [127.0.0.1]Describe Keyspaces−이 명령은 클러스터의 모든 키 스페이스를 나열합니다. 다음은이 명령의 사용법입니다.
cqlsh:tutorialspoint> describe keyspaces;
system_traces system tp tutorialspointDescribe tables−이 명령은 키 스페이스의 모든 테이블을 나열합니다. 다음은이 명령의 사용법입니다.
cqlsh:tutorialspoint> describe tables;
empDescribe table−이 명령은 테이블에 대한 설명을 제공합니다. 다음은이 명령의 사용법입니다.
cqlsh:tutorialspoint> describe table emp;
CREATE TABLE tutorialspoint.emp (
emp_id int PRIMARY KEY,
emp_city text,
emp_name text,
emp_phone varint,
emp_sal varint
) WITH bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = ''
AND compaction = {'min_threshold': '4', 'class':
'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy',
'max_threshold': '32'}
AND compression = {'sstable_compression':
'org.apache.cassandra.io.compress.LZ4Compressor'}
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99.0PERCENTILE';
CREATE INDEX emp_emp_sal_idx ON tutorialspoint.emp (emp_sal);유형 설명
이 명령은 사용자 정의 데이터 유형을 설명하는 데 사용됩니다. 다음은이 명령의 사용법입니다.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
mail text
);유형 설명
이 명령은 모든 사용자 정의 데이터 유형을 나열합니다. 다음은이 명령의 사용법입니다. 두 가지 사용자 정의 데이터 유형이 있다고 가정합니다.card 과 card_details.
cqlsh:tutorialspoint> DESCRIBE TYPES;
card_details card넓히다
이 명령은 출력을 확장하는 데 사용됩니다. 이 명령을 사용하기 전에 확장 명령을 켜야합니다. 다음은이 명령의 사용법입니다.
cqlsh:tutorialspoint> expand on;
cqlsh:tutorialspoint> select * from emp;
@ Row 1
-----------+------------
emp_id | 1
emp_city | Hyderabad
emp_name | ram
emp_phone | 9848022338
emp_sal | 50000
@ Row 2
-----------+------------
emp_id | 2
emp_city | Delhi
emp_name | robin
emp_phone | 9848022339
emp_sal | 50000
@ Row 3
-----------+------------
emp_id | 4
emp_city | Pune
emp_name | rajeev
emp_phone | 9848022331
emp_sal | 30000
@ Row 4
-----------+------------
emp_id | 3
emp_city | Chennai
emp_name | rahman
emp_phone | 9848022330
emp_sal | 50000
(4 rows)Note − 다음 명령을 사용하여 확장 옵션을 끌 수 있습니다.
cqlsh:tutorialspoint> expand off;
Disabled Expanded output.출구
이 명령은 cql 쉘을 종료하는 데 사용됩니다.
보여 주다
이 명령은 Cassandra 버전, 호스트 또는 데이터 유형 가정과 같은 현재 cqlsh 세션의 세부 사항을 표시합니다. 다음은이 명령의 사용법입니다.
cqlsh:tutorialspoint> show host;
Connected to Test Cluster at 127.0.0.1:9042.
cqlsh:tutorialspoint> show version;
[cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]출처
이 명령을 사용하여 파일에서 명령을 실행할 수 있습니다. 입력 파일이 다음과 같다고 가정합니다.
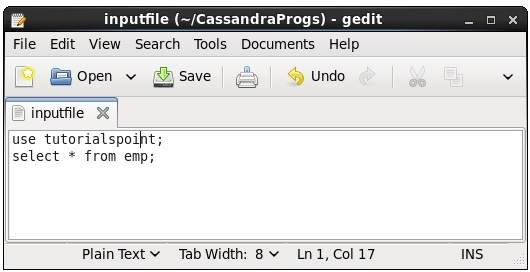
그런 다음 아래와 같이 명령이 포함 된 파일을 실행할 수 있습니다.
cqlsh:tutorialspoint> source '/home/hadoop/CassandraProgs/inputfile';
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Pune | rajeev | 9848022331 | 30000
4 | Chennai | rahman | 9848022330 | 50000
(4 rows)