IMS DB-퀵 가이드
간략한 개요
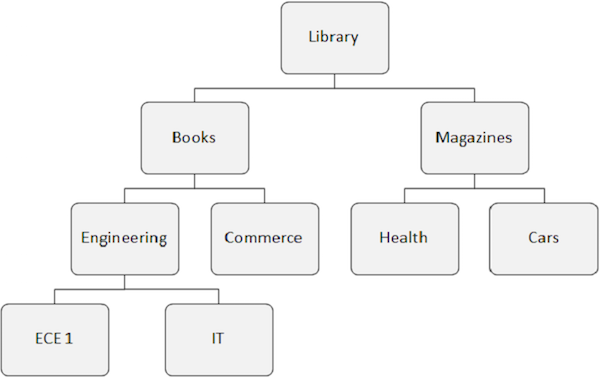
데이터베이스는 상호 관련된 데이터 항목의 모음입니다. 이러한 데이터 항목은 빠르고 쉽게 액세스 할 수 있도록 구성 및 저장됩니다. IMS 데이터베이스는 데이터가 서로 다른 레벨에 저장되고 각 엔티티가 상위 레벨 엔티티에 종속되는 계층 적 데이터베이스입니다. IMS를 사용하는 애플리케이션 시스템의 물리적 요소는 다음 그림에 표시됩니다.
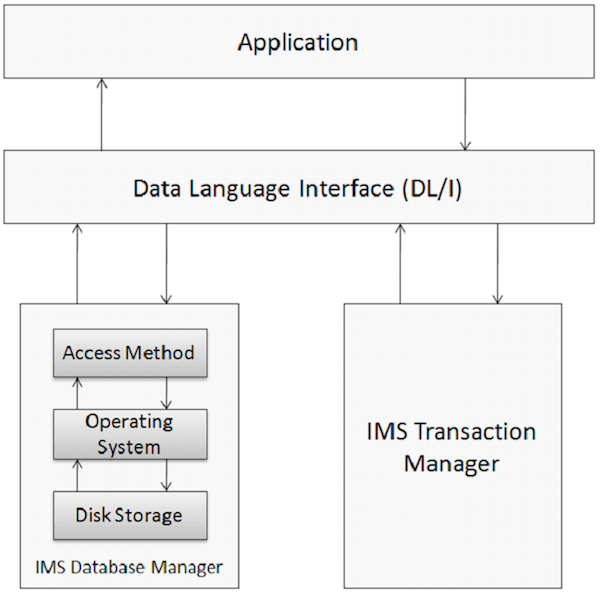
데이터베이스 관리
데이터베이스 관리 시스템은 데이터베이스에서 데이터를 저장, 액세스 및 관리하는 데 사용되는 애플리케이션 프로그램 세트입니다. IMS 데이터베이스 관리 시스템은 무결성을 유지하고 데이터를 쉽게 검색 할 수 있도록 구성하여 데이터를 빠르게 복구 할 수 있습니다. IMS는 데이터베이스 관리 시스템의 도움으로 전 세계의 많은 기업 데이터를 유지합니다.
거래 관리자
트랜잭션 관리자의 기능은 데이터베이스와 응용 프로그램 간의 통신 플랫폼을 제공하는 것입니다. IMS는 트랜잭션 관리자 역할을합니다. 트랜잭션 관리자는 최종 사용자를 처리하여 데이터베이스에서 데이터를 저장하고 검색합니다. IMS는 IMS DB 또는 DB2를 백엔드 데이터베이스로 사용하여 데이터를 저장할 수 있습니다.
DL / I – 데이터 언어 인터페이스
DL / I는 데이터베이스에 저장된 데이터에 대한 액세스 권한을 부여하는 응용 프로그램으로 구성됩니다. IMS DB는 프로그래머가 응용 프로그램에서 데이터베이스에 액세스하는 데 사용하는 인터페이스 언어 역할을하는 DL / I를 사용합니다. 이에 대해서는 다음 장에서 자세히 설명합니다.
IMS의 특징
주목할 점-
- IMS는 Java 및 XML과 같은 다양한 언어의 애플리케이션을 지원합니다.
- IMS 애플리케이션 및 데이터는 모든 플랫폼에서 액세스 할 수 있습니다.
- IMS DB 처리는 DB2에 비해 매우 빠릅니다.
IMS의 한계
주목할 점-
- IMS DB의 구현은 매우 복잡합니다.
- IMS 사전 정의 트리 구조는 유연성을 감소시킵니다.
- IMS DB는 관리가 어렵습니다.
계층 구조
IMS 데이터베이스는 실제 파일을 수용하는 데이터 모음입니다. 계층 적 데이터베이스에서 최상위 수준에는 엔터티에 대한 일반 정보가 포함됩니다. 계층 구조의 최상위 수준에서 최하위 수준으로 진행함에 따라 엔티티에 대한 더 많은 정보를 얻습니다.
계층 구조의 각 수준에는 세그먼트가 포함됩니다. 표준 파일에서는 계층을 구현하기 어렵지만 DL / I는 계층을 지원합니다. 다음 그림은 IMS DB의 구조를 보여줍니다.
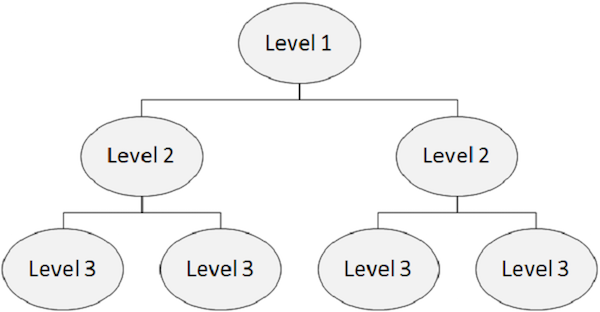
분절
주목할 점-
유사한 데이터를 함께 그룹화하여 세그먼트를 만듭니다.
입출력 조작 중에 DL / I가 애플리케이션 프로그램과주고받는 정보의 최소 단위입니다.
세그먼트는 함께 그룹화 된 하나 이상의 데이터 필드를 가질 수 있습니다.
다음 예에서 세그먼트 Student에는 4 개의 데이터 필드가 있습니다.
| 학생 | |||
|---|---|---|---|
| 롤 번호 | 이름 | 강좌 | 모바일 숫자 |
들
주목할 점 −
필드는 세그먼트에있는 단일 데이터 조각입니다. 예를 들어, 롤 번호, 이름, 과정 및 휴대폰 번호는 학생 세그먼트의 단일 필드입니다.
세그먼트는 엔터티의 정보를 수집하기위한 관련 필드로 구성됩니다.
필드는 세그먼트 주문을위한 키로 사용할 수 있습니다.
필드는 특정 세그먼트에 대한 정보를 검색하기위한 한정자로 사용할 수 있습니다.
세그먼트 유형
주목할 점-
세그먼트 유형은 세그먼트에있는 데이터의 범주입니다.
DL / I 데이터베이스는 255 개의 서로 다른 세그먼트 유형과 15 개의 계층 구조 수준을 가질 수 있습니다.
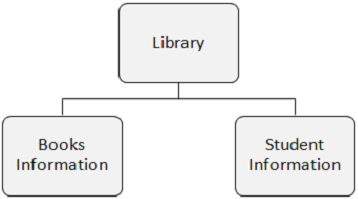
다음 그림에는 도서관, 도서 정보 및 학생 정보의 세 가지 세그먼트가 있습니다.
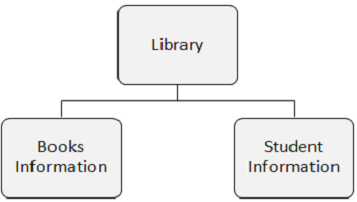
세그먼트 발생
주목할 점-
세그먼트 발생은 사용자 데이터를 포함하는 특정 유형의 개별 세그먼트입니다. 위의 예에서 Books Information은 하나의 세그먼트 유형이며 여러 도서에 대한 정보를 저장할 수 있으므로 여러 항목이 발생할 수 있습니다.
IMS 데이터베이스에는 각 세그먼트 유형의 발생이 하나만 있지만 각 세그먼트 유형의 발생 횟수는 제한되지 않습니다.
계층 적 데이터베이스는 둘 이상의 세그먼트 간의 관계에서 작동합니다. 다음 예는 IMS 데이터베이스 구조에서 세그먼트가 서로 관련되는 방식을 보여줍니다.
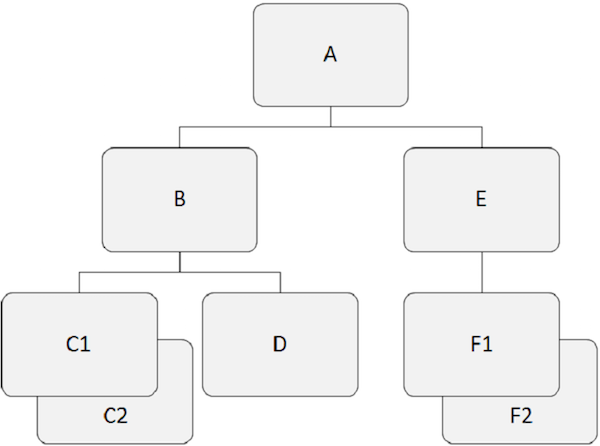
루트 세그먼트
주목할 점-
계층 구조의 맨 위에있는 세그먼트를 루트 세그먼트라고합니다.
루트 세그먼트는 모든 종속 세그먼트에 액세스하는 유일한 세그먼트입니다.
루트 세그먼트는 데이터베이스에서 하위 세그먼트가 아닌 유일한 세그먼트입니다.
IMS 데이터베이스 구조에는 루트 세그먼트가 하나만있을 수 있습니다.
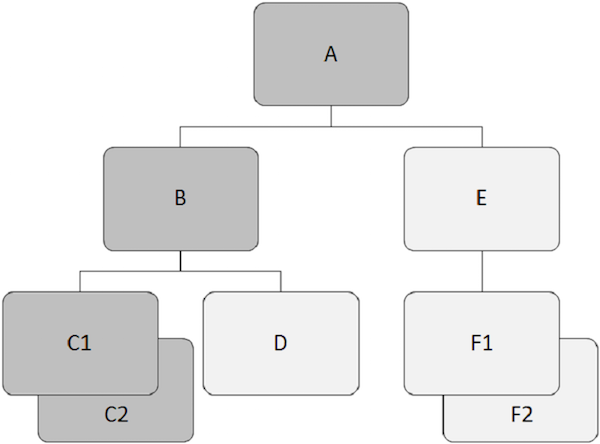
예를 들면 'A' 위의 예에서 루트 세그먼트입니다.
상위 세그먼트
주목할 점-
상위 세그먼트에는 바로 아래에 하나 이상의 종속 세그먼트가 있습니다.
예를 들면 'A', 'B', 및 'E' 위의 예에서 상위 세그먼트입니다.
종속 세그먼트
주목할 점-
루트 세그먼트를 제외한 모든 세그먼트를 종속 세그먼트라고합니다.
종속 세그먼트는 하나 이상의 세그먼트에 의존하여 완전한 의미를 나타냅니다.
예를 들면 'B', 'C1', 'C2', 'D', 'E', 'F1' 과 'F2' 이 예에서는 종속 세그먼트입니다.
하위 세그먼트
주목할 점-
계층 구조에서 바로 위에 세그먼트가있는 모든 세그먼트를 하위 세그먼트라고합니다.
구조의 각 종속 세그먼트는 하위 세그먼트입니다.
예를 들면 'B', 'C1', 'C2', 'D', 'E', 'F1' 과 'F2' 하위 세그먼트입니다.
트윈 세그먼트
주목할 점-
단일 상위 세그먼트 아래에서 특정 세그먼트 유형의 두 개 이상의 세그먼트 발생을 트윈 세그먼트라고합니다.
예를 들면 'C1' 과 'C2' 트윈 세그먼트이므로 'F1' 과 'F2' 아르.
형제 세그먼트
주목할 점-
형제 세그먼트는 다른 유형과 동일한 상위의 세그먼트입니다.
예를 들면 'B' 과 'E' 형제 세그먼트입니다. 비슷하게,'C1', 'C2', 과 'D' 형제 세그먼트입니다.
데이터베이스 기록
주목할 점-
루트 세그먼트의 각 발생과 모든 종속 세그먼트 발생은 하나의 데이터베이스 레코드를 만듭니다.
모든 데이터베이스 레코드에는 루트 세그먼트가 하나만 있지만 세그먼트 발생 횟수에는 제한이 없습니다.
표준 파일 처리에서 레코드는 애플리케이션 프로그램이 특정 작업에 사용하는 데이터 단위입니다. DL / I에서는 해당 데이터 단위를 세그먼트라고합니다. 단일 데이터베이스 레코드에는 많은 세그먼트 발생이 있습니다.
데이터베이스 경로
주목할 점-
경로는 데이터베이스 레코드의 루트 세그먼트에서 특정 세그먼트 발생까지 시작하는 일련의 세그먼트입니다.
계층 구조의 경로는 최하위 수준까지 완전하지 않아도됩니다. 엔티티에 대해 얼마나 많은 정보가 필요한지에 따라 다릅니다.
경로는 연속적이어야하며 구조의 중간 수준을 건너 뛸 수 없습니다.
다음 그림에서 짙은 회색의 하위 레코드는 다음에서 시작하는 경로를 보여줍니다. 'A' 그리고 통과 'C2'.
IMS DB는 다양한 수준의 데이터를 저장합니다. 데이터는 애플리케이션 프로그램에서 DL / I 호출을 발행하여 검색 및 삽입됩니다. 다음 장에서 DL / I 통화에 대해 자세히 설명합니다. 데이터는 다음 두 가지 방법으로 처리 할 수 있습니다.
- 순차 처리
- 무작위 처리
순차 처리
세그먼트가 데이터베이스에서 순차적으로 검색 될 때 DL / I는 사전 정의 된 패턴을 따릅니다. IMS DB의 순차적 처리에 대해 알아 보겠습니다.
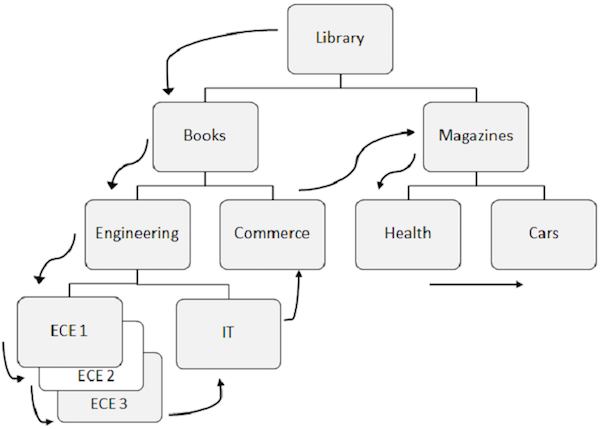
다음은 순차 처리에 대한주의 사항입니다.
DL / I의 데이터에 액세스하기 위해 미리 정의 된 패턴은 먼저 계층 구조 아래에서 왼쪽에서 오른쪽으로입니다.
루트 세그먼트가 먼저 검색된 다음 DL / I가 첫 번째 왼쪽 자식으로 이동하고 가장 낮은 수준까지 내려갑니다. 최하위 수준에서 트윈 세그먼트의 모든 발생을 검색합니다. 그런 다음 올바른 세그먼트로 이동합니다.
더 잘 이해하려면 세그먼트에 액세스하기위한 흐름을 보여주는 위 그림의 화살표를 관찰하십시오. 라이브러리는 루트 세그먼트이며 흐름은 거기에서 시작하여 단일 레코드에 액세스하기 위해 자동차까지 이동합니다. 모든 데이터 레코드를 가져 오기 위해 모든 발생에 대해 동일한 프로세스가 반복됩니다.
데이터에 액세스하는 동안 프로그램은 position 세그먼트를 검색하고 삽입하는 데 도움이되는 데이터베이스에서.
무작위 처리
랜덤 처리는 IMS DB의 데이터 직접 처리라고도합니다. IMS DB의 임의 처리를 이해하는 예를 들어 보겠습니다.
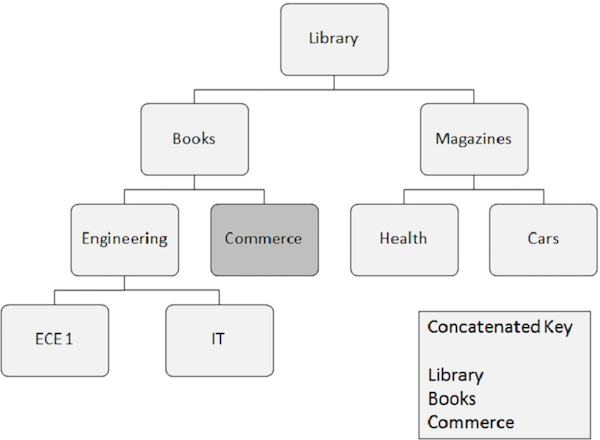
다음은 무작위 처리에 대해주의해야 할 사항입니다.
무작위로 검색해야하는 세그먼트 발생에는 종속 된 모든 세그먼트의 키 필드가 필요합니다. 이러한 키 필드는 응용 프로그램에서 제공합니다.
연결된 키는 루트 세그먼트에서 검색하려는 세그먼트까지의 경로를 완전히 식별합니다.
Commerce 세그먼트의 발생을 검색하려는 경우 Library, Books 및 Commerce와 같이 종속 된 세그먼트의 연결된 키 필드 값을 제공해야합니다.
무작위 처리는 순차 처리보다 빠릅니다. 실제 시나리오에서 응용 프로그램은 순차 및 무작위 처리 방법을 함께 결합하여 최상의 결과를 얻습니다.
키 필드
주목할 점-
키 필드는 시퀀스 필드라고도합니다.
키 필드는 세그먼트 내에 존재하며 세그먼트 발생을 검색하는 데 사용됩니다.
키 필드는 오름차순으로 세그먼트 발생을 관리합니다.
각 세그먼트에서 단일 필드 만 키 필드 또는 시퀀스 필드로 사용할 수 있습니다.
검색 필드
언급했듯이 단일 필드 만 키 필드로 사용할 수 있습니다. 키 필드가 아닌 다른 세그먼트 필드의 내용을 검색하려는 경우 데이터를 검색하는 데 사용되는 필드를 검색 필드라고합니다.
IMS 제어 블록은 IMS 데이터베이스의 구조와 이에 대한 프로그램의 액세스를 정의합니다. 다음 다이어그램은 IMS 제어 블록의 구조를 보여줍니다.
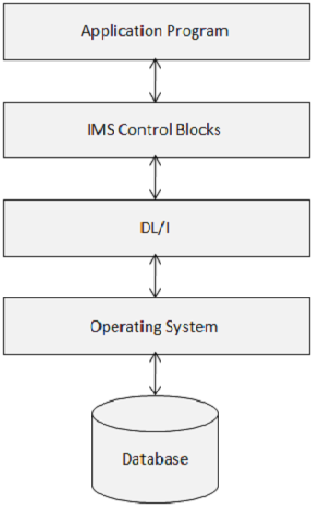
DL / I는 다음 세 가지 유형의 제어 블록을 사용합니다.
- 데이터베이스 설명자 (DBD)
- 프로그램 사양 블록 (PSB)
- 액세스 제어 블록 (ACB)
데이터베이스 설명자 (DBD)
주목할 점-
DBD는 모든 세그먼트가 정의되면 데이터베이스의 전체 물리적 구조를 설명합니다.
DL / I 데이터베이스를 설치하는 동안 IMS 데이터베이스에 액세스하는 데 필요한 하나의 DBD를 작성해야합니다.
응용 프로그램은 DBD의 다른보기를 사용할 수 있습니다. 이를 애플리케이션 데이터 구조라고하며 프로그램 사양 블록에 지정되어 있습니다.
데이터베이스 관리자는 코딩을 통해 DBD를 생성합니다. DBDGEN 제어문.
DBDGEN
DBDGEN은 데이터베이스 설명자 생성기입니다. 제어 블록을 만드는 것은 데이터베이스 관리자의 책임입니다. 모든로드 모듈은 IMS 라이브러리에 저장됩니다. 어셈블리 언어 매크로 문은 제어 블록을 만드는 데 사용됩니다. 다음은 DBDGEN 제어문을 사용하여 DBD를 생성하는 방법을 보여주는 샘플 코드입니다.
PRINT NOGEN
DBD NAME=LIBRARY,ACCESS=HIDAM
DATASET DD1=LIB,DEVICE=3380
SEGM NAME=LIBSEG,PARENT=0,BYTES=10
FIELD NAME=(LIBRARY,SEQ,U),BYTES=10,START=1,TYPE=C
SEGM NAME=BOOKSEG,PARENT=LIBSEG,BYTES=5
FIELD NAME=(BOOKS,SEQ,U),BYTES=10,START=1,TYPE=C
SEGM NAME=MAGSEG,PARENT=LIBSEG,BYTES=9
FIELD NAME=(MAGZINES,SEQ),BYTES=8,START=1,TYPE=C
DBDGEN
FINISH
END위의 DBDGEN에서 사용 된 용어를 이해합시다-
위의 제어문을 실행할 때 JCL, LIBRARY가 루트 세그먼트이고 BOOKS 및 MAGZINES가 하위 세그먼트 인 물리적 구조를 생성합니다.
첫 번째 DBD 매크로 문은 데이터베이스를 식별합니다. 여기에서이 데이터베이스에 액세스하기 위해 DL / I가 사용하는 NAME 및 ACCESS를 언급해야합니다.
두 번째 DATASET 매크로 문은 데이터베이스가 포함 된 파일을 식별합니다.
세그먼트 유형은 SEGM 매크로 문을 사용하여 정의됩니다. 해당 세그먼트의 PARENT를 지정해야합니다. 루트 세그먼트 인 경우 PARENT = 0을 언급합니다.
다음 표는 FIELD 매크로 문에서 사용되는 매개 변수를 보여줍니다-
| S. 아니 | 매개 변수 및 설명 |
|---|---|
| 1 | Name 필드 이름 (일반적으로 1-8 자 길이) |
| 2 | Bytes 필드의 길이 |
| 삼 | Start 세그먼트 내 필드 위치 |
| 4 | Type 필드의 데이터 유형 |
| 5 | Type C 문자 데이터 유형 |
| 6 | Type P 팩형 10 진수 데이터 유형 |
| 7 | Type Z 존 십진수 데이터 유형 |
| 8 | Type X 16 진수 데이터 유형 |
| 9 | Type H 하프 워드 바이너리 데이터 유형 |
| 10 | Type F 전체 단어 바이너리 데이터 유형 |
프로그램 사양 블록 (PSB)
PSB의 기본 사항은 다음과 같습니다.
데이터베이스는 DBD에 의해 정의 된 단일 물리적 구조를 갖지만이를 처리하는 응용 프로그램은 데이터베이스의 다른보기를 가질 수 있습니다. 이러한보기를 애플리케이션 데이터 구조라고하며 PSB에 정의됩니다.
어떤 프로그램도 단일 실행에서 둘 이상의 PSB를 사용할 수 없습니다.
응용 프로그램에는 자체 PSB가 있으며 유사한 데이터베이스 처리 요구 사항을 가진 응용 프로그램이 PSB를 공유하는 것이 일반적입니다.
PSB는 프로그램 통신 블록 (PCB)이라고하는 하나 이상의 제어 블록으로 구성됩니다. PSB에는 애플리케이션 프로그램이 액세스 할 각 DL / I 데이터베이스에 대해 하나의 PCB가 포함됩니다. 다음 모듈에서 PCB에 대해 더 자세히 논의 할 것입니다.
프로그램에 대한 PSB를 생성하려면 PSBGEN을 수행해야합니다.
PSBGEN
PSBGEN은 프로그램 사양 블록 생성기로 알려져 있습니다. 다음 예제는 PSBGEN을 사용하여 PSB를 생성합니다-
PRINT NOGEN
PCB TYPE=DB,DBDNAME=LIBRARY,KEYLEN=10,PROCOPT=LS
SENSEG NAME=LIBSEG
SENSEG NAME=BOOKSEG,PARENT=LIBSEG
SENSEG NAME=MAGSEG,PARENT=LIBSEG
PSBGEN PSBNAME=LIBPSB,LANG=COBOL
END위의 DBDGEN에서 사용 된 용어를 이해합시다-
첫 번째 매크로 문은 데이터베이스 유형, 이름, 키 길이 및 처리 옵션을 설명하는 프로그램 통신 블록 (PCB)입니다.
PCB 매크로의 DBDNAME 매개 변수는 DBD의 이름을 지정합니다. KEYLEN은 가장 긴 연결된 키의 길이를 지정합니다. 프로그램은 데이터베이스에서 처리 할 수 있습니다. PROCOPT 매개 변수는 프로그램의 처리 옵션을 지정합니다. 예를 들어 LS는 LOAD 연산 만 의미합니다.
SENSEG는 세그먼트 레벨 감도로 알려져 있습니다. 데이터베이스의 일부에 대한 프로그램의 액세스를 정의하며 세그먼트 수준에서 식별됩니다. 프로그램은 민감한 세그먼트 내의 모든 필드에 액세스 할 수 있습니다. 프로그램은 또한 필드 수준 감도를 가질 수 있습니다. 여기에서 세그먼트 이름과 세그먼트의 상위 이름을 정의합니다.
마지막 매크로 문은 PCBGEN입니다. PSBGEN은 처리 할 문이 더 이상 없음을 알리는 마지막 문입니다. PSBNAME은 출력 PSB 모듈에 주어진 이름을 정의합니다. LANG 매개 변수는 애플리케이션 프로그램이 작성되는 언어 (예 : COBOL)를 지정합니다.
액세스 제어 블록 (ACB)
다음은 액세스 제어 블록에 대한주의 사항입니다.
응용 프로그램에 대한 액세스 제어 블록은 데이터베이스 설명자와 프로그램 사양 블록을 실행 가능한 형태로 결합합니다.
ACBGEN은 액세스 제어 블록 생성기로 알려져 있습니다. ACB를 생성하는 데 사용됩니다.
온라인 프로그램의 경우 ACB를 사전 구축해야합니다. 따라서 ACBGEN 유틸리티는 응용 프로그램을 실행하기 전에 실행됩니다.
배치 프로그램의 경우 실행 시간에도 ACB를 생성 할 수 있습니다.
DL / I 호출을 포함하는 응용 프로그램은 직접 실행할 수 없습니다. 대신 IMS DL / I 배치 모듈을 트리거하려면 JCL이 필요합니다. IMS의 배치 초기화 모듈은 DFSRRC00입니다. 응용 프로그램과 DL / I 모듈이 함께 실행됩니다. 다음 다이어그램은 데이터베이스에 액세스하기위한 DL / I 호출을 포함하는 애플리케이션 프로그램의 구조를 보여줍니다.
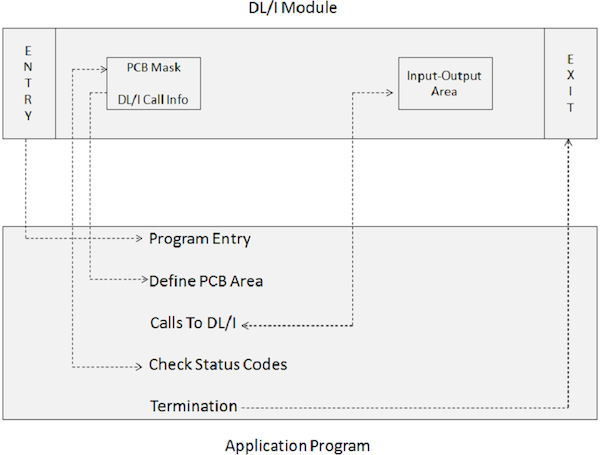
응용 프로그램은 다음 프로그램 요소를 통해 IMS DL / I 모듈과 인터페이스합니다.
ENTRY 문은 프로그램에서 PCB를 사용하도록 지정합니다.
PCB 마스크는 IMS에서 반환 정보를 수신하는 미리 구성된 PCB에 보존 된 정보와 관련이 있습니다.
입력-출력 영역은 IMS 데이터베이스로 (부터) 데이터 세그먼트를 전달하는 데 사용됩니다.
DL / I에 대한 호출은 가져 오기, 삽입, 삭제, 바꾸기 등과 같은 처리 기능을 지정합니다.
상태 코드 확인은 작업의 성공 여부를 알리기 위해 지정된 처리 옵션의 SQL 리턴 코드를 확인하는 데 사용됩니다.
Terminate 문은 DL / I를 포함하는 응용 프로그램의 처리를 종료하는 데 사용됩니다.
세그먼트 레이아웃
지금까지 우리는 IMS가 데이터에 액세스하기 위해 고급 프로그래밍 언어에서 사용되는 세그먼트로 구성되어 있음을 배웠습니다. 이전에 본 라이브러리의 다음 IMS 데이터베이스 구조를 고려하면 여기에서 COBOL의 세그먼트 레이아웃을 볼 수 있습니다.
01 LIBRARY-SEGMENT.
05 BOOK-ID PIC X(5).
05 ISSUE-DATE PIC X(10).
05 RETURN-DATE PIC X(10).
05 STUDENT-ID PIC A(25).
01 BOOK-SEGMENT.
05 BOOK-ID PIC X(5).
05 BOOK-NAME PIC A(30).
05 AUTHOR PIC A(25).
01 STUDENT-SEGMENT.
05 STUDENT-ID PIC X(5).
05 STUDENT-NAME PIC A(25).
05 DIVISION PIC X(10).응용 프로그램 개요
IMS 응용 프로그램의 구조는 비 IMS 응용 프로그램의 구조와 다릅니다. IMS 프로그램은 직접 실행할 수 없습니다. 오히려 항상 서브 루틴으로 호출됩니다. IMS 응용 프로그램은 IMS 데이터베이스보기를 제공하는 프로그램 사양 블록으로 구성됩니다.
IMS DL / I 모듈이 포함 된 응용 프로그램을 실행할 때 해당 프로그램에 연결된 응용 프로그램 및 PSB가로드됩니다. 그런 다음 애플리케이션 프로그램에 의해 트리거 된 CALL 요청이 IMS 모듈에 의해 실행됩니다.
IMS 서비스
다음 IMS 서비스는 응용 프로그램에서 사용됩니다.
- 데이터베이스 레코드 액세스
- IMS 명령 실행
- IMS 서비스 호출 발행
- 체크 포인트 호출
- 통화 동기화
- 온라인 사용자 단말기에서 메시지 보내기 또는 받기
IMS 데이터베이스와 통신하기 위해 COBOL 애플리케이션 프로그램 내에 DL / I 호출을 포함합니다. COBOL 프로그램에서 다음 DL / I 문을 사용하여 데이터베이스에 액세스합니다.
- 입력 명세서
- Goback 진술
- 콜 문
입력 명세서
DL / I에서 COBOL 프로그램으로 제어를 전달하는 데 사용됩니다. 다음은 항목 문의 구문입니다.
ENTRY 'DLITCBL' USING pcb-name1
[pcb-name2]위의 문장은 Procedure DivisionCOBOL 프로그램의. COBOL 프로그램의 항목 설명에 대해 자세히 살펴 보겠습니다.
배치 초기화 모듈은 응용 프로그램을 트리거하고 제어하에 실행됩니다.
DL / I는 필요한 제어 블록과 모듈 및 응용 프로그램을로드하고 응용 프로그램에 제어가 제공됩니다.
DLITCBL은 DL/I to COBOL. 입력 명령문은 프로그램의 진입 점을 정의하는 데 사용됩니다.
COBOL에서 하위 프로그램을 호출 할 때 해당 주소도 제공됩니다. 마찬가지로 DL / I가 응용 프로그램에 제어 권한을 부여 할 때 프로그램의 PSB에 정의 된 각 PCB의 주소도 제공합니다.
응용 프로그램에서 사용되는 모든 PCB는 내부에 정의되어야합니다. Linkage Section PCB가 애플리케이션 프로그램 외부에 있기 때문에 COBOL 프로그램의.
연결 섹션 내부의 PCB 정의는 다음과 같이 호출됩니다. PCB Mask.
PCB 마스크와 스토리지의 실제 PCB 간의 관계는 입력 문에 PCB를 나열하여 생성됩니다. 입력 문의 목록 순서는 PSBGEN에 나타나는 순서와 동일해야합니다.
Goback 진술
제어를 IMS 제어 프로그램으로 다시 전달하는 데 사용됩니다. 다음은 Goback 문의 구문입니다.
GOBACK다음은 Goback 성명서에 대해 주목해야 할 기본 사항입니다.
GOBACK은 애플리케이션 프로그램 끝에 코딩됩니다. 프로그램에서 DL / I로 제어를 되돌립니다.
제어를 운영 체제로 되돌 리므로 STOP RUN을 사용해서는 안됩니다. STOP RUN을 사용하면 DL / I는 종료 기능을 수행 할 기회가 없습니다. 이것이 DL / I 응용 프로그램에서 Goback 문을 사용하는 이유입니다.
Goback 문을 발행하기 전에 COBOL 애플리케이션 프로그램에서 사용되는 모든 비 DL / I 데이터 세트를 닫아야합니다. 그렇지 않으면 프로그램이 비정상적으로 종료됩니다.
콜 문
Call 문은 IMS 데이터베이스에서 특정 작업을 실행하는 것과 같은 DL / I 서비스를 요청하는 데 사용됩니다. 다음은 call 문의 구문입니다.
CALL 'CBLTDLI' USING DLI Function Code
PCB Mask
Segment I/O Area
[Segment Search Arguments]위의 구문은 call 문과 함께 사용할 수있는 매개 변수를 보여줍니다. 다음 표에서 각각에 대해 설명합니다.
| S. 아니. | 매개 변수 및 설명 |
|---|---|
| 1 | DLI Function Code 수행 할 DL / I 기능을 식별합니다. 이 인수는 I / O 작업을 설명하는 네 문자 필드의 이름입니다. |
| 2 | PCB Mask Linkage Section 내부의 PCB 정의를 PCB Mask라고합니다. 이들은 입력 문에 사용됩니다. SELECT, ASSIGN, OPEN 또는 CLOSE 문이 필요하지 않습니다. |
| 삼 | Segment I/O Area 입력 / 출력 작업 영역의 이름입니다. 이것은 DL / I가 요청 된 세그먼트를 넣는 응용 프로그램의 영역입니다. |
| 4 | Segment Search Arguments 이는 발행 된 호출 유형에 따라 선택적 매개 변수입니다. IMS 데이터베이스 내에서 데이터 세그먼트를 검색하는 데 사용됩니다. |
다음은 Call 문에 대해주의해야 할 사항입니다.
CBLTDLI는 COBOL to DL/I. 프로그램의 개체 모듈로 링크 편집 된 인터페이스 모듈의 이름입니다.
각 DL / I 호출 후 DLI는 PCB에 상태 코드를 저장합니다. 프로그램은이 코드를 사용하여 호출의 성공 여부를 확인할 수 있습니다.
예
COBOL에 대한 더 많은 이해를 위해 여기에서 COBOL 튜토리얼을 살펴볼 수 있습니다 . 다음 예제는 IMS 데이터베이스 및 DL / I 호출을 사용하는 COBOL 프로그램의 구조를 보여줍니다. 다음 장의 예제에서 사용되는 각 매개 변수에 대해 자세히 설명합니다.
IDENTIFICATION DIVISION.
PROGRAM-ID. TEST1.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 DLI-FUNCTIONS.
05 DLI-GU PIC X(4) VALUE 'GU '.
05 DLI-GHU PIC X(4) VALUE 'GHU '.
05 DLI-GN PIC X(4) VALUE 'GN '.
05 DLI-GHN PIC X(4) VALUE 'GHN '.
05 DLI-GNP PIC X(4) VALUE 'GNP '.
05 DLI-GHNP PIC X(4) VALUE 'GHNP'.
05 DLI-ISRT PIC X(4) VALUE 'ISRT'.
05 DLI-DLET PIC X(4) VALUE 'DLET'.
05 DLI-REPL PIC X(4) VALUE 'REPL'.
05 DLI-CHKP PIC X(4) VALUE 'CHKP'.
05 DLI-XRST PIC X(4) VALUE 'XRST'.
05 DLI-PCB PIC X(4) VALUE 'PCB '.
01 SEGMENT-I-O-AREA PIC X(150).
LINKAGE SECTION.
01 STUDENT-PCB-MASK.
05 STD-DBD-NAME PIC X(8).
05 STD-SEGMENT-LEVEL PIC XX.
05 STD-STATUS-CODE PIC XX.
05 STD-PROC-OPTIONS PIC X(4).
05 FILLER PIC S9(5) COMP.
05 STD-SEGMENT-NAME PIC X(8).
05 STD-KEY-LENGTH PIC S9(5) COMP.
05 STD-NUMB-SENS-SEGS PIC S9(5) COMP.
05 STD-KEY PIC X(11).
PROCEDURE DIVISION.
ENTRY 'DLITCBL' USING STUDENT-PCB-MASK.
A000-READ-PARA.
110-GET-INVENTORY-SEGMENT.
CALL ‘CBLTDLI’ USING DLI-GN
STUDENT-PCB-MASK
SEGMENT-I-O-AREA.
GOBACK.DL / I 함수는 DL / I 호출에서 사용되는 첫 번째 매개 변수입니다. 이 함수는 IMS DL / I 호출에 의해 IMS 데이터베이스에서 수행 될 작업을 알려줍니다. DL / I 함수의 구문은 다음과 같습니다.
01 DLI-FUNCTIONS.
05 DLI-GU PIC X(4) VALUE 'GU '.
05 DLI-GHU PIC X(4) VALUE 'GHU '.
05 DLI-GN PIC X(4) VALUE 'GN '.
05 DLI-GHN PIC X(4) VALUE 'GHN '.
05 DLI-GNP PIC X(4) VALUE 'GNP '.
05 DLI-GHNP PIC X(4) VALUE 'GHNP'.
05 DLI-ISRT PIC X(4) VALUE 'ISRT'.
05 DLI-DLET PIC X(4) VALUE 'DLET'.
05 DLI-REPL PIC X(4) VALUE 'REPL'.
05 DLI-CHKP PIC X(4) VALUE 'CHKP'.
05 DLI-XRST PIC X(4) VALUE 'XRST'.
05 DLI-PCB PIC X(4) VALUE 'PCB '.이 구문은 다음과 같은 핵심 사항을 나타냅니다.
이 매개 변수의 경우 기능 코드를 저장할 저장 필드로 4 자 이름을 제공 할 수 있습니다.
DL / I 함수 매개 변수는 COBOL 프로그램의 작업 스토리지 섹션에 코딩됩니다.
DL / I 함수를 지정하기 위해 프로그래머는 DL / I 호출에서 DLI-GU와 같은 05 레벨 데이터 이름 중 하나를 코딩해야합니다. COBOL은 CALL 문에서 리터럴을 코딩하는 것을 허용하지 않기 때문입니다.
DL / I 기능은 Get, Update 및 기타 기능의 세 가지 범주로 나뉩니다. 각각에 대해 자세히 논의하겠습니다.
함수 가져 오기
Get 함수는 모든 프로그래밍 언어에서 지원하는 읽기 작업과 유사합니다. Get 기능은 IMS DL / I 데이터베이스에서 세그먼트를 페치하는 데 사용됩니다. 다음 Get 함수는 IMS DB에서 사용됩니다-
- 독특하게
- 다음 받기
- 부모의 다음 단계
- 홀드 고유
- Get Hold Next
- Get Hold Next within Parent
Let us consider the following IMS database structure to understand the DL/I function calls −
Get Unique
'GU' code is used for the Get Unique function. It works similar to the random read statement in COBOL. It is used to fetch a particular segment occurrence based on the field values. The field values can be provided using segment search arguments. The syntax of a GU call is as follows −
CALL 'CBLTDLI' USING DLI-GU
PCB Mask
Segment I/O Area
[Segment Search Arguments]If you execute the above call statement by providing appropriate values for all parameters in the COBOL program, you can retrieve the segment in the segment I/O area from the database. In the above example, if you provide the field values of Library, Magazines, and Health, then you get the desired occurrence of the Health segment.
Get Next
'GN' code is used for the Get Next function. It works similar to the read next statement in COBOL. It is used to fetch segment occurrences in a sequence. The predefined pattern for accessing data segment occurrences is down the hierarchy, then left to right. The syntax of a GN call is as follows −
CALL 'CBLTDLI' USING DLI-GN
PCB Mask
Segment I/O Area
[Segment Search Arguments]If you execute the above call statement by providing appropriate values for all parameters in the COBOL program, you can retrieve the segment occurrence in the segment I/O area from the database in a sequential order. In the above example, it starts with accessing the Library segment, then Books segment, and so on. We perform the GN call again and again, until we reach the segment occurrence we want.
Get Next within Parent
'GNP' code is used for Get Next within Parent. This function is used to retrieve segment occurrences in sequence subordinate to an established parent segment. The syntax of a GNP call is as follows −
CALL 'CBLTDLI' USING DLI-GNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Get Hold Unique
'GHU' code is used for Get Hold Unique. Hold function specifies that we are going to update the segment after retrieval. The Get Hold Unique function corresponds to the Get Unique call. Given below is the syntax of a GHU call −
CALL 'CBLTDLI' USING DLI-GHU
PCB Mask
Segment I/O Area
[Segment Search Arguments]Get Hold Next
'GHN' code is used for Get Hold Next. Hold function specifies that we are going to update the segment after retrieval. The Get Hold Next function corresponds to the Get Next call. Given below is the syntax of a GHN call −
CALL 'CBLTDLI' USING DLI-GHN
PCB Mask
Segment I/O Area
[Segment Search Arguments]Get Hold Next within Parent
'GHNP' code is used for Get Hold Next within Parent. Hold function specifies that we are going to update the segment after retrieval. The Get Hold Next within Parent function corresponds to the Get Next within Parent call. Given below is the syntax of a GHNP call −
CALL 'CBLTDLI' USING DLI-GHNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Update Functions
Update functions are similar to re-write or insert operations in any other programming language. Update functions are used to update segments in an IMS DL/I database. Before using the update function, there must be a successful call with Hold clause for the segment occurrence. The following Update functions are used in IMS DB −
- Insert
- Delete
- Replace
Insert
'ISRT' code is used for the Insert function. The ISRT function is used to add a new segment to the database. It is used to change an existing database or load a new database. Given below is the syntax of an ISRT call −
CALL 'CBLTDLI' USING DLI-ISRT
PCB Mask
Segment I/O Area
[Segment Search Arguments]Delete
'DLET' code is used for the Delete function. It is used to remove a segment from an IMS DL/I database. Given below is the syntax of a DLET call −
CALL 'CBLTDLI' USING DLI-DLET
PCB Mask
Segment I/O Area
[Segment Search Arguments]Replace
'REPL' code is used for Get Hold Next within Parent. The Replace function is used to replace a segment in the IMS DL/I database. Given below is the syntax of an REPL call −
CALL 'CBLTDLI' USING DLI-REPL
PCB Mask
Segment I/O Area
[Segment Search Arguments]Other Functions
The following other functions are used in IMS DL/I calls −
- Checkpoint
- Restart
- PCB
Checkpoint
'CHKP' code is used for the Checkpoint function. It is used in the recovery features of IMS. Given below is the syntax of a CHKP call −
CALL 'CBLTDLI' USING DLI-CHKP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Restart
'XRST' code is used for the Restart function. It is used in the restart features of IMS. Given below is the syntax of an XRST call −
CALL 'CBLTDLI' USING DLI-XRST
PCB Mask
Segment I/O Area
[Segment Search Arguments]PCB
PCB function is used in CICS programs in the IMS DL/I database. Given below is the syntax of a PCB call −
CALL 'CBLTDLI' USING DLI-PCB
PCB Mask
Segment I/O Area
[Segment Search Arguments]You can find more details about these functions in the recovery chapter.
PCB stands for Program Communication Block. PCB Mask is the second parameter used in the DL/I call. It is declared in the linkage section. Given below is the syntax of a PCB Mask −
01 PCB-NAME.
05 DBD-NAME PIC X(8).
05 SEG-LEVEL PIC XX.
05 STATUS-CODE PIC XX.
05 PROC-OPTIONS PIC X(4).
05 RESERVED-DLI PIC S9(5).
05 SEG-NAME PIC X(8).
05 LENGTH-FB-KEY PIC S9(5).
05 NUMB-SENS-SEGS PIC S9(5).
05 KEY-FB-AREA PIC X(n).Here are the key points to note −
For each database, the DL/I maintains an area of storage that is known as the program communication block. It stores the information about the database that are accessed inside the application programs.
The ENTRY statement creates a connection between the PCB masks in the Linkage Section and the PCBs within the program’s PSB. The PCB masks used in a DL/I call tells which database to use for operation.
You can assume this is similar to specifying a file name in a COBOL READ statement or a record name in a COBOL write statement. No SELECT, ASSIGN, OPEN, or CLOSE statements are required.
After each DL/I call, the DL/I stores a status code in the PCB and the program can use that code to determine whether the call succeeded or failed.
PCB Name
Points to note −
PCB Name is the name of the area which refers to the entire structure of the PCB fields.
PCB Name is used in program statements.
PCB Name is not a field in the PCB.
DBD Name
Points to note −
DBD name contains the character data. It is eight bytes long.
The first field in the PCB is the name of the database being processed and it provides the DBD name from the library of database descriptions associated with a particular database.
Segment Level
Points to note −
Segment level is known as Segment Hierarchy Level Indicator. It contains character data and is two bytes long.
A segment level field stores the level of the segment that was processed. When a segment is retrieved successfully, the level number of the retrieved segment is stored here.
A segment level field never has a value greater than 15 because that is the maximum number of levels permitted in a DL/I database.
Status Code
Points to note −
Status code field contains two bytes of character data.
Status code contains the DL/I status code.
Spaces are moved to the status code field when DL/I completes the processing of calls successfully.
Non-space values indicate that the call was not successful.
Status code GB indicates end-of-file and status code GE indicates that the requested segment is not found.
Proc Options
Points to note −
Proc options are known as processing options which contain four-character data fields.
A Processing Option field indicates what kind of processing the program is authorized to do on the database.
Reserved DL/I
Points to note −
Reserved DL/I is known as the reserved area of the IMS. It stores four bytes binary data.
IMS uses this area for its own internal linkage related to an application program.
Segment Name
Points to note −
SEG Name is known as segment name feedback area. It contains 8 bytes of character data.
The name of the segment is stored in this field after each DL/I call.
Length FB Key
Points to note −
Length FB key is known as the length of the key feedback area. It stores four bytes of binary data.
This field is used to report the length of the concatenated key of the lowest level segment processed during the previous call.
It is used with the key feedback area.
Number of Sensitivity Segments
Points to note −
Number of sensitivity segments store four bytes binary data.
It defines to which level an application program is sensitive. It represents a count of number of segments in the logical data structure.
Key Feedback Area
Points to note −
Key feedback area varies in length from one PCB to another.
It contains the longest possible concatenated key that can be used with the program’s view of the database.
After a database operation, DL/I returns the concatenated key of the lowest level segment processed in this field, and it returns the length of the key in the key length feedback area.
SSA stands for Segment Search Arguments. SSA is used to identify the segment occurrence being accessed. It is an optional parameter. We can include any number of SSAs depending on the requirement. There are two types of SSAs −
- Unqualified SSA
- Qualified SSA
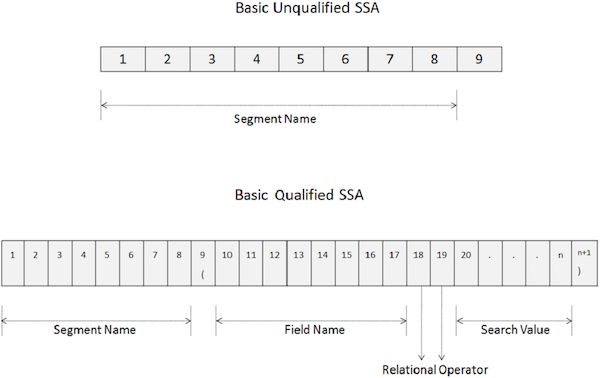
Unqualified SSA
An unqualified SSA provides the name of the segment being used inside the call. Given below is the syntax of an unqualified SSA −
01 UNQUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X VALUE SPACE.The key points of unqualified SSA are as follows −
A basic unqualified SSA is 9 bytes long.
The first 8 bytes hold the segment name which is being used for processing.
The last byte always contains space.
DL/I uses the last byte to determine the type of SSA.
To access a particular segment, move the name of the segment in the SEGMENT-NAME field.
The following images show the structures of unqualified and qualified SSAs −
Qualified SSA
A Qualified SSA provides the segment type with the specific database occurrence of a segment. Given below is the syntax of a Qualified SSA −
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.The key points of qualified SSA are as follows −
The first 8 bytes of a qualified SSA holds the segment name being used for processing.
The ninth byte is a left parenthesis '('.
The next 8 bytes starting from the tenth position specifies the field name which we want to search.
After the field name, in the 18th and 19th positions, we specify two-character relational operator code.
Then we specify the field value and in the last byte, there is a right parenthesis ')'.
The following table shows the relational operators used in a Qualified SSA.
| Relational Operator | Symbol | Description |
|---|---|---|
| EQ | = | Equal |
| NE | ~= ˜ | Not equal |
| GT | > | Greater than |
| GE | >= | Greater than or equal |
| LT | << | Less than |
| LE | <= | Less than or equal |
Command Codes
Command codes are used to enhance the functionality of DL/I calls. Command codes reduce the number of DL/I calls, making the programs simple. Also, it improves the performance as the number of calls is reduced. The following image shows how command codes are used in unqualified and qualified SSAs −
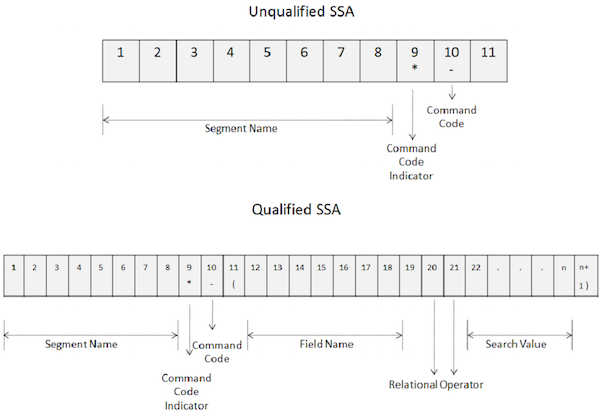
The key points of command codes are as follows −
To use command codes, specify an asterisk in the 9th position of the SSA as shown in the above image.
Command code is coded at the tenth position.
From 10th position onwards, DL/I considers all characters to be command codes until it encounters a space for an unqualified SSA and a left parenthesis for a qualified SSA.
The following table shows the list of command codes used in SSA −
| Command Code | Description |
|---|---|
| C | Concatenated Key |
| D | Path Call |
| F | First Occurrence |
| L | Last Occurrence |
| N | Path Call Ignore |
| P | Set Parentage |
| Q | Enqueue Segment |
| U | Maintain Position at this level |
| V | Maintain Position at this and all above levels |
| - | Null Command Code |
Multiple Qualifications
The fundamental points of multiple qualifications are as follows −
Multiple qualifications are required when we need to use two or more qualifications or fields for comparison.
We use Boolean operators like AND and OR to connect two or more qualifications.
Multiple qualifications can be used when we want to process a segment based on a range of possible values for a single field.
Given below is the syntax of Multiple Qualifications −
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME1 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE1 PIC X(m).
05 MUL-QUAL PIC X VALUE '&'.
05 FIELD-NAME2 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE2 PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.MUL-QUAL is a short term for MULtiple QUALIification in which we can provide boolean operators like AND or OR.
The various data retrieval methods used in IMS DL/I calls are as follows −
- GU Call
- GN Call
- Using Command Codes
- Multiple Processing
Let us consider the following IMS database structure to understand the data retrieval function calls −
GU Call
The fundamentals of GU call are as follows −
GU call is known as Get Unique call. It is used for random processing.
If an application does not update the database regularly or if the number of database updates is less, then we use random processing.
GU call is used to place the pointer at a particular position for further sequential retrieval.
GU calls are independent of the pointer position established by the previous calls.
GU call processing is based on the unique key fields supplied in the call statement.
If we supply a key field that is not unique, then DL/I returns the first segment occurrence of the key field.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSAThe above example shows we issue a GU call by providing a complete set of qualified SSAs. It includes all the key fields starting from the root level to the segment occurrence that we want to retrieve.
GU Call Considerations
If we do not provide the complete set of qualified SSAs in the call, then DL/I works in the following way −
When we use an unqualified SSA in a GU call, DL/I accesses the first segment occurrence in the database that meets the criteria you specify.
When we issue a GU call without any SSAs, DL/I returns the first occurrence of the root segment in the database.
If some SSAs at intermediate levels are not mentioned in the call, then DL/I uses either the established position or the default value of an unqualified SSA for the segment.
상태 코드
다음 표는 GU 호출 후 관련 상태 코드를 보여줍니다-
| S. 아니 | 상태 코드 및 설명 |
|---|---|
| 1 | Spaces 성공적인 통화 |
| 2 | GE DL / I는 호출에 지정된 기준을 충족하는 세그먼트를 찾을 수 없습니다. |
GN 호출
GN 호출의 기본은 다음과 같습니다.
GN 호출은 Get Next 호출로 알려져 있습니다. 기본 순차 처리에 사용됩니다.
데이터베이스에서 포인터의 초기 위치는 첫 번째 데이터베이스 레코드의 루트 세그먼트 앞입니다.
데이터베이스 포인터 위치는 성공적인 GN 호출 후 시퀀스에서 다음 세그먼트 발생 이전입니다.
GN 호출은 이전 호출로 설정된 위치에서 데이터베이스를 통해 시작됩니다.
GN 호출이 규정되지 않은 경우 계층 적 순서로 유형에 관계없이 데이터베이스에서 다음 세그먼트 발생을 반환합니다.
GN 호출에 SSA가 포함 된 경우 DL / I는 지정된 모든 SSA의 요구 사항을 충족하는 세그먼트 만 검색합니다.
CALL 'CBLTDLI' USING DLI-GN
PCB-NAME
IO-AREA
BOOKS-SSA위의 예는 레코드를 순차적으로 읽을 수있는 시작 위치를 제공하는 GN 호출을 실행하는 것을 보여줍니다. BOOKS 세그먼트의 첫 번째 발생을 가져옵니다.
상태 코드
다음 표는 GN 호출 후 관련 상태 코드를 보여줍니다-
| S. 아니 | 상태 코드 및 설명 |
|---|---|
| 1 | Spaces 성공적인 통화 |
| 2 | GE DL / I는 호출에 지정된 기준을 충족하는 세그먼트를 찾을 수 없습니다. |
| 삼 | GA 규정되지 않은 GN 호출은 데이터베이스 계층 구조에서 한 수준 위로 이동하여 세그먼트를 가져옵니다. |
| 4 | GB 데이터베이스 끝에 도달했으며 세그먼트를 찾을 수 없습니다. |
GK 정규화되지 않은 GN 호출은 방금 검색된 유형이 아닌 특정 유형의 세그먼트를 가져 오려고하지만 동일한 계층 수준에 유지됩니다. |
명령 코드
명령 코드는 세그먼트 발생을 가져 오는 호출과 함께 사용됩니다. 호출에 사용되는 다양한 명령 코드는 아래에서 설명합니다.
F 명령 코드
주목할 점-
F 명령 코드가 호출에 지정되면 호출은 세그먼트의 첫 번째 발생을 처리합니다.
F 명령 코드는 순차적으로 처리하고자 할 때 사용할 수 있으며 GN 호출 및 GNP 호출과 함께 사용할 수 있습니다.
GU 호출에 F 명령 코드를 지정하면 GU 호출이 기본적으로 첫 번째 세그먼트 발생을 가져 오므로 의미가 없습니다.
L 명령 코드
주목할 점-
L 명령 코드가 호출에 지정되면 호출은 세그먼트의 마지막 발생을 처리합니다.
L 명령 코드는 순차적으로 처리하고자 할 때 사용할 수 있으며 GN 호출 및 GNP 호출과 함께 사용할 수 있습니다.
D 명령 코드
주목할 점-
D 명령 코드는 단일 호출을 사용하여 둘 이상의 세그먼트 발생을 가져 오는 데 사용됩니다.
일반적으로 DL / I는 SSA에 지정된 가장 낮은 수준의 세그먼트에서 작동하지만 대부분의 경우 다른 수준의 데이터도 필요합니다. 이 경우 D 명령 코드를 사용할 수 있습니다.
D 명령 코드를 사용하면 세그먼트의 전체 경로를 쉽게 검색 할 수 있습니다.
C 명령 코드
주목할 점-
C 명령 코드는 키를 연결하는 데 사용됩니다.
관계 연산자를 사용하는 것은 필드 이름, 관계 연산자 및 검색 값을 지정해야하므로 약간 복잡합니다. 대신 C 명령 코드를 사용하여 연결된 키를 제공 할 수 있습니다.
다음 예제는 C 명령 코드의 사용을 보여줍니다-
01 LOCATION-SSA.
05 FILLER PIC X(11) VALUE ‘INLOCSEG*C(‘.
05 LIBRARY-SSA PIC X(5).
05 BOOKS-SSA PIC X(4).
05 ENGINEERING-SSA PIC X(6).
05 IT-SSA PIC X(3)
05 FILLER PIC X VALUE ‘)’.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LOCATION-SSAP 명령 코드
주목할 점-
GU 또는 GN 호출을 발행 할 때 DL / I는 검색된 가장 낮은 수준의 세그먼트에서 상위 항목을 설정합니다.
P 명령 코드를 포함하면 DL / I는 계층 경로의 상위 레벨 세그먼트에서 상위를 설정합니다.
U 명령 코드
주목할 점-
GN 호출의 규정되지 않은 SSA에 U 명령 코드가 지정되면 DL / I는 세그먼트 검색을 제한합니다.
U 명령 코드는 정규화 된 SSA와 함께 사용되는 경우 무시됩니다.
V 명령 코드
주목할 점-
V 명령 코드는 U 명령 코드와 유사하게 작동하지만 특정 수준과 계층 구조 위의 모든 수준에서 세그먼트 검색을 제한합니다.
V 명령 코드는 정규화 된 SSA와 함께 사용할 때 무시됩니다.
Q 명령 코드
주목할 점-
Q 명령 코드는 애플리케이션 프로그램 전용 세그먼트를 대기열에 넣거나 예약하는 데 사용됩니다.
Q 명령 코드는 다른 프로그램이 세그먼트를 변경할 수있는 대화식 환경에서 사용됩니다.
다중 처리
프로그램은 다중 처리로 알려진 IMS 데이터베이스에서 여러 위치를 가질 수 있습니다. 다중 처리는 두 가지 방법으로 수행 할 수 있습니다.
- 여러 PCB
- 다중 포지셔닝
여러 PCB
단일 데이터베이스에 대해 여러 PCB를 정의 할 수 있습니다. PCB가 여러 개인 경우 애플리케이션 프로그램은 PCB에 대해 다른보기를 가질 수 있습니다. 다중 처리를 구현하는이 방법은 추가 PCB로 인한 오버 헤드로 인해 비효율적입니다.
다중 포지셔닝
프로그램은 단일 PCB를 사용하여 데이터베이스에서 여러 위치를 유지할 수 있습니다. 이는 각 계층 적 경로에 대해 고유 한 위치를 유지함으로써 달성됩니다. 다중 위치 지정은 동시에 두 개 이상의 유형의 세그먼트에 순차적으로 액세스하는 데 사용됩니다.
IMS DL / I 호출에 사용되는 다른 데이터 조작 방법은 다음과 같습니다.
- ISRT 호출
- 보류 전화 받기
- REPL 호출
- DLET 전화
데이터 조작 함수 호출을 이해하기 위해 다음 IMS 데이터베이스 구조를 고려해 보겠습니다.
ISRT 호출
주목할 점-
ISRT 호출은 데이터베이스에 세그먼트 발생을 추가하는 데 사용되는 삽입 호출로 알려져 있습니다.
ISRT 호출은 새 데이터베이스를로드하는 데 사용됩니다.
세그먼트 설명 필드에 데이터가로드되면 ISRT 호출을 발행합니다.
DL / I가 세그먼트 발생 위치를 알 수 있도록 규정되지 않거나 규정 된 SSA가 호출에 지정되어야합니다.
통화에서 자격이없는 SSA와 자격을 갖춘 SSA를 함께 사용할 수 있습니다. 위의 모든 레벨에 대해 적격 SSA를 지정할 수 있습니다. 다음 예를 살펴 보겠습니다.
CALL 'CBLTDLI' USING DLI-ISRT
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
UNQUALIFIED-ENGINEERING-SSA위의 예는 적격 및 비정규 SSA의 조합을 제공하여 ISRT 호출을 발행하고 있음을 보여줍니다.
삽입하는 새 세그먼트에 고유 키 필드가 있으면 적절한 위치에 추가됩니다. 키 필드가 고유하지 않은 경우 데이터베이스 관리자가 정의한 규칙에 의해 추가됩니다.
키 필드를 지정하지 않고 ISRT 호출을 발행하면 삽입 규칙이 기존 트윈 세그먼트와 관련된 세그먼트를 배치 할 위치를 알려줍니다. 다음은 삽입 규칙입니다.
First − 규칙이 첫 번째 인 경우 기존 쌍둥이 앞에 새 세그먼트가 추가됩니다.
Last − 규칙이 마지막이면 기존의 모든 쌍둥이 뒤에 새 세그먼트가 추가됩니다.
Here − 규칙이 여기에 있으면 기존 쌍둥이에 상대적인 현재 위치에 추가됩니다. 이는 첫 번째, 마지막 또는 모든 위치 일 수 있습니다.
상태 코드
다음 표는 ISRT 호출 후 관련 상태 코드를 보여줍니다-
| S. 아니 | 상태 코드 및 설명 |
|---|---|
| 1 | Spaces 성공적인 통화 |
| 2 | GE 여러 SSA가 사용되며 DL / I가 지정된 경로로 호출을 충족 할 수 없습니다. |
| 삼 | II 이미 데이터베이스에있는 세그먼트 발생을 추가해보십시오. |
| 4 | LB / LC LD / LE 로드 처리 중에 이러한 상태 코드를받습니다. 대부분의 경우 정확한 계층 적 순서로 세그먼트를 삽입하지 않음을 나타냅니다. |
보류 전화 받기
주목할 점-
DL / I 통화에서 지정하는 세 가지 유형의 Get Hold 통화가 있습니다.
고유 한 보류 (GHU) 가져 오기
Get Hold Next (GHN)
다음 부모 내에서 보류 (GHNP)
Hold 기능은 검색 후 세그먼트를 업데이트하도록 지정합니다. 따라서 REPL 또는 DLET 호출 전에 데이터베이스를 업데이트 할 의도를 DL / I에 알리는 성공적인 보류 호출이 발행되어야합니다.
REPL 호출
주목할 점-
성공적인 get hold 호출 후 세그먼트 발생을 업데이트하기 위해 REPL 호출을 발행합니다.
REPL 호출을 사용하여 세그먼트의 길이를 변경할 수 없습니다.
REPL 호출을 사용하여 키 필드의 값을 변경할 수 없습니다.
REPL 호출에는 적격 SSA를 사용할 수 없습니다. 정규화 된 SSA를 지정하면 호출이 실패합니다.
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
*Move the values which you want to update in IT segment occurrence*
CALL ‘CBLTDLI’ USING DLI-REPL
PCB-NAME
IO-AREA.위의 예는 REPL 호출을 사용하여 IT 세그먼트 발생을 업데이트합니다. 먼저, 업데이트하려는 세그먼트 발생을 가져 오기 위해 GHU 호출을 발행합니다. 그런 다음 REPL 호출을 발행하여 해당 세그먼트의 값을 업데이트합니다.
DLET 전화
주목할 점-
DLET 호출은 REPL 호출과 동일한 방식으로 작동합니다.
성공적인 보류 호출 후 세그먼트 발생을 삭제하기 위해 DLET 호출을 발행합니다.
DLET 통화에는 적격 SSA를 사용할 수 없습니다. 정규화 된 SSA를 지정하면 호출이 실패합니다.
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
CALL ‘CBLTDLI’ USING DLI-DLET
PCB-NAME
IO-AREA.위의 예는 DLET 호출을 사용하여 IT 세그먼트 발생을 삭제합니다. 먼저, 삭제하려는 세그먼트 발생을 가져 오기 위해 GHU 호출을 발행합니다. 그런 다음 DLET 호출을 실행하여 해당 세그먼트의 값을 업데이트합니다.
상태 코드
다음 표는 REPL 또는 DLET 호출 후 관련 상태 코드를 보여줍니다-
| S. 아니 | 상태 코드 및 설명 |
|---|---|
| 1 | Spaces 성공적인 통화 |
| 2 | AJ REPL 또는 DLET 호출에 사용되는 적격 SSA입니다. |
| 삼 | DJ 프로그램은 바로 이전에 보류 호출을받지 않고 교체 호출을 발행합니다. |
| 4 | DA 프로그램은 REPL 또는 DLET 호출을 발행하기 전에 세그먼트의 키 필드를 변경합니다. |
Secondary Indexing은 완전한 연결 키를 사용하지 않고 데이터베이스에 액세스하거나 시퀀스 기본 필드를 사용하지 않으려는 경우에 사용됩니다.
인덱스 포인터 세그먼트
DL / I는 인덱스 된 데이터베이스의 세그먼트에 대한 포인터를 별도의 데이터베이스에 저장합니다. 인덱스 포인터 세그먼트는 유일한 보조 인덱스 유형입니다. 그것은 두 부분으로 구성됩니다-
- 접두사 요소
- 데이터 요소
접두사 요소
인덱스 포인터 세그먼트의 접두어 부분에는 인덱스 대상 세그먼트에 대한 포인터가 포함됩니다. 인덱스 대상 세그먼트는 보조 인덱스를 사용하여 액세스 할 수있는 세그먼트입니다.
데이터 요소
데이터 요소에는 색인이 작성되는 색인화 된 데이터베이스의 세그먼트에있는 키 값이 포함됩니다. 이를 인덱스 소스 세그먼트라고도합니다.
Secondary Indexing에 대해 주목해야 할 핵심 사항은 다음과 같습니다.
인덱스 소스 세그먼트와 대상 소스 세그먼트는 동일하지 않아도됩니다.
보조 인덱스를 설정하면 DL / I가 자동으로 유지 관리합니다.
DBA는 다중 액세스 경로에 따라 많은 보조 인덱스를 정의합니다. 이러한 보조 인덱스는 별도의 인덱스 데이터베이스에 저장됩니다.
DL / I에 추가 처리 오버 헤드를 부과하므로 더 많은 보조 인덱스를 생성해서는 안됩니다.
보조 키
주목할 점-
보조 인덱스가 작성되는 인덱스 소스 세그먼트의 필드를 보조 키라고합니다.
모든 필드를 보조 키로 사용할 수 있습니다. 세그먼트 시퀀스 필드 일 필요는 없습니다.
보조 키는 인덱스 소스 세그먼트 내의 단일 필드 조합 일 수 있습니다.
보조 키 값은 고유하지 않아도됩니다.
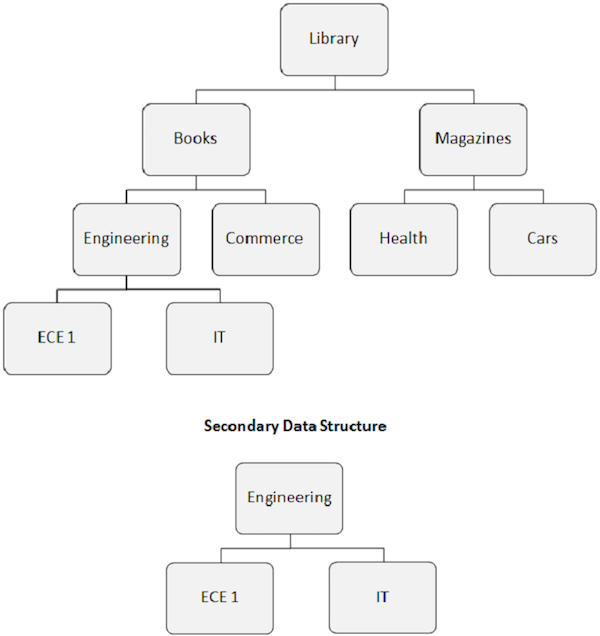
2 차 데이터 구조
주목할 점-
보조 인덱스를 만들 때 데이터베이스의 명백한 계층 구조도 변경됩니다.
인덱스 대상 세그먼트는 명백한 루트 세그먼트가됩니다. 다음 이미지에 표시된대로 엔지니어링 세그먼트는 루트 세그먼트가 아니더라도 루트 세그먼트가됩니다.
보조 인덱스로 인한 데이터베이스 구조 재 배열을 보조 데이터 구조라고합니다.
보조 데이터 구조는 디스크에있는 기본 물리적 데이터베이스 구조를 변경하지 않습니다. 응용 프로그램 앞에서 데이터베이스 구조를 변경하는 방법 일뿐입니다.
독립 AND 연산자
주목할 점-
AND (* 또는 &) 연산자가 보조 인덱스와 함께 사용되는 경우이를 종속 AND 연산자라고합니다.
독립 AND (#)를 사용하면 종속 AND로는 불가능한 자격을 지정할 수 있습니다.
이 연산자는 인덱스 소스 세그먼트가 인덱스 대상 세그먼트에 종속 된 보조 인덱스에만 사용할 수 있습니다.
독립 AND를 사용하여 SSA를 코딩하여 대상 세그먼트의 발생이 둘 이상의 종속 소스 세그먼트의 필드를 기반으로 처리되도록 지정할 수 있습니다.
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.희소 시퀀싱
주목할 점-
Sparse Sequencing은 Sparse Indexing이라고도합니다. 보조 인덱스 데이터베이스에서 스파 스 시퀀싱을 사용하여 인덱스에서 일부 인덱스 소스 세그먼트를 제거 할 수 있습니다.
성능을 향상시키기 위해 희소 시퀀싱이 사용됩니다. 인덱스 소스 세그먼트가 사용되지 않는 경우이를 제거 할 수 있습니다.
DL / I는 억제 값이나 억제 루틴 또는 둘 다를 사용하여 세그먼트를 인덱싱해야하는지 여부를 결정합니다.
인덱스 소스 세그먼트의 시퀀스 필드 값이 억제 값과 일치하면 인덱스 관계가 설정되지 않습니다.
억제 루틴은 세그먼트를 평가하고 색인화해야하는지 여부를 결정하는 사용자 작성 프로그램입니다.
희소 인덱싱이 사용되는 경우 해당 기능은 DL / I에 의해 처리됩니다. 우리는 응용 프로그램에서 그것에 대한 특별한 규정을 만들 필요가 없습니다.
DBDGEN 요구 사항
이전 모듈에서 설명했듯이 DBDGEN은 DBD를 만드는 데 사용됩니다. 보조 인덱스를 만들 때 두 개의 데이터베이스가 관련됩니다. DBA는 인덱싱 된 데이터베이스와 보조 인덱싱 된 데이터베이스 간의 관계를 생성하기 위해 두 개의 DBDGEN을 사용하여 두 개의 DBD를 생성해야합니다.
PSBGEN 요구 사항
데이터베이스에 대한 보조 인덱스를 생성 한 후 DBA는 PSB를 생성해야합니다. 프로그램에 대한 PSBGEN은 PSB 매크로의 PROCSEQ 매개 변수에서 데이터베이스에 대한 적절한 처리 순서를 지정합니다. PROCSEQ 매개 변수의 경우 DBA는 보조 인덱스 데이터베이스의 DBD 이름을 코딩합니다.
IMS 데이터베이스에는 각 세그먼트 유형이 상위를 하나만 가질 수 있다는 규칙이 있습니다. 이것은 물리적 데이터베이스의 복잡성을 제한합니다. 많은 DL / I 애플리케이션에는 세그먼트가 두 개의 상위 세그먼트 유형을 가질 수있는 복잡한 구조가 필요합니다. 이러한 한계를 극복하기 위해 DL / I는 DBA가 세그먼트가 물리적 및 논리적 부모를 모두 가질 수있는 논리적 관계를 구현할 수 있도록합니다. 하나의 물리적 데이터베이스 내에서 추가 관계를 만들 수 있습니다. 논리 관계를 구현 한 후 새로운 데이터 구조를 논리 데이터베이스라고합니다.
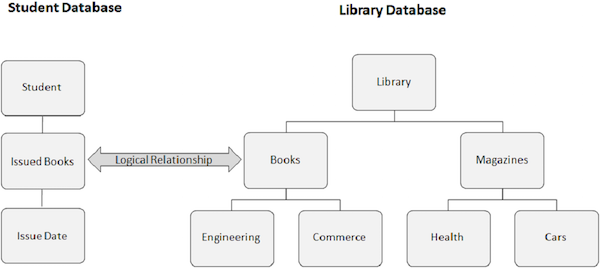
논리적 관계
논리적 관계에는 다음과 같은 속성이 있습니다.
논리적 관계는 물리적이 아닌 논리적으로 관련된 두 세그먼트 간의 경로입니다.
일반적으로 별도의 데이터베이스간에 논리적 관계가 설정됩니다. 그러나 특정 데이터베이스의 세그먼트간에 관계가있을 수 있습니다.
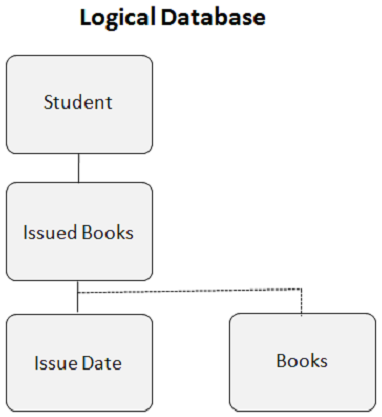
다음 이미지는 두 개의 서로 다른 데이터베이스를 보여줍니다. 하나는 학생 데이터베이스이고 다른 하나는 도서관 데이터베이스입니다. Student 데이터베이스의 Books Issued 세그먼트와 Library 데이터베이스의 Books 세그먼트간에 논리적 관계를 만듭니다.
이것은 논리적 관계를 만들 때 논리적 데이터베이스가 보이는 방식입니다-
논리적 하위 세그먼트
논리적 자식 세그먼트는 논리적 관계의 기반입니다. 물리적 데이터 세그먼트이지만 DL / I의 경우 두 개의 상위가있는 것처럼 보입니다. 위 예의 Books 세그먼트에는 두 개의 상위 세그먼트가 있습니다. 발행 된 도서 세그먼트는 논리적 상위이고 라이브러리 세그먼트는 물리적 상위입니다. 하나의 논리적 하위 세그먼트 발생에는 하나의 논리적 상위 세그먼트 발생 만 있고 하나의 논리적 상위 세그먼트 발생에는 많은 논리적 하위 세그먼트 발생이있을 수 있습니다.
논리 트윈
논리적 쌍은 논리적 상위 세그먼트 유형의 단일 발생에 모두 종속 된 논리적 하위 세그먼트 유형의 발생입니다. DL / I는 논리적 하위 세그먼트를 실제 물리적 하위 세그먼트와 유사하게 표시합니다. 이를 가상 논리적 하위 세그먼트라고도합니다.
논리적 관계의 유형
DBA는 세그먼트 간의 논리적 관계를 만듭니다. 논리적 관계를 구현하려면 DBA는 관련된 물리적 데이터베이스에 대해 DBDGEN에서이를 지정해야합니다. 논리적 관계에는 세 가지 유형이 있습니다.
- Unidirectional
- 양방향 가상
- 양방향 물리적
단방향
논리적 연결은 논리적 자식에서 논리적 부모로 이동하며 반대 방향으로 갈 수 없습니다.
양방향 가상
양방향으로 액세스 할 수 있습니다. 물리적 구조의 논리적 자식과 해당 가상 논리적 자식은 쌍으로 된 세그먼트로 볼 수 있습니다.
양방향 물리적
논리적 자식은 물리적 부모와 논리적 부모 모두에 물리적으로 저장된 하위입니다. 응용 프로그램에서는 양방향 가상 논리적 자식과 같은 방식으로 나타납니다.
프로그래밍 고려 사항
논리 데이터베이스를 사용하기위한 프로그래밍 고려 사항은 다음과 같습니다.
데이터베이스에 액세스하기위한 DL / I 호출은 논리 데이터베이스에서도 동일하게 유지됩니다.
프로그램 사양 블록은 호출에서 사용하는 구조를 나타냅니다. 어떤 경우에는 논리 데이터베이스를 사용하고 있음을 식별 할 수 없습니다.
논리적 관계는 데이터베이스 프로그래밍에 새로운 차원을 추가합니다.
두 개의 데이터베이스가 함께 통합되므로 논리적 데이터베이스로 작업 할 때는주의해야합니다. 한 데이터베이스를 수정하는 경우 동일한 수정 사항이 다른 데이터베이스에 반영되어야합니다.
프로그램 사양은 데이터베이스에서 허용되는 처리를 나타내야합니다. 처리 규칙을 위반하면 공백이 아닌 상태 코드를 받게됩니다.
연결된 세그먼트
논리적 자식 세그먼트는 항상 대상 부모의 전체 연결된 키로 시작합니다. 이를 DPCK (Destination Parent Concatenated Key)라고합니다. 논리적 자식에 대한 세그먼트 I / O 영역의 시작 부분에서 항상 DPCK를 코딩해야합니다. 논리적 데이터베이스에서 연결된 세그먼트는 서로 다른 물리적 데이터베이스에 정의 된 세그먼트 사이를 연결합니다. 연결된 세그먼트는 다음 두 부분으로 구성됩니다.
- 논리적 자식 세그먼트
- 대상 상위 세그먼트
논리적 자식 세그먼트는 다음 두 부분으로 구성됩니다.
- 대상 상위 연결 키 (DPCK)
- 논리적 하위 사용자 데이터

업데이트 중에 연결된 세그먼트로 작업 할 때 단일 호출로 논리적 자식과 대상 부모 모두에서 데이터를 추가하거나 변경할 수 있습니다. 이것은 또한 DBA가 데이터베이스에 대해 지정한 규칙에 따라 다릅니다. 인서트의 경우 올바른 위치에 DPCK를 제공하십시오. 대체 또는 삭제의 경우 연결된 세그먼트의 어느 한 부분에서 DPCK 또는 시퀀스 필드 데이터를 변경하지 마십시오.
데이터베이스 관리자는 시스템 장애시 데이터베이스 복구를 계획해야합니다. 오류는 응용 프로그램 충돌, 하드웨어 오류, 정전 등과 같은 다양한 유형이 될 수 있습니다.
간단한 접근
데이터베이스 복구에 대한 몇 가지 간단한 접근 방식은 다음과 같습니다.
데이터 세트에 대해 게시 된 모든 트랜잭션이 유지되도록 중요한 데이터 세트의주기적인 백업 사본을 만드십시오.
시스템 장애로 인해 데이터 세트가 손상된 경우 백업 사본을 복원하여 문제를 해결합니다. 그런 다음 누적 된 트랜잭션이 백업 복사본에 다시 게시되어 최신 상태로 유지됩니다.
간단한 접근 방식의 단점
데이터베이스 복구에 대한 간단한 접근 방식의 단점은 다음과 같습니다.
누적 된 거래를 다시 게시하는 데 많은 시간이 소요됩니다.
다른 모든 응용 프로그램은 복구가 완료 될 때까지 실행을 기다려야합니다.
논리적 및 보조 인덱스 관계가 관련된 경우 데이터베이스 복구는 파일 복구보다 더 오래 걸립니다.
비정상적인 종료 루틴
DL / I 프로그램은 표준 프로그램이 운영 체제에 의해 직접 실행되는 반면 DL / I 프로그램은 그렇지 않기 때문에 표준 프로그램이 충돌하는 방식과 다른 방식으로 충돌합니다. 비정상 종료 루틴을 사용하여 시스템이 간섭하여 ABEND (ABnormal END) 후에 복구를 수행 할 수 있습니다. 비정상 종료 루틴은 다음 작업을 수행합니다.
- 모든 데이터 세트를 닫습니다.
- 대기열에서 보류중인 모든 작업을 취소합니다.
- ABEND의 근본 원인을 찾기 위해 스토리지 덤프를 생성합니다.
이 루틴의 한계는 사용중인 데이터가 정확한지 여부를 보장하지 않는다는 것입니다.
DL / I 로그
응용 프로그램이 이상 종료되면 응용 프로그램에 의해 수행 된 변경 사항을 되돌리고 오류를 수정 한 다음 응용 프로그램을 다시 실행해야합니다. 이를 위해서는 DL / I 로그가 있어야합니다. 다음은 DL / I 로깅에 대한 핵심 사항입니다.
DL / I는 응용 프로그램이 수행 한 모든 변경 사항을 로그 파일로 알려진 파일에 기록합니다.
응용 프로그램이 세그먼트를 변경하면 DL / I에 의해 이전 이미지와 이후 이미지가 생성됩니다.
이러한 세그먼트 이미지는 애플리케이션 프로그램이 충돌하는 경우 세그먼트를 복원하는 데 사용할 수 있습니다.
DL / I는 미리 쓰기 로깅이라는 기술을 사용하여 데이터베이스 변경 사항을 기록합니다. 미리 쓰기 로깅을 사용하면 데이터베이스 변경 사항이 실제 데이터 세트에 기록되기 전에 로그 데이터 세트에 기록됩니다.
로그는 항상 데이터베이스보다 앞서 있으므로 복구 유틸리티는 모든 데이터베이스 변경 상태를 확인할 수 있습니다.
프로그램이 데이터베이스 세그먼트를 변경하기 위해 호출을 실행할 때 DL / I는 로깅 부분을 처리합니다.
복구 – 앞으로 및 뒤로
데이터베이스 복구의 두 가지 접근 방식은 다음과 같습니다.
Forward Recovery − DL/I uses the log file to store the change data. The accumulated transactions are re-posted using this log file.
Backward Recovery − Backward recovery is also known as backout recovery. The log records for the program are read backwards and their effects are reversed in the database. When the backout is complete, the databases are in the same state as they were in before the failure, assuming that no another application program altered the database in the meantime.
Checkpoint
A checkpoint is a stage where the database changes done by the application program are considered complete and accurate. Listed below are the points to note about a checkpoint −
Database changes made before the most recent checkpoint are not reversed by backward recovery.
Database changes logged after the most recent checkpoint are not applied to an image copy of the database during forward recovery.
Using checkpoint method, the database is restored to its condition at the most recent checkpoint when the recovery process completes.
The default for batch programs is that the checkpoint is the beginning of the program.
A checkpoint can be established using a checkpoint call (CHKP).
A checkpoint call causes a checkpoint record to be written on the DL/I log.
Shown below is the syntax of a CHKP call −
CALL 'CBLTDLI' USING DLI-CHKP
PCB-NAME
CHECKPOINT-IDThere are two checkpoint methods −
Basic Checkpointing − It allows the programmer to issue checkpoint calls that the DL/I recovery utilities use during recovery processing.
Symbolic Checkpointing − It is an advanced form of checkpointing that is used in combination with the extended restart facility. Symbolic checkpointing and extended restart together let the application programmer code the programs so that they can resume processing at the point just after the checkpoint.