Python의 로지스틱 회귀-데이터 준비
분류자를 생성하려면 분류 자 작성 모듈에서 요청하는 형식으로 데이터를 준비해야합니다. 데이터를 준비합니다.One Hot Encoding.
데이터 인코딩
데이터 인코딩이 의미하는 바에 대해 간단히 설명하겠습니다. 먼저 코드를 실행 해 보겠습니다. 코드 창에서 다음 명령을 실행하십시오.
In [10]: # creating one hot encoding of the categorical columns.
data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])주석이 말했듯이 위의 문은 데이터의 핫 인코딩을 생성합니다. 그것이 무엇을 만들어 냈는지 봅시다. 라는 생성 된 데이터를 검사합니다.“data” 데이터베이스의 헤드 레코드를 인쇄하여.
In [11]: data.head()다음 출력이 표시됩니다.
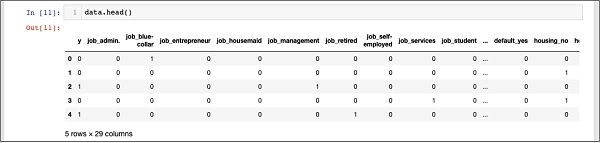
위의 데이터를 이해하기 위해 다음을 실행하여 열 이름을 나열합니다. data.columns 아래와 같이 명령-
In [12]: data.columns
Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'job_unknown', 'marital_divorced', 'marital_married', 'marital_single',
'marital_unknown', 'default_no', 'default_unknown', 'default_yes',
'housing_no', 'housing_unknown', 'housing_yes', 'loan_no',
'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent',
'poutcome_success'], dtype='object')이제 하나의 핫 인코딩이 get_dummies명령. 새로 생성 된 데이터베이스의 첫 번째 열은이 클라이언트가 TD에 가입했는지 여부를 나타내는 "y"필드입니다. 이제 인코딩 된 열을 살펴 보겠습니다. 인코딩 된 첫 번째 열은“job”. 데이터베이스에서 "job"열에는 "admin", "blue-collar", "entrepreneur"등과 같은 많은 가능한 값이 있습니다. 가능한 각 값에 대해 데이터베이스에 열 이름이 접두사로 추가 된 새 열이 생성됩니다.
따라서 "job_admin", "job_blue-collar"등의 열이 있습니다. 원래 데이터베이스의 인코딩 된 각 필드에 대해 생성 된 데이터베이스에 추가 된 열 목록과 해당 열이 원래 데이터베이스에서 가져 오는 가능한 모든 값을 찾을 수 있습니다. 데이터가 새 데이터베이스에 매핑되는 방식을 이해하려면 열 목록을주의 깊게 검토하십시오.
데이터 매핑 이해
생성 된 데이터를 이해하기 위해 data 명령을 사용하여 전체 데이터를 인쇄 해 보겠습니다. 명령을 실행 한 후의 일부 출력은 다음과 같습니다.
In [13]: data
위 화면은 처음 12 개 행을 보여줍니다. 더 아래로 스크롤하면 모든 행에 대해 매핑이 완료된 것을 볼 수 있습니다.
빠른 참조를 위해 데이터베이스 아래에있는 부분 화면 출력이 여기에 표시됩니다.
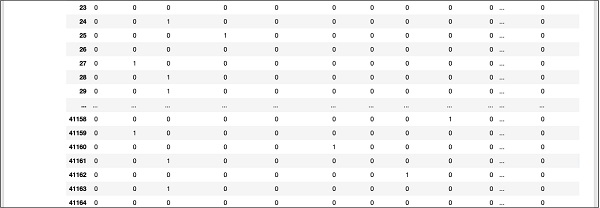
매핑 된 데이터를 이해하기 위해 첫 번째 행을 살펴 보겠습니다.

이 고객은 "y"필드의 값으로 표시된대로 TD를 구독하지 않았다고합니다. 또한이 고객이 "생산직"고객임을 나타냅니다. 수평으로 아래로 스크롤하면 그가 "주택"이 있고 "대출"을받지 않았 음을 알려줍니다.
이 핫 인코딩 후 모델 구축을 시작하기 전에 데이터 처리가 더 필요합니다.
"알 수 없음"삭제
매핑 된 데이터베이스의 열을 살펴보면 "unknown"으로 끝나는 열이 거의 없음을 알 수 있습니다. 예를 들어, 스크린 샷에 표시된 다음 명령을 사용하여 인덱스 12의 열을 검사합니다.
In [14]: data.columns[12]
Out[14]: 'job_unknown'이는 지정된 고객의 작업을 알 수 없음을 나타냅니다. 분명히 우리의 분석 및 모델 구축에 이러한 열을 포함하는 것은 의미가 없습니다. 따라서 "알 수없는"값을 가진 모든 열을 삭제해야합니다. 이것은 다음 명령으로 수행됩니다-
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)올바른 열 번호를 지정했는지 확인하십시오. 의심스러운 경우에는 앞에서 설명한대로 columns 명령에 색인을 지정하여 언제든지 열 이름을 검사 할 수 있습니다.
원하지 않는 열을 삭제 한 후 아래 출력과 같이 최종 열 목록을 검토 할 수 있습니다.
In [16]: data.columns
Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'marital_divorced', 'marital_married', 'marital_single', 'default_no',
'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes',
'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'],
dtype='object')이 시점에서 데이터는 모델 구축을위한 준비가되었습니다.