Zookeeper-워크 플로
ZooKeeper 앙상블이 시작되면 클라이언트가 연결될 때까지 기다립니다. 클라이언트는 ZooKeeper 앙상블의 노드 중 하나에 연결됩니다. 리더 또는 팔로워 노드 일 수 있습니다. 클라이언트가 연결되면 노드는 특정 클라이언트에 세션 ID를 할당하고 클라이언트에 승인을 보냅니다. 클라이언트가 승인을받지 못하면 단순히 ZooKeeper 앙상블의 다른 노드에 연결을 시도합니다. 노드에 연결되면 클라이언트는 연결이 끊어지지 않았는지 확인하기 위해 정기적으로 노드에 하트 비트를 보냅니다.
If a client wants to read a particular znode, 그것은 read requestznode 경로가있는 노드로 이동하면 노드는 요청 된 znode를 자체 데이터베이스에서 가져 와서 반환합니다. 이러한 이유로 ZooKeeper 앙상블에서는 읽기가 빠릅니다.
If a client wants to store data in the ZooKeeper ensemble, znode 경로와 데이터를 서버로 보냅니다. 연결된 서버는 요청을 리더에게 전달하고 리더는 모든 팔로워에게 쓰기 요청을 다시 발행합니다. 대다수의 노드 만 성공적으로 응답하면 쓰기 요청이 성공하고 성공적인 반환 코드가 클라이언트로 전송됩니다. 그렇지 않으면 쓰기 요청이 실패합니다. 대부분의 노드는 다음과 같이 호출됩니다.Quorum.
ZooKeeper 앙상블의 노드
ZooKeeper 앙상블에서 노드 수가 서로 다른 효과를 분석해 보겠습니다.
우리가 가지고 있다면 a single node이면 해당 노드가 실패하면 ZooKeeper 앙상블이 실패합니다. 이는 "단일 장애 지점"에 기여하며 프로덕션 환경에서는 권장되지 않습니다.
우리가 가지고 있다면 two nodes 하나의 노드가 실패하면 둘 중 하나가 과반수가 아니기 때문에 우리는 과반수도 없습니다.
우리가 가지고 있다면 three nodes하나의 노드가 실패하면 다수가 있으므로 최소 요구 사항입니다. ZooKeeper 앙상블은 라이브 프로덕션 환경에서 3 개 이상의 노드를 가져야합니다.
우리가 가지고 있다면 four nodes2 개의 노드가 실패하면 다시 실패하고 3 개의 노드가있는 것과 유사합니다. 추가 노드는 어떤 용도로도 사용되지 않으므로 3, 5, 7과 같이 홀수로 노드를 추가하는 것이 좋습니다.
쓰기 프로세스는 ZooKeeper 앙상블의 읽기 프로세스보다 비용이 많이 든다는 것을 알고 있습니다. 모든 노드가 데이터베이스에 동일한 데이터를 써야하기 때문입니다. 따라서 균형 잡힌 환경을 위해 많은 수의 노드를 갖는 것보다 적은 수의 노드 (3, 5 또는 7)를 갖는 것이 좋습니다.
다음 다이어그램은 ZooKeeper WorkFlow를 설명하고 후속 표에서는 다양한 구성 요소를 설명합니다.
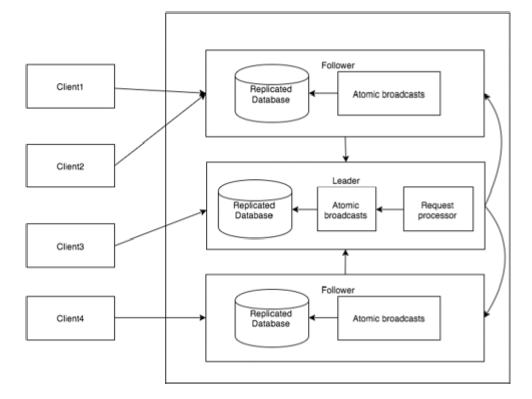
| 구성 요소 | 기술 |
|---|---|
| 쓰다 | 쓰기 프로세스는 리더 노드에서 처리합니다. 리더는 쓰기 요청을 모든 znode에 전달하고 znode의 응답을 기다립니다. znode의 절반이 응답하면 쓰기 프로세스가 완료된 것입니다. |
| 읽다 | 읽기는 연결된 특정 znode에 의해 내부적으로 수행되므로 클러스터와 상호 작용할 필요가 없습니다. |
| 복제 된 데이터베이스 | 사육사에 데이터를 저장하는 데 사용됩니다. 각 znode에는 자체 데이터베이스가 있으며 모든 znode는 일관성의 도움으로 매번 동일한 데이터를 가지고 있습니다. |
| 리더 | 리더는 쓰기 요청 처리를 담당하는 Znode입니다. |
| 수행원 | 추종자는 클라이언트로부터 쓰기 요청을 받고이를 리더 znode에 전달합니다. |
| 프로세서 요청 | 리더 노드에만 존재합니다. 팔로워 노드의 쓰기 요청을 제어합니다. |
| 원자 방송 | 리더 노드에서 팔로어 노드로 변경 사항을 브로드 캐스팅합니다. |