Apache Flink - Architektura
Apache Flink pracuje nad architekturą Kappa. Architektura Kappa ma pojedynczy procesor - strumień, który traktuje wszystkie dane wejściowe jako strumień, a silnik przesyłania strumieniowego przetwarza dane w czasie rzeczywistym. Dane wsadowe w architekturze kappa to szczególny przypadek przesyłania strumieniowego.
Poniższy diagram przedstawia Apache Flink Architecture.
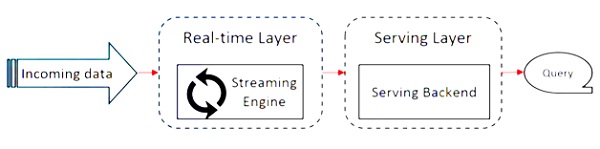
Kluczową ideą w architekturze Kappa jest obsługa zarówno danych wsadowych, jak i danych w czasie rzeczywistym za pośrednictwem silnika przetwarzania pojedynczego strumienia.
Większość frameworków do dużych zbiorów danych działa na architekturze Lambda, która ma oddzielne procesory dla danych wsadowych i strumieniowych. W architekturze Lambda masz oddzielne bazy kodów dla widoków wsadowych i strumieniowych. Aby wykonać zapytanie i uzyskać wynik, należy scalić bazy kodów. Nieutrzymywanie oddzielnych baz kodów / widoków i łączenie ich jest uciążliwe, ale architektura Kappa rozwiązuje ten problem, ponieważ ma tylko jeden widok - w czasie rzeczywistym, dlatego scalanie bazy kodu nie jest wymagane.
Nie oznacza to, że architektura Kappa zastępuje architekturę Lambda, całkowicie zależy od przypadku użycia i aplikacji, która decyduje, która architektura byłaby lepsza.
Poniższy diagram przedstawia architekturę wykonywania zadań Apache Flink.

Program
Jest to fragment kodu, który uruchamiasz w klastrze Flink.
Klient
Odpowiada za pobranie kodu (programu) i zbudowanie wykresu przepływu pracy, a następnie przekazanie go do JobManager. Pobiera również wyniki zadania.
JobManager
Po otrzymaniu Job Dataflow Graph od Klienta odpowiada za stworzenie wykresu wykonania. Przydziela zadanie do TaskManagerów w klastrze i nadzoruje wykonanie zadania.
Menadżer zadań
Jest odpowiedzialny za wykonanie wszystkich zadań, które zostały przydzielone przez JobManager. Wszyscy menedżerowie zadań uruchamiają zadania w swoich oddzielnych gniazdach z określoną równoległością. Odpowiada za wysyłanie statusu zadań do JobManager.
Funkcje Apache Flink
Funkcje Apache Flink są następujące -
Posiada procesor przesyłania strumieniowego, który może uruchamiać zarówno programy wsadowe, jak i strumieniowe.
Potrafi przetwarzać dane z prędkością błyskawicy.
API dostępne w Javie, Scali i Pythonie.
Zapewnia interfejsy API dla wszystkich typowych operacji, co jest bardzo łatwe w użyciu dla programistów.
Przetwarza dane z małym opóźnieniem (nanosekund) i dużą przepustowością.
Jest odporny na uszkodzenia. Jeśli węzeł, aplikacja lub sprzęt ulegną awarii, nie ma to wpływu na klaster.
Można łatwo zintegrować z Apache Hadoop, Apache MapReduce, Apache Spark, HBase i innymi narzędziami do dużych zbiorów danych.
Zarządzanie w pamięci można dostosować dla lepszych obliczeń.
Jest wysoce skalowalny i może skalować się do tysięcy węzłów w klastrze.
Okienkowanie jest bardzo elastyczne w Apache Flink.
Zapewnia przetwarzanie wykresów, uczenie maszynowe i biblioteki przetwarzania złożonych zdarzeń.