Hadoop-퀵 가이드
"지난 몇 년 동안 전 세계 데이터의 90 %가 생성되었습니다."
새로운 기술, 장치 및 소셜 네트워킹 사이트와 같은 통신 수단의 출현으로 인해 인류가 생성하는 데이터의 양은 매년 빠르게 증가하고 있습니다. 처음부터 2003 년까지 우리가 생성 한 데이터의 양은 50 억 기가 바이트였습니다. 디스크 형태로 데이터를 쌓으면 축구장 전체를 채울 수 있습니다. 같은 금액이 2 일마다 생성되었습니다.2011, 그리고 10 분마다 2013. 이 속도는 여전히 엄청나게 증가하고 있습니다. 생성 된이 모든 정보는 의미 있고 처리 할 때 유용 할 수 있지만 무시되고 있습니다.
빅 데이터 란?
Big data기존 컴퓨팅 기술로는 처리 할 수없는 대규모 데이터 세트 모음입니다. 그것은 단일 기술이나 도구가 아니라 다양한 도구, 기술 및 프레임 워크를 포함하는 완전한 주제가되었습니다.
빅 데이터에는 무엇이 포함됩니까?
빅 데이터에는 다양한 장치 및 응용 프로그램에서 생성 된 데이터가 포함됩니다. 다음은 빅 데이터의 우산 아래에있는 몇 가지 분야입니다.
Black Box Data − 헬리콥터, 비행기, 제트기 등의 구성 요소입니다. 승무원의 음성, 마이크 및 이어폰 녹음, 항공기의 성능 정보를 캡처합니다.
Social Media Data − Facebook 및 Twitter와 같은 소셜 미디어에는 전 세계 수백만 명의 사람들이 게시 한 정보와보기가 있습니다.
Stock Exchange Data − 증권 거래소 데이터에는 고객이 만든 여러 회사의 주식에 대한 '매수'및 '매도'결정에 대한 정보가 포함됩니다.
Power Grid Data − 전력망 데이터는 기지국과 관련하여 특정 노드가 소비하는 정보를 보유합니다.
Transport Data − 운송 데이터에는 차량의 모델, 용량, 거리 및 가용성이 포함됩니다.
Search Engine Data − 검색 엔진은 서로 다른 데이터베이스에서 많은 데이터를 검색합니다.

따라서 빅 데이터에는 방대한 양, 고속 및 확장 가능한 다양한 데이터가 포함됩니다. 그 안에있는 데이터는 세 가지 유형입니다.
Structured data − 관계형 데이터.
Semi Structured data − XML 데이터.
Unstructured data − Word, PDF, 텍스트, 미디어 로그.
빅 데이터의 이점
마케팅 대행사는 Facebook과 같은 소셜 네트워크에 보관 된 정보를 사용하여 캠페인, 프로모션 및 기타 광고 매체에 대한 반응에 대해 배우고 있습니다.
소비자, 제품 회사 및 소매 조직의 선호도 및 제품 인식과 같은 소셜 미디어의 정보를 사용하여 생산을 계획하고 있습니다.
환자의 과거 병력에 대한 데이터를 활용하여 병원은보다 빠르고 나은 서비스를 제공하고 있습니다.
빅 데이터 기술
빅 데이터 기술은보다 정확한 분석을 제공하는 데 중요하며, 이는보다 구체적인 의사 결정으로 이어질 수있어 운영 효율성을 높이고 비용을 절감하며 비즈니스에 대한 위험을 줄입니다.
빅 데이터의 힘을 활용하려면 방대한 양의 정형 및 비정형 데이터를 실시간으로 관리 및 처리하고 데이터 개인 정보 보호 및 보안을 보호 할 수있는 인프라가 필요합니다.
빅 데이터를 처리하기 위해 Amazon, IBM, Microsoft 등 다양한 공급 업체의 다양한 기술이 시장에 나와 있습니다. 빅 데이터를 처리하는 기술을 살펴보면서 다음 두 가지 기술 클래스를 살펴 봅니다.
운영 빅 데이터
여기에는 데이터가 주로 캡처되고 저장되는 실시간 대화 형 워크로드를위한 운영 기능을 제공하는 MongoDB와 같은 시스템이 포함됩니다.
NoSQL 빅 데이터 시스템은 대규모 계산을 저렴하고 효율적으로 실행할 수 있도록 지난 10 년 동안 등장한 새로운 클라우드 컴퓨팅 아키텍처를 활용하도록 설계되었습니다. 이를 통해 운영 빅 데이터 워크로드를 훨씬 쉽게 관리하고, 저렴하고, 빠르게 구현할 수 있습니다.
일부 NoSQL 시스템은 데이터 과학자 및 추가 인프라 없이도 최소한의 코딩으로 실시간 데이터를 기반으로 패턴 및 추세에 대한 통찰력을 제공 할 수 있습니다.
분석 빅 데이터
여기에는 MPP (Massively Parallel Processing) 데이터베이스 시스템과 MapReduce와 같은 시스템이 포함되며 대부분 또는 모든 데이터에 영향을 미칠 수있는 회고 및 복잡한 분석을위한 분석 기능을 제공합니다.
MapReduce는 SQL에서 제공하는 기능을 보완하는 데이터를 분석하는 새로운 방법과 단일 서버에서 수천 개의 고급 및 저가형 머신으로 확장 할 수있는 MapReduce 기반 시스템을 제공합니다.
이 두 종류의 기술은 상호 보완 적이며 자주 함께 배포됩니다.
운영 대 분석 시스템
| 운영 | 분석 | |
|---|---|---|
| 지연 시간 | 1ms-100ms | 1 분-100 분 |
| 동시성 | 1000-100,000 | 1 ~ 10 |
| 액세스 패턴 | 쓰기 및 읽기 | 읽기 |
| 쿼리 | 선택적 | 선택 해제 |
| 데이터 범위 | 운영 | 회고전 |
| 최종 사용자 | 고객 | 데이터 과학자 |
| 과학 기술 | NoSQL | MapReduce, MPP 데이터베이스 |
빅 데이터 과제
빅 데이터와 관련된 주요 과제는 다음과 같습니다.
- 데이터 캡처
- Curation
- Storage
- Searching
- Sharing
- Transfer
- Analysis
- Presentation
위의 과제를 해결하기 위해 조직은 일반적으로 엔터프라이즈 서버의 도움을받습니다.
전통적인 접근 방식
이 접근 방식에서 기업은 빅 데이터를 저장하고 처리 할 컴퓨터를 갖게됩니다. 스토리지 목적을 위해 프로그래머는 Oracle, IBM 등과 같은 데이터베이스 공급 업체를 선택하여 도움을받습니다.이 접근 방식에서 사용자는 애플리케이션과 상호 작용하여 데이터 스토리지 및 분석의 일부를 처리합니다.
한정
이 접근 방식은 표준 데이터베이스 서버에서 수용 할 수있는 적은 양의 데이터를 처리하는 애플리케이션이나 데이터를 처리하는 프로세서의 한계까지 잘 작동합니다. 그러나 엄청난 양의 확장 가능한 데이터를 처리 할 때 단일 데이터베이스 병목 현상을 통해 이러한 데이터를 처리하는 것은 바쁜 작업입니다.
Google의 솔루션
Google은 MapReduce라는 알고리즘을 사용하여이 문제를 해결했습니다. 이 알고리즘은 작업을 작은 부분으로 나누어 여러 컴퓨터에 할당하고 통합 될 때 결과 데이터 집합을 형성하는 결과를 수집합니다.

하둡
Google에서 제공하는 솔루션을 사용하여 Doug Cutting 그의 팀은 오픈 소스 프로젝트를 개발했습니다. HADOOP.
Hadoop은 데이터가 다른 데이터와 병렬로 처리되는 MapReduce 알고리즘을 사용하여 애플리케이션을 실행합니다. 요컨대 Hadoop은 방대한 양의 데이터에 대해 완전한 통계 분석을 수행 할 수있는 애플리케이션을 개발하는 데 사용됩니다.

Hadoop은 Java로 작성된 Apache 오픈 소스 프레임 워크로, 간단한 프로그래밍 모델을 사용하여 컴퓨터 클러스터에서 대규모 데이터 세트를 분산 처리 할 수 있습니다. Hadoop 프레임 워크 애플리케이션 은 컴퓨터 클러스터 전반에 분산 스토리지 및 계산 을 제공하는 환경에서 작동 합니다. Hadoop은 단일 서버에서 수천 대의 머신으로 확장하도록 설계되었으며 각각 로컬 계산 및 스토리지를 제공합니다.
Hadoop 아키텍처
핵심에서 Hadoop은 두 가지 주요 계층을 가지고 있습니다.
- 처리 / 계산 계층 (MapReduce) 및
- 스토리지 계층 (Hadoop 분산 파일 시스템).

MapReduce
MapReduce는 신뢰할 수있는 내결함성 방식으로 상용 하드웨어의 대규모 클러스터 (수천 개의 노드)에서 대용량 데이터 (수 테라 바이트 데이터 세트)를 효율적으로 처리하기 위해 Google에서 고안 한 분산 애플리케이션을 작성하기위한 병렬 프로그래밍 모델입니다. MapReduce 프로그램은 Apache 오픈 소스 프레임 워크 인 Hadoop에서 실행됩니다.
Hadoop 분산 파일 시스템
HDFS (Hadoop Distributed File System)는 Google 파일 시스템 (GFS)을 기반으로하며 상용 하드웨어에서 실행되도록 설계된 분산 파일 시스템을 제공합니다. 기존 분산 파일 시스템과 많은 유사점이 있습니다. 그러나 다른 분산 파일 시스템과의 차이점은 중요합니다. 내결함성이 뛰어나고 저렴한 하드웨어에 배포되도록 설계되었습니다. 애플리케이션 데이터에 대한 높은 처리량 액세스를 제공하며 대규모 데이터 세트가있는 애플리케이션에 적합합니다.
위에서 언급 한 두 가지 핵심 구성 요소 외에도 Hadoop 프레임 워크에는 다음 두 모듈이 포함됩니다.
Hadoop Common − 다른 Hadoop 모듈에 필요한 Java 라이브러리 및 유틸리티입니다.
Hadoop YARN − 이것은 작업 스케줄링 및 클러스터 리소스 관리를위한 프레임 워크입니다.
Hadoop은 어떻게 작동합니까?
대규모 처리를 처리하는 무거운 구성으로 더 큰 서버를 구축하는 것은 비용이 많이 들지만, 대안으로 단일 CPU를 사용하여 많은 상용 컴퓨터를 단일 기능 분산 시스템으로 묶을 수 있으며 실제로 클러스터링 된 머신이 데이터 세트를 읽을 수 있습니다. 병렬로 연결하고 훨씬 더 높은 처리량을 제공합니다. 또한 하나의 고급 서버보다 저렴합니다. 따라서 이것이 Hadoop을 사용하여 클러스터 된 저비용 시스템에서 실행되는 첫 번째 동기 부여 요소입니다.
Hadoop은 컴퓨터 클러스터에서 코드를 실행합니다. 이 프로세스에는 Hadoop이 수행하는 다음과 같은 핵심 작업이 포함됩니다.
데이터는 처음에 디렉토리와 파일로 나뉩니다. 파일은 128M 및 64M (바람직하게는 128M)의 균일 한 크기의 블록으로 나뉩니다.
이러한 파일은 추가 처리를 위해 다양한 클러스터 노드에 분산됩니다.
로컬 파일 시스템의 맨 위에있는 HDFS는 처리를 감독합니다.
하드웨어 장애 처리를 위해 블록이 복제됩니다.
코드가 성공적으로 실행되었는지 확인합니다.
맵과 감소 단계 사이에서 발생하는 정렬을 수행합니다.
정렬 된 데이터를 특정 컴퓨터로 전송합니다.
각 작업에 대한 디버깅 로그를 작성합니다.
Hadoop의 장점
Hadoop 프레임 워크를 통해 사용자는 분산 시스템을 빠르게 작성하고 테스트 할 수 있습니다. 효율적이며 데이터를 자동으로 배포하고 시스템 전체에 작업을 수행하고 CPU 코어의 기본 병렬 처리를 활용합니다.
Hadoop은 내결함성 및 고 가용성 (FTHA)을 제공하기 위해 하드웨어에 의존하지 않고, 오히려 Hadoop 라이브러리 자체가 애플리케이션 계층에서 오류를 감지하고 처리하도록 설계되었습니다.
클러스터에서 서버를 동적으로 추가하거나 제거 할 수 있으며 Hadoop은 중단없이 계속 작동합니다.
Hadoop의 또 다른 큰 장점은 오픈 소스와 별도로 Java 기반이므로 모든 플랫폼에서 호환된다는 것입니다.
Hadoop은 GNU / Linux 플랫폼과 그 특징에 의해 지원됩니다. 따라서 Hadoop 환경 설정을 위해 Linux 운영 체제를 설치해야합니다. Linux 이외의 OS가있는 경우 Virtualbox 소프트웨어를 설치하고 Virtualbox 안에 Linux를 포함 할 수 있습니다.
사전 설치 설정
Linux 환경에 Hadoop을 설치하기 전에 다음을 사용하여 Linux를 설정해야합니다. ssh(보안 쉘). Linux 환경을 설정하려면 아래 단계를 따르십시오.
사용자 생성
처음에는 Hadoop에 대해 별도의 사용자를 생성하여 Hadoop 파일 시스템을 Unix 파일 시스템과 분리하는 것이 좋습니다. 사용자를 생성하려면 아래 단계를 따르십시오-
"su"명령을 사용하여 루트를 엽니 다.
"useradd username"명령을 사용하여 루트 계정에서 사용자를 만듭니다.
이제 "su username"명령을 사용하여 기존 사용자 계정을 열 수 있습니다.
Linux 터미널을 열고 다음 명령을 입력하여 사용자를 만듭니다.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdSSH 설정 및 키 생성
클러스터에서 시작, 중지, 분산 데몬 셸 작업과 같은 다른 작업을 수행하려면 SSH 설정이 필요합니다. 다른 Hadoop 사용자를 인증하려면 Hadoop 사용자에 대해 공개 / 개인 키 쌍을 제공하고이를 다른 사용자와 공유해야합니다.
다음 명령은 SSH를 사용하여 키 값 쌍을 생성하는 데 사용됩니다. 공개 키 양식 id_rsa.pub를 authorized_keys에 복사하고 소유자에게 각각 authorized_keys 파일에 대한 읽기 및 쓰기 권한을 제공하십시오.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys자바 설치
Java는 Hadoop의 주요 전제 조건입니다. 먼저 "java -version"명령을 사용하여 시스템에 java가 있는지 확인해야합니다. Java 버전 명령의 구문은 다음과 같습니다.
$ java -version모든 것이 정상이면 다음과 같은 출력을 제공합니다.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)시스템에 java가 설치되어 있지 않으면 아래 단계에 따라 java를 설치하십시오.
1 단계
다음 링크를 방문하여 java (JDK <최신 버전>-X64.tar.gz)를 다운로드하십시오. www.oracle.com
그때 jdk-7u71-linux-x64.tar.gz 시스템에 다운로드됩니다.
2 단계
일반적으로 다운로드 폴더에서 다운로드 한 Java 파일을 찾을 수 있습니다. 그것을 확인하고 추출jdk-7u71-linux-x64.gz 다음 명령을 사용하여 파일.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gz3 단계
모든 사용자가 Java를 사용할 수 있도록하려면 "/ usr / local /"위치로 이동해야합니다. 루트를 열고 다음 명령을 입력하십시오.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exit4 단계
설정 용 PATH 과 JAVA_HOME 변수에 다음 명령을 추가하십시오. ~/.bashrc 파일.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=$PATH:$JAVA_HOME/bin이제 모든 변경 사항을 현재 실행중인 시스템에 적용합니다.
$ source ~/.bashrc5 단계
다음 명령을 사용하여 Java 대안을 구성하십시오-
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jar이제 위에서 설명한대로 터미널에서 java -version 명령을 확인합니다.
Hadoop 다운로드
다음 명령을 사용하여 Apache 소프트웨어 기반에서 Hadoop 2.4.1을 다운로드하고 추출합니다.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitHadoop 작동 모드
Hadoop을 다운로드하면 지원되는 세 가지 모드 중 하나에서 Hadoop 클러스터를 작동 할 수 있습니다.
Local/Standalone Mode − 시스템에 Hadoop을 다운로드하면 기본적으로 독립형 모드로 구성되며 단일 Java 프로세스로 실행할 수 있습니다.
Pseudo Distributed Mode− 단일 머신에 대한 분산 시뮬레이션입니다. hdfs, yarn, MapReduce 등과 같은 각 Hadoop 데몬은 별도의 Java 프로세스로 실행됩니다. 이 모드는 개발에 유용합니다.
Fully Distributed Mode−이 모드는 클러스터로 최소 2 개 이상의 머신으로 완전히 분산됩니다. 이 모드는 다음 장에서 자세히 다룰 것입니다.
독립형 모드로 Hadoop 설치
여기서 우리는 Hadoop 2.4.1 독립형 모드에서.
실행중인 데몬이 없으며 모든 것이 단일 JVM에서 실행됩니다. 독립 실행 형 모드는 테스트 및 디버그가 쉽기 때문에 개발 중에 MapReduce 프로그램을 실행하는 데 적합합니다.
Hadoop 설정
다음 명령을 추가하여 Hadoop 환경 변수를 설정할 수 있습니다. ~/.bashrc 파일.
export HADOOP_HOME=/usr/local/hadoop계속 진행하기 전에 Hadoop이 제대로 작동하는지 확인해야합니다. 다음 명령을 실행하십시오-
$ hadoop version설정에 문제가 없으면 다음 결과가 표시됩니다.
Hadoop 2.4.1
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4Hadoop의 독립형 모드 설정이 제대로 작동하고 있음을 의미합니다. 기본적으로 Hadoop은 단일 시스템에서 비 분산 모드로 실행되도록 구성됩니다.
예
Hadoop의 간단한 예를 살펴 보겠습니다. Hadoop 설치는 MapReduce의 기본 기능을 제공하고 Pi 값, 주어진 파일 목록의 단어 수 등과 같은 계산에 사용할 수있는 다음 예제 MapReduce jar 파일을 제공합니다.
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar몇 개의 파일을 푸시 할 입력 디렉토리를 만들고 해당 파일의 총 단어 수를 계산해야합니다. 총 단어 수를 계산하기 위해 .jar 파일에 단어 수 구현이 포함되어 있으면 MapReduce를 작성할 필요가 없습니다. 동일한 .jar 파일을 사용하여 다른 예제를 시도 할 수 있습니다. 다음 명령을 실행하여 hadoop-mapreduce-examples-2.2.0.jar 파일로 지원되는 MapReduce 기능 프로그램을 확인하십시오.
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar1 단계
입력 디렉터리에 임시 콘텐츠 파일을 만듭니다. 작업하고 싶은 곳이면 어디든이 입력 디렉토리를 만들 수 있습니다.
$ mkdir input $ cp $HADOOP_HOME/*.txt input $ ls -l input입력 디렉토리에 다음 파일이 제공됩니다.
total 24
-rw-r--r-- 1 root root 15164 Feb 21 10:14 LICENSE.txt
-rw-r--r-- 1 root root 101 Feb 21 10:14 NOTICE.txt
-rw-r--r-- 1 root root 1366 Feb 21 10:14 README.txt이러한 파일은 Hadoop 설치 홈 디렉토리에서 복사되었습니다. 실험을 위해 다양하고 큰 파일 세트를 가질 수 있습니다.
2 단계
다음과 같이 입력 디렉토리에서 사용 가능한 모든 파일의 총 단어 수를 계산하는 Hadoop 프로세스를 시작하겠습니다.
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar wordcount input output3 단계
Step-2는 필요한 처리를 수행하고 output / part-r00000 파일에 출력을 저장합니다.-
$cat output/*입력 디렉토리에서 사용 가능한 모든 파일에서 사용 가능한 총 개수와 함께 모든 단어를 나열합니다.
"AS 4
"Contribution" 1
"Contributor" 1
"Derivative 1
"Legal 1
"License" 1
"License"); 1
"Licensor" 1
"NOTICE” 1
"Not 1
"Object" 1
"Source” 1
"Work” 1
"You" 1
"Your") 1
"[]" 1
"control" 1
"printed 1
"submitted" 1
(50%) 1
(BIS), 1
(C) 1
(Don't) 1
(ECCN) 1
(INCLUDING 2
(INCLUDING, 2
.............의사 분산 모드에서 Hadoop 설치
의사 분산 모드에서 Hadoop 2.4.1을 설치하려면 아래 단계를 따르십시오.
1 단계-Hadoop 설정
다음 명령을 추가하여 Hadoop 환경 변수를 설정할 수 있습니다. ~/.bashrc 파일.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME이제 모든 변경 사항을 현재 실행중인 시스템에 적용합니다.
$ source ~/.bashrc2 단계-Hadoop 구성
"$ HADOOP_HOME / etc / hadoop"위치에서 모든 Hadoop 구성 파일을 찾을 수 있습니다. Hadoop 인프라에 따라 해당 구성 파일을 변경해야합니다.
$ cd $HADOOP_HOME/etc/hadoopJava에서 Hadoop 프로그램을 개발하려면 다음에서 Java 환경 변수를 재설정해야합니다. hadoop-env.sh 대체하여 파일 JAVA_HOME 시스템의 java 위치와 함께 값.
export JAVA_HOME=/usr/local/jdk1.7.0_71다음은 Hadoop을 구성하기 위해 편집해야하는 파일 목록입니다.
core-site.xml
그만큼 core-site.xml 파일에는 Hadoop 인스턴스에 사용되는 포트 번호, 파일 시스템에 할당 된 메모리, 데이터 저장을위한 메모리 제한 및 읽기 / 쓰기 버퍼 크기와 같은 정보가 포함됩니다.
core-site.xml을 열고 <configuration>, </ configuration> 태그 사이에 다음 속성을 추가합니다.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
그만큼 hdfs-site.xml파일에는 복제 데이터 값, 이름 노드 경로 및 로컬 파일 시스템의 데이터 노드 경로와 같은 정보가 포함됩니다. Hadoop 인프라를 저장하려는 장소를 의미합니다.
다음 데이터를 가정 해 보겠습니다.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanode이 파일을 열고이 파일의 <configuration> </ configuration> 태그 사이에 다음 속성을 추가합니다.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>Note − 위 파일에서 모든 속성 값은 사용자 정의되며 Hadoop 인프라에 따라 변경할 수 있습니다.
yarn-site.xml
이 파일은 yarn을 Hadoop으로 구성하는 데 사용됩니다. yarn-site.xml 파일을 열고이 파일의 <configuration>, </ configuration> 태그 사이에 다음 특성을 추가하십시오.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
이 파일은 우리가 사용하는 MapReduce 프레임 워크를 지정하는 데 사용됩니다. 기본적으로 Hadoop에는 yarn-site.xml의 템플릿이 포함되어 있습니다. 먼저 파일을 복사해야합니다.mapred-site.xml.template ...에 mapred-site.xml 다음 명령을 사용하여 파일.
$ cp mapred-site.xml.template mapred-site.xml열다 mapred-site.xml 파일을 열고이 파일의 <configuration>, </ configuration> 태그 사이에 다음 속성을 추가합니다.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Hadoop 설치 확인
다음 단계는 Hadoop 설치를 확인하는 데 사용됩니다.
1 단계-이름 노드 설정
다음과 같이“hdfs namenode -format”명령을 사용하여 namenode를 설정합니다.
$ cd ~
$ hdfs namenode -format예상되는 결과는 다음과 같습니다.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/2 단계-Hadoop dfs 확인
다음 명령은 dfs를 시작하는 데 사용됩니다. 이 명령을 실행하면 Hadoop 파일 시스템이 시작됩니다.
$ start-dfs.sh예상 출력은 다음과 같습니다.
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]3 단계-Yarn 스크립트 확인
다음 명령은 yarn 스크립트를 시작하는 데 사용됩니다. 이 명령을 실행하면 yarn 데몬이 시작됩니다.
$ start-yarn.sh다음과 같이 예상되는 출력-
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-nodemanager-localhost.out4 단계-브라우저에서 Hadoop 액세스
Hadoop에 액세스하기위한 기본 포트 번호는 50070입니다. 다음 URL을 사용하여 브라우저에서 Hadoop 서비스를 가져옵니다.
http://localhost:50070/
5 단계-클러스터의 모든 애플리케이션 확인
클러스터의 모든 애플리케이션에 액세스하기위한 기본 포트 번호는 8088입니다.이 서비스를 방문하려면 다음 URL을 사용하십시오.
http://localhost:8088/
Hadoop 파일 시스템은 분산 파일 시스템 설계를 사용하여 개발되었습니다. 상용 하드웨어에서 실행됩니다. 다른 분산 시스템과 달리 HDFS는 내결함성이 뛰어나고 저렴한 하드웨어를 사용하여 설계되었습니다.
HDFS는 매우 많은 양의 데이터를 보유하고 더 쉬운 액세스를 제공합니다. 이러한 방대한 데이터를 저장하기 위해 파일은 여러 시스템에 저장됩니다. 이러한 파일은 오류 발생시 가능한 데이터 손실로부터 시스템을 구하기 위해 중복 방식으로 저장됩니다. HDFS는 또한 응용 프로그램을 병렬 처리에 사용할 수 있도록합니다.
HDFS의 특징
- 분산 저장 및 처리에 적합합니다.
- Hadoop은 HDFS와 상호 작용할 수있는 명령 인터페이스를 제공합니다.
- 네임 노드 및 데이터 노드의 내장 서버는 사용자가 클러스터 상태를 쉽게 확인할 수 있도록 도와줍니다.
- 파일 시스템 데이터에 대한 스트리밍 액세스.
- HDFS는 파일 권한 및 인증을 제공합니다.
HDFS 아키텍처
다음은 Hadoop 파일 시스템의 아키텍처입니다.
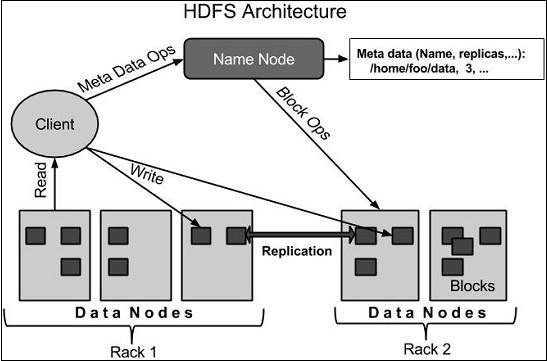
HDFS는 마스터-슬레이브 아키텍처를 따르며 다음과 같은 요소가 있습니다.
네임 노드
네임 노드는 GNU / 리눅스 운영 체제와 네임 노드 소프트웨어를 포함하는 상용 하드웨어입니다. 상용 하드웨어에서 실행할 수있는 소프트웨어입니다. 네임 노드가있는 시스템은 마스터 서버 역할을하며 다음 작업을 수행합니다.
파일 시스템 네임 스페이스를 관리합니다.
파일에 대한 클라이언트의 액세스를 규제합니다.
또한 파일 및 디렉토리의 이름 변경, 닫기 및 열기와 같은 파일 시스템 작업을 실행합니다.
데이터 노드
데이터 노드는 GNU / Linux 운영 체제와 데이터 노드 소프트웨어가있는 상용 하드웨어입니다. 클러스터의 모든 노드 (일반 하드웨어 / 시스템)에는 데이터 노드가 있습니다. 이러한 노드는 시스템의 데이터 저장소를 관리합니다.
데이터 노드는 클라이언트 요청에 따라 파일 시스템에서 읽기-쓰기 작업을 수행합니다.
또한 네임 노드의 지시에 따라 블록 생성, 삭제, 복제 등의 작업을 수행합니다.
블록
일반적으로 사용자 데이터는 HDFS의 파일에 저장됩니다. 파일 시스템의 파일은 하나 이상의 세그먼트로 나뉘거나 개별 데이터 노드에 저장됩니다. 이러한 파일 세그먼트를 블록이라고합니다. 즉, HDFS가 읽거나 쓸 수있는 최소 데이터 양을 블록이라고합니다. 기본 블록 크기는 64MB이지만 HDFS 구성 변경 필요에 따라 늘릴 수 있습니다.
HDFS의 목표
Fault detection and recovery− HDFS에는 많은 수의 상용 하드웨어가 포함되어 있기 때문에 구성 요소의 고장이 자주 발생합니다. 따라서 HDFS에는 빠르고 자동으로 오류를 감지하고 복구 할 수있는 메커니즘이 있어야합니다.
Huge datasets − HDFS는 대규모 데이터 세트가있는 애플리케이션을 관리하기 위해 클러스터 당 수백 개의 노드를 가져야합니다.
Hardware at data− 데이터 근처에서 계산이 이루어지면 요청 된 작업을 효율적으로 수행 할 수 있습니다. 특히 대규모 데이터 세트가 관련된 경우 네트워크 트래픽을 줄이고 처리량을 증가시킵니다.
HDFS 시작
처음에는 구성된 HDFS 파일 시스템을 포맷하고 이름 노드 (HDFS 서버)를 열고 다음 명령을 실행해야합니다.
$ hadoop namenode -formatHDFS를 포맷 한 후 분산 파일 시스템을 시작합니다. 다음 명령은 namenode와 데이터 노드를 클러스터로 시작합니다.
$ start-dfs.shHDFS에서 파일 나열
서버에 정보를로드 한 후 다음을 사용하여 디렉토리의 파일 목록, 파일 상태를 찾을 수 있습니다. ‘ls’. 아래에 주어진 구문은ls 인수로 디렉토리 또는 파일 이름에 전달할 수 있습니다.
$ $HADOOP_HOME/bin/hadoop fs -ls <args>HDFS에 데이터 삽입
hdfs 파일 시스템에 저장되어야하는 로컬 시스템의 file.txt 파일에 데이터가 있다고 가정합니다. Hadoop 파일 시스템에 필요한 파일을 삽입하려면 아래 단계를 따르십시오.
1 단계
입력 디렉터리를 만들어야합니다.
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/input2 단계
put 명령을 사용하여 로컬 시스템에서 Hadoop 파일 시스템으로 데이터 파일을 전송하고 저장합니다.
$ $HADOOP_HOME/bin/hadoop fs -put /home/file.txt /user/input3 단계
ls 명령을 사용하여 파일을 확인할 수 있습니다.
$ $HADOOP_HOME/bin/hadoop fs -ls /user/inputHDFS에서 데이터 검색
HDFS에 다음과 같은 파일이 있다고 가정합니다. outfile. 다음은 Hadoop 파일 시스템에서 필요한 파일을 검색하는 간단한 데모입니다.
1 단계
처음에는 다음을 사용하여 HDFS의 데이터를 봅니다. cat 명령.
$ $HADOOP_HOME/bin/hadoop fs -cat /user/output/outfile2 단계
다음을 사용하여 HDFS에서 로컬 파일 시스템으로 파일 가져 오기 get 명령.
$ $HADOOP_HOME/bin/hadoop fs -get /user/output/ /home/hadoop_tp/HDFS 종료
다음 명령을 사용하여 HDFS를 종료 할 수 있습니다.
$ stop-dfs.sh더 많은 명령이 있습니다. "$HADOOP_HOME/bin/hadoop fs"여기에 설명 된 것보다 더 기본적인 작업이 시작됩니다. 추가 인수없이 ./bin/hadoop dfs를 실행하면 FsShell 시스템에서 실행할 수있는 모든 명령이 나열됩니다. 더욱이,$HADOOP_HOME/bin/hadoop fs -help 멈춘 경우 commandName은 해당 작업에 대한 간단한 사용 요약을 표시합니다.
모든 작업에 대한 표는 다음과 같습니다. 다음 규칙은 매개 변수에 사용됩니다-
"<path>" means any file or directory name.
"<path>..." means one or more file or directory names.
"<file>" means any filename.
"<src>" and "<dest>" are path names in a directed operation.
"<localSrc>" and "<localDest>" are paths as above, but on the local file system.다른 모든 파일 및 경로 이름은 HDFS 내부의 개체를 참조합니다.
| Sr. 아니요 | 명령 및 설명 |
|---|---|
| 1 | -ls <path> 각 항목에 대한 이름, 권한, 소유자, 크기 및 수정 날짜를 표시하여 경로로 지정된 디렉토리의 내용을 나열합니다. |
| 2 | -lsr <path> -ls처럼 작동하지만 경로의 모든 하위 디렉토리에있는 항목을 재귀 적으로 표시합니다. |
| 삼 | -du <path> 경로와 일치하는 모든 파일에 대한 디스크 사용량 (바이트)을 표시합니다. 파일 이름은 전체 HDFS 프로토콜 접두사로보고됩니다. |
| 4 | -dus <path> -du와 비슷하지만 경로에있는 모든 파일 / 디렉토리의 디스크 사용량 요약을 인쇄합니다. |
| 5 | -mv <src><dest> HDFS 내에서 src로 표시된 파일 또는 디렉토리를 dest로 이동합니다. |
| 6 | -cp <src> <dest> HDFS 내에서 src로 식별 된 파일 또는 디렉토리를 dest에 복사합니다. |
| 7 | -rm <path> 경로로 식별되는 파일 또는 빈 디렉토리를 제거합니다. |
| 8 | -rmr <path> 경로로 식별되는 파일 또는 디렉토리를 제거합니다. 하위 항목 (예 : 경로의 파일 또는 하위 디렉터리)을 반복적으로 삭제합니다. |
| 9 | -put <localSrc> <dest> localSrc로 식별 된 로컬 파일 시스템의 파일 또는 디렉토리를 DFS 내에서 대상으로 복사합니다. |
| 10 | -copyFromLocal <localSrc> <dest> -put과 동일 |
| 11 | -moveFromLocal <localSrc> <dest> localSrc로 식별 된 로컬 파일 시스템의 파일 또는 디렉터리를 HDFS 내에서 dest로 복사 한 다음 성공시 로컬 복사본을 삭제합니다. |
| 12 | -get [-crc] <src> <localDest> src로 식별 된 HDFS의 파일 또는 디렉토리를 localDest로 식별 된 로컬 파일 시스템 경로에 복사합니다. |
| 13 | -getmerge <src> <localDest> HDFS의 src 경로와 일치하는 모든 파일을 검색하고 localDest로 식별되는 로컬 파일 시스템의 병합 된 단일 파일로 복사합니다. |
| 14 | -cat <filen-ame> stdout에 파일 이름의 내용을 표시합니다. |
| 15 | -copyToLocal <src> <localDest> -get과 동일 |
| 16 | -moveToLocal <src> <localDest> -get처럼 작동하지만 성공하면 HDFS 사본을 삭제합니다. |
| 17 | -mkdir <path> HDFS에 path라는 디렉토리를 생성합니다. 누락 된 경로에 부모 디렉토리를 만듭니다 (예 : Linux의 경우 mkdir -p). |
| 18 | -setrep [-R] [-w] rep <path> rep에 대한 경로로 식별되는 파일에 대한 대상 복제 요소를 설정합니다. (실제 복제 요소는 시간이 지남에 따라 대상으로 이동합니다) |
| 19 | -touchz <path> 현재 시간을 타임 스탬프로 포함하는 경로에 파일을 만듭니다. 파일이 이미 크기 0이 아닌 경우 경로에 파일이 이미 있으면 실패합니다. |
| 20 | -test -[ezd] <path> 경로가 있으면 1을 반환합니다. 길이가 0입니다. 또는 디렉토리 또는 0입니다. |
| 21 | -stat [format] <path> 경로에 대한 정보를 인쇄합니다. 형식은 블록 (% b), 파일 이름 (% n), 블록 크기 (% o), 복제 (% r) 및 수정 날짜 (% y, % Y)에서 파일 크기를 허용하는 문자열입니다. |
| 22 | -tail [-f] <file2name> stdout에 파일의 마지막 1KB를 표시합니다. |
| 23 | -chmod [-R] mode,mode,... <path>... 경로로 식별되는 하나 이상의 개체와 관련된 파일 권한을 변경합니다 .... R을 사용하여 반복적으로 변경을 수행합니다. 모드는 3 자리 8 진수 모드 또는 {augo} +/- {rwxX}입니다. 범위가 지정되지 않은 것으로 가정하고 umask를 적용하지 않습니다. |
| 24 | -chown [-R] [owner][:[group]] <path>... 경로로 식별되는 파일 또는 디렉토리에 대한 소유 사용자 및 / 또는 그룹을 설정합니다 .... -R이 지정된 경우 소유자를 반복적으로 설정합니다. |
| 25 | -chgrp [-R] group <path>... 경로로 식별되는 파일 또는 디렉토리에 대한 소유 그룹을 설정합니다 .... -R이 지정된 경우 그룹을 재귀 적으로 설정합니다. |
| 26 | -help <cmd-name> 위에 나열된 명령 중 하나에 대한 사용 정보를 반환합니다. cmd에서 선행 '-'문자를 생략해야합니다. |
MapReduce는 대규모 상용 하드웨어 클러스터에서 신뢰할 수있는 방식으로 대량의 데이터를 병렬로 처리하는 애플리케이션을 작성할 수있는 프레임 워크입니다.
MapReduce 란 무엇입니까?
MapReduce는 Java 기반 분산 컴퓨팅을위한 처리 기술 및 프로그램 모델입니다. MapReduce 알고리즘에는 Map 및 Reduce라는 두 가지 중요한 작업이 포함됩니다. Map은 데이터 세트를 가져 와서 개별 요소가 튜플 (키 / 값 쌍)로 분할되는 다른 데이터 세트로 변환합니다. 둘째, 맵의 출력을 입력으로 가져와 해당 데이터 튜플을 더 작은 튜플 세트로 결합하는 작업을 줄입니다. MapReduce라는 이름의 순서에서 알 수 있듯이 축소 작업은 항상 맵 작업 후에 수행됩니다.
MapReduce의 주요 장점은 여러 컴퓨팅 노드에서 데이터 처리를 쉽게 확장 할 수 있다는 것입니다. MapReduce 모델에서 데이터 처리 프리미티브를 매퍼 및 리듀서라고합니다. 데이터 처리 애플리케이션을 매퍼 와 리듀서 로 분해하는 것은 때때로 사소한 일이 아닙니다. 그러나 일단 MapReduce 형식으로 애플리케이션을 작성하면 클러스터에서 수백, 수천 또는 수만 대의 시스템을 실행하도록 애플리케이션을 확장하는 것은 구성 변경에 불과합니다. 이 간단한 확장 성은 많은 프로그래머가 MapReduce 모델을 사용하도록 유도했습니다.
알고리즘
일반적으로 MapReduce 패러다임은 데이터가있는 곳으로 컴퓨터를 보내는 것을 기반으로합니다!
MapReduce 프로그램은 맵 단계, 셔플 단계, 축소 단계의 세 단계로 실행됩니다.
Map stage− 맵 또는 맵퍼의 임무는 입력 데이터를 처리하는 것입니다. 일반적으로 입력 데이터는 파일 또는 디렉토리 형식이며 HDFS (Hadoop 파일 시스템)에 저장됩니다. 입력 파일은 한 줄씩 매퍼 함수에 전달됩니다. 매퍼는 데이터를 처리하고 몇 개의 작은 데이터 청크를 만듭니다.
Reduce stage −이 단계는 Shuffle 무대와 Reduce단계. Reducer의 역할은 매퍼에서 가져온 데이터를 처리하는 것입니다. 처리 후 HDFS에 저장되는 새로운 출력 세트를 생성합니다.
MapReduce 작업 중에 Hadoop은 Map 및 Reduce 작업을 클러스터의 적절한 서버로 보냅니다.
프레임 워크는 작업 실행, 작업 완료 확인 및 노드 간 클러스터 주변의 데이터 복사와 같은 데이터 전달의 모든 세부 정보를 관리합니다.
대부분의 컴퓨팅은 네트워크 트래픽을 줄이는 로컬 디스크의 데이터가있는 노드에서 발생합니다.
주어진 작업을 완료 한 후 클러스터는 데이터를 수집 및 축소하여 적절한 결과를 형성하고 다시 Hadoop 서버로 보냅니다.

입력 및 출력 (Java Perspective)
MapReduce 프레임 워크는 <key, value> 쌍에서 작동합니다. 즉, 프레임 워크는 작업에 대한 입력을 <key, value> 쌍의 집합으로보고 작업의 출력으로 <key, value> 쌍의 집합을 생성합니다. , 아마도 다른 유형의.
키 및 값 클래스는 프레임 워크에 의해 직렬화되어야하므로 쓰기 가능한 인터페이스를 구현해야합니다. 또한 키 클래스는 프레임 워크 별 정렬을 용이하게하기 위해 Writable-Comparable 인터페이스를 구현해야합니다. 입력 및 출력 유형MapReduce job − (입력) <k1, v1> → 맵 → <k2, v2> → 감소 → <k3, v3> (출력).
| 입력 | 산출 | |
|---|---|---|
| 지도 | <k1, v1> | 목록 (<k2, v2>) |
| 줄이다 | <k2, 목록 (v2)> | 목록 (<k3, v3>) |
술어
PayLoad − 응용 프로그램은 Map 및 Reduce 기능을 구현하고 작업의 핵심을 형성합니다.
Mapper − Mapper는 입력 키 / 값 쌍을 중간 키 / 값 쌍 세트에 매핑합니다.
NamedNode − HDFS (Hadoop Distributed File System)를 관리하는 노드.
DataNode − 처리가 발생하기 전에 데이터가 미리 표시되는 노드.
MasterNode − JobTracker가 실행되고 클라이언트의 작업 요청을 수락하는 노드.
SlaveNode − Map and Reduce 프로그램이 실행되는 노드.
JobTracker − 작업을 예약하고 작업 추적기에 할당 된 작업을 추적합니다.
Task Tracker − 작업을 추적하고 상태를 JobTracker에보고합니다.
Job − 프로그램은 데이터 세트 전체에서 Mapper 및 Reducer를 실행하는 것입니다.
Task − 데이터 조각에 대한 Mapper 또는 Reducer 실행.
Task Attempt − SlaveNode에서 작업을 실행하려는 시도의 특정 인스턴스.
예제 시나리오
아래는 조직의 전기 소비에 관한 데이터입니다. 여기에는 월별 전기 소비량과 다양한 연도의 연간 평균이 포함됩니다.
| 1 월 | 2 월 | 망치다 | 4 월 | 할 수있다 | 6 월 | 7 월 | 8 월 | 9 월 | 10 월 | 11 월 | 12 월 | 평균 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 년 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 년 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 년 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 년 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 년 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
위의 데이터가 입력으로 주어지면이를 처리 할 응용 프로그램을 작성하고 최대 사용 연도, 최소 사용 연도 등을 찾는 결과를 생성해야합니다. 이것은 제한된 수의 레코드를 가진 프로그래머를위한 워크 오버입니다. 그들은 단순히 논리를 작성하여 필요한 출력을 생성하고 작성된 응용 프로그램에 데이터를 전달합니다.
그러나 형성 이후 특정주의 모든 대규모 산업의 전력 소비를 나타내는 데이터를 생각해보십시오.
이러한 대량 데이터를 처리하기 위해 애플리케이션을 작성할 때
실행하는 데 많은 시간이 걸립니다.
데이터를 소스에서 네트워크 서버로 이동할 때 네트워크 트래픽이 많이 발생합니다.
이러한 문제를 해결하기 위해 MapReduce 프레임 워크가 있습니다.
입력 데이터
위의 데이터는 다음과 같이 저장됩니다. sample.txt입력으로 제공됩니다. 입력 파일은 아래와 같습니다.
1979 23 23 2 43 24 25 26 26 26 26 25 26 25
1980 26 27 28 28 28 30 31 31 31 30 30 30 29
1981 31 32 32 32 33 34 35 36 36 34 34 34 34
1984 39 38 39 39 39 41 42 43 40 39 38 38 40
1985 38 39 39 39 39 41 41 41 00 40 39 39 45예제 프로그램
다음은 MapReduce 프레임 워크를 사용하는 샘플 데이터에 대한 프로그램입니다.
package hadoop;
import java.util.*;
import java.io.IOException;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class ProcessUnits {
//Mapper class
public static class E_EMapper extends MapReduceBase implements
Mapper<LongWritable ,/*Input key Type */
Text, /*Input value Type*/
Text, /*Output key Type*/
IntWritable> /*Output value Type*/
{
//Map function
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
String lasttoken = null;
StringTokenizer s = new StringTokenizer(line,"\t");
String year = s.nextToken();
while(s.hasMoreTokens()) {
lasttoken = s.nextToken();
}
int avgprice = Integer.parseInt(lasttoken);
output.collect(new Text(year), new IntWritable(avgprice));
}
}
//Reducer class
public static class E_EReduce extends MapReduceBase implements Reducer< Text, IntWritable, Text, IntWritable > {
//Reduce function
public void reduce( Text key, Iterator <IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int maxavg = 30;
int val = Integer.MIN_VALUE;
while (values.hasNext()) {
if((val = values.next().get())>maxavg) {
output.collect(key, new IntWritable(val));
}
}
}
}
//Main function
public static void main(String args[])throws Exception {
JobConf conf = new JobConf(ProcessUnits.class);
conf.setJobName("max_eletricityunits");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(E_EMapper.class);
conf.setCombinerClass(E_EReduce.class);
conf.setReducerClass(E_EReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}위 프로그램을 다른 이름으로 저장 ProcessUnits.java. 프로그램의 컴파일 및 실행은 다음과 같습니다.
프로세스 단위 프로그램의 컴파일 및 실행
Hadoop 사용자의 홈 디렉토리 (예 : / home / hadoop)에 있다고 가정 해 보겠습니다.
위의 프로그램을 컴파일하고 실행하려면 아래 단계를 따르십시오.
1 단계
다음 명령은 컴파일 된 자바 클래스를 저장할 디렉토리를 만드는 것입니다.
$ mkdir units2 단계
다운로드 Hadoop-core-1.2.1.jar,MapReduce 프로그램을 컴파일하고 실행하는 데 사용됩니다. 다음 링크 mvnrepository.com 을 방문하여 jar를 다운로드하십시오. 다운로드 한 폴더가/home/hadoop/.
3 단계
다음 명령은 컴파일에 사용됩니다. ProcessUnits.java 프로그램 및 프로그램을위한 jar 생성.
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java
$ jar -cvf units.jar -C units/ .4 단계
다음 명령은 HDFS에서 입력 디렉토리를 만드는 데 사용됩니다.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir5 단계
다음 명령은 이름이 지정된 입력 파일을 복사하는 데 사용됩니다. sample.txtHDFS의 입력 디렉토리에 있습니다.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dir6 단계
다음 명령은 입력 디렉토리의 파일을 확인하는 데 사용됩니다.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/7 단계
다음 명령은 입력 디렉토리에서 입력 파일을 가져와 Eleunit_max 애플리케이션을 실행하는 데 사용됩니다.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir파일이 실행될 때까지 잠시 기다리십시오. 실행 후 아래와 같이 출력에는 입력 분할 수, Map 작업 수, 감속기 작업 수 등이 포함됩니다.
INFO mapreduce.Job: Job job_1414748220717_0002
completed successfully
14/10/31 06:02:52
INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read = 61
FILE: Number of bytes written = 279400
FILE: Number of read operations = 0
FILE: Number of large read operations = 0
FILE: Number of write operations = 0
HDFS: Number of bytes read = 546
HDFS: Number of bytes written = 40
HDFS: Number of read operations = 9
HDFS: Number of large read operations = 0
HDFS: Number of write operations = 2 Job Counters
Launched map tasks = 2
Launched reduce tasks = 1
Data-local map tasks = 2
Total time spent by all maps in occupied slots (ms) = 146137
Total time spent by all reduces in occupied slots (ms) = 441
Total time spent by all map tasks (ms) = 14613
Total time spent by all reduce tasks (ms) = 44120
Total vcore-seconds taken by all map tasks = 146137
Total vcore-seconds taken by all reduce tasks = 44120
Total megabyte-seconds taken by all map tasks = 149644288
Total megabyte-seconds taken by all reduce tasks = 45178880
Map-Reduce Framework
Map input records = 5
Map output records = 5
Map output bytes = 45
Map output materialized bytes = 67
Input split bytes = 208
Combine input records = 5
Combine output records = 5
Reduce input groups = 5
Reduce shuffle bytes = 6
Reduce input records = 5
Reduce output records = 5
Spilled Records = 10
Shuffled Maps = 2
Failed Shuffles = 0
Merged Map outputs = 2
GC time elapsed (ms) = 948
CPU time spent (ms) = 5160
Physical memory (bytes) snapshot = 47749120
Virtual memory (bytes) snapshot = 2899349504
Total committed heap usage (bytes) = 277684224
File Output Format Counters
Bytes Written = 408 단계
다음 명령은 출력 폴더에서 결과 파일을 확인하는 데 사용됩니다.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/9 단계
다음 명령은 다음에서 출력을 보는 데 사용됩니다. Part-00000 파일. 이 파일은 HDFS에서 생성됩니다.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000다음은 MapReduce 프로그램에서 생성 된 출력입니다.
1981 34
1984 40
1985 4510 단계
다음 명령은 분석을 위해 HDFS에서 로컬 파일 시스템으로 출력 폴더를 복사하는 데 사용됩니다.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs get output_dir /home/hadoop중요한 명령
모든 Hadoop 명령은 $HADOOP_HOME/bin/hadoop명령. 인수없이 Hadoop 스크립트를 실행하면 모든 명령에 대한 설명이 인쇄됩니다.
Usage − hadoop [--config confdir] 명령
다음 표에는 사용 가능한 옵션과 설명이 나열되어 있습니다.
| Sr. 아니. | 옵션 및 설명 |
|---|---|
| 1 | namenode -format DFS 파일 시스템을 포맷합니다. |
| 2 | secondarynamenode DFS 보조 네임 노드를 실행합니다. |
| 삼 | namenode DFS 네임 노드를 실행합니다. |
| 4 | datanode DFS 데이터 노드를 실행합니다. |
| 5 | dfsadmin DFS 관리 클라이언트를 실행합니다. |
| 6 | mradmin Map-Reduce 관리 클라이언트를 실행합니다. |
| 7 | fsck DFS 파일 시스템 검사 유틸리티를 실행합니다. |
| 8 | fs 일반 파일 시스템 사용자 클라이언트를 실행합니다. |
| 9 | balancer 클러스터 균형 조정 유틸리티를 실행합니다. |
| 10 | oiv 오프라인 fsimage 뷰어를 fsimage에 적용합니다. |
| 11 | fetchdt NameNode에서 위임 토큰을 가져옵니다. |
| 12 | jobtracker MapReduce 작업 추적기 노드를 실행합니다. |
| 13 | pipes 파이프 작업을 실행합니다. |
| 14 | tasktracker MapReduce 작업 추적기 노드를 실행합니다. |
| 15 | historyserver 작업 기록 서버를 독립형 데몬으로 실행합니다. |
| 16 | job MapReduce 작업을 조작합니다. |
| 17 | queue JobQueue에 관한 정보를 가져옵니다. |
| 18 | version 버전을 인쇄합니다. |
| 19 | jar <jar> jar 파일을 실행합니다. |
| 20 | distcp <srcurl> <desturl> 파일 또는 디렉토리를 재귀 적으로 복사합니다. |
| 21 | distcp2 <srcurl> <desturl> DistCp 버전 2. |
| 22 | archive -archiveName NAME -p <parent path> <src>* <dest> 하둡 아카이브를 생성합니다. |
| 23 | classpath Hadoop jar 및 필수 라이브러리를 가져 오는 데 필요한 클래스 경로를 인쇄합니다. |
| 24 | daemonlog 각 데몬의 로그 수준 가져 오기 / 설정 |
MapReduce 작업과 상호 작용하는 방법
사용법-하둡 작업 [GENERIC_OPTIONS]
다음은 Hadoop 작업에서 사용할 수있는 일반 옵션입니다.
| Sr. 아니. | GENERIC_OPTION 및 설명 |
|---|---|
| 1 | -submit <job-file> 작업을 제출합니다. |
| 2 | -status <job-id> 지도를 인쇄하고 완료율과 모든 작업 카운터를 줄입니다. |
| 삼 | -counter <job-id> <group-name> <countername> 카운터 값을 인쇄합니다. |
| 4 | -kill <job-id> 일을 죽인다. |
| 5 | -events <job-id> <fromevent-#> <#-of-events> 주어진 범위에 대해 jobtracker가 수신 한 이벤트의 세부 사항을 인쇄합니다. |
| 6 | -history [all] <jobOutputDir> - history < jobOutputDir> 작업 세부 정보, 실패 및 종료 된 팁 세부 정보를 인쇄합니다. 성공한 작업 및 각 작업에 대한 작업 시도와 같은 작업에 대한 자세한 내용은 [all] 옵션을 지정하여 볼 수 있습니다. |
| 7 | -list[all] 모든 작업을 표시합니다. -list는 아직 완료되지 않은 작업 만 표시합니다. |
| 8 | -kill-task <task-id> 작업을 죽입니다. 종료 된 작업은 실패한 시도에 포함되지 않습니다. |
| 9 | -fail-task <task-id> 작업을 실패합니다. 실패한 작업은 실패한 시도로 계산됩니다. |
| 10 | -set-priority <job-id> <priority> 작업의 우선 순위를 변경합니다. 허용되는 우선 순위 값은 VERY_HIGH, HIGH, NORMAL, LOW, VERY_LOW입니다. |
작업 상태를 보려면
$ $HADOOP_HOME/bin/hadoop job -status <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -status job_201310191043_0004작업 output-dir의 기록을 보려면
$ $HADOOP_HOME/bin/hadoop job -history <DIR-NAME> e.g. $ $HADOOP_HOME/bin/hadoop job -history /user/expert/output직업을 죽이려면
$ $HADOOP_HOME/bin/hadoop job -kill <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -kill job_201310191043_0004Hadoop 스트리밍은 Hadoop 배포와 함께 제공되는 유틸리티입니다. 이 유틸리티를 사용하면 실행 파일 또는 스크립트를 매퍼 및 / 또는 감속기로 사용하여 Map / Reduce 작업을 만들고 실행할 수 있습니다.
Python을 사용한 예
Hadoop 스트리밍의 경우 단어 수 문제를 고려하고 있습니다. Hadoop의 모든 작업에는 매퍼와 리듀서의 두 단계가 있어야합니다. Hadoop에서 실행하기 위해 Python 스크립트에 매퍼 및 감속기에 대한 코드를 작성했습니다. Perl과 Ruby에서도 같은 내용을 작성할 수 있습니다.
매퍼 단계 코드
!/usr/bin/python
import sys
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Break the line into words
words = myline.split()
# Iterate the words list
for myword in words:
# Write the results to standard output
print '%s\t%s' % (myword, 1)이 파일에 실행 권한이 있는지 확인하십시오 (chmod + x / home / expert / hadoop-1.2.1 / mapper.py).
감속기 위상 코드
#!/usr/bin/python
from operator import itemgetter
import sys
current_word = ""
current_count = 0
word = ""
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Split the input we got from mapper.py word,
count = myline.split('\t', 1)
# Convert count variable to integer
try:
count = int(count)
except ValueError:
# Count was not a number, so silently ignore this line continue
if current_word == word:
current_count += count
else:
if current_word:
# Write result to standard output print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# Do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)Mapper 및 Reducer 코드를 Hadoop 홈 디렉토리의 mapper.py 및 reducer.py에 저장합니다. 이러한 파일에 실행 권한이 있는지 확인하십시오 (chmod + x mapper.py 및 chmod + x reducer.py). 파이썬은 들여 쓰기에 민감하므로 아래 링크에서 동일한 코드를 다운로드 할 수 있습니다.
WordCount 프로그램 실행
$ $HADOOP_HOME/bin/hadoop jar contrib/streaming/hadoop-streaming-1.
2.1.jar \
-input input_dirs \
-output output_dir \
-mapper <path/mapper.py \
-reducer <path/reducer.py명확한 가독성을 위해 줄 연속에 "\"가 사용됩니다.
예를 들어
./bin/hadoop jar contrib/streaming/hadoop-streaming-1.2.1.jar -input myinput -output myoutput -mapper /home/expert/hadoop-1.2.1/mapper.py -reducer /home/expert/hadoop-1.2.1/reducer.py스트리밍 작동 방식
위의 예에서 매퍼와 감속기는 모두 표준 입력에서 입력을 읽고 출력을 표준 출력으로 내보내는 Python 스크립트입니다. 이 유틸리티는 매핑 / 축소 작업을 만들고 적절한 클러스터에 작업을 제출하며 완료 될 때까지 작업 진행 상황을 모니터링합니다.
매퍼에 대한 스크립트가 지정되면 매퍼가 초기화 될 때 각 매퍼 작업이 스크립트를 별도의 프로세스로 시작합니다. 매퍼 태스크가 실행되면 입력을 라인으로 변환하고 라인을 프로세스의 표준 입력 (STDIN)에 공급합니다. 그 동안 매퍼는 프로세스의 표준 출력 (STDOUT)에서 라인 지향 출력을 수집하고 각 라인을 매퍼의 출력으로 수집되는 키 / 값 쌍으로 변환합니다. 기본적으로 첫 번째 탭 문자까지의 행 접두사가 키이고 나머지 행 (탭 문자 제외)이 값이됩니다. 행에 탭 문자가 없으면 전체 행이 키로 간주되고 값은 널입니다. 그러나 필요에 따라 사용자 정의 할 수 있습니다.
감속기에 대한 스크립트가 지정되면 각 감속기 작업은 스크립트를 별도의 프로세스로 시작한 다음 감속기가 초기화됩니다. 감속기 작업이 실행되면 입력 키 / 값 쌍을 행으로 변환하고 해당 행을 프로세스의 표준 입력 (STDIN)에 공급합니다. 그 동안 감속기는 프로세스의 표준 출력 (STDOUT)에서 라인 지향 출력을 수집하고 각 라인을 키 / 값 쌍으로 변환하여 감속기의 출력으로 수집합니다. 기본적으로 첫 번째 탭 문자까지의 행 접 두부가 키이고 나머지 행 (탭 문자 제외)이 값입니다. 그러나 이것은 특정 요구 사항에 따라 사용자 지정할 수 있습니다.
중요한 명령
| 매개 변수 | 옵션 | 기술 |
|---|---|---|
| -입력 디렉토리 / 파일 이름 | 필수 | 매퍼의 위치를 입력합니다. |
| -출력 디렉토리 이름 | 필수 | 감속기의 출력 위치. |
| -매퍼 실행 파일 또는 스크립트 또는 JavaClassName | 필수 | 매퍼 실행 가능. |
| -reducer 실행 파일 또는 스크립트 또는 JavaClassName | 필수 | 감속기 실행 가능. |
| -파일 파일 이름 | 선택 과목 | 매퍼, 감속기 또는 결합기를 컴퓨팅 노드에서 로컬로 사용할 수 있도록합니다. |
| -inputformat JavaClassName | 선택 과목 | 제공하는 클래스는 Text 클래스의 키 / 값 쌍을 반환해야합니다. 지정하지 않으면 TextInputFormat이 기본값으로 사용됩니다. |
| -outputformat JavaClassName | 선택 과목 | 제공하는 클래스는 Text 클래스의 키 / 값 쌍을 가져야합니다. 지정하지 않으면 TextOutputformat이 기본값으로 사용됩니다. |
| -partitioner JavaClassName | 선택 과목 | 키를 보낼 리 듀스를 결정하는 클래스입니다. |
| -combiner streamingCommand 또는 JavaClassName | 선택 과목 | 맵 출력을위한 결합기 실행 가능. |
| -cmdenv 이름 = 값 | 선택 과목 | 환경 변수를 스트리밍 명령에 전달합니다. |
| -inputreader | 선택 과목 | 이전 버전과의 호환성 : 레코드 판독기 클래스를 지정합니다 (입력 형식 클래스 대신). |
| -말 수가 많은 | 선택 과목 | 자세한 출력. |
| -lazyOutput | 선택 과목 | 느리게 출력을 생성합니다. 예를 들어, 출력 형식이 FileOutputFormat을 기반으로하는 경우 출력 파일은 output.collect (또는 Context.write)에 대한 첫 번째 호출에서만 생성됩니다. |
| -numReduceTasks | 선택 과목 | 감속기의 수를 지정합니다. |
| -mapdebug | 선택 과목 | 지도 작업이 실패 할 때 호출 할 스크립트입니다. |
| -debug 감소 | 선택 과목 | 축소 작업이 실패 할 때 호출 할 스크립트입니다. |
이 장에서는 분산 환경에서 Hadoop 다중 노드 클러스터 설정에 대해 설명합니다.
전체 클러스터를 시연 할 수 없으므로 3 개의 시스템 (마스터 1 개, 슬레이브 2 개)을 사용하는 Hadoop 클러스터 환경을 설명합니다. 아래에 IP 주소가 있습니다.
- Hadoop 마스터 : 192.168.1.15 (hadoop-master)
- Hadoop 슬레이브 : 192.168.1.16 (hadoop-slave-1)
- Hadoop 슬레이브 : 192.168.1.17 (hadoop-slave-2)
Hadoop 다중 노드 클러스터를 설정하려면 아래 단계를 따르십시오.
자바 설치
Java는 Hadoop의 주요 전제 조건입니다. 먼저 "java -version"을 사용하여 시스템에 Java가 있는지 확인해야합니다. Java 버전 명령의 구문은 다음과 같습니다.
$ java -version모든 것이 잘 작동하면 다음과 같은 출력이 제공됩니다.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)시스템에 java가 설치되어 있지 않으면 java를 설치하기 위해 주어진 단계를 따르십시오.
1 단계
다음 링크를 방문하여 java (JDK <최신 버전>-X64.tar.gz)를 다운로드하십시오. www.oracle.com
그때 jdk-7u71-linux-x64.tar.gz 시스템에 다운로드됩니다.
2 단계
일반적으로 다운로드 폴더에서 다운로드 한 Java 파일을 찾을 수 있습니다. 그것을 확인하고 추출jdk-7u71-linux-x64.gz 다음 명령을 사용하여 파일.
$ cd Downloads/ $ ls
jdk-7u71-Linux-x64.gz
$ tar zxf jdk-7u71-Linux-x64.gz $ ls
jdk1.7.0_71 jdk-7u71-Linux-x64.gz3 단계
모든 사용자가 Java를 사용할 수 있도록하려면 "/ usr / local /"위치로 이동해야합니다. 루트를 열고 다음 명령을 입력하십시오.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exit4 단계
설정 용 PATH 과 JAVA_HOME 변수에 다음 명령을 추가하십시오. ~/.bashrc 파일.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=PATH:$JAVA_HOME/bin이제 확인 java -version위에서 설명한대로 터미널에서 명령. 위의 프로세스에 따라 모든 클러스터 노드에 Java를 설치하십시오.
사용자 계정 생성
Hadoop 설치를 사용하려면 마스터 및 슬레이브 시스템 모두에서 시스템 사용자 계정을 만듭니다.
# useradd hadoop
# passwd hadoop노드 매핑
편집해야합니다 hosts 파일 /etc/ 모든 노드의 폴더에서 각 시스템의 IP 주소와 호스트 이름을 지정합니다.
# vi /etc/hosts
enter the following lines in the /etc/hosts file.
192.168.1.109 hadoop-master
192.168.1.145 hadoop-slave-1
192.168.56.1 hadoop-slave-2키 기반 로그인 구성
암호를 묻는 메시지없이 서로 통신 할 수 있도록 모든 노드에서 ssh를 설정합니다.
# su hadoop
$ ssh-keygen -t rsa $ ssh-copy-id -i ~/.ssh/id_rsa.pub tutorialspoint@hadoop-master
$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp1@hadoop-slave-1 $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp2@hadoop-slave-2
$ chmod 0600 ~/.ssh/authorized_keys $ exitHadoop 설치
마스터 서버에서 다음 명령을 사용하여 Hadoop을 다운로드하고 설치합니다.
# mkdir /opt/hadoop
# cd /opt/hadoop/
# wget http://apache.mesi.com.ar/hadoop/common/hadoop-1.2.1/hadoop-1.2.0.tar.gz
# tar -xzf hadoop-1.2.0.tar.gz
# mv hadoop-1.2.0 hadoop
# chown -R hadoop /opt/hadoop
# cd /opt/hadoop/hadoop/Hadoop 구성
다음과 같이 변경하여 Hadoop 서버를 구성해야합니다.
core-site.xml
열기 core-site.xml 파일을 편집하고 아래와 같이 편집합니다.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:9000/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>hdfs-site.xml
열기 hdfs-site.xml 파일을 편집하고 아래와 같이 편집합니다.
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hadoop/dfs/name/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>mapred-site.xml
열기 mapred-site.xml 파일을 편집하고 아래와 같이 편집합니다.
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master:9001</value>
</property>
</configuration>hadoop-env.sh
열기 hadoop-env.sh JAVA_HOME, HADOOP_CONF_DIR, HADOOP_OPTS를 아래와 같이 파일로 수정합니다.
Note − 시스템 구성에 따라 JAVA_HOME을 설정합니다.
export JAVA_HOME=/opt/jdk1.7.0_17
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
export HADOOP_CONF_DIR=/opt/hadoop/hadoop/conf슬레이브 서버에 Hadoop 설치
주어진 명령에 따라 모든 슬레이브 서버에 Hadoop을 설치합니다.
# su hadoop
$ cd /opt/hadoop $ scp -r hadoop hadoop-slave-1:/opt/hadoop
$ scp -r hadoop hadoop-slave-2:/opt/hadoop마스터 서버에서 Hadoop 구성
마스터 서버를 열고 주어진 명령에 따라 구성하십시오.
# su hadoop
$ cd /opt/hadoop/hadoop마스터 노드 구성
$ vi etc/hadoop/masters
hadoop-master슬레이브 노드 구성
$ vi etc/hadoop/slaves
hadoop-slave-1
hadoop-slave-2Hadoop 마스터의 형식 이름 노드
# su hadoop
$ cd /opt/hadoop/hadoop $ bin/hadoop namenode –format
11/10/14 10:58:07 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop-master/192.168.1.109
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.2.0
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1479473;
compiled by 'hortonfo' on Mon May 6 06:59:37 UTC 2013
STARTUP_MSG: java = 1.7.0_71
************************************************************/
11/10/14 10:58:08 INFO util.GSet: Computing capacity for map BlocksMap
editlog=/opt/hadoop/hadoop/dfs/name/current/edits
………………………………………………….
………………………………………………….
………………………………………………….
11/10/14 10:58:08 INFO common.Storage: Storage directory
/opt/hadoop/hadoop/dfs/name has been successfully formatted.
11/10/14 10:58:08 INFO namenode.NameNode:
SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop-master/192.168.1.15
************************************************************/Hadoop 서비스 시작
다음 명령은 Hadoop-Master에서 모든 Hadoop 서비스를 시작하는 것입니다.
$ cd $HADOOP_HOME/sbin
$ start-all.shHadoop 클러스터에 새 데이터 노드 추가
다음은 Hadoop 클러스터에 새 노드를 추가하기 위해 따라야 할 단계입니다.
네트워킹
적절한 네트워크 구성을 사용하여 기존 Hadoop 클러스터에 새 노드를 추가합니다. 다음 네트워크 구성을 가정하십시오.
새 노드 구성의 경우-
IP address : 192.168.1.103
netmask : 255.255.255.0
hostname : slave3.in사용자 및 SSH 액세스 추가
사용자 추가
새 노드에서 "hadoop"사용자를 추가하고 다음 명령을 사용하여 Hadoop 사용자의 비밀번호를 "hadoop123"또는 원하는 것으로 설정하십시오.
useradd hadoop
passwd hadoop마스터에서 새 슬레이브로 암호없이 연결을 설정합니다.
마스터에서 다음을 실행하십시오.
mkdir -p $HOME/.ssh
chmod 700 $HOME/.ssh ssh-keygen -t rsa -P '' -f $HOME/.ssh/id_rsa
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
chmod 644 $HOME/.ssh/authorized_keys Copy the public key to new slave node in hadoop user $HOME directory
scp $HOME/.ssh/id_rsa.pub [email protected]:/home/hadoop/슬레이브에서 다음을 실행하십시오.
hadoop에 로그인하십시오. 그렇지 않은 경우 hadoop 사용자로 로그인하십시오.
su hadoop ssh -X [email protected]공개 키의 내용을 파일로 복사 "$HOME/.ssh/authorized_keys" 그런 다음 다음 명령을 실행하여 동일한 권한을 변경하십시오.
cd $HOME mkdir -p $HOME/.ssh
chmod 700 $HOME/.ssh cat id_rsa.pub >>$HOME/.ssh/authorized_keys
chmod 644 $HOME/.ssh/authorized_keys마스터 시스템에서 ssh 로그인을 확인하십시오. 이제 마스터의 비밀번호없이 새 노드로 ssh 할 수 있는지 확인하십시오.
ssh [email protected] or hadoop@slave3새 노드의 호스트 이름 설정
파일에 호스트 이름을 설정할 수 있습니다. /etc/sysconfig/network
On new slave3 machine
NETWORKING = yes
HOSTNAME = slave3.in변경 사항을 적용하려면 시스템을 다시 시작하거나 해당 호스트 이름을 사용하여 새 시스템에 대해 hostname 명령을 실행하십시오 (다시 시작하는 것이 좋은 옵션입니다).
slave3 노드 머신에서-
호스트 이름 slave3.in
최신 정보 /etc/hosts 다음 줄이있는 클러스터의 모든 컴퓨터에서-
192.168.1.102 slave3.in slave3이제 호스트 이름으로 시스템을 ping하여 IP로 확인되는지 여부를 확인하십시오.
새로운 노드 머신에서-
ping master.in새 노드에서 DataNode 시작
다음을 사용하여 데이터 노드 데몬을 수동으로 시작합니다. $HADOOP_HOME/bin/hadoop-daemon.sh script. 자동으로 마스터 (NameNode)에 연결하고 클러스터에 참여합니다. 또한 마스터 서버의 conf / slaves 파일에 새 노드를 추가해야합니다. 스크립트 기반 명령은 새 노드를 인식합니다.
새 노드에 로그인
su hadoop or ssh -X [email protected]다음 명령을 사용하여 새로 추가 된 슬레이브 노드에서 HDFS를 시작합니다.
./bin/hadoop-daemon.sh start datanode새 노드에서 jps 명령의 출력을 확인하십시오. 다음과 같이 보입니다.
$ jps
7141 DataNode
10312 JpsHadoop 클러스터에서 데이터 노드 제거
클러스터가 실행되는 동안 데이터 손실없이 즉시 클러스터에서 노드를 제거 할 수 있습니다. HDFS는 노드 제거가 안전하게 수행되도록하는 해제 기능을 제공합니다. 그것을 사용하려면 아래 주어진 단계를 따르십시오-
1 단계-마스터에 로그인
Hadoop이 설치된 마스터 컴퓨터 사용자로 로그인합니다.
$ su hadoop2 단계-클러스터 구성 변경
클러스터를 시작하기 전에 제외 파일을 구성해야합니다. dfs.hosts.exclude라는 키를$HADOOP_HOME/etc/hadoop/hdfs-site.xml파일. 이 키와 관련된 값은 HDFS에 연결할 수없는 시스템 목록을 포함하는 NameNode의 로컬 파일 시스템에있는 파일의 전체 경로를 제공합니다.
예를 들어, 다음 줄을 etc/hadoop/hdfs-site.xml 파일.
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt</value>
<description>DFS exclude</description>
</property>3 단계-서비스 해제 할 호스트 결정
해제 할 각 시스템은 hdfs_exclude.txt로 식별되는 파일에 한 줄에 하나씩 도메인 이름을 추가해야합니다. 이것은 그들이 NameNode에 연결하는 것을 방지합니다. 내용"/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt" DataNode2를 제거하려면 파일이 아래에 나와 있습니다.
slave2.in4 단계-강제 구성 다시로드
명령 실행 "$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes" 따옴표없이.
$ $HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes이렇게하면 NameNode가 새로 업데이트 된 '제외'파일을 포함하여 구성을 다시 읽게됩니다. 일정 기간 동안 노드를 폐기하여 각 노드의 블록이 활성 상태로 유지되도록 예약 된 시스템에 복제 될 시간을 허용합니다.
의 위에 slave2.in, jps 명령 출력을 확인하십시오. 잠시 후 DataNode 프로세스가 자동으로 종료되는 것을 볼 수 있습니다.
5 단계-노드 종료
폐기 프로세스가 완료된 후 유지 보수를 위해 폐기 된 하드웨어를 안전하게 종료 할 수 있습니다. dfsadmin에보고 명령을 실행하여 해제 상태를 확인합니다. 다음 명령은 해제 노드 및 클러스터에 연결된 노드의 상태를 설명합니다.
$ $HADOOP_HOME/bin/hadoop dfsadmin -report6 단계-편집은 파일을 다시 제외합니다.
머신이 해제되면 '제외'파일에서 제거 할 수 있습니다. 달리는"$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes"다시 제외 파일을 다시 NameNode로 읽습니다. 유지 보수가 완료된 후 DataNode가 클러스터에 다시 참여하도록 허용하거나 클러스터에 추가 용량이 다시 필요합니다.
Special Note− 위의 프로세스를 따르고 tasktracker 프로세스가 노드에서 여전히 실행 중이면 종료해야합니다. 한 가지 방법은 위의 단계에서했던 것처럼 시스템을 분리하는 것입니다. 마스터는 프로세스를 자동으로 인식하고 죽은 것으로 선언합니다. 작업 추적기를 제거하기 위해 동일한 프로세스를 따를 필요가 없습니다. DataNode에 비해 그다지 중요하지 않기 때문입니다. DataNode에는 데이터 손실없이 안전하게 제거하려는 데이터가 포함되어 있습니다.
tasktracker는 언제든지 다음 명령으로 즉시 실행 / 종료 할 수 있습니다.
$ $HADOOP_HOME/bin/hadoop-daemon.sh stop tasktracker $HADOOP_HOME/bin/hadoop-daemon.sh start tasktracker