Lucene-퀵 가이드
Lucene은 간단하면서도 강력한 Java 기반 Search도서관. 모든 애플리케이션에서 검색 기능을 추가하는 데 사용할 수 있습니다. Lucene은 오픈 소스 프로젝트입니다. 확장 가능합니다. 이 고성능 라이브러리는 거의 모든 종류의 텍스트를 색인화하고 검색하는 데 사용됩니다. Lucene 라이브러리는 모든 검색 애플리케이션에 필요한 핵심 작업을 제공합니다. 인덱싱 및 검색.
검색 애플리케이션은 어떻게 작동합니까?
검색 애플리케이션은 다음 작업의 전부 또는 일부를 수행합니다.
| 단계 | 표제 | 기술 |
|---|---|---|
| 1 | Acquire Raw Content |
검색 응용 프로그램의 첫 번째 단계는 검색 응용 프로그램이 수행 될 대상 콘텐츠를 수집하는 것입니다. |
| 2 | Build the document |
다음 단계는 검색 애플리케이션이 쉽게 이해하고 해석 할 수있는 원시 컨텐츠에서 문서를 작성하는 것입니다. |
| 삼 | Analyze the document |
색인화 프로세스가 시작되기 전에 문서의 어느 부분이 색인화 될 후보인지 분석해야합니다. 이 프로세스는 문서가 분석되는 곳입니다. |
| 4 | Indexing the document |
문서가 작성되고 분석되면 다음 단계는 문서의 전체 내용 대신 특정 키를 기반으로이 문서를 검색 할 수 있도록 문서를 색인화하는 것입니다. 색인화 프로세스는 페이지 번호와 함께 공통 단어가 표시되는 책 끝에있는 색인과 유사하므로 전체 책을 검색하는 대신 이러한 단어를 빠르게 추적 할 수 있습니다. |
| 5 | User Interface for Search |
색인 데이터베이스가 준비되면 애플리케이션은 모든 검색을 수행 할 수 있습니다. 사용자가 쉽게 검색 할 수 있도록 애플리케이션은 사용자를 제공해야합니다.a mean 또는 a user interface 사용자가 텍스트를 입력하고 검색 프로세스를 시작할 수 있습니다. |
| 6 | Build Query |
사용자가 텍스트 검색을 요청하면 애플리케이션은 관련 세부 정보를 얻기 위해 인덱스 데이터베이스를 조회하는 데 사용할 수있는 해당 텍스트를 사용하여 Query 객체를 준비해야합니다. |
| 7 | Search Query |
그런 다음 쿼리 개체를 사용하여 인덱스 데이터베이스를 검사하여 관련 세부 정보와 콘텐츠 문서를 가져옵니다. |
| 8 | Render Results |
결과가 수신되면 애플리케이션은 사용자 인터페이스를 사용하여 결과를 사용자에게 표시하는 방법을 결정해야합니다. 첫눈에 얼마나 많은 정보가 표시되는지 등. |
이러한 기본 작업 외에도 검색 응용 프로그램은 administration user interface애플리케이션 관리자가 사용자 프로필을 기반으로 검색 수준을 제어 할 수 있도록 도와줍니다. 검색 결과 분석은 모든 검색 응용 프로그램의 또 다른 중요하고 고급 기능입니다.
검색 애플리케이션에서 Lucene의 역할
Lucene은 위에서 언급 한 2 ~ 7 단계에서 역할을 수행하고 필요한 작업을 수행하는 클래스를 제공합니다. 간단히 말해서 Lucene은 모든 검색 애플리케이션의 핵심이며 인덱싱 및 검색과 관련된 중요한 작업을 제공합니다. 컨텐츠를 획득하고 결과를 표시하는 것은 애플리케이션 파트가 처리하도록 남겨 둡니다.
다음 장에서는 Lucene 검색 라이브러리를 사용하여 간단한 검색 애플리케이션을 수행합니다.
이 튜토리얼은 Spring Framework로 작업을 시작하기 위해 개발 환경을 준비하는 방법을 안내합니다. 이 튜토리얼은 또한 Spring Framework를 설정하기 전에 컴퓨터에서 JDK, Tomcat 및 Eclipse를 설정하는 방법을 알려줍니다.
1 단계-JDK (Java Development Kit) 설정
Oracle Java 사이트 : Java SE Downloads 에서 최신 버전의 SDK를 다운로드 할 수 있습니다 . 다운로드 한 파일에서 JDK 설치 지침을 찾을 수 있습니다. 주어진 지침에 따라 설정을 설치하고 구성하십시오. 마지막으로 Java 및 javac (일반적으로 각각 java_install_dir / bin 및 java_install_dir)가 포함 된 디렉토리를 참조하도록 PATH 및 JAVA_HOME 환경 변수를 설정하십시오.
Windows를 실행 중이고 C : \ jdk1.6.0_15에 JDK를 설치 한 경우 C : \ autoexec.bat 파일에 다음 행을 입력해야합니다.
set PATH = C:\jdk1.6.0_15\bin;%PATH%
set JAVA_HOME = C:\jdk1.6.0_15또는 Windows NT / 2000 / XP에서 마우스 오른쪽 버튼으로 클릭 할 수도 있습니다. My Computer, 고르다 Properties, 다음 Advanced, 다음 Environment Variables. 그런 다음PATH 값을 누르고 OK 단추.
Unix (Solaris, Linux 등)에서 SDK가 /usr/local/jdk1.6.0_15에 설치되어 있고 C 셸을 사용하는 경우 .cshrc 파일에 다음을 넣습니다.
setenv PATH /usr/local/jdk1.6.0_15/bin:$PATH
setenv JAVA_HOME /usr/local/jdk1.6.0_15또는 Integrated Development Environment (IDE) Borland JBuilder, Eclipse, IntelliJ IDEA 또는 Sun ONE Studio와 같은 간단한 프로그램을 컴파일하고 실행하여 IDE가 Java를 설치 한 위치를 알고 있는지 확인하고 그렇지 않으면 IDE 문서에 제공된대로 적절한 설정을 수행합니다.
2 단계-Eclipse IDE 설정
이 튜토리얼의 모든 예제는 Eclipse IDE. 따라서 컴퓨터에 최신 버전의 Eclipse가 설치되어 있어야합니다.
Eclipse IDE를 설치하려면 다음에서 최신 Eclipse 바이너리를 다운로드하십시오. https://www.eclipse.org/downloads/. 설치를 다운로드 한 후 편리한 위치에 바이너리 배포판의 압축을 풉니 다. 예를 들어C:\eclipse on windows, 또는 /usr/local/eclipse on Linux/Unix 마지막으로 PATH 변수를 적절하게 설정하십시오.
Eclipse는 Windows 시스템에서 다음 명령을 실행하여 시작하거나 간단히 두 번 클릭 할 수 있습니다. eclipse.exe
%C:\eclipse\eclipse.exeEclipse는 Unix (Solaris, Linux 등) 시스템에서 다음 명령을 실행하여 시작할 수 있습니다.
$/usr/local/eclipse/eclipse성공적으로 시작하면 다음 결과가 표시됩니다.
3 단계-Lucene 프레임 워크 라이브러리 설정
시작에 성공하면 Lucene 프레임 워크 설정을 진행할 수 있습니다. 다음은 시스템에 프레임 워크를 다운로드하고 설치하는 간단한 단계입니다.
https://archive.apache.org/dist/lucene/java/3.6.2/
Lucene을 Windows 또는 Unix에 설치할 것인지 선택한 후 다음 단계로 진행하여 Windows 용 .zip 파일과 Unix 용 .tz 파일을 다운로드하십시오.
Lucene 프레임 워크 바이너리의 적합한 버전을 다음에서 다운로드하십시오. https://archive.apache.org/dist/lucene/java/.
이 튜토리얼을 작성할 때 Windows 시스템에 lucene-3.6.2.zip을 다운로드했으며 다운로드 한 파일의 압축을 풀면 다음과 같이 C : \ lucene-3.6.2 내부의 디렉토리 구조가 제공됩니다.
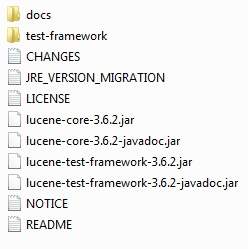
디렉토리에서 모든 Lucene 라이브러리를 찾을 수 있습니다. C:\lucene-3.6.2. 이 디렉토리에서 CLASSPATH 변수를 올바르게 설정했는지 확인하십시오. 그렇지 않으면 응용 프로그램을 실행하는 동안 문제가 발생합니다. Eclipse를 사용하는 경우 모든 설정이 Eclipse를 통해 수행되므로 CLASSPATH를 설정할 필요가 없습니다.
이 마지막 단계를 마치면 다음 장에서 보게 될 첫 번째 Lucene 예제를 진행할 준비가 된 것입니다.
이 장에서는 Lucene 프레임 워크를 사용한 실제 프로그래밍을 배웁니다. Lucene 프레임 워크를 사용하여 첫 번째 예제를 작성하기 전에 Lucene-환경 설정 학습서에 설명 된대로 Lucene 환경을 올바르게 설정했는지 확인해야합니다 . Eclipse IDE에 대한 작업 지식이있는 것이 좋습니다.
이제 발견 된 검색 결과 수를 인쇄하는 간단한 검색 응용 프로그램을 작성하여 진행하겠습니다. 이 프로세스 중에 생성 된 인덱스 목록도 볼 수 있습니다.
1 단계-Java 프로젝트 생성
첫 번째 단계는 Eclipse IDE를 사용하여 간단한 Java 프로젝트를 만드는 것입니다. 옵션을 따르십시오File > New -> Project 마지막으로 선택 Java Project마법사 목록에서 마법사. 이제 프로젝트 이름을LuceneFirstApplication 다음과 같이 마법사 창을 사용하여-
프로젝트가 성공적으로 생성되면 다음 콘텐츠가 Project Explorer −
2 단계-필요한 라이브러리 추가
이제 프로젝트에 Lucene 핵심 프레임 워크 라이브러리를 추가하겠습니다. 이렇게하려면 프로젝트 이름을 마우스 오른쪽 버튼으로 클릭하십시오.LuceneFirstApplication 그런 다음 상황에 맞는 메뉴에서 사용할 수있는 다음 옵션을 따릅니다. Build Path -> Configure Build Path 다음과 같이 Java 빌드 경로 창을 표시하려면-

이제 사용 Add External JARs 아래에서 사용할 수있는 버튼 Libraries Lucene 설치 디렉토리에서 다음 핵심 JAR을 추가하려면 탭-
- lucene-core-3.6.2
3 단계-소스 파일 생성
이제 실제 소스 파일을 LuceneFirstApplication계획. 먼저 다음과 같은 패키지를 생성해야합니다.com.tutorialspoint.lucene. 이렇게하려면 패키지 탐색기 섹션에서 src를 마우스 오른쪽 버튼으로 클릭하고 옵션을 따르십시오. New -> Package.
다음으로 우리는 LuceneTester.java 및 기타 Java 클래스 com.tutorialspoint.lucene 꾸러미.
LuceneConstants.java
이 클래스는 샘플 애플리케이션에서 사용할 다양한 상수를 제공하는 데 사용됩니다.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}TextFileFilter.java
이 클래스는 .txt file 필터.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}Indexer.java
이 클래스는 Lucene 라이브러리를 사용하여 검색 할 수 있도록 원시 데이터를 색인화하는 데 사용됩니다.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}Searcher.java
이 클래스는 요청 된 콘텐츠를 검색하기 위해 인덱서에서 만든 인덱스를 검색하는 데 사용됩니다.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}LuceneTester.java
이 클래스는 lucene 라이브러리의 인덱싱 및 검색 기능을 테스트하는 데 사용됩니다.
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime));
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "
+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}4 단계-데이터 및 색인 디렉토리 생성
우리는 record1.txt에서 10 개의 텍스트 파일을 사용하여 학생의 이름과 기타 세부 정보를 포함하는 record10.txt를 디렉터리에 넣었습니다. E:\Lucene\Data. 테스트 데이터 . 인덱스 디렉토리 경로는 다음과 같이 생성되어야합니다.E:\Lucene\Index. 이 프로그램을 실행하면 해당 폴더에 생성 된 인덱스 파일 목록을 볼 수 있습니다.
5 단계-프로그램 실행
소스, 원시 데이터, 데이터 디렉토리 및 색인 디렉토리 작성이 완료되면 프로그램을 컴파일하고 실행할 준비가 된 것입니다. 이렇게하려면LuceneTester.Java 파일 탭이 활성화되어 있고 Run Eclipse IDE에서 사용 가능한 옵션 또는 Ctrl + F11 컴파일하고 실행하려면 LuceneTester신청. 응용 프로그램이 성공적으로 실행되면 Eclipse IDE의 콘솔에 다음 메시지가 인쇄됩니다.
Indexing E:\Lucene\Data\record1.txt
Indexing E:\Lucene\Data\record10.txt
Indexing E:\Lucene\Data\record2.txt
Indexing E:\Lucene\Data\record3.txt
Indexing E:\Lucene\Data\record4.txt
Indexing E:\Lucene\Data\record5.txt
Indexing E:\Lucene\Data\record6.txt
Indexing E:\Lucene\Data\record7.txt
Indexing E:\Lucene\Data\record8.txt
Indexing E:\Lucene\Data\record9.txt
10 File indexed, time taken: 109 ms
1 documents found. Time :0
File: E:\Lucene\Data\record4.txt프로그램을 성공적으로 실행하면 다음 내용이 index directory −
인덱싱 프로세스는 Lucene에서 제공하는 핵심 기능 중 하나입니다. 다음 다이어그램은 인덱싱 프로세스와 클래스 사용을 보여줍니다.IndexWriter 인덱싱 프로세스의 가장 중요하고 핵심 구성 요소입니다.
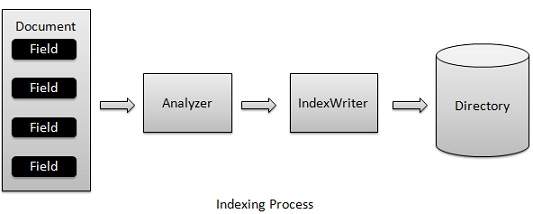
우리는 추가 Document(s) 포함 Field(s) 분석하는 IndexWriter에 Document(s) 사용하여 Analyzer 그런 다음 필요에 따라 색인을 생성 / 열기 / 편집하고 Directory. IndexWriter는 인덱스를 업데이트하거나 생성하는 데 사용됩니다. 인덱스를 읽는 데 사용되지 않습니다.
인덱싱 클래스
다음은 인덱싱 프로세스 중에 일반적으로 사용되는 클래스 목록입니다.
| S. 아니. | 클래스 및 설명 |
|---|---|
| 1 | IndexWriter 이 클래스는 인덱싱 프로세스 중에 인덱스를 생성 / 업데이트하는 핵심 구성 요소 역할을합니다. |
| 2 | 예배 규칙서 이 클래스는 인덱스의 저장 위치를 나타냅니다. |
| 삼 | 분석기 이 클래스는 문서를 분석하고 인덱싱 할 텍스트에서 토큰 / 단어를 가져옵니다. 분석이 완료되지 않으면 IndexWriter는 인덱스를 생성 할 수 없습니다. |
| 4 | 문서 이 클래스는 필드가있는 가상 문서를 나타냅니다. 여기서 Field는 실제 문서의 내용, 메타 데이터 등을 포함 할 수있는 객체입니다. 분석기는 문서 만 이해할 수 있습니다. |
| 5 | 들 이것은 인덱싱 프로세스의 가장 낮은 단위 또는 시작점입니다. 인덱싱 할 값을 식별하는 데 키가 사용되는 키 값 쌍 관계를 나타냅니다. 문서의 내용을 나타내는 데 사용되는 필드에 "내용"과 같은 키가 있고 값에 문서의 텍스트 또는 숫자 내용의 일부 또는 전체가 포함될 수 있다고 가정 해 보겠습니다. Lucene은 텍스트 또는 숫자 컨텐츠 만 색인화 할 수 있습니다. |
검색 프로세스는 다시 Lucene에서 제공하는 핵심 기능 중 하나입니다. 그 흐름은 인덱싱 프로세스의 흐름과 유사합니다. Lucene의 기본 검색은 모든 검색 관련 작업에 대한 기초 클래스라고도 할 수있는 다음 클래스를 사용하여 수행 할 수 있습니다.
수업 검색
다음은 검색 과정에서 일반적으로 사용되는 클래스 목록입니다.
| S. 아니. | 클래스 및 설명 |
|---|---|
| 1 | IndexSearcher 이 클래스는 인덱싱 프로세스 후에 생성 된 인덱스를 읽고 검색하는 핵심 구성 요소 역할을합니다. 색인이 포함 된 위치를 가리키는 디렉토리 인스턴스를 사용합니다. |
| 2 | 기간 이 클래스는 검색의 가장 낮은 단위입니다. 인덱싱 프로세스의 필드와 유사합니다. |
| 삼 | 질문 Query는 추상 클래스이며 다양한 유틸리티 메소드를 포함하며 Lucene이 검색 프로세스 중에 사용하는 모든 유형의 쿼리의 상위입니다. |
| 4 | TermQuery TermQuery는 가장 일반적으로 사용되는 쿼리 개체이며 Lucene이 사용할 수있는 많은 복잡한 쿼리의 기반입니다. |
| 5 | TopDocs TopDocs는 검색 기준과 일치하는 상위 N 개의 검색 결과를 가리 킵니다. 검색 결과의 출력 인 문서를 가리키는 포인터의 간단한 컨테이너입니다. |
인덱싱 프로세스는 Lucene에서 제공하는 핵심 기능 중 하나입니다. 다음 다이어그램은 인덱싱 프로세스와 클래스 사용을 보여줍니다. IndexWriter는 인덱싱 프로세스에서 가장 중요하고 핵심적인 구성 요소입니다.
Analyzer를 사용하여 문서를 분석 한 다음 필요에 따라 색인 을 생성 / 열기 / 편집 하고 디렉토리 에 저장 / 업데이트하는 IndexWriter에 Field (s) 가 포함 된 문서를 추가 합니다 . IndexWriter 는 인덱스를 업데이트하거나 생성하는 데 사용됩니다. 인덱스를 읽는 데 사용되지 않습니다.
이제 기본 예제를 사용하여 인덱싱 프로세스를 이해하는 데 도움이되는 단계별 프로세스를 보여 드리겠습니다.
문서 작성
텍스트 파일에서 lucene 문서를 가져 오는 메서드를 만듭니다.
색인화 할 내용으로 이름과 값을 포함하는 키 값 쌍인 다양한 유형의 필드를 작성하십시오.
분석 할 필드를 설정합니다. 우리의 경우 검색 작업에 필요하지 않은 a, am, are, 등의 데이터를 포함 할 수 있으므로 콘텐츠 만 분석합니다.
새로 만든 필드를 문서 개체에 추가하고 호출자 메서드에 반환합니다.
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}IndexWriter 만들기
IndexWriter 클래스는 인덱싱 프로세스 중에 인덱스를 생성 / 업데이트하는 핵심 구성 요소 역할을합니다. IndexWriter를 생성하려면 다음 단계를 따르십시오-
Step 1 − IndexWriter의 개체를 생성합니다.
Step 2 − 색인이 저장 될 위치를 가리켜 야하는 Lucene 디렉토리를 만듭니다.
Step 3 − 버전 정보 및 기타 필수 / 선택적 매개 변수가있는 표준 분석기 인 색인 디렉토리로 생성 된 IndexWriter 개체를 초기화합니다.
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}인덱싱 프로세스 시작
다음 프로그램은 인덱싱 프로세스를 시작하는 방법을 보여줍니다-
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}예제 애플리케이션
인덱싱 프로세스를 테스트하려면 Lucene 애플리케이션 테스트를 만들어야합니다.
| 단계 | 기술 |
|---|---|
| 1 | Lucene-First Application 장에 설명 된대로 com.tutorialspoint.lucene 패키지 아래에 LuceneFirstApplication 이라는 이름으로 프로젝트를 작성하십시오 . 인덱싱 프로세스를 이해하기 위해 Lucene-첫 번째 애플리케이션 장 에서 작성된 프로젝트를 사용할 수도 있습니다 . |
| 2 | 만들기 LuceneConstants.java, TextFileFilter.java 및 Indexer.java 에 설명 된대로 첫 번째 응용 프로그램 - 루씬 장. 나머지 파일은 변경하지 마십시오. |
| 삼 | 아래 언급 된대로 LuceneTester.java 를 작성하십시오 . |
| 4 | 애플리케이션을 정리하고 빌드하여 비즈니스 로직이 요구 사항에 따라 작동하는지 확인하십시오. |
LuceneConstants.java
이 클래스는 샘플 애플리케이션에서 사용할 다양한 상수를 제공하는 데 사용됩니다.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}TextFileFilter.java
이 클래스는 .txt 파일 필터.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}Indexer.java
이 클래스는 Lucene 라이브러리를 사용하여 검색 할 수 있도록 원시 데이터를 색인화하는 데 사용됩니다.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}LuceneTester.java
이 클래스는 Lucene 라이브러리의 인덱싱 기능을 테스트하는 데 사용됩니다.
package com.tutorialspoint.lucene;
import java.io.IOException;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
} catch (IOException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
}데이터 및 인덱스 디렉토리 생성
우리는 record1.txt에서 10 개의 텍스트 파일을 사용하여 학생의 이름과 기타 세부 정보를 포함하는 record10.txt를 디렉터리에 넣었습니다. E:\Lucene\Data. 테스트 데이터 . 인덱스 디렉토리 경로는 다음과 같이 생성되어야합니다.E:\Lucene\Index. 이 프로그램을 실행하면 해당 폴더에 생성 된 인덱스 파일 목록을 볼 수 있습니다.
프로그램 실행
소스, 원시 데이터, 데이터 디렉토리 및 색인 디렉토리 작성이 완료되면 프로그램을 컴파일하고 실행하여 진행할 수 있습니다. 이를 수행하려면 LuceneTester.Java 파일 탭을 활성 상태로 유지하고Run Eclipse IDE에서 사용 가능한 옵션 또는 Ctrl + F11 컴파일하고 실행하려면 LuceneTester신청. 응용 프로그램이 성공적으로 실행되면 Eclipse IDE의 콘솔에 다음 메시지가 인쇄됩니다.
Indexing E:\Lucene\Data\record1.txt
Indexing E:\Lucene\Data\record10.txt
Indexing E:\Lucene\Data\record2.txt
Indexing E:\Lucene\Data\record3.txt
Indexing E:\Lucene\Data\record4.txt
Indexing E:\Lucene\Data\record5.txt
Indexing E:\Lucene\Data\record6.txt
Indexing E:\Lucene\Data\record7.txt
Indexing E:\Lucene\Data\record8.txt
Indexing E:\Lucene\Data\record9.txt
10 File indexed, time taken: 109 ms프로그램을 성공적으로 실행하면 다음 내용이 index directory −
이 장에서는 인덱싱의 네 가지 주요 작업에 대해 설명합니다. 이러한 작업은 다양한 시간에 유용하며 소프트웨어 검색 응용 프로그램 전체에서 사용됩니다.
인덱싱 작업
다음은 인덱싱 프로세스 중에 일반적으로 사용되는 작업 목록입니다.
| S. 아니. | 작동 및 설명 |
|---|---|
| 1 | 문서 추가 이 작업은 인덱싱 프로세스의 초기 단계에서 새로 사용 가능한 콘텐츠에 대한 인덱스를 만드는 데 사용됩니다. |
| 2 | 문서 업데이트 이 작업은 업데이트 된 내용의 변경 사항을 반영하기 위해 인덱스를 업데이트하는 데 사용됩니다. 인덱스를 다시 만드는 것과 비슷합니다. |
| 삼 | 문서 삭제 이 작업은 색인화 / 검색 할 필요가없는 문서를 제외하도록 색인을 업데이트하는 데 사용됩니다. |
| 4 | 필드 옵션 필드 옵션은 필드의 내용을 검색 할 수있는 방법을 지정하거나 제어합니다. |
검색 프로세스는 Lucene에서 제공하는 핵심 기능 중 하나입니다. 다음 다이어그램은 프로세스와 그 사용을 보여줍니다. IndexSearcher는 검색 프로세스의 핵심 구성 요소 중 하나입니다.
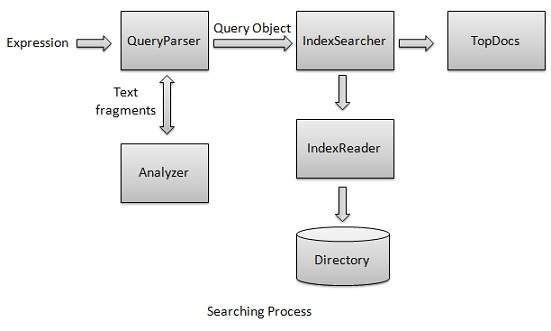
먼저 인덱스를 포함하는 Directory (s) 를 만든 다음 IndexReader를 사용 하여 Directory 를 여는 IndexSearcher에 전달합니다 . 그런 다음 용어 로 쿼리 를 만들고 쿼리 를 검색 자에게 전달 하여 IndexSearcher 를 사용 하여 검색합니다. IndexSearcher 는 검색 작업의 결과 인 문서 의 문서 ID와 함께 검색 세부 정보를 포함 하는 TopDocs 개체를 반환 합니다.
이제 단계별 접근 방식을 보여주고 기본 예제를 사용하여 인덱싱 프로세스를 이해하는 데 도움이됩니다.
QueryParser 만들기
QueryParser 클래스는 Lucene이 이해할 수있는 형식 쿼리에 사용자가 입력 한 입력을 구문 분석합니다. QueryParser를 생성하려면 다음 단계를 따르십시오-
Step 1 − QueryParser의 객체를 생성합니다.
Step 2 −이 쿼리가 실행될 버전 정보와 인덱스 이름이있는 표준 분석기로 생성 된 QueryParser 객체를 초기화합니다.
QueryParser queryParser;
public Searcher(String indexDirectoryPath) throws IOException {
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}IndexSearcher 만들기
IndexSearcher 클래스는 인덱싱 프로세스 중에 생성되는 검색자가 인덱싱하는 핵심 구성 요소 역할을합니다. IndexSearcher를 생성하려면 다음 단계를 따르십시오-
Step 1 − IndexSearcher의 객체를 생성합니다.
Step 2 − 색인이 저장 될 위치를 가리켜 야하는 Lucene 디렉토리를 만듭니다.
Step 3 − 인덱스 디렉토리로 생성 된 IndexSearcher 객체를 초기화합니다.
IndexSearcher indexSearcher;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
}검색하기
검색하려면 다음 단계를 따르십시오-
Step 1 − QueryParser를 통해 검색 표현식을 구문 분석하여 Query 객체를 생성합니다.
Step 2 − IndexSearcher.search () 메서드를 호출하여 검색합니다.
Query query;
public TopDocs search( String searchQuery) throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}문서 받기
다음 프로그램은 문서를 얻는 방법을 보여줍니다.
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}IndexSearcher 닫기
다음 프로그램은 IndexSearcher를 닫는 방법을 보여줍니다.
public void close() throws IOException {
indexSearcher.close();
}예제 애플리케이션
검색 프로세스를 테스트하기 위해 테스트 Lucene 애플리케이션을 작성하겠습니다.
| 단계 | 기술 |
|---|---|
| 1 | Lucene-First Application 장에 설명 된대로 com.tutorialspoint.lucene 패키지 아래에 이름이 LuceneFirstApplication 인 프로젝트를 작성하십시오 . 또한 Lucene-First Application 장 에서 만든 프로젝트 를이 장에서 검색 프로세스를 이해하는 데 사용할 수 있습니다 . |
| 2 | Lucene- 첫 번째 애플리케이션 장에 설명 된대로 LuceneConstants.java, TextFileFilter.java 및 Searcher.java 를 작성하십시오 . 나머지 파일은 변경하지 마십시오. |
| 삼 | 아래 언급 된대로 LuceneTester.java 를 작성하십시오 . |
| 4 | 애플리케이션을 정리하고 빌드하여 비즈니스 논리가 요구 사항에 따라 작동하는지 확인합니다. |
LuceneConstants.java
이 클래스는 샘플 애플리케이션에서 사용할 다양한 상수를 제공하는 데 사용됩니다.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}TextFileFilter.java
이 클래스는 .txt 파일 필터.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}Searcher.java
이 클래스는 원시 데이터에 작성된 색인을 읽고 Lucene 라이브러리를 사용하여 데이터를 검색하는 데 사용됩니다.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}LuceneTester.java
이 클래스는 Lucene 라이브러리의 검색 기능을 테스트하는 데 사용됩니다.
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) +" ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}데이터 및 인덱스 디렉토리 생성
우리는 학생의 이름과 기타 세부 사항을 포함하는 record10.txt에 record1.txt라는 10 개의 텍스트 파일을 사용하여 E : \ Lucene \ Data 디렉토리에 넣었습니다. 테스트 데이터 . 색인 디렉토리 경로는 E : \ Lucene \ Index로 작성되어야합니다. 장의 인덱싱 프로그램을 실행 한 후Lucene - Indexing Process, 해당 폴더에 생성 된 색인 파일 목록을 볼 수 있습니다.
프로그램 실행
소스, 원시 데이터, 데이터 디렉토리, 색인 디렉토리 및 색인 작성이 완료되면 프로그램을 컴파일하고 실행하여 진행할 수 있습니다. 이렇게하려면 계속LuceneTester.Java 파일 탭을 활성화하고 Eclipse IDE에서 사용 가능한 실행 옵션을 사용하거나 Ctrl + F11 컴파일하고 실행하려면 LuceneTesterapplication. 응용 프로그램이 성공적으로 실행되면 Eclipse IDE의 콘솔에 다음 메시지가 인쇄됩니다.
1 documents found. Time :29 ms
File: E:\Lucene\Data\record4.txt우리는 이전 장에서 보았습니다 Lucene - Search Operation, Lucene은 IndexSearcher를 사용하여 검색을하고 QueryParser에서 생성 한 Query 객체를 입력으로 사용합니다. 이 장에서는 다양한 유형의 Query 객체와이를 프로그래밍 방식으로 생성하는 다양한 방법에 대해 설명합니다. 다양한 유형의 Query 객체를 생성하면 검색 유형을 제어 할 수 있습니다.
사용자에게 검색 결과를 제한하는 여러 옵션이 제공되는 많은 애플리케이션에서 제공하는 고급 검색의 경우를 고려하십시오. 쿼리 프로그래밍을 통해 우리는 매우 쉽게 동일한 결과를 얻을 수 있습니다.
다음은 당분간 논의 할 쿼리 유형 목록입니다.
| S. 아니. | 클래스 및 설명 |
|---|---|
| 1 | TermQuery 이 클래스는 인덱싱 프로세스 중에 인덱스를 생성 / 업데이트하는 핵심 구성 요소 역할을합니다. |
| 2 | TermRangeQuery TermRangeQuery는 텍스트 용어 범위를 검색 할 때 사용됩니다. |
| 삼 | PrefixQuery PrefixQuery는 색인이 지정된 문자열로 시작하는 문서를 일치시키는 데 사용됩니다. |
| 4 | BooleanQuery BooleanQuery는 다음을 사용하여 여러 쿼리의 결과 인 문서를 검색하는 데 사용됩니다. AND, OR 또는 NOT 연산자. |
| 5 | PhraseQuery 구문 쿼리는 특정 용어 시퀀스가 포함 된 문서를 검색하는 데 사용됩니다. |
| 6 | WildCardQuery WildcardQuery는 문자 시퀀스에 대해 '*'와 같은 와일드 카드를 사용하여 문서를 검색하는 데 사용됩니다. 단일 문자와 일치합니다. |
| 7 | FuzzyQuery FuzzyQuery는 편집 거리 알고리즘을 기반으로하는 대략적인 검색 인 퍼지 구현을 사용하여 문서를 검색하는 데 사용됩니다. |
| 8 | MatchAllDocsQuery 이름에서 알 수 있듯이 MatchAllDocsQuery는 모든 문서와 일치합니다. |
이전 장 중 하나에서 Lucene이 IndexWriter 를 사용하여 Analyzer를 사용하여 문서 를 분석 한 다음 필요에 따라 색인을 생성 / 열기 / 편집 하는 것을 보았습니다 . 이 장에서는 분석 과정에서 사용되는 다양한 유형의 Analyzer 개체 및 기타 관련 개체에 대해 설명합니다. 분석 프로세스와 분석기 작동 방식을 이해하면 Lucene이 문서를 인덱싱하는 방법에 대한 훌륭한 통찰력을 얻을 수 있습니다.
다음은 당연히 논의 할 개체 목록입니다.
| S. 아니. | 클래스 및 설명 |
|---|---|
| 1 | 토큰 토큰은 메타 데이터 (위치, 시작 오프셋, 끝 오프셋, 토큰 유형 및 위치 증분)와 같은 관련 세부 정보가있는 문서의 텍스트 또는 단어를 나타냅니다. |
| 2 | TokenStream TokenStream은 분석 프로세스의 출력이며 일련의 토큰으로 구성됩니다. 추상 클래스입니다. |
| 삼 | 분석기 이것은 모든 유형의 Analyzer에 대한 추상 기본 클래스입니다. |
| 4 | 공백 분석기 이 분석기는 공백을 기준으로 문서의 텍스트를 분할합니다. |
| 5 | SimpleAnalyzer 이 분석기는 문자가 아닌 문자를 기반으로 문서의 텍스트를 분할하고 텍스트를 소문자로 표시합니다. |
| 6 | StopAnalyzer 이 분석기는 SimpleAnalyzer처럼 작동하며 다음과 같은 일반적인 단어를 제거합니다. 'a', 'an', 'the', 기타 |
| 7 | StandardAnalyzer 이것은 가장 정교한 분석기이며 이름, 이메일 주소 등을 처리 할 수 있습니다. 각 토큰을 소문자로하고 일반적인 단어와 구두점 (있는 경우)을 제거합니다. |
이 장에서는 Lucene이 기본적으로 검색 결과를 제공하거나 필요에 따라 조작 할 수있는 정렬 순서를 살펴 보겠습니다.
관련성에 따라 정렬
Lucene에서 사용하는 기본 정렬 모드입니다. Lucene은 상단에서 가장 관련성이 높은 히트별로 결과를 제공합니다.
private void sortUsingRelevance(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.RELEVANCE);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}IndexOrder로 정렬
이 정렬 모드는 Lucene에서 사용됩니다. 여기에서 색인 된 첫 번째 문서가 검색 결과에 먼저 표시됩니다.
private void sortUsingIndex(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.INDEXORDER);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}예제 애플리케이션
정렬 프로세스를 테스트하기 위해 테스트 Lucene 애플리케이션을 작성하겠습니다.
| 단계 | 기술 |
|---|---|
| 1 | Lucene-First Application 장에 설명 된대로 com.tutorialspoint.lucene 패키지 아래에 이름이 LuceneFirstApplication 인 프로젝트를 작성하십시오 . 또한 Lucene-First Application 장 에서 만든 프로젝트 를이 장에서 검색 프로세스를 이해하는 데 사용할 수 있습니다 . |
| 2 | Lucene- 첫 번째 애플리케이션 장에 설명 된대로 LuceneConstants.java 및 Searcher.java 를 작성하십시오 . 나머지 파일은 변경하지 마십시오. |
| 삼 | 아래 언급 된대로 LuceneTester.java 를 작성하십시오 . |
| 4 | 응용 프로그램을 정리하고 빌드하여 비즈니스 논리가 요구 사항에 따라 작동하는지 확인합니다. |
LuceneConstants.java
이 클래스는 샘플 애플리케이션에서 사용할 다양한 상수를 제공하는 데 사용됩니다.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}Searcher.java
이 클래스는 원시 데이터에 작성된 색인을 읽고 Lucene 라이브러리를 사용하여 데이터를 검색하는 데 사용됩니다.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory
= FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query)
throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query,Sort sort)
throws IOException, ParseException {
return indexSearcher.search(query,
LuceneConstants.MAX_SEARCH,sort);
}
public void setDefaultFieldSortScoring(boolean doTrackScores,
boolean doMaxScores) {
indexSearcher.setDefaultFieldSortScoring(
doTrackScores,doMaxScores);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}LuceneTester.java
이 클래스는 Lucene 라이브러리의 검색 기능을 테스트하는 데 사용됩니다.
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.FuzzyQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.sortUsingRelevance("cord3.txt");
tester.sortUsingIndex("cord3.txt");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void sortUsingRelevance(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.RELEVANCE);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
private void sortUsingIndex(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.INDEXORDER);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}데이터 및 인덱스 디렉토리 생성
우리는 record1.txt에서 10 개의 텍스트 파일을 사용하여 학생의 이름과 기타 세부 정보를 포함하는 record10.txt를 디렉터리에 넣었습니다. E:\Lucene\Data. 테스트 데이터 . 색인 디렉토리 경로는 E : \ Lucene \ Index로 작성되어야합니다. 장의 인덱싱 프로그램을 실행 한 후Lucene - Indexing Process, 해당 폴더에 생성 된 색인 파일 목록을 볼 수 있습니다.
프로그램 실행
소스, 원시 데이터, 데이터 디렉토리, 색인 디렉토리 및 색인 작성이 완료되면 프로그램을 컴파일하고 실행할 수 있습니다. 이렇게하려면LuceneTester.Java 파일 탭을 활성화하고 Eclipse IDE에서 사용 가능한 실행 옵션을 사용하거나 Ctrl + F11 컴파일하고 실행하려면 LuceneTester신청. 응용 프로그램이 성공적으로 실행되면 Eclipse IDE의 콘솔에 다음 메시지가 인쇄됩니다.
10 documents found. Time :31ms
Score: 1.3179655 File: E:\Lucene\Data\record3.txt
Score: 0.790779 File: E:\Lucene\Data\record1.txt
Score: 0.790779 File: E:\Lucene\Data\record2.txt
Score: 0.790779 File: E:\Lucene\Data\record4.txt
Score: 0.790779 File: E:\Lucene\Data\record5.txt
Score: 0.790779 File: E:\Lucene\Data\record6.txt
Score: 0.790779 File: E:\Lucene\Data\record7.txt
Score: 0.790779 File: E:\Lucene\Data\record8.txt
Score: 0.790779 File: E:\Lucene\Data\record9.txt
Score: 0.2635932 File: E:\Lucene\Data\record10.txt
10 documents found. Time :0ms
Score: 0.790779 File: E:\Lucene\Data\record1.txt
Score: 0.2635932 File: E:\Lucene\Data\record10.txt
Score: 0.790779 File: E:\Lucene\Data\record2.txt
Score: 1.3179655 File: E:\Lucene\Data\record3.txt
Score: 0.790779 File: E:\Lucene\Data\record4.txt
Score: 0.790779 File: E:\Lucene\Data\record5.txt
Score: 0.790779 File: E:\Lucene\Data\record6.txt
Score: 0.790779 File: E:\Lucene\Data\record7.txt
Score: 0.790779 File: E:\Lucene\Data\record8.txt
Score: 0.790779 File: E:\Lucene\Data\record9.txt