Lucene-검색 작업
검색 프로세스는 Lucene에서 제공하는 핵심 기능 중 하나입니다. 다음 다이어그램은 프로세스와 그 사용을 보여줍니다. IndexSearcher는 검색 프로세스의 핵심 구성 요소 중 하나입니다.
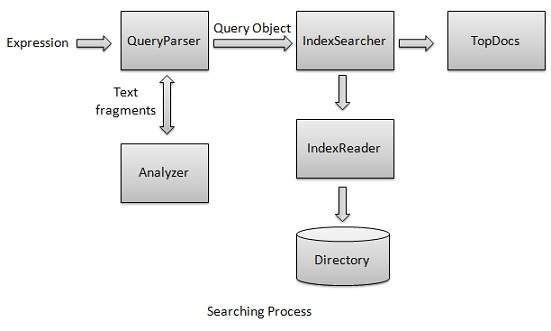
먼저 인덱스를 포함하는 Directory (s) 를 만든 다음 IndexReader를 사용 하여 Directory 를 여는 IndexSearcher에 전달합니다 . 그런 다음 용어 로 쿼리 를 만들고 쿼리 를 검색 자에게 전달 하여 IndexSearcher 를 사용 하여 검색합니다. IndexSearcher 는 검색 작업의 결과 인 문서 의 문서 ID와 함께 검색 세부 정보를 포함 하는 TopDocs 개체를 반환 합니다.
이제 단계별 접근 방식을 보여주고 기본 예제를 사용하여 인덱싱 프로세스를 이해하는 데 도움이됩니다.
QueryParser 만들기
QueryParser 클래스는 Lucene이 이해할 수있는 형식 쿼리에 사용자가 입력 한 입력을 구문 분석합니다. QueryParser를 생성하려면 다음 단계를 따르십시오-
Step 1 − QueryParser의 객체를 생성합니다.
Step 2 −이 쿼리가 실행될 버전 정보와 인덱스 이름이있는 표준 분석기로 생성 된 QueryParser 객체를 초기화합니다.
QueryParser queryParser;
public Searcher(String indexDirectoryPath) throws IOException {
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}IndexSearcher 만들기
IndexSearcher 클래스는 인덱싱 프로세스 중에 생성되는 검색자가 인덱싱하는 핵심 구성 요소 역할을합니다. IndexSearcher를 생성하려면 다음 단계를 따르십시오-
Step 1 − IndexSearcher의 객체를 생성합니다.
Step 2 − 색인이 저장 될 위치를 가리켜 야하는 Lucene 디렉토리를 만듭니다.
Step 3 − 인덱스 디렉토리로 생성 된 IndexSearcher 객체를 초기화합니다.
IndexSearcher indexSearcher;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
}검색하기
다음 단계를 따라 검색하십시오-
Step 1 − QueryParser를 통해 검색 표현식을 구문 분석하여 Query 객체를 생성합니다.
Step 2 − IndexSearcher.search () 메서드를 호출하여 검색합니다.
Query query;
public TopDocs search( String searchQuery) throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}문서 받기
다음 프로그램은 문서를 얻는 방법을 보여줍니다.
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}IndexSearcher 닫기
다음 프로그램은 IndexSearcher를 닫는 방법을 보여줍니다.
public void close() throws IOException {
indexSearcher.close();
}예제 애플리케이션
검색 프로세스를 테스트하기 위해 테스트 Lucene 애플리케이션을 작성하겠습니다.
| 단계 | 기술 |
|---|---|
| 1 | Lucene-First Application 장에 설명 된대로 com.tutorialspoint.lucene 패키지 아래에 이름이 LuceneFirstApplication 인 프로젝트를 작성하십시오 . 또한 Lucene-First Application 장 에서 만든 프로젝트 를이 장에서 검색 프로세스를 이해하는 데 사용할 수 있습니다 . |
| 2 | Lucene- 첫 번째 애플리케이션 장에 설명 된대로 LuceneConstants.java, TextFileFilter.java 및 Searcher.java 를 작성하십시오 . 나머지 파일은 변경하지 마십시오. |
| 삼 | 아래 언급 된대로 LuceneTester.java 를 작성하십시오 . |
| 4 | 응용 프로그램을 정리하고 빌드하여 비즈니스 논리가 요구 사항에 따라 작동하는지 확인합니다. |
LuceneConstants.java
이 클래스는 샘플 애플리케이션에서 사용할 다양한 상수를 제공하는 데 사용됩니다.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}TextFileFilter.java
이 클래스는 .txt 파일 필터.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}Searcher.java
이 클래스는 원시 데이터에 작성된 색인을 읽고 Lucene 라이브러리를 사용하여 데이터를 검색하는 데 사용됩니다.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}LuceneTester.java
이 클래스는 Lucene 라이브러리의 검색 기능을 테스트하는 데 사용됩니다.
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) +" ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}데이터 및 인덱스 디렉토리 생성
우리는 학생의 이름과 기타 세부 사항을 포함하는 record10.txt에 record1.txt라는 10 개의 텍스트 파일을 사용하여 E : \ Lucene \ Data 디렉토리에 넣었습니다. 테스트 데이터 . 색인 디렉토리 경로는 E : \ Lucene \ Index로 작성되어야합니다. 장의 인덱싱 프로그램을 실행 한 후Lucene - Indexing Process, 해당 폴더에 생성 된 색인 파일 목록을 볼 수 있습니다.
프로그램 실행
소스, 원시 데이터, 데이터 디렉토리, 색인 디렉토리 및 색인 작성이 완료되면 프로그램을 컴파일하고 실행하여 진행할 수 있습니다. 이렇게하려면 계속LuceneTester.Java 파일 탭을 활성화하고 Eclipse IDE에서 사용 가능한 실행 옵션을 사용하거나 Ctrl + F11 컴파일하고 실행하려면 LuceneTesterapplication. 응용 프로그램이 성공적으로 실행되면 Eclipse IDE의 콘솔에 다음 메시지가 인쇄됩니다.
1 documents found. Time :29 ms
File: E:\Lucene\Data\record4.txt