Apache Storm - podstawowe pojęcia
Apache Storm odczytuje nieprzetworzony strumień danych w czasie rzeczywistym z jednego końca i przekazuje go przez sekwencję małych jednostek przetwarzania, a na drugim końcu wysyła przetworzone / przydatne informacje.
Poniższy diagram przedstawia podstawową koncepcję Apache Storm.

Przyjrzyjmy się teraz bliżej składnikom Apache Storm -
| składniki | Opis |
|---|---|
| Tuple | Krotka to główna struktura danych w Storm. Jest to lista uporządkowanych elementów. Domyślnie krotka obsługuje wszystkie typy danych. Ogólnie jest modelowany jako zestaw wartości oddzielonych przecinkami i przekazywany do klastra Storm. |
| Strumień | Strumień to nieuporządkowana sekwencja krotek. |
| Wylewki | Źródło strumienia. Ogólnie Storm akceptuje dane wejściowe z surowych źródeł danych, takich jak Twitter Streaming API, kolejka Apache Kafka, kolejka Kestrel itp. W przeciwnym razie możesz pisać spoty, aby odczytywać dane ze źródeł danych. „ISpout” to podstawowy interfejs do implementowania spoutów. Niektóre z konkretnych interfejsów to IRichSpout, BaseRichSpout, KafkaSpout itp. |
| Śruby | Śruby to logiczne jednostki przetwarzające. Wylewki przekazują dane do śrub, a śruby przetwarzają i wytwarzają nowy strumień wyjściowy. Bolts może wykonywać operacje filtrowania, agregacji, łączenia, interakcji ze źródłami danych i bazami danych. Bolt odbiera dane i wysyła je do jednej lub kilku śrub. „IBolt” jest głównym interfejsem do implementacji śrub. Niektóre z popularnych interfejsów to IRichBolt, IBasicBolt itp. |
Weźmy przykład „analizy Twittera” w czasie rzeczywistym i zobaczmy, jak można go modelować w Apache Storm. Poniższy diagram przedstawia strukturę.

Dane wejściowe do „analizy Twittera” pochodzą z Twitter Streaming API. Spout odczyta tweety użytkowników korzystających z Twitter Streaming API i wyprowadzi jako strumień krotek. Pojedyncza krotka z wylewki będzie miała nazwę użytkownika Twittera i pojedynczy tweet jako wartości oddzielone przecinkami. Następnie ta para krotek zostanie przesłana do Bolta, a Bolt podzieli tweet na poszczególne słowa, obliczy liczbę słów i utrwali informacje w skonfigurowanym źródle danych. Teraz możemy łatwo uzyskać wynik, wysyłając zapytanie do źródła danych.
Topologia
Rzygacze i śruby są ze sobą połączone i tworzą topologię. Logika aplikacji czasu rzeczywistego jest określona w topologii Storm. Mówiąc prościej, topologia to skierowany graf, w którym wierzchołki są obliczane, a krawędzie są strumieniem danych.
Prosta topologia zaczyna się od wylotów. Wylewka wysyła dane do jednej lub więcej śrub. Śruba reprezentuje węzeł w topologii, który ma najmniejszą logikę przetwarzania, a dane wyjściowe śruby mogą być wysyłane do innej śruby jako dane wejściowe.
Storm utrzymuje topologię zawsze działającą, dopóki nie zostanie usunięta. Głównym zadaniem Apache Storm jest uruchomienie topologii i uruchomienie dowolnej liczby topologii w danym czasie.
Zadania
Teraz masz podstawowe pojęcie o wylewkach i śrubach. Są najmniejszą jednostką logiczną topologii, a topologia jest budowana przy użyciu jednego wylewki i szeregu śrub. Powinny być wykonane poprawnie w określonej kolejności, aby topologia działała pomyślnie. Wykonanie każdego dziobka i śruby przez Storm nazywane jest „Zadaniami”. W prostych słowach zadanie polega na wykonaniu wylewki lub zasuwy. W danym momencie każdy dziobek i śruba mogą mieć wiele wystąpień działających w wielu oddzielnych gwintach.
Pracownicy
Topologia działa w sposób rozproszony na wielu węzłach roboczych. Storm równomiernie rozkłada zadania na wszystkie węzły robocze. Rolą węzła roboczego jest nasłuchiwanie zadań i uruchamianie lub zatrzymywanie procesów za każdym razem, gdy nadejdzie nowe zadanie.
Grupowanie strumieni
Strumień danych przepływa z wylewek do śrub lub od jednej śruby do drugiej. Grupowanie strumieni kontroluje sposób kierowania krotek w topologii i pomaga nam zrozumieć przepływ krotek w topologii. Istnieją cztery wbudowane grupy, jak wyjaśniono poniżej.
Shuffle Grouping
W przypadku grupowania losowego równa liczba krotek jest rozdzielana losowo na wszystkich pracowników wykonujących śruby. Poniższy diagram przedstawia strukturę.

Grupowanie pól
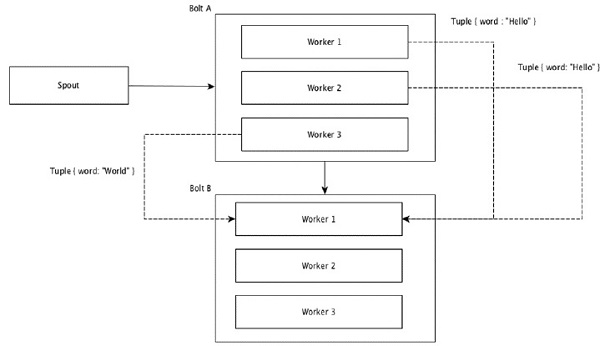
Pola z takimi samymi wartościami w krotkach są grupowane, a pozostałe krotki trzymane na zewnątrz. Następnie krotki z tymi samymi wartościami pól są przesyłane dalej do tego samego pracownika wykonującego śruby. Na przykład, jeśli strumień jest zgrupowany według pola „słowo”, to krotki z tym samym ciągiem „Hello” zostaną przeniesione do tego samego procesu roboczego. Poniższy diagram przedstawia sposób działania grupowania pól.

Grupowanie globalne
Wszystkie strumienie można grupować i przekazywać do jednej śruby. To grupowanie wysyła krotki wygenerowane przez wszystkie wystąpienia źródła do pojedynczej instancji docelowej (w szczególności wybierz proces roboczy o najniższym identyfikatorze).
Wszystkie grupowanie
All Grouping wysyła jedną kopię każdej krotki do wszystkich wystąpień śruby odbierającej. Ten rodzaj grupowania służy do wysyłania sygnałów do rygli. Całe grupowanie jest przydatne w operacjach łączenia.
