Piękna Zupa - Zupa na Stronie
W poprzednim przykładzie kodu analizujemy dokument za pomocą pięknego konstruktora przy użyciu metody string. Innym sposobem jest przekazanie dokumentu przez otwarty uchwyt pliku.
from bs4 import BeautifulSoup
with open("example.html") as fp:
soup = BeautifulSoup(fp)
soup = BeautifulSoup("<html>data</html>")Najpierw dokument jest konwertowany na Unicode, a encje HTML są konwertowane na znaki Unicode: </p>
import bs4
html = '''<b>tutorialspoint</b>, <i>&web scraping &data science;</i>'''
soup = bs4.BeautifulSoup(html, 'lxml')
print(soup)Wynik
<html><body><b>tutorialspoint</b>, <i>&web scraping &data science;</i></body></html>BeautifulSoup analizuje następnie dane za pomocą parsera HTML lub jawnie nakazujesz analizować za pomocą parsera XML.
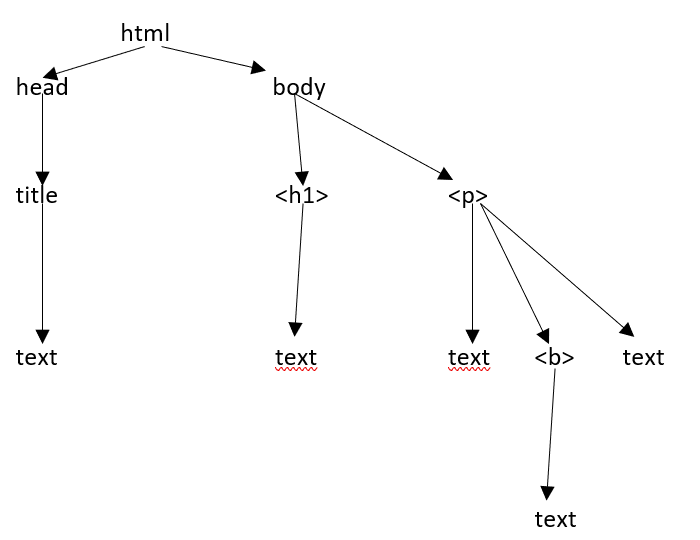
Struktura drzewa HTML
Zanim przyjrzymy się różnym komponentom strony HTML, najpierw zrozumiemy strukturę drzewa HTML.
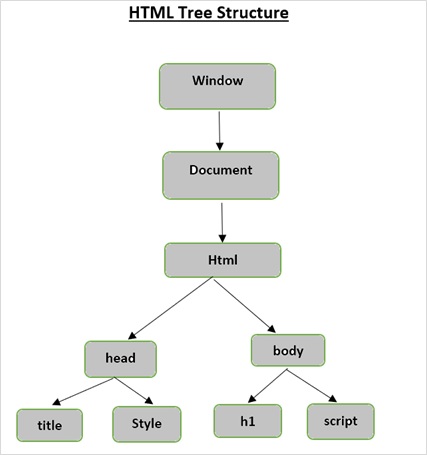
Elementem głównym w drzewie dokumentu jest html, który może mieć rodziców, dzieci i rodzeństwo, o czym decyduje jego pozycja w strukturze drzewa. Aby poruszać się między elementami HTML, atrybutami i tekstem, musisz poruszać się między węzłami w strukturze drzewa.
Załóżmy, że strona internetowa jest taka, jak pokazano poniżej -
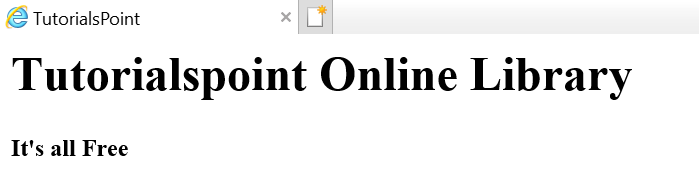
Co przekłada się na dokument HTML w następujący sposób -
<html><head><title>TutorialsPoint</title></head><h1>Tutorialspoint Online Library</h1><p<<b>It's all Free</b></p></body></html>Co po prostu oznacza, że dla powyższego dokumentu HTML mamy następującą strukturę drzewa html -