Systemy wbudowane - język asemblera
Opracowano języki asemblera, aby zapewnić mnemonicslub symbole instrukcji kodowych na poziomie maszyny. Programy w języku asemblerowym składają się z mnemoników, dlatego powinny być przetłumaczone na kod maszynowy. Program odpowiedzialny za tę konwersję jest znany jakoassembler. Język asemblera jest często określany jako język niskiego poziomu, ponieważ bezpośrednio współpracuje z wewnętrzną strukturą procesora. Aby programować w języku asemblera, programista musi znać wszystkie rejestry CPU.
Różne języki programowania, takie jak C, C ++, Java i różne inne języki nazywane są językami wysokiego poziomu, ponieważ nie zajmują się wewnętrznymi szczegółami procesora. W przeciwieństwie do tego, asembler jest używany do tłumaczenia programu w języku asemblera na kod maszynowy (czasami nazywany równieżobject code lub opcode). Podobnie kompilator tłumaczy język wysokiego poziomu na kod maszynowy. Na przykład, aby napisać program w języku C, należy użyć kompilatora C, aby przetłumaczyć program na język maszynowy.
Struktura języka asemblera
Program w języku asemblerowym to seria instrukcji, które są albo instrukcjami języka asemblera, takimi jak ADD i MOV, albo instrukcjami nazwanymi directives.
Na instruction mówi procesorowi, co ma robić, a plik directive (nazywany również pseudo-instructions) podaje instrukcje asemblerowi. Na przykład instrukcje ADD i MOV to polecenia uruchamiane przez procesor, podczas gdy ORG i END są dyrektywami asemblera. Asembler umieszcza opcode w lokalizacji pamięci 0, gdy używana jest dyrektywa ORG, podczas gdy END wskazuje na koniec kodu źródłowego. Instrukcja języka programu składa się z następujących czterech pól -
[ label: ] mnemonics [ operands ] [;comment ]Nawias kwadratowy ([]) oznacza, że pole jest opcjonalne.
Plik label fieldumożliwia programowi odwoływanie się do wiersza kodu według nazwy. Pola etykiet nie mogą przekraczać określonej liczby znaków.
Plik mnemonics i operands fieldswspólnie wykonują rzeczywistą pracę programu i realizują zadania. Instrukcje takie jak ADD A, C i MOV C, # 68, gdzie ADD i MOV to mnemoniki, które tworzą rozkazy; „A, C” i „C, # 68” to operandy. Te dwa pola mogą zawierać dyrektywy. Dyrektywy nie generują kodu maszynowego i są używane tylko przez asembler, podczas gdy instrukcje są tłumaczone na kod maszynowy, aby procesor mógł je wykonać.
1.0000 ORG 0H ;start (origin) at location 0
2 0000 7D25 MOV R5,#25H ;load 25H into R5
3.0002 7F34 MOV R7,#34H ;load 34H into R7
4.0004 7400 MOV A,#0 ;load 0 into A
5.0006 2D ADD A,R5 ;add contents of R5 to A
6.0007 2F ADD A,R7 ;add contents of R7 to A
7.0008 2412 ADD A,#12H ;add to A value 12 H
8.000A 80FE HERE: SJMP HERE ;stay in this loop
9.000C END ;end of asm source filePlik comment field zaczyna się średnikiem, który jest wskaźnikiem komentarza.
Zwróć uwagę na etykietę „TUTAJ” w programie. Po każdej etykiecie odnoszącej się do instrukcji należy umieścić dwukropek.
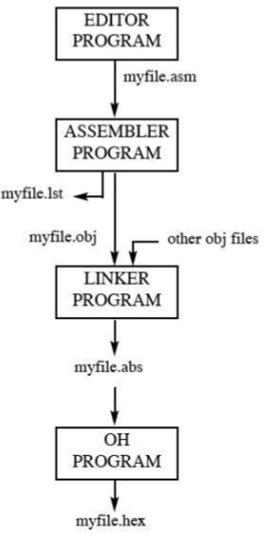
Składanie i uruchamianie programu 8051
Tutaj omówimy podstawową formę języka asemblera. Kroki tworzenia, asemblacji i uruchamiania programu w języku asemblerowym są następujące:
Najpierw używamy edytora, aby wpisać program podobny do powyższego programu. Do tworzenia lub edytowania programów można używać edytorów, takich jak program MS-DOS EDIT, który jest dostarczany ze wszystkimi systemami operacyjnymi firmy Microsoft. Edytor musi mieć możliwość utworzenia pliku ASCII. Rozszerzenie „asm” dla pliku źródłowego jest używane przez asemblera w następnym kroku.
Plik źródłowy „asm” zawiera kod programu utworzony w kroku 1. Jest on przekazywany do asemblera 8051. Następnie asembler konwertuje instrukcje języka asemblera na instrukcje kodu maszynowego i tworzy plik.obj file (plik obiektu) i plik .lst file(plik listy). Jest również nazywany jakosource file, dlatego niektóre asemblery wymagają, aby ten plik miał rozszerzenie „src”. Plik „lst” jest opcjonalny. Jest to bardzo przydatne dla programu, ponieważ zawiera listę wszystkich kodów operacyjnych i adresów, a także błędów, które wykryły asemblery.
Asemblery wymagają trzeciego kroku o nazwie linking. Program łączący pobiera jeden lub więcej plików obiektowych i tworzy absolutny plik obiektowy z rozszerzeniem „abs”.
Następnie plik „abs” jest podawany do programu o nazwie „OH” (konwerter obiektu na hex), który tworzy plik z rozszerzeniem „hex”, który jest gotowy do wypalenia w pamięci ROM.
Typ danych
Mikrokontroler 8051 zawiera pojedynczy typ danych 8-bitowych, a każdy rejestr ma również rozmiar 8-bitowy. Programista musi rozbić dane większe niż 8-bitowe (od 00 do FFH lub do 255 dziesiętnie), aby mogły być przetwarzane przez procesor.
DB (zdefiniuj bajt)
Dyrektywa DB jest najczęściej używaną dyrektywą danych w asemblerze. Służy do definiowania 8-bitowych danych. Może być również używany do definiowania danych w formacie dziesiętnym, binarnym, szesnastkowym lub ASCII. W przypadku liczb dziesiętnych litera „D” po liczbie dziesiętnej jest opcjonalna, ale jest wymagana w przypadku znaków „B” (binarne) i „Hl” (szesnastkowe).
Aby wskazać ASCII, po prostu umieść znaki w cudzysłowie („jak to”). Asembler automatycznie generuje kod ASCII dla liczb / znaków. Dyrektywa DB jest jedyną dyrektywą, której można użyć do zdefiniowania łańcuchów ASCII większych niż dwa znaki; dlatego powinien być używany dla wszystkich definicji danych ASCII. Kilka przykładów DB podano poniżej -
ORG 500H
DATA1: DB 28 ;DECIMAL (1C in hex)
DATA2: DB 00110101B ;BINARY (35 in hex)
DATA3: DB 39H ;HEX
ORG 510H
DATA4: DB "2591" ;ASCII NUMBERS
ORG 520H
DATA6: DA "MY NAME IS Michael" ;ASCII CHARACTERSWokół ciągów znaków ASCII można używać pojedynczych lub podwójnych cudzysłowów. Baza danych jest również używana do przydzielania pamięci w fragmentach o wielkości bajtów.
Dyrektywy asemblera
Niektóre z dyrektyw 8051 są następujące -
ORG (origin)- Dyrektywa pochodzenia służy do wskazania początku adresu. Przyjmuje liczby w formacie szesnastkowym lub dziesiętnym. Jeśli po liczbie podano H, liczba jest traktowana jako szesnastkowa, w przeciwnym razie dziesiętna. Asembler konwertuje liczbę dziesiętną na szesnastkową.
EQU (equate)- Służy do definiowania stałej bez zajmowania miejsca w pamięci. EQU wiąże stałą wartość z etykietą danych, dzięki czemu etykieta pojawia się w programie, jej stała wartość zostanie zastąpiona etykietą. Podczas wykonywania instrukcji „MOV R3, #COUNT” do rejestru R3 zostanie załadowana wartość 25 (zwróć uwagę na znak #). Zaletą używania EQU jest to, że programista może zmienić go raz, a asembler zmieni wszystkie jego wystąpienia; programista nie musi przeszukiwać całego programu.
END directive- Wskazuje koniec pliku źródłowego (asm). Dyrektywa END to ostatnia linia programu; wszystko po dyrektywie END jest ignorowane przez asemblera.
Etykiety w języku asemblera
Wszystkie etykiety w języku asemblera muszą być zgodne z zasadami podanymi poniżej -
Każda nazwa etykiety musi być niepowtarzalna. Nazwy używane do etykiet w programowaniu w asemblerze składają się z liter alfabetu dużych i małych, cyfr od 0 do 9 oraz znaków specjalnych, takich jak znak zapytania (?), Kropka (.), W wysokości @, podkreślenie (_), i dolara ($).
Pierwsza litera powinna być zapisana alfabetycznie; nie może to być liczba.
Zarezerwowanych słów nie można używać jako etykiet w programie. Na przykład słowa ADD i MOV są słowami zastrzeżonymi, ponieważ są mnemonikami instrukcji.