Apache Flume - pobieranie danych z Twittera
Korzystając z Flume, możemy pobierać dane z różnych usług i transportować je do scentralizowanych sklepów (HDFS i HBase). W tym rozdziale wyjaśniono, jak pobierać dane z serwisu Twitter i przechowywać je w HDFS przy użyciu Apache Flume.
Jak omówiono w Flume Architecture, serwer sieciowy generuje dane dziennika, które są gromadzone przez agenta we Flume. Kanał buforuje te dane do ujścia, które ostatecznie wypycha je do scentralizowanych sklepów.
W przykładzie przedstawionym w tym rozdziale utworzymy aplikację i pobierzemy z niej tweety, korzystając z eksperymentalnego źródła twitterowego dostarczonego przez Apache Flume. Użyjemy kanału pamięci do buforowania tych tweetów i ujścia HDFS, aby przesłać te tweety do HDFS.

Aby pobrać dane z Twittera, będziemy musieli wykonać kroki podane poniżej -
- Utwórz aplikację na Twitterze
- Zainstaluj / uruchom HDFS
- Skonfiguruj Flume
Tworzenie aplikacji na Twitterze
Aby otrzymywać tweety z Twittera, konieczne jest utworzenie aplikacji na Twitterze. Wykonaj poniższe czynności, aby utworzyć aplikację na Twitterze.
Krok 1
Aby utworzyć aplikację na Twitterze, kliknij poniższy link https://apps.twitter.com/. Zaloguj się na swoje konto na Twitterze. Będziesz mieć okno zarządzania aplikacjami Twittera, w którym możesz tworzyć, usuwać i zarządzać aplikacjami Twittera.
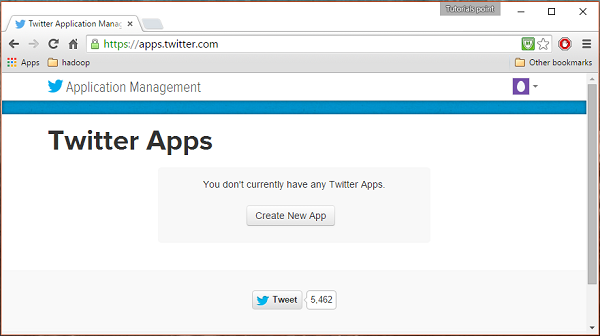
Krok 2
Kliknij na Create New Appprzycisk. Zostaniesz przekierowany do okna, w którym otrzymasz formularz zgłoszeniowy, w którym musisz podać swoje dane, aby utworzyć aplikację. Wypełniając adres strony, podaj pełny wzorzec adresu URL, np.http://example.com.
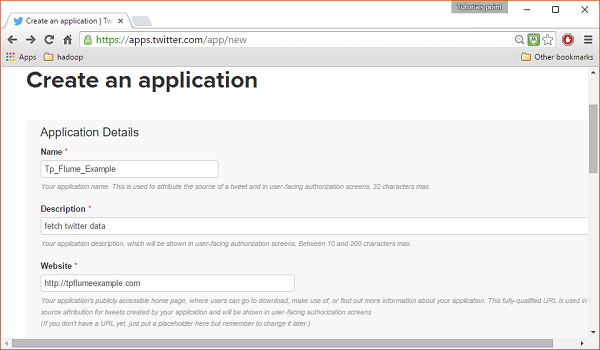
Krok 3
Uzupełnij dane, zaakceptuj Developer Agreement kiedy skończysz, kliknij Create your Twitter application buttonktóry znajduje się na dole strony. Jeśli wszystko pójdzie dobrze, zostanie utworzona aplikacja z podanymi szczegółami, jak pokazano poniżej.
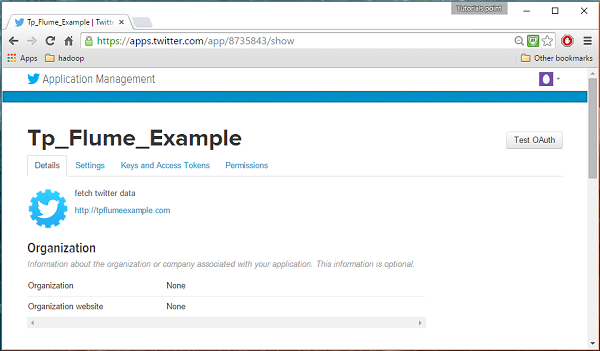
Krok 4
Pod keys and Access Tokens u dołu strony możesz obserwować przycisk o nazwie Create my access token. Kliknij na nią, aby wygenerować token dostępu.
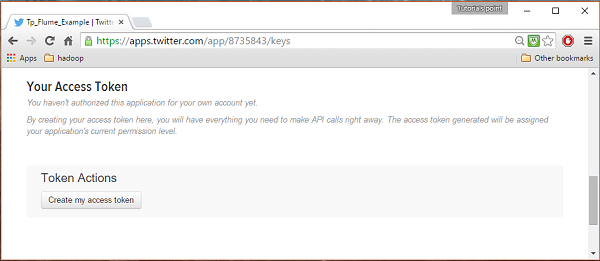
Krok 5
Na koniec kliknij Test OAuthprzycisk znajdujący się w prawej górnej części strony. Doprowadzi to do strony, która wyświetla TwójConsumer key, Consumer secret, Access token, i Access token secret. Skopiuj te szczegóły. Są przydatne do konfigurowania agenta we Flume.

Uruchamiam HDFS
Ponieważ przechowujemy dane w HDFS, musimy zainstalować / zweryfikować Hadoop. Uruchom Hadoop i utwórz w nim folder do przechowywania danych Flume. Przed skonfigurowaniem Flume wykonaj kroki podane poniżej.
Krok 1: Zainstaluj / zweryfikuj Hadoop
Zainstaluj Hadoop . Jeśli usługa Hadoop jest już zainstalowana w systemie, sprawdź instalację za pomocą polecenia wersji Hadoop, jak pokazano poniżej.
$ hadoop versionJeśli twój system zawiera Hadoop i jeśli ustawiłeś zmienną path, otrzymasz następujące dane wyjściowe -
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r
e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jarKrok 2: Uruchamianie Hadoop
Przejrzyj sbin katalogu Hadoop i uruchom Yarn i Hadoop dfs (rozproszony system plików), jak pokazano poniżej.
cd /$Hadoop_Home/sbin/
$ start-dfs.sh
localhost: starting namenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-namenode-localhost.localdomain.out
localhost: starting datanode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-datanode-localhost.localdomain.out
Starting secondary namenodes [0.0.0.0]
starting secondarynamenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-secondarynamenode-localhost.localdomain.out
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-resourcemanager-localhost.localdomain.out
localhost: starting nodemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-nodemanager-localhost.localdomain.outKrok 3: Utwórz katalog w HDFS
W Hadoop DFS można tworzyć katalogi za pomocą polecenia mkdir. Przejrzyj go i utwórz katalog o nazwietwitter_data w wymaganej ścieżce, jak pokazano poniżej.
$cd /$Hadoop_Home/bin/
$ hdfs dfs -mkdir hdfs://localhost:9000/user/Hadoop/twitter_dataKonfiguracja Flume
Musimy skonfigurować źródło, kanał i ujście za pomocą pliku konfiguracyjnego w confteczka. Przykład podany w tym rozdziale wykorzystuje eksperymentalne źródło dostarczone przez Apache Flume o nazwieTwitter 1% Firehose Kanał pamięci i ujście HDFS.
Twitter 1% Źródło Firehose
To źródło jest wysoce eksperymentalne. Łączy się z 1% próbką Twitter Firehose za pomocą interfejsu API przesyłania strumieniowego i stale pobiera tweety, konwertuje je do formatu Avro i wysyła zdarzenia Avro do podrzędnego ujścia Flume.
Źródło to otrzymamy domyślnie wraz z instalacją Flume. Plikjar pliki odpowiadające temu źródłu mogą znajdować się w lib folder, jak pokazano poniżej.

Ustawianie ścieżki klas
Ustaw classpath zmienna na lib folder Flume w formacie Flume-env.sh plik, jak pokazano poniżej.
export CLASSPATH=$CLASSPATH:/FLUME_HOME/lib/*To źródło wymaga szczegółów, takich jak Consumer key, Consumer secret, Access token, i Access token secretaplikacji na Twitterze. Konfigurując to źródło, musisz podać wartości do następujących właściwości -
Channels
Source type : org.apache.flume.source.twitter.TwitterSource
consumerKey - Klucz klienta OAuth
consumerSecret - Tajny klucz klienta OAuth
accessToken - Token dostępu OAuth
accessTokenSecret - Tajny klucz OAuth
maxBatchSize- Maksymalna liczba wiadomości na Twitterze, które powinny znajdować się w paczce na Twitterze. Wartość domyślna to 1000 (opcjonalnie).
maxBatchDurationMillis- Maksymalna liczba milisekund oczekiwania przed zamknięciem partii. Wartość domyślna to 1000 (opcjonalnie).
Kanał
Używamy kanału pamięci. Aby skonfigurować kanał pamięci, musisz podać wartość dla typu kanału.
type- Przechowuje typ kanału. W naszym przykładzie typ toMemChannel.
Capacity- Jest to maksymalna liczba zdarzeń przechowywanych w kanale. Jego domyślna wartość to 100 (opcjonalnie).
TransactionCapacity- Jest to maksymalna liczba zdarzeń, które kanał akceptuje lub wysyła. Jego domyślna wartość to 100 (opcjonalnie).
Zlew HDFS
To ujście zapisuje dane w HDFS. Aby skonfigurować ten ujście, musisz podać następujące szczegóły.
Channel
type - hdfs
hdfs.path - ścieżka do katalogu w HDFS, w którym mają być przechowywane dane.
Na podstawie scenariusza możemy podać kilka opcjonalnych wartości. Poniżej podano opcjonalne właściwości ujścia HDFS, które konfigurujemy w naszej aplikacji.
fileType - To jest wymagany format naszego pliku HDFS. SequenceFile, DataStream i CompressedStreamsą trzy typy dostępne w tym strumieniu. W naszym przykładzie używamyDataStream.
writeFormat - Może być tekstem lub zapisywalnym.
batchSize- Jest to liczba zdarzeń zapisanych w pliku przed umieszczeniem go w HDFS. Jego domyślna wartość to 100.
rollsize- Jest to rozmiar pliku wyzwalający przewijanie. Wartość domyślna to 100.
rollCount- Jest to liczba zdarzeń zapisanych w pliku przed jego przewinięciem. Jego domyślna wartość to 10.
Przykład - plik konfiguracyjny
Poniżej podano przykład pliku konfiguracyjnego. Skopiuj tę zawartość i zapisz jakotwitter.conf w folderze conf Flume.
# Naming the components on the current agent.
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFS
# Describing/Configuring the source
TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource
TwitterAgent.sources.Twitter.consumerKey = Your OAuth consumer key
TwitterAgent.sources.Twitter.consumerSecret = Your OAuth consumer secret
TwitterAgent.sources.Twitter.accessToken = Your OAuth consumer key access token
TwitterAgent.sources.Twitter.accessTokenSecret = Your OAuth consumer key access token secret
TwitterAgent.sources.Twitter.keywords = tutorials point,java, bigdata, mapreduce, mahout, hbase, nosql
# Describing/Configuring the sink
TwitterAgent.sinks.HDFS.type = hdfs
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/twitter_data/
TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream
TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text
TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000
TwitterAgent.sinks.HDFS.hdfs.rollSize = 0
TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000
# Describing/Configuring the channel
TwitterAgent.channels.MemChannel.type = memory
TwitterAgent.channels.MemChannel.capacity = 10000
TwitterAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channel = MemChannelWykonanie
Przejrzyj katalog domowy Flume i uruchom aplikację, jak pokazano poniżej.
$ cd $FLUME_HOME
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf
Dflume.root.logger=DEBUG,console -n TwitterAgentJeśli wszystko pójdzie dobrze, rozpocznie się przesyłanie strumieniowe tweetów do HDFS. Poniżej podano migawkę okna wiersza polecenia podczas pobierania tweetów.
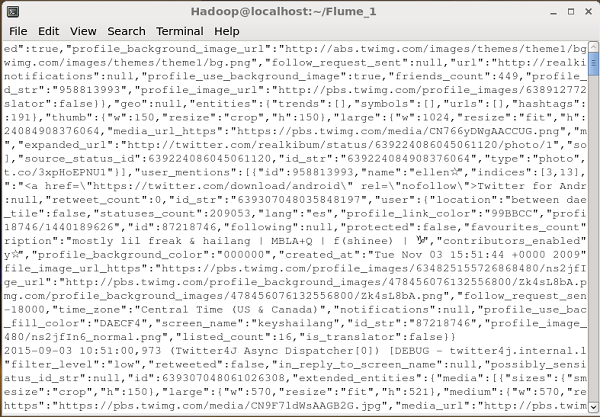
Weryfikacja HDFS
Dostęp do interfejsu administracyjnego sieci Web Hadoop można uzyskać, korzystając z adresu URL podanego poniżej.
http://localhost:50070/Kliknij listę rozwijaną o nazwie Utilitiesw prawej części strony. Możesz zobaczyć dwie opcje, jak pokazano na migawce podanej poniżej.
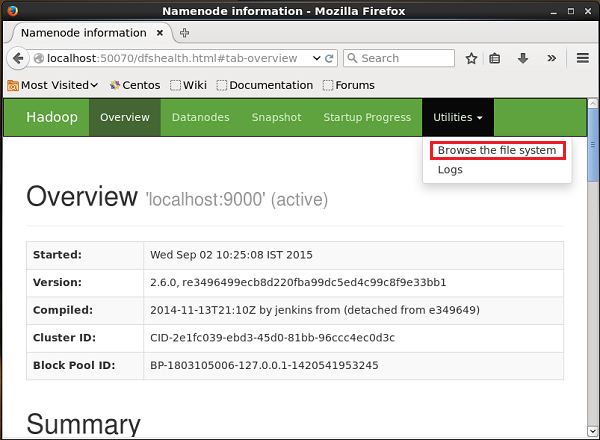
Kliknij Browse the file systemi wprowadź ścieżkę do katalogu HDFS, w którym zapisałeś tweety. W naszym przykładzie ścieżka będzie/user/Hadoop/twitter_data/. Następnie możesz zobaczyć listę plików dziennika Twittera przechowywanych w HDFS, jak podano poniżej.
