병렬 알고리즘-퀵 가이드
안 algorithm사용자로부터 입력을 받고 일부 계산 후 출력을 생성하는 일련의 단계입니다. ㅏparallel algorithm 다른 처리 장치에서 여러 명령을 동시에 실행 한 다음 모든 개별 출력을 결합하여 최종 결과를 생성 할 수있는 알고리즘입니다.
동시 처리
인터넷의 성장과 함께 컴퓨터의 쉬운 가용성은 우리가 데이터를 저장하고 처리하는 방식을 변화 시켰습니다. 우리는 데이터가 풍부한 시대에 살고 있습니다. 매일 우리는 복잡한 컴퓨팅이 필요한 방대한 양의 데이터를 빠른 시간 내에 처리합니다. 때로는 동시에 발생하는 유사하거나 상호 관련된 이벤트에서 데이터를 가져와야합니다. 이것이 우리가 요구하는 곳입니다concurrent processing 복잡한 작업을 분할하고 여러 시스템을 처리하여 빠른 시간에 출력을 생성 할 수 있습니다.
작업이 대량의 복잡한 데이터를 처리하는 경우 동시 처리가 필수적입니다. 예 : 대규모 데이터베이스 액세스, 항공기 테스트, 천문 계산, 원자 및 핵 물리학, 생물 의학 분석, 경제 계획, 이미지 처리, 로봇 공학, 일기 예보, 웹 기반 서비스 등.
병렬 처리 란 무엇입니까?
Parallelism여러 명령 세트를 동시에 처리하는 프로세스입니다. 총 계산 시간이 줄어 듭니다. 병렬 처리는 다음을 사용하여 구현할 수 있습니다.parallel computers,즉, 프로세서가 많은 컴퓨터. 병렬 컴퓨터에는 멀티 태스킹을 지원하는 병렬 알고리즘, 프로그래밍 언어, 컴파일러 및 운영 체제가 필요합니다.
이 튜토리얼에서는 parallel algorithms. 더 나아 가기 전에 먼저 알고리즘과 그 유형에 대해 논의하겠습니다.
알고리즘이란?
안 algorithm문제를 해결하기 위해 따르는 일련의 지침입니다. 알고리즘을 설계 할 때 알고리즘이 실행될 컴퓨터의 아키텍처를 고려해야합니다. 아키텍처에 따라 두 가지 유형의 컴퓨터가 있습니다.
- 순차 컴퓨터
- 병렬 컴퓨터
컴퓨터 구조에 따라 두 가지 유형의 알고리즘이 있습니다.
Sequential Algorithm − 문제를 해결하기 위해 몇 가지 연속적인 명령 단계가 시간순으로 실행되는 알고리즘.
Parallel Algorithm− 문제는 하위 문제로 나뉘어 개별 출력을 얻기 위해 병렬로 실행됩니다. 나중에 이러한 개별 출력을 함께 결합하여 원하는 최종 출력을 얻습니다.
큰 문제를 다음과 같이 나누는 것은 쉽지 않습니다. sub-problems. 하위 문제에는 데이터 종속성이있을 수 있습니다. 따라서 프로세서는 문제를 해결하기 위해 서로 통신해야합니다.
프로세서가 서로 통신하는 데 필요한 시간은 실제 처리 시간보다 많은 것으로 나타났습니다. 따라서 병렬 알고리즘을 설계하는 동안 효율적인 알고리즘을 얻으려면 적절한 CPU 사용률을 고려해야합니다.
알고리즘을 올바르게 설계하려면 기본에 대한 명확한 아이디어가 있어야합니다. model of computation 병렬 컴퓨터에서.
계산 모델
순차 및 병렬 컴퓨터는 모두 알고리즘이라는 명령 집합 (스트림)에서 작동합니다. 이러한 지침 (알고리즘) 집합은 각 단계에서 수행해야하는 작업에 대해 컴퓨터에 지시합니다.
명령어 스트림과 데이터 스트림에 따라 컴퓨터는 네 가지 범주로 분류 될 수 있습니다.
- 단일 명령 스트림, 단일 데이터 스트림 (SISD) 컴퓨터
- 단일 명령 스트림, 다중 데이터 스트림 (SIMD) 컴퓨터
- 다중 명령 스트림, 단일 데이터 스트림 (MISD) 컴퓨터
- 다중 명령 스트림, 다중 데이터 스트림 (MIMD) 컴퓨터
SISD 컴퓨터
SISD 컴퓨터에는 one control unit, one processing unit, 과 one memory unit.

이러한 유형의 컴퓨터에서 프로세서는 제어 장치로부터 단일 스트림의 명령을 수신하고 메모리 장치의 단일 데이터 스트림에서 작동합니다. 계산하는 동안 각 단계에서 프로세서는 제어 장치로부터 하나의 명령을 수신하고 메모리 장치에서 수신 된 단일 데이터에 대해 작동합니다.
SIMD 컴퓨터
SIMD 컴퓨터에는 one control unit, multiple processing units, 과 shared memory or interconnection network.
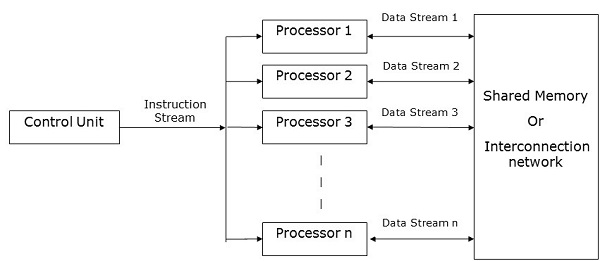
여기서 하나의 단일 제어 장치는 모든 처리 장치에 명령을 보냅니다. 계산하는 동안 각 단계에서 모든 프로세서는 제어 장치로부터 단일 명령 세트를 수신하고 메모리 장치의 다른 데이터 세트에서 작동합니다.
각 처리 장치에는 데이터와 명령을 모두 저장하는 자체 로컬 메모리 장치가 있습니다. SIMD 컴퓨터에서 프로세서는 서로 통신해야합니다. 이것은shared memory 또는 interconnection network.
일부 프로세서는 명령 집합을 실행하지만 나머지 프로세서는 다음 명령 집합을 기다립니다. 제어 장치의 지침에 따라 처리 할 프로세서가 결정됩니다.active (지시 실행) 또는 inactive (다음 지시를 기다리십시오).
MISD 컴퓨터
이름에서 알 수 있듯이 MISD 컴퓨터에는 multiple control units, multiple processing units, 과 one common memory unit.

여기에서 각 프로세서에는 자체 제어 장치가 있으며 공통 메모리 장치를 공유합니다. 모든 프로세서는 자체 제어 장치에서 개별적으로 명령을 받고 각 제어 장치에서받은 명령에 따라 단일 데이터 스트림에서 작동합니다. 이 프로세서는 동시에 작동합니다.
MIMD 컴퓨터
MIMD 컴퓨터에는 multiple control units, multiple processing units, 그리고 shared memory 또는 interconnection network.

여기에서 각 프로세서에는 자체 제어 장치, 로컬 메모리 장치, 산술 및 논리 장치가 있습니다. 그들은 각각의 제어 장치로부터 다른 명령 세트를 수신하고 다른 데이터 세트에서 작동합니다.
노트
공통 메모리를 공유하는 MIMD 컴퓨터는 multiprocessors, 상호 연결 네트워크를 사용하는 사람들은 multicomputers.
프로세서의 물리적 거리에 따라 다중 컴퓨터는 두 가지 유형이 있습니다.
Multicomputer − 모든 프로세서가 서로 매우 가까이있을 때 (예 : 같은 방에 있음).
Distributed system − 모든 프로세서가 서로 멀리 떨어져있는 경우 (예 : 다른 도시)
알고리즘 분석은 알고리즘이 유용한 지 여부를 결정하는 데 도움이됩니다. 일반적으로 알고리즘은 실행 시간을 기준으로 분석됩니다.(Time Complexity) 그리고 공간의 양 (Space Complexity) 필요합니다.
합리적인 비용으로 사용할 수있는 정교한 메모리 장치가 있기 때문에 저장 공간은 더 이상 문제가되지 않습니다. 따라서 공간 복잡성은 그다지 중요하지 않습니다.
병렬 알고리즘은 컴퓨터의 계산 속도를 향상 시키도록 설계되었습니다. 병렬 알고리즘을 분석하기 위해 일반적으로 다음 매개 변수를 고려합니다.
- 시간 복잡성 (실행 시간),
- 사용 된 총 프로세서 수 및
- 총 비용.
시간 복잡성
병렬 알고리즘을 개발 한 주된 이유는 알고리즘의 계산 시간을 줄이는 것이 었습니다. 따라서 알고리즘의 실행 시간을 평가하는 것은 효율성을 분석하는 데 매우 중요합니다.
실행 시간은 알고리즘이 문제를 해결하는 데 걸린 시간을 기준으로 측정됩니다. 총 실행 시간은 알고리즘이 실행을 시작하는 순간부터 중지되는 순간까지 계산됩니다. 모든 프로세서가 동시에 실행을 시작하거나 종료하지 않으면 알고리즘의 총 실행 시간은 첫 번째 프로세서가 실행을 시작한 순간부터 마지막 프로세서가 실행을 중지하는 순간까지입니다.
알고리즘의 시간 복잡도는 세 가지 범주로 분류 할 수 있습니다.
Worst-case complexity − 주어진 입력에 대해 알고리즘에 필요한 시간이 maximum.
Average-case complexity − 주어진 입력에 대해 알고리즘에 필요한 시간이 average.
Best-case complexity − 주어진 입력에 대해 알고리즘에 필요한 시간이 minimum.
점근 분석
알고리즘의 복잡성 또는 효율성은 원하는 출력을 얻기 위해 알고리즘에서 실행하는 단계의 수입니다. 점근 분석은 이론적 분석에서 알고리즘의 복잡성을 계산하기 위해 수행됩니다. 점근 분석에서는 알고리즘의 복잡도 함수를 계산하는 데 큰 길이의 입력이 사용됩니다.
Note − Asymptotic선이 곡선을 만나는 경향이 있지만 교차하지 않는 조건입니다. 여기서 선과 곡선은 서로 점근 적입니다.
점근 표기법은 속도에 대해 상한 및 하한을 사용하는 알고리즘에 대해 가능한 가장 빠르고 가장 느린 실행 시간을 설명하는 가장 쉬운 방법입니다. 이를 위해 다음 표기법을 사용합니다.
- Big O 표기법
- 오메가 표기
- 세타 표기법
Big O 표기법
수학에서 Big O 표기법은 함수의 점근 적 특성을 나타내는 데 사용됩니다. 간단하고 정확한 방법으로 큰 입력에 대한 함수의 동작을 나타냅니다. 알고리즘 실행 시간의 상한을 나타내는 방법입니다. 알고리즘이 실행을 완료하는 데 걸리는 가장 긴 시간을 나타냅니다. 기능-
f (n) = O (g (n))
양의 상수가있는 경우 c 과 n0 그런 f(n) ≤ c * g(n) 모든 n 어디 n ≥ n0.
오메가 표기
오메가 표기법은 알고리즘 실행 시간의 하한을 나타내는 방법입니다. 기능-
f (n) = Ω (g (n))
양의 상수가있는 경우 c 과 n0 그런 f(n) ≥ c * g(n) 모든 n 어디 n ≥ n0.
세타 표기법
Theta 표기법은 알고리즘 실행 시간의 하한과 상한을 모두 나타내는 방법입니다. 기능-
f (n) = θ (g (n))
양의 상수가있는 경우 c1, c2, 과 n0 모두에 대해 c1 * g (n) ≤ f (n) ≤ c2 * g (n) n 어디 n ≥ n0.
알고리즘의 속도 향상
병렬 알고리즘의 성능은 다음을 계산하여 결정됩니다. speedup. 속도 향상은 특정 문제에 대해 알려진 가장 빠른 순차 알고리즘의 최악의 실행 시간과 병렬 알고리즘의 최악의 실행 시간의 비율로 정의됩니다.
사용 된 프로세서 수
사용되는 프로세서의 수는 병렬 알고리즘의 효율성을 분석하는 데 중요한 요소입니다. 컴퓨터를 구입, 유지 관리 및 실행하는 비용이 계산됩니다. 문제를 해결하기 위해 알고리즘이 사용하는 프로세서 수가 많을수록 결과는 더 비싸게됩니다.
총 비용
병렬 알고리즘의 총 비용은 시간 복잡성과 특정 알고리즘에 사용 된 프로세서 수의 곱입니다.
총 비용 = 시간 복잡성 × 사용 된 프로세서 수
따라서 efficiency 병렬 알고리즘의-
병렬 알고리즘의 모델은 데이터 분할 전략과 처리 방법을 고려하고 상호 작용을 줄이기위한 적절한 전략을 적용하여 개발됩니다. 이 장에서는 다음과 같은 병렬 알고리즘 모델에 대해 설명합니다.
- 데이터 병렬 모델
- 작업 그래프 모델
- 작업 풀 모델
- 마스터 슬레이브 모델
- 생산자 소비자 또는 파이프 라인 모델
- 하이브리드 모델
데이터 병렬
데이터 병렬 모델에서 작업은 프로세스에 할당되고 각 작업은 서로 다른 데이터에 대해 유사한 유형의 작업을 수행합니다. Data parallelism 여러 데이터 항목에 적용되는 단일 작업의 결과입니다.
데이터 병렬 모델은 공유 주소 공간과 메시지 전달 패러다임에 적용될 수 있습니다. 데이터 병렬 모델에서 분해를 보존하는 지역성을 선택하거나 최적화 된 집단 상호 작용 루틴을 사용하거나 계산과 상호 작용을 겹침으로써 상호 작용 오버 헤드를 줄일 수 있습니다.
데이터 병렬 모델 문제의 주요 특징은 문제의 크기에 따라 데이터 병렬 처리의 강도가 증가하여 더 큰 문제를 해결하기 위해 더 많은 프로세스를 사용할 수 있다는 것입니다.
Example − 조밀 한 행렬 곱셈.

작업 그래프 모델
작업 그래프 모델에서 병렬 처리는 다음과 같이 표현됩니다. task graph. 작업 그래프는 사소하거나 사소하지 않을 수 있습니다. 이 모델에서는 작업 간의 상관 관계를 활용하여 지역성을 높이거나 상호 작용 비용을 최소화합니다. 이 모델은 작업과 관련된 계산 수에 비해 작업과 관련된 데이터의 양이 많은 문제를 해결하기 위해 적용됩니다. 작업 간 데이터 이동 비용을 개선하기 위해 작업이 할당됩니다.
Examples − 병렬 빠른 정렬, 희소 행렬 분해 및 분할 및 정복 접근 방식을 통해 파생 된 병렬 알고리즘.
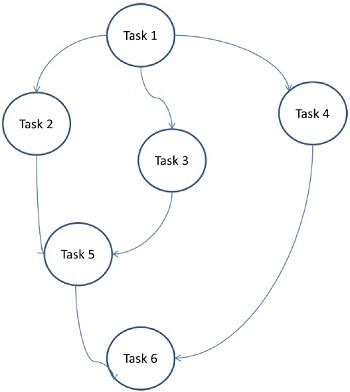
여기서 문제는 원자 작업으로 나누어 그래프로 구현됩니다. 각 태스크는 하나 이상의 선행 태스크에 종속 된 독립적 인 작업 단위입니다. 작업 완료 후 선행 작업의 출력이 종속 작업으로 전달됩니다. 선행 작업이있는 작업은 전체 선행 작업이 완료된 경우에만 실행을 시작합니다. 마지막 종속 작업이 완료되면 그래프의 최종 출력이 수신됩니다 (위 그림의 작업 6).
작업 풀 모델
작업 풀 모델에서 작업은 부하 분산을 위해 프로세스에 동적으로 할당됩니다. 따라서 모든 프로세스는 잠재적으로 모든 작업을 실행할 수 있습니다. 이 모델은 작업과 관련된 데이터의 양이 작업과 관련된 계산보다 상대적으로 적을 때 사용됩니다.
프로세스에 원하는 사전 할당 작업이 없습니다. 작업 할당은 중앙 집중화되거나 분산됩니다. 작업에 대한 포인터는 물리적으로 공유 된 목록, 우선 순위 대기열 또는 해시 테이블 또는 트리에 저장되거나 물리적으로 분산 된 데이터 구조에 저장 될 수 있습니다.
작업은 처음에 사용할 수 있거나 동적으로 생성 될 수 있습니다. 작업이 동적으로 생성되고 분산 된 작업 할당이 완료되면 모든 프로세스가 실제로 전체 프로그램의 완료를 감지하고 더 많은 작업을 찾지 못하도록 종료 감지 알고리즘이 필요합니다.
Example − 병렬 트리 검색

마스터-슬레이브 모델
마스터-슬레이브 모델에서는 하나 이상의 마스터 프로세스가 작업을 생성하고이를 슬레이브 프로세스에 할당합니다. 다음과 같은 경우 작업을 미리 할당 할 수 있습니다.
- 마스터는 작업의 양을 추정 할 수 있습니다.
- 무작위 할당은 만족스러운 부하 분산 작업을 수행 할 수 있습니다.
- 슬레이브는 서로 다른 시간에 더 작은 작업 조각이 할당됩니다.
이 모델은 일반적으로 shared-address-space 또는 message-passing paradigms, 상호 작용은 자연스럽게 두 가지 방식이기 때문입니다.
경우에 따라 작업을 단계별로 완료해야 할 수 있으며 다음 단계의 작업을 생성하기 전에 각 단계의 작업을 완료해야합니다. 마스터-슬레이브 모델은 다음과 같이 일반화 될 수 있습니다.hierarchical 또는 multi-level master-slave model 최상위 마스터가 작업의 많은 부분을 두 번째 수준 마스터에 공급하여 자신의 슬레이브간에 작업을 더 세분화하고 작업 자체의 일부를 수행 할 수 있습니다.
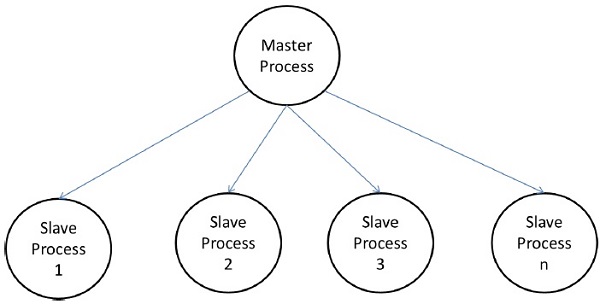
마스터-슬레이브 모델 사용시주의 사항
마스터가 혼잡 지점이되지 않도록주의해야합니다. 작업이 너무 작거나 작업자가 비교적 빠르면 발생할 수 있습니다.
작업은 작업 수행 비용이 통신 비용과 동기화 비용을 지배하는 방식으로 선택되어야합니다.
비동기 상호 작용은 마스터에 의한 작업 생성과 관련된 상호 작용 및 계산을 겹칠 수 있습니다.
파이프 라인 모델
또한 producer-consumer model. 여기에서 일련의 데이터가 일련의 프로세스를 통해 전달되며 각 프로세스는 작업을 수행합니다. 여기에서 새로운 데이터가 도착하면 대기열의 프로세스에 의해 새로운 작업이 실행됩니다. 프로세스는 순환이 있거나없는 선형 또는 다차원 배열, 트리 또는 일반 그래프의 형태로 대기열을 형성 할 수 있습니다.
이 모델은 생산자와 소비자의 사슬입니다. 큐의 각 프로세스는 큐에서 선행하는 프로세스에 대한 데이터 항목 시퀀스의 소비자로 간주되고 큐에서 그 다음 프로세스에 대한 데이터 생산자로 간주 될 수 있습니다. 큐는 선형 체인 일 필요는 없습니다. 방향성 그래프 일 수 있습니다. 이 모델에 적용 할 수있는 가장 일반적인 상호 작용 최소화 기술은 계산과 중첩 상호 작용입니다.
Example − 병렬 LU 분해 알고리즘.

하이브리드 모델
문제를 해결하기 위해 둘 이상의 모델이 필요할 때 하이브리드 알고리즘 모델이 필요합니다.
하이브리드 모델은 계층 적으로 적용된 여러 모델 또는 병렬 알고리즘의 여러 단계에 순차적으로 적용된 여러 모델로 구성 될 수 있습니다.
Example − 병렬 빠른 정렬
Parallel Random Access Machines (PRAM)대부분의 병렬 알고리즘에서 고려되는 모델입니다. 여기에서 여러 프로세서가 단일 메모리 블록에 연결됩니다. PRAM 모델에는 다음이 포함됩니다.
유사한 유형의 프로세서 세트.
모든 프로세서는 공통 메모리 장치를 공유합니다. 프로세서는 공유 메모리를 통해서만 서로 통신 할 수 있습니다.
MAU (메모리 액세스 장치)는 프로세서를 단일 공유 메모리와 연결합니다.

여기, n 프로세서의 수는 독립적 인 작업을 수행 할 수 있습니다. n특정 시간 단위의 데이터 수. 이로 인해 서로 다른 프로세서가 동일한 메모리 위치에 동시에 액세스 할 수 있습니다.
이 문제를 해결하기 위해 PRAM 모델에 다음과 같은 제약이 적용되었습니다.
Exclusive Read Exclusive Write (EREW) − 여기서 두 개의 프로세서는 동시에 같은 메모리 위치에서 읽거나 쓸 수 없습니다.
Exclusive Read Concurrent Write (ERCW) − 여기서 두 개의 프로세서는 동시에 같은 메모리 위치에서 읽을 수 없지만 동시에 같은 메모리 위치에 쓸 수 있습니다.
Concurrent Read Exclusive Write (CREW) − 여기서 모든 프로세서는 동일한 메모리 위치에서 동시에 읽을 수 있지만 동시에 같은 메모리 위치에 쓸 수는 없습니다.
Concurrent Read Concurrent Write (CRCW) − 모든 프로세서는 동일한 메모리 위치에서 동시에 읽거나 쓸 수 있습니다.
PRAM 모델을 구현하는 방법에는 여러 가지가 있지만 가장 눈에 띄는 방법은 다음과 같습니다.
- 공유 메모리 모델
- 메시지 전달 모델
- 데이터 병렬 모델
공유 메모리 모델
공유 메모리는 control parallelism ~보다 data parallelism. 공유 메모리 모델에서 여러 프로세스는 서로 다른 프로세서에서 독립적으로 실행되지만 공통 메모리 공간을 공유합니다. 프로세서 활동으로 인해 메모리 위치가 변경되면 나머지 프로세서에서 볼 수 있습니다.
여러 프로세서가 동일한 메모리 위치에 액세스 할 때 특정 시점에 둘 이상의 프로세서가 동일한 메모리 위치에 액세스 할 수 있습니다. 하나는 그 위치를 읽고 다른 하나는 그 위치에 쓰고 있다고 가정합니다. 혼란을 일으킬 수 있습니다. 이를 방지하기 위해 다음과 같은 제어 메커니즘이 있습니다.lock / semaphore, 상호 배제를 보장하기 위해 구현됩니다.

공유 메모리 프로그래밍은 다음에서 구현되었습니다.
Thread libraries− 스레드 라이브러리는 동일한 메모리 위치에서 동시에 실행되는 여러 제어 스레드를 허용합니다. 스레드 라이브러리는 서브 루틴 라이브러리를 통해 멀티 스레딩을 지원하는 인터페이스를 제공합니다. 다음을위한 서브 루틴을 포함합니다.
- 스레드 생성 및 삭제
- 스레드 실행 예약
- 스레드간에 데이터 및 메시지 전달
- 스레드 컨텍스트 저장 및 복원
스레드 라이브러리의 예는 다음과 같습니다. Solaris 용 SolarisTM 스레드, Linux에서 구현 된 POSIX 스레드, Windows NT 및 Windows 2000에서 사용 가능한 Win32 스레드, 표준 JDK (JavaTM Development Kit)의 일부인 JavaTM 스레드.
Distributed Shared Memory (DSM) Systems− DSM 시스템은 하드웨어 지원없이 공유 메모리 프로그래밍을 구현하기 위해 느슨하게 결합 된 아키텍처에서 공유 메모리의 추상화를 생성합니다. 표준 라이브러리를 구현하고 최신 운영 체제에있는 고급 사용자 수준 메모리 관리 기능을 사용합니다. 예를 들면 트레드 마크 시스템, Munin, IVY, Shasta, Brazos 및 Cashmere가 있습니다.
Program Annotation Packages− 이는 균일 한 메모리 액세스 특성을 갖는 아키텍처에서 구현됩니다. 프로그램 주석 패키지의 가장 주목할만한 예는 OpenMP입니다. OpenMP는 기능적 병렬 처리를 구현합니다. 주로 루프의 병렬화에 중점을 둡니다.
공유 메모리의 개념은 공유 메모리 시스템에 대한 낮은 수준의 제어를 제공하지만 지루하고 오류가 많은 경향이 있습니다. 응용 프로그래밍보다 시스템 프로그래밍에 더 적합합니다.
공유 메모리 프로그래밍의 장점
전역 주소 공간은 메모리에 대한 사용자 친화적 인 프로그래밍 접근 방식을 제공합니다.
메모리가 CPU에 가깝기 때문에 프로세스 간의 데이터 공유가 빠르고 균일합니다.
프로세스 간의 데이터 통신을 명확하게 지정할 필요가 없습니다.
프로세스 통신 오버 헤드는 무시할 수 있습니다.
배우는 것은 매우 쉽습니다.
공유 메모리 프로그래밍의 단점
- 휴대용이 아닙니다.
- 데이터 지역을 관리하는 것은 매우 어렵습니다.
메시지 전달 모델
메시지 전달은 분산 메모리 시스템에서 가장 일반적으로 사용되는 병렬 프로그래밍 접근 방식입니다. 여기에서 프로그래머는 병렬성을 결정해야합니다. 이 모델에서 모든 프로세서는 자체 로컬 메모리 장치를 가지고 있으며 통신 네트워크를 통해 데이터를 교환합니다.

프로세서는 서로 통신하기 위해 메시지 전달 라이브러리를 사용합니다. 전송되는 데이터와 함께 메시지에는 다음 구성 요소가 포함됩니다.
메시지가 전송되는 프로세서의 주소.
송신 프로세서에있는 데이터의 메모리 위치의 시작 주소.
보내는 데이터의 데이터 유형
보내는 데이터의 데이터 크기
메시지가 전송되는 프로세서의 주소.
수신 프로세서의 데이터에 대한 메모리 위치의 시작 주소입니다.
프로세서는 다음 방법 중 하나로 서로 통신 할 수 있습니다.
- 지점 간 통신
- 집단 커뮤니케이션
- 메시지 전달 인터페이스
지점 간 통신
지점 간 통신은 메시지 전달의 가장 간단한 형태입니다. 여기서 메시지는 다음 전송 모드 중 하나에 의해 송신 프로세서에서 수신 프로세서로 전송 될 수 있습니다.
Synchronous mode − 다음 메시지는 메시지의 순서를 유지하기 위해 이전 메시지가 전달되었다는 확인을받은 후에 만 전송됩니다.
Asynchronous mode − 다음 메시지를 전송하기 위해 이전 메시지 전송 확인을받을 필요가 없습니다.
집단 커뮤니케이션
집합 적 통신에는 메시지 전달을 위해 두 개 이상의 프로세서가 포함됩니다. 다음 모드는 집단 통신을 허용합니다-
Barrier − 통신에 포함 된 모든 프로세서가 특정 블록을 실행하면 배리어 모드가 가능합니다. barrier block) 메시지 전달.
Broadcast − 방송은 두 가지 유형이 있습니다 −
One-to-all − 여기서 단일 작업을 수행하는 하나의 프로세서는 다른 모든 프로세서에 동일한 메시지를 보냅니다.
All-to-all − 여기서 모든 프로세서는 다른 모든 프로세서에 메시지를 보냅니다.
방송되는 메시지는 세 가지 유형이 있습니다.
Personalized − 고유 메시지는 다른 모든 대상 프로세서로 전송됩니다.
Non-personalized − 모든 대상 프로세서가 동일한 메시지를받습니다.
Reduction − 축소 방송에서 그룹의 한 프로세서는 그룹의 다른 모든 프로세서로부터 모든 메시지를 수집하여 그룹의 다른 모든 프로세서가 액세스 할 수있는 단일 메시지로 결합합니다.
메시지 전달의 장점
- 낮은 수준의 병렬 처리 제어를 제공합니다.
- 휴대용입니다.
- 오류가 덜 발생합니다.
- 병렬 동기화 및 데이터 배포의 오버 헤드가 적습니다.
메시지 전달의 단점
병렬 공유 메모리 코드와 비교할 때 메시지 전달 코드는 일반적으로 더 많은 소프트웨어 오버 헤드가 필요합니다.
메시지 전달 라이브러리
많은 메시지 전달 라이브러리가 있습니다. 여기에서 가장 많이 사용되는 메시지 전달 라이브러리 두 가지에 대해 설명합니다.
- 메시지 전달 인터페이스 (MPI)
- 병렬 가상 머신 (PVM)
메시지 전달 인터페이스 (MPI)
분산 메모리 시스템의 모든 동시 프로세스간에 통신을 제공하는 범용 표준입니다. 일반적으로 사용되는 대부분의 병렬 컴퓨팅 플랫폼은 메시지 전달 인터페이스의 구현을 하나 이상 제공합니다. 호출 된 미리 정의 된 함수 모음으로 구현되었습니다.library C, C ++, Fortran 등과 같은 언어에서 호출 할 수 있습니다. MPI는 다른 메시지 전달 라이브러리에 비해 빠르고 이식 가능합니다.
Merits of Message Passing Interface
공유 메모리 아키텍처 또는 분산 메모리 아키텍처에서만 실행됩니다.
각 프로세서에는 고유 한 지역 변수가 있습니다.
대용량 공유 메모리 컴퓨터에 비해 분산 메모리 컴퓨터는 비용이 저렴합니다.
Demerits of Message Passing Interface
- 병렬 알고리즘에는 더 많은 프로그래밍 변경이 필요합니다.
- 때로는 디버깅하기가 어렵습니다. 과
- 노드 간의 통신 네트워크에서 잘 수행되지 않습니다.
병렬 가상 머신 (PVM)
PVM은 별도의 이기종 호스트 시스템을 연결하여 단일 가상 시스템을 형성하도록 설계된 휴대용 메시지 전달 시스템입니다. 관리 가능한 단일 병렬 컴퓨팅 리소스입니다. 초전도 연구, 분자 역학 시뮬레이션 및 매트릭스 알고리즘과 같은 대규모 계산 문제는 많은 컴퓨터의 메모리와 집계 능력을 사용하여보다 비용 효율적으로 해결할 수 있습니다. 호환되지 않는 컴퓨터 아키텍처의 네트워크에서 모든 메시지 라우팅, 데이터 변환, 작업 예약을 관리합니다.
Features of PVM
- 설치 및 구성이 매우 쉽습니다.
- 여러 사용자가 동시에 PVM을 사용할 수 있습니다.
- 한 사용자가 여러 응용 프로그램을 실행할 수 있습니다.
- 작은 패키지입니다.
- C, C ++, Fortran 지원;
- 주어진 PVM 프로그램 실행에 대해 사용자는 머신 그룹을 선택할 수 있습니다.
- 메시지 전달 모델입니다.
- 프로세스 기반 계산;
- 이기종 아키텍처를 지원합니다.
데이터 병렬 프로그래밍
데이터 병렬 프로그래밍 모델의 주요 초점은 데이터 세트에 대한 작업을 동시에 수행하는 것입니다. 데이터 세트는 배열, 하이퍼 큐브 등과 같은 일부 구조로 구성됩니다. 프로세서는 동일한 데이터 구조에서 집합 적으로 작업을 수행합니다. 각 작업은 동일한 데이터 구조의 다른 파티션에서 수행됩니다.
모든 알고리즘이 데이터 병렬 처리 측면에서 지정 될 수있는 것은 아니므로 제한적입니다. 이것이 데이터 병렬성이 보편적이지 않은 이유입니다.
데이터 병렬 언어는 데이터 분해 및 프로세서에 대한 매핑을 지정하는 데 도움이됩니다. 또한 프로그래머가 데이터를 제어 할 수 있도록하는 데이터 배포 명령문 (예 : 어떤 데이터가 어떤 프로세서로 이동하는지)을 포함하여 프로세서 내의 통신량을 줄입니다.
알고리즘을 올바르게 적용하려면 적절한 데이터 구조를 선택하는 것이 매우 중요합니다. 데이터 구조에서 수행되는 특정 작업은 다른 데이터 구조에서 수행되는 동일한 작업에 비해 시간이 더 오래 걸릴 수 있기 때문입니다.
Example− 배열을 이용하여 집합 의 i 번째 원소에 접근하기 위해서는 일정한 시간이 소요될 수 있으나 연결리스트를 이용하면 동일한 연산을 수행하는 데 필요한 시간이 다항식이 될 수 있습니다.
따라서 데이터 구조의 선택은 수행 할 아키텍처와 작업 유형을 고려하여 이루어져야합니다.
다음 데이터 구조는 일반적으로 병렬 프로그래밍에 사용됩니다.
- 연결된 목록
- Arrays
- Hypercube 네트워크
연결된 목록
링크드리스트는 포인터로 연결된 0 개 이상의 노드가있는 데이터 구조입니다. 노드는 연속적인 메모리 위치를 차지할 수도 있고 차지하지 않을 수도 있습니다. 각 노드에는 2 개 또는 3 개의 부분이 있습니다.data part 데이터를 저장하고 나머지 두 개는 link fields이전 또는 다음 노드의 주소를 저장합니다. 첫 번째 노드의 주소는 다음과 같은 외부 포인터에 저장됩니다.head. 다음으로 알려진 마지막 노드tail, 일반적으로 주소를 포함하지 않습니다.
연결 목록에는 세 가지 유형이 있습니다.
- 단일 연결 목록
- 이중 연결 목록
- 순환 연결 목록
단일 연결 목록
단일 연결 목록의 노드에는 데이터와 다음 노드의 주소가 포함됩니다. 호출 된 외부 포인터head 첫 번째 노드의 주소를 저장합니다.

이중 연결 목록
이중 연결 목록의 노드에는 데이터와 이전 및 다음 노드의 주소가 모두 포함됩니다. 호출 된 외부 포인터head 첫 번째 노드의 주소와 호출 된 외부 포인터를 저장합니다. tail 마지막 노드의 주소를 저장합니다.

순환 연결 목록
순환 연결 목록은 마지막 노드가 첫 번째 노드의 주소를 저장했다는 점을 제외하면 단일 연결 목록과 매우 유사합니다.

배열
배열은 유사한 유형의 데이터를 저장할 수있는 데이터 구조입니다. 1 차원 또는 다차원 일 수 있습니다. 배열은 정적으로 또는 동적으로 만들 수 있습니다.
에 statically declared arrays, 배열의 차원과 크기는 컴파일 시점에 알려져 있습니다.
에 dynamically declared arrays, 배열의 차원과 크기는 런타임에 알려집니다.
공유 메모리 프로그래밍의 경우 배열을 공통 메모리로 사용할 수 있고 데이터 병렬 프로그래밍의 경우 하위 배열로 분할하여 사용할 수 있습니다.
Hypercube 네트워크
Hypercube 아키텍처는 각 작업이 다른 작업과 통신해야하는 병렬 알고리즘에 유용합니다. Hypercube 토폴로지는 링 및 메시와 같은 다른 토폴로지를 쉽게 포함 할 수 있습니다. n-cubes라고도합니다.n차원의 수입니다. 하이퍼 큐브는 재귀 적으로 구성 될 수 있습니다.


병렬 알고리즘을위한 적절한 설계 기법을 선택하는 것이 가장 어렵고 중요한 작업입니다. 대부분의 병렬 프로그래밍 문제에는 둘 이상의 솔루션이있을 수 있습니다. 이 장에서는 병렬 알고리즘을위한 다음과 같은 설계 기법에 대해 설명합니다.
- 분할 및 정복
- 욕심 많은 방법
- 동적 프로그래밍
- Backtracking
- 분기 및 경계
- 선형 프로그래밍
분할 및 정복 방법
분할 및 정복 접근법에서 문제는 몇 가지 작은 하위 문제로 나뉩니다. 그런 다음 하위 문제를 재귀 적으로 해결하고 결합하여 원래 문제의 솔루션을 얻습니다.
분할 및 정복 접근 방식은 각 수준에서 다음 단계를 포함합니다.
Divide − 원래 문제는 하위 문제로 나뉩니다.
Conquer − 하위 문제는 재귀 적으로 해결됩니다.
Combine − 하위 문제의 해가 함께 결합되어 원래 문제의 해를 구합니다.
분할 및 정복 접근법은 다음 알고리즘에 적용됩니다.
- 이진 검색
- 빠른 정렬
- 병합 정렬
- 정수 곱셈
- 매트릭스 반전
- 행렬 곱셈
욕심 많은 방법
욕심 많은 솔루션 최적화 알고리즘에서는 언제든지 최상의 솔루션이 선택됩니다. 탐욕스러운 알고리즘은 복잡한 문제에 적용하기가 매우 쉽습니다. 다음 단계에서 가장 정확한 솔루션을 제공 할 단계를 결정합니다.
이 알고리즘은 greedy더 작은 인스턴스에 대한 최적의 솔루션이 제공 될 때 알고리즘은 전체 프로그램을 전체로 고려하지 않기 때문입니다. 솔루션이 고려되면 탐욕 알고리즘은 동일한 솔루션을 다시 고려하지 않습니다.
탐욕스러운 알고리즘은 가능한 가장 작은 구성 요소 부분에서 개체 그룹을 반복적으로 생성합니다. 재귀는 특정 문제에 대한 솔루션이 해당 문제의 더 작은 인스턴스의 솔루션에 의존하는 문제를 해결하는 절차입니다.
동적 프로그래밍
동적 프로그래밍은 문제를 작은 하위 문제로 나누고 각 하위 문제를 해결 한 후 모든 솔루션을 결합하여 궁극적 인 솔루션을 얻는 최적화 기술입니다. 나누기 및 정복 방법과 달리 동적 프로그래밍은 하위 문제에 대한 솔루션을 여러 번 재사용합니다.
피보나치 시리즈의 재귀 알고리즘은 동적 프로그래밍의 예입니다.
역 추적 알고리즘
역 추적은 조합 문제를 해결하기위한 최적화 기술입니다. 프로그래밍 문제와 실제 문제 모두에 적용됩니다. 여덟 여왕 문제, 스도쿠 퍼즐 및 미로 통과는 역 추적 알고리즘이 사용되는 인기있는 예입니다.
역 추적에서는 필요한 모든 조건을 충족하는 가능한 솔루션으로 시작합니다. 그런 다음 다음 레벨로 이동하고 해당 레벨이 만족스러운 솔루션을 생성하지 않으면 한 레벨 뒤로 돌아가서 새로운 옵션으로 시작합니다.
분기 및 경계
분기 및 경계 알고리즘은 문제에 대한 최적의 솔루션을 얻기위한 최적화 기술입니다. 솔루션의 전체 공간에서 주어진 문제에 대한 최상의 솔루션을 찾습니다. 최적화 할 함수의 경계는 최신 최상의 솔루션 값과 병합됩니다. 이를 통해 알고리즘이 솔루션 공간의 일부를 완전히 찾을 수 있습니다.
분기 및 바운드 검색의 목적은 대상에 대한 최저 비용 경로를 유지하는 것입니다. 솔루션을 찾으면 솔루션을 계속 개선 할 수 있습니다. 분기 및 경계 검색은 깊이 경계 검색 및 깊이 우선 검색에서 구현됩니다.
선형 프로그래밍
선형 프로그래밍은 최적화 기준과 제약 조건이 모두 선형 함수 인 광범위한 최적화 작업 클래스를 설명합니다. 최대 수익, 최단 경로 또는 최저 비용과 같은 최상의 결과를 얻는 기술입니다.
이 프로그래밍에서 우리는 변수 세트를 가지고 있으며 선형 방정식 세트를 만족시키고 주어진 선형 목적 함수를 최대화하거나 최소화하기 위해 절대 값을 할당해야합니다.
행렬은 고정 된 수의 행과 열로 배열 된 숫자 및 비 숫자 데이터 집합입니다. 행렬 곱셈은 병렬 계산에서 중요한 곱셈 설계입니다. 여기서는 메쉬 및 하이퍼 큐브와 같은 다양한 통신 네트워크에서 행렬 곱셈의 구현에 대해 설명합니다. 메시와 하이퍼 큐브는 네트워크 연결성이 높기 때문에 링 네트워크와 같은 다른 네트워크보다 빠른 알고리즘을 허용합니다.
메시 네트워크
노드 집합이 p 차원 그리드를 형성하는 토폴로지를 메시 토폴로지라고합니다. 여기에서 모든 모서리는 그리드 축에 평행하고 모든 인접 노드는 서로 통신 할 수 있습니다.
총 노드 수 = (행의 노드 수) × (열의 노드 수)
메쉬 네트워크는 다음 요소를 사용하여 평가할 수 있습니다.
- Diameter
- 이등분 폭
Diameter − 메시 네트워크에서 가장 긴 distance두 노드 사이의 지름이 있습니다. p 차원 메쉬 네트워크kP 노드의 지름은 p(k–1).
Bisection width − Bisection width는 메쉬 네트워크를 두 개의 절반으로 나누기 위해 네트워크에서 제거해야하는 최소 가장자리 수입니다.
메시 네트워크를 사용한 행렬 곱셈
랩 어라운드 연결이있는 2D 메시 네트워크 SIMD 모델을 고려했습니다. 특정 시간 동안 n 2 프로세서를 사용하여 두 개의 n × n 어레이를 곱하는 알고리즘을 설계합니다 .
행렬 A와 B에는 각각 요소 a ij 와 b ij가 있습니다. 처리 요소 PE ij 는 a ij 및 b ij를 나타냅니다 . 모든 프로세서가 곱할 요소 쌍을 갖도록 행렬 A와 B를 배열하십시오. 행렬 A의 요소는 왼쪽 방향으로 이동하고 행렬 B의 요소는 위쪽 방향으로 이동합니다. 행렬 A와 B의 요소 위치에서의 이러한 변화는 곱할 새로운 값 쌍인 각 처리 요소 PE를 나타냅니다.
알고리즘의 단계
- 두 행렬을 엇갈리게 만듭니다.
- 모든 제품 계산, a ik × b kj
- 2 단계가 완료되면 합계를 계산합니다.
연산
Procedure MatrixMulti
Begin
for k = 1 to n-1
for all Pij; where i and j ranges from 1 to n
ifi is greater than k then
rotate a in left direction
end if
if j is greater than k then
rotate b in the upward direction
end if
for all Pij ; where i and j lies between 1 and n
compute the product of a and b and store it in c
for k= 1 to n-1 step 1
for all Pi;j where i and j ranges from 1 to n
rotate a in left direction
rotate b in the upward direction
c=c+aXb
EndHypercube 네트워크
하이퍼 큐브는 가장자리가 서로 직각이고 길이가 같은 n 차원 구조입니다. n 차원 하이퍼 큐브는 n 큐브 또는 n 차원 큐브라고도합니다.
2k 노드 가있는 Hypercube의 기능
- 지름 = k
- 이등분 너비 = 2k–1
- 모서리 수 = k
Hypercube 네트워크를 사용한 행렬 곱셈
Hypercube 네트워크의 일반 사양 −
허락하다 N = 2m총 프로세서 수입니다. 프로세서를 P 0, P 1 … ..P N-1이라고 합니다.
i와 i b 를 두 개의 정수, 0 <i, i b <N-1로 설정하고 이진 표현은 위치 b, 0 <b <k–1에서만 다릅니다.
두 개의 n × n 행렬, 행렬 A와 행렬 B를 고려해 보겠습니다.
Step 1− 행렬 A와 행렬 B의 요소는 위치 i, j, k의 프로세서가 ji 및 b ik를 갖도록 n 3 개의 프로세서에 할당됩니다 .
Step 2 − (i, j, k) 위치에있는 모든 프로세서가 제품을 계산합니다.
C (i, j, k) = A (i, j, k) × B (i, j, k)
Step 3 − 0 ≤ i ≤ n-1 (0 ≤ j, k <n-1)에 대한 합 C (0, j, k) = ΣC (i, j, k).
블록 매트릭스
블록 행렬 또는 분할 행렬은 각 요소 자체가 개별 행렬을 나타내는 행렬입니다. 이러한 개별 섹션을block 또는 sub-matrix.
예


그림 (a)에서 X는 A, B, C, D 자체가 행렬 인 블록 행렬입니다. 그림 (f)는 총 행렬을 보여줍니다.
블록 행렬 곱셈
두 개의 블록 행렬이 정사각형 행렬 인 경우 간단한 행렬 곱셈을 수행하는 방식으로 곱해집니다. 예를 들면

정렬은 특정 순서 (예 : 오름차순, 내림차순, 알파벳 순서 등)로 그룹의 요소를 배열하는 프로세스입니다. 여기서는 다음을 설명합니다.
- 열거 형 정렬
- 홀수 짝수 조옮김 정렬
- 병렬 병합 정렬
- 하이퍼 퀵 정렬
요소 목록을 정렬하는 것은 매우 일반적인 작업입니다. 순차 정렬 알고리즘은 대량의 데이터를 정렬해야 할 때 충분히 효율적이지 않을 수 있습니다. 따라서 정렬에는 병렬 알고리즘이 사용됩니다.
열거 형 정렬
열거 형 정렬은 정렬 된 목록에서 각 요소의 최종 위치를 찾아 목록의 모든 요소를 정렬하는 방법입니다. 각 요소를 다른 모든 요소와 비교하고 값이 작은 요소의 수를 찾아서 수행됩니다.
따라서 두 요소, a i 및 a j 에 대해 다음 경우 중 하나가 참이어야합니다.
- a 나는 <a j
- a i > a j
- a i = a j
연산
procedure ENUM_SORTING (n)
begin
for each process P1,j do
C[j] := 0;
for each process Pi, j do
if (A[i] < A[j]) or A[i] = A[j] and i < j) then
C[j] := 1;
else
C[j] := 0;
for each process P1, j do
A[C[j]] := A[j];
end ENUM_SORTING홀수 짝수 조옮김 정렬
홀수 짝수 전치 정렬은 버블 정렬 기술을 기반으로합니다. 인접한 두 숫자를 비교하고 첫 번째 숫자가 두 번째 숫자보다 큰 경우이를 전환하여 오름차순 목록을 얻습니다. 내림차순 시리즈에는 반대의 경우가 적용됩니다. 홀수 짝수 전치 정렬은 두 단계로 작동합니다.odd phase 과 even phase. 두 단계 모두에서 프로세스는 오른쪽에있는 인접 번호와 번호를 교환합니다.
연산
procedure ODD-EVEN_PAR (n)
begin
id := process's label
for i := 1 to n do
begin
if i is odd and id is odd then
compare-exchange_min(id + 1);
else
compare-exchange_max(id - 1);
if i is even and id is even then
compare-exchange_min(id + 1);
else
compare-exchange_max(id - 1);
end for
end ODD-EVEN_PAR병렬 병합 정렬
병합 정렬은 먼저 정렬되지 않은 목록을 가능한 가장 작은 하위 목록으로 나누고 인접한 목록과 비교 한 다음 정렬 된 순서로 병합합니다. 분할 및 정복 알고리즘을 따라 병렬 처리를 매우 훌륭하게 구현합니다.

연산
procedureparallelmergesort(id, n, data, newdata)
begin
data = sequentialmergesort(data)
for dim = 1 to n
data = parallelmerge(id, dim, data)
endfor
newdata = data
end하이퍼 퀵 정렬
하이퍼 빠른 정렬은 하이퍼 큐브에서 빠른 정렬을 구현 한 것입니다. 그 단계는 다음과 같습니다-
- 정렬되지 않은 목록을 각 노드로 나눕니다.
- 각 노드를 로컬로 정렬합니다.
- 노드 0에서 중앙값을 브로드 캐스트합니다.
- 각 목록을 로컬로 분할 한 다음 가장 높은 차원에서 절반을 교환합니다.
- 치수가 0이 될 때까지 3 단계와 4 단계를 병렬로 반복합니다.
연산
procedure HYPERQUICKSORT (B, n)
begin
id := process’s label;
for i := 1 to d do
begin
x := pivot;
partition B into B1 and B2 such that B1 ≤ x < B2;
if ith bit is 0 then
begin
send B2 to the process along the ith communication link;
C := subsequence received along the ith communication link;
B := B1 U C;
endif
else
send B1 to the process along the ith communication link;
C := subsequence received along the ith communication link;
B := B2 U C;
end else
end for
sort B using sequential quicksort;
end HYPERQUICKSORT검색은 컴퓨터 과학의 기본 작업 중 하나입니다. 요소가 주어진 목록에 있는지 여부를 찾아야하는 모든 응용 프로그램에서 사용됩니다. 이 장에서는 다음 검색 알고리즘에 대해 설명합니다.
- 분할 및 정복
- 깊이 우선 검색
- 폭 우선 검색
- 최우선 검색
분할 및 정복
분할 및 정복 접근법에서 문제는 몇 가지 작은 하위 문제로 나뉩니다. 그런 다음 하위 문제를 재귀 적으로 해결하고 결합하여 원래 문제의 솔루션을 얻습니다.
분할 및 정복 접근 방식은 각 수준에서 다음 단계를 포함합니다.
Divide − 원래 문제는 하위 문제로 나뉩니다.
Conquer − 하위 문제는 재귀 적으로 해결됩니다.
Combine − 하위 문제의 해를 결합하여 원래 문제의 해를 구합니다.
이진 검색은 분할 및 정복 알고리즘의 예입니다.
의사 코드
Binarysearch(a, b, low, high)
if low < high then
return NOT FOUND
else
mid ← (low+high) / 2
if b = key(mid) then
return key(mid)
else if b < key(mid) then
return BinarySearch(a, b, low, mid−1)
else
return BinarySearch(a, b, mid+1, high)깊이 우선 검색
깊이 우선 검색 (또는 DFS)은 트리 또는 무 방향 그래프 데이터 구조를 검색하는 알고리즘입니다. 여기서 개념은 시작 노드에서 시작하는 것입니다.root같은 지점에서 가능한 한 멀리 횡단합니다. 후속 노드가없는 노드를 얻으면 아직 방문하지 않은 정점으로 돌아가 계속합니다.
깊이 우선 검색 단계
이전에 방문하지 않은 노드 (루트)를 고려하고 방문한 것으로 표시하십시오.
첫 번째 인접 후속 노드를 방문하여 방문한 것으로 표시합니다.
고려 된 노드의 모든 후속 노드가 이미 방문되었거나 더 이상 후속 노드가없는 경우 상위 노드로 돌아갑니다.
의사 코드
허락하다 v 그래프에서 검색이 시작되는 꼭지점 G.
DFS(G,v)
Stack S := {};
for each vertex u, set visited[u] := false;
push S, v;
while (S is not empty) do
u := pop S;
if (not visited[u]) then
visited[u] := true;
for each unvisited neighbour w of u
push S, w;
end if
end while
END DFS()폭 우선 검색
BFS (Breadth-First Search)는 트리 또는 무 방향 그래프 데이터 구조를 검색하는 알고리즘입니다. 여기서는 노드로 시작한 다음 동일한 수준의 모든 인접 노드를 방문한 다음 다음 수준의 인접한 후속 노드로 이동합니다. 이것은 또한 알려진level-by-level search.
폭 우선 검색의 단계
- 루트 노드로 시작하여 방문한 것으로 표시하십시오.
- 루트 노드에는 동일한 수준의 노드가 없으므로 다음 수준으로 이동합니다.
- 인접한 모든 노드를 방문하고 방문한 것으로 표시하십시오.
- 다음 레벨로 이동하여 방문하지 않은 모든 인접 노드를 방문하십시오.
- 모든 노드를 방문 할 때까지이 프로세스를 계속하십시오.
의사 코드
허락하다 v 그래프에서 검색이 시작되는 꼭지점 G.
BFS(G,v)
Queue Q := {};
for each vertex u, set visited[u] := false;
insert Q, v;
while (Q is not empty) do
u := delete Q;
if (not visited[u]) then
visited[u] := true;
for each unvisited neighbor w of u
insert Q, w;
end if
end while
END BFS()최우선 검색
Best-First Search는 가능한 최단 경로에서 목표에 도달하기 위해 그래프를 순회하는 알고리즘입니다. BFS 및 DFS와 달리 Best-First Search는 평가 기능을 따라 다음에 순회하기에 가장 적합한 노드를 결정합니다.
Best-First Search 단계
- 루트 노드로 시작하여 방문한 것으로 표시하십시오.
- 다음 적절한 노드를 찾아 방문한 것으로 표시하십시오.
- 다음 레벨로 이동하여 적절한 노드를 찾아 방문한 것으로 표시하십시오.
- 목표에 도달 할 때까지이 프로세스를 계속하십시오.
의사 코드
BFS( m )
Insert( m.StartNode )
Until PriorityQueue is empty
c ← PriorityQueue.DeleteMin
If c is the goal
Exit
Else
Foreach neighbor n of c
If n "Unvisited"
Mark n "Visited"
Insert( n )
Mark c "Examined"
End procedure그래프는 개체 쌍 간의 연결을 나타내는 데 사용되는 추상 표기법입니다. 그래프는-
Vertices− 그래프에서 상호 연결된 개체를 정점이라고합니다. 정점은 다음과 같이 알려져 있습니다.nodes.
Edges − Edge는 정점을 연결하는 링크입니다.
두 가지 유형의 그래프가 있습니다.
Directed graph − 유 방향 그래프에서 에지는 방향을가집니다.
Undirected graph − 무 방향 그래프에서 간선에는 방향이 없습니다.
그래프 채색
그래프 색상 지정은 인접한 두 정점이 같은 색을 갖지 않도록 그래프의 정점에 색상을 할당하는 방법입니다. 일부 그래프 색상 문제는 다음과 같습니다.
Vertex coloring − 인접한 두 정점이 같은 색을 공유하지 않도록 그래프의 정점을 채색하는 방법.
Edge Coloring − 인접한 두 모서리가 같은 색을 가지지 않도록 각 모서리에 색상을 할당하는 방법입니다.
Face coloring − 평면 그래프의 각면 또는 영역에 색을 할당하여 공통 경계를 공유하는 두면이 같은 색을 갖지 않도록합니다.
색채 번호
색수는 그래프를 색칠하는 데 필요한 최소 색상 수입니다. 예를 들어, 다음 그래프의 색수는 3입니다.

그래프 채색의 개념은 시간표 작성, 모바일 무선 주파수 할당, Suduku, 레지스터 할당 및지도 채색에 적용됩니다.
그래프 채색 단계
n 차원 배열에있는 각 프로세서의 초기 값을 1로 설정합니다.
이제 특정 색상을 정점에 할당하려면 해당 색상이 이미 인접한 정점에 할당되었는지 여부를 확인합니다.
프로세서가 인접한 정점에서 동일한 색상을 감지하면 배열의 값을 0으로 설정합니다.
n 2 비교를 한 후 배열의 요소가 1이면 유효한 색상입니다.
그래프 채색을위한 의사 코드
begin
create the processors P(i0,i1,...in-1) where 0_iv < m, 0 _ v < n
status[i0,..in-1] = 1
for j varies from 0 to n-1 do
begin
for k varies from 0 to n-1 do
begin
if aj,k=1 and ij=ikthen
status[i0,..in-1] =0
end
end
ok = ΣStatus
if ok > 0, then display valid coloring exists
else
display invalid coloring
end최소 스패닝 트리
모든 모서리의 가중치 (또는 길이)의 합이 그래프 G의 다른 모든 가능한 스패닝 트리보다 작은 스패닝 트리는 minimal spanning tree 또는 minimum cost spanning나무. 다음 그림은 가중 연결 그래프를 보여줍니다.

위 그래프의 가능한 스패닝 트리는 다음과 같습니다.



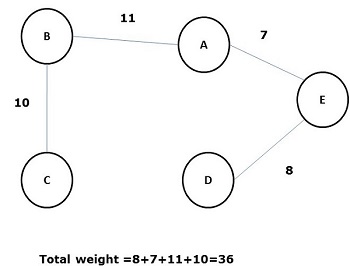



위의 모든 스패닝 트리 중에서 그림 (d)는 최소 스패닝 트리입니다. 최소 비용 스패닝 트리의 개념은 출장 세일즈맨 문제, 전자 회로 설계, 효율적인 네트워크 설계 및 효율적인 라우팅 알고리즘 설계에 적용됩니다.
최소 비용 스패닝 트리를 구현하기 위해 다음 두 가지 방법이 사용됩니다.
- 프림의 알고리즘
- Kruskal의 알고리즘
프림의 알고리즘
Prim의 알고리즘은 가중 된 무 방향 그래프에 대한 최소 스패닝 트리를 찾는 데 도움이되는 탐욕스러운 알고리즘입니다. 먼저 정점을 선택하고 해당 정점에 입사되는 가중치가 가장 낮은 모서리를 찾습니다.
프림 알고리즘의 단계
그래프 G의 v 1 과 같은 정점을 선택합니다 .
e 1 = v 1 v 2 및 v 1 ≠ v 2 및 e 1 이 그래프 G 에서 v 1 에 입사 하는 간선 사이에 최소 가중치를 갖도록 G의 e 1 과 같은 간선을 선택합니다 .
이제 2 단계에 따라 v 2 에서 최소 가중 에지 입사를 선택합니다 .
n–1 모서리가 선택 될 때까지 계속합니다. 여기n 정점의 수입니다.

최소 스패닝 트리는-

Kruskal의 알고리즘
Kruskal의 알고리즘은 연결된 가중치 그래프에 대한 최소 스패닝 트리를 찾는 데 도움이되는 탐욕스러운 알고리즘으로 각 단계에서 비용이 증가합니다. 포리스트의 두 트리를 연결하는 가능한 최소 가중치의 가장자리를 찾는 최소 스패닝 트리 알고리즘입니다.
Kruskal 알고리즘의 단계
최소 무게의 모서리를 선택하십시오. 말하자면 전자 1 그래프 G 및 E 중 하나는 루프 아니다.
e 1에 연결된 다음 최소 가중치 모서리를 선택합니다 .
n–1 모서리가 선택 될 때까지 계속합니다. 여기n 정점의 수입니다.

위 그래프의 최소 스패닝 트리는 다음과 같습니다.
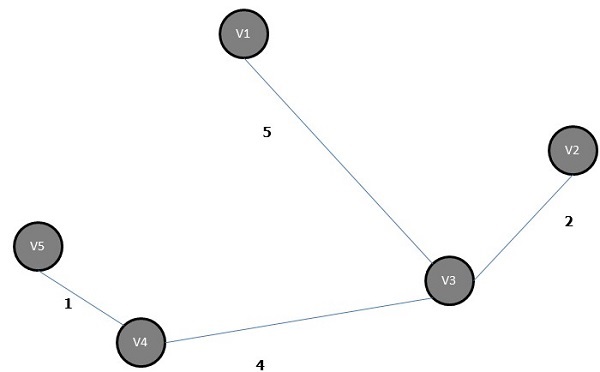
최단 경로 알고리즘
최단 경로 알고리즘은 소스 노드 (S)에서 대상 노드 (D)까지의 최소 비용 경로를 찾는 방법입니다. 여기서는 Breadth First Search Algorithm이라고도하는 Moore의 알고리즘에 대해 설명합니다.
무어의 알고리즘
소스 정점 S에 레이블을 지정하고 레이블을 지정합니다. i 및 설정 i=0.
레이블이 지정된 정점에 인접한 레이블이없는 모든 정점 찾기 i. 정점에 연결된 정점이 없으면 S, 정점 D는 S에 연결되지 않습니다. S에 연결된 정점이 있으면 레이블을 지정합니다.i+1.
D에 레이블이 지정되어 있으면 4 단계로 이동하고 그렇지 않으면 2 단계로 이동하여 i = i + 1을 늘립니다.
최단 경로의 길이를 찾은 후 중지하십시오.