Apache Storm - szybki przewodnik
Co to jest Apache Storm?
Apache Storm to rozproszony system przetwarzania dużych zbiorów danych w czasie rzeczywistym. Storm jest zaprojektowany do przetwarzania ogromnych ilości danych w odpornej na błędy i poziomej skalowalnej metodzie. Jest to platforma przesyłania strumieniowego danych, która ma możliwość uzyskania najwyższych współczynników pozyskiwania. Chociaż Storm jest bezstanowy, zarządza środowiskiem rozproszonym i stanem klastra za pośrednictwem Apache ZooKeeper. Jest to proste i można równolegle wykonywać wszelkiego rodzaju manipulacje na danych w czasie rzeczywistym.
Apache Storm nadal jest liderem w dziedzinie analizy danych w czasie rzeczywistym. Storm jest łatwy w konfiguracji, obsłudze i gwarantuje, że każda wiadomość zostanie przynajmniej raz przetworzona w topologii.
Apache Storm vs Hadoop
Zasadniczo platformy Hadoop i Storm są używane do analizowania dużych zbiorów danych. Oba uzupełniają się i różnią w niektórych aspektach. Apache Storm wykonuje wszystkie operacje z wyjątkiem trwałości, podczas gdy Hadoop jest dobry we wszystkim, ale opóźnia się w obliczeniach w czasie rzeczywistym. W poniższej tabeli porównano atrybuty Storm i Hadoop.
| Burza | Hadoop |
|---|---|
| Przetwarzanie strumienia w czasie rzeczywistym | Przetwarzanie wsadowe |
| Bezpaństwowcy | Stanowy |
| Architektura Master / Slave z koordynacją opartą na ZooKeeper. Węzeł główny nosi nazwęnimbus i niewolnicy supervisors. | Architektura master-slave z / bez koordynacji opartej na ZooKeeper. Węzeł główny tojob tracker a węzeł slave to task tracker. |
| Proces przesyłania strumieniowego Storm może uzyskać dostęp do dziesiątek tysięcy wiadomości na sekundę w klastrze. | Rozproszony system plików Hadoop (HDFS) wykorzystuje strukturę MapReduce do przetwarzania ogromnych ilości danych, które zajmują minuty lub godziny. |
| Topologia Storm działa do momentu wyłączenia przez użytkownika lub nieoczekiwanej, nieodwracalnej awarii. | Zadania MapReduce są wykonywane w kolejności i ostatecznie kończone. |
| Both are distributed and fault-tolerant | |
| Jeśli nimbus / nadzorca umrze, ponowne uruchomienie sprawia, że będzie kontynuowane od miejsca, w którym zostało zatrzymane, więc nic nie zostanie naruszone. | Jeśli JobTracker umrze, wszystkie uruchomione zadania zostaną utracone. |
Przypadki użycia Apache Storm
Apache Storm jest bardzo znany z przetwarzania dużych strumieni danych w czasie rzeczywistym. Z tego powodu większość firm używa Storm jako integralnej części swojego systemu. Oto niektóre godne uwagi przykłady -
Twitter- Twitter korzysta z Apache Storm w zakresie „produktów Analytics dla wydawców”. „Produkty analityczne wydawcy” przetwarzają każdy tweet i kliknięcie na platformie Twitter. Apache Storm jest głęboko zintegrowany z infrastrukturą Twittera.
NaviSite- NaviSite używa Storm do monitorowania / audytu dzienników zdarzeń. Wszystkie dzienniki wygenerowane w systemie przejdą przez burzę. Storm porówna wiadomość ze skonfigurowanym zestawem wyrażeń regularnych i jeśli znajdzie dopasowanie, ta konkretna wiadomość zostanie zapisana w bazie danych.
Wego- Wego to wyszukiwarka metasearch zlokalizowana w Singapurze. Dane dotyczące podróży pochodzą z wielu źródeł na całym świecie w różnym czasie. Storm pomaga Wego przeszukiwać dane w czasie rzeczywistym, rozwiązuje problemy z współbieżnością i znajduje najlepsze dopasowanie dla użytkownika końcowego.
Korzyści Apache Storm
Oto lista korzyści, które oferuje Apache Storm -
Storm jest oprogramowaniem open source, solidnym i przyjaznym dla użytkownika. Może znaleźć zastosowanie zarówno w małych firmach, jak i dużych korporacjach.
Storm jest odporny na błędy, elastyczny, niezawodny i obsługuje każdy język programowania.
Umożliwia przetwarzanie strumieniowe w czasie rzeczywistym.
Storm jest niewiarygodnie szybki, ponieważ ma ogromną moc przetwarzania danych.
Storm może utrzymać wydajność nawet przy rosnącym obciążeniu, liniowo dodając zasoby. Jest wysoce skalowalny.
Storm przeprowadza odświeżanie danych i kompleksową odpowiedź w ciągu kilku sekund lub minut, w zależności od problemu. Ma bardzo małe opóźnienie.
Storm ma inteligencję operacyjną.
Storm zapewnia gwarantowane przetwarzanie danych, nawet jeśli którykolwiek z podłączonych węzłów w klastrze umrze lub wiadomości zostaną utracone.
Apache Storm odczytuje nieprzetworzony strumień danych w czasie rzeczywistym z jednego końca i przekazuje go przez sekwencję małych jednostek przetwarzania, a na drugim końcu wysyła przetworzone / przydatne informacje.
Poniższy diagram przedstawia podstawową koncepcję Apache Storm.

Przyjrzyjmy się teraz bliżej składnikom Apache Storm -
| składniki | Opis |
|---|---|
| Tuple | Krotka to główna struktura danych w Storm. Jest to lista uporządkowanych elementów. Domyślnie krotka obsługuje wszystkie typy danych. Ogólnie jest modelowany jako zestaw wartości oddzielonych przecinkami i przekazywany do klastra Storm. |
| Strumień | Strumień to nieuporządkowana sekwencja krotek. |
| Wylewki | Źródło strumienia. Ogólnie Storm akceptuje dane wejściowe z surowych źródeł danych, takich jak Twitter Streaming API, kolejka Apache Kafka, kolejka Kestrel itp. W przeciwnym razie możesz pisać spoty, aby odczytywać dane ze źródeł danych. „ISpout” to podstawowy interfejs do implementowania spoutów. Niektóre z konkretnych interfejsów to IRichSpout, BaseRichSpout, KafkaSpout itp. |
| Śruby | Śruby to logiczne jednostki przetwarzające. Wylewki przekazują dane do śrub, a śruby przetwarzają i wytwarzają nowy strumień wyjściowy. Bolts może wykonywać operacje filtrowania, agregacji, łączenia, interakcji ze źródłami danych i bazami danych. Bolt odbiera dane i wysyła je do jednej lub kilku śrub. „IBolt” jest głównym interfejsem do implementacji śrub. Niektóre z typowych interfejsów to IRichBolt, IBasicBolt itp. |
Weźmy przykład „analizy Twittera” w czasie rzeczywistym i zobaczmy, jak można go modelować w Apache Storm. Poniższy diagram przedstawia strukturę.

Dane wejściowe do „analizy Twittera” pochodzą z Twitter Streaming API. Spout odczyta tweety użytkowników korzystających z Twitter Streaming API i wyprowadzi jako strumień krotek. Pojedyncza krotka z wylewki będzie miała nazwę użytkownika Twittera i pojedynczy tweet jako wartości oddzielone przecinkami. Następnie ta para krotek zostanie przesłana do Bolta, a Bolt podzieli tweet na poszczególne słowa, obliczy liczbę słów i utrwali informacje w skonfigurowanym źródle danych. Teraz możemy łatwo uzyskać wynik, wysyłając zapytanie do źródła danych.
Topologia
Rzygacze i śruby są ze sobą połączone i tworzą topologię. Logika aplikacji czasu rzeczywistego jest określona w topologii Storm. Mówiąc prościej, topologia to skierowany graf, w którym wierzchołki są obliczane, a krawędzie są strumieniem danych.
Prosta topologia zaczyna się od wylotów. Wylewka wysyła dane do jednej lub więcej śrub. Śruba reprezentuje węzeł w topologii, który ma najmniejszą logikę przetwarzania, a dane wyjściowe śruby mogą być wysyłane do innej śruby jako dane wejściowe.
Storm utrzymuje topologię zawsze działającą, dopóki nie zostanie usunięta. Głównym zadaniem Apache Storm jest uruchomienie topologii i uruchomienie dowolnej liczby topologii w danym czasie.
Zadania
Teraz masz podstawowe pojęcie o wylewkach i śrubach. Są najmniejszą jednostką logiczną topologii, a topologia jest budowana przy użyciu jednego wylewki i szeregu śrub. Powinny być wykonane poprawnie w określonej kolejności, aby topologia działała pomyślnie. Wykonanie każdego dziobka i śruby przez Storm nazywane jest „Zadaniami”. W prostych słowach zadanie polega na wykonaniu wylewki lub zasuwy. W danym momencie każdy dziobek i śruba mogą mieć wiele wystąpień działających w wielu oddzielnych gwintach.
Pracownicy
Topologia działa w sposób rozproszony na wielu węzłach roboczych. Storm równomiernie rozkłada zadania na wszystkie węzły robocze. Rolą węzła roboczego jest nasłuchiwanie zadań i uruchamianie lub zatrzymywanie procesów za każdym razem, gdy nadejdzie nowe zadanie.
Grupowanie strumieni
Strumień danych przepływa z wylewek do śrub lub od jednej śruby do drugiej. Grupowanie strumieni kontroluje sposób kierowania krotek w topologii i pomaga nam zrozumieć przepływ krotek w topologii. Istnieją cztery wbudowane grupy, jak wyjaśniono poniżej.
Shuffle Grouping
W przypadku grupowania losowego równa liczba krotek jest rozdzielana losowo na wszystkich pracowników wykonujących śruby. Poniższy diagram przedstawia strukturę.

Grupowanie pól
Pola z takimi samymi wartościami w krotkach są grupowane, a pozostałe krotki trzymane na zewnątrz. Następnie krotki z tymi samymi wartościami pól są przesyłane dalej do tego samego pracownika wykonującego śruby. Na przykład, jeśli strumień jest zgrupowany według pola „słowo”, to krotki z tym samym ciągiem „Hello” zostaną przeniesione do tego samego procesu roboczego. Poniższy diagram przedstawia sposób działania grupowania pól.

Grupowanie globalne
Wszystkie strumienie można grupować i przekazywać do jednej śruby. To grupowanie wysyła krotki wygenerowane przez wszystkie wystąpienia źródła do pojedynczej instancji docelowej (w szczególności wybierz proces roboczy o najniższym identyfikatorze).
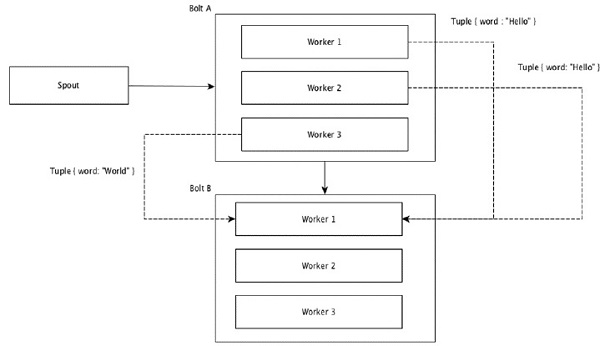
Wszystkie grupowanie
All Grouping wysyła jedną kopię każdej krotki do wszystkich wystąpień śruby odbierającej. Ten rodzaj grupowania służy do wysyłania sygnałów do rygli. Całe grupowanie jest przydatne w operacjach łączenia.

Jedną z głównych zalet Apache Storm jest to, że jest to odporna na błędy, szybka i pozbawiona rozproszonych aplikacji typu „Single Point of Failure” (SPOF). Możemy zainstalować Apache Storm w tylu systemach, ile potrzeba, aby zwiększyć pojemność aplikacji.
Przyjrzyjmy się, jak został zaprojektowany klaster Apache Storm i jego wewnętrzna architektura. Poniższy diagram przedstawia projekt klastra.

Apache Storm ma dwa typy węzłów, Nimbus (węzeł główny) i Supervisor(węzeł roboczy). Nimbus to centralny składnik Apache Storm. Głównym zadaniem Nimbusa jest uruchomienie topologii Storm. Nimbus analizuje topologię i zbiera zadanie do wykonania. Następnie przydzieli zadanie do dostępnego przełożonego.
Przełożony będzie miał jeden lub więcej procesów roboczych. Przełożony przekaże zadania do procesów roboczych. Proces roboczy utworzy tyle programów wykonawczych, ile potrzeba, i uruchomi zadanie. Apache Storm wykorzystuje wewnętrzny rozproszony system przesyłania wiadomości do komunikacji między nimbusem a przełożonymi.
| składniki | Opis |
|---|---|
| Chmura | Nimbus to główny węzeł klastra Storm. Wszystkie inne węzły w klastrze nazywane są jakoworker nodes. Węzeł główny jest odpowiedzialny za dystrybucję danych do wszystkich węzłów roboczych, przydzielanie zadań do węzłów roboczych i monitorowanie awarii. |
| Kierownik | Węzły, które wykonują instrukcje podane przez nimbus, nazywane są nadzorcami. ZAsupervisor ma wiele procesów roboczych i zarządza procesami roboczymi w celu wykonania zadań przypisanych przez nimbus. |
| Proces roboczy | Proces roboczy będzie wykonywał zadania związane z określoną topologią. Proces roboczy nie uruchomi zadania samodzielnie, ale je utworzyexecutorsi prosi ich o wykonanie określonego zadania. Proces roboczy będzie miał wielu wykonawców. |
| Wykonawca | Executor to nic innego jak pojedynczy wątek spawnowany przez proces roboczy. Wykonawca uruchamia jedno lub więcej zadań, ale tylko dla określonej wylewki lub śruby. |
| Zadanie | Zadanie wykonuje faktyczne przetwarzanie danych. Jest to więc wylewka lub śruba. |
| Framework ZooKeeper | Apache ZooKeeper to usługa używana przez klaster (grupę węzłów) do koordynowania między sobą i utrzymywania współdzielonych danych za pomocą zaawansowanych technik synchronizacji. Nimbus jest bezstanowy, więc monitorowanie stanu węzła roboczego zależy od ZooKeepera. ZooKeeper pomaga przełożonemu w interakcji z nimbem. Jest odpowiedzialny za utrzymywanie stanu nimbusa i nadzorcy. |
Storm ma charakter bezpaństwowy. Mimo że bezstanowa natura ma swoje wady, w rzeczywistości pomaga Storm przetwarzać dane w czasie rzeczywistym w najlepszy możliwy i najszybszy sposób.
Storm nie jest jednak całkowicie bezpaństwowy. Przechowuje swój stan w Apache ZooKeeper. Ponieważ stan jest dostępny w Apache ZooKeeper, uszkodzony nimbus można uruchomić ponownie i rozpocząć pracę od miejsca, w którym został. Zwykle narzędzia do monitorowania usług, takie jakmonit będzie monitorować Nimbus i ponownie go uruchamiać, jeśli wystąpi jakakolwiek awaria.
Apache Storm ma również zaawansowaną topologię o nazwie Trident Topologyz utrzymaniem stanu, a także zapewnia interfejs API wysokiego poziomu, taki jak Pig. Omówimy wszystkie te funkcje w następnych rozdziałach.
Działający klaster Storm powinien mieć jeden nimbus i co najmniej jednego nadzorcę. Innym ważnym węzłem jest Apache ZooKeeper, który będzie używany do koordynacji między nimbusem a nadzorcami.
Przyjrzyjmy się teraz bliżej przepływowi pracy Apache Storm -
Początkowo nimbus będzie czekał na przesłanie do niego „Topologii burzy”.
Po przesłaniu topologii, przetwarza topologię i zbiera wszystkie zadania, które mają być wykonane, oraz kolejność, w jakiej zadanie ma zostać wykonane.
Następnie nimbus równomiernie rozdzieli zadania między wszystkich dostępnych przełożonych.
W określonym przedziale czasu wszyscy nadzorcy będą wysyłali bicie serca do nimbusa, aby poinformować, że nadal żyją.
Kiedy przełożony umiera i nie wysyła bicia serca do nimbu, wtedy nimbus przydziela zadania innemu nadzorcy.
Kiedy sam nimb umrze, przełożeni będą bez problemu pracować nad już przydzielonym zadaniem.
Po wykonaniu wszystkich zadań przełożony będzie czekał na nadejście nowego zadania.
W międzyczasie martwy nimbus zostanie automatycznie ponownie uruchomiony przez narzędzia do monitorowania usług.
Zrestartowany nimb będzie kontynuowany od miejsca, w którym został zatrzymany. Podobnie martwego nadzorcy można również uruchomić ponownie automatycznie. Ponieważ zarówno nimbus, jak i nadzorca mogą zostać ponownie uruchomione automatycznie i oba będą kontynuowane jak poprzednio, Storm ma gwarancję, że przetworzy całe zadanie przynajmniej raz.
Po przetworzeniu wszystkich topologii nimbus czeka na nadejście nowej topologii i podobnie nadzorca czeka na nowe zadania.
Domyślnie w klastrze Storm są dwa tryby -
Local mode- Ten tryb jest używany do programowania, testowania i debugowania, ponieważ jest to najłatwiejszy sposób, aby zobaczyć wszystkie komponenty topologii współpracujące. W tym trybie możemy dostosować parametry, które pozwolą nam zobaczyć, jak nasza topologia działa w różnych środowiskach konfiguracyjnych Storm. W trybie lokalnym topologie burzy działają na komputerze lokalnym w jednej maszynie JVM.
Production mode- W tym trybie przekazujemy naszą topologię do działającego klastra burzowego, który składa się z wielu procesów, zwykle działających na różnych maszynach. Jak omówiono w przepływie pracy burzy, działający klaster będzie działał przez czas nieokreślony, dopóki nie zostanie zamknięty.
Apache Storm przetwarza dane w czasie rzeczywistym, a dane wejściowe zwykle pochodzą z systemu kolejkowania wiadomości. Zewnętrzny rozproszony system przesyłania wiadomości zapewni dane wejściowe niezbędne do obliczeń w czasie rzeczywistym. Spout odczyta dane z systemu przesyłania wiadomości i przekształci je w krotki i wprowadzi do Apache Storm. Ciekawostką jest to, że Apache Storm wykorzystuje swój własny rozproszony system przesyłania wiadomości wewnętrznie do komunikacji między nimbusem a przełożonym.
Co to jest rozproszony system przesyłania wiadomości?
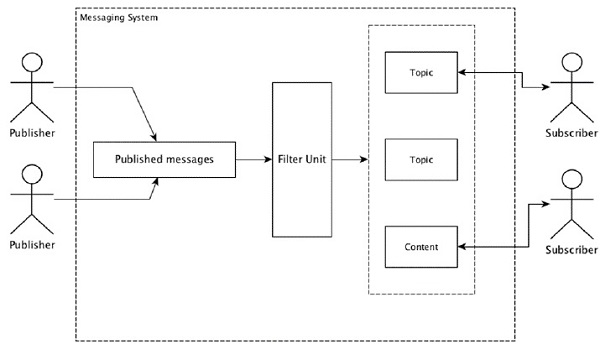
Rozproszone przesyłanie wiadomości opiera się na koncepcji niezawodnego kolejkowania wiadomości. Wiadomości są kolejkowane asynchronicznie między aplikacjami klienckimi a systemami przesyłania wiadomości. Rozproszony system obsługi wiadomości zapewnia korzyści w postaci niezawodności, skalowalności i trwałości.
Większość wzorców przesyłania wiadomości jest zgodna z publish-subscribe model (po prostu Pub-Sub), gdzie są wywoływani nadawcy wiadomości publishers i ci, którzy chcą otrzymywać orędzia, są wezwani subscribers.
Po opublikowaniu wiadomości przez nadawcę abonenci mogą odebrać wybraną wiadomość za pomocą opcji filtrowania. Zwykle mamy dwa rodzaje filtrowania, jeden totopic-based filtering a inny jest content-based filtering.
Należy pamiętać, że model pub-sub może komunikować się tylko za pośrednictwem wiadomości. Jest to bardzo luźno związana architektura; nawet nadawcy nie wiedzą, kim są ich subskrybenci. Wiele wzorców komunikatów umożliwia brokerowi komunikatów wymianę komunikatów publikowania w celu uzyskania szybkiego dostępu dla wielu subskrybentów. Przykładem z życia jest Dish TV, które publikuje różne kanały, takie jak sport, filmy, muzyka itp., A każdy może subskrybować własny zestaw kanałów i pobierać je, gdy tylko dostępne są jego kanały.
W poniższej tabeli opisano niektóre popularne systemy przesyłania wiadomości o dużej przepustowości -
| Rozproszony system przesyłania wiadomości | Opis |
|---|---|
| Apache Kafka | Kafka powstał w korporacji LinkedIn, a później stał się podprojektem Apache. Apache Kafka jest oparty na trwałym, rozproszonym modelu publikowania i subskrybowania, z obsługą brokera. Kafka jest szybka, skalowalna i bardzo wydajna. |
| RabbitMQ | RabbitMQ to niezawodna, rozproszona aplikacja do przesyłania wiadomości typu open source. Jest łatwy w użyciu i działa na wszystkich platformach. |
| JMS (Java Message Service) | JMS to interfejs API typu open source, który obsługuje tworzenie, odczytywanie i wysyłanie wiadomości z jednej aplikacji do drugiej. Zapewnia gwarantowane dostarczanie wiadomości i jest zgodny z modelem publikowania i subskrybowania. |
| ActiveMQ | System przesyłania wiadomości ActiveMQ jest interfejsem API typu open source dla JMS. |
| ZeroMQ | ZeroMQ to przetwarzanie komunikatów peer-peer bez brokera. Zapewnia wzorce komunikatów typu push-pull, router-dealer. |
| Pustułka | Kestrel to szybka, niezawodna i prosta rozproszona kolejka komunikatów. |
Protokół oszczędności
Thrift został stworzony na Facebooku w celu rozwoju usług międzyjęzykowych i zdalnego wywoływania procedur (RPC). Później stał się projektem Open Source Apache. Apache Thrift toInterface Definition Language i pozwala w łatwy sposób definiować nowe typy danych i wdrażanie usług na podstawie zdefiniowanych typów danych.
Apache Thrift to także platforma komunikacyjna obsługująca systemy wbudowane, aplikacje mobilne, aplikacje internetowe i wiele innych języków programowania. Niektóre z kluczowych funkcji związanych z Apache Thrift to jego modułowość, elastyczność i wysoka wydajność. Ponadto umożliwia przesyłanie strumieniowe, przesyłanie wiadomości i RPC w aplikacjach rozproszonych.
Storm intensywnie używa protokołu Thrift do wewnętrznej komunikacji i definiowania danych. Topologia burzy jest prostaThrift Structs. Storm Nimbus obsługujący topologię w Apache Storm to plikThrift service.
Zobaczmy teraz, jak zainstalować framework Apache Storm na twoim komputerze. Tutaj są trzy główne kroki -
- Zainstaluj Javę w swoim systemie, jeśli jeszcze jej nie masz.
- Zainstaluj framework ZooKeeper.
- Zainstaluj framework Apache Storm.
Krok 1 - weryfikacja instalacji Java
Użyj następującego polecenia, aby sprawdzić, czy w systemie jest już zainstalowana Java.
$ java -versionJeśli Java już tam jest, zobaczysz jej numer wersji. W przeciwnym razie pobierz najnowszą wersję JDK.
Krok 1.1 - Pobierz JDK
Pobierz najnowszą wersję JDK, korzystając z następującego łącza - www.oracle.com
Najnowsza wersja to JDK 8u 60, a plik to “jdk-8u60-linux-x64.tar.gz”. Pobierz plik na swój komputer.
Krok 1.2 - Rozpakuj pliki
Zwykle pliki są pobierane do downloadsteczka. Wyodrębnij ustawienia tar za pomocą następujących poleceń.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzKrok 1.3 - Przejdź do katalogu opt
Aby udostępnić środowisko Java wszystkim użytkownikom, przenieś wyodrębnioną zawartość Java do folderu „/ usr / local / java”.
$ su
password: (type password of root user)
$ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/Krok 1.4 - Ustaw ścieżkę
Aby ustawić ścieżkę i zmienne JAVA_HOME, dodaj następujące polecenia do pliku ~ / .bashrc.
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binTeraz zastosuj wszystkie zmiany w aktualnie działającym systemie.
$ source ~/.bashrcKrok 1.5 - Alternatywy dla języka Java
Użyj następującego polecenia, aby zmienić alternatywy Java.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100Krok 1.6
Teraz zweryfikuj instalację Java za pomocą polecenia weryfikacji (java -version) wyjaśnione w kroku 1.
Krok 2 - Instalacja oprogramowania ZooKeeper Framework
Krok 2.1 - Pobierz ZooKeeper
Aby zainstalować środowisko ZooKeeper na swoim komputerze, kliknij poniższe łącze i pobierz najnowszą wersję ZooKeeper http://zookeeper.apache.org/releases.html
W chwili obecnej najnowsza wersja ZooKeeper to 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Krok 2.2 - Wypakuj plik tar
Wyodrębnij plik tar, używając następujących poleceń -
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6
$ mkdir dataKrok 2.3 - Utwórz plik konfiguracyjny
Otwórz plik konfiguracyjny o nazwie „conf / zoo.cfg”, używając polecenia „vi conf / zoo.cfg” i ustawiając wszystkie poniższe parametry jako punkt początkowy.
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2Po pomyślnym zapisaniu pliku konfiguracyjnego możesz uruchomić serwer ZooKeeper.
Krok 2.4 - Uruchom serwer ZooKeeper
Użyj następującego polecenia, aby uruchomić serwer ZooKeeper.
$ bin/zkServer.sh startPo wykonaniu tego polecenia otrzymasz następującą odpowiedź -
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTEDKrok 2.5 - Uruchom CLI
Użyj następującego polecenia, aby uruchomić CLI.
$ bin/zkCli.shPo wykonaniu powyższego polecenia zostaniesz połączony z serwerem ZooKeeper i otrzymasz następującą odpowiedź.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]Krok 2.6 - Zatrzymaj serwer ZooKeeper
Po podłączeniu serwera i wykonaniu wszystkich operacji możesz zatrzymać serwer ZooKeeper za pomocą następującego polecenia.
bin/zkServer.sh stopPomyślnie zainstalowałeś Javę i ZooKeepera na swoim komputerze. Zobaczmy teraz, jak zainstalować framework Apache Storm.
Krok 3 - Instalacja Apache Storm Framework
Krok 3.1 Pobierz Storm
Aby zainstalować platformę Storm na swoim komputerze, odwiedź poniższy link i pobierz najnowszą wersję Storm http://storm.apache.org/downloads.html
Obecnie najnowszą wersją Storm jest „apache-storm-0.9.5.tar.gz”.
Krok 3.2 - Wypakuj plik tar
Wyodrębnij plik tar, używając następujących poleceń -
$ cd opt/
$ tar -zxf apache-storm-0.9.5.tar.gz $ cd apache-storm-0.9.5
$ mkdir dataKrok 3.3 - Otwórz plik konfiguracyjny
Bieżąca wersja Storm zawiera plik w „conf / storm.yaml”, który konfiguruje demony Storm. Dodaj następujące informacje do tego pliku.
$ vi conf/storm.yaml
storm.zookeeper.servers:
- "localhost"
storm.local.dir: “/path/to/storm/data(any path)”
nimbus.host: "localhost"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703Po zastosowaniu wszystkich zmian zapisz i wróć do terminala.
Krok 3.4 - Uruchom Nimbus
$ bin/storm nimbusKrok 3.5 - Uruchom Supervisora
$ bin/storm supervisorKrok 3.6 Uruchom interfejs użytkownika
$ bin/storm uiPo uruchomieniu aplikacji interfejsu użytkownika Storm wpisz adres URL http://localhost:8080w ulubionej przeglądarce i możesz zobaczyć informacje o klastrze Storm i jego działającą topologię. Strona powinna wyglądać podobnie do poniższego zrzutu ekranu.

Zapoznaliśmy się z podstawowymi szczegółami technicznymi Apache Storm, a teraz nadszedł czas, aby zakodować kilka prostych scenariuszy.
Scenariusz - mobilny analizator dziennika połączeń
Połączenie mobilne i czas jego trwania zostaną podane jako dane wejściowe do Apache Storm, a Storm przetworzy i pogrupuje połączenie między tego samego dzwoniącego i odbierającego oraz ich całkowitą liczbę połączeń.
Tworzenie wylewki
Wylewka to element służący do generowania danych. Zasadniczo wylewka będzie implementowała interfejs IRichSpout. Interfejs „IRichSpout” ma następujące ważne metody -
open- Zapewnia wylewce środowisko do wykonania. Wykonawcy uruchomią tę metodę w celu zainicjowania wylewki.
nextTuple - Emituje wygenerowane dane za pośrednictwem kolektora.
close - Ta metoda jest wywoływana, gdy wylewka będzie się wyłączać.
declareOutputFields - Deklaruje schemat wyjściowy krotki.
ack - potwierdza, że przetwarzana jest konkretna krotka
fail - określa, że określona krotka nie jest przetwarzana i nie ma być ponownie przetwarzana.
otwarty
Podpis open metoda jest następująca -
open(Map conf, TopologyContext context, SpoutOutputCollector collector)conf - Zapewnia konfigurację burzową dla tej wylewki.
context - Zapewnia pełne informacje o miejscu wylewki w topologii, jego identyfikatorze zadania, danych wejściowych i wyjściowych.
collector - Umożliwia nam emitowanie krotki, która będzie przetwarzana przez śruby.
nextTuple
Podpis nextTuple metoda jest następująca -
nextTuple()nextTuple () jest wywoływana okresowo z tej samej pętli, co metody ACK () i Fail (). Musi zwolnić kontrolę nad wątkiem, gdy nie ma pracy do wykonania, aby inne metody miały szansę zostać wywołane. Zatem pierwsza linia nextTuple sprawdza, czy przetwarzanie zostało zakończone. Jeśli tak, powinien spać przez co najmniej jedną milisekundę, aby zmniejszyć obciążenie procesora przed powrotem.
blisko
Podpis close metoda jest następująca -
close()deklarujOutputFields
Podpis declareOutputFields metoda jest następująca -
declareOutputFields(OutputFieldsDeclarer declarer)declarer - Służy do deklarowania identyfikatorów strumieni wyjściowych, pól wyjściowych itp.
Ta metoda służy do określania schematu wyjściowego spójnej kolekcji.
ACK
Podpis ack metoda jest następująca -
ack(Object msgId)Ta metoda potwierdza, że została przetworzona konkretna krotka.
zawieść
Podpis nextTuple metoda jest następująca -
ack(Object msgId)Ta metoda informuje, że określona krotka nie została w pełni przetworzona. Storm ponownie przetworzy określoną krotkę.
FakeCallLogReaderSpout
W naszym scenariuszu musimy zebrać szczegóły rejestru połączeń. Zawiera informacje z rejestru połączeń.
- numer dzwoniącego
- numer odbiorcy
- duration
Ponieważ nie mamy informacji o dziennikach połączeń w czasie rzeczywistym, będziemy generować fałszywe dzienniki połączeń. Fałszywe informacje zostaną utworzone za pomocą klasy Random. Pełny kod programu znajduje się poniżej.
Kodowanie - FakeCallLogReaderSpout.java
import java.util.*;
//import storm tuple packages
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import Spout interface packages
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
//Create a class FakeLogReaderSpout which implement IRichSpout interface
to access functionalities
public class FakeCallLogReaderSpout implements IRichSpout {
//Create instance for SpoutOutputCollector which passes tuples to bolt.
private SpoutOutputCollector collector;
private boolean completed = false;
//Create instance for TopologyContext which contains topology data.
private TopologyContext context;
//Create instance for Random class.
private Random randomGenerator = new Random();
private Integer idx = 0;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
if(this.idx <= 1000) {
List<String> mobileNumbers = new ArrayList<String>();
mobileNumbers.add("1234123401");
mobileNumbers.add("1234123402");
mobileNumbers.add("1234123403");
mobileNumbers.add("1234123404");
Integer localIdx = 0;
while(localIdx++ < 100 && this.idx++ < 1000) {
String fromMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
String toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
while(fromMobileNumber == toMobileNumber) {
toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
}
Integer duration = randomGenerator.nextInt(60);
this.collector.emit(new Values(fromMobileNumber, toMobileNumber, duration));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("from", "to", "duration"));
}
//Override all the interface methods
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Tworzenie śrub
Bolt to komponent, który pobiera krotki jako dane wejściowe, przetwarza krotkę i generuje nowe krotki jako dane wyjściowe. Śruby będą realizowaćIRichBoltberło. W tym programie dwie klasy śrubCallLogCreatorBolt i CallLogCounterBolt służą do wykonywania operacji.
Interfejs IRichBolt ma następujące metody -
prepare- Zapewnia śrubie środowisko do wykonania. Wykonawcy uruchomią tę metodę w celu zainicjowania wylewki.
execute - Przetwarzaj pojedynczą krotkę danych wejściowych.
cleanup - Wezwany, gdy śruba się wyłączy.
declareOutputFields - Deklaruje schemat wyjściowy krotki.
Przygotować
Podpis prepare metoda jest następująca -
prepare(Map conf, TopologyContext context, OutputCollector collector)conf - Zapewnia konfigurację burzy dla tej śruby.
context - Zapewnia pełne informacje o położeniu śruby w topologii, identyfikatorze zadania, danych wejściowych i wyjściowych itp.
collector - Umożliwia nam emitowanie przetworzonej krotki.
wykonać
Podpis execute metoda jest następująca -
execute(Tuple tuple)Tutaj tuple jest krotką wejściową do przetworzenia.
Plik executemetoda przetwarza pojedynczą krotkę naraz. Dostęp do danych krotki można uzyskać za pomocą metody getValue klasy Tuple. Nie jest konieczne natychmiastowe przetwarzanie krotki wejściowej. Wiele krotek może być przetwarzanych i wyprowadzanych jako jedna krotka wyjściowa. Przetworzoną krotkę można wyemitować przy użyciu klasy OutputCollector.
sprzątać
Podpis cleanup metoda jest następująca -
cleanup()deklarujOutputFields
Podpis declareOutputFields metoda jest następująca -
declareOutputFields(OutputFieldsDeclarer declarer)Tutaj parametr declarer służy do deklarowania identyfikatorów strumieni wyjściowych, pól wyjściowych itp.
Ta metoda służy do określania schematu wyjściowego spójnej kolekcji
Twórca rejestru połączeń Bolt
Bolt kreatora rejestru połączeń odbiera krotkę rejestru połączeń. Krotka rejestru połączeń zawiera numer dzwoniącego, numer odbiorcy i czas trwania połączenia. Ta śruba po prostu tworzy nową wartość, łącząc numer dzwoniącego i numer odbiorcy. Format nowej wartości to „Numer dzwoniącego - Numer odbiorcy” i nazywa się ją nowym polem „Zadzwoń”. Pełny kod podano poniżej.
Kodowanie - CallLogCreatorBolt.java
//import util packages
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
//import Storm IRichBolt package
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
//Create a class CallLogCreatorBolt which implement IRichBolt interface
public class CallLogCreatorBolt implements IRichBolt {
//Create instance for OutputCollector which collects and emits tuples to produce output
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String from = tuple.getString(0);
String to = tuple.getString(1);
Integer duration = tuple.getInteger(2);
collector.emit(new Values(from + " - " + to, duration));
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call", "duration"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Rejestr połączeń Bolt licznika
Blokada rejestru połączeń odbiera połączenie i jego czas trwania jako krotkę. Ta śruba inicjuje obiekt Dictionary (Map) w metodzie przygotowania. Wexecutesprawdza krotkę i tworzy nowy wpis w obiekcie słownika dla każdej nowej wartości „wywołania” w krotce i ustawia wartość 1 w obiekcie słownika. Dla już dostępnego wpisu w słowniku po prostu zwiększa jego wartość. Mówiąc prościej, ten rygiel zapisuje wywołanie i jego liczbę w obiekcie słownika. Zamiast zapisywać wywołanie i jego liczbę w słowniku, możemy również zapisać je w źródle danych. Pełny kod programu jest następujący -
Kodowanie - CallLogCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class CallLogCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String call = tuple.getString(0);
Integer duration = tuple.getInteger(1);
if(!counterMap.containsKey(call)){
counterMap.put(call, 1);
}else{
Integer c = counterMap.get(call) + 1;
counterMap.put(call, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Tworzenie topologii
Topologia Storm jest w zasadzie strukturą Thrift. Klasa TopologyBuilder udostępnia proste i łatwe metody tworzenia złożonych topologii. Klasa TopologyBuilder zawiera metody ustawiania wylewu(setSpout) i ustawić rygiel (setBolt). Wreszcie, TopologyBuilder ma createTopology do tworzenia topologii. Użyj poniższego fragmentu kodu, aby utworzyć topologię -
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));shuffleGrouping i fieldsGrouping metody pomagają ustawić grupowanie strumieni dla wylewek i śrub.
Klaster lokalny
Dla celów programistycznych możemy stworzyć klaster lokalny za pomocą obiektu „LocalCluster”, a następnie przesłać topologię metodą „submitTopology” klasy „LocalCluster”. Jednym z argumentów argumentu „submitTopology” jest instancja klasy „Config”. Klasa „Config” służy do ustawiania opcji konfiguracyjnych przed przesłaniem topologii. Ta opcja konfiguracji zostanie scalona z konfiguracją klastra w czasie wykonywania i wysłana do wszystkich zadań (wylewki i śruby) metodą przygotowania. Po przesłaniu topologii do klastra będziemy czekać 10 sekund, aż klaster obliczy przesłaną topologię, a następnie zamknie klaster przy użyciu metody „shutdown” „LocalCluster”. Pełny kod programu jest następujący -
Kodowanie - LogAnalyserStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import storm configuration packages
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
//Create main class LogAnalyserStorm submit topology.
public class LogAnalyserStorm {
public static void main(String[] args) throws Exception{
//Create Config instance for cluster configuration
Config config = new Config();
config.setDebug(true);
//
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LogAnalyserStorm", config, builder.createTopology());
Thread.sleep(10000);
//Stop the topology
cluster.shutdown();
}
}Tworzenie i uruchamianie aplikacji
Cała aplikacja zawiera cztery kody Java. Oni są -
- FakeCallLogReaderSpout.java
- CallLogCreaterBolt.java
- CallLogCounterBolt.java
- LogAnalyerStorm.java
Aplikację można zbudować za pomocą następującego polecenia -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaAplikację można uruchomić za pomocą następującego polecenia -
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserStormWynik
Po uruchomieniu aplikacja wyświetli szczegółowe informacje o procesie uruchamiania klastra, przetwarzaniu spout i śruby, a na końcu o procesie zamykania klastra. W „CallLogCounterBolt” wydrukowaliśmy wywołanie i jego liczbę. Te informacje zostaną wyświetlone na konsoli w następujący sposób -
1234123402 - 1234123401 : 78
1234123402 - 1234123404 : 88
1234123402 - 1234123403 : 105
1234123401 - 1234123404 : 74
1234123401 - 1234123403 : 81
1234123401 - 1234123402 : 81
1234123403 - 1234123404 : 86
1234123404 - 1234123401 : 63
1234123404 - 1234123402 : 82
1234123403 - 1234123402 : 83
1234123404 - 1234123403 : 86
1234123403 - 1234123401 : 93Języki spoza JVM
Topologie Storm są implementowane przez interfejsy Thrift, co ułatwia przesyłanie topologii w dowolnym języku. Storm obsługuje Ruby, Python i wiele innych języków. Rzućmy okiem na powiązanie Pythona.
Python Binding
Python to interpretowany, interaktywny, zorientowany obiektowo język programowania wysokiego poziomu ogólnego przeznaczenia. Storm obsługuje Pythona w celu implementacji swojej topologii. Python obsługuje operacje emitowania, zakotwiczania, potwierdzania i rejestrowania.
Jak wiesz, śruby można definiować w dowolnym języku. Śruby napisane w innym języku są wykonywane jako podprocesy, a Storm komunikuje się z tymi podprocesami za pomocą komunikatów JSON przez stdin / stdout. Najpierw weź przykładową śrubę WordCount, która obsługuje powiązanie języka Python.
public static class WordCount implements IRichBolt {
public WordSplit() {
super("python", "splitword.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}Tutaj klasa WordCount implementuje IRichBoltinterfejs i działa z implementacją Pythona z określonym argumentem super metody "splitword.py". Teraz utwórz implementację Pythona o nazwie „splitword.py”.
import storm
class WordCountBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
WordCountBolt().run()To jest przykładowa implementacja dla Pythona, która liczy słowa w danym zdaniu. Podobnie możesz również łączyć się z innymi językami pomocniczymi.
Trident to rozszerzenie Storm. Podobnie jak Storm, Trident również został opracowany przez Twittera. Głównym powodem rozwoju Trident jest zapewnienie wysokiego poziomu abstrakcji na szczycie Storm, wraz z przetwarzaniem strumieniowym i rozproszonymi zapytaniami o niskim opóźnieniu.
Trident używa dziobka i śruby, ale te komponenty niskiego poziomu są automatycznie generowane przez Trident przed wykonaniem. Trident ma funkcje, filtry, łączenia, grupowanie i agregację.
Trident przetwarza strumienie jako serie partii, które nazywane są transakcjami. Ogólnie rzecz biorąc, wielkość tych małych partii będzie rzędu tysięcy lub milionów krotek, w zależności od strumienia wejściowego. W ten sposób Trident różni się od Storm, który przetwarza krotkę po krotce.
Koncepcja przetwarzania wsadowego jest bardzo podobna do transakcji w bazie danych. Każda transakcja ma przypisany identyfikator transakcji. Transakcja jest uważana za udaną, gdy wszystkie jej przetwarzanie zostaną zakończone. Jednak niepowodzenie w przetwarzaniu jednej z krotek transakcji spowoduje retransmisję całej transakcji. Dla każdej partii Trident wywoła na początku transakcji beginCommit i zatwierdzi na końcu.
Topologia Trident
Trident API udostępnia łatwą opcję tworzenia topologii Trident przy użyciu klasy „TridentTopology”. Zasadniczo topologia Trident odbiera strumień wejściowy z wylewki i wykonuje uporządkowaną sekwencję operacji (filtrowanie, agregacja, grupowanie itp.) Na strumieniu. Krąg burzy zostaje zastąpiony krotką z trójzębem, a śruby - operacjami. Prostą topologię Trident można utworzyć w następujący sposób -
TridentTopology topology = new TridentTopology();Krotki trójzębne
Krotka trójzębna to nazwana lista wartości. Interfejs TridentTuple jest modelem danych topologii Trident. Interfejs TridentTuple jest podstawową jednostką danych, które mogą być przetwarzane przez topologię Trident.
Wylewka Trident
Wylewka Trident jest podobna do wylewki Storm, z dodatkowymi opcjami wykorzystania funkcji Trident. Właściwie nadal możemy korzystać z IRichSpout, którego używaliśmy w topologii Storm, ale będzie on miał charakter nietransakcyjny i nie będziemy mogli korzystać z zalet oferowanych przez Trident.
Podstawową wylewką posiadającą wszystkie funkcje potrzebne do korzystania z funkcji Trident jest „ITridentSpout”. Obsługuje zarówno transakcyjną, jak i nieprzejrzystą semantykę transakcyjną. Pozostałe wylewki to IBatchSpout, IPartitionedTridentSpout i IOpaquePartitionedTridentSpout.
Oprócz tych typowych wylewek, Trident ma wiele przykładowych realizacji wylewki Trident. Jednym z nich jest wylewka FeederBatchSpout, za pomocą której możemy łatwo wysłać nazwaną listę krotek trójzębnych, nie martwiąc się o przetwarzanie wsadowe, równoległość itp.
Tworzenie FeederBatchSpout i podawanie danych można wykonać w sposób pokazany poniżej -
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(
ImmutableList.of("fromMobileNumber", "toMobileNumber", “duration”));
topology.newStream("fixed-batch-spout", testSpout)
testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123402", 20)));Operacje Trident
Trident wykorzystuje „Operację Trident” do przetwarzania strumienia wejściowego krotek trójzębu. Trident API ma wiele wbudowanych operacji do obsługi prostego do złożonego przetwarzania strumieniowego. Operacje te obejmują zakres od prostej walidacji po złożone grupowanie i agregację krotek trójzębnych. Przejdźmy przez najważniejsze i najczęściej używane operacje.
Filtr
Filtr to obiekt używany do wykonywania zadania sprawdzania poprawności danych wejściowych. Filtr Trident pobiera podzbiór trójzębowych pól krotek jako dane wejściowe i zwraca wartość true lub false w zależności od tego, czy określone warunki są spełnione, czy nie. Jeśli zwracana jest wartość true, krotka jest przechowywana w strumieniu wyjściowym; w przeciwnym razie krotka zostanie usunięta ze strumienia. Filtr w zasadzie odziedziczy poBaseFilter klasę i zaimplementuj isKeepmetoda. Oto przykładowa implementacja operacji filtra -
public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(1) % 2 == 0;
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2]
[1, 4]Funkcję filtru można wywołać w topologii za pomocą metody „each”. Do określenia danych wejściowych można użyć klasy „Fields” (podzbiór krotki trójzębnej). Przykładowy kod jest następujący -
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields("a", "b"), new MyFilter())Funkcjonować
Functionjest obiektem używanym do wykonania prostej operacji na pojedynczej krotce trójzębu. Pobiera podzbiór pól krotek trójzębnych i emituje zero lub więcej nowych pól krotek trójzębnych.
Function zasadniczo dziedziczy z BaseFunction i implementuje executemetoda. Przykładowa implementacja jest podana poniżej -
public class MyFunction extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
int a = tuple.getInteger(0);
int b = tuple.getInteger(1);
collector.emit(new Values(a + b));
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2, 3]
[1, 3, 4]
[1, 4, 5]Podobnie jak operacja filtru, operację funkcji można wywołać w topologii przy użyciu rozszerzenia eachmetoda. Przykładowy kod jest następujący -
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d")));Zbiór
Agregacja to obiekt używany do wykonywania operacji agregacji na wejściowym wsadzie, partycji lub strumieniu. Trident ma trzy typy agregacji. Są następujące -
aggregate- Agreguje każdą partię krotki trójzębu oddzielnie. Podczas procesu agregacji krotki są początkowo ponownie partycjonowane przy użyciu grupowania globalnego w celu połączenia wszystkich partycji tej samej partii w jedną partycję.
partitionAggregate- Agreguje każdą partycję zamiast całej partii trójzębnej krotki. Dane wyjściowe agregacji partycji całkowicie zastępują krotkę wejściową. Dane wyjściowe agregatu partycji zawierają krotkę pojedynczego pola.
persistentaggregate - Agreguje wszystkie krotki trójzębne we wszystkich wsadach i zapisuje wynik w pamięci lub w bazie danych.
TridentTopology topology = new TridentTopology();
// aggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.aggregate(new Count(), new Fields(“count”))
// partitionAggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.partitionAggregate(new Count(), new Fields(“count"))
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));Operację agregacji można utworzyć przy użyciu CombinerAggregator, ReducerAggregator lub ogólnego interfejsu Aggregator. Agregator „count” użyty w powyższym przykładzie jest jednym z wbudowanych agregatorów. Jest zaimplementowany przy użyciu narzędzia „CombinerAggregator”. Implementacja jest następująca -
public class Count implements CombinerAggregator<Long> {
@Override
public Long init(TridentTuple tuple) {
return 1L;
}
@Override
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
@Override
public Long zero() {
return 0L;
}
}Grupowanie
Operacja grupowania jest operacją wbudowaną i może być wywoływana przez groupBymetoda. Metoda groupBy dzieli strumień na partycje, wykonując partycjonowanie na określonych polach, a następnie w ramach każdej partycji grupuje krotki, których pola grup są równe. Zwykle używamy „groupBy” razem z „persistentAggregate”, aby uzyskać zgrupowaną agregację. Przykładowy kod jest następujący -
TridentTopology topology = new TridentTopology();
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.groupBy(new Fields(“d”)
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));Scalanie i łączenie
Scalanie i łączenie można wykonać odpowiednio metodą „merge” i „join”. Scalanie łączy jeden lub więcej strumieni. Łączenie jest podobne do scalania, z wyjątkiem faktu, że łączenie wykorzystuje trójzębne pole krotki z obu stron do sprawdzania i łączenia dwóch strumieni. Co więcej, łączenie będzie działać tylko na poziomie partii. Przykładowy kod jest następujący -
TridentTopology topology = new TridentTopology();
topology.merge(stream1, stream2, stream3);
topology.join(stream1, new Fields("key"), stream2, new Fields("x"),
new Fields("key", "a", "b", "c"));Utrzymanie stanu
Trident zapewnia mechanizm utrzymania stanu. Informacje o stanie mogą być przechowywane w samej topologii, w przeciwnym razie można je również przechowywać w oddzielnej bazie danych. Powodem jest utrzymanie stanu, w którym jeśli jakakolwiek krotka ulegnie awarii podczas przetwarzania, zostanie ponowiona próba wykonania błędnej krotki. Stwarza to problem podczas aktualizowania stanu, ponieważ nie masz pewności, czy stan tej krotki został zaktualizowany wcześniej, czy nie. Jeśli krotka nie powiodła się przed zaktualizowaniem stanu, ponowienie próby spowoduje, że stan będzie stabilny. Jeśli jednak krotka zakończyła się niepowodzeniem po zaktualizowaniu stanu, ponowna próba wykonania tej samej krotki ponownie zwiększy liczbę w bazie danych i spowoduje niestabilność stanu. Aby wiadomość została przetworzona tylko raz, należy wykonać następujące kroki -
Przetwarzaj krotki w małych partiach.
Przypisz unikalny identyfikator do każdej partii. Jeśli partia zostanie ponowiona, otrzyma ten sam unikalny identyfikator.
Aktualizacje stanu są uporządkowane w partiach. Na przykład aktualizacja stanu drugiej partii nie będzie możliwa do czasu zakończenia aktualizacji stanu dla pierwszej partii.
Rozproszone RPC
Rozproszone RPC służy do wykonywania zapytań i pobierania wyników z topologii Trident. Storm ma wbudowany rozproszony serwer RPC. Rozproszony serwer RPC odbiera żądanie RPC od klienta i przekazuje je do topologii. Topologia przetwarza żądanie i wysyła wynik do rozproszonego serwera RPC, który jest przekierowywany przez rozproszony serwer RPC do klienta. Rozproszone zapytanie RPC Trident jest wykonywane jak zwykłe zapytanie RPC, z wyjątkiem faktu, że zapytania te są wykonywane równolegle.
Kiedy używać Trident?
Podobnie jak w wielu przypadkach użycia, jeśli wymaganiem jest przetworzenie zapytania tylko raz, możemy to osiągnąć, pisząc topologię w Trident. Z drugiej strony w przypadku Storma trudno będzie uzyskać dokładnie raz przetworzenie. Dlatego Trident będzie przydatny w tych przypadkach użycia, w których potrzebujesz dokładnie raz przetworzyć. Trident nie jest przeznaczony dla wszystkich przypadków użycia, zwłaszcza przypadków użycia o wysokiej wydajności, ponieważ zwiększa złożoność Storm i zarządza stanem.
Roboczy przykład Trident
Zamierzamy przekonwertować naszą aplikację do analizy dzienników połączeń opracowaną w poprzedniej sekcji do frameworka Trident. Aplikacja Trident będzie stosunkowo łatwa w porównaniu do zwykłej burzy, dzięki wysokopoziomowemu API. Storm będzie zasadniczo wymagany do wykonania dowolnej z operacji Funkcji, Filtruj, Agreguj, Grupuj według, Połącz i Połącz w Trident. Na koniec uruchomimy serwer DRPC przy użyciu rozszerzeniaLocalDRPC class i wyszukaj słowo kluczowe za pomocą execute metoda klasy LocalDRPC.
Formatowanie informacji o połączeniu
Zadaniem klasy FormatCall jest formatowanie informacji o połączeniu zawierającej „Numer dzwoniącego” i „Numer odbiorcy”. Pełny kod programu jest następujący -
Kodowanie: FormatCall.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class FormatCall extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String fromMobileNumber = tuple.getString(0);
String toMobileNumber = tuple.getString(1);
collector.emit(new Values(fromMobileNumber + " - " + toMobileNumber));
}
}CSVSplit
Celem klasy CSVSplit jest podzielenie ciągu wejściowego na podstawie „przecinka (,)” i wyemitowanie każdego słowa w ciągu. Ta funkcja jest używana do analizowania argumentu wejściowego zapytań rozproszonych. Kompletny kod wygląda następująco -
Kodowanie: CSVSplit.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class CSVSplit extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
for(String word: tuple.getString(0).split(",")) {
if(word.length() > 0) {
collector.emit(new Values(word));
}
}
}
}Analizator logów
To jest główna aplikacja. Początkowo aplikacja zainicjuje TridentTopology i przekaże informacje o dzwoniącym przy użyciuFeederBatchSpout. Strumień topologii Trident można utworzyć za pomocąnewStreammetoda klasy TridentTopology. Podobnie, strumień DRPC topologii Trident można utworzyć przy użyciunewDRCPStreammetoda klasy TridentTopology. Prosty serwer DRCP można utworzyć za pomocą klasy LocalDRPC.LocalDRPCma metodę execute, aby wyszukać jakieś słowo kluczowe. Pełny kod podano poniżej.
Kodowanie: LogAnalyserTrident.java
import java.util.*;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.utils.DRPCClient;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import storm.trident.TridentState;
import storm.trident.TridentTopology;
import storm.trident.tuple.TridentTuple;
import storm.trident.operation.builtin.FilterNull;
import storm.trident.operation.builtin.Count;
import storm.trident.operation.builtin.Sum;
import storm.trident.operation.builtin.MapGet;
import storm.trident.operation.builtin.Debug;
import storm.trident.operation.BaseFilter;
import storm.trident.testing.FixedBatchSpout;
import storm.trident.testing.FeederBatchSpout;
import storm.trident.testing.Split;
import storm.trident.testing.MemoryMapState;
import com.google.common.collect.ImmutableList;
public class LogAnalyserTrident {
public static void main(String[] args) throws Exception {
System.out.println("Log Analyser Trident");
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(ImmutableList.of("fromMobileNumber",
"toMobileNumber", "duration"));
TridentState callCounts = topology
.newStream("fixed-batch-spout", testSpout)
.each(new Fields("fromMobileNumber", "toMobileNumber"),
new FormatCall(), new Fields("call"))
.groupBy(new Fields("call"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(),
new Fields("count"));
LocalDRPC drpc = new LocalDRPC();
topology.newDRPCStream("call_count", drpc)
.stateQuery(callCounts, new Fields("args"), new MapGet(), new Fields("count"));
topology.newDRPCStream("multiple_call_count", drpc)
.each(new Fields("args"), new CSVSplit(), new Fields("call"))
.groupBy(new Fields("call"))
.stateQuery(callCounts, new Fields("call"), new MapGet(),
new Fields("count"))
.each(new Fields("call", "count"), new Debug())
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
Config conf = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident", conf, topology.build());
Random randomGenerator = new Random();
int idx = 0;
while(idx < 10) {
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123402", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123403", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123404", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123402",
"1234123403", randomGenerator.nextInt(60))));
idx = idx + 1;
}
System.out.println("DRPC : Query starts");
System.out.println(drpc.execute("call_count","1234123401 - 1234123402"));
System.out.println(drpc.execute("multiple_call_count", "1234123401 -
1234123402,1234123401 - 1234123403"));
System.out.println("DRPC : Query ends");
cluster.shutdown();
drpc.shutdown();
// DRPCClient client = new DRPCClient("drpc.server.location", 3772);
}
}Tworzenie i uruchamianie aplikacji
Cała aplikacja ma trzy kody Java. Są następujące -
- FormatCall.java
- CSVSplit.java
- LogAnalyerTrident.java
Aplikację można zbudować za pomocą następującego polecenia -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaAplikację można uruchomić za pomocą następującego polecenia -
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserTridentWynik
Po uruchomieniu aplikacji aplikacja wyświetli szczegółowe informacje o procesie uruchamiania klastra, przetwarzaniu operacji, serwerze DRPC i kliencie, a na końcu o procesie zamykania klastra. Te dane wyjściowe zostaną wyświetlone na konsoli, jak pokazano poniżej.
DRPC : Query starts
[["1234123401 - 1234123402",10]]
DEBUG: [1234123401 - 1234123402, 10]
DEBUG: [1234123401 - 1234123403, 10]
[[20]]
DRPC : Query endsW tym rozdziale omówimy zastosowanie Apache Storm w czasie rzeczywistym. Zobaczymy, jak Storm jest używany na Twitterze.
Świergot
Twitter to serwis społecznościowy online, który zapewnia platformę do wysyłania i odbierania tweetów użytkowników. Zarejestrowani użytkownicy mogą czytać i wysyłać tweety, ale niezarejestrowani użytkownicy mogą czytać tylko tweety. Hashtag służy do kategoryzowania tweetów według słów kluczowych poprzez dodanie znaku # przed odpowiednim słowem kluczowym. Teraz przyjrzyjmy się scenariuszowi w czasie rzeczywistym znajdowania najczęściej używanego hashtagu na temat.
Tworzenie wylewki
Celem spouta jest jak najszybsze otrzymywanie tweetów przesłanych przez ludzi. Twitter zapewnia „Twitter Streaming API”, narzędzie oparte na usłudze internetowej do pobierania tweetów przesłanych przez ludzi w czasie rzeczywistym. Dostęp do interfejsu API przesyłania strumieniowego na Twitterze można uzyskać w dowolnym języku programowania.
twitter4j to nieoficjalna biblioteka Java o otwartym kodzie źródłowym, która zapewnia oparty na Javie moduł umożliwiający łatwy dostęp do interfejsu API przesyłania strumieniowego na Twitterze. twitter4judostępnia strukturę opartą na odbiornikach umożliwiającą dostęp do tweetów. Aby uzyskać dostęp do Twitter Streaming API, musimy zalogować się na konto programisty Twittera i powinniśmy uzyskać następujące dane uwierzytelniania OAuth.
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
Storm zapewnia wylewkę twittera, TwitterSampleSpout,w zestawie startowym. Będziemy go używać do pobierania tweetów. Dziobek wymaga szczegółów uwierzytelniania OAuth i przynajmniej słowa kluczowego. Dziobek będzie emitował tweety w czasie rzeczywistym na podstawie słów kluczowych. Pełny kod programu znajduje się poniżej.
Kodowanie: TwitterSampleSpout.java
import java.util.Map;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.FilterQuery;
import twitter4j.StallWarning;
import twitter4j.Status;
import twitter4j.StatusDeletionNotice;
import twitter4j.StatusListener;
import twitter4j.TwitterStream;
import twitter4j.TwitterStreamFactory;
import twitter4j.auth.AccessToken;
import twitter4j.conf.ConfigurationBuilder;
import backtype.storm.Config;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
@SuppressWarnings("serial")
public class TwitterSampleSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
LinkedBlockingQueue<Status> queue = null;
TwitterStream _twitterStream;
String consumerKey;
String consumerSecret;
String accessToken;
String accessTokenSecret;
String[] keyWords;
public TwitterSampleSpout(String consumerKey, String consumerSecret,
String accessToken, String accessTokenSecret, String[] keyWords) {
this.consumerKey = consumerKey;
this.consumerSecret = consumerSecret;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
this.keyWords = keyWords;
}
public TwitterSampleSpout() {
// TODO Auto-generated constructor stub
}
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
queue = new LinkedBlockingQueue<Status>(1000);
_collector = collector;
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
}
@Override
public void onDeletionNotice(StatusDeletionNotice sdn) {}
@Override
public void onTrackLimitationNotice(int i) {}
@Override
public void onScrubGeo(long l, long l1) {}
@Override
public void onException(Exception ex) {}
@Override
public void onStallWarning(StallWarning arg0) {
// TODO Auto-generated method stub
}
};
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
_twitterStream = new TwitterStreamFactory(cb.build()).getInstance();
_twitterStream.addListener(listener);
if (keyWords.length == 0) {
_twitterStream.sample();
}else {
FilterQuery query = new FilterQuery().track(keyWords);
_twitterStream.filter(query);
}
}
@Override
public void nextTuple() {
Status ret = queue.poll();
if (ret == null) {
Utils.sleep(50);
} else {
_collector.emit(new Values(ret));
}
}
@Override
public void close() {
_twitterStream.shutdown();
}
@Override
public Map<String, Object> getComponentConfiguration() {
Config ret = new Config();
ret.setMaxTaskParallelism(1);
return ret;
}
@Override
public void ack(Object id) {}
@Override
public void fail(Object id) {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("tweet"));
}
}Hashtag Reader Bolt
Tweet wyemitowany przez dziobek zostanie przekazany do HashtagReaderBolt, który przetworzy tweet i wyemituje wszystkie dostępne hashtagi. HashtagReaderBolt używagetHashTagEntitiesmetoda dostarczona przez twitter4j. getHashTagEntities odczytuje tweet i zwraca listę hashtagów. Pełny kod programu jest następujący -
Kodowanie: HashtagReaderBolt.java
import java.util.HashMap;
import java.util.Map;
import twitter4j.*;
import twitter4j.conf.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagReaderBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
Status tweet = (Status) tuple.getValueByField("tweet");
for(HashtagEntity hashtage : tweet.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
this.collector.emit(new Values(hashtage.getText()));
}
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Hashtag Counter Bolt
Wyemitowany hashtag zostanie przekazany do HashtagCounterBolt. Ten rygiel przetworzy wszystkie hashtagi i zapisze każdy hashtag i jego liczbę w pamięci za pomocą obiektu Java Map. Pełny kod programu znajduje się poniżej.
Kodowanie: HashtagCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String key = tuple.getString(0);
if(!counterMap.containsKey(key)){
counterMap.put(key, 1);
}else{
Integer c = counterMap.get(key) + 1;
counterMap.put(key, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println("Result: " + entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Przesyłanie topologii
Główną aplikacją jest przesłanie topologii. Topologia Twittera składa się zTwitterSampleSpout, HashtagReaderBolt, i HashtagCounterBolt. Poniższy kod programu pokazuje, jak przesłać topologię.
Kodowanie: TwitterHashtagStorm.java
import java.util.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class TwitterHashtagStorm {
public static void main(String[] args) throws Exception{
String consumerKey = args[0];
String consumerSecret = args[1];
String accessToken = args[2];
String accessTokenSecret = args[3];
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 4, arguments.length);
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("twitter-spout", new TwitterSampleSpout(consumerKey,
consumerSecret, accessToken, accessTokenSecret, keyWords));
builder.setBolt("twitter-hashtag-reader-bolt", new HashtagReaderBolt())
.shuffleGrouping("twitter-spout");
builder.setBolt("twitter-hashtag-counter-bolt", new HashtagCounterBolt())
.fieldsGrouping("twitter-hashtag-reader-bolt", new Fields("hashtag"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("TwitterHashtagStorm", config,
builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}Tworzenie i uruchamianie aplikacji
Cała aplikacja zawiera cztery kody Java. Są następujące -
- TwitterSampleSpout.java
- HashtagReaderBolt.java
- HashtagCounterBolt.java
- TwitterHashtagStorm.java
Możesz skompilować aplikację za pomocą następującego polecenia -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*” *.javaUruchom aplikację za pomocą następujących poleceń -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*”:.
TwitterHashtagStorm <customerkey> <customersecret> <accesstoken> <accesstokensecret>
<keyword1> <keyword2> … <keywordN>Wynik
Aplikacja wydrukuje aktualny dostępny hashtag i jego liczbę. Wynik powinien być podobny do następującego -
Result: jazztastic : 1
Result: foodie : 1
Result: Redskins : 1
Result: Recipe : 1
Result: cook : 1
Result: android : 1
Result: food : 2
Result: NoToxicHorseMeat : 1
Result: Purrs4Peace : 1
Result: livemusic : 1
Result: VIPremium : 1
Result: Frome : 1
Result: SundayRoast : 1
Result: Millennials : 1
Result: HealthWithKier : 1
Result: LPs30DaysofGratitude : 1
Result: cooking : 1
Result: gameinsight : 1
Result: Countryfile : 1
Result: androidgames : 1Wieśniak! Finanse to wiodąca witryna internetowa zawierająca wiadomości biznesowe i dane finansowe. Jest częścią Yahoo! i zawiera informacje o nowościach finansowych, statystykach rynkowych, danych z rynków międzynarodowych i inne informacje o zasobach finansowych, do których każdy ma dostęp.
Jeśli jesteś zarejestrowanym użytkownikiem Yahoo! użytkownika, możesz dostosować Yahoo! Finanse, aby skorzystać z niektórych ofert. Wieśniak! Finance API służy do wykonywania zapytań dotyczących danych finansowych z Yahoo!
Ten interfejs API wyświetla dane opóźnione o 15 minut od czasu rzeczywistego i aktualizuje swoją bazę danych co 1 minutę, aby uzyskać dostęp do aktualnych informacji dotyczących zapasów. Przyjrzyjmy się teraz scenariuszowi firmy w czasie rzeczywistym i zobaczmy, jak zgłosić alert, gdy jej wartość akcji spadnie poniżej 100.
Tworzenie wylewki
Zadaniem wylewki jest poznanie danych firmy i przekazanie ceny do śrub. Możesz użyć następującego kodu programu, aby utworzyć wylewkę.
Kodowanie: YahooFinanceSpout.java
import java.util.*;
import java.io.*;
import java.math.BigDecimal;
//import yahoofinace packages
import yahoofinance.YahooFinance;
import yahoofinance.Stock;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
public class YahooFinanceSpout implements IRichSpout {
private SpoutOutputCollector collector;
private boolean completed = false;
private TopologyContext context;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector){
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
try {
Stock stock = YahooFinance.get("INTC");
BigDecimal price = stock.getQuote().getPrice();
this.collector.emit(new Values("INTC", price.doubleValue()));
stock = YahooFinance.get("GOOGL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("GOOGL", price.doubleValue()));
stock = YahooFinance.get("AAPL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("AAPL", price.doubleValue()));
} catch(Exception e) {}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("company", "price"));
}
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Tworzenie śrub
Tutaj celem bolt jest przetworzenie cen danej firmy, gdy ceny spadną poniżej 100. Używa obiektu Java Map do ustawienia ostrzeżenia o granicznej cenie jako truegdy ceny akcji spadną poniżej 100; inaczej fałszywe. Pełny kod programu jest następujący -
Kodowanie: PriceCutOffBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class PriceCutOffBolt implements IRichBolt {
Map<String, Integer> cutOffMap;
Map<String, Boolean> resultMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.cutOffMap = new HashMap <String, Integer>();
this.cutOffMap.put("INTC", 100);
this.cutOffMap.put("AAPL", 100);
this.cutOffMap.put("GOOGL", 100);
this.resultMap = new HashMap<String, Boolean>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String company = tuple.getString(0);
Double price = tuple.getDouble(1);
if(this.cutOffMap.containsKey(company)){
Integer cutOffPrice = this.cutOffMap.get(company);
if(price < cutOffPrice) {
this.resultMap.put(company, true);
} else {
this.resultMap.put(company, false);
}
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Boolean> entry:resultMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("cut_off_price"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Przesyłanie topologii
Jest to główna aplikacja, w której YahooFinanceSpout.java i PriceCutOffBolt.java są ze sobą połączone i tworzą topologię. Poniższy kod programu przedstawia, w jaki sposób można przesłać topologię.
Kodowanie: YahooFinanceStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class YahooFinanceStorm {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("yahoo-finance-spout", new YahooFinanceSpout());
builder.setBolt("price-cutoff-bolt", new PriceCutOffBolt())
.fieldsGrouping("yahoo-finance-spout", new Fields("company"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("YahooFinanceStorm", config, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}Tworzenie i uruchamianie aplikacji
Cała aplikacja ma trzy kody Java. Są następujące -
- YahooFinanceSpout.java
- PriceCutOffBolt.java
- YahooFinanceStorm.java
Aplikację można zbudować za pomocą następującego polecenia -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*” *.javaAplikację można uruchomić za pomocą następującego polecenia -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*”:.
YahooFinanceStormWynik
Wynik będzie podobny do następującego -
GOOGL : false
AAPL : false
INTC : trueFramework Apache Storm obsługuje wiele z najlepszych współczesnych aplikacji przemysłowych. W tym rozdziale przedstawimy bardzo krótki przegląd niektórych z najważniejszych zastosowań Storm.
Klout
Klout to aplikacja, która wykorzystuje analitykę mediów społecznościowych do oceniania swoich użytkowników w oparciu o wpływy społeczne online Klout Score, która jest wartością liczbową od 1 do 100. Klout używa wbudowanej abstrakcji Trident Apache Storm do tworzenia złożonych topologii, które przesyłają strumieniowo dane.
Kanał pogodowy
Weather Channel wykorzystuje topologie Storm do pozyskiwania danych pogodowych. Połączył się z Twitterem, aby umożliwić wyświetlanie reklam opartych na pogodzie na Twitterze i w aplikacjach mobilnych.OpenSignal to firma specjalizująca się w mapowaniu zasięgu sieci bezprzewodowej. StormTag i WeatherSignalto projekty oparte na pogodzie stworzone przez OpenSignal. StormTag to stacja pogodowa Bluetooth podłączana do pęku kluczy. Dane pogodowe zebrane przez urządzenie są przesyłane do aplikacji WeatherSignal i serwerów OpenSignal.
Przemysł telekomunikacyjny
Dostawcy usług telekomunikacyjnych obsługują miliony połączeń telefonicznych na sekundę. Przeprowadzają badania kryminalistyczne dotyczące zerwanych połączeń i słabej jakości dźwięku. Rekordy szczegółów połączeń napływają z szybkością milionów na sekundę, a Apache Storm przetwarza je w czasie rzeczywistym i identyfikuje wszelkie niepokojące wzorce. Analiza burzy może służyć do ciągłej poprawy jakości połączeń.