사육사-퀵 가이드
ZooKeeper는 대규모 호스트 집합을 관리하기위한 분산 조정 서비스입니다. 분산 환경에서 서비스를 조정하고 관리하는 것은 복잡한 프로세스입니다. ZooKeeper는 간단한 아키텍처와 API로이 문제를 해결합니다. ZooKeeper를 사용하면 개발자가 애플리케이션의 분산 특성에 대해 걱정하지 않고 핵심 애플리케이션 로직에 집중할 수 있습니다.
ZooKeeper 프레임 워크는 원래 "Yahoo!"에서 빌드되었습니다. 쉽고 강력한 방식으로 애플리케이션에 액세스 할 수 있습니다. 나중에 Apache ZooKeeper는 Hadoop, HBase 및 기타 분산 프레임 워크에서 사용하는 조직화 된 서비스의 표준이되었습니다. 예를 들어 Apache HBase는 ZooKeeper를 사용하여 분산 데이터의 상태를 추적합니다.
더 나아 가기 전에 분산 애플리케이션에 대해 한두 가지를 아는 것이 중요합니다. 이제 분산 응용 프로그램에 대한 간략한 개요로 토론을 시작하겠습니다.
분산 응용 프로그램
분산 응용 프로그램은 특정 작업을 빠르고 효율적인 방식으로 완료하기 위해 서로 조정하여 주어진 시간에 (동시에) 네트워크의 여러 시스템에서 실행할 수 있습니다. 일반적으로 비 분산 애플리케이션 (단일 시스템에서 실행)으로 완료하는 데 몇 시간이 걸리는 복잡하고 시간이 많이 걸리는 작업은 관련된 모든 시스템의 컴퓨팅 기능을 사용하여 분산 애플리케이션에서 몇 분 안에 수행 할 수 있습니다.
더 많은 시스템에서 실행되도록 분산 응용 프로그램을 구성하면 작업 완료 시간을 더욱 줄일 수 있습니다. 분산 응용 프로그램이 실행되는 시스템 그룹을Cluster 클러스터에서 실행되는 각 머신을 Node.
분산 응용 프로그램은 두 부분으로 구성됩니다. Server 과 Client신청. 서버 응용 프로그램은 실제로 분산되어 있으며 클라이언트가 클러스터의 모든 서버에 연결하여 동일한 결과를 얻을 수 있도록 공통 인터페이스를 가지고 있습니다. 클라이언트 응용 프로그램은 분산 응용 프로그램과 상호 작용하는 도구입니다.

분산 응용 프로그램의 이점
Reliability − 단일 또는 소수의 시스템이 실패한다고해서 전체 시스템이 실패하는 것은 아닙니다.
Scalability − 가동 중지 시간없이 애플리케이션 구성을 약간 변경하여 더 많은 기계를 추가하여 필요할 때마다 성능을 향상시킬 수 있습니다.
Transparency − 시스템의 복잡성을 숨기고 자신을 단일 개체 / 응용 프로그램으로 표시합니다.
분산 응용 프로그램의 과제
Race condition− 특정 작업을 수행하려는 두 대 이상의 컴퓨터. 실제로 주어진 시간에 단일 컴퓨터에서만 수행해야하는 작업. 예를 들어, 공유 리소스는 주어진 시간에 단일 시스템에서만 수정해야합니다.
Deadlock − 서로가 무기한 완료되기를 기다리는 두 개 이상의 작업.
Inconsistency − 부분적인 데이터 오류.
Apache ZooKeeper는 무엇을 의미합니까?
Apache ZooKeeper는 클러스터 (노드 그룹)에서 강력한 동기화 기술을 사용하여 자신을 조정하고 공유 데이터를 유지하는 데 사용하는 서비스입니다. ZooKeeper는 그 자체로 분산 애플리케이션 작성을위한 서비스를 제공하는 분산 애플리케이션입니다.
ZooKeeper에서 제공하는 일반적인 서비스는 다음과 같습니다.
Naming service− 이름으로 클러스터의 노드 식별. DNS와 유사하지만 노드 용입니다.
Configuration management − 가입 노드에 대한 시스템의 최신 및 최신 구성 정보.
Cluster management − 클러스터의 노드 가입 / 탈퇴 및 실시간 노드 상태.
Leader election − 조정 목적으로 노드를 리더로 선출.
Locking and synchronization service− 데이터를 수정하는 동안 잠금. 이 메커니즘은 Apache HBase와 같은 다른 분산 애플리케이션을 연결하는 동안 자동 장애 복구에 도움이됩니다.
Highly reliable data registry − 하나 또는 몇 개의 노드가 다운 된 경우에도 데이터 가용성.
분산 응용 프로그램은 많은 이점을 제공하지만 몇 가지 복잡하고 해결하기 어려운 문제도 제기합니다. ZooKeeper 프레임 워크는 모든 문제를 극복 할 수있는 완전한 메커니즘을 제공합니다. 경쟁 조건 및 교착 상태는 다음을 사용하여 처리됩니다.fail-safe synchronization approach. 또 다른 주요 단점은 ZooKeeper가 해결하는 데이터의 불일치입니다.atomicity.
ZooKeeper의 이점
ZooKeeper 사용의 이점은 다음과 같습니다.
Simple distributed coordination process
Synchronization− 서버 프로세스 간의 상호 배제 및 협력. 이 프로세스는 구성 관리를 위해 Apache HBase에서 도움이됩니다.
Ordered Messages
Serialization− 특정 규칙에 따라 데이터를 인코딩합니다. 애플리케이션이 일관되게 실행되는지 확인하십시오. 이 접근 방식은 MapReduce에서 큐를 조정하여 실행중인 스레드를 실행하는 데 사용할 수 있습니다.
Reliability
Atomicity − 데이터 전송은 완전히 성공하거나 실패하지만 부분적인 트랜잭션은 없습니다.
ZooKeeper의 작업에 대해 자세히 알아보기 전에 ZooKeeper의 기본 개념을 살펴 보겠습니다. 이 장에서는 다음 주제에 대해 설명합니다.
- Architecture
- 계층 적 네임 스페이스
- Session
- Watches
ZooKeeper의 아키텍처
다음 다이어그램을 살펴보십시오. ZooKeeper의 "클라이언트-서버 아키텍처"를 설명합니다.
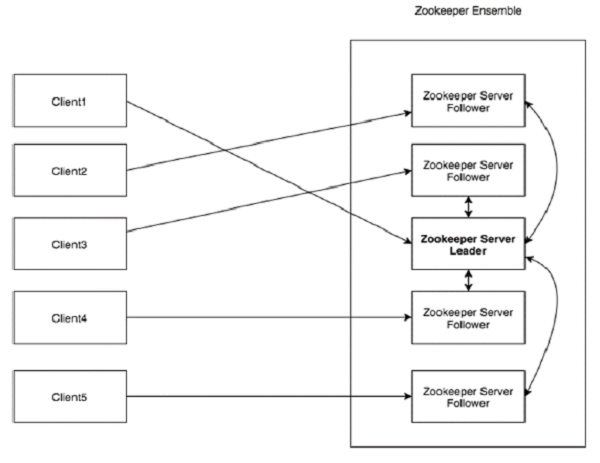
ZooKeeper 아키텍처의 일부인 각 구성 요소는 다음 표에 설명되어 있습니다.
| 부품 | 기술 |
|---|---|
| 고객 | 분산 애플리케이션 클러스터의 노드 중 하나 인 클라이언트는 서버의 정보에 액세스합니다. 특정 시간 간격 동안 모든 클라이언트는 서버에 클라이언트가 살아 있음을 알리기 위해 서버에 메시지를 보냅니다. 마찬가지로, 서버는 클라이언트가 연결될 때 승인을 보냅니다. 연결된 서버에서 응답이 없으면 클라이언트는 자동으로 메시지를 다른 서버로 리디렉션합니다. |
| 섬기는 사람 | ZooKeeper 앙상블의 노드 중 하나 인 서버는 모든 서비스를 클라이언트에 제공합니다. 서버가 살아 있음을 알리기 위해 클라이언트에 승인을 제공합니다. |
| 앙상블 | ZooKeeper 서버 그룹. 앙상블을 구성하는 데 필요한 최소 노드 수는 3 개입니다. |
| 리더 | 연결된 노드 중 하나가 실패하면 자동 복구를 수행하는 서버 노드입니다. 리더는 서비스 시작시 선출됩니다. |
| 수행원 | 리더 지시를 따르는 서버 노드. |
계층 적 네임 스페이스
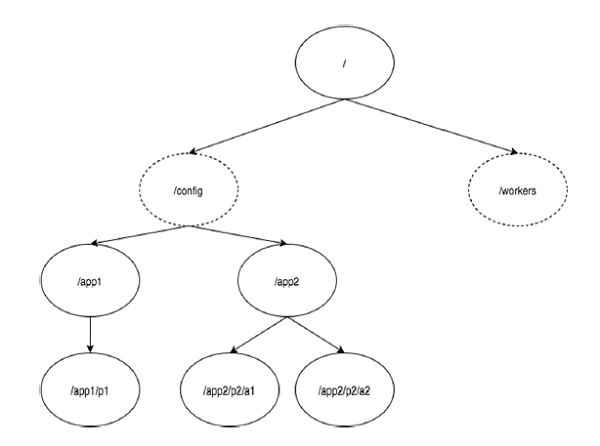
다음 다이어그램은 메모리 표현에 사용되는 ZooKeeper 파일 시스템의 트리 구조를 보여줍니다. ZooKeeper 노드는znode. 모든 znode는 이름으로 식별되고 일련의 경로 (/)로 구분됩니다.
다이어그램에서 먼저 루트가 있습니다. znode"/"로 구분됩니다. 루트 아래에는 두 개의 논리적 네임 스페이스가 있습니다.config 과 workers.
그만큼 config 네임 스페이스는 중앙 집중식 구성 관리에 사용되며 workers 네임 스페이스는 이름 지정에 사용됩니다.
아래에 config각 znode는 최대 1MB의 데이터를 저장할 수 있습니다. 이것은 상위 znode가 데이터를 저장할 수 있다는 점을 제외하면 UNIX 파일 시스템과 유사합니다. 이 구조의 주요 목적은 동기화 된 데이터를 저장하고 znode의 메타 데이터를 설명하는 것입니다. 이 구조는ZooKeeper Data Model.
ZooKeeper 데이터 모델의 모든 znode는 stat구조. 통계는 단순히metadataznode의. 그것은 구성 버전 번호, 동작 제어 목록 (ACL), 타임 스탬프 및 데이터 길이.
Version number− 모든 znode에는 버전 번호가 있습니다. 즉, znode와 관련된 데이터가 변경 될 때마다 해당 버전 번호도 증가합니다. 여러 zookeeper 클라이언트가 동일한 znode에서 작업을 수행하려고 할 때 버전 번호의 사용이 중요합니다.
Action Control List (ACL)− ACL은 기본적으로 znode에 액세스하기위한 인증 메커니즘입니다. 모든 znode 읽기 및 쓰기 작업을 제어합니다.
Timestamp− 타임 스탬프는 znode 생성 및 수정에서 경과 한 시간을 나타냅니다. 일반적으로 밀리 초로 표시됩니다. ZooKeeper는 "트랜잭션 ID"(zxid)에서 znode에 대한 모든 변경 사항을 식별합니다.Zxid 고유하고 각 트랜잭션에 대한 시간을 유지하므로 한 요청에서 다른 요청까지 경과 된 시간을 쉽게 식별 할 수 있습니다.
Data length− znode에 저장된 데이터의 총량은 데이터 길이입니다. 최대 1MB의 데이터를 저장할 수 있습니다.
Znode의 유형
Znode는 지속성, 순차 및 임시로 분류됩니다.
Persistence znode− 지속성 znode는 특정 znode를 생성 한 클라이언트가 연결 해제 된 후에도 살아 있습니다. 기본적으로 모든 znode는 달리 지정하지 않는 한 지속적입니다.
Ephemeral znode− 임시 znode는 클라이언트가 활성화 될 때까지 활성화됩니다. 클라이언트가 ZooKeeper 앙상블에서 연결이 끊어지면 임시 znode가 자동으로 삭제됩니다. 이러한 이유로 임시 znode 만 더 이상 자식을 가질 수 없습니다. 임시 znode가 삭제되면 다음 적합한 노드가 해당 위치를 채 웁니다. 임시 znode는 리더 선택에서 중요한 역할을합니다.
Sequential znode− 순차 znode는 지속적이거나 임시적 일 수 있습니다. 새 znode가 순차적 인 znode로 생성되면 ZooKeeper는 원래 이름에 10 자리 시퀀스 번호를 첨부하여 znode의 경로를 설정합니다. 예를 들어, 경로가있는 znode가/myapp 순차 znode로 생성되면 ZooKeeper는 경로를 다음과 같이 변경합니다. /myapp0000000001다음 시퀀스 번호를 0000000002로 설정합니다. 두 개의 순차적 인 znode가 동시에 생성되면 ZooKeeper는 각 znode에 대해 동일한 번호를 사용하지 않습니다. 순차적 znode는 잠금 및 동기화에서 중요한 역할을합니다.
세션
세션은 ZooKeeper의 운영에 매우 중요합니다. 세션의 요청은 FIFO 순서로 실행됩니다. 클라이언트가 서버에 연결되면 세션이 설정되고session id 클라이언트에 할당됩니다.
클라이언트는 heartbeats세션을 유효하게 유지하기 위해 특정 시간 간격으로. ZooKeeper 앙상블이 서비스 시작시 지정된 기간 (세션 시간 초과) 이상 동안 클라이언트로부터 하트 비트를받지 못하면 클라이언트가 죽었다고 결정합니다.
세션 시간 초과는 일반적으로 밀리 초로 표시됩니다. 어떤 이유로 든 세션이 종료되면 해당 세션 중에 생성 된 임시 znode도 삭제됩니다.
시계
Watch는 클라이언트가 ZooKeeper 앙상블의 변경 사항에 대한 알림을받을 수있는 간단한 메커니즘입니다. 클라이언트는 특정 znode를 읽는 동안 시계를 설정할 수 있습니다. 감시는 클라이언트가 등록하는 znode 변경 사항에 대해 등록 된 클라이언트에 알림을 보냅니다.
Znode 변경은 znode와 관련된 데이터의 수정 또는 znode의 자식 변경입니다. 시계는 한 번만 트리거됩니다. 클라이언트가 알림을 다시 원하면 다른 읽기 작업을 통해 수행해야합니다. 연결 세션이 만료되면 클라이언트와 서버의 연결이 끊어지고 관련 감시도 제거됩니다.
ZooKeeper 앙상블이 시작되면 클라이언트가 연결될 때까지 기다립니다. 클라이언트는 ZooKeeper 앙상블의 노드 중 하나에 연결됩니다. 리더 또는 팔로워 노드 일 수 있습니다. 클라이언트가 연결되면 노드는 특정 클라이언트에 세션 ID를 할당하고 클라이언트에 승인을 보냅니다. 클라이언트가 승인을받지 못하면 단순히 ZooKeeper 앙상블의 다른 노드에 연결을 시도합니다. 노드에 연결되면 클라이언트는 연결이 끊어지지 않도록 정기적으로 노드에 하트 비트를 보냅니다.
If a client wants to read a particular znode, 그것은 read requestznode 경로가있는 노드로 이동하면 노드는 요청 된 znode를 자체 데이터베이스에서 가져 와서 반환합니다. 이러한 이유로 ZooKeeper 앙상블에서는 읽기가 빠릅니다.
If a client wants to store data in the ZooKeeper ensemble, znode 경로와 데이터를 서버로 보냅니다. 연결된 서버는 요청을 리더에게 전달하고 리더는 모든 팔로워에게 쓰기 요청을 다시 발행합니다. 대다수의 노드 만 성공적으로 응답하면 쓰기 요청이 성공하고 성공적인 반환 코드가 클라이언트로 전송됩니다. 그렇지 않으면 쓰기 요청이 실패합니다. 대부분의 노드는 다음과 같이 호출됩니다.Quorum.
ZooKeeper 앙상블의 노드
ZooKeeper 앙상블에서 노드 수가 서로 다른 효과를 분석해 보겠습니다.
우리가 가지고 있다면 a single node, 노드가 실패하면 ZooKeeper 앙상블이 실패합니다. 이는 "단일 장애 지점"에 기여하며 프로덕션 환경에서는 권장되지 않습니다.
우리가 가지고 있다면 two nodes 한 노드가 실패하면 둘 중 하나가 과반수가 아니기 때문에 우리는 과반수도 없습니다.
우리가 가지고 있다면 three nodes하나의 노드가 실패하면 다수가 있으므로 최소 요구 사항입니다. ZooKeeper 앙상블은 라이브 프로덕션 환경에서 3 개 이상의 노드를 가져야합니다.
우리가 가지고 있다면 four nodes2 개의 노드가 실패하면 다시 실패하고 3 개의 노드가있는 것과 유사합니다. 추가 노드는 어떤 용도로도 사용되지 않으므로 3, 5, 7과 같이 홀수로 노드를 추가하는 것이 좋습니다.
쓰기 프로세스는 ZooKeeper 앙상블의 읽기 프로세스보다 비용이 많이 든다는 것을 알고 있습니다. 모든 노드가 데이터베이스에 동일한 데이터를 써야하기 때문입니다. 따라서 균형 잡힌 환경을 위해 많은 수의 노드를 갖는 것보다 적은 수의 노드 (3, 5 또는 7)를 갖는 것이 좋습니다.
다음 다이어그램은 ZooKeeper WorkFlow를 설명하고 후속 표에서는 다양한 구성 요소를 설명합니다.
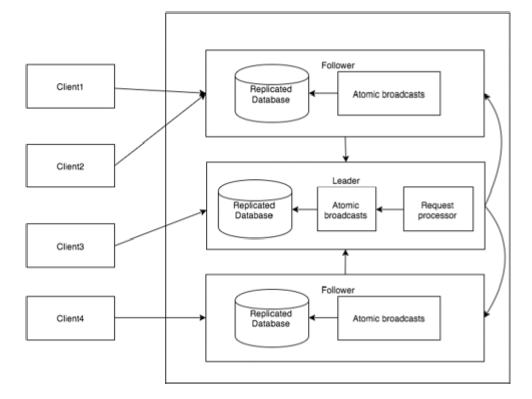
| 구성 요소 | 기술 |
|---|---|
| 쓰다 | 쓰기 프로세스는 리더 노드에서 처리합니다. 리더는 쓰기 요청을 모든 znode에 전달하고 znode의 응답을 기다립니다. znodes의 절반이 응답하면 쓰기 프로세스가 완료된 것입니다. |
| 읽다 | 읽기는 연결된 특정 znode에 의해 내부적으로 수행되므로 클러스터와 상호 작용할 필요가 없습니다. |
| 복제 된 데이터베이스 | 사육사에 데이터를 저장하는 데 사용됩니다. 각 znode에는 자체 데이터베이스가 있으며 모든 znode는 일관성의 도움으로 매번 동일한 데이터를 갖습니다. |
| 리더 | 리더는 쓰기 요청 처리를 담당하는 Znode입니다. |
| 수행원 | 추종자는 클라이언트로부터 쓰기 요청을 받고이를 리더 znode에 전달합니다. |
| 프로세서 요청 | 리더 노드에만 존재합니다. 팔로워 노드의 쓰기 요청을 관리합니다. |
| 원자 방송 | 리더 노드에서 팔로어 노드로 변경 사항을 브로드 캐스팅합니다. |
ZooKeeper 앙상블에서 리더 노드를 선택하는 방법을 분석해 보겠습니다. 거기 고려N클러스터의 노드 수. 리더 선출 과정은 다음과 같습니다.
모든 노드는 동일한 경로로 순차적 인 임시 znode를 만듭니다. /app/leader_election/guid_.
ZooKeeper 앙상블은 경로에 10 자리 시퀀스 번호를 추가하고 생성 된 znode는 /app/leader_election/guid_0000000001, /app/leader_election/guid_0000000002, 기타
주어진 인스턴스에서 znode에서 가장 작은 수를 생성하는 노드가 리더가되고 다른 모든 노드는 팔로어가됩니다.
각 팔로워 노드는 다음으로 작은 숫자를 가진 znode를 감시합니다. 예를 들어 znode를 생성하는 노드/app/leader_election/guid_0000000008 znode를 볼 것입니다 /app/leader_election/guid_0000000007 및 znode를 생성하는 노드 /app/leader_election/guid_0000000007 znode를 볼 것입니다 /app/leader_election/guid_0000000006.
리더가 다운되면 해당 znode /app/leader_electionN 삭제됩니다.
다음 인라인 팔로워 노드는 리더 제거에 대해 감시자를 통해 알림을받습니다.
다음 라인 추종자 노드는 가장 작은 숫자를 가진 다른 znode가 있는지 확인합니다. 없으면 리더의 역할을 맡게됩니다. 그렇지 않으면 리더로 가장 작은 수의 znode를 생성 한 노드를 찾습니다.
마찬가지로, 다른 모든 팔로워 노드는 가장 적은 수의 znode를 리더로 만든 노드를 선택합니다.
리더 선출은 처음부터 끝날 때 복잡한 과정입니다. 그러나 ZooKeeper 서비스는 매우 간단합니다. 다음 장에서 개발 목적으로 ZooKeeper 설치로 넘어가겠습니다.
ZooKeeper를 설치하기 전에 시스템이 다음 운영 체제에서 실행 중인지 확인하십시오.
Any of Linux OS− 개발 및 배포를 지원합니다. 데모 애플리케이션에 선호됩니다.
Windows OS − 개발 만 지원합니다.
Mac OS − 개발 만 지원합니다.
ZooKeeper 서버는 Java로 생성되며 JVM에서 실행됩니다. JDK 6 이상을 사용해야합니다.
이제 아래 단계에 따라 컴퓨터에 ZooKeeper 프레임 워크를 설치합니다.
1 단계 : Java 설치 확인
시스템에 이미 Java 환경이 설치되어 있다고 생각합니다. 다음 명령을 사용하여 확인하십시오.
$ java -version시스템에 Java가 설치되어있는 경우 설치된 Java 버전을 볼 수 있습니다. 그렇지 않으면 아래의 간단한 단계에 따라 최신 버전의 Java를 설치하십시오.
1.1 단계 : JDK 다운로드
다음 링크를 방문하여 최신 버전의 JDK를 다운로드하고 최신 버전을 다운로드하십시오. 자바
최신 버전 (이 튜토리얼을 작성하는 동안)은 JDK 8u 60이고 파일은“jdk-8u60-linuxx64.tar.gz”입니다. 컴퓨터에 파일을 다운로드하십시오.
1.2 단계 : 파일 추출
일반적으로 파일은 downloads폴더. 이를 확인하고 다음 명령을 사용하여 tar 설정을 추출하십시오.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gz1.3 단계 : opt 디렉토리로 이동
모든 사용자가 Java를 사용할 수 있도록하려면 추출 된 Java 컨텐츠를 "/ usr / local / java"폴더로 이동하십시오.
$ su
password: (type password of root user)
$ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/1.4 단계 : 경로 설정
경로 및 JAVA_HOME 변수를 설정하려면 ~ / .bashrc 파일에 다음 명령을 추가하십시오.
export JAVA_HOME = /usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/bin이제 모든 변경 사항을 현재 실행중인 시스템에 적용합니다.
$ source ~/.bashrc1.5 단계 : Java 대안
다음 명령을 사용하여 Java 대안을 변경하십시오.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 1001.6 단계
확인 명령을 사용하여 Java 설치 확인 (java -version) 1 단계에서 설명합니다.
2 단계 : ZooKeeper 프레임 워크 설치
2.1 단계 : ZooKeeper 다운로드
컴퓨터에 ZooKeeper 프레임 워크를 설치하려면 다음 링크를 방문하여 최신 버전의 ZooKeeper를 다운로드하십시오. http://zookeeper.apache.org/releases.html
현재 ZooKeeper의 최신 버전은 3.4.6 (ZooKeeper-3.4.6.tar.gz)입니다.
2.2 단계 : tar 파일 추출
다음 명령을 사용하여 tar 파일을 추출하십시오.
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6
$ mkdir data2.3 단계 : 구성 파일 만들기
이름이 지정된 구성 파일을 엽니 다. conf/zoo.cfg 명령 사용 vi conf/zoo.cfg 및 시작점으로 설정할 다음 모든 매개 변수.
$ vi conf/zoo.cfg
tickTime = 2000
dataDir = /path/to/zookeeper/data
clientPort = 2181
initLimit = 5
syncLimit = 2구성 파일이 성공적으로 저장되면 터미널로 다시 돌아갑니다. 이제 사육사 서버를 시작할 수 있습니다.
2.4 단계 : ZooKeeper 서버 시작
다음 명령을 실행하십시오-
$ bin/zkServer.sh start이 명령을 실행하면 다음과 같은 응답을 받게됩니다.
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTED2.5 단계 : CLI 시작
다음 명령을 입력하십시오-
$ bin/zkCli.sh위의 명령을 입력하면 ZooKeeper 서버에 연결되고 다음과 같은 응답이 표시됩니다.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]ZooKeeper 서버 중지
서버를 연결하고 모든 작업을 수행 한 후 다음 명령을 사용하여 사육사 서버를 중지 할 수 있습니다.
$ bin/zkServer.sh stopZooKeeper CLI (명령 줄 인터페이스)는 개발 목적으로 ZooKeeper 앙상블과 상호 작용하는 데 사용됩니다. 다른 옵션으로 디버깅하고 작업하는 데 유용합니다.
ZooKeeper CLI 작업을 수행하려면 먼저 ZooKeeper 서버 ( "bin / zkServer.sh start" )를 켠 다음 ZooKeeper 클라이언트 ( "bin / zkCli.sh" )를 켜십시오 . 클라이언트가 시작되면 다음 작업을 수행 할 수 있습니다.
- znode 생성
- 데이터 가져 오기
- znode에서 변경 사항보기
- 데이터 설정
- znode의 자식 만들기
- znode의 자식 나열
- 상태 확인
- znode 제거 / 삭제
이제 위의 명령을 예제와 함께 하나씩 살펴 보겠습니다.
Znode 생성
주어진 경로로 znode를 만듭니다. 그만큼flag인수는 생성 된 znode가 임시, 영구 또는 순차적인지 여부를 지정합니다. 기본적으로 모든 znode는 지속적입니다.
Ephemeral znodes (플래그 : e) 세션이 만료되거나 클라이언트 연결이 끊어지면 자동으로 삭제됩니다.
Sequential znodes znode 경로가 고유하다는 것을 보장합니다.
ZooKeeper 앙상블은 znode 경로에 10 자리 패딩과 함께 시퀀스 번호를 추가합니다. 예를 들어, znode 경로 / myapp은 / myapp0000000001로 변환되고 다음 시퀀스 번호는 / myapp0000000002가 됩니다. 플래그가 지정되지 않으면 znode는 다음과 같이 간주됩니다.persistent.
통사론
create /path /data견본
create /FirstZnode “Myfirstzookeeper-app”산출
[zk: localhost:2181(CONNECTED) 0] create /FirstZnode “Myfirstzookeeper-app”
Created /FirstZnode만들려면 Sequential znode, 추가 -s flag 아래 그림과 같이.
통사론
create -s /path /data견본
create -s /FirstZnode second-data산출
[zk: localhost:2181(CONNECTED) 2] create -s /FirstZnode “second-data”
Created /FirstZnode0000000023만들려면 Ephemeral Znode, 추가 -e flag 아래 그림과 같이.
통사론
create -e /path /data견본
create -e /SecondZnode “Ephemeral-data”산출
[zk: localhost:2181(CONNECTED) 2] create -e /SecondZnode “Ephemeral-data”
Created /SecondZnode클라이언트 연결이 끊어지면 임시 znode가 삭제됩니다. ZooKeeper CLI를 종료 한 다음 CLI를 다시 열어 사용해 볼 수 있습니다.
데이터 가져 오기
znode의 관련 데이터와 지정된 znode의 메타 데이터를 반환합니다. 데이터가 마지막으로 수정 된시기, 수정 된 위치 및 데이터에 대한 정보와 같은 정보를 얻을 수 있습니다. 이 CLI는 데이터에 대한 알림을 표시하기 위해 감시를 할당하는데도 사용됩니다.
통사론
get /path견본
get /FirstZnode산출
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode
“Myfirstzookeeper-app”
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x7f
mtime = Tue Sep 29 16:15:47 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 22
numChildren = 0순차 znode에 액세스하려면 znode의 전체 경로를 입력해야합니다.
견본
get /FirstZnode0000000023산출
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode0000000023
“Second-data”
cZxid = 0x80
ctime = Tue Sep 29 16:25:47 IST 2015
mZxid = 0x80
mtime = Tue Sep 29 16:25:47 IST 2015
pZxid = 0x80
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 13
numChildren = 0손목 시계
시계는 지정된 znode 또는 znode의 하위 데이터가 변경 될 때 알림을 표시합니다. 당신은 설정할 수 있습니다watch 오직 get 명령.
통사론
get /path [watch] 1견본
get /FirstZnode 1산출
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode 1
“Myfirstzookeeper-app”
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x7f
mtime = Tue Sep 29 16:15:47 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 22
numChildren = 0출력은 정상과 유사합니다. get명령이지만 백그라운드에서 znode 변경을 기다립니다. <여기에서 시작>
데이터 설정
지정된 znode의 데이터를 설정합니다. 이 설정 작업을 마치면 다음을 사용하여 데이터를 확인할 수 있습니다.get CLI 명령.
통사론
set /path /data견본
set /SecondZnode Data-updated산출
[zk: localhost:2181(CONNECTED) 1] get /SecondZnode “Data-updated”
cZxid = 0x82
ctime = Tue Sep 29 16:29:50 IST 2015
mZxid = 0x83
mtime = Tue Sep 29 16:29:50 IST 2015
pZxid = 0x82
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x15018b47db00000
dataLength = 14
numChildren = 0할당 한 경우 watch 옵션 get 명령 (이전 명령에서와 같이), 출력은 다음과 유사합니다-
산출
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode “Mysecondzookeeper-app”
WATCHER: :
WatchedEvent state:SyncConnected type:NodeDataChanged path:/FirstZnode
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x84
mtime = Tue Sep 29 17:14:47 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 23
numChildren = 0하위 / 하위 znode 만들기
자식을 만드는 것은 새 znode를 만드는 것과 비슷합니다. 유일한 차이점은 자식 znode의 경로에도 부모 경로가 있다는 것입니다.
통사론
create /parent/path/subnode/path /data견본
create /FirstZnode/Child1 firstchildren산출
[zk: localhost:2181(CONNECTED) 16] create /FirstZnode/Child1 “firstchildren”
created /FirstZnode/Child1
[zk: localhost:2181(CONNECTED) 17] create /FirstZnode/Child2 “secondchildren”
created /FirstZnode/Child2자녀 나열
이 명령은 children znode의.
통사론
ls /path견본
ls /MyFirstZnode산출
[zk: localhost:2181(CONNECTED) 2] ls /MyFirstZnode
[mysecondsubnode, myfirstsubnode]상태 확인
Status지정된 znode의 메타 데이터를 설명합니다. 여기에는 타임 스탬프, 버전 번호, ACL, 데이터 길이 및 하위 znode와 같은 세부 정보가 포함됩니다.
통사론
stat /path견본
stat /FirstZnode산출
[zk: localhost:2181(CONNECTED) 1] stat /FirstZnode
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x7f
mtime = Tue Sep 29 17:14:24 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 23
numChildren = 0Znode 제거
지정된 znode 및 모든 하위 항목을 재귀 적으로 제거합니다. 이는 그러한 znode를 사용할 수있는 경우에만 발생합니다.
통사론
rmr /path견본
rmr /FirstZnode산출
[zk: localhost:2181(CONNECTED) 10] rmr /FirstZnode
[zk: localhost:2181(CONNECTED) 11] get /FirstZnode
Node does not exist: /FirstZnode지우다 (delete /path) 명령은 다음과 유사합니다. remove 명령을 제외하고는 자식이없는 znode에서만 작동합니다.
ZooKeeper에는 Java 및 C에 대한 공식 API 바인딩이 있습니다. ZooKeeper 커뮤니티는 대부분의 언어 (.NET, python 등)에 대한 비공식 API를 제공합니다. 애플리케이션은 ZooKeeper API를 사용하여 연결, 상호 작용, 데이터 조작, 조정 및 마지막으로 ZooKeeper 앙상블과의 연결을 끊을 수 있습니다.
ZooKeeper API에는 ZooKeeper 앙상블의 모든 기능을 간단하고 안전한 방식으로 얻을 수있는 다양한 기능이 있습니다. ZooKeeper API는 동기 및 비동기 메서드를 모두 제공합니다.
ZooKeeper 앙상블과 ZooKeeper API는 모든 측면에서 서로를 완벽하게 보완하며 개발자에게 큰 도움이됩니다. 이 장에서 Java 바인딩에 대해 설명하겠습니다.
ZooKeeper API의 기초
ZooKeeper 앙상블과 상호 작용하는 응용 프로그램은 ZooKeeper Client 또는 간단히 Client.
Znode는 ZooKeeper 앙상블의 핵심 구성 요소이며 ZooKeeper API는 ZooKeeper 앙상블을 사용하여 znode의 모든 세부 사항을 조작하는 작은 메서드 집합을 제공합니다.
클라이언트는 ZooKeeper 앙상블과 명확하고 깔끔한 상호 작용을하기 위해 아래의 단계를 따라야합니다.
ZooKeeper 앙상블에 연결합니다. ZooKeeper 앙상블은 클라이언트에 대한 세션 ID를 할당합니다.
주기적으로 서버에 하트 비트를 보냅니다. 그렇지 않으면 ZooKeeper 앙상블이 세션 ID를 만료하고 클라이언트를 다시 연결해야합니다.
세션 ID가 활성 상태 인 한 znode를 가져 오거나 설정합니다.
모든 작업이 완료되면 ZooKeeper 앙상블에서 연결을 끊습니다. 클라이언트가 장기간 비활성 상태이면 ZooKeeper 앙상블이 자동으로 클라이언트 연결을 끊습니다.
자바 바인딩
이 장에서 가장 중요한 ZooKeeper API 세트를 이해하겠습니다. ZooKeeper API의 핵심 부분은ZooKeeper class. 생성자에서 ZooKeeper 앙상블을 연결하는 옵션을 제공하며 다음과 같은 방법이 있습니다.
connect − ZooKeeper 앙상블에 연결
create − znode 생성
exists − znode의 존재 여부와 정보 확인
getData − 특정 znode에서 데이터 가져 오기
setData − 특정 znode에 데이터 설정
getChildren − 특정 znode에서 사용 가능한 모든 하위 노드 가져 오기
delete − 특정 znode와 모든 자식을 가져옵니다.
close − 연결 종료
ZooKeeper Ensemble에 연결
ZooKeeper 클래스는 생성자를 통해 연결 기능을 제공합니다. 생성자의 서명은 다음과 같습니다.
ZooKeeper(String connectionString, int sessionTimeout, Watcher watcher)어디,
connectionString − ZooKeeper 앙상블 호스트.
sessionTimeout − 세션 시간 초과 (밀리 초).
watcher− "Watcher"인터페이스를 구현하는 객체. ZooKeeper 앙상블은 감시자 개체를 통해 연결 상태를 반환합니다.
새로운 도우미 클래스를 만들어 보겠습니다. ZooKeeperConnection 방법 추가 connect. 그만큼connect 메서드는 ZooKeeper 개체를 만들고 ZooKeeper 앙상블에 연결 한 다음 개체를 반환합니다.
여기 CountDownLatch 클라이언트가 ZooKeeper 앙상블에 연결될 때까지 기본 프로세스를 중지 (대기)하는 데 사용됩니다.
ZooKeeper 앙상블은 다음을 통해 연결 상태를 응답합니다. Watcher callback. Watcher 콜백은 클라이언트가 ZooKeeper 앙상블과 연결되고 Watcher 콜백이countDown 의 방법 CountDownLatch 잠금을 해제하려면 await 주요 과정에서.
다음은 ZooKeeper 앙상블과 연결하는 완전한 코드입니다.
코딩 : ZooKeeperConnection.java
// import java classes
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
// import zookeeper classes
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.AsyncCallback.StatCallback;
import org.apache.zookeeper.KeeperException.Code;
import org.apache.zookeeper.data.Stat;
public class ZooKeeperConnection {
// declare zookeeper instance to access ZooKeeper ensemble
private ZooKeeper zoo;
final CountDownLatch connectedSignal = new CountDownLatch(1);
// Method to connect zookeeper ensemble.
public ZooKeeper connect(String host) throws IOException,InterruptedException {
zoo = new ZooKeeper(host,5000,new Watcher() {
public void process(WatchedEvent we) {
if (we.getState() == KeeperState.SyncConnected) {
connectedSignal.countDown();
}
}
});
connectedSignal.await();
return zoo;
}
// Method to disconnect from zookeeper server
public void close() throws InterruptedException {
zoo.close();
}
}위 코드를 저장하면 다음 섹션에서 ZooKeeper 앙상블을 연결하는 데 사용됩니다.
Znode 생성
ZooKeeper 클래스는 create methodZooKeeper 앙상블에서 새 znode를 만듭니다. 의 서명create 방법은 다음과 같습니다-
create(String path, byte[] data, List<ACL> acl, CreateMode createMode)어디,
path− Znode 경로. 예 : / myapp1, / myapp2, / myapp1 / mydata1, myapp2 / mydata1 / myanothersubdata
data − 지정된 znode 경로에 저장할 데이터
acl− 생성 될 노드의 액세스 제어 목록. ZooKeeper API는 정적 인터페이스를 제공합니다ZooDefs.Ids기본적인 ACL 목록을 얻으려면. 예를 들어, ZooDefs.Ids.OPEN_ACL_UNSAFE는 열린 znode에 대한 acl 목록을 반환합니다.
createMode− 노드 유형, 임시, 순차 또는 둘 다. 이것은enum.
새로운 Java 애플리케이션을 만들어서 createZooKeeper API의 기능. 파일 생성ZKCreate.java. 기본 방법에서 유형의 개체를 만듭니다.ZooKeeperConnection 그리고 전화 connect ZooKeeper 앙상블에 연결하는 방법.
연결 메서드는 ZooKeeper 개체를 반환합니다. zk. 이제create 의 방법 zk 사용자 지정 개체 path 과 data.
znode를 만드는 전체 프로그램 코드는 다음과 같습니다.
코딩 : ZKCreate.java
import java.io.IOException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
public class ZKCreate {
// create static instance for zookeeper class.
private static ZooKeeper zk;
// create static instance for ZooKeeperConnection class.
private static ZooKeeperConnection conn;
// Method to create znode in zookeeper ensemble
public static void create(String path, byte[] data) throws
KeeperException,InterruptedException {
zk.create(path, data, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
public static void main(String[] args) {
// znode path
String path = "/MyFirstZnode"; // Assign path to znode
// data in byte array
byte[] data = "My first zookeeper app”.getBytes(); // Declare data
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
create(path, data); // Create the data to the specified path
conn.close();
} catch (Exception e) {
System.out.println(e.getMessage()); //Catch error message
}
}
}애플리케이션이 컴파일되고 실행되면 지정된 데이터가있는 znode가 ZooKeeper 앙상블에 생성됩니다. ZooKeeper CLI를 사용하여 확인할 수 있습니다.zkCli.sh.
cd /path/to/zookeeper
bin/zkCli.sh
>>> get /MyFirstZnodeExists – Znode의 존재 여부 확인
ZooKeeper 클래스는 exists methodznode의 존재를 확인합니다. 지정된 znode가있는 경우 znode의 메타 데이터를 리턴합니다. 의 서명exists 방법은 다음과 같습니다-
exists(String path, boolean watcher)어디,
path − Znode 경로
watcher − 지정된 znode를 감시할지 여부를 지정하는 부울 값
ZooKeeper API의 "존재"기능을 확인하기 위해 새로운 Java 애플리케이션을 만들어 보겠습니다. "ZKExists.java" 파일을 만듭니다 . 주 메서드에서 "ZooKeeperConnection" 개체를 사용하여 ZooKeeper 개체 "zk" 를 만듭니다. 그런 다음 사용자 지정 "path"를 사용 하여 "zk" 개체 의 "exists" 메서드를 호출 합니다 . 전체 목록은 다음과 같습니다-
코딩 : ZKExists.java
import java.io.IOException;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKExists {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path, true);
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; // Assign znode to the specified path
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path); // Stat checks the path of the znode
if(stat != null) {
System.out.println("Node exists and the node version is " +
stat.getVersion());
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage()); // Catches error messages
}
}
}응용 프로그램이 컴파일되고 실행되면 아래 출력이 표시됩니다.
Node exists and the node version is 1.getData 메서드
ZooKeeper 클래스는 getData지정된 znode 및 그 상태에 첨부 된 데이터를 가져 오는 메소드. 의 서명getData 방법은 다음과 같습니다-
getData(String path, Watcher watcher, Stat stat)어디,
path − Znode 경로.
watcher − 유형의 콜백 기능 Watcher. ZooKeeper 앙상블은 지정된 znode의 데이터가 변경 될 때 Watcher 콜백을 통해 알립니다. 일회성 알림입니다.
stat − znode의 메타 데이터를 반환합니다.
새로운 Java 애플리케이션을 만들어 getDataZooKeeper API의 기능. 파일 생성ZKGetData.java. 주 메서드에서 ZooKeeper 개체를 만듭니다.zk 그를 사용하여 ZooKeeperConnection목적. 그런 다음getData 사용자 지정 경로가있는 zk 개체의 메서드.
다음은 지정된 노드에서 데이터를 가져 오는 완전한 프로그램 코드입니다.
코딩 : ZKGetData.java
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKGetData {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path,true);
}
public static void main(String[] args) throws InterruptedException, KeeperException {
String path = "/MyFirstZnode";
final CountDownLatch connectedSignal = new CountDownLatch(1);
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path);
if(stat != null) {
byte[] b = zk.getData(path, new Watcher() {
public void process(WatchedEvent we) {
if (we.getType() == Event.EventType.None) {
switch(we.getState()) {
case Expired:
connectedSignal.countDown();
break;
}
} else {
String path = "/MyFirstZnode";
try {
byte[] bn = zk.getData(path,
false, null);
String data = new String(bn,
"UTF-8");
System.out.println(data);
connectedSignal.countDown();
} catch(Exception ex) {
System.out.println(ex.getMessage());
}
}
}
}, null);
String data = new String(b, "UTF-8");
System.out.println(data);
connectedSignal.await();
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}응용 프로그램이 컴파일되고 실행되면 다음과 같은 출력이 표시됩니다.
My first zookeeper app그리고 응용 프로그램은 ZooKeeper 앙상블의 추가 알림을 기다립니다. ZooKeeper CLI를 사용하여 지정된 znode의 데이터 변경zkCli.sh.
cd /path/to/zookeeper
bin/zkCli.sh
>>> set /MyFirstZnode Hello이제 응용 프로그램은 다음 출력을 인쇄하고 종료합니다.
HellosetData 메서드
ZooKeeper 클래스는 setData지정된 znode에 첨부 된 데이터를 수정하는 메소드입니다. 의 서명setData 방법은 다음과 같습니다-
setData(String path, byte[] data, int version)어디,
path − Znode 경로
data − 지정된 znode 경로에 저장할 데이터.
version− znode의 현재 버전. ZooKeeper는 데이터가 변경 될 때마다 znode의 버전 번호를 업데이트합니다.
이제 새로운 Java 애플리케이션을 만들어 setDataZooKeeper API의 기능. 파일 생성ZKSetData.java. 주 메서드에서 ZooKeeper 개체를 만듭니다.zk 사용하여 ZooKeeperConnection목적. 그런 다음setData 의 방법 zk 지정된 경로, 새 데이터 및 노드 버전이있는 개체.
다음은 지정된 znode에 첨부 된 데이터를 수정하는 완전한 프로그램 코드입니다.
코드 : ZKSetData.java
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import java.io.IOException;
public class ZKSetData {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to update the data in a znode. Similar to getData but without watcher.
public static void update(String path, byte[] data) throws
KeeperException,InterruptedException {
zk.setData(path, data, zk.exists(path,true).getVersion());
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path= "/MyFirstZnode";
byte[] data = "Success".getBytes(); //Assign data which is to be updated.
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
update(path, data); // Update znode data to the specified path
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}응용 프로그램이 컴파일되고 실행되면 지정된 znode의 데이터가 변경되며 ZooKeeper CLI를 사용하여 확인할 수 있습니다. zkCli.sh.
cd /path/to/zookeeper
bin/zkCli.sh
>>> get /MyFirstZnodegetChildrenMethod
ZooKeeper 클래스는 getChildren특정 znode의 모든 하위 노드를 가져 오는 방법. 의 서명getChildren 방법은 다음과 같습니다-
getChildren(String path, Watcher watcher)어디,
path − Znode 경로.
watcher− "Watcher"유형의 콜백 기능. ZooKeeper 앙상블은 지정된 znode가 삭제되거나 znode 아래의 자식이 생성 / 삭제 될 때이를 알립니다. 일회성 알림입니다.
코딩 : ZKGetChildren.java
import java.io.IOException;
import java.util.*;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKGetChildren {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path,true);
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; // Assign path to the znode
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path); // Stat checks the path
if(stat!= null) {
//“getChildren” method- get all the children of znode.It has two
args, path and watch
List <String> children = zk.getChildren(path, false);
for(int i = 0; i < children.size(); i++)
System.out.println(children.get(i)); //Print children's
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}프로그램을 실행하기 전에 두 개의 하위 노드를 만들어 /MyFirstZnode ZooKeeper CLI 사용, zkCli.sh.
cd /path/to/zookeeper
bin/zkCli.sh
>>> create /MyFirstZnode/myfirstsubnode Hi
>>> create /MyFirstZnode/mysecondsubmode Hi이제 프로그램을 컴파일하고 실행하면 위에서 만든 znode가 출력됩니다.
myfirstsubnode
mysecondsubnodeZnode 삭제
ZooKeeper 클래스는 delete지정된 znode를 삭제하는 방법. 의 서명delete 방법은 다음과 같습니다-
delete(String path, int version)어디,
path − Znode 경로.
version − znode의 현재 버전.
새로운 Java 애플리케이션을 만들어 deleteZooKeeper API의 기능. 파일 생성ZKDelete.java. 주 메서드에서 ZooKeeper 개체를 만듭니다.zk 사용 ZooKeeperConnection목적. 그런 다음delete 의 방법 zk 지정된 개체 path 그리고 노드의 버전.
znode를 삭제하는 전체 프로그램 코드는 다음과 같습니다.
코딩 : ZKDelete.java
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
public class ZKDelete {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static void delete(String path) throws KeeperException,InterruptedException {
zk.delete(path,zk.exists(path,true).getVersion());
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; //Assign path to the znode
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
delete(path); //delete the node with the specified path
} catch(Exception e) {
System.out.println(e.getMessage()); // catches error messages
}
}
}Zookeeper는 분산 환경을위한 유연한 조정 인프라를 제공합니다. ZooKeeper 프레임 워크는 오늘날 최고의 산업용 애플리케이션을 많이 지원합니다. 이 장에서는 가장 주목할만한 ZooKeeper 응용 프로그램에 대해 설명합니다.
야후!
ZooKeeper 프레임 워크는 원래 "Yahoo!"에서 빌드되었습니다. 잘 설계된 분산 애플리케이션은 데이터 투명성, 더 나은 성능, 견고성, 중앙 집중식 구성 및 조정과 같은 요구 사항을 충족해야합니다. 그래서 그들은 이러한 요구 사항을 충족시키기 위해 ZooKeeper 프레임 워크를 설계했습니다.
Apache Hadoop
Apache Hadoop은 빅 데이터 산업 성장의 원동력입니다. Hadoop은 구성 관리 및 조정을 위해 ZooKeeper를 사용합니다. Hadoop에서 ZooKeeper의 역할을 이해하는 시나리오를 살펴 보겠습니다.
가정 Hadoop cluster 교량 100 or more commodity servers. 따라서 조정 및 이름 지정 서비스가 필요합니다. 많은 수의 노드 계산이 관련되므로 각 노드는 서로 동기화하고 서비스에 액세스 할 위치와 구성 방법을 알아야합니다. 이 시점에서 Hadoop 클러스터에는 교차 노드 서비스가 필요합니다. ZooKeeper는cross-node synchronization Hadoop 프로젝트의 작업이 직렬화되고 동기화되도록합니다.
여러 ZooKeeper 서버가 대규모 Hadoop 클러스터를 지원합니다. 각 클라이언트 컴퓨터는 ZooKeeper 서버 중 하나와 통신하여 동기화 정보를 검색하고 업데이트합니다. 실시간 예제 중 일부는-
Human Genome Project− 인간 게놈 프로젝트에는 테라 바이트의 데이터가 포함되어 있습니다. Hadoop MapReduce 프레임 워크를 사용하여 데이터 세트를 분석하고 인간 개발을위한 흥미로운 사실을 찾을 수 있습니다.
Healthcare − 병원은 일반적으로 테라 바이트 단위 인 방대한 양의 환자 의료 기록을 저장, 검색 및 분석 할 수 있습니다.
Apache HBase
Apache HBase는 대규모 데이터 세트의 실시간 읽기 / 쓰기 액세스에 사용되는 오픈 소스 분산 NoSQL 데이터베이스이며 HDFS 위에서 실행됩니다. HBase는master-slave architectureHBase 마스터가 모든 슬레이브를 관리합니다. 노예는Region servers.
HBase 분산 애플리케이션 설치는 실행중인 ZooKeeper 클러스터에 따라 다릅니다. Apache HBase는 ZooKeeper를 사용하여 다음의 도움으로 마스터 및 리전 서버 전체에 분산 된 데이터의 상태를 추적합니다.centralized configuration management 과 distributed mutex메커니즘. 다음은 HBase의 사용 사례 중 일부입니다.
Telecom− 통신 업계는 수십억 건의 모바일 통화 기록 (약 30TB / 월)을 저장하며 이러한 통화 기록에 실시간으로 액세스하는 것은 엄청난 작업이됩니다. HBase를 사용하여 모든 기록을 실시간으로 쉽고 효율적으로 처리 할 수 있습니다.
Social network− 통신 산업과 마찬가지로 Twitter, LinkedIn, Facebook과 같은 사이트는 사용자가 작성한 게시물을 통해 방대한 양의 데이터를받습니다. HBase는 최근 동향 및 기타 흥미로운 사실을 찾는 데 사용할 수 있습니다.
Apache Solr
Apache Solr는 Java로 작성된 빠른 오픈 소스 검색 플랫폼입니다. 매우 빠르고 내결함성이있는 분산 검색 엔진입니다. 위에 구축Lucene, 그것은 고성능의 완전한 기능을 갖춘 텍스트 검색 엔진입니다.
Solr은 구성 관리, 리더 선택, 노드 관리, 데이터 잠금 및 동기화와 같은 ZooKeeper의 모든 기능을 광범위하게 사용합니다.
Solr에는 두 가지 부분이 있습니다. indexing 과 searching. 인덱싱은 나중에 검색 할 수 있도록 데이터를 적절한 형식으로 저장하는 프로세스입니다. Solr은 여러 노드에서 데이터를 인덱싱하고 여러 노드에서 검색하기 위해 ZooKeeper를 사용합니다. ZooKeeper는 다음과 같은 기능을 제공합니다.
필요할 때 노드 추가 / 제거
노드 간 데이터 복제 및 이후 데이터 손실 최소화
여러 노드간에 데이터를 공유하고 더 빠른 검색 결과를 위해 여러 노드에서 검색
Apache Solr의 일부 사용 사례에는 전자 상거래, 구직 등이 있습니다.