Kibana-Elk Stack 소개
Kibana는 주로 선 그래프, 막대 그래프, 파이 차트, 히트 맵 등의 형태로 대량의 로그를 분석하는 데 사용되는 오픈 소스 시각화 도구입니다. Kibana는 Elasticsearch 및 Logstash와 동기화되어 작동하며 소위 ELK 스택.
ELK Elasticsearch, Logstash 및 Kibana를 의미합니다. ELK 로그 분석에 전 세계적으로 사용되는 인기있는 로그 관리 플랫폼 중 하나입니다.
ELK 스택에서-
Logstash다른 입력 소스에서 로깅 데이터 또는 기타 이벤트를 추출합니다. 이벤트를 처리하고 나중에 Elasticsearch에 저장합니다.
Kibana Elasticsearch에서 로그에 액세스하고 선 그래프, 막대 그래프, 파이 차트 등의 형태로 사용자에게 표시 할 수있는 시각화 도구입니다.
이 튜토리얼에서는 Kibana 및 Elasticsearch와 밀접하게 작업하고 데이터를 다양한 형식으로 시각화합니다.
이 장에서는 ELK 스택을 함께 사용하는 방법을 이해하겠습니다. 게다가, 당신은 또한-
- Logstash에서 Elasticsearch로 CSV 데이터를로드합니다.
- Kibana에서 Elasticsearch의 인덱스를 사용하십시오.
Logstash에서 Elasticsearch로 CSV 데이터로드
CSV 데이터를 사용하여 Logstash를 사용하여 Elasticsearch에 데이터를 업로드 할 것입니다. 데이터 분석을 위해 kaggle.com 웹 사이트에서 데이터를 얻을 수 있습니다. Kaggle.com 사이트에는 업로드 된 모든 유형의 데이터가 있으며 사용자는이를 사용하여 데이터 분석 작업을 할 수 있습니다.
여기에서 countries.csv 데이터를 가져 왔습니다. https://www.kaggle.com/fernandol/countries-of-the-world. csv 파일을 다운로드하여 사용할 수 있습니다.
우리가 사용할 csv 파일에는 다음과 같은 세부 정보가 있습니다.
파일 이름-countriesdata.csv
열- "국가", "지역", "인구", "지역"
더미 csv 파일을 만들어 사용할 수도 있습니다. logstash를 사용하여이 데이터를 countriesdata.csv 에서 elasticsearch 로 덤프 할 것 입니다.
터미널에서 elasticsearch와 Kibana를 시작하고 계속 실행하십시오. CSV 파일의 열에 대한 세부 정보와 아래에 주어진 logstash-config 파일에 표시된 기타 세부 정보가있는 logstash에 대한 구성 파일을 만들어야합니다.
input {
file {
path => "C:/kibanaproject/countriesdata.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns => ["Country","Region","Population","Area"]
}
mutate {convert => ["Population", "integer"]}
mutate {convert => ["Area", "integer"]}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
=> "countriesdata-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}구성 파일에서 3 개의 구성 요소를 만들었습니다.
입력
우리의 경우 csv 파일 인 입력 파일의 경로를 지정해야합니다. csv 파일이 저장된 경로는 경로 필드에 제공됩니다.
필터
우리의 경우 쉼표 인 구분 기호가 사용 된 csv 구성 요소와 csv 파일에 사용할 수있는 열이 있습니다. logstash는 들어오는 모든 데이터를 string으로 간주하므로 모든 열을 integer로 사용하려는 경우 위와 같이 mutate를 사용하여 동일한 값을 지정해야합니다.
산출
출력을 위해 데이터를 넣어야하는 위치를 지정해야합니다. 여기에서는 우리의 경우 elasticsearch를 사용하고 있습니다. elasticsearch에 제공되는 데 필요한 데이터는 실행중인 호스트이며 localhost라고 언급했습니다. 다음 필드는 이름을 국가- 현재 날짜 로 지정한 색인입니다 . Elasticsearch에서 데이터가 업데이트되면 Kibana에서 동일한 인덱스를 사용해야합니다.
위의 구성 파일을 logstash_countries.config 로 저장하십시오 . 다음 단계에서이 구성의 경로를 logstash 명령에 제공해야합니다.
csv 파일에서 elasticsearch로 데이터를로드하려면 elasticsearch 서버를 시작해야합니다.
자, 실행 http://localhost:9200 브라우저에서 elasticsearch가 성공적으로 실행 중인지 확인합니다.
Elasticsearch가 실행 중입니다. 이제 logstash가 설치된 경로로 이동하여 다음 명령을 실행하여 데이터를 elasticsearch에 업로드하십시오.
> logstash -f logstash_countries.conf
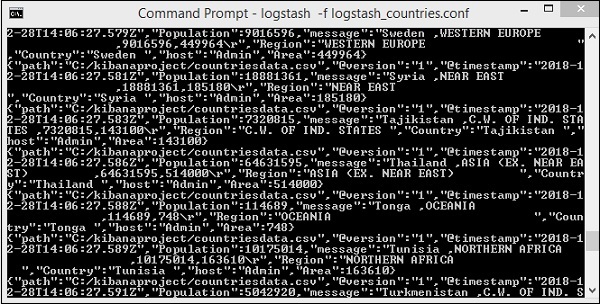
위 화면은 CSV 파일에서 Elasticsearch로로드되는 데이터를 보여줍니다. Elasticsearch에서 생성 된 인덱스가 있는지 확인하려면 다음과 같이 확인할 수 있습니다.
위와 같이 생성 된 countriesdata-28.12.2018 인덱스를 볼 수 있습니다.

지수의 세부 사항-국가 -28.12.2018은 다음과 같습니다-
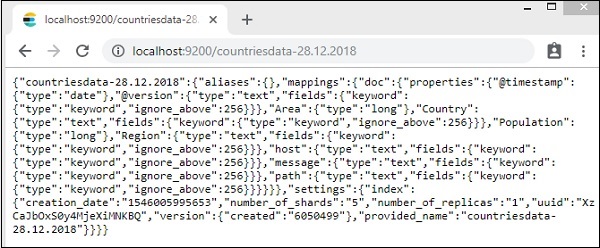
logstash에서 elasticsearch로 데이터가 업로드 될 때 속성이있는 매핑 세부 정보가 생성됩니다.
Kibana에서 Elasticsearch의 데이터 사용
현재, 우리는 Kibana가 localhost, 포트 5601에서 실행되고 있습니다. http://localhost:5601. Kibana의 UI는 다음과 같습니다.
이미 Kibana가 Elasticsearch에 연결되어 있으며 다음을 볼 수 있습니다. index :countries-28.12.2018 Kibana 내부.
Kibana UI에서 왼쪽의 관리 메뉴 옵션을 클릭하십시오.
이제 클릭 인덱스 관리-
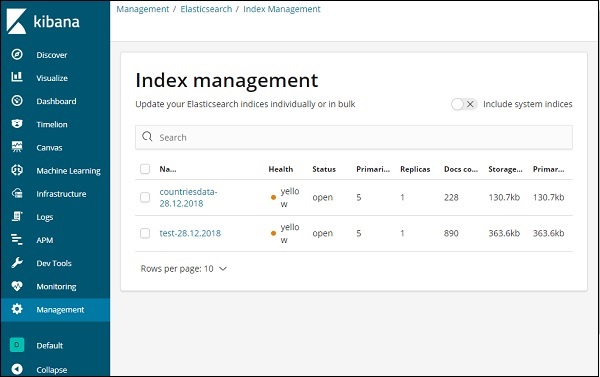
Elasticsearch에있는 인덱스는 인덱스 관리에 표시됩니다. Kibana에서 사용할 인덱스는 countriesdata-28.12.2018입니다.
따라서 Kibana에 이미 elasticsearch 인덱스가 있으므로 Kibana에서 인덱스를 사용하여 파이 차트, 막대 그래프, 꺾은 선형 차트 등의 형태로 데이터를 시각화하는 방법을 이해할 것입니다.