Python 데이터 지속성-Cassandra 드라이버
Cassandra는 또 다른 인기있는 NoSQL 데이터베이스입니다. 높은 확장 성, 일관성 및 내결함성-이들은 Cassandra의 중요한 기능 중 일부입니다. 이것은Column store데이터 베이스. 데이터는 많은 상용 서버에 저장됩니다. 결과적으로 데이터의 가용성이 높아집니다.
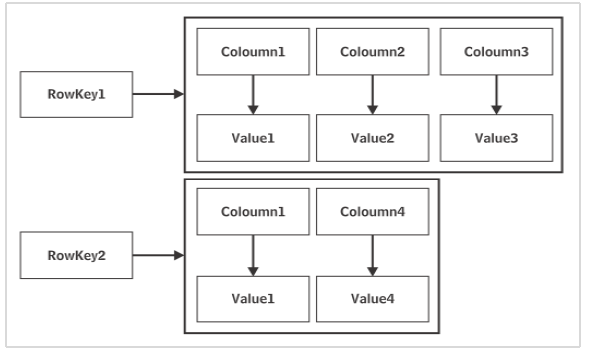
Cassandra는 Apache Software Foundation의 제품입니다. 데이터는 여러 노드에 분산 방식으로 저장됩니다. 각 노드는 키 스페이스로 구성된 단일 서버입니다. Cassandra 데이터베이스의 기본 구성 요소는keyspace 데이터베이스와 유사한 것으로 간주 될 수 있습니다.
Cassandra의 한 노드에있는 데이터는 피어-투-피어 노드 네트워크를 통해 다른 노드에 복제됩니다. 그것은 Cassandra를 완벽한 데이터베이스로 만듭니다. 네트워크를 데이터 센터라고합니다. 여러 데이터 센터를 상호 연결하여 클러스터를 형성 할 수 있습니다. 복제 특성은 키 스페이스 생성시 복제 전략 및 복제 요소를 설정하여 구성됩니다.
하나의 데이터베이스에 여러 테이블이 포함될 수있는 것처럼 하나의 키 스페이스에는 둘 이상의 Column family가있을 수 있습니다. Cassandra의 키 스페이스에는 미리 정의 된 스키마가 없습니다. Cassandra 테이블의 각 행에는 이름과 변수 번호가 다른 열이있을 수 있습니다.
Cassandra 소프트웨어는 커뮤니티와 엔터프라이즈의 두 가지 버전으로도 제공됩니다. 최신 엔터프라이즈 버전의 Cassandra는 다음 사이트에서 다운로드 할 수 있습니다.https://cassandra.apache.org/download/. 커뮤니티 에디션은https://academy.datastax.com/planet-cassandra/cassandra.
Cassandra에는 자체 쿼리 언어가 있습니다. Cassandra Query Language (CQL). CQL 쿼리는 MySQL 또는 SQLite 셸과 유사한 CQLASH 셸 내부에서 실행할 수 있습니다. CQL 구문은 표준 SQL과 유사합니다.
Datastax 커뮤니티 에디션은 다음 그림과 같이 Develcenter IDE와 함께 제공됩니다.
Cassandra 데이터베이스 작업을위한 Python 모듈이 호출됩니다. Cassandra Driver. 또한 Apache 재단에서 개발했습니다. 이 모듈에는 ORM API는 물론 관계형 데이터베이스 용 DB-API와 본질적으로 유사한 핵심 API가 포함되어 있습니다.
Cassandra 드라이버 설치는 다음을 사용하여 쉽게 수행됩니다. pip utility.
pip3 install cassandra-driverCassandra 데이터베이스와의 상호 작용은 Cluster 개체를 통해 수행됩니다. Cassandra.cluster 모듈은 Cluster 클래스를 정의합니다. 먼저 Cluster 객체를 선언해야합니다.
from cassandra.cluster import Cluster
clstr=Cluster()삽입 / 업데이트 등과 같은 모든 트랜잭션은 키 스페이스로 세션을 시작하여 수행됩니다.
session=clstr.connect()새 키 스페이스를 생성하려면 execute()세션 개체의 메서드. execute () 메서드는 쿼리 문자열이어야하는 문자열 인수를 사용합니다. CQL에는 다음과 같은 CREATE KEYSPACE 문이 있습니다. 완전한 코드는 다음과 같습니다.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect()
session.execute(“create keyspace mykeyspace with replication={
'class': 'SimpleStrategy', 'replication_factor' : 3
};”여기, SimpleStrategy 값입니다 replication strategy 과 replication factor앞에서 언급했듯이 키 스페이스에는 하나 이상의 테이블이 포함됩니다. 각 테이블은 데이터 유형이 특징입니다. Python 데이터 유형은 다음 표에 따라 해당 CQL 데이터 유형으로 자동 구문 분석됩니다.
| 파이썬 유형 | CQL 유형 |
|---|---|
| 없음 | 없는 |
| 부울 | 부울 |
| 흙손 | float, double |
| int, long | int, bigint, varint, smallint, tinyint, 카운터 |
| decimal.Decimal | 소수 |
| str, 유니 코드 | ascii, varchar, 텍스트 |
| 버퍼, 바이트 배열 | 얼룩 |
| 데이트 | 데이트 |
| 날짜 시간 | 타임 스탬프 |
| 시각 | 시각 |
| 목록, 튜플, 생성기 | 명부 |
| set, frozenset | 세트 |
| dict, OrderedDict | 지도 |
| uuid.UUID | timeuuid, uuid |
테이블을 생성하려면 세션 객체를 사용하여 테이블 생성을위한 CQL 쿼리를 실행합니다.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
qry= '''
create table students (
studentID int,
name text,
age int,
marks int,
primary key(studentID)
);'''
session.execute(qry)이렇게 생성 된 키 스페이스는 행을 삽입하는 데 사용할 수 있습니다. INSERT 쿼리의 CQL 버전은 SQL Insert 문과 유사합니다. 다음 코드는 students 테이블에 행을 삽입합니다.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
session.execute("insert into students (studentID, name, age, marks) values
(1, 'Juhi',20, 200);"예상대로 SELECT 문은 Cassandra에서도 사용됩니다. SELECT 쿼리 문자열이 포함 된 execute () 메서드의 경우 루프를 사용하여 순회 할 수있는 결과 집합 객체를 반환합니다.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
rows=session.execute("select * from students;")
for row in rows:
print (StudentID: {} Name:{} Age:{} price:{} Marks:{}'
.format(row[0],row[1], row[2], row[3]))Cassandra의 SELECT 쿼리는 가져올 결과 집합에 필터를 적용하기 위해 WHERE 절 사용을 지원합니다. <,> == 등과 같은 전통적인 논리 연산자가 인식됩니다. 검색하려면 학생 테이블에서 나이가 20 세 이상인 이름의 행만 실행 () 메서드의 쿼리 문자열은 다음과 같아야합니다.
rows=session.execute("select * from students WHERE age>20 allow filtering;")참고, 사용 ALLOW FILTERING. 이 문의 ALLOW FILTERING 부분은 필터링이 필요한 (일부) 쿼리를 명시 적으로 허용 할 수 있습니다.
Cassandra 드라이버 API는 cassendra.query 모듈에서 다음과 같은 Statement 유형 클래스를 정의합니다.
SimpleStatement
쿼리 문자열에 포함 된 단순하고 준비되지 않은 CQL 쿼리입니다. 위의 모든 예는 SimpleStatement의 예입니다.
BatchStatement
여러 쿼리 (예 : INSERT, UPDATE 및 DELETE)가 일괄 처리되고 한 번에 실행됩니다. 각 행은 먼저 SimpleStatement로 변환 된 다음 일괄 처리에 추가됩니다.
다음과 같이 튜플 목록의 형태로 Students 테이블에 추가 할 행을 입력합니다.
studentlist=[(1,'Juhi',20,100), ('2,'dilip',20, 110),(3,'jeevan',24,145)]BathStatement를 사용하여 위의 행을 추가하려면 다음 스크립트를 실행하십시오.
from cassandra.query import SimpleStatement, BatchStatement
batch=BatchStatement()
for student in studentlist:
batch.add(SimpleStatement("INSERT INTO students
(studentID, name, age, marks) VALUES
(%s, %s, %s %s)"), (student[0], student[1],student[2], student[3]))
session.execute(batch)PreparedStatement
준비된 문은 DB-API의 매개 변수화 된 쿼리와 같습니다. 쿼리 문자열은 나중에 사용하기 위해 Cassandra에 의해 저장됩니다. Session.prepare () 메서드는 PreparedStatement 인스턴스를 반환합니다.
학생 테이블의 경우 INSERT 쿼리에 대한 PreparedStatement는 다음과 같습니다.
stmt=session.prepare("INSERT INTO students (studentID, name, age, marks) VALUES (?,?,?)")이후에는 바인딩 할 매개 변수 값만 보내면됩니다. 예를 들면-
qry=stmt.bind([1,'Ram', 23,175])마지막으로 위의 바인딩 된 문을 실행합니다.
session.execute(qry)이렇게하면 Cassandra가 매번 쿼리를 다시 구문 분석 할 필요가 없기 때문에 네트워크 트래픽과 CPU 사용률이 감소합니다.