IMS DB-데이터 검색
IMS DL / I 호출에 사용되는 다양한 데이터 검색 방법은 다음과 같습니다.
- GU 호출
- GN 호출
- 명령 코드 사용
- 다중 처리
데이터 검색 함수 호출을 이해하기 위해 다음 IMS 데이터베이스 구조를 고려해 보겠습니다.
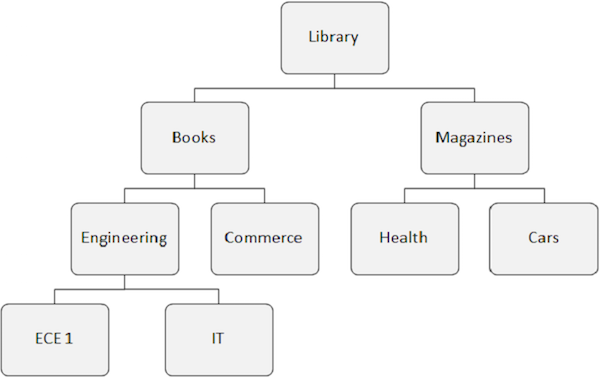
GU 호출
GU 호출의 기본 사항은 다음과 같습니다.
GU 호출은 Get Unique 호출로 알려져 있습니다. 랜덤 처리에 사용됩니다.
응용 프로그램이 데이터베이스를 정기적으로 업데이트하지 않거나 데이터베이스 업데이트 수가 적 으면 무작위 처리를 사용합니다.
GU 호출은 추가 순차 검색을 위해 포인터를 특정 위치에 배치하는 데 사용됩니다.
GU 호출은 이전 호출에 의해 설정된 포인터 위치와 무관합니다.
GU 호출 처리는 call 문에 제공된 고유 키 필드를 기반으로합니다.
고유하지 않은 키 필드를 제공하면 DL / I는 키 필드의 첫 번째 세그먼트 발생을 반환합니다.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA위의 예는 완전한 SSA 세트를 제공하여 GU 호출을 발행하는 것을 보여줍니다. 여기에는 루트 수준에서 시작하여 검색하려는 세그먼트 발생까지의 모든 키 필드가 포함됩니다.
GU 호출 고려 사항
통화에서 적격 SSA 전체 세트를 제공하지 않으면 DL / I는 다음과 같은 방식으로 작동합니다.
GU 호출에서 정규화되지 않은 SSA를 사용하면 DL / I는 지정한 기준을 충족하는 데이터베이스의 첫 번째 세그먼트 발생에 액세스합니다.
SSA없이 GU 호출을 발행하면 DL / I는 데이터베이스에서 루트 세그먼트의 첫 번째 발생을 반환합니다.
중간 수준의 일부 SSA가 호출에 언급되지 않은 경우 DL / I는 세그먼트에 대해 설정된 위치 또는 규정되지 않은 SSA의 기본값을 사용합니다.
상태 코드
다음 표는 GU 호출 후 관련 상태 코드를 보여줍니다-
| S. 아니 | 상태 코드 및 설명 |
|---|---|
| 1 | Spaces 성공적인 통화 |
| 2 | GE DL / I는 호출에 지정된 기준을 충족하는 세그먼트를 찾을 수 없습니다. |
GN 호출
GN 호출의 기본은 다음과 같습니다.
GN 호출은 Get Next 호출로 알려져 있습니다. 기본 순차 처리에 사용됩니다.
데이터베이스에서 포인터의 초기 위치는 첫 번째 데이터베이스 레코드의 루트 세그먼트 앞입니다.
데이터베이스 포인터 위치는 성공적인 GN 호출 후 시퀀스에서 다음 세그먼트 발생 이전입니다.
GN 호출은 이전 호출로 설정된 위치에서 데이터베이스를 통해 시작됩니다.
GN 호출이 규정되지 않은 경우 계층 적 순서로 유형에 관계없이 데이터베이스에서 다음 세그먼트 발생을 반환합니다.
GN 호출에 SSA가 포함 된 경우 DL / I는 지정된 모든 SSA의 요구 사항을 충족하는 세그먼트 만 검색합니다.
CALL 'CBLTDLI' USING DLI-GN
PCB-NAME
IO-AREA
BOOKS-SSA위의 예는 레코드를 순차적으로 읽을 수있는 시작 위치를 제공하는 GN 호출을 실행하는 것을 보여줍니다. BOOKS 세그먼트의 첫 번째 발생을 가져옵니다.
상태 코드
다음 표는 GN 호출 후 관련 상태 코드를 보여줍니다-
| S. 아니 | 상태 코드 및 설명 |
|---|---|
| 1 | Spaces 성공적인 통화 |
| 2 | GE DL / I는 호출에 지정된 기준을 충족하는 세그먼트를 찾을 수 없습니다. |
| 삼 | GA 규정되지 않은 GN 호출은 데이터베이스 계층 구조에서 한 수준 위로 이동하여 세그먼트를 가져옵니다. |
| 4 | GB 데이터베이스 끝에 도달했으며 세그먼트를 찾을 수 없습니다. |
GK 정규화되지 않은 GN 호출은 방금 검색된 유형이 아닌 특정 유형의 세그먼트를 가져 오려고하지만 동일한 계층 수준에 유지됩니다. |
명령 코드
명령 코드는 세그먼트 발생을 가져 오는 호출과 함께 사용됩니다. 호출에 사용되는 다양한 명령 코드는 아래에서 설명합니다.
F 명령 코드
주목할 점-
F 명령 코드가 호출에 지정되면 호출은 세그먼트의 첫 번째 발생을 처리합니다.
F 명령 코드는 순차적으로 처리하고자 할 때 사용할 수 있으며 GN 호출 및 GNP 호출과 함께 사용할 수 있습니다.
GU 호출에 F 명령 코드를 지정하면 GU 호출이 기본적으로 첫 번째 세그먼트 발생을 가져 오므로 의미가 없습니다.
L 명령 코드
주목할 점-
L 명령 코드가 호출에 지정되면 호출은 세그먼트의 마지막 발생을 처리합니다.
L 명령 코드는 순차적으로 처리하고자 할 때 사용할 수 있으며 GN 호출 및 GNP 호출과 함께 사용할 수 있습니다.
D 명령 코드
주목할 점-
D 명령 코드는 단일 호출을 사용하여 둘 이상의 세그먼트 발생을 가져 오는 데 사용됩니다.
일반적으로 DL / I는 SSA에 지정된 가장 낮은 수준의 세그먼트에서 작동하지만 대부분의 경우 다른 수준의 데이터도 필요합니다. 이 경우 D 명령 코드를 사용할 수 있습니다.
D 명령 코드를 사용하면 세그먼트의 전체 경로를 쉽게 검색 할 수 있습니다.
C 명령 코드
주목할 점-
C 명령 코드는 키를 연결하는 데 사용됩니다.
관계 연산자를 사용하는 것은 필드 이름, 관계 연산자 및 검색 값을 지정해야하기 때문에 약간 복잡합니다. 대신 C 명령 코드를 사용하여 연결된 키를 제공 할 수 있습니다.
다음 예제는 C 명령 코드의 사용을 보여줍니다-
01 LOCATION-SSA.
05 FILLER PIC X(11) VALUE ‘INLOCSEG*C(‘.
05 LIBRARY-SSA PIC X(5).
05 BOOKS-SSA PIC X(4).
05 ENGINEERING-SSA PIC X(6).
05 IT-SSA PIC X(3)
05 FILLER PIC X VALUE ‘)’.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LOCATION-SSAP 명령 코드
주목할 점-
GU 또는 GN 호출을 발행 할 때 DL / I는 검색된 최하위 레벨 세그먼트에서 상위를 설정합니다.
P 명령 코드를 포함하면 DL / I는 계층 경로의 상위 레벨 세그먼트에서 상위를 설정합니다.
U 명령 코드
주목할 점-
GN 호출의 규정되지 않은 SSA에 U 명령 코드가 지정되면 DL / I는 세그먼트 검색을 제한합니다.
U 명령 코드는 정규화 된 SSA와 함께 사용되는 경우 무시됩니다.
V 명령 코드
주목할 점-
V 명령 코드는 U 명령 코드와 유사하게 작동하지만 특정 수준 및 계층 위의 모든 수준에서 세그먼트 검색을 제한합니다.
V 명령 코드는 정규화 된 SSA와 함께 사용할 때 무시됩니다.
Q 명령 코드
주목할 점-
Q 명령 코드는 애플리케이션 프로그램 전용 세그먼트를 대기열에 추가하거나 예약하는 데 사용됩니다.
Q 명령 코드는 다른 프로그램이 세그먼트를 변경할 수있는 대화식 환경에서 사용됩니다.
다중 처리
프로그램은 다중 처리로 알려진 IMS 데이터베이스에서 여러 위치를 가질 수 있습니다. 다중 처리는 두 가지 방법으로 수행 할 수 있습니다.
- 여러 PCB
- 다중 포지셔닝
여러 PCB
단일 데이터베이스에 대해 여러 PCB를 정의 할 수 있습니다. PCB가 여러 개인 경우 애플리케이션 프로그램이 PCB에 대해 다른보기를 가질 수 있습니다. 다중 처리를 구현하는이 방법은 여분의 PCB로 인한 오버 헤드 때문에 비효율적입니다.
다중 포지셔닝
프로그램은 단일 PCB를 사용하여 데이터베이스에서 여러 위치를 유지할 수 있습니다. 이는 각 계층 적 경로에 대해 고유 한 위치를 유지함으로써 달성됩니다. 다중 위치 지정은 동시에 두 개 이상의 유형의 세그먼트에 순차적으로 액세스하는 데 사용됩니다.