Spark SQL-퀵 가이드
업계에서는 데이터 세트를 분석하기 위해 Hadoop을 광범위하게 사용하고 있습니다. 그 이유는 Hadoop 프레임 워크가 단순 프로그래밍 모델 (MapReduce)을 기반으로하며 확장 가능하고 유연하며 내결함성이 있으며 비용 효율적인 컴퓨팅 솔루션을 가능하게하기 때문입니다. 여기서 주요 관심사는 쿼리 간 대기 시간과 프로그램 실행 대기 시간 측면에서 대용량 데이터 세트 처리 속도를 유지하는 것입니다.
Spark는 Hadoop 컴퓨팅 컴퓨팅 소프트웨어 프로세스의 속도를 높이기 위해 Apache Software Foundation에서 도입했습니다.
일반적인 믿음과는 반대로 Spark is not a modified version of Hadoop자체 클러스터 관리 기능이 있기 때문에 실제로 Hadoop에 의존하지 않습니다. Hadoop은 Spark를 구현하는 방법 중 하나 일뿐입니다.
Spark는 두 가지 방식으로 Hadoop을 사용합니다. storage 두 번째는 processing. Spark에는 자체 클러스터 관리 계산이 있으므로 저장 용도로만 Hadoop을 사용합니다.
Apache Spark
Apache Spark는 빠른 계산을 위해 설계된 초고속 클러스터 컴퓨팅 기술입니다. Hadoop MapReduce를 기반으로하며 MapReduce 모델을 확장하여 대화 형 쿼리 및 스트림 처리를 포함하는 더 많은 유형의 계산에 효율적으로 사용합니다. Spark의 주요 기능은in-memory cluster computing 이는 애플리케이션의 처리 속도를 증가시킵니다.
Spark는 배치 애플리케이션, 반복 알고리즘, 대화 형 쿼리 및 스트리밍과 같은 광범위한 워크로드를 처리하도록 설계되었습니다. 각 시스템에서 이러한 모든 워크로드를 지원하는 것 외에도 별도의 도구를 유지 관리하는 관리 부담이 줄어 듭니다.
Apache Spark의 진화
Spark는 Matei Zaharia가 UC Berkeley의 AMPLab에서 2009 년에 개발 한 Hadoop의 하위 프로젝트 중 하나입니다. BSD 라이선스에 따라 2010 년에 오픈 소스되었습니다. 2013 년 Apache 소프트웨어 재단에 기부되었으며 이제 Apache Spark는 2014 년 2 월부터 최상위 수준의 Apache 프로젝트가되었습니다.
Apache Spark의 기능
Apache Spark에는 다음과 같은 기능이 있습니다.
Speed− Spark는 Hadoop 클러스터에서 애플리케이션을 실행하는 데 도움이됩니다. 메모리에서 최대 100 배, 디스크에서 실행할 때 10 배 더 빠릅니다. 이는 디스크에 대한 읽기 / 쓰기 작업 수를 줄임으로써 가능합니다. 중간 처리 데이터를 메모리에 저장합니다.
Supports multiple languages− Spark는 Java, Scala 또는 Python으로 내장 된 API를 제공합니다. 따라서 다른 언어로 응용 프로그램을 작성할 수 있습니다. Spark는 대화 형 쿼리를위한 80 개의 고급 연산자를 제공합니다.
Advanced Analytics− Spark는 'Map'및 'reduce'만 지원하지 않습니다. 또한 SQL 쿼리, 스트리밍 데이터, ML (기계 학습) 및 그래프 알고리즘을 지원합니다.
Hadoop에 구축 된 Spark
다음 다이어그램은 Hadoop 구성 요소로 Spark를 빌드 할 수있는 세 가지 방법을 보여줍니다.
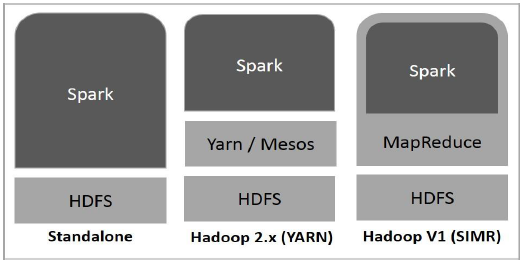
아래 설명과 같이 Spark 배포에는 세 가지 방법이 있습니다.
Standalone− Spark Standalone 배포는 Spark가 HDFS (Hadoop Distributed File System) 위에 자리를 차지하고 HDFS를위한 공간이 명시 적으로 할당됨을 의미합니다. 여기서 Spark와 MapReduce는 클러스터의 모든 Spark 작업을 처리하기 위해 나란히 실행됩니다.
Hadoop Yarn− Hadoop Yarn 배포는 간단히 말해 사전 설치 또는 루트 액세스없이 Yarn에서 스파크가 실행됨을 의미합니다. Spark를 Hadoop 에코 시스템 또는 Hadoop 스택에 통합하는 데 도움이됩니다. 다른 구성 요소가 스택 위에서 실행될 수 있습니다.
Spark in MapReduce (SIMR)− MapReduce의 Spark는 독립 실행 형 배포 외에 Spark 작업을 시작하는 데 사용됩니다. SIMR을 통해 사용자는 Spark를 시작하고 관리 액세스없이 셸을 사용할 수 있습니다.
Spark의 구성 요소
다음 그림은 Spark의 다양한 구성 요소를 보여줍니다.
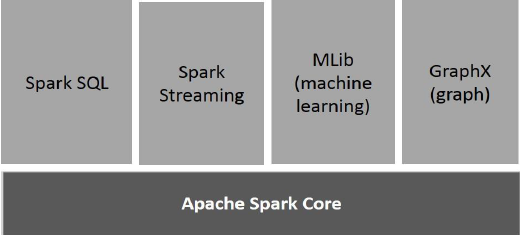
Apache Spark 코어
Spark Core는 다른 모든 기능을 기반으로하는 Spark 플랫폼의 기본 일반 실행 엔진입니다. 메모리 내 컴퓨팅을 제공하고 외부 스토리지 시스템의 데이터 세트를 참조합니다.
Spark SQL
Spark SQL은 정형 및 반 정형 데이터를 지원하는 SchemaRDD라는 새로운 데이터 추상화를 도입하는 Spark Core의 상위 구성 요소입니다.
스파크 스트리밍
Spark Streaming은 Spark Core의 빠른 스케줄링 기능을 활용하여 스트리밍 분석을 수행합니다. 미니 배치로 데이터를 수집하고 해당 미니 배치 데이터에 대해 RDD (Resilient Distributed Datasets) 변환을 수행합니다.
MLlib (머신 러닝 라이브러리)
MLlib는 분산 메모리 기반 Spark 아키텍처로 인해 Spark 위의 분산 기계 학습 프레임 워크입니다. 벤치 마크에 따르면 MLlib 개발자가 ALS (Alternating Least Squares) 구현에 대해 수행했습니다. Spark MLlib는 Hadoop 디스크 기반 버전보다 9 배 빠릅니다.Apache Mahout (Mahout이 Spark 인터페이스를 얻기 전).
GraphX
GraphX는 Spark 기반의 분산 그래프 처리 프레임 워크입니다. Pregel abstraction API를 이용하여 사용자 정의 그래프를 모델링 할 수있는 그래프 연산 표현을위한 API를 제공합니다. 또한이 추상화를 위해 최적화 된 런타임을 제공합니다.
탄력적 인 분산 데이터 세트
RDD (Resilient Distributed Dataset)는 Spark의 기본 데이터 구조입니다. 불변의 분산 된 객체 모음입니다. RDD의 각 데이터 세트는 클러스터의 다른 노드에서 계산 될 수있는 논리 파티션으로 나뉩니다. RDD는 사용자 정의 클래스를 포함하여 모든 유형의 Python, Java 또는 Scala 객체를 포함 할 수 있습니다.
공식적으로 RDD는 읽기 전용으로 분할 된 레코드 모음입니다. RDD는 안정적인 스토리지 또는 다른 RDD의 데이터에 대한 결정적 작업을 통해 생성 될 수 있습니다. RDD는 병렬로 작동 할 수있는 내결함성 요소 모음입니다.
RDD를 생성하는 방법에는 두 가지가 있습니다. parallelizing 드라이버 프로그램의 기존 컬렉션 또는 referencing a dataset 공유 파일 시스템, HDFS, HBase 또는 Hadoop 입력 형식을 제공하는 모든 데이터 소스와 같은 외부 스토리지 시스템
Spark는 RDD 개념을 사용하여 더 빠르고 효율적인 MapReduce 작업을 수행합니다. 먼저 MapReduce 작업이 발생하는 방식과 그다지 효율적이지 않은 이유에 대해 논의하겠습니다.
MapReduce에서 데이터 공유가 느립니다.
MapReduce는 클러스터에서 병렬 분산 알고리즘을 사용하여 대규모 데이터 세트를 처리하고 생성하는 데 널리 채택됩니다. 이를 통해 사용자는 작업 분배 및 내결함성에 대해 걱정할 필요없이 고급 연산자 세트를 사용하여 병렬 계산을 작성할 수 있습니다.
안타깝게도 대부분의 현재 프레임 워크에서 계산간에 (예 : 두 MapReduce 작업간에) 데이터를 재사용하는 유일한 방법은 외부 안정적인 스토리지 시스템 (예 : HDFS)에 데이터를 쓰는 것입니다. 이 프레임 워크는 클러스터의 계산 리소스에 액세스하기위한 수많은 추상화를 제공하지만 사용자는 여전히 더 많은 것을 원합니다.
양자 모두 Iterative 과 Interactive응용 프로그램은 병렬 작업에서 더 빠른 데이터 공유가 필요합니다. MapReduce에서 데이터 공유가 느립니다.replication, serialization, 및 disk IO. 스토리지 시스템과 관련하여 대부분의 Hadoop 애플리케이션은 HDFS 읽기-쓰기 작업에 90 % 이상의 시간을 소비합니다.
MapReduce에 대한 반복 작업
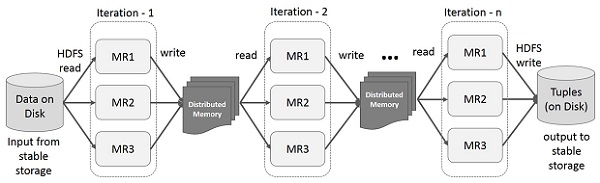
다단계 응용 프로그램의 여러 계산에서 중간 결과를 재사용합니다. 다음 그림은 MapReduce에서 반복 작업을 수행하는 동안 현재 프레임 워크가 작동하는 방식을 설명합니다. 이로 인해 데이터 복제, 디스크 I / O 및 직렬화로 인해 상당한 오버 헤드가 발생하여 시스템 속도가 느려집니다.
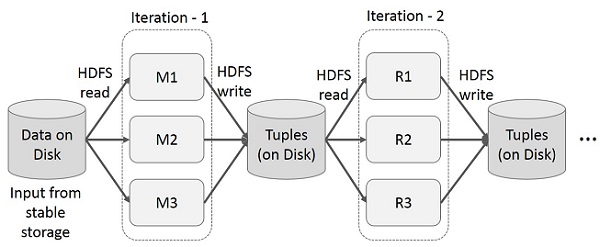
MapReduce의 대화 형 작업
사용자는 동일한 데이터 하위 집합에 대해 임시 쿼리를 실행합니다. 각 쿼리는 안정적인 스토리지에서 디스크 I / O를 수행하므로 애플리케이션 실행 시간을 지배 할 수 있습니다.
다음 그림은 MapReduce에서 대화 형 쿼리를 수행하는 동안 현재 프레임 워크가 작동하는 방식을 설명합니다.
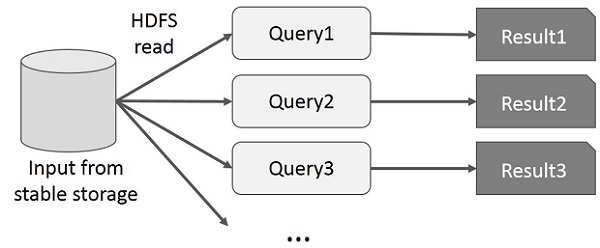
Spark RDD를 사용한 데이터 공유
MapReduce에서 데이터 공유가 느립니다. replication, serialization, 및 disk IO. 대부분의 Hadoop 애플리케이션은 HDFS 읽기-쓰기 작업에 90 % 이상의 시간을 소비합니다.
이 문제를 인식 한 연구원들은 Apache Spark라는 특수 프레임 워크를 개발했습니다. 스파크의 핵심 아이디어는R탄력이있는 D분배 D아타 세트 (RDD); 메모리 내 처리 계산을 지원합니다. 즉, 메모리 상태를 작업 전반에 걸쳐 객체로 저장하고 객체를 해당 작업간에 공유 할 수 있습니다. 메모리의 데이터 공유는 네트워크 및 디스크보다 10 ~ 100 배 빠릅니다.
이제 Spark RDD에서 반복 및 대화 형 작업이 어떻게 발생하는지 알아 보겠습니다.
Spark RDD에 대한 반복 작업
아래 그림은 Spark RDD의 반복 작업을 보여줍니다. 중간 결과를 안정적인 스토리지 (디스크) 대신 분산 메모리에 저장하고 시스템을 더 빠르게 만듭니다.
Note − 분산 메모리 (RAM)가 중간 결과 (작업 상태)를 저장하기에 충분한 경우 해당 결과를 디스크에 저장합니다.
Spark RDD에서 대화 형 작업
이 그림은 Spark RDD의 대화 형 작업을 보여줍니다. 동일한 데이터 세트에 대해 다른 쿼리가 반복적으로 실행되는 경우이 특정 데이터는 더 나은 실행 시간을 위해 메모리에 보관 될 수 있습니다.

기본적으로 변환 된 각 RDD는 작업을 실행할 때마다 다시 계산 될 수 있습니다. 그러나persist메모리의 RDD.이 경우 Spark는 다음에 쿼리 할 때 훨씬 빠른 액세스를 위해 클러스터에 요소를 유지합니다. 또한 디스크에 RDD를 유지하거나 여러 노드에 복제되는 지원도 있습니다.
Spark는 Hadoop의 하위 프로젝트입니다. 따라서 Linux 기반 시스템에 Spark를 설치하는 것이 좋습니다. 다음 단계는 Apache Spark를 설치하는 방법을 보여줍니다.
1 단계 : Java 설치 확인
Java 설치는 Spark 설치의 필수 사항 중 하나입니다. JAVA 버전을 확인하려면 다음 명령을 시도하십시오.
$java -versionJava가 이미 시스템에 설치되어 있으면 다음과 같은 응답을 볼 수 있습니다.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)시스템에 Java가 설치되어 있지 않은 경우 다음 단계로 진행하기 전에 Java를 설치하십시오.
2 단계 : Scala 설치 확인
Spark를 구현하려면 Scala 언어를 사용해야합니다. 따라서 다음 명령을 사용하여 Scala 설치를 확인하겠습니다.
$scala -versionScala가 이미 시스템에 설치되어 있으면 다음과 같은 응답을 볼 수 있습니다.
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL시스템에 Scala가 설치되어 있지 않은 경우 Scala 설치를 위해 다음 단계로 진행하십시오.
3 단계 : Scala 다운로드
Scala 다운로드 링크를 방문하여 최신 버전의 Scala를 다운로드 하십시오 . 이 튜토리얼에서는 scala-2.11.6 버전을 사용합니다. 다운로드 후 다운로드 폴더에서 Scala tar 파일을 찾을 수 있습니다.
4 단계 : Scala 설치
Scala를 설치하려면 아래 단계를 따르십시오.
Scala tar 파일 추출
Scala tar 파일을 추출하려면 다음 명령을 입력하십시오.
$ tar xvf scala-2.11.6.tgzScala 소프트웨어 파일 이동
Scala 소프트웨어 파일을 각 디렉토리로 이동하려면 다음 명령을 사용하십시오. (/usr/local/scala).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv scala-2.11.6 /usr/local/scala
# exitScala에 대한 PATH 설정
Scala에 대한 PATH를 설정하려면 다음 명령을 사용하십시오.
$ export PATH = $PATH:/usr/local/scala/binScala 설치 확인
설치 후 확인하는 것이 좋습니다. Scala 설치를 확인하려면 다음 명령을 사용하십시오.
$scala -versionScala가 이미 시스템에 설치되어 있으면 다음과 같은 응답을 볼 수 있습니다.
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL5 단계 : Apache Spark 다운로드
다음 링크를 방문하여 최신 버전의 Spark를 다운로드하십시오 . 이 튜토리얼에서는spark-1.3.1-bin-hadoop2.6버전. 다운로드 후 다운로드 폴더에서 Spark tar 파일을 찾을 수 있습니다.
6 단계 : Spark 설치
Spark를 설치하려면 아래 단계를 따르십시오.
Spark tar 추출
다음은 Spark tar 파일을 추출하는 명령입니다.
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgzSpark 소프트웨어 파일 이동
Spark 소프트웨어 파일을 각 디렉터리로 이동하기위한 다음 명령 (/usr/local/spark).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark
# exitSpark를위한 환경 설정
~에 다음 줄을 추가하십시오./.bashrc파일. 이는 스파크 소프트웨어 파일이있는 위치를 PATH 변수에 추가하는 것을 의미합니다.
export PATH = $PATH:/usr/local/spark/bin~ / .bashrc 파일을 소싱하려면 다음 명령을 사용하십시오.
$ source ~/.bashrc7 단계 : Spark 설치 확인
Spark 셸을 열기 위해 다음 명령을 작성합니다.
$spark-shell스파크가 성공적으로 설치되면 다음 출력을 찾을 수 있습니다.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>Spark는 Spark SQL이라는 구조화 된 데이터 처리를위한 프로그래밍 모듈을 도입했습니다. DataFrame이라는 프로그래밍 추상화를 제공하며 분산 SQL 쿼리 엔진으로 작동 할 수 있습니다.
Spark SQL의 기능
다음은 Spark SQL의 기능입니다-
Integrated− SQL 쿼리를 Spark 프로그램과 원활하게 혼합합니다. Spark SQL을 사용하면 Python, Scala 및 Java의 통합 API를 사용하여 Spark에서 분산 데이터 세트 (RDD)로 구조화 된 데이터를 쿼리 할 수 있습니다. 이러한 긴밀한 통합을 통해 복잡한 분석 알고리즘과 함께 SQL 쿼리를 쉽게 실행할 수 있습니다.
Unified Data Access− 다양한 소스에서 데이터를로드하고 쿼리합니다. Schema-RDD는 Apache Hive 테이블, parquet 파일 및 JSON 파일을 포함한 구조화 된 데이터로 효율적으로 작업 할 수있는 단일 인터페이스를 제공합니다.
Hive Compatibility− 기존웨어 하우스에서 수정되지 않은 Hive 쿼리를 실행합니다. Spark SQL은 Hive 프런트 엔드 및 MetaStore를 재사용하여 기존 Hive 데이터, 쿼리 및 UDF와 완벽하게 호환됩니다. Hive와 함께 설치하기 만하면됩니다.
Standard Connectivity− JDBC 또는 ODBC를 통해 연결합니다. Spark SQL에는 산업 표준 JDBC 및 ODBC 연결이있는 서버 모드가 포함되어 있습니다.
Scalability− 대화 형 쿼리와 긴 쿼리 모두에 동일한 엔진을 사용하십시오. Spark SQL은 RDD 모델을 활용하여 중간 쿼리 내결함성을 지원하므로 대규모 작업으로도 확장 할 수 있습니다. 기록 데이터에 대해 다른 엔진을 사용하는 것에 대해 걱정하지 마십시오.
Spark SQL 아키텍처
다음 그림은 Spark SQL의 아키텍처를 설명합니다.
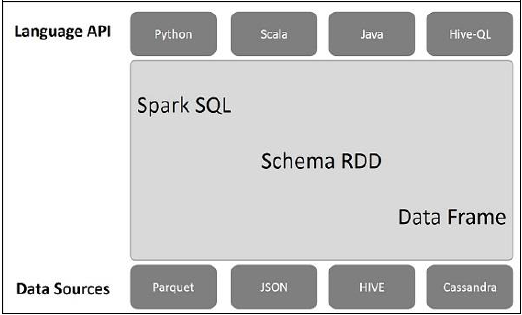
이 아키텍처에는 언어 API, 스키마 RDD 및 데이터 소스의 세 계층이 포함됩니다.
Language API− Spark는 다른 언어 및 Spark SQL과 호환됩니다. 또한 API (python, scala, java, HiveQL)와 같은 언어로 지원됩니다.
Schema RDD− Spark Core는 RDD라는 특수 데이터 구조로 설계되었습니다. 일반적으로 Spark SQL은 스키마, 테이블 및 레코드에서 작동합니다. 따라서 Schema RDD를 임시 테이블로 사용할 수 있습니다. 이 스키마 RDD를 데이터 프레임이라고 부를 수 있습니다.
Data Sources− 일반적으로 spark-core의 데이터 소스는 텍스트 파일, Avro 파일 등입니다. 그러나 Spark SQL의 데이터 소스는 다릅니다. Parquet 파일, JSON 문서, HIVE 테이블 및 Cassandra 데이터베이스입니다.
이에 대한 자세한 내용은 다음 장에서 설명합니다.
DataFrame은 명명 된 열로 구성된 분산 된 데이터 모음입니다. 개념적으로는 좋은 최적화 기술을 가진 관계형 테이블과 동일합니다.
DataFrame은 Hive 테이블, 구조화 된 데이터 파일, 외부 데이터베이스 또는 기존 RDD와 같은 다양한 소스의 배열에서 구성 될 수 있습니다. 이 API는 최신 빅 데이터 및 데이터 과학 애플리케이션을 위해 설계되었습니다.DataFrame in R Programming 과 Pandas in Python.
DataFrame의 특징
다음은 DataFrame의 몇 가지 특징입니다.
단일 노드 클러스터에서 대규모 클러스터까지 킬로바이트에서 페타 바이트 크기의 데이터를 처리하는 기능.
다양한 데이터 형식 (Avro, csv, 탄력적 검색 및 Cassandra) 및 스토리지 시스템 (HDFS, HIVE 테이블, mysql 등)을 지원합니다.
Spark SQL Catalyst 최적화 프로그램 (트리 변환 프레임 워크)을 통한 최첨단 최적화 및 코드 생성.
Spark-Core를 통해 모든 빅 데이터 도구 및 프레임 워크와 쉽게 통합 할 수 있습니다.
Python, Java, Scala 및 R 프로그래밍을위한 API를 제공합니다.
SQLContext
SQLContext는 클래스이며 Spark SQL의 기능을 초기화하는 데 사용됩니다. SQLContext 클래스 개체를 초기화하려면 SparkContext 클래스 개체 (sc)가 필요합니다.
다음 명령어는 spark-shell을 통해 SparkContext를 초기화하는 데 사용됩니다.
$ spark-shell기본적으로 SparkContext 개체는 다음 이름으로 초기화됩니다. sc 스파크 쉘이 시작될 때.
다음 명령을 사용하여 SQLContext를 만듭니다.
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)예
다음과 같은 이름의 JSON 파일에있는 직원 레코드의 예를 살펴 보겠습니다. employee.json. 다음 명령을 사용하여 DataFrame (df)을 만들고 이름이 지정된 JSON 문서를 읽습니다.employee.json 다음 내용으로.
employee.json −이 파일을 현재 scala> 포인터가 있습니다.
{
{"id" : "1201", "name" : "satish", "age" : "25"}
{"id" : "1202", "name" : "krishna", "age" : "28"}
{"id" : "1203", "name" : "amith", "age" : "39"}
{"id" : "1204", "name" : "javed", "age" : "23"}
{"id" : "1205", "name" : "prudvi", "age" : "23"}
}DataFrame 작업
DataFrame은 구조화 된 데이터 조작을위한 도메인 별 언어를 제공합니다. 여기에는 DataFrames를 사용한 구조화 된 데이터 처리의 몇 가지 기본 예가 포함되어 있습니다.
DataFrame 작업을 수행하려면 아래 단계를 따르십시오-
JSON 문서 읽기
먼저 JSON 문서를 읽어야합니다. 이를 기반으로 (dfs)라는 DataFrame을 생성합니다.
다음 명령을 사용하여 이름이 지정된 JSON 문서를 읽으십시오. employee.json. 데이터는 id, name 및 age 필드가있는 테이블로 표시됩니다.
scala> val dfs = sqlContext.read.json("employee.json")Output − 필드 이름은 employee.json.
dfs: org.apache.spark.sql.DataFrame = [age: string, id: string, name: string]데이터 표시
DataFrame의 데이터를 보려면 다음 명령을 사용하십시오.
scala> dfs.show()Output − 직원 데이터를 표 형식으로 볼 수 있습니다.
<console>:22, took 0.052610 s
+----+------+--------+
|age | id | name |
+----+------+--------+
| 25 | 1201 | satish |
| 28 | 1202 | krishna|
| 39 | 1203 | amith |
| 23 | 1204 | javed |
| 23 | 1205 | prudvi |
+----+------+--------+printSchema 메서드 사용
DataFrame의 구조 (스키마)를 보려면 다음 명령을 사용하십시오.
scala> dfs.printSchema()Output
root
|-- age: string (nullable = true)
|-- id: string (nullable = true)
|-- name: string (nullable = true)선택 방법 사용
다음 명령을 사용하여 가져옵니다. name-DataFrame의 세 열 중 열.
scala> dfs.select("name").show()Output − 당신은 값을 볼 수 있습니다 name 기둥.
<console>:22, took 0.044023 s
+--------+
| name |
+--------+
| satish |
| krishna|
| amith |
| javed |
| prudvi |
+--------+연령 필터 사용
다음 명령을 사용하여 나이가 23 세 (연령> 23 세)보다 큰 직원을 찾습니다.
scala> dfs.filter(dfs("age") > 23).show()Output
<console>:22, took 0.078670 s
+----+------+--------+
|age | id | name |
+----+------+--------+
| 25 | 1201 | satish |
| 28 | 1202 | krishna|
| 39 | 1203 | amith |
+----+------+--------+groupBy 메서드 사용
나이가 같은 직원 수를 계산하려면 다음 명령을 사용하십시오.
scala> dfs.groupBy("age").count().show()Output − 두 명의 직원이 23 세입니다.
<console>:22, took 5.196091 s
+----+-----+
|age |count|
+----+-----+
| 23 | 2 |
| 25 | 1 |
| 28 | 1 |
| 39 | 1 |
+----+-----+프로그래밍 방식으로 SQL 쿼리 실행
SQLContext를 사용하면 응용 프로그램이 SQL 함수를 실행하는 동안 프로그래밍 방식으로 SQL 쿼리를 실행하고 결과를 DataFrame으로 반환 할 수 있습니다.
일반적으로 백그라운드에서 SparkSQL은 기존 RDD를 DataFrame으로 변환하는 두 가지 방법을 지원합니다.
| Sr. 아니오 | 방법 및 설명 |
|---|---|
| 1 | 리플렉션을 사용하여 스키마 추론 이 메서드는 리플렉션을 사용하여 특정 유형의 개체를 포함하는 RDD의 스키마를 생성합니다. |
| 2 | 프로그래밍 방식으로 스키마 지정 DataFrame을 만드는 두 번째 방법은 스키마를 생성 한 다음 기존 RDD에 적용 할 수있는 프로그래밍 인터페이스를 사용하는 것입니다. |
DataFrame 인터페이스를 사용하면 다양한 데이터 소스가 Spark SQL에서 작동 할 수 있습니다. 임시 테이블이며 일반 RDD로 작동 할 수 있습니다. DataFrame을 테이블로 등록하면 해당 데이터에 대해 SQL 쿼리를 실행할 수 있습니다.
이 장에서는 다양한 Spark 데이터 소스를 사용하여 데이터를로드하고 저장하는 일반적인 방법을 설명합니다. 그런 다음 기본 제공 데이터 원본에 사용할 수있는 특정 옵션에 대해 자세히 설명합니다.
SparkSQL에는 다양한 유형의 데이터 소스가 있으며, 그중 일부는 아래에 나열되어 있습니다.
| Sr. 아니오 | 데이터 소스 |
|---|---|
| 1 | JSON 데이터 세트 Spark SQL은 JSON 데이터 세트의 스키마를 자동으로 캡처하고이를 DataFrame으로로드 할 수 있습니다. |
| 2 | Hive 테이블 Hive는 SQLContext에서 상속되는 HiveContext로 Spark 라이브러리와 함께 번들로 제공됩니다. |
| 삼 | 마루 파일 Parquet는 많은 데이터 처리 시스템에서 지원하는 열 형식입니다. |