Spark SQL-소개
Spark는 Spark SQL이라는 구조화 된 데이터 처리를위한 프로그래밍 모듈을 도입했습니다. DataFrame이라는 프로그래밍 추상화를 제공하며 분산 SQL 쿼리 엔진으로 작동 할 수 있습니다.
Spark SQL의 기능
다음은 Spark SQL의 기능입니다-
Integrated− SQL 쿼리를 Spark 프로그램과 원활하게 혼합합니다. Spark SQL을 사용하면 Python, Scala 및 Java의 통합 API를 사용하여 Spark에서 분산 데이터 세트 (RDD)로 구조화 된 데이터를 쿼리 할 수 있습니다. 이러한 긴밀한 통합을 통해 복잡한 분석 알고리즘과 함께 SQL 쿼리를 쉽게 실행할 수 있습니다.
Unified Data Access− 다양한 소스에서 데이터를로드하고 쿼리합니다. Schema-RDD는 Apache Hive 테이블, parquet 파일 및 JSON 파일을 포함한 구조화 된 데이터로 효율적으로 작업 할 수있는 단일 인터페이스를 제공합니다.
Hive Compatibility− 기존웨어 하우스에서 수정되지 않은 Hive 쿼리를 실행합니다. Spark SQL은 Hive 프런트 엔드 및 MetaStore를 재사용하여 기존 Hive 데이터, 쿼리 및 UDF와 완벽하게 호환됩니다. Hive와 함께 설치하기 만하면됩니다.
Standard Connectivity− JDBC 또는 ODBC를 통해 연결합니다. Spark SQL에는 산업 표준 JDBC 및 ODBC 연결이있는 서버 모드가 포함되어 있습니다.
Scalability− 대화 형 쿼리와 긴 쿼리 모두에 동일한 엔진을 사용하십시오. Spark SQL은 RDD 모델을 활용하여 중간 쿼리 내결함성을 지원하므로 대규모 작업으로도 확장 할 수 있습니다. 기록 데이터에 대해 다른 엔진을 사용하는 것에 대해 걱정하지 마십시오.
Spark SQL 아키텍처
다음 그림은 Spark SQL의 아키텍처를 설명합니다.
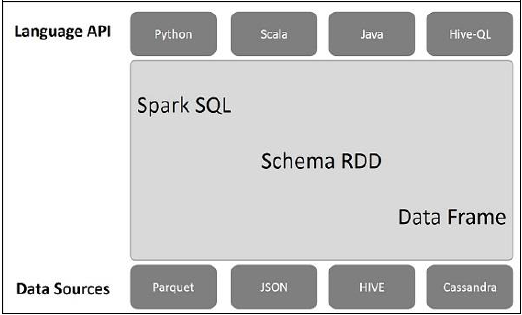
이 아키텍처에는 언어 API, 스키마 RDD 및 데이터 소스의 세 계층이 포함됩니다.
Language API− Spark는 다른 언어 및 Spark SQL과 호환됩니다. 또한 API (python, scala, java, HiveQL)와 같은 언어로 지원됩니다.
Schema RDD− Spark Core는 RDD라는 특수 데이터 구조로 설계되었습니다. 일반적으로 Spark SQL은 스키마, 테이블 및 레코드에서 작동합니다. 따라서 Schema RDD를 임시 테이블로 사용할 수 있습니다. 이 스키마 RDD를 데이터 프레임이라고 부를 수 있습니다.
Data Sources− 일반적으로 spark-core의 데이터 소스는 텍스트 파일, Avro 파일 등입니다. 그러나 Spark SQL의 데이터 소스는 다릅니다. Parquet 파일, JSON 문서, HIVE 테이블 및 Cassandra 데이터베이스입니다.
이에 대한 자세한 내용은 다음 장에서 설명합니다.