운영 체제-가상 메모리
컴퓨터는 시스템에 물리적으로 설치된 양보다 더 많은 메모리를 지정할 수 있습니다. 이 추가 메모리는 실제로virtual memory 컴퓨터의 RAM을 에뮬레이트하도록 설정된 하드 디스크의 한 부분입니다.
이 체계의 주요 눈에 띄는 장점은 프로그램이 실제 메모리보다 클 수 있다는 것입니다. 가상 메모리는 두 가지 용도로 사용됩니다. 첫째, 디스크를 사용하여 물리적 메모리 사용을 확장 할 수 있습니다. 둘째, 각 가상 주소가 물리적 주소로 변환되기 때문에 메모리 보호가 가능합니다.
다음은 전체 프로그램을 주 메모리에 완전히로드 할 필요가없는 상황입니다.
사용자가 작성한 오류 처리 루틴은 데이터 또는 계산에 오류가 발생한 경우에만 사용됩니다.
프로그램의 특정 옵션 및 기능은 거의 사용되지 않을 수 있습니다.
실제로 적은 양의 테이블 만 사용하더라도 많은 테이블에 고정 된 양의 주소 공간이 할당됩니다.
메모리에 부분적으로 만있는 프로그램을 실행할 수있는 능력은 많은 이점을 상쇄합니다.
각 사용자 프로그램을 메모리에로드하거나 스왑하는 데 필요한 I / O 수가 적습니다.
프로그램은 더 이상 사용 가능한 실제 메모리의 양에 의해 제한되지 않습니다.
각 사용자 프로그램은 실제 메모리를 덜 사용하고 더 많은 프로그램을 동시에 실행할 수 있으며 이에 따라 CPU 사용률 및 처리량이 증가합니다.
범용 사용을위한 최신 마이크로 프로세서, 메모리 관리 장치 또는 MMU가 하드웨어에 내장되어 있습니다. MMU의 역할은 가상 주소를 물리적 주소로 변환하는 것입니다. 기본 예는 다음과 같습니다.
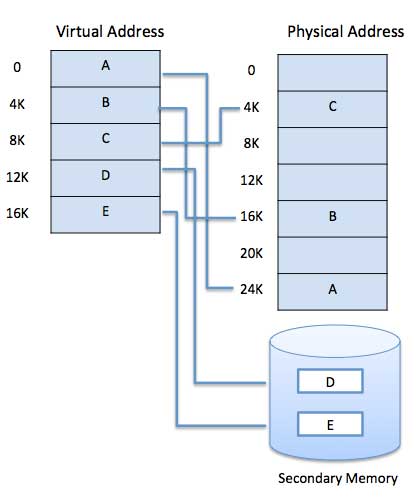
가상 메모리는 일반적으로 요청 페이징에 의해 구현됩니다. 분할 시스템에서도 구현할 수 있습니다. 수요 세분화를 사용하여 가상 메모리를 제공 할 수도 있습니다.
수요 페이징
수요 페이징 시스템은 프로세스가 보조 메모리에 상주하고 페이지가 미리가 아닌 요청시에만로드되는 스와핑이있는 페이징 시스템과 매우 유사합니다. 컨텍스트 전환이 발생하면 운영 체제는 이전 프로그램의 페이지를 디스크로 복사하지 않거나 새 프로그램의 페이지를 주 메모리로 복사하지 않고 대신 첫 번째 페이지를로드 한 후 새 프로그램을 실행하고이를 가져옵니다. 참조되는 프로그램의 페이지.
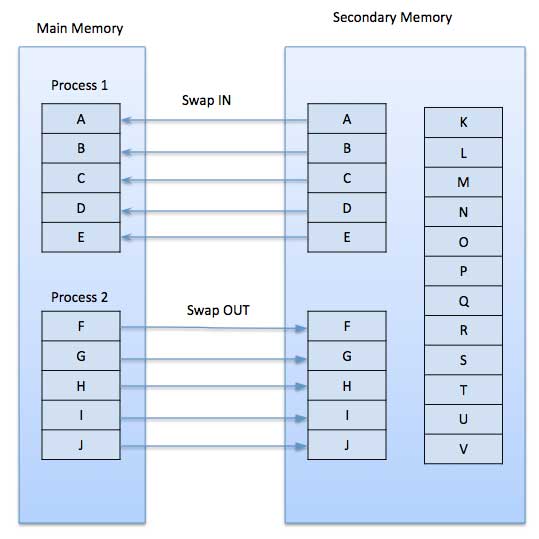
프로그램을 실행하는 동안 프로그램이 주 메모리에서 사용할 수없는 페이지를 참조하면 조금 전에 교체 되었기 때문에 프로세서는이 유효하지 않은 메모리 참조를 page fault 프로그램에서 운영 체제로 제어를 전송하여 페이지를 다시 메모리로 요구합니다.
장점
다음은 Demand Paging의 장점입니다-
- 대용량 가상 메모리.
- 보다 효율적인 메모리 사용.
- 다중 프로그래밍의 정도에는 제한이 없습니다.
단점
페이지 인터럽트를 처리하기위한 테이블 수와 프로세서 오버 헤드 양은 단순 페이지 관리 기술의 경우보다 큽니다.
페이지 교체 알고리즘
페이지 교체 알고리즘은 운영 체제가 스왑 아웃 할 메모리 페이지를 결정하고 메모리 페이지를 할당해야 할 때 디스크에 쓰는 기술입니다. 페이지 폴트가 발생할 때마다 페이징이 발생하고 페이지를 사용할 수 없거나 사용 가능한 페이지 수가 필요한 페이지보다 적다는 이유로 할당 목적으로 사용 가능한 페이지를 사용할 수 없습니다.
교체를 위해 선택되어 페이지 아웃 된 페이지가 다시 참조 될 때 디스크에서 읽어야하므로 I / O 완료가 필요합니다. 이 프로세스는 페이지 교체 알고리즘의 품질을 결정합니다. 페이지 인을 기다리는 시간이 짧을수록 알고리즘이 좋습니다.
페이지 교체 알고리즘은 하드웨어에서 제공하는 페이지 액세스에 대한 제한된 정보를 확인하고, 총 페이지 누락 수를 최소화하기 위해 교체해야하는 페이지를 선택하는 동시에 알고리즘의 기본 스토리지 비용 및 프로세서 시간과 균형을 유지합니다. 그 자체. 다양한 페이지 교체 알고리즘이 있습니다. 특정 메모리 참조 문자열에서 알고리즘을 실행하고 페이지 오류 수를 계산하여 알고리즘을 평가합니다.
참조 문자열
메모리 참조 문자열을 참조 문자열이라고합니다. 참조 문자열은 인위적으로 또는 주어진 시스템을 추적하고 각 메모리 참조의 주소를 기록하여 생성됩니다. 후자의 선택은 많은 수의 데이터를 생성하는데, 여기서 두 가지를 주목합니다.
주어진 페이지 크기에 대해 전체 주소가 아닌 페이지 번호 만 고려하면됩니다.
페이지에 대한 참조가있는 경우 p, 페이지에 대한 바로 다음 참조 p페이지 오류가 발생하지 않습니다. 페이지 p는 첫 번째 참조 이후 메모리에 있습니다. 바로 다음 참조는 잘못되지 않습니다.
예를 들어, 다음 주소 시퀀스를 고려하십시오-123,215,600,1234,76,96
페이지 크기가 100이면 참조 문자열은 1,2,6,12,0,0입니다.
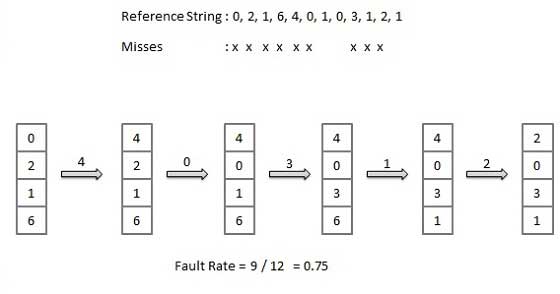
선입 선출 (FIFO) 알고리즘
메인 메모리에서 가장 오래된 페이지는 교체를 위해 선택되는 페이지입니다.
구현하기 쉽고, 목록을 유지하고, 꼬리부터 페이지를 교체하고, 헤드에 새 페이지를 추가합니다.
최적의 페이지 알고리즘
최적의 페이지 교체 알고리즘은 모든 알고리즘 중 페이지 오류율이 가장 낮습니다. 최적의 페이지 교체 알고리즘이 있으며 OPT 또는 MIN이라고합니다.
가장 오랫동안 사용하지 않을 페이지를 교체하십시오. 페이지를 사용할 시간을 사용하십시오.

LRU (Least Recent Used) 알고리즘
메인 메모리에서 가장 오랫동안 사용하지 않은 페이지가 교체 대상으로 선택됩니다.
구현하기 쉽고, 목록을 유지하고, 시간을 거슬러 올라가서 페이지를 교체합니다.

페이지 버퍼링 알고리즘
- 프로세스를 빠르게 시작하려면 여유 프레임 풀을 유지하십시오.
- 페이지 폴트에서 교체 할 페이지를 선택하십시오.
- 여유 풀 프레임에 새 페이지를 작성하고 페이지 테이블을 표시 한 후 프로세스를 다시 시작하십시오.
- 이제 디스크에서 더티 페이지를 쓰고 교체 된 페이지를 유지하는 프레임을 여유 풀에 배치합니다.
최소 사용 빈도 (LFU) 알고리즘
가장 적은 수의 페이지가 교체를 위해 선택되는 페이지입니다.
이 알고리즘은 프로세스의 초기 단계에서 페이지가 많이 사용되었지만 다시 사용되지 않는 상황에서 어려움을 겪습니다.
가장 자주 사용되는 (MFU) 알고리즘
이 알고리즘은 개수가 가장 작은 페이지가 방금 가져온 것일 수 있으며 아직 사용되지 않았다는 주장을 기반으로합니다.