Gensim - Tworzenie osadzania słów
Ten rozdział pomoże nam zrozumieć osadzanie słów rozwijających się w Gensim.
Osadzanie słów, podejście do reprezentowania słów i dokumentów, to gęsta reprezentacja wektorowa tekstu, w której słowa o tym samym znaczeniu mają podobną reprezentację. Poniżej przedstawiono niektóre cechy osadzania słów -
Jest to klasa techniki, która przedstawia poszczególne słowa jako wektory o wartościach rzeczywistych w określonej przestrzeni wektorowej.
Technika ta jest często umieszczana w polu DL (głębokiego uczenia się), ponieważ każde słowo jest mapowane na jeden wektor, a wartości wektorów są uczone w taki sam sposób, jak NN (sieci neuronowe).
Kluczowym podejściem do techniki osadzania słów jest gęsto rozmieszczona reprezentacja każdego słowa.
Różne metody / algorytmy osadzania słów
Jak omówiono powyżej, metody / algorytmy osadzania słów uczą się reprezentacji wektorowej o wartościach rzeczywistych z korpusu tekstu. Ten proces uczenia się może być używany z modelem NN w zadaniach, takich jak klasyfikacja dokumentów, lub jest procesem nienadzorowanym, takim jak statystyki dokumentów. Tutaj omówimy dwie metody / algorytmy, których można użyć do nauki osadzania słowa z tekstu -
Word2Vec firmy Google
Word2Vec, opracowany przez Tomasa Mikolova i in. glin. w Google w 2013 roku jest metodą statystyczną do efektywnego uczenia się osadzania słów z korpusu tekstu. W rzeczywistości został opracowany w odpowiedzi na zwiększenie wydajności uczenia osadzania słów w oparciu o NN. Stało się de facto standardem osadzania słów.
Osadzanie słów przez Word2Vec obejmuje analizę wyuczonych wektorów, a także eksplorację matematyki wektorowej na reprezentacji słów. Poniżej znajdują się dwie różne metody uczenia się, które można wykorzystać jako część metody Word2Vec -
- Model CBoW (ciągły zbiór słów)
- Ciągły model Skip-Gram
GloVe firmy Standford
GloVe (Global vectors for Word Representation) to rozszerzenie metody Word2Vec. Został opracowany przez Penningtona i wsp. w Stanford. Algorytm GloVe jest połączeniem obu -
- Globalne statystyki technik faktoryzacji macierzy, takich jak LSA (Latent Semantic Analysis)
- Lokalne uczenie się oparte na kontekście w Word2Vec.
Jeśli mówimy o jego działaniu, zamiast używać okna do definiowania lokalnego kontekstu, GloVe konstruuje jawną macierz współwystępowania słów, używając statystyk w całym korpusie tekstu.
Tworzenie osadzania Word2Vec
Tutaj będziemy rozwijać osadzanie Word2Vec przy użyciu Gensim. Aby pracować z modelem Word2Vec, Gensim zapewnia namWord2Vec klasa, z której można importować models.word2vec. Do swojej implementacji word2vec wymaga dużej ilości tekstu, np. Całego korpusu recenzji Amazon. Ale tutaj zastosujemy tę zasadę do tekstu o małej pamięci.
Przykład implementacji
Najpierw musimy zaimportować klasę Word2Vec z gensim.models w następujący sposób -
from gensim.models import Word2VecNastępnie musimy zdefiniować dane treningowe. Zamiast brać duży plik tekstowy, używamy kilku zdań, aby zaimplementować tę zasadę.
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]Po dostarczeniu danych szkoleniowych musimy wytrenować model. można to zrobić w następujący sposób -
model = Word2Vec(sentences, min_count=1)Możemy podsumować model w następujący sposób -;
print(model)Możemy podsumować słownictwo w następujący sposób -
words = list(model.wv.vocab)
print(words)Następnie przejdźmy do wektora dla jednego słowa. Robimy to dla słowa „tutorial”.
print(model['tutorial'])Następnie musimy zapisać model -
model.save('model.bin')Następnie musimy załadować model -
new_model = Word2Vec.load('model.bin')Na koniec wydrukuj zapisany model w następujący sposób -
print(new_model)Pełny przykład implementacji
from gensim.models import Word2Vec
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
print(model)
words = list(model.wv.vocab)
print(words)
print(model['tutorial'])
model.save('model.bin')
new_model = Word2Vec.load('model.bin')
print(new_model)Wynik
Word2Vec(vocab=20, size=100, alpha=0.025)
[
'this', 'is', 'gensim', 'tutorial', 'for', 'free', 'the', 'tutorialspoint',
'website', 'you', 'can', 'read', 'technical', 'tutorials', 'we', 'are',
'implementing', 'word2vec', 'learn', 'full'
]
[
-2.5256255e-03 -4.5352755e-03 3.9024993e-03 -4.9509313e-03
-1.4255195e-03 -4.0217536e-03 4.9407515e-03 -3.5925603e-03
-1.1933431e-03 -4.6682903e-03 1.5440651e-03 -1.4101702e-03
3.5070938e-03 1.0914479e-03 2.3334436e-03 2.4452661e-03
-2.5336299e-04 -3.9676363e-03 -8.5054158e-04 1.6443320e-03
-4.9968651e-03 1.0974540e-03 -1.1123562e-03 1.5393364e-03
9.8941079e-04 -1.2656028e-03 -4.4471184e-03 1.8309267e-03
4.9302122e-03 -1.0032534e-03 4.6892050e-03 2.9563988e-03
1.8730218e-03 1.5343715e-03 -1.2685956e-03 8.3664013e-04
4.1721235e-03 1.9445885e-03 2.4097660e-03 3.7517555e-03
4.9687522e-03 -1.3598346e-03 7.1032363e-04 -3.6595813e-03
6.0000515e-04 3.0872561e-03 -3.2115565e-03 3.2270295e-03
-2.6354722e-03 -3.4988276e-04 1.8574356e-04 -3.5757164e-03
7.5391348e-04 -3.5205986e-03 -1.9795434e-03 -2.8321696e-03
4.7155009e-03 -4.3349937e-04 -1.5320212e-03 2.7013756e-03
-3.7055744e-03 -4.1658725e-03 4.8034848e-03 4.8594419e-03
3.7129463e-03 4.2385766e-03 2.4612297e-03 5.4920948e-04
-3.8912550e-03 -4.8226118e-03 -2.2763973e-04 4.5571579e-03
-3.4609400e-03 2.7903817e-03 -3.2709218e-03 -1.1036445e-03
2.1492650e-03 -3.0384419e-04 1.7709908e-03 1.8429896e-03
-3.4038599e-03 -2.4872608e-03 2.7693063e-03 -1.6352943e-03
1.9182395e-03 3.7772327e-03 2.2769428e-03 -4.4629495e-03
3.3151123e-03 4.6509290e-03 -4.8521687e-03 6.7615538e-04
3.1034781e-03 2.6369948e-05 4.1454583e-03 -3.6932561e-03
-1.8769916e-03 -2.1958587e-04 6.3395966e-04 -2.4969708e-03
]
Word2Vec(vocab=20, size=100, alpha=0.025)Wizualizacja osadzania słów
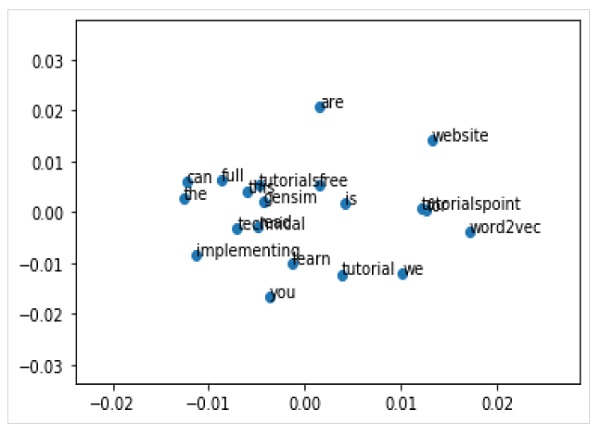
Możemy również zbadać osadzanie słów za pomocą wizualizacji. Można to zrobić za pomocą klasycznej metody rzutowania (takiej jak PCA), aby zredukować wielowymiarowe wektory słów do wykresów 2-D. Po zmniejszeniu możemy przedstawić je na wykresie.
Wykreślanie wektorów słownych za pomocą PCA
Najpierw musimy pobrać wszystkie wektory z wytrenowanego modelu w następujący sposób -
Z = model[model.wv.vocab]Następnie musimy utworzyć model 2-D PCA wektorów słów przy użyciu klasy PCA w następujący sposób -
pca = PCA(n_components=2)
result = pca.fit_transform(Z)Teraz możemy wykreślić wynikową projekcję za pomocą matplotlib w następujący sposób -
Pyplot.scatter(result[:,0],result[:,1])Możemy również opisać punkty na wykresie za pomocą samych słów. Wykreśl wynikowy rzut za pomocą matplotlib w następujący sposób -
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))Pełny przykład implementacji
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from matplotlib import pyplot
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
X = model[model.wv.vocab]
pca = PCA(n_components=2)
result = pca.fit_transform(X)
pyplot.scatter(result[:, 0], result[:, 1])
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))
pyplot.show()Wynik