Kibana-샘플 데이터로드
logstash에서 elasticsearch로 데이터를 업로드하는 방법을 살펴 보았습니다. 여기에서 logstash 및 elasticsearch를 사용하여 데이터를 업로드합니다. 그러나 우리가 사용해야하는 날짜, 경도 및 위도 필드가있는 데이터에 대해서는 다음 장에서 배울 것입니다. CSV 파일이없는 경우 Kibana에서 직접 데이터를 업로드하는 방법도 살펴 봅니다.
이 장에서는 다음 주제를 다룰 것입니다.
- Elasticsearch에서 날짜, 경도 및 위도 필드가있는 Logstash 업로드 데이터 사용
- 개발자 도구를 사용하여 대량 데이터 업로드
Elasticsearch에 필드가있는 데이터에 Logstash 업로드 사용
우리는 CSV 형식의 데이터를 사용할 것이며, 분석에 사용할 수있는 데이터를 다루는 Kaggle.com에서도 동일한 데이터를 가져옵니다.
여기에서 사용되는 가정 의료 방문 데이터 는 Kaggle.com 사이트에서 가져옵니다.
다음은 CSV 파일에 사용할 수있는 필드입니다-
["Visit_Status","Time_Delay","City","City_id","Patient_Age","Zipcode","Latitude","Longitude",
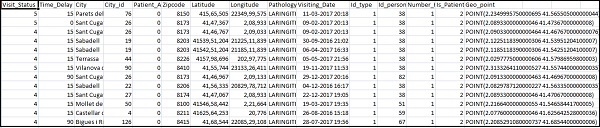
"Pathology","Visiting_Date","Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]Home_visits.csv는 다음과 같습니다-
다음은 logstash와 함께 사용되는 conf 파일입니다-
input {
file {
path => "C:/kibanaproject/home_visits.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns =>
["Visit_Status","Time_Delay","City","City_id","Patient_Age",
"Zipcode","Latitude","Longitude","Pathology","Visiting_Date",
"Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]
}
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "medicalvisits-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}기본적으로 logstash는 elasticsearch에 업로드 될 모든 것을 문자열로 간주합니다. CSV 파일에 날짜 필드가있는 경우 날짜 형식을 가져 오려면 다음을 수행해야합니다.
For date field −
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}지리적 위치의 경우 elasticsearch는 다음과 동일하게 이해합니다.
"location": {
"lat":41.565505000000044,
"lon": 2.2349995750000695
}따라서 우리는 elasticsearch에 필요한 형식의 경도와 위도가 있는지 확인해야합니다. 따라서 먼저 경도와 위도를 부동으로 변환하고 나중에 이름을 변경하여 다음의 일부로 사용할 수 있도록해야합니다.location json 객체 lat 과 lon. 동일한 코드가 여기에 표시됩니다.
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}필드를 정수로 변환하려면 다음 코드를 사용하십시오.
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}필드가 처리되면 다음 명령을 실행하여 elasticsearch에 데이터를 업로드하십시오.
- Logstash bin 디렉토리로 이동하여 다음 명령을 실행하십시오.
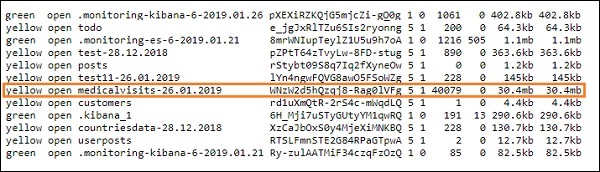
logstash -f logstash_homevisists.conf- 완료되면 아래와 같이 elasticsearch의 logstash conf 파일에 언급 된 인덱스를 볼 수 있습니다.
이제 업로드 된 인덱스 위에 인덱스 패턴을 생성하고 시각화 생성을 위해 추가로 사용할 수 있습니다.
개발자 도구를 사용하여 대량 데이터 업로드
Kibana UI에서 개발 도구를 사용할 것입니다. Dev Tools는 Logstash를 사용하지 않고 Elasticsearch에서 데이터를 업로드하는 데 유용합니다. Dev Tools를 사용하여 Kibana에서 원하는 데이터를 게시, 추가, 삭제, 검색 할 수 있습니다.
이 섹션에서는 Kibana 자체에서 샘플 데이터를로드하려고합니다. 이를 사용하여 샘플 데이터로 연습하고 Kibana 기능을 가지고 놀아서 Kibana를 잘 이해할 수 있습니다.
다음 URL에서 json 데이터를 가져와 Kibana에 업로드하겠습니다. 마찬가지로 Kibana 내에서로드 할 샘플 json 데이터를 시도 할 수 있습니다.
샘플 데이터 업로드를 시작하기 전에 Elasticsearch에서 사용할 인덱스가있는 json 데이터가 있어야합니다. logstash를 사용하여 업로드 할 때 logstash는 인덱스를 추가하기 위해주의를 기울이고 사용자는 elasticsearch에 필요한 인덱스에 대해 신경 쓸 필요가 없습니다.
일반 Json 데이터
[
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"},
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"SCENE I.London. The palace."},
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the
EARL of WESTMORELAND, SIR WALTER BLUNT, and others"}
]Kibana와 함께 사용되는 json 코드는 다음과 같이 인덱싱되어야합니다.
{"index":{"_index":"shakespeare","_id":0}}
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"}
{"index":{"_index":"shakespeare","_id":1}}
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"",
"text_entry":"SCENE I. London. The palace."}
{"index":{"_index":"shakespeare","_id":2}}
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the EARL
of WESTMORELAND, SIR WALTER BLUNT, and others"}jsonfile에 추가 데이터가 있습니다.{"index":{"_index":"nameofindex","_id":key}}.
elasticsearch와 호환되는 샘플 json 파일을 변환하기 위해 여기에 elasticsearch가 원하는 형식으로 지정된 json 파일을 출력하는 PHP의 작은 코드가 있습니다.
PHP 코드
<?php
$myfile = fopen("todo.json", "r") or die("Unable to open file!"); // your json
file here
$alldata = fread($myfile,filesize("todo.json"));
fclose($myfile);
$farray = json_decode($alldata);
$afinalarray = [];
$index_name = "todo";
$i=0;
$myfile1 = fopen("todonewfile.json", "w") or die("Unable to open file!"); //
writes a new file to be used in kibana dev tool
foreach ($farray as $a => $value) {
$_index = json_decode('{"index": {"_index": "'.$index_name.'", "_id": "'.$i.'"}}');
fwrite($myfile1, json_encode($_index));
fwrite($myfile1, "\n");
fwrite($myfile1, json_encode($value));
fwrite($myfile1, "\n");
$i++;
}
?>우리는 todo json 파일을 가져 왔습니다. https://jsonplaceholder.typicode.com/todos 그리고 PHP 코드를 사용하여 Kibana에서 업로드하는 데 필요한 형식으로 변환합니다.
샘플 데이터를로드하려면 아래와 같이 개발 도구 탭을 엽니 다.
이제 위와 같이 콘솔을 사용하겠습니다. PHP 코드를 통해 실행 한 후 얻은 json 데이터를 가져옵니다.
json 데이터를 업로드하기 위해 개발 도구에서 사용되는 명령은 다음과 같습니다.
POST _bulk우리가 만들고있는 색인의 이름은 todo 입니다.
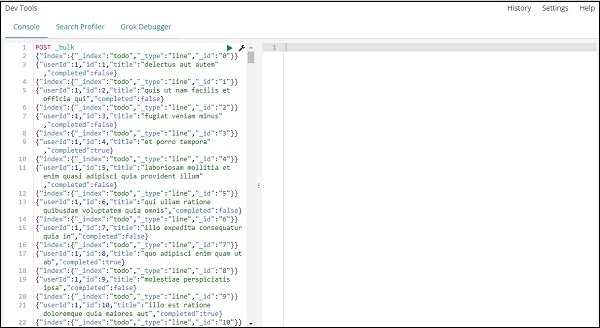

녹색 버튼을 클릭하면 데이터가 업로드되면 다음과 같이 elasticsearch에서 인덱스가 생성되었는지 여부를 확인할 수 있습니다.

다음과 같이 개발 도구 자체에서 동일하게 확인할 수 있습니다.
Command −
GET /_cat/indices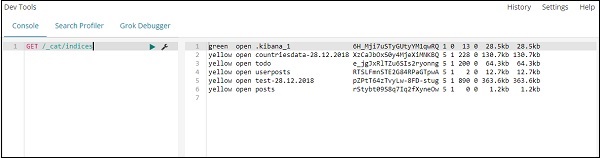
index : todo에서 무언가를 검색하려면 아래와 같이 할 수 있습니다.
Command in dev tool
GET /todo/_search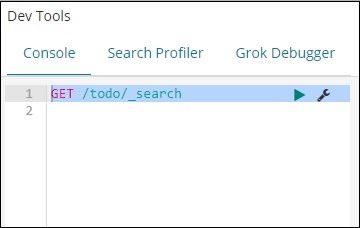
위의 검색 결과는 다음과 같습니다.

todoindex에있는 모든 레코드를 제공합니다. 우리가 얻고있는 총 기록은 200 개입니다.
할일 색인에서 레코드 검색
다음 명령을 사용하여 수행 할 수 있습니다.
GET /todo/_search
{
"query":{
"match":{
"title":"delectusautautem"
}
}
}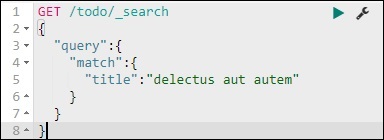

주어진 제목과 일치하는 레코드를 가져올 수 있습니다.