Splunk-검색 최적화
Splunk에는 이미 최적화 기능이 포함되어 있으며 최대 효율성을 위해 검색을 분석 및 처리합니다. 이 효율성은 주로 다음 두 가지 최적화 목표를 통해 달성됩니다.
Early Filtering− 이러한 최적화는 결과를 매우 일찍 필터링하므로 처리되는 데이터의 양이 검색 프로세스 중에 가능한 한 빨리 감소됩니다. 이 초기 필터는 최종 검색 결과의 일부가 아닌 이벤트에 대한 불필요한 조회 및 평가 계산을 방지합니다.
Parallel Processing − 내장 된 최적화는 검색 처리 순서를 변경할 수 있으므로 최종 처리를 위해 검색 결과를 검색 헤드로 보내기 전에 인덱서에서 가능한 한 많은 명령이 병렬로 실행됩니다.
검색 최적화 분석
Splunk는 검색 최적화 작동 방식을 분석 할 수있는 도구를 제공했습니다. 이러한 도구는 필터 조건이 사용되는 방법과 이러한 최적화 단계의 순서를 파악하는 데 도움이됩니다. 또한 검색 작업과 관련된 다양한 단계의 비용을 제공합니다.
예
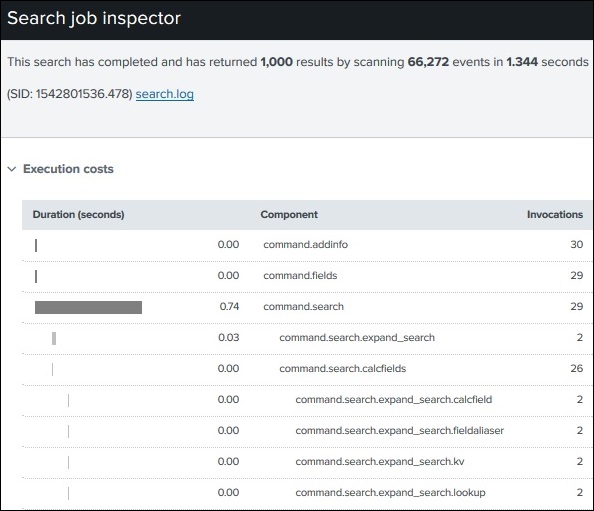
검색 작업을 고려하여 실패, 실패 또는 비밀번호 단어가 포함 된 이벤트를 찾으십시오. 이 검색 쿼리를 검색 상자에 넣으면 기본 제공 최적화 프로그램이 자동으로 작동하여 검색 경로를 결정합니다. 검색이 특정 수의 검색 결과를 반환하는 데 걸린 시간을 확인할 수 있으며 필요한 경우 관련 비용과 함께 최적화의 모든 단계를 계속 확인할 수 있습니다.
우리는 Search → Job → Inspect Job 다음과 같이 이러한 세부 정보를 얻으려면-
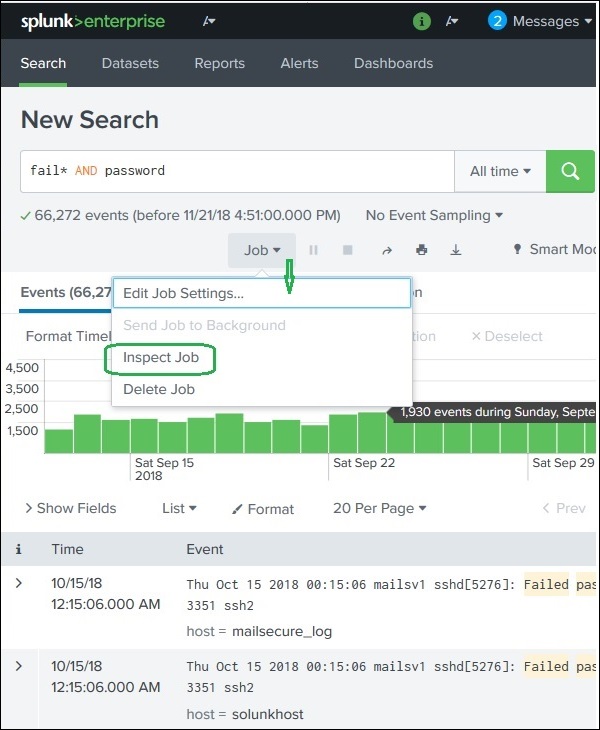
다음 화면은 위 쿼리에 대해 발생한 최적화에 대한 세부 정보를 제공합니다. 여기에서 이벤트 수와 결과를 반환하는 데 걸린 시간을 기록해야합니다.
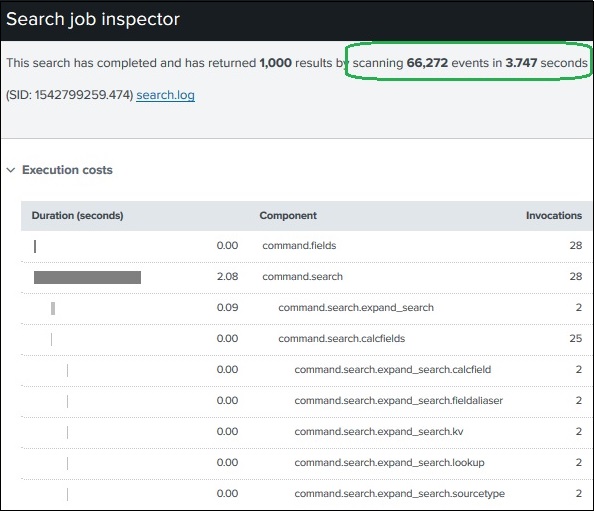
최적화 끄기
내장 된 최적화 기능을 끄고 검색 결과에 걸리는 시간의 차이를 확인할 수도 있습니다. 결과는 내장 검색보다 좋을 수도 있고 아닐 수도 있습니다. 더 좋은 경우에는 항상이 특정 검색에 대해서만 최적화를 해제하는이 옵션을 선택할 수 있습니다.
아래 다이어그램에서는 다음과 같이 표시된 최적화 없음 명령을 사용합니다. noop 검색어에서.
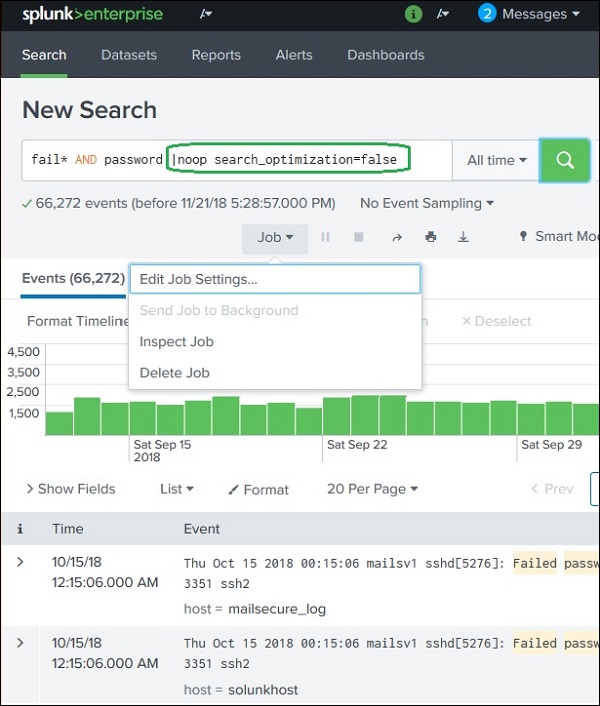
다음 화면은 최적화를 사용하지 않은 결과를 보여줍니다. 이 주어진 쿼리의 경우 내장 된 최적화를 사용하지 않고도 결과가 더 빨라집니다.