Budowanie modelu regresji
Regresja logistyczna odnosi się do algorytmu uczenia maszynowego używanego do przewidywania prawdopodobieństwa jakościowej zmiennej zależnej. W regresji logistycznej zmienną zależną jest zmienna binarna, która składa się z danych zakodowanych jako 1 (wartości logiczne prawda i fałsz).
W tym rozdziale skupimy się na opracowaniu modelu regresji w Pythonie przy użyciu zmiennej ciągłej. Przykład modelu regresji liniowej skupi się na eksploracji danych z pliku CSV.
Celem klasyfikacji jest przewidywanie, czy klient zapisze się (1/0) na lokatę terminową.
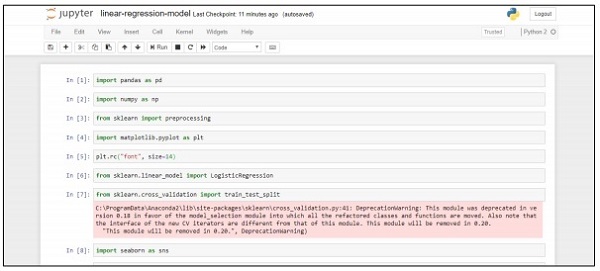
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
import seaborn as sns
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
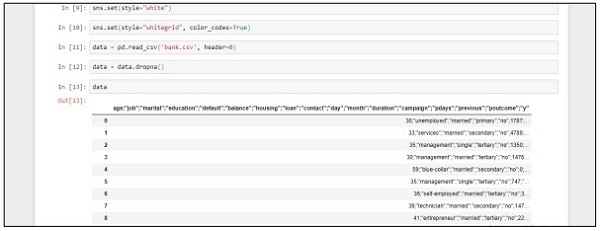
data = pd.read_csv('bank.csv', header=0)
data = data.dropna()
print(data.shape)
print(list(data.columns))Wykonaj następujące kroki, aby zaimplementować powyższy kod w programie Anaconda Navigator z „Jupyter Notebook” -
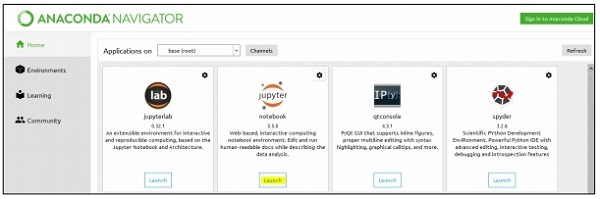
Step 1 - Uruchom notatnik Jupyter z Anaconda Navigator.
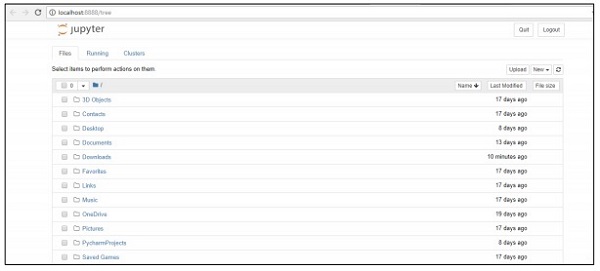
Step 2 - Prześlij plik csv, aby uzyskać dane wyjściowe modelu regresji w sposób systematyczny.
Step 3 - Utwórz nowy plik i wykonaj powyższą linię kodu, aby uzyskać żądane dane wyjściowe.