Splunk-피벗 및 데이터 세트
Splunk는 다양한 유형의 데이터 소스를 수집하고 관계형 테이블과 유사한 테이블을 작성할 수 있습니다. 이것들은table dataset 아니면 그냥 tables. 데이터 및 조회 등을 분석하고 필터링하는 쉬운 방법을 제공합니다. 이러한 테이블 데이터 세트는이 장에서 배우는 피벗 분석을 만드는데도 사용됩니다.
데이터 세트 만들기
Splunk Datasets Add-on이라는 Splunk Add-on을 사용하여 데이터 세트를 만들고 관리합니다. Splunk 웹 사이트에서 다운로드 할 수 있습니다.https://splunkbase.splunk.com/app/3245/#/details.이 링크의 세부 정보 탭에 제공된 지침에 따라 설치해야합니다. 성공적으로 설치되면Create New Table Dataset.
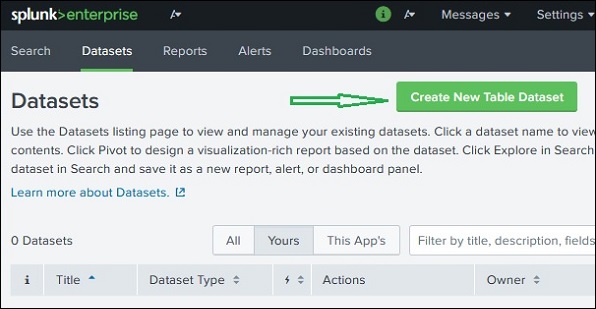
데이터 세트 선택
다음으로, 우리는 Create New Table Dataset 버튼을 클릭하면 아래 세 가지 옵션 중에서 선택할 수있는 옵션이 제공됩니다.
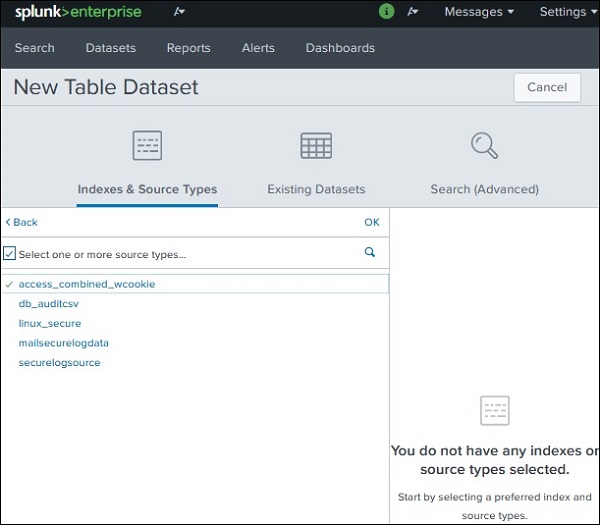
Indexes and Source Types − 데이터 추가 앱을 통해 Splunk에 이미 추가 된 기존 인덱스 또는 소스 유형 중에서 선택합니다.
Existing Datasets − 이전에 새 데이터 세트를 생성하여 수정하려는 일부 데이터 세트를 이미 생성했을 수 있습니다.
Search − 검색 쿼리를 작성하면 그 결과를 사용하여 새 데이터 세트를 생성 할 수 있습니다.
이 예에서는 아래 이미지와 같이 데이터 세트의 소스가 될 인덱스를 선택합니다.
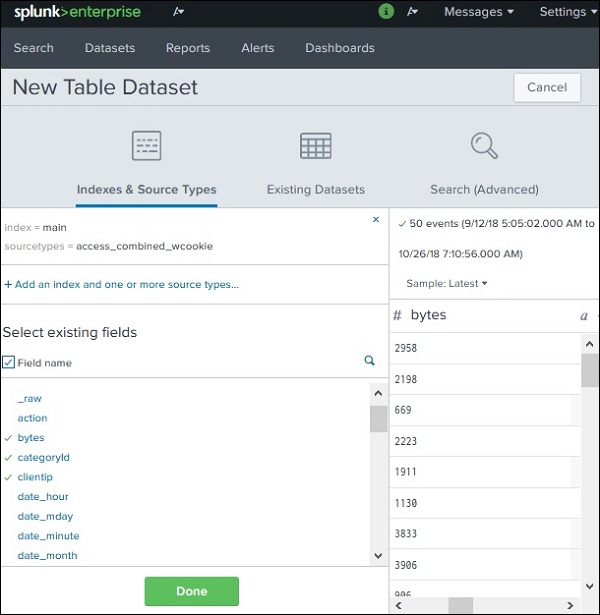
데이터 세트 필드 선택
위 화면에서 확인을 클릭하면 최종적으로 테이블 데이터 세트에 들어 가려는 다양한 필드를 선택할 수있는 옵션이 제공됩니다. _time 필드는 기본적으로 선택되며이 필드는 삭제할 수 없습니다. 필드를 선택합니다.bytes, categoryID, clientIP 과 files.
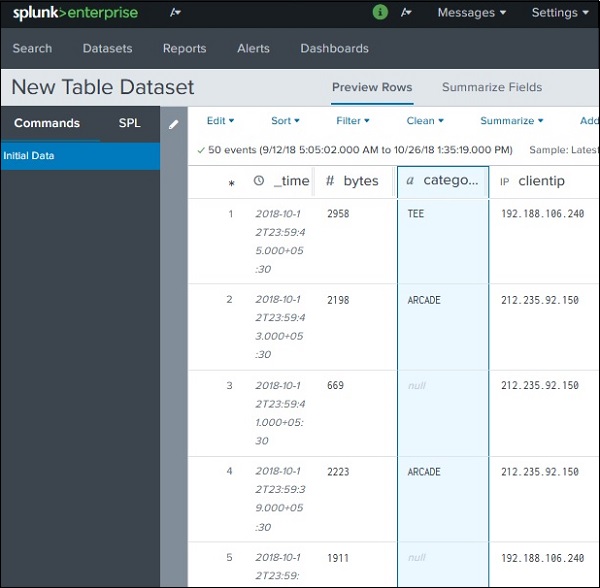
위 화면에서 완료를 클릭하면 아래와 같이 선택된 모든 필드가 포함 된 최종 데이터 세트 테이블이 표시됩니다. 여기서 데이터 세트는 관계형 테이블과 비슷해졌습니다. 데이터 세트를save as 오른쪽 상단 모서리에서 옵션을 사용할 수 있습니다.
피벗 생성
위의 데이터 세트를 사용하여 피벗 보고서를 만듭니다. 피벗 보고서는 다른 열의 값과 관련하여 한 열의 값 집계를 반영합니다. 즉, 하나의 열 값이 행으로 만들어지고 다른 열 값이 행으로 만들어집니다.
데이터 세트 작업 선택
이를 위해 먼저 데이터 세트 탭을 사용하여 데이터 세트를 선택한 다음 옵션을 선택합니다. Visualize with Pivot 해당 데이터 세트의 작업 열에서
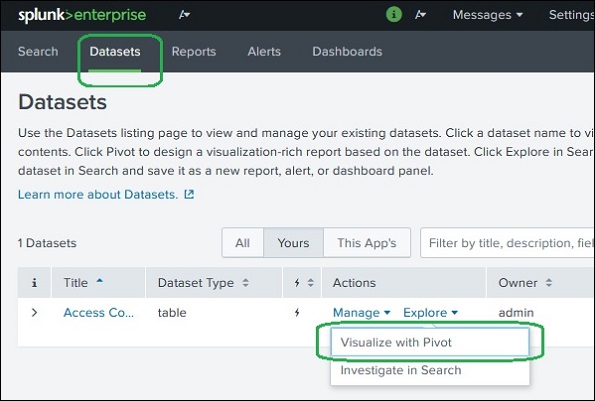
피벗 필드 선택
다음으로 피벗 테이블을 만들기위한 적절한 필드를 선택합니다. 우리는 카테고리 ID를split columns옵션은 값이 보고서에서 다른 열로 표시되어야하는 필드입니다. 그런 다음Split Rows값이 행에 표시되어야하는 필드이므로 옵션입니다. 결과는 파일 필드의 각 값에 대한 각 categoryid 값의 개수를 보여줍니다.

다음으로, 나중에 참조 할 수 있도록 피벗 테이블을 보고서 또는 기존 대시 보드의 패널로 저장할 수 있습니다.