심층 신경망
심층 신경망 (DNN)은 입력 레이어와 출력 레이어 사이에 숨겨진 레이어가 여러 개있는 ANN입니다. 얕은 ANN과 유사하게 DNN은 복잡한 비선형 관계를 모델링 할 수 있습니다.
신경망의 주요 목적은 일련의 입력을 받고, 점진적으로 복잡한 계산을 수행하고, 분류와 같은 실제 문제를 해결하기 위해 출력을 제공하는 것입니다. 우리는 신경망을 전달하도록 제한합니다.
우리는 딥 네트워크에 입력, 출력 및 순차적 데이터 흐름이 있습니다.
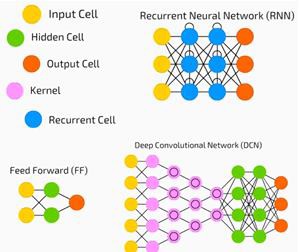
신경망은지도 학습 및 강화 학습 문제에 널리 사용됩니다. 이러한 네트워크는 서로 연결된 계층 집합을 기반으로합니다.
딥 러닝에서는 대부분 비선형 인 은닉층의 수가 많을 수 있습니다. 약 1000 개의 층을 말합니다.
DL 모델은 일반 ML 네트워크보다 훨씬 더 나은 결과를 생성합니다.
네트워크를 최적화하고 손실 함수를 최소화하기 위해 주로 경사 하강 법을 사용합니다.
우리는 Imagenet는 데이터 세트를 고양이와 개와 같은 카테고리로 분류하기위한 수백만 개의 디지털 이미지 저장소입니다. DL 넷은 정적 이미지와는 별도로 동적 이미지와 시계열 및 텍스트 분석에 점점 더 많이 사용됩니다.
데이터 세트 훈련은 딥 러닝 모델의 중요한 부분을 형성합니다. 또한 역전 파는 DL 모델 훈련의 주요 알고리즘입니다.
DL은 복잡한 입력 출력 변환으로 대규모 신경망 훈련을 처리합니다.
DL의 한 가지 예는 소셜 네트워크에서하는 것처럼 사진에있는 사람 (들)의 이름에 사진을 매핑하는 것입니다. 문구로 사진을 설명하는 것은 DL의 또 다른 최근 응용 프로그램입니다.
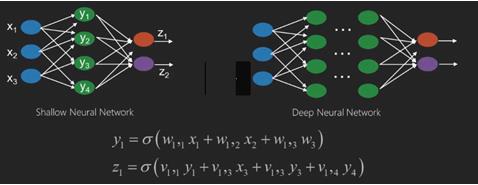
신경망은 x1, x2, x3…와 같은 입력이있는 함수로, z1, z2, z3 등과 같은 출력으로 변환되어 2 개 (얕은 네트워크) 또는 여러 중간 작업 (딥 네트워크)이라고도합니다.
가중치와 편향은 레이어마다 변경됩니다. 'w'와 'v'는 신경망 계층의 가중치 또는 시냅스입니다.
딥 러닝의 가장 좋은 사용 사례는지도 학습 문제입니다. 여기에는 원하는 출력 세트가있는 대규모 데이터 입력 세트가 있습니다.
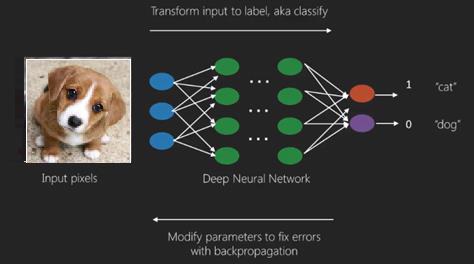
여기서 우리는 정확한 출력 예측을 얻기 위해 역 전파 알고리즘을 적용합니다.
딥 러닝의 가장 기본적인 데이터 세트는 손으로 쓴 숫자의 데이터 세트 인 MNIST입니다.
Keras로 심층 컨볼 루션 신경망을 훈련하여이 데이터 세트에서 손으로 쓴 숫자의 이미지를 분류 할 수 있습니다.
신경망 분류기의 실행 또는 활성화는 점수를 생성합니다. 예를 들어 환자를 아프고 건강한 것으로 분류하기 위해 키, 체중, 체온, 혈압 등과 같은 매개 변수를 고려합니다.
높은 점수는 환자가 아프다는 것을 의미하고 낮은 점수는 그가 건강하다는 것을 의미합니다.
출력 및 히든 레이어의 각 노드에는 자체 분류자가 있습니다. 입력 레이어는 추가 활성화를 위해 입력을 받아 다음 은닉 레이어로 점수를 전달하며 출력에 도달 할 때까지 계속됩니다.
입력에서 출력으로 왼쪽에서 오른쪽으로 순방향으로 진행하는 과정을 forward propagation.
신경망의 CAP (크레딧 할당 경로)는 입력에서 출력으로 시작하는 일련의 변환입니다. CAP는 입력과 출력 사이의 가능한 인과 관계를 자세히 설명합니다.
주어진 피드 포워드 신경망에 대한 CAP 깊이 또는 CAP 깊이는 숨겨진 계층의 수에 출력 계층이 포함됨에 따라 1을 더한 것입니다. 신호가 계층을 통해 여러 번 전파 될 수있는 순환 신경망의 경우 CAP 깊이는 잠재적으로 무한 할 수 있습니다.
깊은 그물과 얕은 그물
얕은 학습과 딥 러닝을 구분하는 명확한 깊이 임계 값은 없습니다. 그러나 여러 비선형 계층이있는 딥 러닝의 경우 CAP가 2보다 커야한다는 데 대부분 동의합니다.
신경망의 기본 노드는 생물학적 신경망의 뉴런을 모방 한 인식입니다. 그런 다음 다중 계층 인식 또는 MLP가 있습니다. 각 입력 세트는 가중치 및 편향 세트에 의해 수정됩니다. 각 에지에는 고유 한 가중치가 있고 각 노드에는 고유 한 편향이 있습니다.
예측 accuracy 신경망의 weights and biases.
신경망의 정확도를 높이는 과정을 training. 전방 소품 망의 출력은 올바른 것으로 알려진 값과 비교됩니다.
그만큼 cost function or the loss function 생성 된 출력과 실제 출력의 차이입니다.
훈련의 요점은 수백만 개의 훈련 예제에서 훈련 비용을 가능한 한 작게 만드는 것입니다.이를 위해 네트워크는 예측이 올바른 출력과 일치 할 때까지 가중치와 편향을 조정합니다.
잘 훈련되면 신경망은 매번 정확한 예측을 할 수 있습니다.
패턴이 복잡해지고 컴퓨터가이를 인식하도록하려면 신경망을 사용해야합니다. 이러한 복잡한 패턴 시나리오에서 신경망은 다른 경쟁 알고리즘보다 성능이 뛰어납니다.
이제 그 어느 때보 다 빠르게 훈련 할 수있는 GPU가 있습니다. 심층 신경망은 이미 AI 분야를 혁신하고 있습니다.
컴퓨터는 반복적 인 계산을 수행하고 자세한 지침을 따르는 데 능숙 함이 입증되었지만 복잡한 패턴을 인식하는 데는 그다지 좋지 않았습니다.
단순 패턴 인식에 문제가있는 경우 SVM (Support Vector Machine) 또는 로지스틱 회귀 분류 기가 작업을 잘 수행 할 수 있지만 패턴의 복잡성이 증가함에 따라 심층 신경망으로 갈 수밖에 없습니다.
따라서 인간의 얼굴과 같은 복잡한 패턴의 경우 얕은 신경망은 실패하고 더 많은 계층을 가진 심층 신경망으로 이동하는 것 외에는 대안이 없습니다. 딥넷은 복잡한 패턴을 더 간단한 패턴으로 분할하여 작업을 수행 할 수 있습니다. 예를 들어, 인간의 얼굴; adeep net은 가장자리를 사용하여 입술, 코, 눈, 귀 등과 같은 부분을 감지 한 다음 다시 결합하여 사람의 얼굴을 만듭니다.
정확한 예측의 정확성이 너무 높아져 최근 Google 패턴 인식 챌린지에서 딥넷이 인간을 이겼습니다.
레이어드 퍼셉트론의 웹에 대한이 아이디어는 한동안 존재 해 왔습니다. 이 영역에서 깊은 그물은 인간의 뇌를 모방합니다. 그러나 이것의 한 가지 단점은 훈련하는 데 오랜 시간이 걸린다는 것입니다.
그러나 최근의 고성능 GPU는 1 주일 이내에 이러한 딥넷을 훈련 할 수있었습니다. 빠른 CPU는 동일한 작업을 수행하는 데 몇 주 또는 몇 달이 걸렸을 수 있습니다.
딥넷 선택
깊은 그물을 선택하는 방법? 분류기를 만들고 있는지 아니면 데이터에서 패턴을 찾고 있는지, 그리고 비지도 학습을 사용할 것인지 결정해야합니다. 레이블이 지정되지 않은 데이터 세트에서 패턴을 추출하기 위해 제한된 Boltzman 기계 또는 자동 인코더를 사용합니다.
깊은 그물을 선택할 때 다음 사항을 고려하십시오.
텍스트 처리, 정서 분석, 구문 분석 및 이름 엔티티 인식을 위해 우리는 순환 네트워크 또는 순환 신경 텐서 네트워크 또는 RNTN을 사용합니다.
문자 수준에서 작동하는 모든 언어 모델에 대해 반복 네트워크를 사용합니다.
이미지 인식을 위해 심층 신념 네트워크 DBN 또는 컨볼 루션 네트워크를 사용합니다.
물체 인식을 위해 RNTN 또는 컨볼 루션 네트워크를 사용합니다.
음성 인식을 위해 우리는 recurrent net을 사용합니다.
일반적으로 수정 된 선형 단위 또는 RELU가있는 심층 신념 네트워크와 다층 퍼셉트론은 모두 분류를위한 좋은 선택입니다.
시계열 분석의 경우 항상 recurrent net을 사용하는 것이 좋습니다.
신경망은 50 년 이상 사용되어 왔습니다. 하지만 이제야 그들은 눈에 띄게 떠 올랐습니다. 그 이유는 훈련하기가 어렵 기 때문입니다. 역 전파 (back propagation)라는 방법으로 그들을 훈련 시키려고하면 소멸 또는 폭발 그라디언트라는 문제가 발생하는데, 그럴 경우 훈련에 더 많은 시간이 걸리고 정확도는 뒷자리를 차지합니다. 데이터 세트를 학습 할 때 예측 출력과 레이블이 지정된 학습 데이터 세트의 실제 출력의 차이 인 비용 함수를 지속적으로 계산하고, 가중치 및 편향 값을 최저 값까지 조정하여 비용 함수를 최소화합니다. 획득됩니다. 훈련 프로세스는 가중치 또는 편향 값의 변화와 관련하여 비용이 변경되는 비율 인 기울기를 사용합니다.
제한된 Boltzman 네트워크 또는 오토 인코더-RBN
2006 년에는 그라디언트 소멸 문제를 해결하는 데 돌파구가 마련되었습니다. Geoff Hinton은 새로운 전략을 고안하여Restricted Boltzman Machine - RBM, 얕은 두 층 그물.
첫 번째 레이어는 visible 레이어와 두 번째 레이어는 hidden층. 보이는 레이어의 각 노드는 히든 레이어의 모든 노드에 연결됩니다. 네트워크는 동일한 레이어 내의 두 레이어가 연결을 공유 할 수 없기 때문에 제한된 것으로 알려져 있습니다.
오토 인코더는 입력 데이터를 벡터로 인코딩하는 네트워크입니다. 원시 데이터의 숨겨진 또는 압축 된 표현을 만듭니다. 벡터는 차원 감소에 유용합니다. 벡터는 원시 데이터를 더 적은 수의 필수 차원으로 압축합니다. 오토 인코더는 디코더와 쌍을 이루어 숨겨진 표현을 기반으로 입력 데이터를 재구성 할 수 있습니다.
RBM은 양방향 번역기와 수학적 동등합니다. 정방향 패스는 입력을 받아 입력을 인코딩하는 숫자 집합으로 변환합니다. 한편 역방향 패스는이 숫자 세트를 가져와 재구성 된 입력으로 다시 변환합니다. 잘 훈련 된 네트는 높은 정확도로 백 프롭을 수행합니다.
두 단계에서 가중치와 편향은 중요한 역할을합니다. RBM이 입력 간의 상호 관계를 디코딩하고 패턴을 감지하는 데 필수적인 입력을 결정하는 데 도움이됩니다. 순방향 및 역방향 패스를 통해 RBM은 입력 및 구성이 가능한 한 가까울 때까지 다른 가중치와 편향으로 입력을 재구성하도록 훈련됩니다. RBM의 흥미로운 점은 데이터에 레이블을 지정할 필요가 없다는 것입니다. 이것은 사진, 비디오, 음성 및 센서 데이터와 같은 실제 데이터 세트에 매우 중요한 것으로 밝혀졌으며 모두 레이블이 지정되지 않은 경향이 있습니다. 사람이 수동으로 데이터에 레이블을 지정하는 대신 RBM은 데이터를 자동으로 정렬합니다. 가중치와 편향을 적절히 조정함으로써 RBM은 중요한 특징을 추출하고 입력을 재구성 할 수 있습니다. RBM은 데이터의 고유 한 패턴을 인식하도록 설계된 기능 추출기 신경망 제품군의 일부입니다. 이들은 자체 구조를 인코딩해야하기 때문에 자동 인코더라고도합니다.

Deep Belief Networks-DBN
DBN (딥 신념 네트워크)은 RBM을 결합하고 영리한 훈련 방법을 도입하여 형성됩니다. 마침내 그라디언트가 사라지는 문제를 해결하는 새로운 모델이 있습니다. Geoff Hinton은 역 전파에 대한 대안으로 RBM과 Deep Belief Net을 발명했습니다.
DBN은 MLP (Multi-layer perceptron)와 구조가 비슷하지만 훈련에 있어서는 매우 다릅니다. DBN이 얕은 상대를 능가 할 수있는 훈련입니다.
DBN은 하나의 RBM의 숨겨진 계층이 그 위에있는 RBM의 가시적 계층 인 RBM의 스택으로 시각화 될 수 있습니다. 첫 번째 RBM은 입력을 최대한 정확하게 재구성하도록 훈련되었습니다.
첫 번째 RBM의 숨겨진 계층은 두 번째 RBM의 가시적 계층으로 간주되고 두 번째 RBM은 첫 번째 RBM의 출력을 사용하여 훈련됩니다. 이 프로세스는 네트워크의 모든 계층이 훈련 될 때까지 반복됩니다.
DBN에서 각 RBM은 전체 입력을 학습합니다. DBN은 카메라 렌즈가 사진에 천천히 초점을 맞추는 것처럼 모델이 천천히 향상됨에 따라 전체 입력을 연속적으로 미세 조정하여 전역 적으로 작동합니다. 다중 레이어 퍼셉트론 MLP가 단일 퍼셉트론보다 성능이 뛰어 나기 때문에 RBM 스택은 단일 RBM보다 성능이 뛰어납니다.
이 단계에서 RBM은 데이터에서 고유 한 패턴을 감지했지만 이름이나 레이블은 없습니다. DBN 교육을 마치려면 패턴에 레이블을 도입하고지도 학습으로 네트워크를 미세 조정해야합니다.
특징과 패턴이 이름과 연관 될 수 있도록 매우 작은 레이블이 지정된 샘플 세트가 필요합니다. 이 작은 레이블이 지정된 데이터 세트는 학습에 사용됩니다. 이 레이블이 지정된 데이터 세트는 원래 데이터 세트와 비교할 때 매우 작을 수 있습니다.
가중치와 편향이 약간 변경되어 패턴에 대한 네트의 인식에 약간의 변화가 생기고 종종 전체 정확도가 약간 증가합니다.
훈련은 또한 GPU를 사용하여 얕은 그물에 비해 매우 정확한 결과를 제공함으로써 합리적인 시간 내에 완료 할 수 있으며, 그라디언트 문제가 사라짐에 대한 해결책도 볼 수 있습니다.
생성 적 적대 네트워크-GAN
생성 적 적대적 네트워크는 두 개의 네트로 구성된 심층 신경망으로, 서로 대항하여 "적대적"이름입니다.
GAN은 2014 년 몬트리올 대학의 연구자들이 발표 한 논문에서 소개되었습니다. Facebook의 AI 전문가 Yann LeCun은 GAN을 언급하며 적대적 훈련을 "지난 10 년 동안 ML에서 가장 흥미로운 아이디어"라고 불렀습니다.
네트워크 스캔이 데이터 배포를 모방하는 방법을 배우기 때문에 GAN의 잠재력은 엄청납니다. GAN은 이미지, 음악, 연설, 산문 등 모든 영역에서 우리와 놀랍도록 유사한 평행 세계를 만들도록 가르 칠 수 있습니다. 그들은 어떤면에서 로봇 예술가이며 그들의 결과물은 매우 인상적입니다.
GAN에서 생성기라고하는 하나의 신경망은 새로운 데이터 인스턴스를 생성하고 다른 하나는 판별 기에서 진위 여부를 평가합니다.
실제 세계에서 가져온 MNIST 데이터 세트에있는 것과 같은 손으로 쓴 숫자를 생성하려고한다고 가정 해 보겠습니다. 진정한 MNIST 데이터 세트의 인스턴스를 표시 할 때 판별 자의 작업은이를 진품으로 인식하는 것입니다.
이제 GAN의 다음 단계를 고려하십시오-
생성기 네트워크는 난수 형식으로 입력을 받아 이미지를 반환합니다.
이 생성 된 이미지는 실제 데이터 세트에서 가져온 이미지 스트림과 함께 판별 기 네트워크에 대한 입력으로 제공됩니다.
판별 기는 실제 이미지와 가짜 이미지를 모두 가져와 0과 1 사이의 숫자로 확률을 반환합니다. 1은 진위 예측을 나타내고 0은 가짜를 나타냅니다.
따라서 이중 피드백 루프가 있습니다.
판별 기는 우리가 알고있는 이미지의 실제와 함께 피드백 루프에 있습니다.
생성기는 판별 기와 함께 피드백 루프에 있습니다.
순환 신경망-RNN
RNN데이터가 모든 방향으로 흐를 수있는 신경망. 이러한 네트워크는 언어 모델링 또는 자연어 처리 (NLP)와 같은 애플리케이션에 사용됩니다.
RNN의 기본 개념은 순차 정보를 활용하는 것입니다. 정상적인 신경망에서는 모든 입력과 출력이 서로 독립적이라고 가정합니다. 문장에서 다음 단어를 예측하려면 그 앞에 오는 단어를 알아야합니다.
RNN은 시퀀스의 모든 요소에 대해 동일한 작업을 반복하므로 반복이라고합니다. 출력은 이전 계산을 기반으로합니다. 따라서 RNN은 이전에 계산 된 정보를 캡처하는 "메모리"를 가지고 있다고 말할 수 있습니다. 이론적으로 RNN은 매우 긴 시퀀스의 정보를 사용할 수 있지만 실제로는 몇 단계 만 되돌아 볼 수 있습니다.
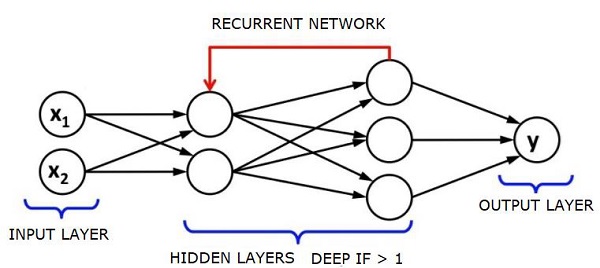
장단기 기억 네트워크 (LSTM)는 가장 일반적으로 사용되는 RNN입니다.
컨볼 루션 신경망과 함께 RNN은 라벨이없는 이미지에 대한 설명을 생성하는 모델의 일부로 사용되었습니다. 이것이 얼마나 잘 작동하는지 놀랍습니다.
컨볼 루션 심층 신경망-CNN
더 깊게 만들기 위해 신경망의 계층 수를 늘리면 네트워크의 복잡성이 증가하고 더 복잡한 함수를 모델링 할 수 있습니다. 그러나 가중치와 편향의 수는 기하 급수적으로 증가 할 것입니다. 사실 이러한 어려운 문제를 배우는 것은 정상적인 신경망에서는 불가능해질 수 있습니다. 이것은 솔루션 인 컨볼 루션 신경망으로 이어집니다.
CNN은 컴퓨터 비전에서 광범위하게 사용됩니다. 자동 음성 인식을위한 음향 모델링에도 적용되었습니다.
컨볼 루션 신경망 뒤에있는 아이디어는 이미지를 통과하는 "움직이는 필터"의 아이디어입니다. 이 이동 필터 또는 컨볼 루션은 예를 들어 픽셀 일 수있는 특정 인접 노드에 적용됩니다. 여기서 적용된 필터는 노드 값의 0.5 x-
저명한 연구원 Yann LeCun은 컨볼 루션 신경망을 개척했습니다. 얼굴 인식 소프트웨어로서 Facebook은 이러한 네트워크를 사용합니다. CNN은 머신 비전 프로젝트를위한 솔루션이었습니다. 컨볼 루션 네트워크에는 많은 계층이 있습니다. Imagenet 챌린지에서 기계는 2015 년에 물체 인식에서 사람을 이길 수있었습니다.
간단히 말해서, 컨볼 루션 신경망 (CNN)은 다층 신경망입니다. 레이어는 때때로 최대 17 개 이상이며 입력 데이터를 이미지라고 가정합니다.
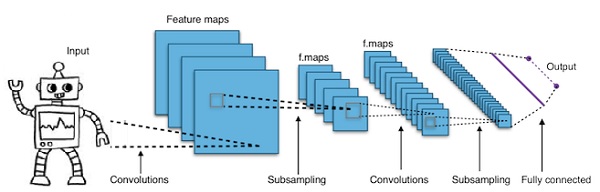
CNN은 조정해야하는 매개 변수의 수를 크게 줄입니다. 따라서 CNN은 원시 이미지의 높은 차원을 효율적으로 처리합니다.