Python 데이터 지속성-SQLAlchemy
모든 관계형 데이터베이스는 테이블에 데이터를 보유합니다. 테이블 구조는 기본적으로 기본 데이터 유형으로 만 구성된 속성의 데이터 유형을 정의하며 해당하는 Python 내장 데이터 유형에 매핑됩니다. 그러나 Python의 사용자 정의 객체는 SQL 테이블에 영구적으로 저장 및 검색 할 수 없습니다.
이것은 SQL 유형과 Python과 같은 객체 지향 프로그래밍 언어 간의 차이입니다. SQL에는 dict, tuple, list 또는 사용자 정의 클래스와 같은 다른 데이터 유형에 해당하는 데이터 유형이 없습니다.
관계형 데이터베이스에 개체를 저장해야하는 경우 INSERT 쿼리를 실행하기 전에 먼저 인스턴스 속성을 SQL 데이터 유형으로 분해해야합니다. 반면에 SQL 테이블에서 검색된 데이터는 기본 유형입니다. 원하는 유형의 Python 객체는 Python 스크립트에서 사용하기 위해를 사용하여 구성해야합니다. 이것이 Object Relational Mapper가 유용한 곳입니다.
객체 관계 매퍼 (ORM)
안 Object Relation Mapper(ORM)은 클래스와 SQL 테이블 간의 인터페이스입니다. Python 클래스는 데이터베이스의 특정 테이블에 매핑되므로 객체 유형과 SQL 유형 간의 변환이 자동으로 수행됩니다.
Python 코드로 작성된 Students 클래스는 데이터베이스의 Students 테이블에 매핑됩니다. 결과적으로 모든 CRUD 작업은 클래스의 각 메서드를 호출하여 수행됩니다. 따라서 Python 스크립트에서 하드 코딩 된 SQL 쿼리를 실행할 필요가 없습니다.
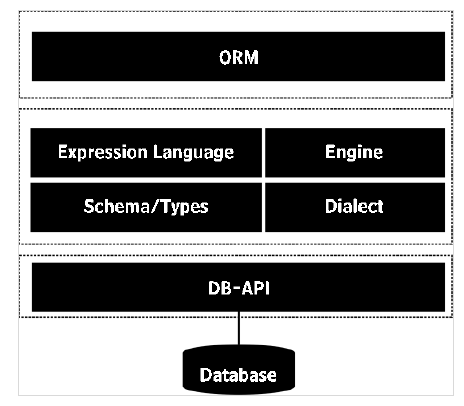
따라서 ORM 라이브러리는 원시 SQL 쿼리에 대한 추상화 계층 역할을하며 신속한 애플리케이션 개발에 도움이 될 수 있습니다. SQLAlchemyPython에서 널리 사용되는 객체 관계형 매퍼입니다. 모델 객체의 상태 조작은 데이터베이스 테이블의 관련 행과 동기화됩니다.
SQLALchemy 라이브러리에는 다음이 포함됩니다. ORM API 및 SQL 표현식 언어 (SQLAlchemy Core). 표현 언어는 관계형 데이터베이스의 기본 구조를 직접 실행합니다.
ORM은 SQL Expression Language 위에 구축 된 높은 수준의 추상화 된 사용 패턴입니다. ORM은 Expression Language의 적용 용도라고 할 수 있습니다. 이 주제에서는 SQLAlchemy ORM API에 대해 논의하고 SQLite 데이터베이스를 사용합니다.
SQLAlchemy는 dialect 시스템을 사용하는 각각의 DBAPI 구현을 통해 다양한 유형의 데이터베이스와 통신합니다. 모든 언어를 사용하려면 적절한 DBAPI 드라이버가 설치되어 있어야합니다. 다음 유형의 데이터베이스에 대한 방언이 포함됩니다.
- Firebird
- 마이크로 소프트 SQL 서버
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase
SQLAlchemy의 설치는 pip 유틸리티를 사용하여 쉽고 간단합니다.
pip install sqlalchemySQLalchemy가 제대로 설치되었는지 확인하려면 Python 프롬프트에 다음을 입력하십시오.
>>> import sqlalchemy
>>>sqlalchemy.__version__
'1.3.11'데이터베이스와의 상호 작용은 반환 값으로 얻은 Engine 개체를 통해 수행됩니다. create_engine() 함수.
engine =create_engine('sqlite:///mydb.sqlite')SQLite를 사용하면 메모리 내 데이터베이스를 만들 수 있습니다. 인 메모리 데이터베이스 용 SQLAlchemy 엔진은 다음과 같이 생성됩니다.
from sqlalchemy import create_engine
engine=create_engine('sqlite:///:memory:')대신 MySQL 데이터베이스를 사용하려면 해당 DB-API 모듈 인 pymysql 및 각 dialect 드라이버를 사용하십시오.
engine = create_engine('mysql+pymydsql://root@localhost/mydb')create_engine에는 선택적 echo 인수가 있습니다. true로 설정하면 엔진에서 생성 한 SQL 쿼리가 터미널에 에코됩니다.
SQLAlchemy는 다음을 포함합니다. declarative base수업. 모델 클래스 및 매핑 된 테이블의 카탈로그 역할을합니다.
from sqlalchemy.ext.declarative import declarative_base
base=declarative_base()다음 단계는 모델 클래스를 정의하는 것입니다. 위와 같이 declarative_base 클래스의 기본 객체에서 파생되어야합니다.
__ 설정tablename__ 속성을 데이터베이스에 만들려는 테이블의 이름으로 변경합니다. 다른 속성은 필드에 해당합니다. 각각은 SQLAlchemy의 Column 객체이며 데이터 유형은 아래 목록 중 하나입니다-
- BigInteger
- Boolean
- Date
- DateTime
- Float
- Integer
- Numeric
- SmallInteger
- String
- Text
- Time
다음 코드는 Students 테이블에 매핑 된 Student라는 이름의 모델 클래스입니다.
#myclasses.py
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Numeric
base=declarative_base()
class Student(base):
__tablename__='Students'
StudentID=Column(Integer, primary_key=True)
name=Column(String)
age=Column(Integer)
marks=Column(Numeric)해당 구조의 Students 테이블을 생성하려면 기본 클래스에 대해 정의 된 create_all () 메서드를 실행합니다.
base.metadata.create_all(engine)이제 Student 클래스의 객체를 선언해야합니다. 데이터베이스에서 데이터 추가, 삭제 또는 검색 등과 같은 모든 데이터베이스 트랜잭션은 Session 개체에 의해 처리됩니다.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()Student 객체에 저장된 데이터는 세션의 add () 메서드에 의해 기본 테이블에 물리적으로 추가됩니다.
s1 = Student(name='Juhi', age=25, marks=200)
sessionobj.add(s1)
sessionobj.commit()다음은 students 테이블에 레코드를 추가하는 전체 코드입니다. 실행되면 해당 SQL 문 로그가 콘솔에 표시됩니다.
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
from myclasses import Student, base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
s1 = Student(name='Juhi', age=25, marks=200)
sessionobj.add(s1)
sessionobj.commit()콘솔 출력
CREATE TABLE "Students" (
"StudentID" INTEGER NOT NULL,
name VARCHAR,
age INTEGER,
marks NUMERIC,
PRIMARY KEY ("StudentID")
)
INFO sqlalchemy.engine.base.Engine ()
INFO sqlalchemy.engine.base.Engine COMMIT
INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
INFO sqlalchemy.engine.base.Engine INSERT INTO "Students" (name, age, marks) VALUES (?, ?, ?)
INFO sqlalchemy.engine.base.Engine ('Juhi', 25, 200.0)
INFO sqlalchemy.engine.base.Engine COMMIT그만큼 session object는 또한 add_all () 메서드를 제공하여 단일 트랜잭션에 둘 이상의 개체를 삽입합니다.
sessionobj.add_all([s2,s3,s4,s5])
sessionobj.commit()이제 테이블에 레코드가 추가되었으므로 SELECT 쿼리와 마찬가지로 테이블에서 가져 오려고합니다. 세션 개체에는 작업을 수행하는 query () 메서드가 있습니다. Query 객체는 Student 모델에서 query () 메서드에 의해 반환됩니다.
qry=seesionobj.query(Student)이 Query 객체의 get () 메소드를 사용하여 주어진 기본 키에 해당하는 객체를 가져옵니다.
S1=qry.get(1)이 문이 실행되는 동안 콘솔에 표시되는 해당 SQL 문은 다음과 같습니다.
BEGIN (implicit)
SELECT "Students"."StudentID" AS "Students_StudentID", "Students".name AS
"Students_name", "Students".age AS "Students_age",
"Students".marks AS "Students_marks"
FROM "Students"
WHERE "Products"."Students" = ?
sqlalchemy.engine.base.Engine (1,)query.all () 메소드는 루프를 사용하여 순회 할 수있는 모든 객체의 목록을 반환합니다.
from sqlalchemy import Column, Integer, String, Numeric
from sqlalchemy import create_engine
from myclasses import Student,base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
qry=sessionobj.query(Students)
rows=qry.all()
for row in rows:
print (row)매핑 된 테이블에서 레코드를 업데이트하는 것은 매우 쉽습니다. get () 메서드를 사용하여 레코드를 가져오고 원하는 속성에 새 값을 할당 한 다음 세션 개체를 사용하여 변경 사항을 커밋하기 만하면됩니다. 아래에서 Juhi 학생의 점수를 100으로 변경합니다.
S1=qry.get(1)
S1.marks=100
sessionobj.commit()레코드를 삭제하는 것은 세션에서 원하는 객체를 삭제하는 것만 큼 쉽습니다.
S1=qry.get(1)
Sessionobj.delete(S1)
sessionobj.commit()