Apache Flume - Szybki przewodnik
Co to jest Flume?
Apache Flume to narzędzie / usługa / mechanizm pozyskiwania danych do gromadzenia i przenoszenia dużych ilości danych strumieniowych, takich jak pliki dziennika, zdarzenia (itp.) Z różnych źródeł do scentralizowanego magazynu danych.
Flume to wysoce niezawodne, rozproszone i konfigurowalne narzędzie. Jest przeznaczony głównie do kopiowania danych strumieniowych (danych dziennika) z różnych serwerów internetowych do HDFS.
Zastosowania Flume
Załóżmy, że aplikacja internetowa do handlu elektronicznego chce analizować zachowanie klientów z określonego regionu. Aby to zrobić, musieliby przenieść dostępne dane dziennika do Hadoop w celu analizy. Tutaj z pomocą przychodzi nam Apache Flume.
Flume służy do przenoszenia danych dziennika generowanych przez serwery aplikacji do HDFS z większą prędkością.
Zalety Flume
Oto zalety korzystania z Flume -
Korzystając z Apache Flume możemy przechowywać dane w dowolnym ze scentralizowanych sklepów (HBase, HDFS).
Gdy szybkość napływających danych przekracza szybkość, z jaką dane mogą być zapisywane w miejscu docelowym, Flume działa jako pośrednik między producentami danych a scentralizowanymi magazynami i zapewnia stały przepływ danych między nimi.
Flume zapewnia funkcję contextual routing.
Transakcje w Flume są oparte na kanałach, gdzie dla każdej wiadomości są utrzymywane dwie transakcje (jeden nadawca i jeden odbiorca). Gwarantuje niezawodne dostarczanie wiadomości.
Flume jest niezawodny, odporny na błędy, skalowalny, łatwy w zarządzaniu i dostosowywalny.
Funkcje Flume
Niektóre z godnych uwagi cech Flume są następujące -
Flume efektywnie pozyskuje dane dziennika z wielu serwerów internetowych do centralnego magazynu (HDFS, HBase).
Korzystając z Flume, możemy natychmiast pobrać dane z wielu serwerów do Hadoop.
Wraz z plikami dziennika Flume jest również używany do importowania ogromnych ilości danych o wydarzeniach pochodzących z serwisów społecznościowych, takich jak Facebook i Twitter, oraz witryn handlu elektronicznego, takich jak Amazon i Flipkart.
Flume obsługuje duży zestaw typów źródeł i miejsc docelowych.
Flume obsługuje przepływy multi-hop, przepływy fan-in, fan-out, kontekstowe trasowanie itp.
Koryto można skalować w poziomie.
Big Data,jak wiemy, to zbiór dużych zbiorów danych, których nie można przetworzyć przy użyciu tradycyjnych technik obliczeniowych. Analiza Big Data daje cenne wyniki.Hadoop to platforma typu open source, która umożliwia przechowywanie i przetwarzanie Big Data w rozproszonym środowisku na klastrach komputerów przy użyciu prostych modeli programowania.
Przesyłanie strumieniowe / dane dziennika
Ogólnie rzecz biorąc, większość danych, które mają być analizowane, będzie generowana przez różne źródła danych, takie jak serwery aplikacji, serwisy społecznościowe, serwery w chmurze i serwery przedsiębiorstwa. Dane te będą miały postaćlog files i events.
Log file - Ogólnie plik dziennika to plik filektóry zawiera listę zdarzeń / działań, które mają miejsce w systemie operacyjnym. Na przykład serwery WWW wymieniają każde żądanie skierowane do serwera w plikach dziennika.
Gromadząc takie dane z dziennika, możemy uzyskać informacje o -
- wydajność aplikacji i zlokalizuj różne awarie oprogramowania i sprzętu.
- zachowanie użytkowników i uzyskać lepsze spostrzeżenia biznesowe.
Tradycyjną metodą przesyłania danych do systemu HDFS jest użycie rozszerzenia putKomenda. Zobaczmy, jak używaćput Komenda.
HDFS umieścić polecenie
Głównym wyzwaniem związanym z obsługą danych dziennika jest przeniesienie tych dzienników generowanych przez wiele serwerów do środowiska Hadoop.
Hadoop File System Shelludostępnia polecenia do wstawiania danych do Hadoop i odczytywania z niego. Możesz wstawiać dane do Hadoop przy użyciuput polecenie, jak pokazano poniżej.
$ Hadoop fs –put /path of the required file /path in HDFS where to save the fileProblem z poleceniem put
Możemy użyć putpolecenie Hadoop do przesyłania danych z tych źródeł do HDFS. Ale ma następujące wady -
Za pomocą put polecenie, możemy przenieść only one file at a timepodczas gdy generatory danych generują dane z dużo większą szybkością. Ponieważ analiza przeprowadzona na starszych danych jest mniej dokładna, musimy mieć rozwiązanie do przesyłania danych w czasie rzeczywistym.
Jeśli używamy putpolecenie, dane są potrzebne do spakowania i powinny być gotowe do przesłania. Ponieważ serwery sieciowe generują dane w sposób ciągły, jest to bardzo trudne zadanie.
Potrzebujemy tutaj rozwiązań, które mogą przezwyciężyć wady programu put wydawać polecenia i przesyłać „strumieniowe dane” z generatorów danych do scentralizowanych magazynów (zwłaszcza HDFS) z mniejszym opóźnieniem.
Problem z HDFS
W HDFS plik istnieje jako pozycja katalogu, a długość pliku będzie traktowana jako zero, dopóki nie zostanie zamknięty. Na przykład, jeśli źródło zapisuje dane do HDFS, a sieć została przerwana w połowie operacji (bez zamykania pliku), to dane zapisane w pliku zostaną utracone.
Dlatego potrzebujemy niezawodnego, konfigurowalnego i łatwego w utrzymaniu systemu do przesyłania danych dziennika do HDFS.
Note- W systemie plików POSIX, ilekroć uzyskujemy dostęp do pliku (powiedzmy wykonując operację zapisu), inne programy nadal mogą odczytać ten plik (przynajmniej zapisaną część pliku). Dzieje się tak, ponieważ plik istnieje na dysku przed jego zamknięciem.
Dostępne rozwiązania
Aby przesyłać dane strumieniowe (pliki dziennika, zdarzenia itp.) Z różnych źródeł do HDFS, mamy do dyspozycji następujące narzędzia -
Skryba Facebooka
Scribe to niezwykle popularne narzędzie, które służy do agregowania i przesyłania strumieniowego danych dziennika. Został zaprojektowany do skalowania do bardzo dużej liczby węzłów i jest odporny na awarie sieci i węzłów.
Apache Kafka
Kafka została stworzona przez Apache Software Foundation. Jest to broker komunikatów typu open source. Korzystając z platformy Kafka, możemy obsługiwać kanały o dużej przepustowości i małych opóźnieniach.
Apache Flume
Apache Flume to narzędzie / usługa / mechanizm pozyskiwania danych do gromadzenia, agregacji i transportu dużych ilości danych strumieniowych, takich jak dane dziennika, zdarzenia (itp.) Z różnych usług internetowych do scentralizowanego magazynu danych.
Jest to wysoce niezawodne, rozproszone i konfigurowalne narzędzie, które zostało zaprojektowane głównie do przesyłania strumieniowych danych z różnych źródeł do HDFS.
W tym samouczku omówimy szczegółowo, jak używać Flume z kilkoma przykładami.
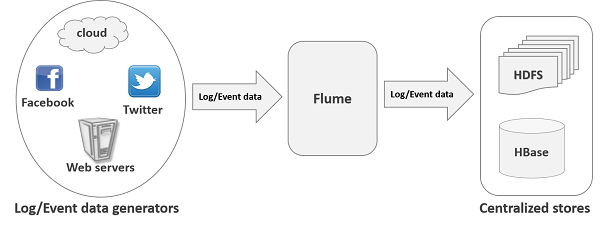
Poniższa ilustracja przedstawia podstawową architekturę Flume. Jak pokazano na ilustracji,data generators (np. Facebook, Twitter) generują dane, które są zbierane przez poszczególne Flume agentsbieganie na nich. Następnie adata collector (który jest również agentem) zbiera dane od agentów, które są agregowane i przekazywane do scentralizowanego magazynu, takiego jak HDFS lub HBase.

Wydarzenie Flume
Na event jest podstawową jednostką danych transportowanych wewnątrz Flume. Zawiera ładunek tablicy bajtów, który ma zostać przesłany ze źródła do miejsca docelowego wraz z opcjonalnymi nagłówkami. Typowe zdarzenie Flume miałoby następującą strukturę -

Agent Flume
Na agentjest niezależnym procesem demona (JVM) we Flume. Odbiera dane (zdarzenia) od klientów lub innych agentów i przekazuje je do następnego miejsca docelowego (ujścia lub agenta). Flume może mieć więcej niż jednego agenta. Poniższy diagram przedstawiaFlume Agent

Jak pokazano na diagramie, Flume Agent składa się z trzech głównych składników, a mianowicie: source, channel, i sink.
Źródło
ZA source jest komponentem Agenta, który odbiera dane z generatorów danych i przekazuje je do jednego lub kilku kanałów w postaci zdarzeń Flume.
Apache Flume obsługuje kilka typów źródeł, a każde źródło otrzymuje zdarzenia z określonego generatora danych.
Example - Źródło Avro, źródło Thrift, źródło twitter 1% itp.
Kanał
ZA channelto magazyn przejściowy, który odbiera zdarzenia ze źródła i buforuje je, dopóki nie zostaną zużyte przez ujścia. Działa jako pomost między źródłami a zlewami.
Kanały te są w pełni transakcyjne i mogą współpracować z dowolną liczbą źródeł i ujść.
Example - Kanał JDBC, kanał systemu plików, kanał pamięci itp.
Tonąć
ZA sinkprzechowuje dane w scentralizowanych magazynach, takich jak HBase i HDFS. Pobiera dane (zdarzenia) z kanałów i dostarcza je do miejsca przeznaczenia. Miejscem docelowym zlewu może być inny agent lub centralne sklepy.
Example - Umywalka HDFS
Note- Środek do odprowadzania spalin może mieć wiele źródeł, zlewów i kanałów. Wymieniliśmy wszystkie obsługiwane źródła, ujścia i kanały w rozdziale poświęconym konfiguracji Flume w tym samouczku.
Dodatkowe składniki Flume Agent
To, co omówiliśmy powyżej, to prymitywne składniki agenta. Oprócz tego mamy jeszcze kilka komponentów, które odgrywają istotną rolę w przenoszeniu zdarzeń z generatora danych do scentralizowanych sklepów.
Interceptory
Interceptory są używane do zmiany / kontroli zdarzeń w strumieniu, które są przenoszone między źródłem a kanałem.
Selektory kanałów
Służą one do określenia, który kanał ma być wybrany do przesyłania danych w przypadku wielu kanałów. Istnieją dwa typy selektorów kanałów -
Default channel selectors - Są one również znane jako replikujące selektory kanałów, replikują wszystkie zdarzenia w każdym kanale.
Multiplexing channel selectors - Decyduje o kanale do wysłania zdarzenia na podstawie adresu w nagłówku tego zdarzenia.
Procesory do zlewów
Są one używane do wywoływania określonego ujścia z wybranej grupy ujść. Są one używane do tworzenia ścieżek przełączania awaryjnego dla ujść lub zdarzeń równoważenia obciążenia w wielu ujściach z kanału.
Flume to struktura, która służy do przenoszenia danych dziennika do HDFS. Ogólnie zdarzenia i dane dziennika są generowane przez serwery dziennika i na tych serwerach działają agenci Flume. Agenci ci odbierają dane od generatorów danych.
Dane w tych agentach będą gromadzone przez węzeł pośredni znany jako Collector. Podobnie jak agenci, we Flume może znajdować się wielu zbieraczy.
Wreszcie, dane ze wszystkich tych kolektorów zostaną zagregowane i przesłane do scentralizowanego magazynu, takiego jak HBase lub HDFS. Poniższy diagram wyjaśnia przepływ danych w Flume.
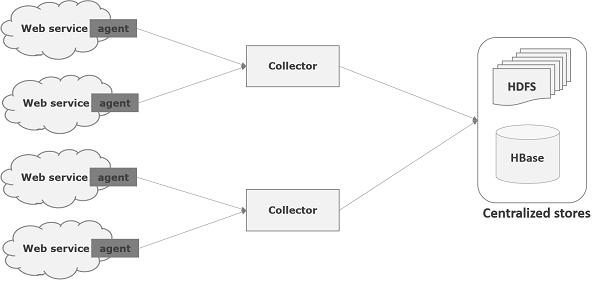
Przepływ multi-hop
We Flume może być wielu agentów i przed dotarciem do miejsca docelowego zdarzenie może odbywać się za pośrednictwem więcej niż jednego agenta. Jest to znane jakomulti-hop flow.
Przepływ na zewnątrz
Przepływ danych z jednego źródła do wielu kanałów jest znany jako fan-out flow. Jest dwojakiego rodzaju -
Replicating - Przepływ danych, w którym dane będą replikowane we wszystkich skonfigurowanych kanałach.
Multiplexing - Przepływ danych, w którym dane będą wysyłane do wybranego kanału, który jest wymieniony w nagłówku zdarzenia.
Przepływ wlotowy
Przepływ danych, w którym dane będą przesyłane z wielu źródeł do jednego kanału, jest znany jako fan-in flow.
Obsługa awarii
We Flume dla każdego zdarzenia mają miejsce dwie transakcje: jedna u nadawcy i jedna u odbiorcy. Nadawca wysyła zdarzenia do odbiorcy. Wkrótce po otrzymaniu danych odbiorca dokonuje własnej transakcji i wysyła „odebrany” sygnał do nadawcy. Po otrzymaniu sygnału nadawca dokonuje transakcji. (Nadawca nie zatwierdzi transakcji, dopóki nie otrzyma sygnału od odbiorcy).
Omówiliśmy już architekturę Flume w poprzednim rozdziale. W tym rozdziale zobaczmy, jak pobrać i skonfigurować Apache Flume.
Zanim przejdziesz dalej, musisz mieć w swoim systemie środowisko Java. Przede wszystkim upewnij się, że masz zainstalowaną Javę w swoim systemie. W przypadku niektórych przykładów w tym samouczku użyliśmy Hadoop HDFS (jako ujścia). Dlatego zalecamy zainstalowanie Hadoop wraz z Javą. Aby zebrać więcej informacji, kliknij link -http://www.tutorialspoint.com/hadoop/hadoop_enviornment_setup.htm
Instalowanie Flume
Przede wszystkim pobierz najnowszą wersję oprogramowania Apache Flume ze strony internetowej https://flume.apache.org/.
Krok 1
Otwórz witrynę. Kliknij nadownloadlink po lewej stronie strony głównej. Zostaniesz przeniesiony na stronę pobierania Apache Flume.
Krok 2
Na stronie pobierania można zobaczyć łącza do plików binarnych i źródłowych Apache Flume. Kliknij odsyłacz apache-flume-1.6.0-bin.tar.gz
Zostaniesz przekierowany do listy serwerów lustrzanych, z których możesz rozpocząć pobieranie, klikając dowolny z tych serwerów. W ten sam sposób możesz pobrać kod źródłowy Apache Flume, klikając apache-flume-1.6.0-src.tar.gz .
Krok 3
Utwórz katalog o nazwie Flume w tym samym katalogu, w którym znajdują się katalogi instalacyjne Hadoop, HBasei inne oprogramowanie zostało zainstalowane (jeśli zostało już zainstalowane), jak pokazano poniżej.
$ mkdir FlumeKrok 4
Rozpakuj pobrane pliki tar, jak pokazano poniżej.
$ cd Downloads/
$ tar zxvf apache-flume-1.6.0-bin.tar.gz
$ tar zxvf apache-flume-1.6.0-src.tar.gzKrok 5
Przenieś zawartość apache-flume-1.6.0-bin.tar plik do Flumekatalog utworzony wcześniej, jak pokazano poniżej. (Załóżmy, że utworzyliśmy katalog Flume w lokalnym użytkowniku o nazwie Hadoop.)
$ mv apache-flume-1.6.0-bin.tar/* /home/Hadoop/Flume/Konfiguracja Flume
Aby skonfigurować Flume, musimy zmodyfikować trzy pliki, a mianowicie: flume-env.sh, flumeconf.properties, i bash.rc.
Ustawianie ścieżki / ścieżki klas
w .bashrc plik, ustaw folder domowy, ścieżkę i ścieżkę klasy dla Flume, jak pokazano poniżej.
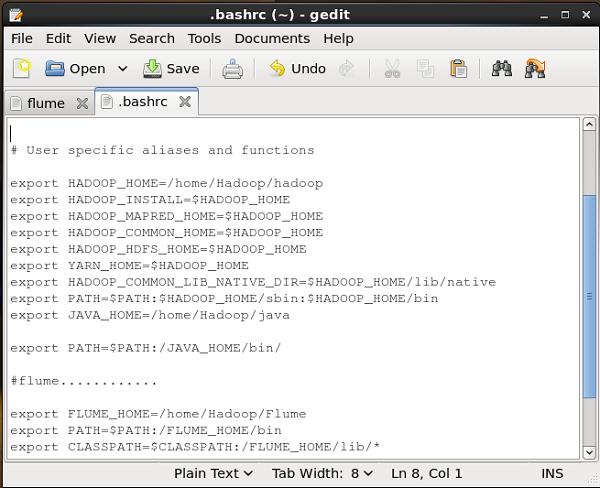
conf Folder
Jeśli otworzysz conf folder Apache Flume, będziesz mieć następujące cztery pliki -
- flume-conf.properties.template,
- flume-env.sh.template,
- flume-env.ps1.template i
- log4j.properties.

Teraz zmień nazwę
flume-conf.properties.template plik jako flume-conf.properties i
flume-env.sh.template tak jak flume-env.sh
flume-env.sh
otwarty flume-env.sh plik i ustaw plik JAVA_Home do folderu, w którym w systemie została zainstalowana Java.
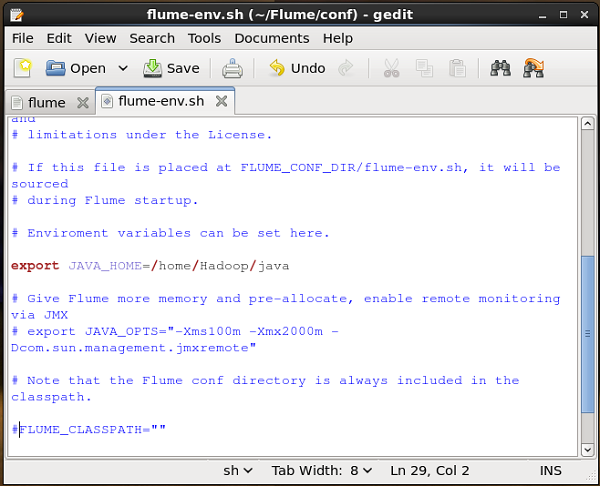
Weryfikacja instalacji
Sprawdź instalację Apache Flume, przeglądając plik bin folder i wpisując następujące polecenie.
$ ./flume-ngJeśli pomyślnie zainstalowałeś Flume, pojawi się monit pomocy Flume, jak pokazano poniżej.
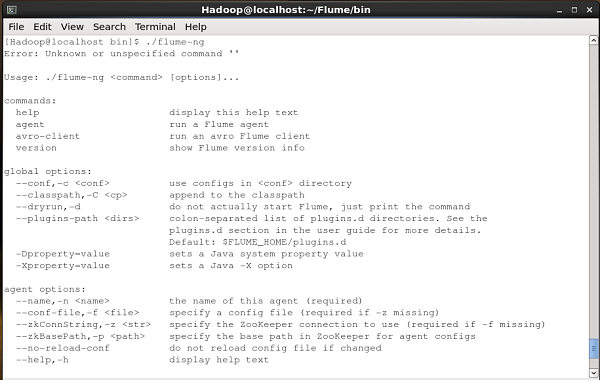
Po zainstalowaniu Flume musimy skonfigurować go za pomocą pliku konfiguracyjnego, który jest plikiem właściwości Java posiadającym key-value pairs. Musimy przekazać wartości do kluczy w pliku.
W pliku konfiguracyjnym Flume musimy -
- Nazwij komponenty bieżącego agenta.
- Opisz / skonfiguruj źródło.
- Opisz / skonfiguruj ujście.
- Opisz / skonfiguruj kanał.
- Powiąż źródło i ujście z kanałem.
Zwykle we Flume możemy mieć wielu agentów. Każdego agenta możemy odróżnić za pomocą unikalnej nazwy. Używając tej nazwy, musimy skonfigurować każdego agenta.
Nazewnictwo składników
Przede wszystkim musisz nazwać / wymienić komponenty, takie jak źródła, ujścia i kanały agenta, jak pokazano poniżej.
agent_name.sources = source_name
agent_name.sinks = sink_name
agent_name.channels = channel_nameFlume obsługuje różne źródła, zlewy i kanały. Są one wymienione w poniższej tabeli.
| Źródła | Kanały | Zlewozmywaki |
|---|---|---|
|
|
|
Możesz użyć dowolnego z nich. Na przykład, jeśli przesyłasz dane z Twittera za pomocą źródła Twittera przez kanał pamięci do ujścia HDFS, a identyfikator nazwy agentaTwitterAgent, następnie
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFSPo wyszczególnieniu składników agenta należy opisać źródła, ujścia i kanały, podając wartości ich właściwości.
Opis źródła
Każde źródło będzie miało oddzielną listę właściwości. Właściwość o nazwie „typ” jest wspólna dla każdego źródła i służy do określenia typu używanego źródła.
Wraz z właściwością „type” należy podać wartości wszystkich required właściwości określonego źródła, aby je skonfigurować, jak pokazano poniżej.
agent_name.sources. source_name.type = value
agent_name.sources. source_name.property2 = value
agent_name.sources. source_name.property3 = valueNa przykład, jeśli weźmiemy pod uwagę twitter source, Są następujące właściwości, do których należy podać wartości aby go skonfigurować.
TwitterAgent.sources.Twitter.type = Twitter (type name)
TwitterAgent.sources.Twitter.consumerKey =
TwitterAgent.sources.Twitter.consumerSecret =
TwitterAgent.sources.Twitter.accessToken =
TwitterAgent.sources.Twitter.accessTokenSecret =Opis zlewu
Podobnie jak źródło, każdy ujście będzie miał oddzielną listę właściwości. Właściwość o nazwie „typ” jest wspólna dla każdego ujścia i służy do określenia typu ujścia, którego używamy. Wraz z właściwością „type” konieczne jest podanie wartości dla wszystkichrequired właściwości konkretnego ujścia, aby go skonfigurować, jak pokazano poniżej.
agent_name.sinks. sink_name.type = value
agent_name.sinks. sink_name.property2 = value
agent_name.sinks. sink_name.property3 = valueNa przykład, jeśli weźmiemy pod uwagę HDFS sink, Są następujące właściwości, do których należy podać wartości aby go skonfigurować.
TwitterAgent.sinks.HDFS.type = hdfs (type name)
TwitterAgent.sinks.HDFS.hdfs.path = HDFS directory’s Path to store the dataOpisywanie kanału
Flume zapewnia różne kanały do przesyłania danych między źródłami i ujściami. Dlatego wraz ze źródłami i kanałami należy opisać kanał używany w agencie.
Aby opisać każdy kanał, musisz ustawić wymagane właściwości, jak pokazano poniżej.
agent_name.channels.channel_name.type = value
agent_name.channels.channel_name. property2 = value
agent_name.channels.channel_name. property3 = valueNa przykład, jeśli weźmiemy pod uwagę memory channel, Są następujące właściwości, do których należy podać wartości aby go skonfigurować.
TwitterAgent.channels.MemChannel.type = memory (type name)Wiązanie źródła i zlewu z kanałem
Ponieważ kanały łączą źródła i zlewy, wymagane jest powiązanie ich obu z kanałem, jak pokazano poniżej.
agent_name.sources.source_name.channels = channel_name
agent_name.sinks.sink_name.channels = channel_namePoniższy przykład pokazuje, jak powiązać źródła i ujścia z kanałem. Tutaj rozważymytwitter source, memory channel, i HDFS sink.
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channels = MemChannelUruchomienie agenta Flume
Po skonfigurowaniu musimy uruchomić agenta Flume. Odbywa się to w następujący sposób -
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf
Dflume.root.logger=DEBUG,console -n TwitterAgentgdzie -
agent - Polecenie uruchomienia agenta Flume
--conf ,-c<conf> - Użyj pliku konfiguracyjnego w katalogu conf
-f<file> - Określa ścieżkę do pliku konfiguracyjnego, jeśli jej nie ma
--name, -n <name> - Imię i nazwisko agenta Twittera
-D property =value - Ustawia wartość właściwości systemowej Java.
Korzystając z Flume, możemy pobierać dane z różnych usług i transportować je do scentralizowanych sklepów (HDFS i HBase). W tym rozdziale wyjaśniono, jak pobierać dane z serwisu Twitter i przechowywać je w HDFS przy użyciu Apache Flume.
Jak omówiono w Flume Architecture, serwer sieciowy generuje dane dziennika, które są gromadzone przez agenta we Flume. Kanał buforuje te dane do ujścia, które ostatecznie wypycha je do scentralizowanych sklepów.
W przykładzie przedstawionym w tym rozdziale utworzymy aplikację i pobierzemy z niej tweety, korzystając z eksperymentalnego źródła twitterowego dostarczonego przez Apache Flume. Użyjemy kanału pamięci do buforowania tych tweetów i ujścia HDFS, aby przesłać te tweety do HDFS.

Aby pobrać dane z Twittera, będziemy musieli wykonać kroki podane poniżej -
- Utwórz aplikację na Twitterze
- Zainstaluj / uruchom HDFS
- Skonfiguruj Flume
Tworzenie aplikacji na Twitterze
Aby otrzymywać tweety z Twittera, konieczne jest utworzenie aplikacji na Twitterze. Wykonaj poniższe czynności, aby utworzyć aplikację na Twitterze.
Krok 1
Aby utworzyć aplikację na Twitterze, kliknij poniższy link https://apps.twitter.com/. Zaloguj się na swoje konto na Twitterze. Będziesz mieć okno zarządzania aplikacjami Twittera, w którym możesz tworzyć, usuwać i zarządzać aplikacjami Twittera.
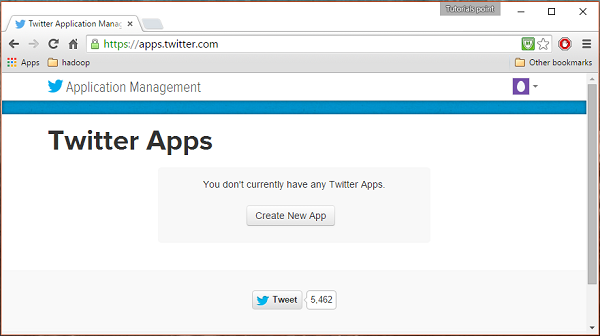
Krok 2
Kliknij na Create New Appprzycisk. Zostaniesz przekierowany do okna, w którym otrzymasz formularz zgłoszeniowy, w którym musisz podać swoje dane, aby utworzyć aplikację. Wypełniając adres strony, podaj pełny wzorzec adresu URL, np.http://example.com.
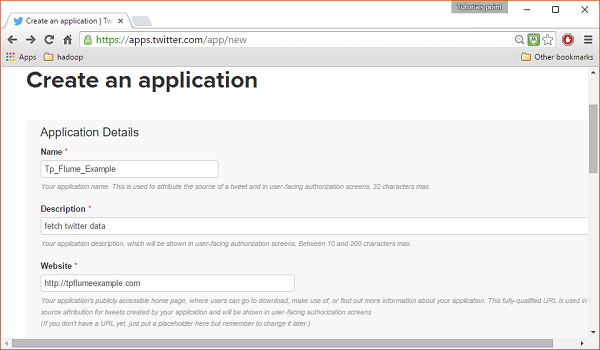
Krok 3
Uzupełnij dane, zaakceptuj Developer Agreement kiedy skończysz, kliknij Create your Twitter application buttonktóry znajduje się na dole strony. Jeśli wszystko pójdzie dobrze, zostanie utworzona aplikacja z podanymi szczegółami, jak pokazano poniżej.
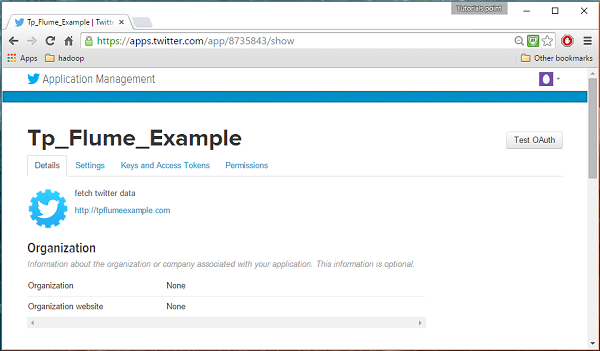
Krok 4
Pod keys and Access Tokens u dołu strony możesz obserwować przycisk o nazwie Create my access token. Kliknij na nią, aby wygenerować token dostępu.
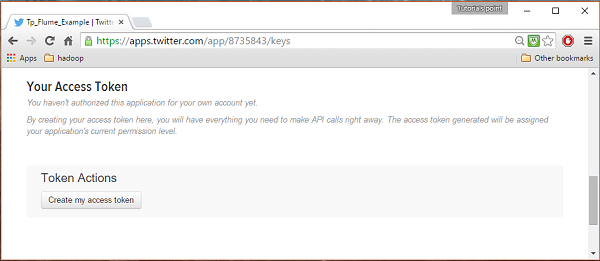
Krok 5
Na koniec kliknij Test OAuthprzycisk znajdujący się w prawej górnej części strony. Doprowadzi to do strony, która wyświetla TwójConsumer key, Consumer secret, Access token, i Access token secret. Skopiuj te szczegóły. Są przydatne do konfigurowania agenta we Flume.

Uruchamiam HDFS
Ponieważ przechowujemy dane w HDFS, musimy zainstalować / zweryfikować Hadoop. Uruchom Hadoop i utwórz w nim folder do przechowywania danych Flume. Przed skonfigurowaniem Flume wykonaj kroki podane poniżej.
Krok 1: Zainstaluj / zweryfikuj Hadoop
Zainstaluj Hadoop . Jeśli usługa Hadoop jest już zainstalowana w systemie, sprawdź instalację za pomocą polecenia wersji Hadoop, jak pokazano poniżej.
$ hadoop versionJeśli twój system zawiera Hadoop i jeśli ustawiłeś zmienną path, otrzymasz następujące dane wyjściowe -
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r
e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jarKrok 2: Uruchamianie Hadoop
Przejrzyj sbin katalogu Hadoop i uruchom Yarn i Hadoop dfs (rozproszony system plików), jak pokazano poniżej.
cd /$Hadoop_Home/sbin/
$ start-dfs.sh
localhost: starting namenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-namenode-localhost.localdomain.out
localhost: starting datanode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-datanode-localhost.localdomain.out
Starting secondary namenodes [0.0.0.0]
starting secondarynamenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-secondarynamenode-localhost.localdomain.out
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-resourcemanager-localhost.localdomain.out
localhost: starting nodemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-nodemanager-localhost.localdomain.outKrok 3: Utwórz katalog w HDFS
W Hadoop DFS można tworzyć katalogi za pomocą polecenia mkdir. Przejrzyj go i utwórz katalog o nazwietwitter_data w wymaganej ścieżce, jak pokazano poniżej.
$cd /$Hadoop_Home/bin/
$ hdfs dfs -mkdir hdfs://localhost:9000/user/Hadoop/twitter_dataKonfiguracja Flume
Musimy skonfigurować źródło, kanał i ujście za pomocą pliku konfiguracyjnego w confteczka. Przykład podany w tym rozdziale wykorzystuje eksperymentalne źródło dostarczone przez Apache Flume o nazwieTwitter 1% Firehose Kanał pamięci i ujście HDFS.
Twitter 1% Źródło Firehose
To źródło jest wysoce eksperymentalne. Łączy się z 1% próbką Twitter Firehose za pomocą interfejsu API przesyłania strumieniowego i stale pobiera tweety, konwertuje je do formatu Avro i wysyła zdarzenia Avro do podrzędnego ujścia Flume.
Źródło to otrzymamy domyślnie wraz z instalacją Flume. Plikjar pliki odpowiadające temu źródłu mogą znajdować się w lib folder, jak pokazano poniżej.

Ustawianie ścieżki klas
Ustaw classpath zmienna na lib folder Flume w formacie Flume-env.sh plik, jak pokazano poniżej.
export CLASSPATH=$CLASSPATH:/FLUME_HOME/lib/*To źródło wymaga szczegółów, takich jak Consumer key, Consumer secret, Access token, i Access token secretaplikacji na Twitterze. Konfigurując to źródło, musisz podać wartości do następujących właściwości -
Channels
Source type : org.apache.flume.source.twitter.TwitterSource
consumerKey - Klucz klienta OAuth
consumerSecret - Tajny klucz klienta OAuth
accessToken - Token dostępu OAuth
accessTokenSecret - Tajny klucz OAuth
maxBatchSize- Maksymalna liczba wiadomości na Twitterze, które powinny znajdować się w paczce na Twitterze. Wartość domyślna to 1000 (opcjonalnie).
maxBatchDurationMillis- Maksymalna liczba milisekund oczekiwania przed zamknięciem partii. Wartość domyślna to 1000 (opcjonalnie).
Kanał
Używamy kanału pamięci. Aby skonfigurować kanał pamięci, musisz podać wartość dla typu kanału.
type- Przechowuje typ kanału. W naszym przykładzie typ toMemChannel.
Capacity- Jest to maksymalna liczba zdarzeń przechowywanych w kanale. Jego domyślna wartość to 100 (opcjonalnie).
TransactionCapacity- Jest to maksymalna liczba zdarzeń, które kanał akceptuje lub wysyła. Jego domyślna wartość to 100 (opcjonalnie).
Zlew HDFS
To ujście zapisuje dane w HDFS. Aby skonfigurować ten ujście, musisz podać następujące szczegóły.
Channel
type - hdfs
hdfs.path - ścieżka do katalogu w HDFS, w którym mają być przechowywane dane.
Na podstawie scenariusza możemy podać kilka opcjonalnych wartości. Poniżej podano opcjonalne właściwości ujścia HDFS, które konfigurujemy w naszej aplikacji.
fileType - To jest wymagany format naszego pliku HDFS. SequenceFile, DataStream i CompressedStreamsą trzy typy dostępne w tym strumieniu. W naszym przykładzie używamyDataStream.
writeFormat - Może być tekstem lub zapisywalnym.
batchSize- Jest to liczba zdarzeń zapisanych w pliku przed umieszczeniem go w HDFS. Jego domyślna wartość to 100.
rollsize- Jest to rozmiar pliku wyzwalający przewijanie. Wartość domyślna to 100.
rollCount- Jest to liczba zdarzeń zapisanych w pliku przed jego przewinięciem. Jego domyślna wartość to 10.
Przykład - plik konfiguracyjny
Poniżej podano przykład pliku konfiguracyjnego. Skopiuj tę zawartość i zapisz jakotwitter.conf w folderze conf Flume.
# Naming the components on the current agent.
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFS
# Describing/Configuring the source
TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource
TwitterAgent.sources.Twitter.consumerKey = Your OAuth consumer key
TwitterAgent.sources.Twitter.consumerSecret = Your OAuth consumer secret
TwitterAgent.sources.Twitter.accessToken = Your OAuth consumer key access token
TwitterAgent.sources.Twitter.accessTokenSecret = Your OAuth consumer key access token secret
TwitterAgent.sources.Twitter.keywords = tutorials point,java, bigdata, mapreduce, mahout, hbase, nosql
# Describing/Configuring the sink
TwitterAgent.sinks.HDFS.type = hdfs
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/twitter_data/
TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream
TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text
TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000
TwitterAgent.sinks.HDFS.hdfs.rollSize = 0
TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000
# Describing/Configuring the channel
TwitterAgent.channels.MemChannel.type = memory
TwitterAgent.channels.MemChannel.capacity = 10000
TwitterAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channel = MemChannelWykonanie
Przejrzyj katalog domowy Flume i uruchom aplikację, jak pokazano poniżej.
$ cd $FLUME_HOME
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf
Dflume.root.logger=DEBUG,console -n TwitterAgentJeśli wszystko pójdzie dobrze, rozpocznie się przesyłanie strumieniowe tweetów do HDFS. Poniżej podano migawkę okna wiersza polecenia podczas pobierania tweetów.
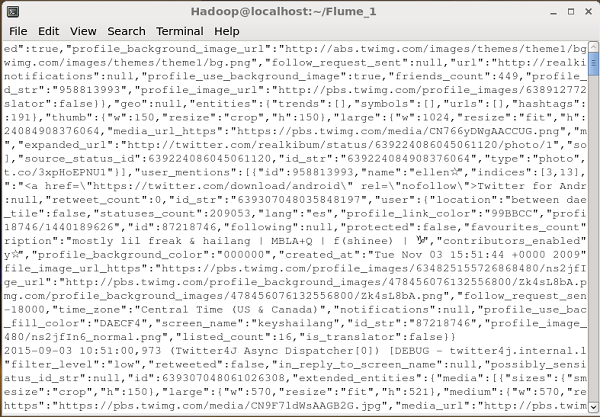
Weryfikacja HDFS
Dostęp do interfejsu administracyjnego sieci Web Hadoop można uzyskać, korzystając z adresu URL podanego poniżej.
http://localhost:50070/Kliknij listę rozwijaną o nazwie Utilitiesw prawej części strony. Możesz zobaczyć dwie opcje, jak pokazano na migawce podanej poniżej.
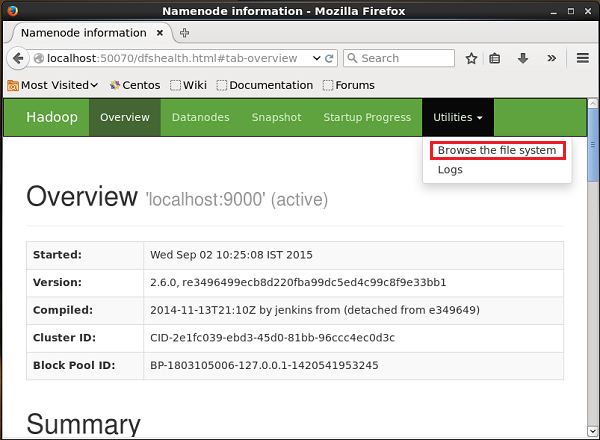
Kliknij Browse the file systemi wprowadź ścieżkę do katalogu HDFS, w którym zapisałeś tweety. W naszym przykładzie ścieżka będzie/user/Hadoop/twitter_data/. Następnie możesz zobaczyć listę plików dziennika Twittera przechowywanych w HDFS, jak podano poniżej.

W poprzednim rozdziale widzieliśmy, jak pobrać dane ze źródła Twittera do HDFS. W tym rozdziale wyjaśniono, jak pobrać dane zSequence generator.
Wymagania wstępne
Aby uruchomić przykład przedstawiony w tym rozdziale, musisz zainstalować HDFS wraz z Flume. Dlatego sprawdź instalację Hadoop i uruchom HDFS, zanim przejdziesz dalej. (Zapoznaj się z poprzednim rozdziałem, aby dowiedzieć się, jak uruchomić HDFS).
Konfiguracja Flume
Musimy skonfigurować źródło, kanał i ujście za pomocą pliku konfiguracyjnego w confteczka. W przykładzie podanym w tym rozdziale zastosowano pliksequence generator source, a memory channeli plik HDFS sink.
Źródło generatora sekwencji
To źródło nieustannie generuje zdarzenia. Utrzymuje licznik, który zaczyna się od 0 i zwiększa o 1. Jest używany do celów testowych. Podczas konfigurowania tego źródła należy podać wartości do następujących właściwości -
Channels
Source type - nast
Kanał
Używamy memorykanał. Aby skonfigurować kanał pamięci, musisz podać wartość dla typu kanału. Poniżej podano listę właściwości, które należy podać podczas konfigurowania kanału pamięci -
type- Przechowuje typ kanału. W naszym przykładzie jest to typ MemChannel.
Capacity- Jest to maksymalna liczba zdarzeń przechowywanych w kanale. Jego domyślna wartość to 100. (opcjonalnie)
TransactionCapacity- Jest to maksymalna liczba zdarzeń, które kanał akceptuje lub wysyła. Jego wartość domyślna to 100. (opcjonalnie).
Zlew HDFS
To ujście zapisuje dane w HDFS. Aby skonfigurować ten ujście, musisz podać następujące szczegóły.
Channel
type - hdfs
hdfs.path - ścieżka do katalogu w HDFS, w którym mają być przechowywane dane.
Na podstawie scenariusza możemy podać kilka opcjonalnych wartości. Poniżej podano opcjonalne właściwości ujścia HDFS, które konfigurujemy w naszej aplikacji.
fileType - To jest wymagany format naszego pliku HDFS. SequenceFile, DataStream i CompressedStreamsą trzy typy dostępne w tym strumieniu. W naszym przykładzie używamyDataStream.
writeFormat - Może być tekstem lub zapisywalnym.
batchSize- Jest to liczba zdarzeń zapisanych w pliku przed umieszczeniem go w HDFS. Jego domyślna wartość to 100.
rollsize- Jest to rozmiar pliku wyzwalający przewijanie. Wartość domyślna to 100.
rollCount- Jest to liczba zdarzeń zapisanych w pliku przed jego przewinięciem. Jego domyślna wartość to 10.
Przykład - plik konfiguracyjny
Poniżej podano przykład pliku konfiguracyjnego. Skopiuj tę zawartość i zapisz jakoseq_gen .conf w folderze conf Flume.
# Naming the components on the current agent
SeqGenAgent.sources = SeqSource
SeqGenAgent.channels = MemChannel
SeqGenAgent.sinks = HDFS
# Describing/Configuring the source
SeqGenAgent.sources.SeqSource.type = seq
# Describing/Configuring the sink
SeqGenAgent.sinks.HDFS.type = hdfs
SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/seqgen_data/
SeqGenAgent.sinks.HDFS.hdfs.filePrefix = log
SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0
SeqGenAgent.sinks.HDFS.hdfs.rollCount = 10000
SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream
# Describing/Configuring the channel
SeqGenAgent.channels.MemChannel.type = memory
SeqGenAgent.channels.MemChannel.capacity = 1000
SeqGenAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
SeqGenAgent.sources.SeqSource.channels = MemChannel
SeqGenAgent.sinks.HDFS.channel = MemChannelWykonanie
Przejrzyj katalog domowy Flume i uruchom aplikację, jak pokazano poniżej.
$ cd $FLUME_HOME
$./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/seq_gen.conf
--name SeqGenAgentJeśli wszystko pójdzie dobrze, źródło zacznie generować numery sekwencyjne, które zostaną przesłane do HDFS w postaci plików dziennika.
Poniżej przedstawiono migawkę okna wiersza polecenia pobierającego dane wygenerowane przez generator sekwencji do HDFS.

Weryfikacja HDFS
Dostęp do administracyjnego interfejsu użytkownika sieci Web Hadoop można uzyskać, korzystając z następującego adresu URL -
http://localhost:50070/Kliknij listę rozwijaną o nazwie Utilitiesw prawej części strony. Możesz zobaczyć dwie opcje, jak pokazano na poniższym schemacie.
Kliknij Browse the file system i wprowadź ścieżkę do katalogu HDFS, w którym zostały zapisane dane wygenerowane przez generator sekwencji.
W naszym przykładzie ścieżka będzie /user/Hadoop/ seqgen_data /. Następnie możesz zobaczyć listę plików dziennika wygenerowanych przez generator sekwencji, przechowywanych w HDFS, jak podano poniżej.
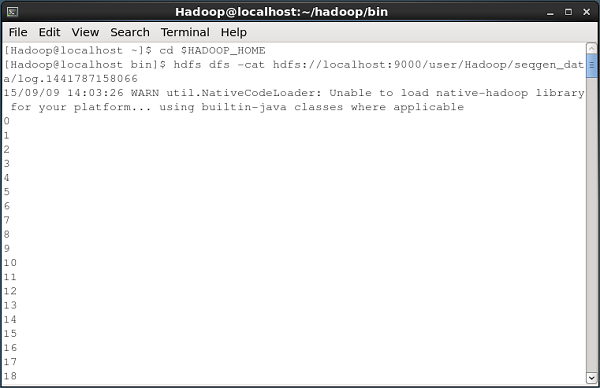
Weryfikacja zawartości pliku
Wszystkie te pliki dziennika zawierają liczby w formacie sekwencyjnym. Zawartość tego pliku można sprawdzić w systemie plików przy użyciu rozszerzeniacat polecenie, jak pokazano poniżej.
W tym rozdziale przedstawiono przykład, aby wyjaśnić, jak można generować zdarzenia, a następnie logować je do konsoli. W tym celu używamyNetCat źródło i logger tonąć.
Wymagania wstępne
Aby uruchomić przykład przedstawiony w tym rozdziale, musisz zainstalować Flume.
Konfiguracja Flume
Musimy skonfigurować źródło, kanał i ujście za pomocą pliku konfiguracyjnego w confteczka. W przykładzie podanym w tym rozdziale zastosowano plikNetCat Source, Memory channeli a logger sink.
Źródło NetCat
Konfigurując źródło NetCat, musimy określić port podczas konfigurowania źródła. Teraz źródło (źródło NetCat) nasłuchuje podanego portu i odbiera każdą linię, którą wprowadziliśmy w tym porcie jako indywidualne zdarzenie i przekazuje ją do ujścia przez określony kanał.
Konfigurując to źródło, musisz podać wartości do następujących właściwości -
channels
Source type - netcat
bind - Nazwa hosta lub adres IP do powiązania.
port - Numer portu, którego ma nasłuchiwać źródło.
Kanał
Używamy memorykanał. Aby skonfigurować kanał pamięci, musisz podać wartość dla typu kanału. Poniżej podano listę właściwości, które należy podać podczas konfigurowania kanału pamięci -
type- Przechowuje typ kanału. W naszym przykładzie typ toMemChannel.
Capacity- Jest to maksymalna liczba zdarzeń przechowywanych w kanale. Jego domyślna wartość to 100. (opcjonalnie)
TransactionCapacity- Jest to maksymalna liczba zdarzeń, które kanał akceptuje lub wysyła. Jego domyślna wartość to 100. (opcjonalnie).
Logger Sink
Ten ujście rejestruje wszystkie przekazane do niego zdarzenia. Zwykle służy do testowania lub debugowania. Aby skonfigurować ten ujście, musisz podać następujące szczegóły.
Channel
type - rejestrator
Przykładowy plik konfiguracyjny
Poniżej podano przykład pliku konfiguracyjnego. Skopiuj tę zawartość i zapisz jakonetcat.conf w folderze conf Flume.
# Naming the components on the current agent
NetcatAgent.sources = Netcat
NetcatAgent.channels = MemChannel
NetcatAgent.sinks = LoggerSink
# Describing/Configuring the source
NetcatAgent.sources.Netcat.type = netcat
NetcatAgent.sources.Netcat.bind = localhost
NetcatAgent.sources.Netcat.port = 56565
# Describing/Configuring the sink
NetcatAgent.sinks.LoggerSink.type = logger
# Describing/Configuring the channel
NetcatAgent.channels.MemChannel.type = memory
NetcatAgent.channels.MemChannel.capacity = 1000
NetcatAgent.channels.MemChannel.transactionCapacity = 100
# Bind the source and sink to the channel
NetcatAgent.sources.Netcat.channels = MemChannel
NetcatAgent.sinks. LoggerSink.channel = MemChannelWykonanie
Przejrzyj katalog domowy Flume i uruchom aplikację, jak pokazano poniżej.
$ cd $FLUME_HOME
$ ./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/netcat.conf
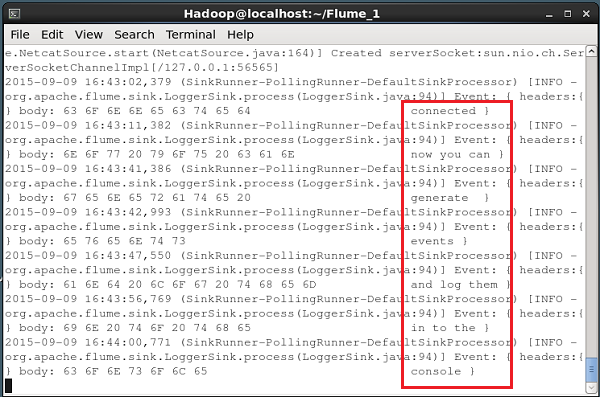
--name NetcatAgent -Dflume.root.logger=INFO,consoleJeśli wszystko pójdzie dobrze, źródło zacznie nasłuchiwać na danym porcie. W tym przypadku tak jest56565. Poniżej przedstawiono migawkę okna wiersza poleceń źródła NetCat, które zostało uruchomione i nasłuchuje portu 56565.
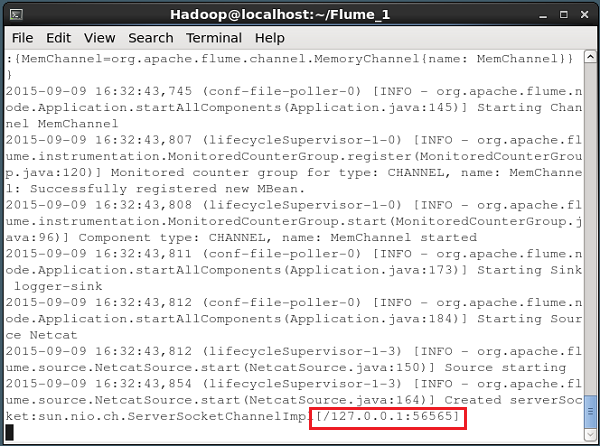
Przekazywanie danych do źródła
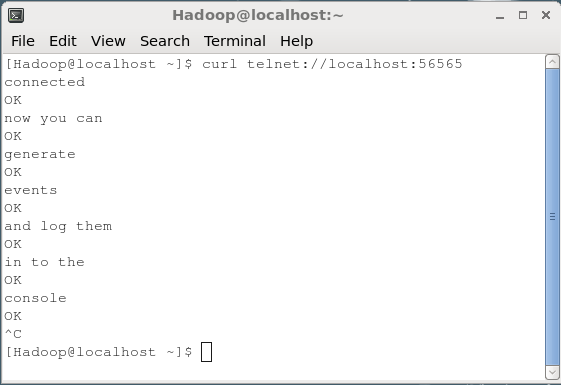
Aby przekazać dane do źródła NetCat, musisz otworzyć port podany w pliku konfiguracyjnym. Otwórz oddzielny terminal i podłącz do źródła (56565) za pomocącurlKomenda. Po pomyślnym nawiązaniu połączenia zostanie wyświetlony komunikat „connected" jak pokazano niżej.
$ curl telnet://localhost:56565
connectedTeraz możesz wprowadzać dane wiersz po wierszu (po każdym wierszu musisz nacisnąć Enter). Źródło NetCat odbiera każdą linię jako osobne zdarzenie, a otrzymasz otrzymaną wiadomość ”OK”.
Gdy skończysz z przekazywaniem danych, możesz wyjść z konsoli naciskając (Ctrl+C). Poniżej przedstawiono migawkę konsoli, w której połączyliśmy się ze źródłem za pomocącurl Komenda.
Każda linia wprowadzona w powyższej konsoli zostanie odebrana przez źródło jako indywidualne zdarzenie. Ponieważ użyliśmyLogger sink, zdarzenia te zostaną zalogowane do konsoli (konsoli źródłowej) przez określony kanał (w tym przypadku kanał pamięci).
Poniższa migawka przedstawia konsolę NetCat, w której są rejestrowane zdarzenia.