운영 체제-빠른 가이드
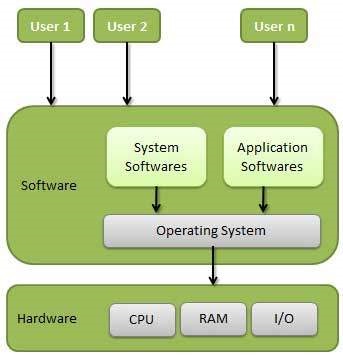
운영 체제 (OS)는 컴퓨터 사용자와 컴퓨터 하드웨어 간의 인터페이스입니다. 운영 체제는 파일 관리, 메모리 관리, 프로세스 관리, 입력 및 출력 처리, 디스크 드라이브 및 프린터와 같은 주변 장치 제어와 같은 모든 기본 작업을 수행하는 소프트웨어입니다.
널리 사용되는 운영 체제로는 Linux 운영 체제, Windows 운영 체제, VMS, OS / 400, AIX, z / OS 등이 있습니다.
정의
운영 체제는 사용자와 컴퓨터 하드웨어 간의 인터페이스 역할을하며 모든 종류의 프로그램 실행을 제어하는 프로그램입니다.
다음은 운영 체제의 몇 가지 중요한 기능입니다.
- 메모리 관리
- 프로세서 관리
- 장치 관리
- 파일 관리
- Security
- 시스템 성능 제어
- 직업 회계
- 오류 감지 보조 장치
- 다른 소프트웨어와 사용자 간의 조정
메모리 관리
메모리 관리는 기본 메모리 또는 메인 메모리의 관리를 의미합니다. 주 메모리는 각 단어 또는 바이트에 자체 주소가있는 많은 단어 또는 바이트 배열입니다.
메인 메모리는 CPU에서 직접 액세스 할 수있는 빠른 스토리지를 제공합니다. 프로그램이 실행 되려면 메인 메모리에 있어야합니다. 운영 체제는 메모리 관리를 위해 다음 활동을 수행합니다.
주 메모리의 어떤 부분을 누가 사용하고 있는지, 어떤 부분을 사용하지 않는지 추적합니다.
다중 프로그래밍에서 OS는 메모리를 언제 얼마나 많이 확보할지 결정합니다.
프로세스가 요청하면 메모리를 할당합니다.
프로세스가 더 이상 메모리를 필요로하지 않거나 종료 된 경우 메모리를 할당 해제합니다.
프로세서 관리
다중 프로그래밍 환경에서 OS는 프로세서를 언제 얼마나 많은 시간 동안 가져 오는 프로세스를 결정합니다. 이 함수는process scheduling. 운영 체제는 프로세서 관리를 위해 다음 활동을 수행합니다.
프로세서 및 프로세스 상태를 추적합니다. 이 작업을 담당하는 프로그램은traffic controller.
프로세서 (CPU)를 프로세스에 할당합니다.
프로세스가 더 이상 필요하지 않은 경우 프로세서를 할당 해제합니다.
장치 관리
운영 체제는 해당 드라이버를 통해 장치 통신을 관리합니다. 장치 관리를 위해 다음 활동을 수행합니다.
모든 장치의 추적을 유지합니다. 이 작업을 담당하는 프로그램을I/O controller.
시간과 시간 동안 장치를 가져 오는 프로세스를 결정합니다.
효율적인 방법으로 장치를 할당합니다.
장치 할당을 해제합니다.
파일 관리
파일 시스템은 일반적으로 쉽게 탐색하고 사용할 수 있도록 디렉토리로 구성됩니다. 이러한 디렉토리에는 파일 및 기타 방향이 포함될 수 있습니다.
운영 체제는 파일 관리를 위해 다음 활동을 수행합니다.
정보, 위치, 사용, 상태 등을 추적합니다. 집합 시설은 종종 다음과 같이 알려져 있습니다. file system.
자원을 얻는 사람을 결정합니다.
리소스를 할당합니다.
리소스 할당을 해제합니다.
기타 중요한 활동
다음은 운영 체제가 수행하는 몇 가지 중요한 활동입니다.
Security − 암호 및 기타 유사한 기술을 사용하여 프로그램 및 데이터에 대한 무단 액세스를 방지합니다.
Control over system performance − 서비스 요청과 시스템 응답 사이의 지연 기록.
Job accounting − 다양한 작업과 사용자가 사용하는 시간과 자원을 추적합니다.
Error detecting aids − 덤프, 추적, 오류 메시지 및 기타 디버깅 및 오류 감지 지원의 생성.
Coordination between other softwares and users − 컴파일러, 인터프리터, 어셈블러 및 기타 소프트웨어를 컴퓨터 시스템의 다양한 사용자에게 조정하고 할당합니다.
운영 체제는 최초의 컴퓨터 세대에서 왔으며 시간이 지남에 따라 계속 진화합니다. 이 장에서는 가장 일반적으로 사용되는 운영 체제의 몇 가지 중요한 유형에 대해 설명합니다.
배치 운영 체제
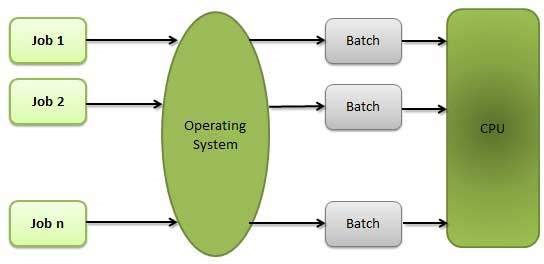
배치 운영 체제의 사용자는 컴퓨터와 직접 상호 작용하지 않습니다. 각 사용자는 펀치 카드와 같은 오프라인 장치에서 작업을 준비하고 컴퓨터 운영자에게 제출합니다. 처리 속도를 높이기 위해 유사한 요구 사항이있는 작업을 함께 일괄 처리하고 그룹으로 실행합니다. 프로그래머는 프로그램을 운영자에게 맡기고 운영자는 유사한 요구 사항을 가진 프로그램을 배치로 분류합니다.
배치 시스템의 문제점은 다음과 같습니다.
- 사용자와 작업 간의 상호 작용 부족.
- 기계식 I / O 장치의 속도가 CPU보다 느리기 때문에 CPU는 종종 유휴 상태입니다.
- 원하는 우선 순위를 제공하기가 어렵습니다.
시간 공유 운영 체제
시분할은 여러 단말기에있는 많은 사람들이 특정 컴퓨터 시스템을 동시에 사용할 수 있도록하는 기술입니다. 시간 공유 또는 멀티 태스킹은 멀티 프로그래밍의 논리적 확장입니다. 여러 사용자가 동시에 공유하는 프로세서의 시간을 시간 공유라고합니다.
멀티 프로그래밍 된 배치 시스템과 시분할 시스템의 주요 차이점은 멀티 프로그래밍 된 배치 시스템의 경우 목표는 프로세서 사용을 최대화하는 것이고, 시분할 시스템에서는 목표가 응답 시간을 최소화하는 것입니다.
CPU는 여러 작업을 전환하여 실행하지만 전환이 너무 자주 발생합니다. 따라서 사용자는 즉각적인 응답을받을 수 있습니다. 예를 들어, 트랜잭션 처리에서 프로세서는 짧은 버스트 또는 양자 계산으로 각 사용자 프로그램을 실행합니다. 즉,n사용자가 있으면 각 사용자가 시간 퀀텀을 얻을 수 있습니다. 사용자가 명령을 제출할 때 응답 시간은 최대 몇 초입니다.
운영 체제는 CPU 스케줄링 및 다중 프로그래밍을 사용하여 각 사용자에게 작은 시간을 제공합니다. 주로 배치 시스템으로 설계된 컴퓨터 시스템은 시간 공유 시스템으로 수정되었습니다.
시분할 운영 체제의 장점은 다음과 같습니다.
- 빠른 응답의 이점을 제공합니다.
- 소프트웨어 중복을 방지합니다.
- CPU 유휴 시간을 줄입니다.
시간 공유 운영 체제의 단점은 다음과 같습니다.
- 신뢰성 문제.
- 사용자 프로그램 및 데이터의 보안 및 무결성 문제.
- 데이터 통신 문제.
분산 운영 체제
분산 시스템은 여러 중앙 프로세서를 사용하여 여러 실시간 응용 프로그램과 여러 사용자에게 서비스를 제공합니다. 데이터 처리 작업은 그에 따라 프로세서간에 분산됩니다.
프로세서는 다양한 통신 회선 (예 : 고속 버스 또는 전화선)을 통해 서로 통신합니다. 이것들은loosely coupled systems또는 분산 시스템. 분산 시스템의 프로세서는 크기와 기능이 다를 수 있습니다. 이러한 프로세서를 사이트, 노드, 컴퓨터 등이라고합니다.
분산 시스템의 장점은 다음과 같습니다.
- 리소스 공유 기능을 사용하면 한 사이트의 사용자가 다른 사이트에서 사용 가능한 리소스를 사용할 수 있습니다.
- 전자 메일을 통해 서로 데이터 교환 속도를 높입니다.
- 분산 시스템에서 한 사이트가 실패하면 나머지 사이트는 잠재적으로 계속 작동 할 수 있습니다.
- 고객에게 더 나은 서비스.
- 호스트 컴퓨터의 부하 감소.
- 데이터 처리 지연 감소.
네트워크 운영 체제
네트워크 운영 체제는 서버에서 실행되며 서버에 데이터, 사용자, 그룹, 보안, 응용 프로그램 및 기타 네트워킹 기능을 관리하는 기능을 제공합니다. 네트워크 운영 체제의 주요 목적은 일반적으로 LAN (Local Area Network), 개인 네트워크 또는 기타 네트워크와 같은 네트워크의 여러 컴퓨터간에 공유 파일 및 프린터 액세스를 허용하는 것입니다.
네트워크 운영 체제의 예로는 Microsoft Windows Server 2003, Microsoft Windows Server 2008, UNIX, Linux, Mac OS X, Novell NetWare 및 BSD가 있습니다.
네트워크 운영 체제의 장점은 다음과 같습니다.
- 중앙 집중식 서버는 매우 안정적입니다.
- 보안은 서버에서 관리합니다.
- 새로운 기술과 하드웨어로의 업그레이드는 시스템에 쉽게 통합 될 수 있습니다.
- 다양한 위치와 시스템 유형에서 서버에 대한 원격 액세스가 가능합니다.
네트워크 운영 체제의 단점은 다음과 같습니다.
- 서버 구매 및 운영 비용이 높습니다.
- 대부분의 작업을 중앙 위치에 의존합니다.
- 정기적 인 유지 관리 및 업데이트가 필요합니다.
실시간 운영 체제
실시간 시스템은 입력을 처리하고 응답하는 데 필요한 시간 간격이 너무 작아서 환경을 제어하는 데이터 처리 시스템으로 정의됩니다. 시스템이 필요한 업데이트 정보의 입력 및 표시에 응답하는 데 걸리는 시간을response time. 따라서이 방법에서는 온라인 처리에 비해 응답 시간이 매우 짧습니다.
실시간 시스템은 프로세서 작동에 엄격한 시간 요구 사항이 있거나 데이터 흐름이 엄격 할 때 사용되며 실시간 시스템은 전용 애플리케이션에서 제어 장치로 사용될 수 있습니다. 실시간 운영 체제에는 잘 정의되고 고정 된 시간 제약이 있어야합니다. 그렇지 않으면 시스템이 실패합니다. 예를 들어 과학 실험, 의료 영상 시스템, 산업 제어 시스템, 무기 시스템, 로봇, 항공 교통 제어 시스템 등이 있습니다.
실시간 운영 체제에는 두 가지 유형이 있습니다.
하드 실시간 시스템
하드 실시간 시스템은 중요한 작업이 적시에 완료되도록 보장합니다. 하드 실시간 시스템에서는 보조 스토리지가 제한되거나 누락되고 데이터가 ROM에 저장됩니다. 이러한 시스템에서 가상 메모리는 거의 발견되지 않습니다.
소프트 실시간 시스템
소프트 실시간 시스템은 덜 제한적입니다. 중요한 실시간 작업은 다른 작업보다 우선 순위를 가지며 완료 될 때까지 우선 순위를 유지합니다. 소프트 실시간 시스템은 하드 실시간 시스템보다 유용성이 제한적입니다. 예를 들어 멀티미디어, 가상 현실, 해저 탐사 및 행성 탐사선과 같은 고급 과학 프로젝트 등이 있습니다.
운영 체제는 사용자와 프로그램 모두에게 서비스를 제공합니다.
- 프로그램을 실행할 환경을 제공합니다.
- 사용자에게 편리한 방식으로 프로그램을 실행할 수있는 서비스를 제공합니다.
다음은 운영 체제에서 제공하는 몇 가지 일반적인 서비스입니다.
- 프로그램 실행
- I / O 작업
- 파일 시스템 조작
- Communication
- 오류 감지
- 자원 할당
- Protection
프로그램 실행
운영 체제는 사용자 프로그램에서 프린터 스풀러, 이름 서버, 파일 서버 등과 같은 시스템 프로그램에 이르기까지 많은 종류의 활동을 처리합니다. 이러한 각 활동은 프로세스로 캡슐화됩니다.
프로세스에는 전체 실행 컨텍스트 (실행할 코드, 조작 할 데이터, 등록, 사용중인 OS 리소스)가 포함됩니다. 다음은 프로그램 관리와 관련하여 운영 체제의 주요 활동입니다.
- 프로그램을 메모리로로드합니다.
- 프로그램을 실행합니다.
- 프로그램의 실행을 처리합니다.
- 프로세스 동기화를위한 메커니즘을 제공합니다.
- 프로세스 통신을위한 메커니즘을 제공합니다.
- 교착 상태 처리를위한 메커니즘을 제공합니다.
I / O 작동
I / O 하위 시스템은 I / O 장치와 해당 드라이버 소프트웨어로 구성됩니다. 드라이버는 사용자로부터 특정 하드웨어 장치의 특성을 숨 깁니다.
운영 체제는 사용자와 장치 드라이버 간의 통신을 관리합니다.
- I / O 작업은 파일 또는 특정 I / O 장치에 대한 읽기 또는 쓰기 작업을 의미합니다.
- 운영 체제는 필요할 때 필요한 I / O 장치에 대한 액세스를 제공합니다.
파일 시스템 조작
파일은 관련 정보의 모음을 나타냅니다. 컴퓨터는 장기 저장 목적으로 디스크 (보조 저장소)에 파일을 저장할 수 있습니다. 저장 매체의 예로는 자기 테이프, 자기 디스크 및 CD, DVD와 같은 광학 디스크 드라이브가 있습니다. 이러한 각 미디어에는 속도, 용량, 데이터 전송 속도 및 데이터 액세스 방법과 같은 고유 한 속성이 있습니다.
파일 시스템은 일반적으로 쉽게 탐색하고 사용할 수 있도록 디렉토리로 구성됩니다. 이러한 디렉토리에는 파일 및 기타 방향이 포함될 수 있습니다. 다음은 파일 관리와 관련하여 운영 체제의 주요 활동입니다-
- 프로그램은 파일을 읽거나 파일을 써야합니다.
- 운영 체제는 파일에서 작업 할 수 있도록 프로그램에 권한을 부여합니다.
- 권한은 읽기 전용, 읽기-쓰기, 거부 등에서 다릅니다.
- 운영 체제는 사용자에게 파일을 생성 / 삭제할 수있는 인터페이스를 제공합니다.
- 운영 체제는 사용자에게 디렉토리를 생성 / 삭제할 수있는 인터페이스를 제공합니다.
- 운영 체제는 파일 시스템의 백업을 생성하는 인터페이스를 제공합니다.
통신
메모리, 주변 장치 또는 클록을 공유하지 않는 프로세서 모음 인 분산 시스템의 경우 운영 체제가 모든 프로세스 간의 통신을 관리합니다. 여러 프로세스가 네트워크의 통신 회선을 통해 서로 통신합니다.
OS는 라우팅 및 연결 전략, 경합 및 보안 문제를 처리합니다. 다음은 통신과 관련하여 운영 체제의 주요 활동입니다-
- 두 프로세스는 종종 데이터를 전송해야합니다.
- 두 프로세스 모두 한 컴퓨터 또는 다른 컴퓨터에있을 수 있지만 컴퓨터 네트워크를 통해 연결됩니다.
- 통신은 공유 메모리 또는 메시지 전달의 두 가지 방법으로 구현할 수 있습니다.
오류 처리
오류는 언제 어디서나 발생할 수 있습니다. CPU, I / O 장치 또는 메모리 하드웨어에서 오류가 발생할 수 있습니다. 다음은 오류 처리와 관련하여 운영 체제의 주요 활동입니다.
- OS는 가능한 오류를 지속적으로 확인합니다.
- OS는 정확하고 일관된 컴퓨팅을 보장하기 위해 적절한 조치를 취합니다.
자원 관리
다중 사용자 또는 다중 작업 환경의 경우 메인 메모리, CPU주기 및 파일 스토리지와 같은 리소스가 각 사용자 또는 작업에 할당됩니다. 다음은 자원 관리와 관련하여 운영 체제의 주요 활동입니다-
- OS는 스케줄러를 사용하여 모든 종류의 리소스를 관리합니다.
- CPU 스케줄링 알고리즘은 CPU 활용도를 높이는 데 사용됩니다.
보호
여러 사용자가 있고 여러 프로세스를 동시에 실행하는 컴퓨터 시스템을 고려하면 다양한 프로세스가 서로의 활동으로부터 보호되어야합니다.
보호는 컴퓨터 시스템에 정의 된 리소스에 대한 프로그램, 프로세스 또는 사용자의 액세스를 제어하는 메커니즘 또는 방법을 의미합니다. 다음은 보호와 관련된 운영 체제의 주요 활동입니다.
- OS는 시스템 리소스에 대한 모든 액세스가 제어되도록합니다.
- OS는 외부 I / O 장치가 잘못된 액세스 시도로부터 보호되도록합니다.
- OS는 암호를 통해 각 사용자에 대한 인증 기능을 제공합니다.
일괄 처리
일괄 처리는 처리가 시작되기 전에 운영 체제가 프로그램과 데이터를 일괄 적으로 수집하는 기술입니다. 운영 체제는 일괄 처리와 관련된 다음 활동을 수행합니다.
OS는 명령, 프로그램 및 데이터의 순서를 미리 정의한 작업을 단일 단위로 정의합니다.
OS는 메모리에 많은 작업을 보관하고 수동 정보없이 작업을 실행합니다.
작업은 제출 순서대로 처리됩니다. 즉, 선착순 방식입니다.
작업이 실행을 완료하면 해당 메모리가 해제되고 작업에 대한 출력이 나중에 인쇄 또는 처리 할 수 있도록 출력 스풀에 복사됩니다.
장점
일괄 처리는 작업자의 작업 대부분을 컴퓨터에 맡깁니다.
수동 개입없이 이전 작업이 완료되는 즉시 새 작업이 시작되므로 성능이 향상됩니다.
단점
- 프로그램 디버깅이 어렵습니다.
- 작업이 무한 루프에 들어갈 수 있습니다.
- 보호 체계가 없기 때문에 하나의 일괄 작업이 보류중인 작업에 영향을 미칠 수 있습니다.
멀티 태스킹
멀티 태스킹은 CPU가 여러 작업을 전환하여 동시에 실행하는 것입니다. 스위치가 너무 자주 발생하여 사용자가 실행되는 동안 각 프로그램과 상호 작용할 수 있습니다. OS는 멀티 태스킹과 관련된 다음 활동을 수행합니다.
사용자는 운영 체제 나 프로그램에 직접 지시를 내리고 즉시 응답을받습니다.
OS는 여러 작업을 처리하고 한 번에 여러 프로그램을 실행하는 방식으로 멀티 태스킹을 처리합니다.
멀티 태스킹 운영 체제는 시간 공유 시스템이라고도합니다.
이러한 운영 체제는 합리적인 비용으로 컴퓨터 시스템의 대화 형 사용을 제공하기 위해 개발되었습니다.
시간 공유 운영 체제는 CPU 스케줄링 및 멀티 프로그래밍 개념을 사용하여 각 사용자에게 시간 공유 CPU의 작은 부분을 제공합니다.
각 사용자는 메모리에 하나 이상의 개별 프로그램을 가지고 있습니다.
메모리에로드되고 실행중인 프로그램을 일반적으로 process.
프로세스가 실행되면 일반적으로 완료되거나 I / O를 수행해야하기 전에 매우 짧은 시간 동안 만 실행됩니다.
대화 형 I / O는 일반적으로 느린 속도로 실행되므로 완료하는 데 시간이 오래 걸릴 수 있습니다. 이 시간 동안 다른 프로세스에서 CPU를 사용할 수 있습니다.
운영 체제를 통해 사용자는 컴퓨터를 동시에 공유 할 수 있습니다. 시간 공유 시스템의 각 작업이나 명령은 짧은 경향이 있기 때문에 각 사용자에게 약간의 CPU 시간 만 필요합니다.
시스템이 한 사용자 / 프로그램에서 다음 프로그램으로 CPU를 빠르게 전환함에 따라 각 사용자는 자신의 CPU를 가지고있는 반면 실제로는 하나의 CPU를 많은 사용자가 공유하고 있다는 인상을받습니다.
다중 프로그래밍
두 개 이상의 프로그램이 동시에 메모리에 상주하는 경우 프로세서를 공유하는 것을 multiprogramming. 다중 프로그래밍은 단일 공유 프로세서를 가정합니다. 멀티 프로그래밍은 작업을 구성하여 CPU 사용률을 높여 CPU가 항상 실행할 수 있도록합니다.
다음 그림은 다중 프로그래밍 시스템의 메모리 레이아웃을 보여줍니다.
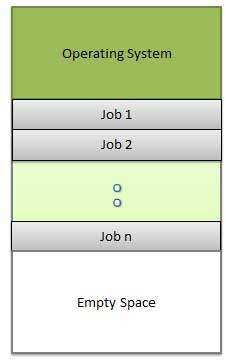
OS는 멀티 프로그래밍과 관련된 다음 활동을 수행합니다.
운영 체제는 한 번에 여러 작업을 메모리에 보관합니다.
이 작업 세트는 작업 풀에 보관 된 작업의 하위 집합입니다.
운영 체제는 메모리에있는 작업 중 하나를 선택하고 실행하기 시작합니다.
다중 프로그래밍 운영 체제는 메모리 관리 프로그램을 사용하여 모든 활성 프로그램 및 시스템 리소스의 상태를 모니터링하여 처리 할 작업이없는 경우 CPU가 유휴 상태가되지 않도록합니다.
장점
- 높고 효율적인 CPU 활용.
- 사용자는 많은 프로그램에 거의 동시에 CPU가 할당되어 있다고 느낍니다.
단점
- CPU 스케줄링이 필요합니다.
- 메모리에 많은 작업을 수용하려면 메모리 관리가 필요합니다.
상호 작용
상호 작용은 사용자가 컴퓨터 시스템과 상호 작용할 수있는 능력을 의미합니다. 운영 체제는 상호 작용과 관련된 다음 활동을 수행합니다.
- 사용자에게 시스템과 상호 작용할 수있는 인터페이스를 제공합니다.
- 사용자로부터 입력을 받기 위해 입력 장치를 관리합니다. 예를 들어, 키보드.
- 사용자에게 출력을 표시하기 위해 출력 장치를 관리합니다. 예를 들어, 모니터.
사용자가 결과를 제출하고 기다리기 때문에 OS의 응답 시간이 짧아야합니다.
실시간 시스템
실시간 시스템은 일반적으로 전용 임베디드 시스템입니다. 운영 체제는 실시간 시스템 활동과 관련된 다음 활동을 수행합니다.
- 이러한 시스템에서 운영 체제는 일반적으로 센서 데이터를 읽고 반응합니다.
- 운영 체제는 정확한 성능을 보장하기 위해 정해진 시간 내에 이벤트에 대한 응답을 보장해야합니다.
분산 환경
분산 환경은 컴퓨터 시스템의 여러 독립 CPU 또는 프로세서를 의미합니다. 운영 체제는 분산 환경과 관련된 다음 활동을 수행합니다.
OS는 여러 물리적 프로세서에 계산 논리를 배포합니다.
프로세서는 메모리 나 시계를 공유하지 않습니다. 대신 각 프로세서에는 자체 로컬 메모리가 있습니다.
OS는 프로세서 간의 통신을 관리합니다. 그들은 다양한 통신 회선을 통해 서로 통신합니다.
스풀링
스풀링은 온라인 동시 주변 장치 작업의 약어입니다. 스풀링은 다양한 I / O 작업의 데이터를 버퍼에 넣는 것을 말합니다. 이 버퍼는 I / O 장치에 액세스 할 수있는 메모리 또는 하드 디스크의 특수 영역입니다.
운영 체제는 분산 환경과 관련된 다음 활동을 수행합니다.
장치의 데이터 액세스 속도가 다르기 때문에 I / O 장치 데이터 스풀링을 처리합니다.
느린 장치가 따라 잡는 동안 데이터가 휴식을 취할 수있는 대기 스테이션을 제공하는 스풀링 버퍼를 유지합니다.
컴퓨터가 병렬 방식으로 I / O를 수행 할 수 있으므로 스풀링 프로세스로 인해 병렬 계산을 유지합니다. 컴퓨터가 컴퓨팅 작업을 수행하는 동안 테이프에서 데이터를 읽고 디스크에 데이터를 쓰고 테이프 프린터에 기록하는 것이 가능해집니다.

장점
- 스풀링 작업은 디스크를 매우 큰 버퍼로 사용합니다.
- 스풀링은 한 작업에 대한 I / O 작업을 다른 작업에 대한 프로세서 작업과 겹칠 수 있습니다.
방법
프로세스는 기본적으로 실행중인 프로그램입니다. 프로세스 실행은 순차적으로 진행되어야합니다.
프로세스는 시스템에서 구현할 기본 작업 단위를 나타내는 엔티티로 정의됩니다.
간단히 말해서 컴퓨터 프로그램을 텍스트 파일로 작성하고이 프로그램을 실행하면 프로그램에서 언급 한 모든 작업을 수행하는 프로세스가됩니다.
프로그램이 메모리에로드되고 프로세스가되면 스택, 힙, 텍스트 및 데이터의 4 개 섹션으로 나눌 수 있습니다. 다음 이미지는 메인 메모리 내부 프로세스의 단순화 된 레이아웃을 보여줍니다.
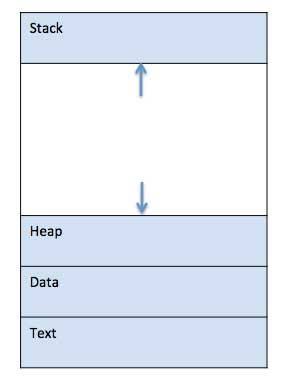
| SN | 구성 요소 및 설명 |
|---|---|
| 1 | Stack 프로세스 스택에는 메서드 / 함수 매개 변수, 반환 주소 및 로컬 변수와 같은 임시 데이터가 포함됩니다. |
| 2 | Heap 이것은 런타임 동안 프로세스에 동적으로 할당 된 메모리입니다. |
| 삼 | Text 여기에는 Program Counter 값으로 표시되는 현재 활동과 프로세서 레지스터의 내용이 포함됩니다. |
| 4 | Data 이 섹션에는 전역 및 정적 변수가 포함되어 있습니다. |
프로그램
프로그램은 한 줄 또는 수백만 줄이 될 수있는 코드 조각입니다. 컴퓨터 프로그램은 일반적으로 컴퓨터 프로그래머가 프로그래밍 언어로 작성합니다. 예를 들어, 다음은 C 프로그래밍 언어로 작성된 간단한 프로그램입니다.
#include <stdio.h>
int main() {
printf("Hello, World! \n");
return 0;
}컴퓨터 프로그램은 컴퓨터에서 실행할 때 특정 작업을 수행하는 명령 모음입니다. 프로그램을 프로세스와 비교할 때 프로세스가 컴퓨터 프로그램의 동적 인스턴스라는 결론을 내릴 수 있습니다.
잘 정의 된 작업을 수행하는 컴퓨터 프로그램의 일부를 algorithm. 컴퓨터 프로그램, 라이브러리 및 관련 데이터의 모음을software.
프로세스 라이프 사이클
프로세스가 실행되면 다른 상태를 통과합니다. 이러한 단계는 운영 체제마다 다를 수 있으며 이러한 상태의 이름도 표준화되지 않았습니다.
일반적으로 프로세스는 한 번에 다음 5 개 상태 중 하나를 가질 수 있습니다.
| SN | 상태 및 설명 |
|---|---|
| 1 | Start 프로세스가 처음 시작 / 생성 될 때의 초기 상태입니다. |
| 2 | Ready 프로세스가 프로세서에 할당되기를 기다리고 있습니다. 준비된 프로세스는 실행될 수 있도록 운영 체제에서 프로세서를 할당하기를 기다리고 있습니다. 프로세스가이 상태가 될 수 있습니다.Start 다른 프로세스에 CPU를 할당하기 위해 스케줄러에 의해 중단되었지만 실행 중입니다. |
| 삼 | Running OS 스케줄러에 의해 프로세스가 프로세서에 할당되면 프로세스 상태가 실행 중으로 설정되고 프로세서가 명령을 실행합니다. |
| 4 | Waiting 사용자 입력을 기다리거나 파일을 사용할 수있을 때까지 기다리는 것과 같이 리소스를 기다려야하는 경우 프로세스가 대기 상태로 전환됩니다. |
| 5 | Terminated or Exit 프로세스가 실행을 완료하거나 운영 체제에 의해 종료되면 종료 상태로 이동하여 주 메모리에서 제거되기를 기다립니다. |

공정 제어 블록 (PCB)
프로세스 제어 블록은 모든 프로세스에 대해 운영 체제에서 유지 관리하는 데이터 구조입니다. PCB는 정수 프로세스 ID (PID)로 식별됩니다. PCB는 아래 표에 나열된 프로세스를 추적하는 데 필요한 모든 정보를 유지합니다.
| SN | 정보 및 설명 |
|---|---|
| 1 | Process State 프로세스의 현재 상태, 즉 준비, 실행 중, 대기 중인지 여부. |
| 2 | Process privileges 시스템 리소스에 대한 액세스를 허용 / 금지하는 데 필요합니다. |
| 삼 | Process ID 운영 체제의 각 프로세스에 대한 고유 식별. |
| 4 | Pointer 부모 프로세스에 대한 포인터. |
| 5 | Program Counter 프로그램 카운터는이 프로세스를 위해 실행될 다음 명령어의 주소에 대한 포인터입니다. |
| 6 | CPU registers 실행 상태에 대한 실행을 위해 프로세스를 저장해야하는 다양한 CPU 레지스터. |
| 7 | CPU Scheduling Information 프로세스를 예약하는 데 필요한 프로세스 우선 순위 및 기타 예약 정보. |
| 8 | Memory management information 여기에는 운영 체제에서 사용하는 메모리에 따른 페이지 테이블, 메모리 제한, 세그먼트 테이블 정보가 포함됩니다. |
| 9 | Accounting information 여기에는 프로세스 실행에 사용 된 CPU 양, 시간 제한, 실행 ID 등이 포함됩니다. |
| 10 | IO status information 여기에는 프로세스에 할당 된 I / O 장치 목록이 포함됩니다. |
PCB의 아키텍처는 운영 체제에 완전히 의존하며 운영 체제마다 다른 정보를 포함 할 수 있습니다. 다음은 PCB의 단순화 된 다이어그램입니다.

PCB는 수명 내내 프로세스에 대해 유지되며 프로세스가 종료되면 삭제됩니다.
정의
프로세스 스케줄링은 CPU에서 실행중인 프로세스를 제거하고 특정 전략에 따라 다른 프로세스를 선택하는 프로세스 관리자의 활동입니다.
프로세스 스케줄링은 멀티 프로그래밍 운영 체제의 필수적인 부분입니다. 이러한 운영 체제를 사용하면 한 번에 둘 이상의 프로세스를 실행 가능 메모리로로드 할 수 있으며로드 된 프로세스는 시간 다중화를 사용하여 CPU를 공유합니다.
프로세스 예약 대기열
OS는 프로세스 스케줄링 대기열에있는 모든 PCB를 유지합니다. OS는 각 프로세스 상태에 대해 별도의 대기열을 유지하며 동일한 실행 상태에있는 모든 프로세스의 PCB는 동일한 대기열에 배치됩니다. 프로세스의 상태가 변경되면 PCB는 현재 큐에서 링크 해제되고 새 상태 큐로 이동됩니다.
운영 체제는 다음과 같은 중요한 프로세스 스케줄링 대기열을 유지합니다.
Job queue −이 대기열은 시스템의 모든 프로세스를 유지합니다.
Ready queue−이 큐는 메인 메모리에 상주하는 모든 프로세스를 준비하고 실행 대기 상태로 유지합니다. 새 프로세스는 항상이 대기열에 배치됩니다.
Device queues − I / O 장치를 사용할 수 없어 차단 된 프로세스가이 대기열을 구성합니다.

OS는 서로 다른 정책을 사용하여 각 대기열 (FIFO, 라운드 로빈, 우선 순위 등)을 관리 할 수 있습니다. OS 스케줄러는 시스템의 프로세서 코어 당 하나의 항목 만 가질 수있는 준비 및 실행 대기열간에 프로세스를 이동하는 방법을 결정합니다. 위 다이어그램에서는 CPU와 병합되었습니다.
2- 상태 프로세스 모델
2- 상태 프로세스 모델은 아래에 설명 된 실행 및 비 실행 상태를 나타냅니다.
| SN | 상태 및 설명 |
|---|---|
| 1 | Running 새 프로세스가 생성되면 실행 중 상태로 시스템에 들어갑니다. |
| 2 | Not Running 실행되지 않는 프로세스는 차례가 실행될 때까지 대기하면서 대기열에 보관됩니다. 대기열의 각 항목은 특정 프로세스에 대한 포인터입니다. 큐는 연결 목록을 사용하여 구현됩니다. 발송자의 이용은 다음과 같습니다. 프로세스가 중단되면 해당 프로세스는 대기 대기열로 전송됩니다. 프로세스가 완료되거나 중단되면 프로세스가 삭제됩니다. 두 경우 모두 디스패처는 대기열에서 실행할 프로세스를 선택합니다. |
스케줄러
스케줄러는 다양한 방식으로 프로세스 스케줄링을 처리하는 특수 시스템 소프트웨어입니다. 주요 임무는 시스템에 제출할 작업을 선택하고 실행할 프로세스를 결정하는 것입니다. 스케줄러는 세 가지 유형입니다-
- 장기 스케줄러
- 단기 스케줄러
- 중기 스케줄러
장기 스케줄러
그것은 또한 job scheduler. 장기 스케줄러는 처리를 위해 시스템에 허용되는 프로그램을 결정합니다. 큐에서 프로세스를 선택하고 실행을 위해 메모리에로드합니다. CPU 스케줄링을 위해 프로세스가 메모리에로드됩니다.
작업 스케줄러의 주요 목표는 I / O 바인딩 및 프로세서 바인딩과 같은 균형 잡힌 작업 조합을 제공하는 것입니다. 또한 다중 프로그래밍의 정도를 제어합니다. 다중 프로그래밍의 정도가 안정적인 경우 평균 프로세스 생성 속도는 시스템을 떠나는 프로세스의 평균 출발 속도와 같아야합니다.
일부 시스템에서는 장기 스케줄러를 사용할 수 없거나 최소화 할 수 있습니다. 시간 공유 운영 체제에는 장기 스케줄러가 없습니다. 프로세스가 상태를 신규에서 준비로 변경하면 장기 스케줄러가 사용됩니다.
단기 스케줄러
그것은 또한 CPU scheduler. 주요 목표는 선택한 기준 세트에 따라 시스템 성능을 높이는 것입니다. 프로세스의 준비 상태에서 실행 상태로 변경됩니다. CPU 스케줄러는 실행할 준비가 된 프로세스 중에서 프로세스를 선택하고 그 중 하나에 CPU를 할당합니다.
디스패처라고도하는 단기 스케줄러는 다음에 실행할 프로세스를 결정합니다. 단기 스케줄러는 장기 스케줄러보다 빠릅니다.
중기 스케줄러
중기 일정은 다음의 일부입니다. swapping. 메모리에서 프로세스를 제거합니다. 다중 프로그래밍의 정도를 줄입니다. 중기 스케줄러는 교체 된 아웃 프로세스를 처리합니다.
I / O 요청을하면 실행중인 프로세스가 일시 중단 될 수 있습니다. 일시 중단 된 프로세스는 완료를 향해 진행할 수 없습니다. 이 상태에서 프로세스를 메모리에서 제거하고 다른 프로세스를위한 공간을 확보하기 위해 일시 중단 된 프로세스를 보조 저장소로 이동합니다. 이 과정을swapping, 프로세스가 스왑 아웃 또는 롤아웃되었다고합니다. 공정 혼합을 개선하기 위해 스와핑이 필요할 수 있습니다.
스케줄러 비교
| SN | 장기 스케줄러 | 단기 스케줄러 | 중기 스케줄러 |
|---|---|---|---|
| 1 | 작업 스케줄러입니다 | CPU 스케줄러입니다 | 프로세스 스와핑 스케줄러입니다. |
| 2 | 속도는 단기 스케줄러보다 느립니다. | 속도는 다른 두 가지 중에서 가장 빠릅니다 | 속도는 단기 및 장기 스케줄러 사이에 있습니다. |
| 삼 | 다중 프로그래밍의 정도를 제어합니다. | 다중 프로그래밍 정도에 대한 제어가 적습니다. | 다중 프로그래밍의 정도를 줄입니다. |
| 4 | 시간 공유 시스템에서 거의 없거나 최소화됩니다. | 시간 공유 시스템에서도 최소화 | 시간 공유 시스템의 일부입니다. |
| 5 | 풀에서 프로세스를 선택하고 실행을 위해 메모리에로드합니다. | 실행할 준비가 된 프로세스를 선택합니다. | 프로세스를 메모리에 다시 도입하고 실행을 계속할 수 있습니다. |
컨텍스트 전환
컨텍스트 스위치는 프로세스 실행이 나중에 같은 지점에서 재개 될 수 있도록 프로세스 제어 블록에 CPU의 상태 또는 컨텍스트를 저장하고 복원하는 메커니즘입니다. 이 기술을 사용하면 컨텍스트 전환기를 통해 여러 프로세스가 단일 CPU를 공유 할 수 있습니다. 컨텍스트 전환은 멀티 태스킹 운영 체제 기능의 필수 부분입니다.
스케줄러가 CPU를 한 프로세스 실행에서 다른 프로세스 실행으로 전환하면 현재 실행중인 프로세스의 상태가 프로세스 제어 블록에 저장됩니다. 그 후 프로세스가 다음에 실행될 상태는 자체 PCB에서로드되어 PC, 레지스터 등을 설정하는 데 사용됩니다.이 시점에서 두 번째 프로세스가 실행을 시작할 수 있습니다.
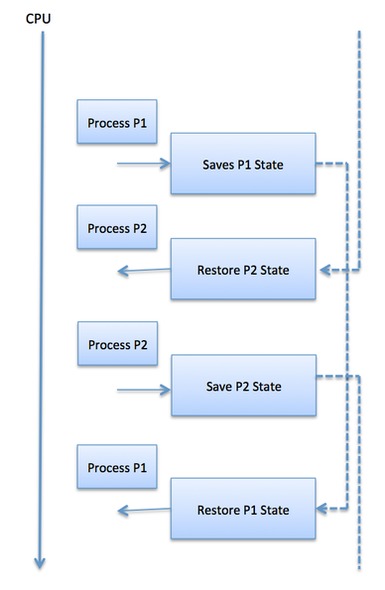
컨텍스트 스위치는 레지스터와 메모리 상태를 저장하고 복원해야하므로 계산 집약적입니다. 컨텍스트 전환 시간을 피하기 위해 일부 하드웨어 시스템은 두 개 이상의 프로세서 레지스터 세트를 사용합니다. 프로세스가 전환되면 나중에 사용할 수 있도록 다음 정보가 저장됩니다.
- 프로그램 카운터
- 일정 정보
- 기본 및 제한 레지스터 값
- 현재 사용되는 레지스터
- 변경된 상태
- I / O 상태 정보
- 회계 정보
프로세스 스케줄러는 특정 스케줄링 알고리즘을 기반으로 CPU에 할당 할 여러 프로세스를 스케줄링합니다. 이 장에서 논의 할 6 개의 인기있는 프로세스 스케줄링 알고리즘이 있습니다.
- FCFS (First-Come, First-Served) 스케줄링
- 최단 작업 다음 (SJN) 스케줄링
- 우선 순위 스케줄링
- 최단 남은 시간
- 라운드 로빈 (RR) 스케줄링
- 다중 수준 대기열 예약
이러한 알고리즘은 non-preemptive or preemptive. 비 선점 알고리즘은 프로세스가 실행 상태에 들어가면 할당 된 시간이 완료 될 때까지 선점 될 수 없도록 설계되었으며, 선점 스케줄링은 우선 순위가 높을 때 스케줄러가 낮은 우선 순위 실행 프로세스를 언제든지 선점 할 수있는 우선 순위를 기반으로합니다. 프로세스가 준비 상태로 들어갑니다.
선착순 (FCFS)
- 작업은 선착순으로 실행됩니다.
- 비 선점, 선점 스케줄링 알고리즘입니다.
- 이해하고 구현하기 쉽습니다.
- 구현은 FIFO 대기열을 기반으로합니다.
- 평균 대기 시간이 길어 성능이 저하됩니다.
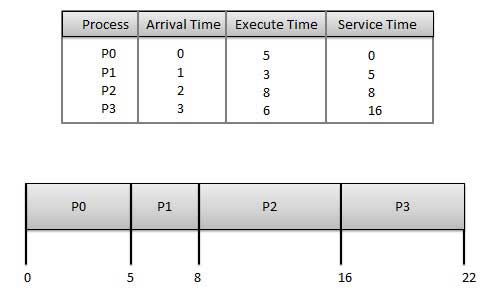
Wait time 각 프로세스의 다음과 같습니다-
| 방법 | 대기 시간 : 서비스 시간-도착 시간 |
|---|---|
| P0 | 0-0 = 0 |
| P1 | 5-1 = 4 |
| P2 | 8-2 = 6 |
| P3 | 16-3 = 13 |
평균 대기 시간 : (0 + 4 + 6 + 13) / 4 = 5.75
최단 작업 다음 (SJN)
이것은 또한 알려진 shortest job first, 또는 SJF
이것은 비 선점, 선점 스케줄링 알고리즘입니다.
대기 시간을 최소화하는 최선의 방법.
필요한 CPU 시간을 미리 알고있는 배치 시스템에서 쉽게 구현할 수 있습니다.
필요한 CPU 시간을 알 수없는 대화 형 시스템에서는 구현할 수 없습니다.
처리자는 처리에 걸리는 시간을 미리 알아야합니다.
주어진 : 프로세스 테이블 및 도착 시간, 실행 시간
| 방법 | 도착 시간 | 실행 시간 | 서비스 시간 |
|---|---|---|---|
| P0 | 0 | 5 | 0 |
| P1 | 1 | 삼 | 5 |
| P2 | 2 | 8 | 14 |
| P3 | 삼 | 6 | 8 |

Waiting time 각 프로세스의 다음과 같습니다-
| 방법 | 대기 시간 |
|---|---|
| P0 | 0-0 = 0 |
| P1 | 5-1 = 4 |
| P2 | 14-2 = 12 |
| P3 | 8-3 = 5 |
평균 대기 시간 : (0 + 4 + 12 + 5) / 4 = 21/4 = 5.25
우선 순위 기반 스케줄링
우선 순위 스케줄링은 비 선점 알고리즘이며 배치 시스템에서 가장 일반적인 스케줄링 알고리즘 중 하나입니다.
각 프로세스에는 우선 순위가 할당됩니다. 우선 순위가 가장 높은 프로세스가 먼저 실행됩니다.
우선 순위가 동일한 프로세스는 선착순으로 실행됩니다.
우선 순위는 메모리 요구 사항, 시간 요구 사항 또는 기타 리소스 요구 사항에 따라 결정할 수 있습니다.
주어진 : 프로세스 및 해당 도착 시간, 실행 시간 및 우선 순위 표. 여기서 우리는 1이 가장 낮은 우선 순위라고 생각합니다.
| 방법 | 도착 시간 | 실행 시간 | 우선 순위 | 서비스 시간 |
|---|---|---|---|---|
| P0 | 0 | 5 | 1 | 0 |
| P1 | 1 | 삼 | 2 | 11 |
| P2 | 2 | 8 | 1 | 14 |
| P3 | 삼 | 6 | 삼 | 5 |

Waiting time 각 프로세스의 다음과 같습니다-
| 방법 | 대기 시간 |
|---|---|
| P0 | 0-0 = 0 |
| P1 | 11-1 = 10 |
| P2 | 14-2 = 12 |
| P3 | 5-3 = 2 |
평균 대기 시간 : (0 + 10 + 12 + 2) / 4 = 24/4 = 6
최단 남은 시간
최단 잔여 시간 (SRT)은 SJN 알고리즘의 선점 형 버전입니다.
프로세서는 완료에 가장 가까운 작업에 할당되지만 완료 시간이 더 짧은 최신 준비 작업에 의해 선점 될 수 있습니다.
필요한 CPU 시간을 알 수없는 대화 형 시스템에서는 구현할 수 없습니다.
짧은 작업에 우선권을 부여해야하는 배치 환경에서 자주 사용됩니다.
라운드 로빈 스케줄링
라운드 로빈은 선점 프로세스 스케줄링 알고리즘입니다.
각 프로세스에는 실행할 고정 시간이 제공되며이를 quantum.
주어진 시간 동안 프로세스가 실행되면 해당 프로세스가 선점되고 지정된 시간 동안 다른 프로세스가 실행됩니다.
컨텍스트 전환은 선점 된 프로세스의 상태를 저장하는 데 사용됩니다.
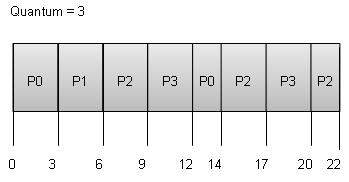
Wait time 각 프로세스의 다음과 같습니다-
| 방법 | 대기 시간 : 서비스 시간-도착 시간 |
|---|---|
| P0 | (0-0) + (12-3) = 9 |
| P1 | (3-1) = 2 |
| P2 | (6-2) + (14-9) + (20-17) = 12 |
| P3 | (9-3) + (17-12) = 11 |
평균 대기 시간 : (9 + 2 + 12 + 11) / 4 = 8.5
다중 수준 대기열 예약
다중 레벨 큐는 독립적 인 스케줄링 알고리즘이 아닙니다. 다른 기존 알고리즘을 사용하여 공통 특성을 가진 작업을 그룹화하고 예약합니다.
- 공통 특성을 가진 프로세스에 대해 여러 큐가 유지됩니다.
- 각 대기열에는 자체 예약 알고리즘이있을 수 있습니다.
- 우선 순위는 각 대기열에 할당됩니다.
예를 들어 CPU 바인딩 작업은 한 큐에서 예약하고 모든 I / O 바인딩 작업은 다른 큐에서 예약 할 수 있습니다. 그런 다음 프로세스 스케줄러는 각 대기열에서 작업을 번갈아 선택하고 대기열에 할당 된 알고리즘을 기반으로 CPU에 할당합니다.
스레드는 무엇입니까?
스레드는 다음에 실행할 명령어를 추적하는 자체 프로그램 카운터, 현재 작업 변수를 보유하는 시스템 레지스터 및 실행 내역을 포함하는 스택을 포함하는 프로세스 코드를 통한 실행 흐름입니다.
스레드는 코드 세그먼트, 데이터 세그먼트 및 열린 파일과 같은 몇 가지 정보를 피어 스레드와 공유합니다. 한 스레드가 코드 세그먼트 메모리 항목을 변경하면 다른 모든 스레드에서이를 확인합니다.
스레드는 또한 lightweight process. 스레드는 병렬 처리를 통해 애플리케이션 성능을 향상시키는 방법을 제공합니다. 스레드는 오버 헤드 스레드를 줄임으로써 운영 체제의 성능을 향상시키는 소프트웨어 접근 방식을 나타내며 이는 기존 프로세스와 동일합니다.
각 스레드는 정확히 하나의 프로세스에 속하며 프로세스 외부에는 스레드가 존재할 수 없습니다. 각 스레드는 별도의 제어 흐름을 나타냅니다. 스레드는 네트워크 서버 및 웹 서버를 구현하는 데 성공적으로 사용되었습니다. 또한 공유 메모리 멀티 프로세서에서 애플리케이션의 병렬 실행을위한 적절한 기반을 제공합니다. 다음 그림은 단일 스레드 및 다중 스레드 프로세스의 작업을 보여줍니다.
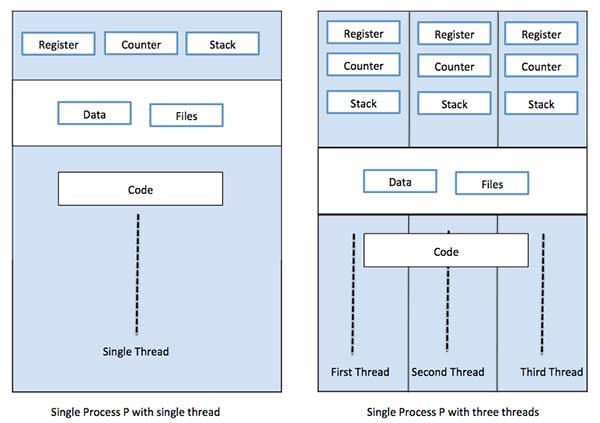
프로세스와 스레드의 차이점
| SN | 방법 | 실 |
|---|---|---|
| 1 | 프로세스가 무겁거나 리소스 집약적입니다. | 스레드는 가볍고 프로세스보다 리소스를 적게 사용합니다. |
| 2 | 프로세스 전환에는 운영 체제와의 상호 작용이 필요합니다. | 스레드 전환은 운영 체제와 상호 작용할 필요가 없습니다. |
| 삼 | 여러 처리 환경에서 각 프로세스는 동일한 코드를 실행하지만 자체 메모리 및 파일 리소스가 있습니다. | 모든 스레드는 동일한 열린 파일 세트, 하위 프로세스를 공유 할 수 있습니다. |
| 4 | 한 프로세스가 차단되면 첫 번째 프로세스가 차단 해제 될 때까지 다른 프로세스를 실행할 수 없습니다. | 한 스레드가 차단되고 대기하는 동안 동일한 작업의 두 번째 스레드가 실행될 수 있습니다. |
| 5 | 스레드를 사용하지 않는 여러 프로세스는 더 많은 리소스를 사용합니다. | 다중 스레드 프로세스는 더 적은 리소스를 사용합니다. |
| 6 | 여러 프로세스에서 각 프로세스는 다른 프로세스와 독립적으로 작동합니다. | 한 스레드는 다른 스레드의 데이터를 읽거나 쓰거나 변경할 수 있습니다. |
스레드의 장점
- 스레드는 컨텍스트 전환 시간을 최소화합니다.
- 스레드를 사용하면 프로세스 내에서 동시성이 제공됩니다.
- 효율적인 커뮤니케이션.
- 스레드를 만들고 컨텍스트 전환하는 것이 더 경제적입니다.
- 스레드를 사용하면 다중 프로세서 아키텍처를 더 큰 규모와 효율성으로 활용할 수 있습니다.
실의 종류
스레드는 다음 두 가지 방법으로 구현됩니다.
User Level Threads − 사용자 관리 스레드.
Kernel Level Threads − 운영 체제 코어 인 커널에서 작동하는 운영 체제 관리 스레드.
사용자 수준 스레드
이 경우 스레드 관리 커널은 스레드의 존재를 인식하지 못합니다. 스레드 라이브러리에는 스레드 생성 및 삭제, 스레드 간 메시지 및 데이터 전달, 스레드 실행 예약 및 스레드 컨텍스트 저장 및 복원을위한 코드가 포함되어 있습니다. 응용 프로그램은 단일 스레드로 시작됩니다.
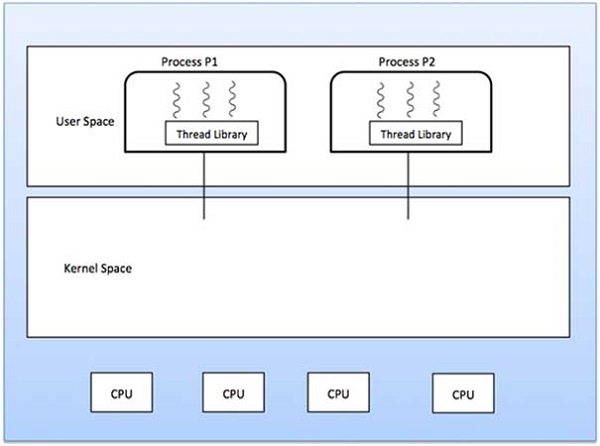
장점
- 스레드 전환에는 커널 모드 권한이 필요하지 않습니다.
- 사용자 수준 스레드는 모든 운영 체제에서 실행할 수 있습니다.
- 스케줄링은 사용자 레벨 스레드에서 애플리케이션에 따라 다를 수 있습니다.
- 사용자 수준 스레드는 빠르게 만들고 관리 할 수 있습니다.
단점
- 일반적인 운영 체제에서 대부분의 시스템 호출은 차단됩니다.
- 다중 스레드 응용 프로그램은 다중 처리를 활용할 수 없습니다.
커널 수준 스레드
이 경우 스레드 관리는 커널에 의해 수행됩니다. 응용 프로그램 영역에는 스레드 관리 코드가 없습니다. 커널 스레드는 운영 체제에서 직접 지원됩니다. 모든 응용 프로그램을 다중 스레드로 프로그래밍 할 수 있습니다. 응용 프로그램 내의 모든 스레드는 단일 프로세스 내에서 지원됩니다.
커널은 프로세스 전체와 프로세스 내의 개별 스레드에 대한 컨텍스트 정보를 유지합니다. 커널에 의한 스케줄링은 스레드 기반으로 수행됩니다. Kernel은 Kernel 공간에서 스레드 생성, 스케줄링 및 관리를 수행합니다. 커널 스레드는 일반적으로 사용자 스레드보다 생성 및 관리 속도가 느립니다.
장점
- 커널은 여러 프로세스에서 동일한 프로세스의 여러 스레드를 동시에 예약 할 수 있습니다.
- 프로세스의 한 스레드가 차단되면 커널은 동일한 프로세스의 다른 스레드를 예약 할 수 있습니다.
- 커널 루틴 자체는 다중 스레드가 될 수 있습니다.
단점
- 커널 스레드는 일반적으로 사용자 스레드보다 생성 및 관리 속도가 느립니다.
- 동일한 프로세스 내에서 한 스레드에서 다른 스레드로 제어를 전송하려면 모드를 커널로 전환해야합니다.
멀티 스레딩 모델
일부 운영 체제는 결합 된 사용자 수준 스레드와 커널 수준 스레드 기능을 제공합니다. 솔라리스는 이러한 결합 된 접근 방식의 좋은 예입니다. 결합 된 시스템에서는 동일한 애플리케이션 내의 여러 스레드가 여러 프로세서에서 병렬로 실행될 수 있으며 차단 시스템 호출이 전체 프로세스를 차단할 필요는 없습니다. 멀티 스레딩 모델은 세 가지 유형입니다.
- 다 대다 관계.
- 다 대일 관계.
- 일대일 관계.
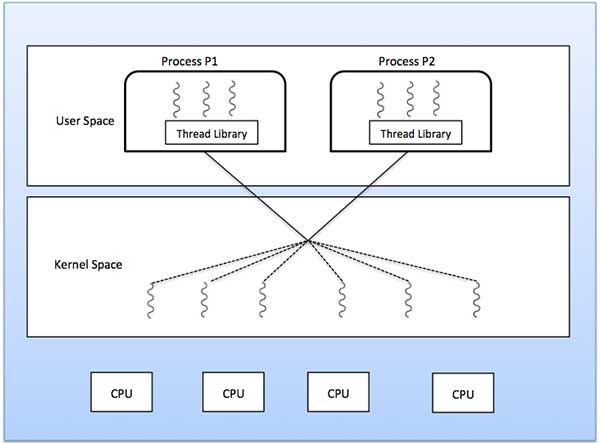
다 대다 모델
다 대다 모델은 임의의 수의 사용자 스레드를 동일하거나 더 적은 수의 커널 스레드로 다중화합니다.
다음 다이어그램은 6 개의 사용자 레벨 스레드가 6 개의 커널 레벨 스레드로 멀티플렉싱되는 다 대다 스레딩 모델을 보여줍니다. 이 모델에서 개발자는 필요한만큼 많은 사용자 스레드를 만들 수 있으며 해당 커널 스레드는 다중 프로세서 시스템에서 병렬로 실행할 수 있습니다. 이 모델은 동시성에 대해 최고의 정확도를 제공하며 스레드가 차단 시스템 호출을 수행 할 때 커널은 실행을 위해 다른 스레드를 예약 할 수 있습니다.
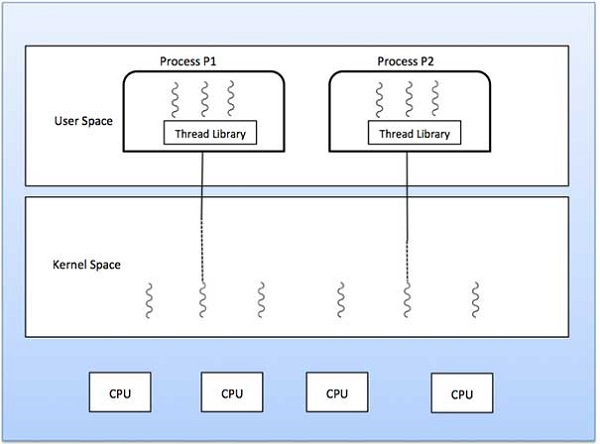
다 대일 모델
다 대일 모델은 많은 사용자 수준 스레드를 하나의 커널 수준 스레드에 매핑합니다. 스레드 관리는 스레드 라이브러리에 의해 사용자 공간에서 수행됩니다. 스레드가 차단 시스템 호출을 할 때 전체 프로세스가 차단됩니다. 한 번에 하나의 스레드 만 커널에 액세스 할 수 있으므로 다중 스레드는 다중 프로세서에서 병렬로 실행할 수 없습니다.
사용자 수준 스레드 라이브러리가 시스템이 지원하지 않는 방식으로 운영 체제에 구현 된 경우 커널 스레드는 다 대일 관계 모드를 사용합니다.
일대일 모델
사용자 수준 스레드와 커널 수준 스레드의 일대일 관계가 있습니다. 이 모델은 다 대일 모델보다 더 많은 동시성을 제공합니다. 또한 스레드가 차단 시스템 호출을 할 때 다른 스레드를 실행할 수 있습니다. 마이크로 프로세서에서 병렬로 실행되는 다중 스레드를 지원합니다.
이 모델의 단점은 사용자 스레드를 생성하려면 해당 커널 스레드가 필요하다는 것입니다. OS / 2, Windows NT 및 Windows 2000은 일대일 관계 모델을 사용합니다.
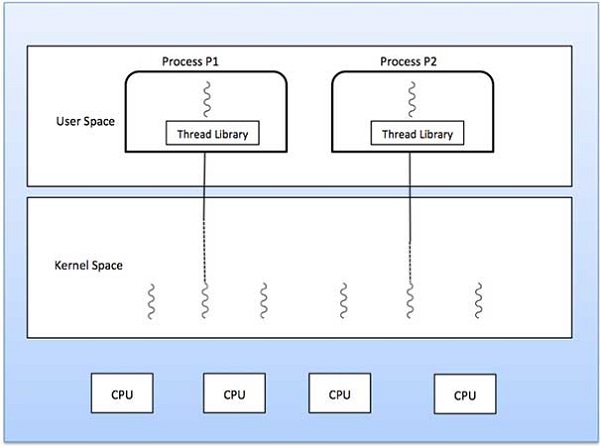
사용자 수준 스레드와 커널 수준 스레드의 차이점
| SN | 사용자 수준 스레드 | 커널 수준 스레드 |
|---|---|---|
| 1 | 사용자 수준 스레드는 생성 및 관리가 더 빠릅니다. | 커널 수준 스레드는 생성 및 관리 속도가 느립니다. |
| 2 | 구현은 사용자 수준의 스레드 라이브러리에 의해 이루어집니다. | 운영 체제는 커널 스레드 생성을 지원합니다. |
| 삼 | 사용자 수준 스레드는 일반적이며 모든 운영 체제에서 실행할 수 있습니다. | 커널 수준 스레드는 운영 체제에 따라 다릅니다. |
| 4 | 다중 스레드 응용 프로그램은 다중 처리를 활용할 수 없습니다. | 커널 루틴 자체는 다중 스레드가 될 수 있습니다. |
메모리 관리는 주 메모리를 처리하거나 관리하고 실행 중에 주 메모리와 디스크간에 프로세스를 앞뒤로 이동하는 운영 체제의 기능입니다. 메모리 관리는 일부 프로세스에 할당되었는지 여부에 관계없이 각각의 모든 메모리 위치를 추적합니다. 프로세스에 할당 할 메모리 양을 확인합니다. 어떤 프로세스가 언제 메모리를 확보할지 결정합니다. 일부 메모리가 해제되거나 할당되지 않을 때마다 추적하고 이에 따라 상태를 업데이트합니다.
이 튜토리얼은 메모리 관리와 관련된 기본 개념을 알려줍니다.
프로세스 주소 공간
프로세스 주소 공간은 프로세스가 코드에서 참조하는 논리 주소 집합입니다. 예를 들어 32 비트 주소 지정을 사용하는 경우 주소 범위는 0에서 0x7fffffff까지입니다. 즉, 이론상 총 2 기가 바이트 크기에 대해 2 ^ 31 개의 가능한 숫자입니다.
운영 체제는 프로그램에 메모리를 할당 할 때 논리 주소를 실제 주소에 매핑합니다. 메모리가 할당되기 전과 후에 프로그램에서 사용되는 세 가지 유형의 주소가 있습니다.
| SN | 메모리 주소 및 설명 |
|---|---|
| 1 | Symbolic addresses 소스 코드에 사용 된 주소입니다. 변수 이름, 상수 및 명령어 레이블은 기호 주소 공간의 기본 요소입니다. |
| 2 | Relative addresses 컴파일시 컴파일러는 기호 주소를 상대 주소로 변환합니다. |
| 삼 | Physical addresses 로더는 프로그램이 주 메모리에로드 될 때 이러한 주소를 생성합니다. |
가상 및 물리적 주소는 컴파일 시간 및로드 시간 주소 바인딩 체계에서 동일합니다. 가상 및 실제 주소는 실행 시간 주소 바인딩 체계가 다릅니다.
프로그램에 의해 생성 된 모든 논리 주소 집합을 logical address space. 이러한 논리적 주소에 해당하는 모든 물리적 주소의 집합을physical address space.
가상 주소에서 물리적 주소로의 런타임 매핑은 하드웨어 장치 인 MMU (메모리 관리 장치)에 의해 수행됩니다. MMU는 다음 메커니즘을 사용하여 가상 주소를 물리적 주소로 변환합니다.
기본 레지스터의 값은 사용자 프로세스에 의해 생성 된 모든 주소에 추가되며 메모리로 전송 될 때 오프셋으로 처리됩니다. 예를 들어, 기본 레지스터 값이 10000이면 사용자가 주소 위치 100을 사용하려는 시도는 위치 10100에 동적으로 재 할당됩니다.
사용자 프로그램은 가상 주소를 다룹니다. 실제 물리적 주소는 볼 수 없습니다.
정적 및 동적 로딩
Static 또는 Dynamic Loading 중 선택은 컴퓨터 프로그램이 개발 될 때 이루어져야합니다. 프로그램을 정적으로로드해야하는 경우 컴파일 할 때 전체 프로그램이 외부 프로그램 또는 모듈 종속성을 남기지 않고 컴파일 및 링크됩니다. 링커는 개체 프로그램과 다른 필수 개체 모듈을 논리 주소도 포함하는 절대 프로그램으로 결합합니다.
동적으로로드 된 프로그램을 작성하는 경우 컴파일러는 프로그램을 컴파일하고 동적으로 포함하려는 모든 모듈에 대해 참조 만 제공되고 나머지 작업은 실행시 수행됩니다.
로딩시 static loading, 절대 프로그램 (및 데이터)이 실행을 시작하기 위해 메모리에로드됩니다.
사용하는 경우 dynamic loading, 라이브러리의 동적 루틴은 재배치 가능한 형식으로 디스크에 저장되며 프로그램에서 필요할 때만 메모리에로드됩니다.
정적 연결과 동적 연결
위에서 설명한 것처럼 정적 링크를 사용할 때 링커는 프로그램에 필요한 다른 모든 모듈을 단일 실행 프로그램으로 결합하여 런타임 종속성을 방지합니다.
동적 연결을 사용하는 경우 실제 모듈이나 라이브러리를 프로그램과 연결할 필요가 없으며 컴파일 및 연결시 동적 모듈에 대한 참조가 제공됩니다. Windows의 DLL (Dynamic Link Libraries)과 Unix의 공유 개체는 동적 라이브러리의 좋은 예입니다.
교환
스와핑은 프로세스를 주 메모리에서 일시적으로 스왑하거나 보조 저장소 (디스크)로 이동하고 해당 메모리를 다른 프로세스에서 사용할 수 있도록하는 메커니즘입니다. 나중에 시스템은 보조 스토리지에서 주 메모리로 프로세스를 다시 스왑합니다.
성능은 일반적으로 스와핑 프로세스의 영향을 받지만 여러 대규모 프로세스를 병렬로 실행하는 데 도움이되며 그 이유가 Swapping is also known as a technique for memory compaction.

스왑 프로세스에 걸리는 총 시간에는 전체 프로세스를 보조 디스크로 이동 한 다음 프로세스를 다시 메모리로 복사하는 데 걸리는 시간과 프로세스가 주 메모리를 다시 확보하는 데 걸리는 시간이 포함됩니다.
사용자 프로세스의 크기가 2048KB이고 스와핑이 발생하는 표준 하드 디스크에서 초당 약 1MB의 데이터 전송 속도를 갖는다 고 가정 해 보겠습니다. 1000K 프로세스를 메모리로 또는 메모리에서 실제로 전송하는 데는
2048KB / 1024KB per second
= 2 seconds
= 2000 milliseconds이제 시작 및 종료 시간을 고려할 때 전체 4000 밀리 초와 프로세스가 주 메모리를 다시 확보하기 위해 경쟁하는 다른 오버 헤드가 필요합니다.
메모리 할당
주 메모리는 일반적으로 두 개의 파티션으로 구성됩니다.
Low Memory − 운영 체제는이 메모리에 상주합니다.
High Memory − 사용자 프로세스는 높은 메모리에 보관됩니다.
운영 체제는 다음과 같은 메모리 할당 메커니즘을 사용합니다.
| SN | 메모리 할당 및 설명 |
|---|---|
| 1 | Single-partition allocation 이러한 유형의 할당에서는 재배치 등록 체계를 사용하여 사용자 프로세스를 서로 보호하고 운영 체제 코드 및 데이터를 변경하지 못하도록합니다. 재배치 레지스터는 가장 작은 물리적 주소의 값을 포함하는 반면 제한 레지스터는 논리적 주소의 범위를 포함합니다. 각 논리 주소는 제한 레지스터보다 작아야합니다. |
| 2 | Multiple-partition allocation 이러한 유형의 할당에서 주 메모리는 각 파티션이 하나의 프로세스 만 포함해야하는 여러 고정 크기 파티션으로 나뉩니다. 파티션이 사용 가능하면 입력 대기열에서 프로세스가 선택되고 사용 가능한 파티션으로로드됩니다. 프로세스가 종료되면 파티션을 다른 프로세스에 사용할 수있게됩니다. |
분열
프로세스가로드되고 메모리에서 제거되면 사용 가능한 메모리 공간이 작은 조각으로 나뉩니다. 때때로 프로세스가 작은 크기를 고려하여 메모리 블록에 할당 될 수없고 메모리 블록이 사용되지 않은 상태로 남아있는 경우가 있습니다. 이 문제를 조각화라고합니다.
조각화는 두 가지 유형이 있습니다.
| SN | 조각화 및 설명 |
|---|---|
| 1 | External fragmentation 총 메모리 공간은 요청을 충족 시키거나 그 안에 프로세스를 상주하기에 충분하지만 연속적이지 않으므로 사용할 수 없습니다. |
| 2 | Internal fragmentation 프로세스에 할당 된 메모리 블록이 더 큽니다. 메모리의 일부는 다른 프로세스에서 사용할 수 없으므로 사용되지 않은 상태로 남아 있습니다. |
다음 다이어그램은 조각화가 메모리 낭비를 유발할 수 있고 압축 기술을 사용하여 조각난 메모리에서 더 많은 여유 메모리를 만드는 방법을 보여줍니다.
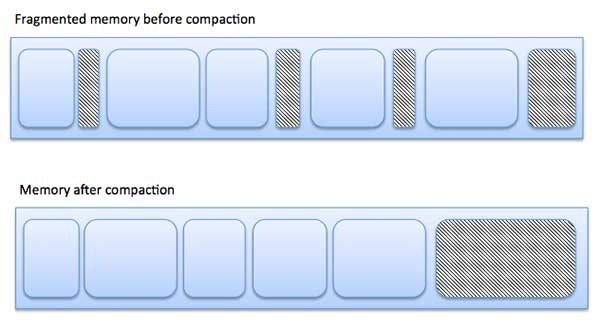
메모리 내용을 압축하거나 셔플하여 모든 여유 메모리를 하나의 큰 블록에 함께 배치하면 외부 조각화를 줄일 수 있습니다. 압축을 가능하게하려면 재배치가 동적이어야합니다.
내부 조각화는 가장 작은 파티션을 효과적으로 할당하지만 프로세스에 충분히 큰 파티션을 할당하여 줄일 수 있습니다.
페이징
컴퓨터는 시스템에 물리적으로 설치된 양보다 더 많은 메모리를 지정할 수 있습니다. 이 추가 메모리는 실제로 가상 메모리라고하며 컴퓨터의 RAM을 에뮬레이트하도록 설정된 하드 부분입니다. 페이징 기술은 가상 메모리 구현에 중요한 역할을합니다.
페이징은 프로세스 주소 공간이 같은 크기의 블록으로 분할되는 메모리 관리 기술입니다. pages(크기는 512 바이트에서 8192 바이트 사이의 2의 제곱입니다.) 프로세스의 크기는 페이지 수로 측정됩니다.
마찬가지로 주 메모리는 고정 된 크기의 작은 (물리적) 메모리 블록으로 나뉩니다. frames 그리고 프레임의 크기는 페이지의 크기와 동일하게 유지되어 메인 메모리를 최적으로 활용하고 외부 조각화를 방지합니다.

주소 번역
페이지 주소가 호출 됨 logical address 그리고 page number 그리고 offset.
Logical Address = Page number + page offset프레임 주소가 호출 됨 physical address 그리고 frame number 그리고 offset.
Physical Address = Frame number + page offset라는 데이터 구조 page map table 프로세스의 페이지와 실제 메모리의 프레임 간의 관계를 추적하는 데 사용됩니다.

시스템이 임의의 페이지에 프레임을 할당하면이 논리 주소를 실제 주소로 변환하고 프로그램 실행 전체에 사용할 페이지 테이블에 항목을 생성합니다.
프로세스가 실행될 때 해당 페이지는 사용 가능한 메모리 프레임에로드됩니다. 8Kb의 프로그램이 있지만 주어진 시점에서 메모리가 5Kb 만 수용 할 수 있다고 가정하면 페이징 개념이 그림에 나타납니다. 컴퓨터의 RAM이 부족하면 운영 체제 (OS)는 유휴 또는 원하지 않는 메모리 페이지를 보조 메모리로 이동하여 다른 프로세스를 위해 RAM을 확보하고 프로그램에서 필요할 때 다시 가져옵니다.
이 프로세스는 OS가 주 메모리에서 유휴 페이지를 계속 제거하고 보조 메모리에 쓰고 프로그램에서 필요할 때 다시 가져 오는 프로그램의 전체 실행 중에 계속됩니다.
페이징의 장점과 단점
다음은 페이징의 장단점 목록입니다.
페이징은 외부 조각화를 줄이지 만 여전히 내부 조각화를 겪습니다.
페이징은 구현이 간단하며 효율적인 메모리 관리 기술로 간주됩니다.
페이지와 프레임의 크기가 같기 때문에 교체가 매우 쉽습니다.
페이지 테이블에는 추가 메모리 공간이 필요하므로 RAM이 작은 시스템에는 적합하지 않을 수 있습니다.
분할
세그먼테이션은 각 작업이 서로 다른 크기의 여러 세그먼트로 나뉘는 메모리 관리 기술입니다. 각 모듈에는 관련 기능을 수행하는 부분이 포함됩니다. 각 세그먼트는 실제로 프로그램의 다른 논리적 주소 공간입니다.
프로세스가 실행될 때 모든 세그먼트가 사용 가능한 메모리의 연속 블록에로드 되더라도 해당 세그먼트가 비 연속 메모리에로드됩니다.
세그먼트 메모리 관리는 페이징과 매우 유사하게 작동하지만 여기서 세그먼트는 페이징 페이지에서와 같이 고정 크기 인 가변 길이입니다.
프로그램 세그먼트에는 프로그램의 주요 기능, 유틸리티 기능, 데이터 구조 등이 포함됩니다. 운영 체제는segment map table모든 프로세스에 대해 세그먼트 번호, 크기 및 주 메모리의 해당 메모리 위치와 함께 사용 가능한 메모리 블록 목록. 각 세그먼트에 대해 테이블은 세그먼트의 시작 주소와 세그먼트의 길이를 저장합니다. 메모리 위치에 대한 참조에는 세그먼트와 오프셋을 식별하는 값이 포함됩니다.

컴퓨터는 시스템에 물리적으로 설치된 양보다 더 많은 메모리를 지정할 수 있습니다. 이 추가 메모리는 실제로virtual memory 컴퓨터의 RAM을 에뮬레이트하도록 설정된 하드 디스크의 한 부분입니다.
이 체계의 주요 눈에 띄는 장점은 프로그램이 실제 메모리보다 클 수 있다는 것입니다. 가상 메모리는 두 가지 용도로 사용됩니다. 첫째, 디스크를 사용하여 물리적 메모리 사용을 확장 할 수 있습니다. 둘째, 각 가상 주소가 물리적 주소로 변환되기 때문에 메모리 보호가 가능합니다.
다음은 전체 프로그램을 메인 메모리에 완전히로드 할 필요가없는 상황입니다.
사용자가 작성한 오류 처리 루틴은 데이터 또는 계산에 오류가 발생한 경우에만 사용됩니다.
프로그램의 특정 옵션 및 기능은 거의 사용되지 않을 수 있습니다.
실제로 적은 양의 테이블 만 사용하더라도 많은 테이블에 고정 된 양의 주소 공간이 할당됩니다.
메모리에 부분적으로 만있는 프로그램을 실행할 수있는 능력은 많은 이점을 상쇄합니다.
각 사용자 프로그램을 메모리에로드하거나 스왑하는 데 필요한 I / O 수가 적습니다.
프로그램은 더 이상 사용 가능한 실제 메모리의 양에 의해 제한되지 않습니다.
각 사용자 프로그램은 실제 메모리를 덜 사용하고 더 많은 프로그램을 동시에 실행할 수 있으며 이에 따라 CPU 사용률 및 처리량이 증가합니다.
범용 사용을위한 최신 마이크로 프로세서, 메모리 관리 장치 또는 MMU가 하드웨어에 내장되어 있습니다. MMU의 역할은 가상 주소를 물리적 주소로 변환하는 것입니다. 기본 예는 다음과 같습니다.
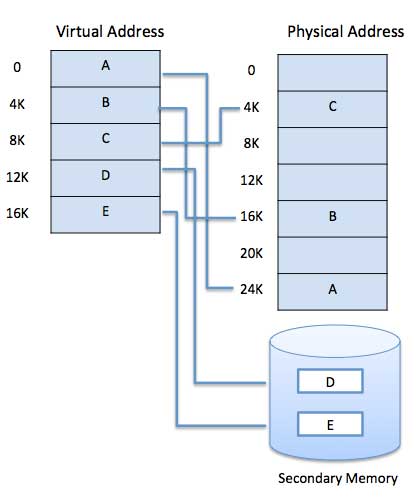
가상 메모리는 일반적으로 요청 페이징으로 구현됩니다. 분할 시스템에서도 구현할 수 있습니다. 수요 세분화를 사용하여 가상 메모리를 제공 할 수도 있습니다.
수요 페이징
수요 페이징 시스템은 프로세스가 보조 메모리에 상주하고 페이지가 미리가 아닌 요청시에만로드되는 스와핑이있는 페이징 시스템과 매우 유사합니다. 컨텍스트 전환이 발생하면 운영 체제는 이전 프로그램의 페이지를 디스크로 복사하지 않거나 새 프로그램의 페이지를 주 메모리로 복사하지 않고 대신 첫 번째 페이지를로드 한 후 새 프로그램을 실행하고이를 가져옵니다. 참조되는 프로그램의 페이지.
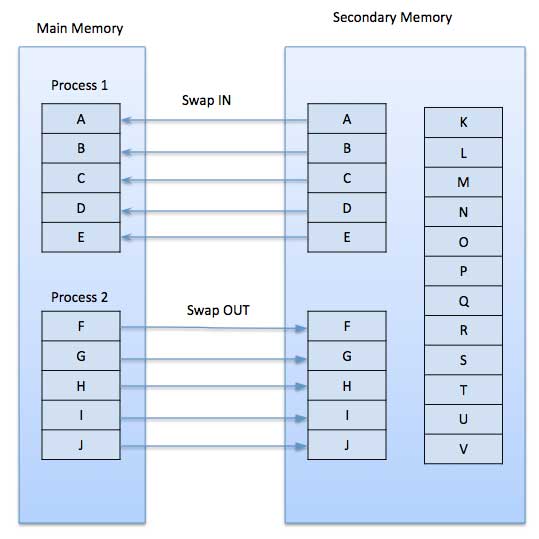
프로그램을 실행하는 동안 프로그램이 주 메모리에서 사용할 수없는 페이지를 참조하면 조금 전에 교체 되었기 때문에 프로세서는이 유효하지 않은 메모리 참조를 page fault 프로그램에서 운영 체제로 제어를 전송하여 페이지를 다시 메모리로 요구합니다.
장점
다음은 Demand Paging의 장점입니다-
- 대용량 가상 메모리.
- 보다 효율적인 메모리 사용.
- 다중 프로그래밍의 정도에는 제한이 없습니다.
단점
페이지 인터럽트를 처리하기위한 테이블 수와 프로세서 오버 헤드 양은 단순 페이지 관리 기술의 경우보다 큽니다.
페이지 교체 알고리즘
페이지 교체 알고리즘은 운영 체제가 스왑 아웃 할 메모리 페이지를 결정하고 메모리 페이지를 할당해야 할 때 디스크에 쓰는 기술입니다. 페이지 폴트가 발생할 때마다 페이징이 발생하고 페이지를 사용할 수 없거나 사용 가능한 페이지 수가 필요한 페이지보다 적다는 이유로 할당 목적으로 사용 가능한 페이지를 사용할 수 없습니다.
교체를 위해 선택되어 페이지 아웃 된 페이지가 다시 참조 될 때 디스크에서 읽어야하므로 I / O 완료가 필요합니다. 이 프로세스는 페이지 교체 알고리즘의 품질을 결정합니다. 페이지 인을 기다리는 시간이 짧을수록 알고리즘이 좋습니다.
페이지 교체 알고리즘은 하드웨어에서 제공하는 페이지 액세스에 대한 제한된 정보를 확인하고, 총 페이지 누락 수를 최소화하기 위해 교체해야하는 페이지를 선택하는 동시에 알고리즘의 기본 스토리지 비용 및 프로세서 시간과 균형을 유지합니다. 그 자체. 다양한 페이지 교체 알고리즘이 있습니다. 특정 메모리 참조 문자열에서 알고리즘을 실행하고 페이지 오류 수를 계산하여 알고리즘을 평가합니다.
참조 문자열
메모리 참조 문자열을 참조 문자열이라고합니다. 참조 문자열은 인위적으로 또는 주어진 시스템을 추적하고 각 메모리 참조의 주소를 기록하여 생성됩니다. 후자의 선택은 많은 수의 데이터를 생성하는데, 여기서 두 가지를 주목합니다.
주어진 페이지 크기에 대해 전체 주소가 아닌 페이지 번호 만 고려하면됩니다.
페이지에 대한 참조가있는 경우 p, 페이지에 대한 바로 다음 참조 p페이지 오류가 발생하지 않습니다. 페이지 p는 첫 번째 참조 후 메모리에 있습니다. 바로 다음 참조는 잘못되지 않습니다.
예를 들어, 다음 주소 시퀀스를 고려하십시오-123,215,600,1234,76,96
페이지 크기가 100이면 참조 문자열은 1,2,6,12,0,0입니다.
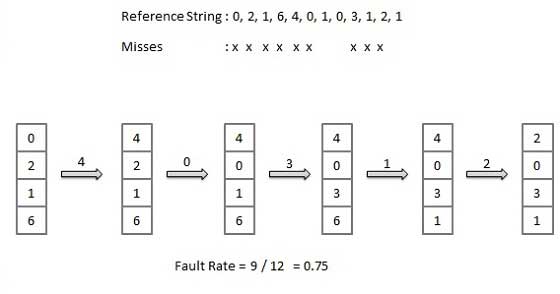
선입 선출 (FIFO) 알고리즘
메인 메모리에서 가장 오래된 페이지는 교체를 위해 선택되는 페이지입니다.
구현하기 쉽고, 목록을 유지하고, 꼬리부터 페이지를 교체하고, 헤드에 새 페이지를 추가합니다.
최적의 페이지 알고리즘
최적의 페이지 교체 알고리즘은 모든 알고리즘 중 페이지 오류율이 가장 낮습니다. 최적의 페이지 교체 알고리즘이 있으며 OPT 또는 MIN이라고합니다.
가장 오랫동안 사용하지 않을 페이지를 교체하십시오. 페이지를 사용할 시간을 사용하십시오.

LRU (Least Recent Used) 알고리즘
메인 메모리에서 가장 오랫동안 사용하지 않은 페이지가 교체 대상으로 선택됩니다.
구현하기 쉽고, 목록을 유지하고, 시간을 거슬러 올라가 페이지를 교체합니다.

페이지 버퍼링 알고리즘
- 프로세스를 빠르게 시작하려면 여유 프레임 풀을 유지하십시오.
- 페이지 폴트에서 교체 할 페이지를 선택하십시오.
- 여유 풀 프레임에 새 페이지를 작성하고 페이지 테이블을 표시 한 후 프로세스를 다시 시작하십시오.
- 이제 디스크에서 더티 페이지를 쓰고 교체 된 페이지를 유지하는 프레임을 여유 풀에 배치합니다.
최소 사용 빈도 (LFU) 알고리즘
가장 적은 수의 페이지가 교체를 위해 선택되는 페이지입니다.
이 알고리즘은 프로세스의 초기 단계에서 페이지가 많이 사용되었지만 다시 사용되지 않는 상황에서 어려움을 겪습니다.
가장 자주 사용되는 (MFU) 알고리즘
이 알고리즘은 개수가 가장 작은 페이지가 방금 가져온 것일 수 있으며 아직 사용되지 않았다는 주장을 기반으로합니다.
운영 체제의 중요한 작업 중 하나는 마우스, 키보드, 터치 패드, 디스크 드라이브, 디스플레이 어댑터, USB 장치, 비트 맵 화면, LED, 아날로그-디지털 변환기, 켜기 / 끄기 등 다양한 I / O 장치를 관리하는 것입니다. 오프 스위치, 네트워크 연결, 오디오 I / O, 프린터 등
I / O 시스템은 응용 프로그램 I / O 요청을 받아 물리적 장치로 보낸 다음 장치에서 오는 응답을 받아 응용 프로그램으로 보내야합니다. I / O 장치는 두 가지 범주로 나눌 수 있습니다.
Block devices− 블록 장치는 드라이버가 전체 데이터 블록을 전송하여 통신하는 장치입니다. 예를 들어, 하드 디스크, USB 카메라, Disk-On-Key 등
Character devices− 문자 장치는 드라이버가 단일 문자 (바이트, 옥텟)를 송수신하여 통신하는 장치입니다. 예 : 직렬 포트, 병렬 포트, 사운드 카드 등
장치 컨트롤러
장치 드라이버는 특정 장치를 처리하기 위해 OS에 연결할 수있는 소프트웨어 모듈입니다. 운영 체제는 모든 I / O 장치를 처리하기 위해 장치 드라이버의 도움을받습니다.
장치 컨트롤러는 장치와 장치 드라이버 간의 인터페이스처럼 작동합니다. I / O 장치 (키보드, 마우스, 프린터 등)는 일반적으로 기계 부품과 전자 부품을 장치 컨트롤러라고하는 전자 부품으로 구성됩니다.
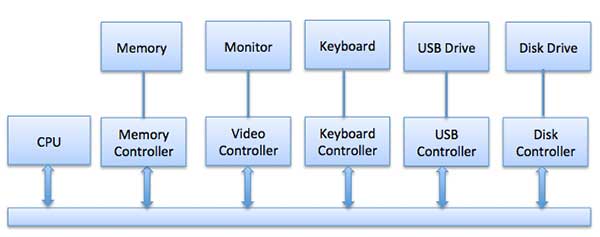
운영 체제와 통신하기위한 각 장치에는 항상 장치 컨트롤러와 장치 드라이버가 있습니다. 장치 컨트롤러는 여러 장치를 처리 할 수 있습니다. 인터페이스로서의 주요 임무는 직렬 비트 스트림을 바이트 블록으로 변환하고 필요에 따라 오류 수정을 수행하는 것입니다.
컴퓨터에 연결된 모든 장치는 플러그와 소켓으로 연결되고 소켓은 장치 컨트롤러에 연결됩니다. 다음은 CPU와 장치 컨트롤러가 모두 통신을 위해 공통 버스를 사용하는 CPU, 메모리, 컨트롤러 및 I / O 장치를 연결하는 모델입니다.
동기식 대 비동기식 I / O
Synchronous I/O −이 방식에서 CPU 실행은 I / O가 진행되는 동안 대기합니다.
Asynchronous I/O − I / O는 CPU 실행과 동시에 진행됩니다.
I / O 장치와의 통신
CPU에는 I / O 장치와 정보를주고받을 수있는 방법이 있어야합니다. CPU 및 장치와 통신하는 데 사용할 수있는 세 가지 접근 방식이 있습니다.
- 특수 명령 I / O
- 메모리 매핑 된 I / O
- 직접 메모리 액세스 (DMA)
특수 명령 I / O
이것은 I / O 장치를 제어하기 위해 특별히 만들어진 CPU 명령어를 사용합니다. 이러한 명령어를 사용하면 일반적으로 데이터를 I / O 장치로 보내거나 I / O 장치에서 읽을 수 있습니다.
메모리 매핑 된 I / O
메모리 매핑 된 I / O를 사용할 때 메모리와 I / O 장치가 동일한 주소 공간을 공유합니다. 이 장치는 특정 주 메모리 위치에 직접 연결되므로 I / O 장치는 CPU를 거치지 않고 메모리에서 데이터 블록을 전송할 수 있습니다.
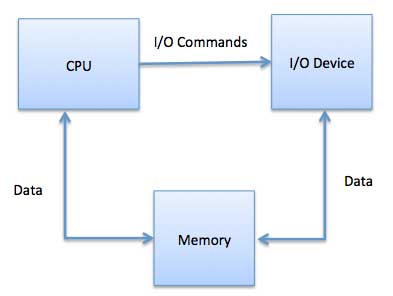
메모리 매핑 된 IO를 사용하는 동안 OS는 메모리에 버퍼를 할당하고 해당 버퍼를 사용하여 CPU로 데이터를 전송하도록 I / O 장치에 알립니다. I / O 장치는 CPU와 비동기 적으로 작동하며 완료되면 CPU를 중단합니다.
이 방법의 장점은 메모리에 액세스 할 수있는 모든 명령을 I / O 장치를 조작하는 데 사용할 수 있다는 것입니다. 메모리 매핑 IO는 디스크, 통신 인터페이스와 같은 대부분의 고속 I / O 장치에 사용됩니다.
직접 메모리 액세스 (DMA)
키보드와 같은 느린 장치는 각 바이트가 전송 된 후 메인 CPU에 인터럽트를 생성합니다. 디스크와 같은 고속 장치가 각 바이트에 대해 인터럽트를 생성하면 운영 체제는 이러한 인터럽트를 처리하는 데 대부분의 시간을 소비합니다. 따라서 일반적인 컴퓨터는이 오버 헤드를 줄이기 위해 직접 메모리 액세스 (DMA) 하드웨어를 사용합니다.
직접 메모리 액세스 (DMA)는 CPU가 개입없이 메모리에서 읽거나 메모리에 쓸 수있는 I / O 모듈 권한을 부여 함을 의미합니다. DMA 모듈 자체는 메인 메모리와 I / O 장치 간의 데이터 교환을 제어합니다. CPU는 전송의 시작과 끝에 만 관여하고 전체 블록이 전송 된 후에 만 중단됩니다.
직접 메모리 액세스에는 데이터 전송을 관리하고 시스템 버스에 대한 액세스를 중재하는 DMA 컨트롤러 (DMAC)라는 특수 하드웨어가 필요합니다. 컨트롤러는 소스 및 대상 포인터 (데이터 읽기 / 쓰기 위치), 전송 된 바이트 수를 추적하는 카운터, I / O 및 메모리 유형, CPU주기에 대한 인터럽트 및 상태를 포함하는 설정으로 프로그래밍됩니다.
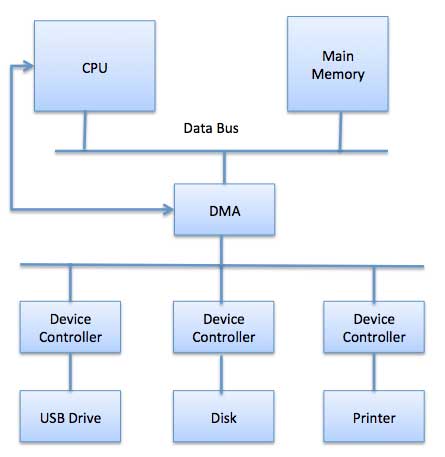
운영 체제는 다음과 같이 DMA 하드웨어를 사용합니다-
| 단계 | 기술 |
|---|---|
| 1 | 장치 드라이버는 디스크 데이터를 버퍼 주소 X로 전송하라는 지시를받습니다. |
| 2 | 그런 다음 장치 드라이버는 디스크 컨트롤러에 데이터를 버퍼로 전송하도록 지시합니다. |
| 삼 | 디스크 컨트롤러는 DMA 전송을 시작합니다. |
| 4 | 디스크 컨트롤러는 각 바이트를 DMA 컨트롤러로 보냅니다. |
| 5 | DMA 컨트롤러는 바이트를 버퍼로 전송하고 메모리 주소를 늘리고 C가 0이 될 때까지 카운터 C를 줄입니다. |
| 6 | C가 0이되면 DMA는 CPU를 인터럽트하여 전송 완료 신호를 보냅니다. |
폴링 vs 인터럽트 I / O
컴퓨터에는 모든 유형의 입력이 도착하는 것을 감지하는 방법이 있어야합니다. 이것이 발생할 수있는 두 가지 방법이 있습니다.polling 과 interrupts. 이 두 기술을 사용하면 프로세서는 언제든지 발생할 수 있고 현재 실행중인 프로세스와 관련이없는 이벤트를 처리 할 수 있습니다.
I / O 폴링
폴링은 I / O 장치가 프로세서와 통신하는 가장 간단한 방법입니다. 주기적으로 장치의 상태를 확인하여 다음 I / O 작업 시간인지 확인하는 프로세스를 폴링이라고합니다. I / O 장치는 정보를 상태 레지스터에 저장하기 만하면 프로세서가 와서 정보를 가져와야합니다.
대부분의 경우 장치는주의가 필요하지 않으며주의가 필요하면 다음에 폴링 프로그램에서 조사 할 때까지 기다려야합니다. 이것은 비효율적 인 방법이며 불필요한 폴링에 많은 프로세서 시간이 낭비됩니다.
이 방법을 수업의 모든 학생에게 계속해서 도움이 필요한지 묻는 교사와 비교하십시오. 분명히 더 효율적인 방법은 학생이 도움이 필요할 때마다 교사에게 알리는 것입니다.
I / O 중단
I / O를 처리하는 또 다른 방법은 인터럽트 구동 방식입니다. 인터럽트는주의가 필요한 장치에서 마이크로 프로세서로 보내는 신호입니다.
장치 컨트롤러는 CPU가 인터럽트를 수신 할 때 CPU의주의가 필요할 때 버스에 인터럽트 신호를 보내고, 현재 상태를 저장하고 인터럽트 벡터 (다양한 이벤트를 처리하기위한 OS 루틴의 주소)를 사용하여 적절한 인터럽트 핸들러를 호출합니다. 중단 장치가 처리되면 CPU는 중단되지 않은 것처럼 원래 작업을 계속합니다.
I / O 소프트웨어는 종종 다음 계층으로 구성됩니다.
User Level Libraries− 입력 및 출력을 수행하기 위해 사용자 프로그램에 간단한 인터페이스를 제공합니다. 예를 들면stdio C 및 C ++ 프로그래밍 언어에서 제공하는 라이브러리입니다.
Kernel Level Modules − 이것은 장치 드라이버가 사용하는 장치 컨트롤러 및 장치 독립 I / O 모듈과 상호 작용할 수있는 장치 드라이버를 제공합니다.
Hardware −이 계층에는 장치 드라이버와 상호 작용하고 하드웨어를 활성화하는 실제 하드웨어 및 하드웨어 컨트롤러가 포함됩니다.
I / O 소프트웨어 설계의 핵심 개념은 장치를 미리 지정하지 않고도 모든 I / O 장치에 액세스 할 수있는 프로그램을 작성할 수 있어야하는 장치 독립적이어야한다는 것입니다. 예를 들어, 파일을 입력으로 읽는 프로그램은 각기 다른 장치에 대해 프로그램을 수정하지 않고도 플로피 디스크, 하드 디스크 또는 CD-ROM에있는 파일을 읽을 수 있어야합니다.
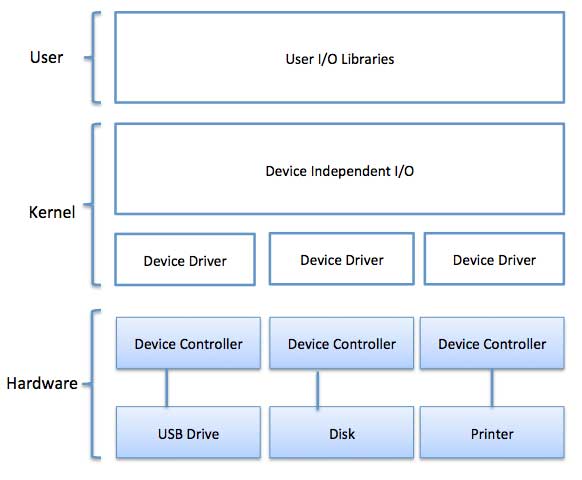
장치 드라이버
장치 드라이버는 특정 장치를 처리하기 위해 OS에 연결할 수있는 소프트웨어 모듈입니다. 운영 체제는 모든 I / O 장치를 처리하기 위해 장치 드라이버의 도움을받습니다. 장치 드라이버는 장치 별 코드를 캡슐화하고 코드에 장치 별 레지스터 읽기 / 쓰기를 포함하는 방식으로 표준 인터페이스를 구현합니다. 장치 드라이버는 일반적으로 장치 제조업체에서 작성하고 장치와 함께 CD-ROM으로 제공됩니다.
장치 드라이버는 다음 작업을 수행합니다.
- 위의 장치 독립 소프트웨어에서 요청을 수락합니다.
- 장치 컨트롤러와 상호 작용하여 I / O를 가져 와서 필요한 오류 처리를 수행합니다.
- 요청이 성공적으로 실행되었는지 확인
장치 드라이버가 요청을 처리하는 방법은 다음과 같습니다. 요청이 블록 N을 읽는다고 가정합니다. 요청이 도착할 때 드라이버가 유휴 상태이면 요청을 즉시 수행하기 시작합니다. 그렇지 않고 드라이버가 이미 다른 요청으로 사용 중이면 보류중인 요청 대기열에 새 요청을 넣습니다.
인터럽트 핸들러
인터럽트 서비스 루틴 또는 ISR이라고도하는 인터럽트 핸들러는 소프트웨어의 한 부분이거나보다 구체적으로 운영 체제 또는보다 구체적으로 장치 드라이버의 콜백 함수이며, 그 실행은 인터럽트 수신에 의해 트리거됩니다.
인터럽트가 발생하면 인터럽트 프로시 저는 인터럽트를 처리하고 데이터 구조를 업데이트하며 인터럽트가 발생하기를 기다리는 프로세스를 깨우기 위해 필요한 모든 작업을 수행합니다.
인터럽트 메커니즘은 작은 집합에서 특정 인터럽트 처리 루틴 / 기능을 선택하는 번호 인 주소를받습니다. 대부분의 아키텍처에서이 주소는 인터럽트 벡터 테이블이라는 테이블에 저장된 오프셋입니다. 이 벡터는 특수 인터럽트 핸들러의 메모리 주소를 포함합니다.
장치 독립적 I / O 소프트웨어
장치 독립 소프트웨어의 기본 기능은 모든 장치에 공통적 인 I / O 기능을 수행하고 사용자 수준 소프트웨어에 일관된 인터페이스를 제공하는 것입니다. 완전히 장치 독립적 인 소프트웨어를 작성하는 것은 어렵지만 모든 장치에 공통되는 일부 모듈을 작성할 수 있습니다. 다음은 장치 독립적 I / O 소프트웨어의 기능 목록입니다.
- 장치 드라이버를위한 균일 한 인터페이스
- 장치 이름 지정-주 및 부 장치 번호에 매핑 된 니모닉 이름
- 장치 보호
- 장치 독립적 인 블록 크기 제공
- 장치에서 나오는 데이터를 최종 대상에 저장할 수 없기 때문에 버퍼링합니다.
- 블록 장치에 대한 스토리지 할당
- 전용 장치 할당 및 해제
- 오류보고
사용자 공간 I / O 소프트웨어
이들은 커널의 기능에 액세스하거나 궁극적으로 장치 드라이버와 상호 작용할 수 있도록 더 풍부하고 단순화 된 인터페이스를 제공하는 라이브러리입니다. 대부분의 사용자 수준 I / O 소프트웨어는 다중 프로그래밍 시스템에서 전용 I / O 장치를 처리하는 방법 인 스풀링 시스템과 같은 일부 예외를 제외하고 라이브러리 프로 시저로 구성됩니다.
I / O 라이브러리 (예 : stdio)는 OS 상주 장치 독립적 I / O SW에 인터페이스를 제공하기 위해 사용자 공간에 있습니다. 예를 들어 putchar (), getchar (), printf () 및 scanf ()는 C 프로그래밍에서 사용할 수있는 사용자 수준 I / O 라이브러리 stdio의 예입니다.
커널 I / O 하위 시스템
커널 I / O 서브 시스템은 I / O와 관련된 많은 서비스를 제공 할 책임이 있습니다. 다음은 제공되는 서비스 중 일부입니다.
Scheduling− Kernel은 일련의 I / O 요청을 예약하여 실행 순서를 결정합니다. 애플리케이션이 차단 I / O 시스템 호출을 발행하면 요청이 해당 장치의 대기열에 배치됩니다. 커널 I / O 스케줄러는 전체 시스템 효율성과 애플리케이션에서 경험하는 평균 응답 시간을 개선하기 위해 대기열의 순서를 다시 정렬합니다.
Buffering − 커널 I / O 하위 시스템은 다음과 같은 메모리 영역을 유지합니다. buffer두 장치간에 또는 애플리케이션 작업이있는 장치간에 전송되는 동안 데이터를 저장합니다. 버퍼링은 데이터 스트림의 생산자와 소비자 간의 속도 불일치에 대처하거나 데이터 전송 크기가 다른 장치간에 적응하기 위해 수행됩니다.
Caching− Kernel은 데이터 사본을 보유하는 고속 메모리 영역 인 캐시 메모리를 유지합니다. 캐시 된 사본에 대한 액세스는 원본에 대한 액세스보다 더 효율적입니다.
Spooling and Device Reservation− 스풀은 인터리브 된 데이터 스트림을 수용 할 수없는 프린터와 같은 장치에 대한 출력을 보유하는 버퍼입니다. 스풀링 시스템은 대기열에있는 스풀 파일을 한 번에 하나씩 프린터로 복사합니다. 일부 운영 체제에서 스풀링은 시스템 데몬 프로세스에 의해 관리됩니다. 다른 운영 체제에서는 커널 스레드에서 처리됩니다.
Error Handling − 보호 된 메모리를 사용하는 운영 체제는 다양한 종류의 하드웨어 및 응용 프로그램 오류로부터 보호 할 수 있습니다.
파일
파일은 자기 디스크, 자기 테이프 및 광 디스크와 같은 보조 저장소에 기록되는 명명 된 관련 정보 모음입니다. 일반적으로 파일은 파일 작성자와 사용자가 의미를 정의하는 일련의 비트, 바이트, 행 또는 레코드입니다.
파일 구조
파일 구조는 운영 체제가 이해할 수있는 필수 형식을 따라야합니다.
파일은 유형에 따라 특정 구조가 정의되어 있습니다.
텍스트 파일은 줄로 구성된 일련의 문자입니다.
소스 파일은 일련의 절차 및 기능입니다.
오브젝트 파일은 기계가 이해할 수있는 블록으로 구성된 일련의 바이트입니다.
운영 체제가 다른 파일 구조를 정의 할 때 이러한 파일 구조를 지원하는 코드도 포함합니다. Unix, MS-DOS는 최소 파일 구조 수를 지원합니다.
파일 유형
파일 유형은 텍스트 파일 소스 파일 및 이진 파일 등과 같은 다양한 유형의 파일을 구별하는 운영 체제의 기능을 나타냅니다. 많은 운영 체제는 많은 유형의 파일을 지원합니다. MS-DOS 및 UNIX와 같은 운영 체제에는 다음과 같은 유형의 파일이 있습니다.
일반 파일
- 사용자 정보가 포함 된 파일입니다.
- 여기에는 텍스트, 데이터베이스 또는 실행 프로그램이있을 수 있습니다.
- 사용자는 전체 파일 추가, 수정, 삭제 또는 제거와 같은 다양한 작업을 파일에 적용 할 수 있습니다.
디렉토리 파일
- 이러한 파일에는 파일 이름 목록 및 이러한 파일과 관련된 기타 정보가 포함되어 있습니다.
특수 파일
- 이러한 파일을 장치 파일이라고도합니다.
- 이러한 파일은 디스크, 터미널, 프린터, 네트워크, 테이프 드라이브 등과 같은 물리적 장치를 나타냅니다.
이 파일은 두 가지 유형이 있습니다.
Character special files − 데이터는 단말기 또는 프린터의 경우와 같이 문자별로 처리됩니다.
Block special files − 데이터는 디스크와 테이프의 경우처럼 블록 단위로 처리됩니다.
파일 액세스 메커니즘
파일 액세스 메커니즘은 파일 레코드에 액세스 할 수있는 방식을 나타냅니다. 파일에 액세스하는 방법에는 여러 가지가 있습니다.
- 순차 액세스
- 직접 / 무작위 액세스
- 인덱스 된 순차 액세스
순차 액세스
순차 액세스는 레코드가 어떤 순서로 액세스되는 것입니다. 즉, 파일의 정보가 순서대로 한 레코드 씩 처리됩니다. 이 액세스 방법은 가장 원시적 인 방법입니다. 예 : 컴파일러는 일반적으로 이러한 방식으로 파일에 액세스합니다.
직접 / 무작위 액세스
랜덤 액세스 파일 구성은 레코드에 직접 액세스하여 제공합니다.
각 레코드는 읽기 또는 쓰기를 위해 직접 액세스 할 수있는 도움으로 파일에 고유 한 주소를 가지고 있습니다.
레코드는 파일 내에서 어떤 순서로도 될 필요가 없으며 저장 매체의 인접한 위치에있을 필요도 없습니다.
인덱스 된 순차 액세스
- 이 메커니즘은 순차 액세스를 기반으로 구축됩니다.
- 다양한 블록에 대한 포인터를 포함하는 각 파일에 대해 인덱스가 생성됩니다.
- 인덱스는 순차적으로 검색되며 포인터는 파일에 직접 액세스하는 데 사용됩니다.
공간 할당
파일은 운영 체제에 의해 할당 된 디스크 공간입니다. 운영 체제는 파일에 디스크 공간을 할당하는 세 가지 주요 방법에 따라 배포됩니다.
- 연속 할당
- 연결된 할당
- 인덱싱 된 할당
연속 할당
- 각 파일은 디스크에서 연속 된 주소 공간을 차지합니다.
- 할당 된 디스크 주소는 선형 순서입니다.
- 구현하기 쉽습니다.
- 외부 조각화는 이러한 유형의 할당 기술에서 중요한 문제입니다.
연결된 할당
- 각 파일에는 디스크 블록에 대한 링크 목록이 있습니다.
- 디렉토리에는 파일의 첫 번째 블록에 대한 링크 / 포인터가 있습니다.
- 외부 조각화 없음
- 순차 액세스 파일에서 효과적으로 사용됩니다.
- 직접 액세스 파일의 경우 비효율적입니다.
인덱싱 된 할당
- 연속 및 링크 할당 문제에 대한 솔루션을 제공합니다.
- 파일에 대한 모든 포인터가있는 인덱스 블록이 생성됩니다.
- 각 파일에는 파일이 차지하는 디스크 공간의 주소를 저장하는 자체 인덱스 블록이 있습니다.
- 디렉토리에는 파일의 인덱스 블록 주소가 포함됩니다.
보안은 CPU, 메모리, 디스크, 소프트웨어 프로그램 및 가장 중요한 컴퓨터 시스템에 저장된 데이터 / 정보와 같은 컴퓨터 시스템 리소스에 보호 시스템을 제공하는 것을 말합니다. 권한이없는 사용자가 컴퓨터 프로그램을 실행하면 컴퓨터 나 그 안에 저장된 데이터에 심각한 손상을 줄 수 있습니다. 따라서 컴퓨터 시스템은 무단 액세스, 시스템 메모리에 대한 악의적 인 액세스, 바이러스, 웜 등으로부터 보호되어야합니다.이 장에서는 다음 주제에 대해 논의 할 것입니다.
- Authentication
- 일회용 암호
- 프로그램 위협
- 시스템 위협
- 컴퓨터 보안 분류
입증
인증은 시스템의 각 사용자를 식별하고 실행중인 프로그램을 해당 사용자와 연결하는 것을 의미합니다. 특정 프로그램을 실행하는 사용자의 인증을 보장하는 보호 시스템을 만드는 것은 운영 체제의 책임입니다. 운영 체제는 일반적으로 다음 세 가지 방법을 사용하여 사용자를 식별 / 인증합니다.
Username / Password − 사용자는 시스템에 로그인하기 위해 운영 체제에 등록 된 사용자 이름과 암호를 입력해야합니다.
User card/key − 사용자는 카드 슬롯에 카드를 펀칭하거나 운영 체제에서 제공하는 옵션에 키 생성기에서 생성 된 키를 입력하여 시스템에 로그인해야합니다.
User attribute - fingerprint/ eye retina pattern/ signature − 사용자는 시스템에 로그인하기 위해 운영 체제에서 사용하는 지정된 입력 장치를 통해 자신의 속성을 전달해야합니다.
일회용 암호
일회용 암호는 일반 인증과 함께 추가 보안을 제공합니다. 일회용 암호 시스템에서는 사용자가 시스템에 로그인을 시도 할 때마다 고유 한 암호가 필요합니다. 일회용 암호를 사용하면 다시 사용할 수 없습니다. 일회용 비밀번호는 다양한 방식으로 구현됩니다.
Random numbers− 사용자에게는 해당 알파벳과 함께 숫자가 인쇄 된 카드가 제공됩니다. 시스템은 무작위로 선택한 몇 개의 알파벳에 해당하는 숫자를 요청합니다.
Secret key− 사용자에게는 사용자 ID와 매핑 된 비밀 ID를 생성 할 수있는 하드웨어 장치가 제공됩니다. 시스템은 로그인하기 전에 매번 생성 될 비밀 ID를 요청합니다.
Network password − 일부 상용 애플리케이션은 등록 된 모바일 / 이메일을 통해 사용자에게 로그인 전에 입력해야하는 일회용 비밀번호를 보냅니다.
프로그램 위협
운영 체제의 프로세스와 커널은 지시에 따라 지정된 작업을 수행합니다. 사용자 프로그램이 이러한 프로세스를 악의적 인 작업으로 만들면 다음과 같이 알려져 있습니다.Program Threats. 프로그램 위협의 일반적인 예 중 하나는 네트워크를 통해 일부 해커에게 사용자 자격 증명을 저장하고 보낼 수있는 컴퓨터에 설치된 프로그램입니다. 다음은 잘 알려진 프로그램 위협의 목록입니다.
Trojan Horse − 이러한 프로그램은 사용자 로그인 자격 증명을 트랩하여 나중에 컴퓨터에 로그인 할 수 있고 시스템 리소스에 액세스 할 수있는 악의적 인 사용자에게 전송하도록 저장합니다.
Trap Door − 필요에 따라 작동하도록 설계된 프로그램이 코드에 보안 허점을 가지고 사용자 모르게 불법 행위를 수행하면 트랩 도어가 호출됩니다.
Logic Bomb− 논리 폭탄은 특정 조건이 충족 될 때만 프로그램이 오작동하는 상황입니다. 그렇지 않으면 정품 프로그램으로 작동합니다. 감지하기가 더 어렵습니다.
Virus− 이름에서 알 수 있듯이 바이러스는 컴퓨터 시스템에서 스스로 복제 할 수 있습니다. 그들은 매우 위험하며 사용자 파일, 충돌 시스템을 수정 / 삭제할 수 있습니다. 바이러스는 일반적으로 프로그램에 포함 된 작은 코드입니다. 사용자가 프로그램에 액세스하면 바이러스가 다른 파일 / 프로그램에 포함되기 시작하여 사용자가 시스템을 사용할 수 없게 만들 수 있습니다.
시스템 위협
시스템 위협이란 시스템 서비스 및 네트워크 연결을 잘못 사용하여 사용자를 문제에 빠뜨리는 것을 말합니다. 시스템 위협은 프로그램 공격이라고하는 완전한 네트워크에서 프로그램 위협을 시작하는 데 사용될 수 있습니다. 시스템 위협은 운영 체제 리소스 / 사용자 파일이 오용되는 환경을 만듭니다. 다음은 잘 알려진 시스템 위협의 목록입니다.
Worm− 웜은 시스템 리소스를 극도로 사용하여 시스템 성능을 저하시킬 수있는 프로세스입니다. Worm 프로세스는 각 복사본이 시스템 리소스를 사용하는 여러 복사본을 생성하여 다른 모든 프로세스가 필요한 리소스를 얻지 못하도록합니다. 웜 프로세스는 전체 네트워크를 종료 할 수도 있습니다.
Port Scanning − 포트 스캐닝은 해커가 시스템 취약성을 탐지하여 시스템을 공격 할 수있는 메커니즘 또는 수단입니다.
Denial of Service− 서비스 거부 공격은 일반적으로 사용자가 시스템을 합법적으로 사용하는 것을 방지합니다. 예를 들어 서비스 거부가 브라우저의 콘텐츠 설정을 공격하면 사용자가 인터넷을 사용하지 못할 수 있습니다.
컴퓨터 보안 분류
미국 국방부의 신뢰할 수있는 컴퓨터 시스템 평가 기준에 따라 컴퓨터 시스템에는 A, B, C, D의 네 가지 보안 등급이 있습니다. 이는 시스템 및 보안 솔루션의 보안을 결정하고 모델링하는 데 널리 사용되는 사양입니다. 다음은 각 분류에 대한 간략한 설명입니다.
| SN | 분류 유형 및 설명 |
|---|---|
| 1 | Type A 최고 수준. 공식적인 설계 사양 및 검증 기술을 사용합니다. 프로세스 보안에 대한 높은 수준의 보증을 부여합니다. |
| 2 | Type B 필수 보호 시스템을 제공합니다. 클래스 C2 시스템의 모든 속성을 갖습니다. 각 개체에 민감도 레이블을 부착합니다. 그것은 세 가지 유형입니다.
|
| 삼 | Type C 감사 기능을 사용하여 보호 및 사용자 책임을 제공합니다. 두 가지 유형이 있습니다.
|
| 4 | Type D 가장 낮은 단계. 최소한의 보호. MS-DOS, Window 3.1이이 범주에 속합니다. |
Linux는 널리 사용되는 UNIX 운영 체제 버전 중 하나입니다. 소스 코드를 자유롭게 사용할 수 있으므로 오픈 소스입니다. 사용은 무료입니다. Linux는 UNIX 호환성을 고려하여 설계되었습니다. 기능 목록은 UNIX와 매우 유사합니다.
Linux 시스템의 구성 요소
Linux 운영 체제에는 주로 세 가지 구성 요소가 있습니다.
Kernel− 커널은 Linux의 핵심 부분입니다. 이 운영 체제의 모든 주요 활동을 담당합니다. 다양한 모듈로 구성되며 기본 하드웨어와 직접 상호 작용합니다. 커널은 시스템 또는 응용 프로그램에 대한 낮은 수준의 하드웨어 세부 정보를 숨기는 데 필요한 추상화를 제공합니다.
System Library− 시스템 라이브러리는 응용 프로그램 또는 시스템 유틸리티가 커널의 기능에 액세스하는 데 사용하는 특수 기능 또는 프로그램입니다. 이러한 라이브러리는 운영 체제의 대부분의 기능을 구현하며 커널 모듈의 코드 액세스 권한이 필요하지 않습니다.
System Utility − 시스템 유틸리티 프로그램은 전문화 된 개별 수준의 작업을 수행 할 책임이 있습니다.

커널 모드와 사용자 모드
커널 구성 요소 코드는 다음과 같은 특수 권한 모드에서 실행됩니다. kernel mode컴퓨터의 모든 리소스에 대한 전체 액세스 권한이 있습니다. 이 코드는 단일 프로세스를 나타내며 단일 주소 공간에서 실행되며 컨텍스트 전환이 필요하지 않으므로 매우 효율적이고 빠릅니다. 커널은 각 프로세스를 실행하고 프로세스에 시스템 서비스를 제공하고 프로세스에 대한 하드웨어 액세스를 보호합니다.
커널 모드에서 실행하는 데 필요하지 않은 지원 코드는 시스템 라이브러리에 있습니다. 사용자 프로그램 및 기타 시스템 프로그램은User Mode시스템 하드웨어 및 커널 코드에 액세스 할 수 없습니다. 사용자 프로그램 / 유틸리티는 시스템 라이브러리를 사용하여 커널 기능에 액세스하여 시스템의 하위 수준 작업을 가져옵니다.
기본 기능
다음은 Linux 운영 체제의 몇 가지 중요한 기능입니다.
Portable− 이식성은 소프트웨어가 다른 유형의 하드웨어에서 동일한 방식으로 작동 할 수 있음을 의미합니다. Linux 커널 및 응용 프로그램은 모든 종류의 하드웨어 플랫폼에 설치를 지원합니다.
Open Source− Linux 소스 코드는 무료로 제공되며 커뮤니티 기반 개발 프로젝트입니다. 여러 팀이 공동으로 작업하여 Linux 운영 체제의 기능을 향상시키고 있으며 지속적으로 발전하고 있습니다.
Multi-User − Linux는 다중 사용자 시스템으로 여러 사용자가 메모리 / 램 / 응용 프로그램과 같은 시스템 리소스에 동시에 액세스 할 수 있습니다.
Multiprogramming − Linux는 다중 프로그래밍 시스템으로 여러 응용 프로그램을 동시에 실행할 수 있습니다.
Hierarchical File System − Linux는 시스템 파일 / 사용자 파일이 정렬 된 표준 파일 구조를 제공합니다.
Shell− Linux는 운영 체제의 명령을 실행하는 데 사용할 수있는 특수 인터프리터 프로그램을 제공합니다. 다양한 유형의 작업을 수행하고 응용 프로그램을 호출하는 데 사용할 수 있습니다. 기타
Security − Linux는 암호 보호 / 특정 파일에 대한 액세스 제어 / 데이터 암호화와 같은 인증 기능을 사용하여 사용자 보안을 제공합니다.
건축물
다음 그림은 Linux 시스템의 아키텍처를 보여줍니다.

Linux 시스템의 아키텍처는 다음 계층으로 구성됩니다.
Hardware layer − 하드웨어는 모든 주변 장치 (RAM / HDD / CPU 등)로 구성됩니다.
Kernel − 운영 체제의 핵심 구성 요소이며 하드웨어와 직접 상호 작용하며 상위 계층 구성 요소에 낮은 수준의 서비스를 제공합니다.
Shell− 커널에 대한 인터페이스로 사용자에게 커널 기능의 복잡성을 숨 깁니다. 쉘은 사용자로부터 명령을 받아 커널의 기능을 실행합니다.
Utilities − 사용자에게 운영 체제의 대부분의 기능을 제공하는 유틸리티 프로그램.