Piękna zupa - krótki przewodnik
W dzisiejszym świecie mamy mnóstwo nieustrukturyzowanych danych / informacji (głównie danych internetowych) dostępnych bezpłatnie. Czasami swobodnie dostępne dane są łatwe do odczytania, a czasami nie. Bez względu na to, w jaki sposób dostępne są Twoje dane, skrobanie z sieci jest bardzo przydatnym narzędziem do przekształcania danych nieustrukturyzowanych w dane strukturalne, które są łatwiejsze do odczytania i analizy. Innymi słowy, jednym ze sposobów gromadzenia, organizowania i analizowania tej ogromnej ilości danych jest skrobanie sieci. Więc najpierw zrozummy, czym jest skrobanie sieci.
Co to jest skrobanie sieci?
Skrobanie to po prostu proces wyodrębniania (różnymi sposobami), kopiowania i przeglądania danych.
Kiedy dokonujemy skrobania lub wyodrębniania danych lub kanałów z sieci (np. Ze stron internetowych lub witryn internetowych), określa się to jako skrobanie sieci.
Tak więc skrobanie sieci, znane również jako wyodrębnianie danych z sieci lub zbieranie danych z sieci, to wyodrębnianie danych z sieci. Krótko mówiąc, skrobanie sieci umożliwia programistom gromadzenie i analizowanie danych z Internetu.
Dlaczego skrobanie w sieci?
Web-scraping to jedno z doskonałych narzędzi do automatyzacji większości czynności wykonywanych przez człowieka podczas przeglądania. Web-scraping jest używany w przedsiębiorstwie na wiele sposobów -
Dane do badań
Inteligentny analityk (np. Badacz lub dziennikarz) używa skrobaka internetowego zamiast ręcznie zbierać i czyścić dane ze stron internetowych.
Ceny produktów i porównanie popularności
Obecnie istnieje kilka usług, które wykorzystują skrobaki internetowe do zbierania danych z wielu witryn internetowych i porównywania ich popularności z cenami.
Monitorowanie SEO
Istnieje wiele narzędzi SEO, takich jak Ahrefs, Seobility, SEMrush itp., Które służą do analizy konkurencji i do pobierania danych ze stron internetowych Twojego klienta.
Wyszukiwarki
Istnieje kilka dużych firm IT, których działalność opiera się wyłącznie na skrobaniu sieci.
Sprzedaż i marketing
Dane zebrane w ramach skrobania stron internetowych mogą być wykorzystywane przez marketerów do analizy różnych nisz i konkurentów lub przez specjalistę ds. Sprzedaży do sprzedaży usług marketingu treści lub promocji w mediach społecznościowych.
Dlaczego Python do przeglądania sieci?
Python jest jednym z najpopularniejszych języków do skrobania stron internetowych, ponieważ bardzo łatwo radzi sobie z większością zadań związanych z przeszukiwaniem sieci.
Poniżej znajduje się kilka wskazówek, dlaczego warto wybrać Pythona do skrobania stron internetowych:
Łatwość użycia
Ponieważ większość programistów zgadza się, że Python jest bardzo łatwy do kodowania. Nie musimy używać nawiasów klamrowych „{}” ani średników „;” w dowolnym miejscu, co czyni go bardziej czytelnym i łatwiejszym w użyciu podczas tworzenia skrobaków internetowych.
Ogromna obsługa bibliotek
Python zapewnia ogromny zestaw bibliotek dla różnych wymagań, więc jest odpowiedni do skrobania stron internetowych, a także do wizualizacji danych, uczenia maszynowego itp.
Łatwo wyjaśniona składnia
Python to bardzo czytelny język programowania, ponieważ składnia Pythona jest łatwa do zrozumienia. Python jest bardzo wyrazisty, a wcięcia kodu pomagają użytkownikom rozróżniać różne bloki lub zakresy w kodzie.
Język dynamicznie wpisywany
Python jest językiem z typami dynamicznymi, co oznacza, że dane przypisane do zmiennej mówią, jaki to jest typ zmiennej. Oszczędza dużo czasu i przyspiesza pracę.
Ogromna społeczność
Społeczność Pythona jest ogromna, która pomaga Ci wszędzie tam, gdzie utknąłeś podczas pisania kodu.
Wprowadzenie do pięknej zupy
The Beautiful Soup to biblioteka Pythona, której nazwa pochodzi od wiersza Lewisa Carrolla o tej samej nazwie z „Alicji w Krainie Czarów”. Beautiful Soup to pakiet w Pythonie, który, jak sama nazwa wskazuje, analizuje niechciane dane i pomaga organizować i formatować niechciane dane internetowe, naprawiając zły HTML i przedstawiając nam łatwo dostępne struktury XML.
Krótko mówiąc, Beautiful Soup to pakiet w Pythonie, który pozwala nam wyciągać dane z dokumentów HTML i XML.
Ponieważ BeautifulSoup nie jest standardową biblioteką Pythona, musimy ją najpierw zainstalować. Zamierzamy zainstalować najnowszą bibliotekę BeautifulSoup 4 (znaną również jako BS4).
Aby odizolować nasze środowisko pracy, aby nie zakłócać istniejącej konfiguracji, stwórzmy najpierw środowisko wirtualne.
Tworzenie środowiska wirtualnego (opcjonalnie)
Środowisko wirtualne pozwala nam stworzyć izolowaną kopię roboczą Pythona dla konkretnego projektu bez wpływu na zewnętrzną konfigurację.
Najlepszym sposobem na zainstalowanie dowolnego komputera z pakietami Pythona jest użycie pip, jednak jeśli pip nie jest jeszcze zainstalowany (możesz to sprawdzić za pomocą - „pip –version” w poleceniu lub znaku zachęty powłoki), możesz zainstalować, wydając poniższe polecenie -
Środowisko Linux
$sudo apt-get install python-pipŚrodowisko Windows
Aby zainstalować pip w systemie Windows, wykonaj następujące czynności -
Pobierz get-pip.py z https://bootstrap.pypa.io/get-pip.py lub z githuba na swój komputer.
Otwórz wiersz polecenia i przejdź do folderu zawierającego plik get-pip.py.
Uruchom następujące polecenie -
>python get-pip.pyTo wszystko, pip jest teraz zainstalowany na twoim komputerze z systemem Windows.
Możesz zweryfikować swój pip zainstalowany, uruchamiając poniższe polecenie -
>pip --version
pip 19.2.3 from c:\users\yadur\appdata\local\programs\python\python37\lib\site-packages\pip (python 3.7)Instalowanie środowiska wirtualnego
Uruchom poniższe polecenie w wierszu polecenia -
>pip install virtualenvPo uruchomieniu zobaczysz poniższy zrzut ekranu -

Poniższe polecenie utworzy środowisko wirtualne („myEnv”) w Twoim bieżącym katalogu -
>virtualenv myEnvZrzut ekranu

Aby aktywować środowisko wirtualne, uruchom następujące polecenie -
>myEnv\Scripts\activate
Na powyższym zrzucie ekranu widać, że mamy przedrostek „myEnv”, który mówi nam, że jesteśmy w środowisku wirtualnym „myEnv”.
Aby wyjść ze środowiska wirtualnego, uruchom dezaktywuj.
(myEnv) C:\Users\yadur>deactivate
C:\Users\yadur>Ponieważ nasze wirtualne środowisko jest już gotowe, zainstalujmy beautifulsoup.
Instalowanie BeautifulSoup
Ponieważ BeautifulSoup nie jest standardową biblioteką, musimy ją zainstalować. Będziemy używać pakietu BeautifulSoup 4 (znanego jako bs4).
Maszyna Linux
Aby zainstalować bs4 na Debianie lub Ubuntu Linux za pomocą systemowego menedżera pakietów, uruchom poniższe polecenie -
$sudo apt-get install python-bs4 (for python 2.x)
$sudo apt-get install python3-bs4 (for python 3.x)Możesz zainstalować bs4 za pomocą easy_install lub pip (na wypadek, gdybyś znalazł problem z instalacją przy użyciu systemowego narzędzia do pakowania).
$easy_install beautifulsoup4
$pip install beautifulsoup4(Może być konieczne użycie odpowiednio easy_install3 lub pip3, jeśli używasz python3)
Komputer z systemem Windows
Instalacja beautifulsoup4 w systemie Windows jest bardzo prosta, zwłaszcza jeśli masz już zainstalowany pip.
>pip install beautifulsoup4
Więc teraz beautifulsoup4 jest zainstalowany w naszej maszynie. Porozmawiajmy o niektórych problemach napotkanych po instalacji.
Problemy po instalacji
Na komputerze z systemem Windows możesz napotkać błąd instalacji niewłaściwej wersji, głównie przez -
błąd: ImportError “No module named HTMLParser”, musisz uruchomić wersję kodu w języku Python 2 pod Pythonem 3.
błąd: ImportError “No module named html.parser” błąd, musisz uruchomić wersję kodu w Pythonie 3 pod Pythonem 2.
Najlepszym sposobem na wyjście z powyższych dwóch sytuacji jest ponowna instalacja BeautifulSoup, całkowicie usuwając istniejącą instalację.
Jeśli masz SyntaxError “Invalid syntax” w wierszu ROOT_TAG_NAME = u '[dokument]', musisz przekonwertować kod python 2 na python 3, po prostu instalując pakiet -
$ python3 setup.py installlub ręcznie uruchamiając skrypt konwersji 2 do 3 języka Python w katalogu bs4 -
$ 2to3-3.2 -w bs4Instalowanie parsera
Domyślnie Beautiful Soup obsługuje parser HTML zawarty w standardowej bibliotece Pythona, ale obsługuje również wiele zewnętrznych parserów Pythona, takich jak parser lxml lub parser html5lib.
Aby zainstalować parser lxml lub html5lib, użyj polecenia -
Maszyna Linux
$apt-get install python-lxml
$apt-get insall python-html5libKomputer z systemem Windows
$pip install lxml
$pip install html5lib
Ogólnie rzecz biorąc, użytkownicy używają lxml dla szybkości i zaleca się używanie parsera lxml lub html5lib, jeśli używasz starszej wersji pythona 2 (przed wersją 2.7.3) lub pythona 3 (przed wersją 3.2.2), ponieważ wbudowany parser HTML Pythona jest niezbyt dobrze radzi sobie ze starszą wersją.
Prowadzenie Pięknej Zupy
Czas przetestować nasz pakiet Beautiful Soup na jednej ze stron html (biorąc stronę internetową - https://www.tutorialspoint.com/index.htm, możesz wybrać dowolną inną stronę internetową) i wyodrębnić z niej pewne informacje.
W poniższym kodzie próbujemy wyodrębnić tytuł ze strony internetowej -
from bs4 import BeautifulSoup
import requests
url = "https://www.tutorialspoint.com/index.htm"
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
print(soup.title)Wynik
<title>H2O, Colab, Theano, Flutter, KNime, Mean.js, Weka, Solidity, Org.Json, AWS QuickSight, JSON.Simple, Jackson Annotations, Passay, Boon, MuleSoft, Nagios, Matplotlib, Java NIO, PyTorch, SLF4J, Parallax Scrolling, Java Cryptography</title>Jednym z typowych zadań jest wyodrębnienie wszystkich adresów URL na stronie internetowej. W tym celu wystarczy dodać poniższy wiersz kodu -
for link in soup.find_all('a'):
print(link.get('href'))Wynik
https://www.tutorialspoint.com/index.htm
https://www.tutorialspoint.com/about/about_careers.htm
https://www.tutorialspoint.com/questions/index.php
https://www.tutorialspoint.com/online_dev_tools.htm
https://www.tutorialspoint.com/codingground.htm
https://www.tutorialspoint.com/current_affairs.htm
https://www.tutorialspoint.com/upsc_ias_exams.htm
https://www.tutorialspoint.com/tutor_connect/index.php
https://www.tutorialspoint.com/whiteboard.htm
https://www.tutorialspoint.com/netmeeting.php
https://www.tutorialspoint.com/index.htm
https://www.tutorialspoint.com/tutorialslibrary.htm
https://www.tutorialspoint.com/videotutorials/index.php
https://store.tutorialspoint.com
https://www.tutorialspoint.com/gate_exams_tutorials.htm
https://www.tutorialspoint.com/html_online_training/index.asp
https://www.tutorialspoint.com/css_online_training/index.asp
https://www.tutorialspoint.com/3d_animation_online_training/index.asp
https://www.tutorialspoint.com/swift_4_online_training/index.asp
https://www.tutorialspoint.com/blockchain_online_training/index.asp
https://www.tutorialspoint.com/reactjs_online_training/index.asp
https://www.tutorix.com
https://www.tutorialspoint.com/videotutorials/top-courses.php
https://www.tutorialspoint.com/the_full_stack_web_development/index.asp
….
….
https://www.tutorialspoint.com/online_dev_tools.htm
https://www.tutorialspoint.com/free_web_graphics.htm
https://www.tutorialspoint.com/online_file_conversion.htm
https://www.tutorialspoint.com/netmeeting.php
https://www.tutorialspoint.com/free_online_whiteboard.htm
http://www.tutorialspoint.com
https://www.facebook.com/tutorialspointindia
https://plus.google.com/u/0/+tutorialspoint
http://www.twitter.com/tutorialspoint
http://www.linkedin.com/company/tutorialspoint
https://www.youtube.com/channel/UCVLbzhxVTiTLiVKeGV7WEBg
https://www.tutorialspoint.com/index.htm
/about/about_privacy.htm#cookies
/about/faq.htm
/about/about_helping.htm
/about/contact_us.htmPodobnie możemy wyodrębnić przydatne informacje za pomocą beautifulsoup4.
Teraz zrozumiemy więcej na temat „zupy” w powyższym przykładzie.
W poprzednim przykładzie kodu analizujemy dokument za pomocą pięknego konstruktora przy użyciu metody string. Innym sposobem jest przekazanie dokumentu przez otwarty uchwyt pliku.
from bs4 import BeautifulSoup
with open("example.html") as fp:
soup = BeautifulSoup(fp)
soup = BeautifulSoup("<html>data</html>")Najpierw dokument jest konwertowany na Unicode, a encje HTML są konwertowane na znaki Unicode: </p>
import bs4
html = '''<b>tutorialspoint</b>, <i>&web scraping &data science;</i>'''
soup = bs4.BeautifulSoup(html, 'lxml')
print(soup)Wynik
<html><body><b>tutorialspoint</b>, <i>&web scraping &data science;</i></body></html>Następnie BeautifulSoup analizuje dane za pomocą parsera HTML lub jawnie nakazujesz analizować za pomocą parsera XML.
Struktura drzewa HTML
Zanim przyjrzymy się różnym komponentom strony HTML, najpierw zrozumiemy strukturę drzewa HTML.
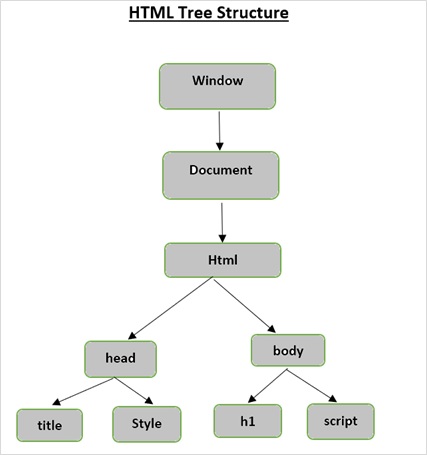
Elementem głównym w drzewie dokumentu jest html, który może mieć rodziców, dzieci i rodzeństwo, o czym decyduje jego pozycja w strukturze drzewa. Aby poruszać się między elementami HTML, atrybutami i tekstem, musisz poruszać się między węzłami w strukturze drzewa.
Załóżmy, że strona internetowa jest taka, jak pokazano poniżej -
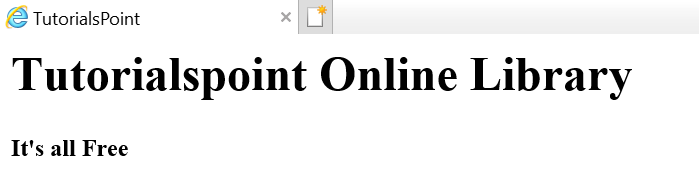
Co przekłada się na dokument HTML w następujący sposób -
<html><head><title>TutorialsPoint</title></head><h1>Tutorialspoint Online Library</h1><p<<b>It's all Free</b></p></body></html>Co po prostu oznacza, że dla powyższego dokumentu HTML mamy następującą strukturę drzewa html -
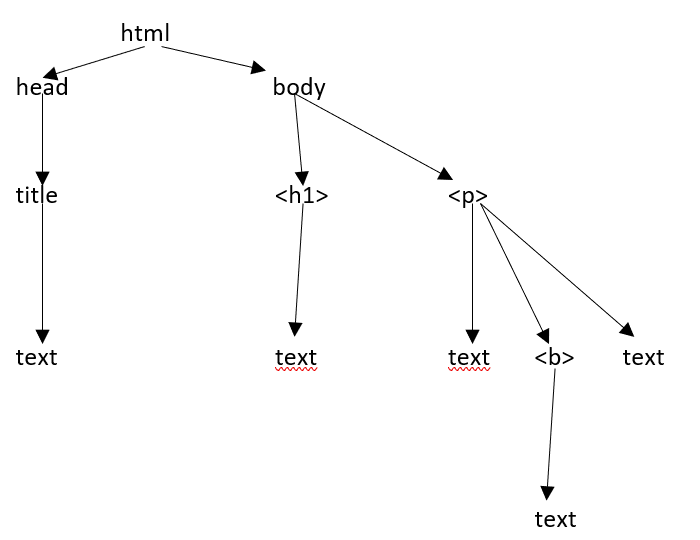
Kiedy przekazaliśmy dokument lub ciąg html do konstruktora beautifulsoup, beautifulsoup w zasadzie konwertuje złożoną stronę html na różne obiekty Pythona. Poniżej omówimy cztery główne rodzaje obiektów:
Tag
NavigableString
BeautifulSoup
Comments
Oznacz obiekty
Znacznik HTML służy do definiowania różnych typów treści. Obiekt znacznika w BeautifulSoup odpowiada znacznikowi HTML lub XML na rzeczywistej stronie lub dokumencie.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup('<b class="boldest">TutorialsPoint</b>')
>>> tag = soup.html
>>> type(tag)
<class 'bs4.element.Tag'>Tagi zawierają wiele atrybutów i metod, a dwie ważne cechy tagu to jego nazwa i atrybuty.
Imię (tag.name)
Każdy tag zawiera nazwę i jest dostępny poprzez rozszerzenie „.name” jako sufiks. tag.name zwróci typ tagu.
>>> tag.name
'html'Jeśli jednak zmienimy nazwę tagu, to samo zostanie odzwierciedlone w znaczniku HTML wygenerowanym przez BeautifulSoup.
>>> tag.name = "Strong"
>>> tag
<Strong><body><b class="boldest">TutorialsPoint</b></body></Strong>
>>> tag.name
'Strong'Atrybuty (tag.attrs)
Obiekt znacznika może mieć dowolną liczbę atrybutów. Znacznik <b class = ”boldest”> ma atrybut „class”, którego wartość to „boldest”. Wszystko, co NIE jest tagiem, jest w zasadzie atrybutem i musi zawierać wartość. Dostęp do atrybutów można uzyskać, uzyskując dostęp do kluczy (np. Uzyskując dostęp do „klasy” w powyższym przykładzie) lub bezpośrednio przez „.attrs”
>>> tutorialsP = BeautifulSoup("<div class='tutorialsP'></div>",'lxml')
>>> tag2 = tutorialsP.div
>>> tag2['class']
['tutorialsP']Możemy dokonać wszelkiego rodzaju modyfikacji atrybutów naszego tagu (dodaj / usuń / zmodyfikuj).
>>> tag2['class'] = 'Online-Learning'
>>> tag2['style'] = '2007'
>>>
>>> tag2
<div class="Online-Learning" style="2007"></div>
>>> del tag2['style']
>>> tag2
<div class="Online-Learning"></div>
>>> del tag['class']
>>> tag
<b SecondAttribute="2">TutorialsPoint</b>
>>>
>>> del tag['SecondAttribute']
>>> tag
</b>
>>> tag2['class']
'Online-Learning'
>>> tag2['style']
KeyError: 'style'Atrybuty wielowartościowe
Niektóre atrybuty HTML5 mogą mieć wiele wartości. Najczęściej używany jest atrybut-klasa, który może mieć wiele wartości CSS. Inne to „rel”, „rev”, „headers”, „accesskey” i „accept-charset”. Wielowartościowe atrybuty pięknej zupy są pokazane jako lista.
>>> from bs4 import BeautifulSoup
>>>
>>> css_soup = BeautifulSoup('<p class="body"></p>')
>>> css_soup.p['class']
['body']
>>>
>>> css_soup = BeautifulSoup('<p class="body bold"></p>')
>>> css_soup.p['class']
['body', 'bold']Jednak jeśli jakikolwiek atrybut zawiera więcej niż jedną wartość, ale nie jest atrybutem wielowartościowym w żadnej wersji standardu HTML, piękna zupa pozostawi ten atrybut w spokoju -
>>> id_soup = BeautifulSoup('<p id="body bold"></p>')
>>> id_soup.p['id']
'body bold'
>>> type(id_soup.p['id'])
<class 'str'>Możesz skonsolidować wiele wartości atrybutów, jeśli zmienisz tag w ciąg.
>>> rel_soup = BeautifulSoup("<p> tutorialspoint Main <a rel='Index'> Page</a></p>")
>>> rel_soup.a['rel']
['Index']
>>> rel_soup.a['rel'] = ['Index', ' Online Library, Its all Free']
>>> print(rel_soup.p)
<p> tutorialspoint Main <a rel="Index Online Library, Its all Free"> Page</a></p>Używając „get_attribute_list”, otrzymujesz wartość, która zawsze jest listą, ciągiem znaków, niezależnie od tego, czy jest to wielowartościowa, czy nie.
id_soup.p.get_attribute_list(‘id’)Jeśli jednak przeanalizujesz dokument jako „xml”, nie ma atrybutów wielowartościowych -
>>> xml_soup = BeautifulSoup('<p class="body bold"></p>', 'xml')
>>> xml_soup.p['class']
'body bold'NavigableString
Obiekt navigablestring służy do reprezentowania zawartości znacznika. Aby uzyskać dostęp do zawartości, użyj „.string” z tagiem.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>")
>>>
>>> soup.string
'Hello, Tutorialspoint!'
>>> type(soup.string)
>Możesz zamienić ciąg na inny, ale nie możesz edytować istniejącego.
>>> soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>")
>>> soup.string.replace_with("Online Learning!")
'Hello, Tutorialspoint!'
>>> soup.string
'Online Learning!'
>>> soup
<html><body><h2 id="message">Online Learning!</h2></body></html>BeautifulSoup
BeautifulSoup to obiekt tworzony, gdy próbujemy zeskrobać zasób sieciowy. Jest to więc cały dokument, który próbujemy zeskrobać. W większości przypadków jest to obiekt typu tag.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>")
>>> type(soup)
<class 'bs4.BeautifulSoup'>
>>> soup.name
'[document]'Komentarze
Obiekt komentarza ilustruje część dokumentu WWW zawierającą komentarz. To po prostu specjalny typ NavigableString.
>>> soup = BeautifulSoup('<p><!-- Everything inside it is COMMENTS --></p>')
>>> comment = soup.p.string
>>> type(comment)
<class 'bs4.element.Comment'>
>>> type(comment)
<class 'bs4.element.Comment'>
>>> print(soup.p.prettify())
<p>
<!-- Everything inside it is COMMENTS -->
</p>NavigableString Objects
Obiekty nawigacyjne służą do reprezentowania tekstu w znacznikach, a nie samych znaczników.
W tym rozdziale omówimy nawigację za pomocą tagów.
Poniżej znajduje się nasz dokument HTML -
>>> html_doc = """
<html><head><title>Tutorials Point</title></head>
<body>
<p class="title"><b>The Biggest Online Tutorials Library, It's all Free</b></p>
<p class="prog">Top 5 most used Programming Languages are:
<a href="https://www.tutorialspoint.com/java/java_overview.htm" class="prog" id="link1">Java</a>,
<a href="https://www.tutorialspoint.com/cprogramming/index.htm" class="prog" id="link2">C</a>,
<a href="https://www.tutorialspoint.com/python/index.htm" class="prog" id="link3">Python</a>,
<a href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" class="prog" id="link4">JavaScript</a> and
<a href="https://www.tutorialspoint.com/ruby/index.htm" class="prog" id="link5">C</a>;
as per online survey.</p>
<p class="prog">Programming Languages</p>
"""
>>>
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html_doc, 'html.parser')
>>>Na podstawie powyższego dokumentu spróbujemy przejść z jednej części dokumentu do drugiej.
Zejście w dół
Jednym z ważnych elementów każdego fragmentu dokumentu HTML są tagi, które mogą zawierać inne tagi / ciągi znaków (dzieci tagu). Beautiful Soup zapewnia różne sposoby nawigacji i iteracji po elementach potomnych tagu.
Nawigacja przy użyciu nazw tagów
Najłatwiejszym sposobem przeszukania drzewa parsowania jest wyszukanie znacznika według jego nazwy. Jeśli chcesz mieć tag <head>, użyj soup.head -
>>> soup.head
<head>&t;title>Tutorials Point</title></head>
>>> soup.title
<title>Tutorials Point</title>Aby uzyskać określony tag (taki jak pierwszy tag <b>) w tagu <body>.
>>> soup.body.b
<b>The Biggest Online Tutorials Library, It's all Free</b>Użycie nazwy tagu jako atrybutu da ci tylko pierwszy tag o tej nazwie -
>>> soup.a
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>Aby uzyskać wszystkie atrybuty tagu, możesz użyć metody find_all () -
>>> soup.find_all("a")
[<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>, <a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>, <a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>, <a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>]>>> soup.find_all("a")
[<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>, <a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>, <a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>, <a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>].contents i .children
Możemy wyszukiwać dzieci tagu na liście według jego .contents -
>>> head_tag = soup.head
>>> head_tag
<head><title>Tutorials Point</title></head>
>>> Htag = soup.head
>>> Htag
<head><title>Tutorials Point</title></head>
>>>
>>> Htag.contents
[<title>Tutorials Point</title>
>>>
>>> Ttag = head_tag.contents[0]
>>> Ttag
<title>Tutorials Point</title>
>>> Ttag.contents
['Tutorials Point']Sam obiekt BeautifulSoup ma dzieci. W tym przypadku tag <html> jest elementem podrzędnym obiektu BeautifulSoup -
>>> len(soup.contents)
2
>>> soup.contents[1].name
'html'Ciąg nie zawiera .contents, ponieważ nie może niczego zawierać -
>>> text = Ttag.contents[0]
>>> text.contents
self.__class__.__name__, attr))
AttributeError: 'NavigableString' object has no attribute 'contents'Zamiast pobierać je jako listę, użyj generatora .children, aby uzyskać dostęp do dzieci tagu -
>>> for child in Ttag.children:
print(child)
Tutorials Point.potomków
Atrybut .descendants pozwala na iterację po wszystkich elementach podrzędnych tagu, rekurencyjnie -
jego bezpośrednie dzieci i dzieci jego bezpośrednich dzieci i tak dalej -
>>> for child in Htag.descendants:
print(child)
<title>Tutorials Point</title>
Tutorials PointTag <head> ma tylko jedno dziecko, ale ma dwóch potomków: tag <title> i tag podrzędny tagu <title>. Obiekt beautifulsoup ma tylko jedno bezpośrednie dziecko (tag <html>), ale ma wiele potomków -
>>> len(list(soup.children))
2
>>> len(list(soup.descendants))
33.strunowy
Jeśli tag ma tylko jedno dziecko, a to dziecko jest NavigableString, element podrzędny jest udostępniany jako .string -
>>> Ttag.string
'Tutorials Point'Jeśli jedynym elementem podrzędnym tagu jest inny tag, a ten tag ma ciąg .string, wówczas uważa się, że tag nadrzędny ma taki sam ciąg .string, jak jego element podrzędny -
>>> Htag.contents
[<title>Tutorials Point</title>]
>>>
>>> Htag.string
'Tutorials Point'Jeśli jednak tag zawiera więcej niż jedną rzecz, nie jest jasne, do czego ma się odnosić .string, więc .string jest zdefiniowane jako None -
>>> print(soup.html.string)
None.strings i stripped_strings
Jeśli w tagu jest więcej niż jedna rzecz, nadal możesz patrzeć tylko na ciągi. Użyj generatora .strings -
>>> for string in soup.strings:
print(repr(string))
'\n'
'Tutorials Point'
'\n'
'\n'
"The Biggest Online Tutorials Library, It's all Free"
'\n'
'Top 5 most used Programming Languages are: \n'
'Java'
',\n'
'C'
',\n'
'Python'
',\n'
'JavaScript'
' and\n'
'C'
';\n \nas per online survey.'
'\n'
'Programming Languages'
'\n'Aby usunąć dodatkowe białe znaki, użyj generatora .stripped_strings -
>>> for string in soup.stripped_strings:
print(repr(string))
'Tutorials Point'
"The Biggest Online Tutorials Library, It's all Free"
'Top 5 most used Programming Languages are:'
'Java'
','
'C'
','
'Python'
','
'JavaScript'
'and'
'C'
';\n \nas per online survey.'
'Programming Languages'Wchodzę w górę
W analogii „drzewo genealogiczne” każdy znacznik i każdy ciąg ma rodzica: znacznik, który go zawiera:
.rodzic
Aby uzyskać dostęp do elementu nadrzędnego elementu, użyj atrybutu .parent.
>>> Ttag = soup.title
>>> Ttag
<title>Tutorials Point</title>
>>> Ttag.parent
<head>title>Tutorials Point</title></head>W naszym html_doc sam ciąg tytułu ma rodzica: tag <title>, który go zawiera -
>>> Ttag.string.parent
<title>Tutorials Point</title>Rodzicem tagu najwyższego poziomu, takiego jak <html>, jest sam obiekt Beautifulsoup -
>>> htmltag = soup.html
>>> type(htmltag.parent)
<class 'bs4.BeautifulSoup'>Element .parent obiektu Beautifulsoup jest zdefiniowany jako None -
>>> print(soup.parent)
None.rodzice
Aby wykonać iterację po wszystkich elementach nadrzędnych, użyj atrybutu .parents.
>>> link = soup.a
>>> link
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>
>>>
>>> for parent in link.parents:
if parent is None:
print(parent)
else:
print(parent.name)
p
body
html
[document]Idąc bokiem
Poniżej znajduje się jeden prosty dokument -
>>> sibling_soup = BeautifulSoup("<a><b>TutorialsPoint</b><c><strong>The Biggest Online Tutorials Library, It's all Free</strong></b></a>")
>>> print(sibling_soup.prettify())
<html>
<body>
<a>
<b>
TutorialsPoint
</b>
<c>
<strong>
The Biggest Online Tutorials Library, It's all Free
</strong>
</c>
</a>
</body>
</html>W powyższym dokumencie znaczniki <b> i <c> są na tym samym poziomie i oba są elementami podrzędnymi tego samego znacznika. Zarówno tag <b>, jak i <c> są rodzeństwem.
.next_sibling i .previous_sibling
Użyj .next_sibling i .previous_sibling, aby nawigować między elementami strony, które znajdują się na tym samym poziomie drzewa parsowania:
>>> sibling_soup.b.next_sibling
<c><strong>The Biggest Online Tutorials Library, It's all Free</strong></c>
>>>
>>> sibling_soup.c.previous_sibling
<b>TutorialsPoint</b>Znacznik <b> ma .next_sibling, ale nie ma .previous_sibling, ponieważ nie ma nic przed znacznikiem <b> na tym samym poziomie drzewa, to samo dotyczy tagu <c>.
>>> print(sibling_soup.b.previous_sibling)
None
>>> print(sibling_soup.c.next_sibling)
NoneTe dwa łańcuchy nie są rodzeństwem, ponieważ nie mają tego samego rodzica.
>>> sibling_soup.b.string
'TutorialsPoint'
>>>
>>> print(sibling_soup.b.string.next_sibling)
None.next_siblings i .previous_siblings
Aby iterować po rodzeństwie tagu, użyj .next_siblings i .previous_siblings.
>>> for sibling in soup.a.next_siblings:
print(repr(sibling))
',\n'
<a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>
',\n'
>a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>
',\n'
<a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>
' and\n'
<a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm"
id="link5">C</a>
';\n \nas per online survey.'
>>> for sibling in soup.find(id="link3").previous_siblings:
print(repr(sibling))
',\n'
<a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>
',\n'
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>
'Top 5 most used Programming Languages are: \n'Chodzić tam i z powrotem
Wróćmy teraz do pierwszych dwóch wierszy w naszym poprzednim przykładzie „html_doc” -
&t;html><head><title>Tutorials Point</title></head>
<body>
<h4 class="tagLine"><b>The Biggest Online Tutorials Library, It's all Free</b></h4>Parser HTML przyjmuje powyższy ciąg znaków i zamienia go w serię zdarzeń, takich jak „otwórz tag <html>”, „otwórz tag <head>”, „otwórz tag <title>”, „dodaj ciąg”, „Zamknij tag </title>”, „zamknij tag </head>”, „otwórz tag <h4>” i tak dalej. BeautifulSoup oferuje różne metody rekonstrukcji początkowej analizy dokumentu.
.next_element i .previous_element
Atrybut .next_element tagu lub ciągu wskazuje na wszystko, co zostało przeanalizowane natychmiast potem. Czasami wygląda podobnie do .next_sibling, jednak nie jest całkowicie taki sam. Poniżej znajduje się ostatni znacznik <a> w naszym przykładowym dokumencie „html_doc”.
>>> last_a_tag = soup.find("a", id="link5")
>>> last_a_tag
<a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>
>>> last_a_tag.next_sibling
';\n \nas per online survey.'Jednak .next_element tego znacznika <a>, rzecz, która została przeanalizowana bezpośrednio po znaczniku <a>, nie jest pozostałą częścią tego zdania: jest to słowo „C”:
>>> last_a_tag.next_element
'C'Powyższe zachowanie wynika z tego, że w oryginalnym oznaczeniu litera „C” pojawiła się przed średnikiem. Parser napotkał znacznik <a>, następnie literę „C”, następnie tag zamykający </a>, a następnie średnik i resztę zdania. Średnik jest na tym samym poziomie co znacznik <a>, ale najpierw napotkano literę „C”.
Atrybut .previous_element jest dokładnym przeciwieństwem .next_element. Wskazuje na który element został przeanalizowany bezpośrednio przed tym.
>>> last_a_tag.previous_element
' and\n'
>>>
>>> last_a_tag.previous_element.next_element
<a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>.next_elements i .previous_elements
Używamy tych iteratorów do przechodzenia do przodu i do tyłu do elementu.
>>> for element in last_a_tag.next_e lements:
print(repr(element))
'C'
';\n \nas per online survey.'
'\n'
<p class="prog">Programming Languages</p>
'Programming Languages'
'\n'Istnieje wiele metod Beautifulsoup, które pozwalają nam przeszukiwać drzewo parsowania. Dwie najpopularniejsze i najczęściej używane metody to find () i find_all ().
Zanim porozmawiamy o find () i find_all (), zobaczmy kilka przykładów różnych filtrów, które możesz przekazać do tych metod.
Rodzaje filtrów
Mamy różne filtry, które możemy przekazać do tych metod, a zrozumienie tych filtrów jest kluczowe, ponieważ są one używane wielokrotnie w całym API wyszukiwania. Możemy użyć tych filtrów w oparciu o nazwę tagu, jego atrybuty, tekst ciągu lub ich mieszankę.
Sznurek
Jednym z najprostszych typów filtrów jest łańcuch. Przekazanie ciągu do metody wyszukiwania i Beautifulsoup przeprowadzi dopasowanie do tego dokładnego ciągu.
Poniższy kod zawiera wszystkie tagi <p> w dokumencie -
>>> markup = BeautifulSoup('<p>Top Three</p><p><pre>Programming Languages are:</pre></p><p><b>Java, Python, Cplusplus</b></p>')
>>> markup.find_all('p')
[<p>Top Three</p>, <p></p>, <p><b>Java, Python, Cplusplus</b></p>]Wyrażenie regularne
Możesz znaleźć wszystkie tagi zaczynające się od danego ciągu / tagu. Wcześniej musimy zaimportować moduł re, aby użyć wyrażenia regularnego.
>>> import re
>>> markup = BeautifulSoup('<p>Top Three</p><p><pre>Programming Languages are:</pre></p><p><b>Java, Python, Cplusplus</b></p>')
>>>
>>> markup.find_all(re.compile('^p'))
[<p>Top Three</p>, <p></p>, <pre>Programming Languages are:</pre>, <p><b>Java, Python, Cplusplus</b></p>]Lista
Możesz przekazać wiele tagów do znalezienia, podając listę. Poniższy kod znajduje wszystkie tagi <b> i <pre> -
>>> markup.find_all(['pre', 'b'])
[<pre>Programming Languages are:</pre>, <b>Java, Python, Cplusplus</b>]Prawdziwe
True zwróci wszystkie tagi, które może znaleźć, ale żadnych ciągów samodzielnie -
>>> markup.find_all(True)
[<html><body><p>Top Three</p><p></p><pre>Programming Languages are:</pre>
<p><b>Java, Python, Cplusplus</b> </p> </body></html>,
<body><p>Top Three</p><p></p><pre> Programming Languages are:</pre><p><b>Java, Python, Cplusplus</b></p>
</body>,
<p>Top Three</p>, <p></p>, <pre>Programming Languages are:</pre>, <p><b>Java, Python, Cplusplus</b></p>, <b>Java, Python, Cplusplus</b>]Aby zwrócić tylko tagi z powyższej zupy -
>>> for tag in markup.find_all(True):
(tag.name)
'html'
'body'
'p'
'p'
'pre'
'p'
'b'Znajdź wszystko()
Możesz użyć find_all, aby wyodrębnić wszystkie wystąpienia określonego tagu z odpowiedzi strony jako -
Składnia
find_all(name, attrs, recursive, string, limit, **kwargs)Wyciągnijmy kilka interesujących danych z IMDB - „Najwyżej oceniane filmy” wszechczasów.
>>> url="https://www.imdb.com/chart/top/?ref_=nv_mv_250"
>>> content = requests.get(url)
>>> soup = BeautifulSoup(content.text, 'html.parser')
#Extract title Page
>>> print(soup.find('title'))
<title>IMDb Top 250 - IMDb</title>
#Extracting main heading
>>> for heading in soup.find_all('h1'):
print(heading.text)
Top Rated Movies
#Extracting sub-heading
>>> for heading in soup.find_all('h3'):
print(heading.text)
IMDb Charts
You Have Seen
IMDb Charts
Top India Charts
Top Rated Movies by Genre
Recently ViewedZ góry widzimy, że find_all poda nam wszystkie elementy pasujące do zdefiniowanych przez nas kryteriów wyszukiwania. Wszystkie filtry, których możemy użyć w funkcji find_all (), mogą być używane z funkcją find () i innymi metodami wyszukiwania, takimi jak find_parents () lub find_siblings ().
odnaleźć()
Widzieliśmy powyżej, find_all () służy do skanowania całego dokumentu w celu znalezienia całej zawartości, ale coś, wymaganiem jest znalezienie tylko jednego wyniku. Jeśli wiesz, że dokument zawiera tylko jeden tag <body>, przeszukiwanie całego dokumentu jest stratą czasu. Jednym ze sposobów jest wywołanie find_all () z limitem = 1 za każdym razem lub możemy użyć metody find (), aby zrobić to samo -
Składnia
find(name, attrs, recursive, string, **kwargs)Więc poniżej dwie różne metody dają ten sam wynik -
>>> soup.find_all('title',limit=1)
[<title>IMDb Top 250 - IMDb</title>]
>>>
>>> soup.find('title')
<title>IMDb Top 250 - IMDb</title>W powyższych wynikach widzimy, że metoda find_all () zwraca listę zawierającą pojedynczy element, podczas gdy metoda find () zwraca pojedynczy wynik.
Kolejna różnica między metodą find () i find_all () to -
>>> soup.find_all('h2')
[]
>>>
>>> soup.find('h2')Jeśli metoda soup.find_all () nie może niczego znaleźć, zwraca pustą listę, podczas gdy find () zwraca None.
find_parents () i find_parent ()
W przeciwieństwie do metod find_all () i find (), które przechodzą przez drzewo, patrząc na potomków tagu, metody find_parents () i find_parents () robią odwrotnie, przechodzą przez drzewo w górę i patrzą na rodziców tagu (lub łańcucha).
Składnia
find_parents(name, attrs, string, limit, **kwargs)
find_parent(name, attrs, string, **kwargs)
>>> a_string = soup.find(string="The Godfather")
>>> a_string
'The Godfather'
>>> a_string.find_parents('a')
[<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>]
>>> a_string.find_parent('a')
<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>
>>> a_string.find_parent('tr')
<tr>
<td class="posterColumn">
<span data-value="2" name="rk"></span>
<span data-value="9.149038526210072" name="ir"></span>
<span data-value="6.93792E10" name="us"></span>
<span data-value="1485540" name="nv"></span>
<span data-value="-1.850961473789928" name="ur"></span>
<a href="/title/tt0068646/"> <img alt="The Godfather" height="67" src="https://m.media-amazon.com/images/M/MV5BM2MyNjYxNmUtYTAwNi00MTYxLWJmNWYtYzZlODY3ZTk3OTFlXkEyXkFqcGdeQXVyNzkwMjQ5NzM@._V1_UY67_CR1,0,45,67_AL_.jpg" width="45"/>
</a> </td>
<td class="titleColumn">
2.
<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>
<span class="secondaryInfo">(1972)</span>
</td>
<td class="ratingColumn imdbRating">
<strong title="9.1 based on 1,485,540 user ratings">9.1</strong>
</td>
<td class="ratingColumn">
<div class="seen-widget seen-widget-tt0068646 pending" data-titleid="tt0068646">
<div class="boundary">
<div class="popover">
<span class="delete"> </span><ol><li>1<li>2<li>3<li>4<li>5<li>6<li>7<li>8<li>9<li>10</li>0</li></li></li></li&td;</li></li></li></li></li></ol> </div>
</div>
<div class="inline">
<div class="pending"></div>
<div class="unseeable">NOT YET RELEASED</div>
<div class="unseen"> </div>
<div class="rating"></div>
<div class="seen">Seen</div>
</div>
</div>
</td>
<td class="watchlistColumn">
<div class="wlb_ribbon" data-recordmetrics="true" data-tconst="tt0068646"></div>
</td>
</tr>
>>>
>>> a_string.find_parents('td')
[<td class="titleColumn">
2.
<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>
<span class="secondaryInfo">(1972)</span>
</td>]Istnieje osiem innych podobnych metod -
find_next_siblings(name, attrs, string, limit, **kwargs)
find_next_sibling(name, attrs, string, **kwargs)
find_previous_siblings(name, attrs, string, limit, **kwargs)
find_previous_sibling(name, attrs, string, **kwargs)
find_all_next(name, attrs, string, limit, **kwargs)
find_next(name, attrs, string, **kwargs)
find_all_previous(name, attrs, string, limit, **kwargs)
find_previous(name, attrs, string, **kwargs)Gdzie,
find_next_siblings() i find_next_sibling() metody będą iterować po wszystkich rodzeństwach elementu, który nastąpi po bieżącym.
find_previous_siblings() i find_previous_sibling() metody będą iterować po wszystkich rodzeństwach, które występują przed bieżącym elementem.
find_all_next() i find_next() metody będą iterować po wszystkich znacznikach i ciągach znaków, które występują po bieżącym elemencie.
find_all_previous i find_previous() metody będą iterować po wszystkich znacznikach i ciągach znaków, które występują przed bieżącym elementem.
Selektory CSS
Biblioteka BeautifulSoup do obsługi najczęściej używanych selektorów CSS. Możesz wyszukiwać elementy za pomocą selektorów CSS za pomocą metody select ().
Oto kilka przykładów -
>>> soup.select('title')
[<title>IMDb Top 250 - IMDb</title>, <title>IMDb Top Rated Movies</title>]
>>>
>>> soup.select("p:nth-of-type(1)")
[<p>The Top Rated Movie list only includes theatrical features.</p>, <p> class="imdb-footer__copyright _2-iNNCFskmr4l2OFN2DRsf">© 1990- by IMDb.com, Inc.</p>]
>>> len(soup.select("p:nth-of-type(1)"))
2
>>> len(soup.select("a"))
609
>>> len(soup.select("p"))
2
>>> soup.select("html head title")
[<title>IMDb Top 250 - IMDb</title>, <title>IMDb Top Rated Movies</title>]
>>> soup.select("head > title")
[<title>IMDb Top 250 - IMDb</title>]
#print HTML code of the tenth li elemnet
>>> soup.select("li:nth-of-type(10)")
[<li class="subnav_item_main">
<a href="/search/title?genres=film_noir&sort=user_rating,desc&title_type=feature&num_votes=25000,">Film-Noir
</a> </li>]Jednym z ważnych aspektów BeautifulSoup jest przeszukiwanie drzewa parsowania i umożliwia wprowadzanie zmian w dokumencie sieciowym zgodnie z wymaganiami. Możemy dokonywać zmian we właściwościach tagu za pomocą jego atrybutów, takich jak metoda .name, .string czy .append (). Pozwala na dodawanie nowych znaczników i ciągów do istniejącego znacznika za pomocą metod .new_string () i .new_tag (). Istnieją również inne metody, takie jak .insert (), .insert_before () lub .insert_after (), służące do wprowadzania różnych modyfikacji w dokumencie HTML lub XML.
Zmiana nazw i atrybutów znaczników
Po utworzeniu zupy łatwo jest wprowadzić modyfikacje, takie jak zmiana nazwy tagu, modyfikacja jego atrybutów, dodawanie nowych atrybutów i usuwanie atrybutów.
>>> soup = BeautifulSoup('<b class="bolder">Very Bold</b>')
>>> tag = soup.bModyfikacje i dodawanie nowych atrybutów są następujące -
>>> tag.name = 'Blockquote'
>>> tag['class'] = 'Bolder'
>>> tag['id'] = 1.1
>>> tag
<Blockquote class="Bolder" id="1.1">Very Bold</Blockquote>Usuwanie atrybutów jest następujące -
>>> del tag['class']
>>> tag
<Blockquote id="1.1">Very Bold</Blockquote>
>>> del tag['id']
>>> tag
<Blockquote>Very Bold</Blockquote>Modyfikowanie .string
Możesz łatwo zmodyfikować atrybut .string tagu -
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">Must for every <i>Learner>/i<</a>'
>>> Bsoup = BeautifulSoup(markup)
>>> tag = Bsoup.a
>>> tag.string = "My Favourite spot."
>>> tag
<a href="https://www.tutorialspoint.com/index.htm">My Favourite spot.</a>Z góry możemy zobaczyć, czy tag zawiera inny tag, on i cała ich zawartość zostaną zastąpione nowymi danymi.
dodać()
Dodanie nowych danych / treści do istniejącego tagu odbywa się za pomocą metody tag.append (). Jest bardzo podobny do metody append () na liście Pythona.
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">Must for every <i>Learner</i></a>'
>>> Bsoup = BeautifulSoup(markup)
>>> Bsoup.a.append(" Really Liked it")
>>> Bsoup
<html><body><a href="https://www.tutorialspoint.com/index.htm">Must for every <i>Learner</i> Really Liked it</a></body></html>
>>> Bsoup.a.contents
['Must for every ', <i>Learner</i>, ' Really Liked it']NavigableString () i .new_tag ()
Jeśli chcesz dodać ciąg do dokumentu, można to łatwo zrobić za pomocą konstruktora append () lub NavigableString () -
>>> soup = BeautifulSoup("<b></b>")
>>> tag = soup.b
>>> tag.append("Start")
>>>
>>> new_string = NavigableString(" Your")
>>> tag.append(new_string)
>>> tag
<b>Start Your</b>
>>> tag.contents
['Start', ' Your']Note: Jeśli znajdziesz jakąkolwiek nazwę Błąd podczas uzyskiwania dostępu do funkcji NavigableString (), wykonaj następujące czynności:
NameError: nazwa „NavigableString” nie jest zdefiniowana
Po prostu zaimportuj katalog NavigableString z pakietu bs4 -
>>> from bs4 import NavigableStringMożemy rozwiązać powyższy błąd.
Możesz dodać komentarze do istniejącego tagu lub możesz dodać inną podklasę NavigableString, po prostu wywołaj konstruktora.
>>> from bs4 import Comment
>>> adding_comment = Comment("Always Learn something Good!")
>>> tag.append(adding_comment)
>>> tag
<b>Start Your<!--Always Learn something Good!--></b>
>>> tag.contents
['Start', ' Your', 'Always Learn something Good!']Dodanie całego nowego tagu (bez dołączania do istniejącego tagu) można wykonać za pomocą wbudowanej metody Beautifulsoup, BeautifulSoup.new_tag () -
>>> soup = BeautifulSoup("<b></b>")
>>> Otag = soup.b
>>>
>>> Newtag = soup.new_tag("a", href="https://www.tutorialspoint.com")
>>> Otag.append(Newtag)
>>> Otag
<b><a href="https://www.tutorialspoint.com"></a></b>Wymagany jest tylko pierwszy argument, nazwa tagu.
wstawić()
Podobnie jak w przypadku metody .insert () na liście Pythona, tag.insert () wstawi nowy element, jednak w przeciwieństwie do tag.append (), nowy element niekoniecznie musi znajdować się na końcu zawartości swojego rodzica. Nowy element można dodać w dowolnym miejscu.
>>> markup = '<a href="https://www.djangoproject.com/community/">Django Official website <i>Huge Community base</i></a>'
>>> soup = BeautifulSoup(markup)
>>> tag = soup.a
>>>
>>> tag.insert(1, "Love this framework ")
>>> tag
<a href="https://www.djangoproject.com/community/">Django Official website Love this framework <i>Huge Community base</i></a>
>>> tag.contents
['Django Official website ', 'Love this framework ', <i>Huge Community base</i
>]
>>>insert_before () i insert_after ()
Aby wstawić jakiś znacznik lub ciąg tuż przed czymś w drzewie parsowania, używamy insert_before () -
>>> soup = BeautifulSoup("Brave")
>>> tag = soup.new_tag("i")
>>> tag.string = "Be"
>>>
>>> soup.b.string.insert_before(tag)
>>> soup.b
<b><i>Be</i>Brave</b>Podobnie, aby wstawić jakiś znacznik lub ciąg zaraz po czymś w drzewie parsowania, użyj insert_after ().
>>> soup.b.i.insert_after(soup.new_string(" Always "))
>>> soup.b
<b><i>Be</i> Always Brave</b>
>>> soup.b.contents
[<i>Be</i>, ' Always ', 'Brave']jasny()
Aby usunąć zawartość tagu, użyj tag.clear () -
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical&lr;/i> Contents</a>'
>>> soup = BeautifulSoup(markup)
>>> tag = soup.a
>>> tag
<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical</i> Contents</a>
>>>
>>> tag.clear()
>>> tag
<a href="https://www.tutorialspoint.com/index.htm"></a>wyciąg()
Aby usunąć tag lub ciągi z drzewa, użyj PageElement.extract ().
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">For <i&gr;technical & Non-technical</i> Contents</a>'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>>
>>> i_tag = soup.i.extract()
>>>
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">For Contents</a>
>>>
>>> i_tag
<i>technical & Non-technical</i>
>>>
>>> print(i_tag.parent)
Nonerozkładać się()
Tag.decompose () usuwa znacznik z drzewa i całą jego zawartość.
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical</i> Contents</a>'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical</i> Contents</a>
>>>
>>> soup.i.decompose()
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">For Contents</a>
>>>Zamienić()
Jak sama nazwa wskazuje, funkcja pageElement.replace_with () zastąpi stary tag lub ciąg nowym tagiem lub ciągiem w drzewie -
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">Complete Python <i>Material</i></a>'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>>
>>> new_tag = soup.new_tag("Official_site")
>>> new_tag.string = "https://www.python.org/"
>>> a_tag.i.replace_with(new_tag)
<i>Material</i>
>>>
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">Complete Python <Official_site>https://www.python.org/</Official_site></a>Na powyższym wyjściu zauważyłeś, że replace_with () zwraca tag lub ciąg, który został zastąpiony (jak „Materiał” w naszym przypadku), więc możesz go zbadać lub dodać z powrotem do innej części drzewa.
owinąć()
Metoda pageElement.wrap () ujęła element w określonym tagu i zwraca nowe opakowanie -
>>> soup = BeautifulSoup("<p>tutorialspoint.com</p>")
>>> soup.p.string.wrap(soup.new_tag("b"))
<b>tutorialspoint.com</b>
>>>
>>> soup.p.wrap(soup.new_tag("Div"))
<Div><p><b>tutorialspoint.com</b></p></Div>rozwijać()
Tag.unwrap () jest przeciwieństwem metody wrap () i zastępuje tag tym, co znajduje się wewnątrz tego tagu.
>>> soup = BeautifulSoup('<a href="https://www.tutorialspoint.com/">I liked <i>tutorialspoint</i></a>')
>>> a_tag = soup.a
>>>
>>> a_tag.i.unwrap()
<i></i>
>>> a_tag
<a href="https://www.tutorialspoint.com/">I liked tutorialspoint</a>Z góry zauważyłeś, że podobnie jak replace_with (), unrap () zwraca tag, który został zastąpiony.
Poniżej znajduje się jeszcze jeden przykład funkcji unrap (), aby lepiej to zrozumieć -
>>> soup = BeautifulSoup("<p>I <strong>AM</strong> a <i>text</i>.</p>")
>>> soup.i.unwrap()
<i></i>
>>> soup
<html><body><p>I <strong>AM</strong> a text.</p></body></html>unrap () jest dobre do usuwania znaczników.
Wszystkie dokumenty HTML lub XML są zapisywane w określonym kodowaniu, takim jak ASCII lub UTF-8. Jednak po załadowaniu tego dokumentu HTML / XML do BeautifulSoup został on przekonwertowany na Unicode.
>>> markup = "<p>I will display £</p>"
>>> Bsoup = BeautifulSoup(markup)
>>> Bsoup.p
<p>I will display £</p>
>>> Bsoup.p.string
'I will display £'Powyższe zachowanie wynika z tego, że BeautifulSoup wewnętrznie używa biblioteki podrzędnej o nazwie Unicode, Dammit, aby wykryć kodowanie dokumentu, a następnie przekonwertować go na Unicode.
Jednak nie zawsze Unicode, Dammit odgaduje poprawnie. Ponieważ dokument jest przeszukiwany bajt po bajcie, aby odgadnąć kodowanie, zajmuje to dużo czasu. Możesz zaoszczędzić trochę czasu i uniknąć błędów, jeśli znasz już kodowanie, przekazując je do konstruktora BeautifulSoup jako from_encoding.
Poniżej znajduje się przykład, w którym BeautifulSoup błędnie identyfikuje dokument ISO-8859-8 jako ISO-8859-7 -
>>> markup = b"<h1>\xed\xe5\xec\xf9</h1>"
>>> soup = BeautifulSoup(markup)
>>> soup.h1
<h1>νεμω</h1>
>>> soup.original_encoding
'ISO-8859-7'
>>>Aby rozwiązać powyższy problem, przekaż go do BeautifulSoup za pomocą from_encoding -
>>> soup = BeautifulSoup(markup, from_encoding="iso-8859-8")
>>> soup.h1
<h1>ולש </h1>
>>> soup.original_encoding
'iso-8859-8'
>>>Kolejną nową funkcją dodaną z BeautifulSoup 4.4.0 jest exclude_encoding. Można go użyć, gdy nie znasz prawidłowego kodowania, ale jesteś pewien, że Unicode, Cholera pokazuje zły wynik.
>>> soup = BeautifulSoup(markup, exclude_encodings=["ISO-8859-7"])Kodowanie wyjściowe
Dane wyjściowe z BeautifulSoup to dokument UTF-8, niezależnie od dokumentu wprowadzonego do BeautifulSoup. Poniżej dokument, w którym znajdują się polskie znaki w formacie ISO-8859-2.
html_markup = """
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<HTML>
<HEAD>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=iso-8859-2">
</HEAD>
<BODY>
ą ć ę ł ń ó ś ź ż Ą Ć Ę Ł Ń Ó Ś Ź Ż
</BODY>
</HTML>
"""
>>> soup = BeautifulSoup(html_markup)
>>> print(soup.prettify())
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<meta content="text/html; charset=utf-8" http-equiv="content-type"/>
</head>
<body>
ą ć ę ł ń ó ś ź ż Ą Ć Ę Ł Ń Ó Ś Ź Ż
</body>
</html>W powyższym przykładzie, jeśli zauważysz, tag <meta> został przepisany, aby odzwierciedlić wygenerowany dokument z BeautifulSoup jest teraz w formacie UTF-8.
Jeśli nie chcesz generowanego wyjścia w UTF-8, możesz przypisać żądane kodowanie w prettify ().
>>> print(soup.prettify("latin-1"))
b'<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">\n<html>\n <head>\n <meta content="text/html; charset=latin-1" http-equiv="content-type"/>\n </head>\n <body>\n ą ć ę ł ń \xf3 ś ź ż Ą Ć Ę Ł Ń \xd3 Ś Ź Ż\n </body>\n</html>\n'W powyższym przykładzie zakodowaliśmy cały dokument, jednak możesz zakodować dowolny element w zupie tak, jakby był ciągiem znaków Pythona -
>>> soup.p.encode("latin-1")
b'<p>0My first paragraph.</p>'
>>> soup.h1.encode("latin-1")
b'<h1>My First Heading</h1>'Wszelkie znaki, których nie można przedstawić w wybranym kodowaniu, zostaną przekonwertowane na numeryczne odniesienia do encji XML. Poniżej znajduje się jeden taki przykład -
>>> markup = u"<b>\N{SNOWMAN}</b>"
>>> snowman_soup = BeautifulSoup(markup)
>>> tag = snowman_soup.b
>>> print(tag.encode("utf-8"))
b'<b>\xe2\x98\x83</b>'Jeśli spróbujesz zakodować powyższe w „latin-1” lub „ascii”, wygeneruje „☃”, co oznacza, że nie ma dla tego reprezentacji.
>>> print (tag.encode("latin-1"))
b'<b>☃</b>'
>>> print (tag.encode("ascii"))
b'<b>☃</b>'Unicode, cholera
Unicode, Dammit jest używany głównie wtedy, gdy przychodzący dokument jest w nieznanym formacie (głównie w języku obcym) i chcemy zakodować w jakimś znanym formacie (Unicode), a także nie potrzebujemy do tego Beautifulsoup.
Punktem wyjścia każdego projektu BeautifulSoup jest obiekt BeautifulSoup. Obiekt BeautifulSoup reprezentuje wejściowy dokument HTML / XML użyty do jego utworzenia.
Możemy przekazać ciąg znaków lub obiekt podobny do pliku dla Beautiful Soup, gdzie pliki (obiekty) są lokalnie przechowywane na naszym komputerze lub na stronie internetowej.
Najpopularniejsze obiekty BeautifulSoup to -
- Tag
- NavigableString
- BeautifulSoup
- Comment
Porównywanie obiektów pod kątem równości
Podobnie jak w przypadku pięknej zupy, dwa obiekty ciągów lub tagów, po których można nawigować, są równe, jeśli reprezentują te same znaczniki HTML / XML.
Spójrzmy teraz na poniższy przykład, w którym dwa znaczniki <b> są traktowane jako równe, mimo że znajdują się w różnych częściach drzewa obiektów, ponieważ oba wyglądają jak „<b> Java </b>”.
>>> markup = "<p>Learn Python and <b>Java</b> and advanced <b>Java</b>! from Tutorialspoint</p>"
>>> soup = BeautifulSoup(markup, "html.parser")
>>> first_b, second_b = soup.find_all('b')
>>> print(first_b == second_b)
True
>>> print(first_b.previous_element == second_b.previous_element)
FalseJednakże, aby sprawdzić, czy te dwie zmienne odnoszą się do tych samych obiektów, możesz użyć następującego -
>>> print(first_b is second_b)
FalseKopiowanie pięknych obiektów zupy
Aby utworzyć kopię dowolnego tagu lub NavigableString, użyj funkcji copy.copy (), tak jak poniżej -
>>> import copy
>>> p_copy = copy.copy(soup.p)
>>> print(p_copy)
<p>Learn Python and <b>Java</b> and advanced <b>Java</b>! from Tutorialspoint</p>
>>>Chociaż dwie kopie (oryginalna i skopiowana) zawierają te same znaczniki, jednak nie reprezentują tego samego obiektu -
>>> print(soup.p == p_copy)
True
>>>
>>> print(soup.p is p_copy)
False
>>>Jedyną prawdziwą różnicą jest to, że kopia jest całkowicie oddzielona od oryginalnego drzewa obiektów Beautiful Soup, tak jakby została wywołana na niej extract ().
>>> print(p_copy.parent)
NonePowyższe zachowanie wynika z dwóch różnych obiektów etykiet, które nie mogą zajmować tego samego miejsca w tym samym czasie.
Istnieje wiele sytuacji, w których chcesz wyodrębnić określone typy informacji (tylko znaczniki <a>) za pomocą Beautifulsoup4. Klasa SoupStrainer w Beautifulsoup umożliwia analizowanie tylko określonej części przychodzącego dokumentu.
Jednym ze sposobów jest utworzenie SoupStrainer i przekazanie go konstruktorowi Beautifulsoup4 jako argumentu parse_only.
SoupStrainer
SoupStrainer mówi BeautifulSoup, które części wyodrębniają, a drzewo analizy składa się tylko z tych elementów. Jeśli zawęzisz wymagane informacje do określonej części kodu HTML, przyspieszy to wyniki wyszukiwania.
product = SoupStrainer('div',{'id': 'products_list'})
soup = BeautifulSoup(html,parse_only=product)Powyższe wiersze kodu przeanalizują tylko tytuły ze strony produktu, które mogą znajdować się w polu tagu.
Podobnie, jak powyżej, możemy użyć innych obiektów soupStrainer, aby przeanalizować określone informacje ze znacznika HTML. Poniżej znajduje się kilka przykładów -
from bs4 import BeautifulSoup, SoupStrainer
#Only "a" tags
only_a_tags = SoupStrainer("a")
#Will parse only the below mentioned "ids".
parse_only = SoupStrainer(id=["first", "third", "my_unique_id"])
soup = BeautifulSoup(my_document, "html.parser", parse_only=parse_only)
#parse only where string length is less than 10
def is_short_string(string):
return len(string) < 10
only_short_strings =SoupStrainer(string=is_short_string)Obsługa błędów
W BeautifulSoup należy obsłużyć dwa główne rodzaje błędów. Te dwa błędy nie pochodzą z Twojego skryptu, ale ze struktury fragmentu kodu, ponieważ interfejs API BeautifulSoup zgłasza błąd.
Dwa główne błędy są następujące -
AttributeError
Jest to spowodowane tym, że notacja kropkowa nie znajduje tagu równorzędnego dla bieżącego tagu HTML. Na przykład mógł wystąpić ten błąd z powodu braku „tagu kotwicy”, klucz kosztu zgłosi błąd podczas przechodzenia i wymaga tagu kotwicy.
KeyError
Ten błąd występuje, jeśli brakuje wymaganego atrybutu tagu HTML. Na przykład, jeśli nie mamy atrybutu data-pid we fragmencie kodu, klucz pid zgłosi błąd klucza.
Aby uniknąć dwóch wymienionych powyżej błędów podczas analizowania wyniku, ten wynik zostanie pominięty, aby upewnić się, że źle sformułowany fragment nie zostanie wstawiony do baz danych -
except(AttributeError, KeyError) as er:
passrozpoznać chorobę()
Ilekroć napotkamy trudności w zrozumieniu, co robi BeautifulSoup z naszym dokumentem lub HTML, po prostu przekaż to do funkcji diagnose (). Przekazując plik dokumentu do funkcji diagnose (), możemy pokazać, jak lista różnych parserów obsługuje dokument.
Poniżej znajduje się przykład ilustrujący użycie funkcji diagnose () -
from bs4.diagnose import diagnose
with open("20 Books.html",encoding="utf8") as fp:
data = fp.read()
diagnose(data)Wynik
Błąd analizy
Istnieją dwa główne typy błędów analizy. Możesz otrzymać wyjątek, taki jak HTMLParseError, podczas przesyłania dokumentu do BeautifulSoup. Możesz również otrzymać nieoczekiwany wynik, w którym drzewo analizy BeautifulSoup wygląda znacznie inaczej niż oczekiwany wynik z dokumentu analizy.
Żaden z błędów analizy nie jest spowodowany przez BeautifulSoup. Dzieje się tak z powodu zewnętrznego parsera, którego używamy (html5lib, lxml), ponieważ BeautifulSoup nie zawiera żadnego kodu parsera. Jednym ze sposobów rozwiązania powyższego błędu analizy jest użycie innego parsera.
from HTMLParser import HTMLParser
try:
from HTMLParser import HTMLParseError
except ImportError, e:
# From python 3.5, HTMLParseError is removed. Since it can never be
# thrown in 3.5, we can just define our own class as a placeholder.
class HTMLParseError(Exception):
passWbudowany parser HTML w Pythonie powoduje dwa najczęstsze błędy parsowania: HTMLParser.HTMLParserError: nieprawidłowy tag początkowy i HTMLParser.HTMLParserError: zły tag końcowy. Aby rozwiązać ten problem, należy użyć innego parsera, głównie: lxml lub html5lib.
Innym częstym rodzajem nieoczekiwanego zachowania jest to, że nie możesz znaleźć znacznika, o którym wiesz, że znajduje się w dokumencie. Jednak po uruchomieniu find_all () zwraca [] lub find () zwraca None.
Może to być spowodowane tym, że parser HTML wbudowany w Python czasami pomija tagi, których nie rozumie.
Błąd parsera XML
Domyślnie pakiet BeautifulSoup analizuje dokumenty jako HTML, jednak jest bardzo łatwy w użyciu i obsługuje źle sformułowany XML w bardzo elegancki sposób, używając beautifulsoup4.
Aby przeanalizować dokument jako XML, musisz mieć parser lxml i wystarczy przekazać „xml” jako drugi argument do konstruktora Beautifulsoup -
soup = BeautifulSoup(markup, "lxml-xml")lub
soup = BeautifulSoup(markup, "xml")Jednym z typowych błędów analizy XML jest -
AttributeError: 'NoneType' object has no attribute 'attrib'Może się to zdarzyć w przypadku, gdy brakuje jakiegoś elementu lub nie jest on zdefiniowany podczas korzystania z funkcji find () lub findall ().
Inne błędy analizy
Poniżej podano kilka innych błędów analizy, które omówimy w tej sekcji -
Problem środowiskowy
Oprócz wspomnianych powyżej błędów analizy, możesz napotkać inne problemy z analizą, takie jak problemy środowiskowe, w których twój skrypt może działać w jednym systemie operacyjnym, ale nie w innym systemie operacyjnym lub może działać w jednym środowisku wirtualnym, ale nie w innym środowisku wirtualnym lub może nie działać poza środowiskiem wirtualnym. Wszystkie te problemy mogą wynikać z tego, że oba środowiska mają dostępne różne biblioteki parserów.
Zaleca się poznanie lub sprawdzenie domyślnego parsera w bieżącym środowisku pracy. Możesz sprawdzić bieżący domyślny parser dostępny dla bieżącego środowiska pracy lub przekazać jawnie wymaganą bibliotekę parsera jako drugie argumenty do konstruktora BeautifulSoup.
Bez rozróżniania wielkości liter
Ponieważ w znacznikach i atrybutach HTML wielkość liter nie jest rozróżniana, wszystkie trzy parsery HTML konwertują nazwy znaczników i atrybutów na małe litery. Jeśli jednak chcesz zachować znaczniki i atrybuty pisane wielkimi lub dużymi literami, lepiej przeanalizować dokument jako XML.
UnicodeEncodeError
Przyjrzyjmy się poniższemu segmentowi kodu -
soup = BeautifulSoup(response, "html.parser")
print (soup)Wynik
UnicodeEncodeError: 'charmap' codec can't encode character '\u011f'Powyższy problem może wynikać z dwóch głównych sytuacji. Być może próbujesz wydrukować znak Unicode, którego Twoja konsola nie potrafi wyświetlić. Po drugie, próbujesz pisać do pliku i przekazujesz znak Unicode, który nie jest obsługiwany przez domyślne kodowanie.
Jednym ze sposobów rozwiązania powyższego problemu jest zakodowanie tekstu / znaku odpowiedzi przed przygotowaniem zupy, aby uzyskać pożądany rezultat, w następujący sposób -
responseTxt = response.text.encode('UTF-8')KeyError: [atr]
Jest to spowodowane dostępem do tagu ['attr'], gdy dany tag nie definiuje atrybutu attr. Najczęstsze błędy to: „KeyError: 'href'” i „KeyError: 'class'”. Użyj tag.get ('attr'), jeśli nie jesteś pewien, czy attr jest zdefiniowany.
for item in soup.fetch('a'):
try:
if (item['href'].startswith('/') or "tutorialspoint" in item['href']):
(...)
except KeyError:
pass # or some other fallback actionAttributeError
Możesz napotkać AttributeError w następujący sposób -
AttributeError: 'list' object has no attribute 'find_all'Powyższy błąd występuje głównie dlatego, że oczekiwano, że funkcja find_all () zwróci pojedynczy znacznik lub ciąg. Jednak soup.find_all zwraca listę elementów w języku Python.
Wszystko, co musisz zrobić, to powtórzyć listę i złapać dane z tych elementów.