데이터 마이닝-마이닝 텍스트 데이터
텍스트 데이터베이스는 방대한 문서 모음으로 구성됩니다. 뉴스 기사, 서적, 디지털 도서관, 전자 메일 메시지, 웹 페이지 등과 같은 여러 출처에서 이러한 정보를 수집합니다. 정보의 양이 증가함에 따라 텍스트 데이터베이스는 빠르게 성장하고 있습니다. 많은 텍스트 데이터베이스에서 데이터는 반 구조적입니다.
예를 들어, 문서에는 제목, 작성자, 게시 _ 날짜 등과 같은 몇 가지 구조화 된 필드가 포함될 수 있습니다. 그러나 구조 데이터와 함께 문서에는 추상 및 내용과 같은 구조화되지 않은 텍스트 구성 요소도 포함됩니다. 문서에 무엇이있을 수 있는지 모르면 데이터에서 유용한 정보를 분석하고 추출하기위한 효과적인 쿼리를 작성하기가 어렵습니다. 사용자는 문서를 비교하고 중요도와 관련성의 순위를 매기는 도구가 필요합니다. 따라서 텍스트 마이닝이 대중화되고 데이터 마이닝의 필수 주제가되었습니다.
정보 검색
정보 검색은 많은 수의 텍스트 기반 문서에서 정보 검색을 처리합니다. 일부 데이터베이스 시스템은 서로 다른 종류의 데이터를 처리하기 때문에 일반적으로 정보 검색 시스템에 존재하지 않습니다. 정보 검색 시스템의 예는 다음과 같습니다.
- 온라인 도서관 카탈로그 시스템
- 온라인 문서 관리 시스템
- 웹 검색 시스템 등
Note− 정보 검색 시스템의 주요 문제점은 사용자의 쿼리를 기반으로 문서 모음에서 관련 문서를 찾는 것입니다. 이러한 종류의 사용자 쿼리는 필요한 정보를 설명하는 몇 가지 키워드로 구성됩니다.
이러한 검색 문제에서 사용자는 컬렉션에서 관련 정보를 추출하기 위해 주도권을 잡습니다. 이는 사용자가 임시 정보가 필요한 경우 즉, 단기적인 정보가 필요한 경우에 적합합니다. 그러나 사용자에게 장기적인 정보가 필요한 경우 검색 시스템은 새로 도착한 정보 항목을 사용자에게 푸시하기 위해 주도권을 가질 수도 있습니다.
이러한 종류의 정보 액세스를 정보 필터링이라고합니다. 그리고 해당 시스템은 필터링 시스템 또는 추천 시스템으로 알려져 있습니다.
텍스트 검색을위한 기본 조치
사용자 입력을 기반으로 여러 문서를 검색 할 때 시스템의 정확성을 확인해야합니다. 쿼리와 관련된 문서 세트를 {Relevant}로 표시하고 검색된 문서 세트를 {Retrieved}로 표시합니다. 관련성이 있고 검색된 문서 세트는 {Relevant} ∩ {Retrieved}로 표시 할 수 있습니다. 이것은 다음과 같이 벤 다이어그램의 형태로 표시 될 수 있습니다.
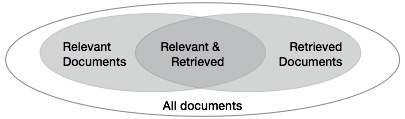
텍스트 검색의 품질을 평가하기위한 세 가지 기본 조치가 있습니다.
- Precision
- Recall
- F-score
정도
정밀도는 실제로 쿼리와 관련된 검색된 문서의 백분율입니다. 정밀도는 다음과 같이 정의 할 수 있습니다.
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|소환
재현율은 쿼리와 관련이 있고 실제로 검색된 문서의 비율입니다. 리콜은 다음과 같이 정의됩니다.
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|F- 점수
F- 점수는 일반적으로 사용되는 트레이드 오프입니다. 정보 검색 시스템은 종종 정확성을 위해 트레이드 오프를 필요로하며 그 반대의 경우도 마찬가지입니다. F- 점수는 다음과 같이 재현율 또는 정밀도의 조화 평균으로 정의됩니다.
F-score = recall x precision / (recall + precision) / 2