HBase - instalacja
W tym rozdziale wyjaśniono, jak instaluje się i początkowo konfiguruje HBase. Java i Hadoop są wymagane do kontynuowania HBase, więc musisz pobrać i zainstalować Javę i Hadoop w swoim systemie.
Konfiguracja przed instalacją
Przed zainstalowaniem Hadoopa w środowisku Linux, musimy skonfigurować Linuksa przy użyciu ssh(Bezpieczna powłoka). Wykonaj poniższe czynności, aby skonfigurować środowisko Linux.
Tworzenie użytkownika
Przede wszystkim zaleca się utworzenie oddzielnego użytkownika dla Hadoop w celu odizolowania systemu plików Hadoop od systemu plików Unix. Wykonaj poniższe czynności, aby utworzyć użytkownika.
- Otwórz root za pomocą polecenia „su”.
- Utwórz użytkownika z konta root za pomocą polecenia „useradd username”.
- Teraz możesz otworzyć istniejące konto użytkownika za pomocą polecenia „su nazwa użytkownika”.
Otwórz terminal Linux i wpisz następujące polecenia, aby utworzyć użytkownika.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdKonfiguracja SSH i generowanie klucza
Konfiguracja SSH jest wymagana do wykonywania różnych operacji w klastrze, takich jak uruchamianie, zatrzymywanie i rozproszone operacje powłoki demona. Aby uwierzytelnić różnych użytkowników Hadoop, wymagane jest podanie pary kluczy publiczny / prywatny dla użytkownika Hadoop i udostępnienie go różnym użytkownikom.
Poniższe polecenia służą do generowania pary klucz-wartość przy użyciu protokołu SSH. Skopiuj klucze publiczne z formularza id_rsa.pub do Authorized_keys i zapewnij właścicielowi, odpowiednio, uprawnienia do odczytu i zapisu w pliku allowed_keys.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keysSprawdź ssh
ssh localhostInstalowanie Java
Java jest głównym wymaganiem wstępnym dla Hadoop i HBase. Przede wszystkim powinieneś zweryfikować istnienie javy w twoim systemie używając “java -version”. Poniżej podano składnię polecenia wersji java.
$ java -versionJeśli wszystko działa dobrze, otrzymasz następujący wynik.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Jeśli java nie jest zainstalowana w twoim systemie, wykonaj poniższe kroki, aby zainstalować java.
Krok 1
Pobierz java (JDK <najnowsza wersja> - X64.tar.gz), odwiedzając poniższy link Oracle Java .
Następnie jdk-7u71-linux-x64.tar.gz zostaną pobrane do twojego systemu.
Krok 2
Pobrany plik java znajdziesz zazwyczaj w folderze Pobrane. Sprawdź go i wyodrębnij plikjdk-7u71-linux-x64.gz plik za pomocą następujących poleceń.
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzKrok 3
Aby udostępnić Javę wszystkim użytkownikom, musisz przenieść ją do lokalizacji „/ usr / local /”. Otwórz root i wpisz następujące polecenia.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitKrok 4
Do konfiguracji PATH i JAVA_HOME zmienne, dodaj następujące polecenia do ~/.bashrc plik.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH= $PATH:$JAVA_HOME/binTeraz zastosuj wszystkie zmiany w aktualnie działającym systemie.
$ source ~/.bashrcKrok 5
Użyj następujących poleceń, aby skonfigurować alternatywy Java:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarTeraz zweryfikuj java -version polecenie z terminala, jak wyjaśniono powyżej.
Pobieranie Hadoop
Po zainstalowaniu Java, musisz zainstalować Hadoop. Przede wszystkim sprawdź istnienie Hadoop za pomocą polecenia „Wersja Hadoop”, jak pokazano poniżej.
hadoop versionJeśli wszystko działa dobrze, otrzymasz następujący wynik.
Hadoop 2.6.0
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using
/home/hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jarJeśli Twój system nie może zlokalizować Hadoop, pobierz Hadoop w swoim systemie. Aby to zrobić, postępuj zgodnie z poleceniami podanymi poniżej.
Pobierz i wyodrębnij hadoop-2.6.0 z Apache Software Foundation, używając następujących poleceń.
$ su
password:
# cd /usr/local
# wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-
2.6.0/hadoop-2.6.0-src.tar.gz
# tar xzf hadoop-2.6.0-src.tar.gz
# mv hadoop-2.6.0/* hadoop/
# exitInstalowanie Hadoop
Zainstaluj Hadoop w dowolnym wymaganym trybie. Tutaj demonstrujemy funkcjonalności HBase w trybie pseudo rozproszonym, dlatego zainstaluj Hadoop w trybie pseudo rozproszonym.
Podczas instalacji wykonywane są następujące kroki Hadoop 2.4.1.
Krok 1 - Konfiguracja Hadoop
Możesz ustawić zmienne środowiskowe Hadoop, dołączając następujące polecenia do ~/.bashrc plik.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOMETeraz zastosuj wszystkie zmiany w aktualnie działającym systemie.
$ source ~/.bashrcKrok 2 - Konfiguracja Hadoop
Wszystkie pliki konfiguracyjne Hadoop można znaleźć w lokalizacji „$ HADOOP_HOME / etc / hadoop”. Musisz wprowadzić zmiany w tych plikach konfiguracyjnych zgodnie z infrastrukturą Hadoop.
$ cd $HADOOP_HOME/etc/hadoopAby tworzyć programy Hadoop w Javie, musisz zresetować zmienną środowiskową Java w hadoop-env.sh plik, zastępując JAVA_HOME wartość wraz z lokalizacją Java w systemie.
export JAVA_HOME=/usr/local/jdk1.7.0_71Będziesz musiał edytować następujące pliki, aby skonfigurować Hadoop.
core-site.xml
Plik core-site.xml plik zawiera informacje, takie jak numer portu używanego dla wystąpienia Hadoop, pamięć przydzielona dla systemu plików, limit pamięci do przechowywania danych i rozmiar buforów do odczytu / zapisu.
Otwórz plik core-site.xml i dodaj następujące właściwości między tagami <configuration> i </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
Plik hdfs-site.xml plik zawiera informacje, takie jak wartość danych replikacji, ścieżka nazwy i ścieżki danych lokalnych systemów plików, w których chcesz przechowywać infrastrukturę Hadoop.
Przyjmijmy następujące dane.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeOtwórz ten plik i dodaj następujące właściwości między tagami <configuration>, </configuration>.
<configuration>
<property>
<name>dfs.replication</name >
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note: W powyższym pliku wszystkie wartości właściwości są zdefiniowane przez użytkownika i można wprowadzać zmiany zgodnie z infrastrukturą Hadoop.
yarn-site.xml
Ten plik służy do konfigurowania przędzy w Hadoop. Otwórz plik yarn-site.xml i dodaj następującą właściwość między <configuration $ gt ;, </ configuration $ gt; tagi w tym pliku.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Ten plik jest używany do określenia, której platformy MapReduce używamy. Domyślnie Hadoop zawiera szablon yarn-site.xml. Przede wszystkim należy skopiować plik zmapred-site.xml.template do mapred-site.xml plik za pomocą następującego polecenia.
$ cp mapred-site.xml.template mapred-site.xmlotwarty mapred-site.xml file i dodaj następujące właściwości między tagami <configuration> i </configuration>.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Weryfikacja instalacji Hadoop
Poniższe kroki służą do weryfikacji instalacji Hadoop.
Krok 1 - Konfiguracja nazwy węzła
Skonfiguruj namenode za pomocą polecenia „hdfs namenode -format” w następujący sposób.
$ cd ~
$ hdfs namenode -formatOczekiwany wynik jest następujący.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Krok 2 - Weryfikacja plików dfs na platformie Hadoop
Następujące polecenie służy do uruchamiania dfs. Wykonanie tego polecenia spowoduje uruchomienie systemu plików Hadoop.
$ start-dfs.shOczekiwany wynik jest następujący.
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Krok 3 - weryfikacja skryptu przędzy
Następujące polecenie służy do uruchamiania skryptu przędzy. Wykonanie tego polecenia spowoduje uruchomienie demonów przędzy.
$ start-yarn.shOczekiwany wynik jest następujący.
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outKrok 4 - Dostęp do Hadoop w przeglądarce
Domyślny numer portu dostępu do Hadoop to 50070. Użyj następującego adresu URL, aby pobrać usługi Hadoop w przeglądarce.
http://localhost:50070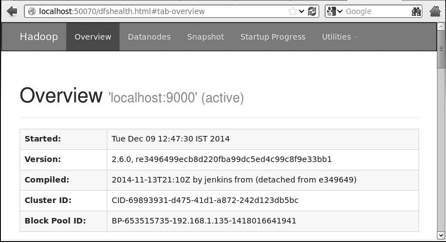
Krok 5 - Sprawdź wszystkie aplikacje klastra
Domyślny numer portu dostępu do wszystkich aplikacji klastra to 8088. Aby odwiedzić tę usługę, użyj następującego adresu URL.
http://localhost:8088/
Instalowanie HBase
Możemy zainstalować HBase w dowolnym z trzech trybów: trybie autonomicznym, trybie pseudo rozproszonym i trybie pełnej dystrybucji.
Instalowanie HBase w trybie autonomicznym
Pobierz najnowszą stabilną wersję formularza HBase http://www.interior-dsgn.com/apache/hbase/stable/używając polecenia „wget” i wyodrębnij go za pomocą polecenia tar „zxvf”. Zobacz następujące polecenie.
$cd usr/local/
$wget http://www.interior-dsgn.com/apache/hbase/stable/hbase-0.98.8-
hadoop2-bin.tar.gz
$tar -zxvf hbase-0.98.8-hadoop2-bin.tar.gzPrzejdź do trybu superużytkownika i przenieś folder HBase do / usr / local, jak pokazano poniżej.
$su
$password: enter your password here
mv hbase-0.99.1/* Hbase/Konfigurowanie HBase w trybie autonomicznym
Przed kontynuowaniem z HBase, musisz edytować następujące pliki i skonfigurować HBase.
hbase-env.sh
Ustaw java Home dla HBase i otwórz hbase-env.shplik z folderu conf. Edytuj zmienną środowiskową JAVA_HOME i zmień istniejącą ścieżkę do bieżącej zmiennej JAVA_HOME, jak pokazano poniżej.
cd /usr/local/Hbase/conf
gedit hbase-env.shSpowoduje to otwarcie pliku env.sh HBase. Teraz zamień istniejąceJAVA_HOME wartość z aktualną wartością, jak pokazano poniżej.
export JAVA_HOME=/usr/lib/jvm/java-1.7.0hbase-site.xml
To jest główny plik konfiguracyjny HBase. Ustaw katalog danych w odpowiedniej lokalizacji, otwierając folder macierzysty HBase w / usr / local / HBase. W folderze conf znajdziesz kilka plików, otwórz plikhbase-site.xml plik, jak pokazano poniżej.
#cd /usr/local/HBase/
#cd conf
# gedit hbase-site.xmlW środku hbase-site.xmlpliku, znajdziesz tagi <configuration> i </configuration>. W nich ustaw katalog HBase pod kluczem właściwości o nazwie „hbase.rootdir”, jak pokazano poniżej.
<configuration>
//Here you have to set the path where you want HBase to store its files.
<property>
<name>hbase.rootdir</name>
<value>file:/home/hadoop/HBase/HFiles</value>
</property>
//Here you have to set the path where you want HBase to store its built in zookeeper files.
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper</value>
</property>
</configuration>Dzięki temu część instalacji i konfiguracji HBase została pomyślnie zakończona. Możemy uruchomić HBase za pomocąstart-hbase.shskrypt znajdujący się w folderze bin HBase. W tym celu otwórz folder domowy HBase i uruchom skrypt startowy HBase, jak pokazano poniżej.
$cd /usr/local/HBase/bin
$./start-hbase.shJeśli wszystko pójdzie dobrze, przy próbie uruchomienia skryptu startowego HBase pojawi się komunikat informujący, że HBase został uruchomiony.
starting master, logging to /usr/local/HBase/bin/../logs/hbase-tpmaster-localhost.localdomain.outInstalowanie HBase w trybie pseudo-rozproszonym
Sprawdźmy teraz, jak HBase jest instalowana w trybie pseudo-rozproszonym.
Konfigurowanie HBase
Przed kontynuowaniem z HBase skonfiguruj Hadoop i HDFS w systemie lokalnym lub zdalnym i upewnij się, że są uruchomione. Zatrzymaj HBase, jeśli jest uruchomiona.
hbase-site.xml
Edytuj plik hbase-site.xml, aby dodać następujące właściwości.
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>Wspomni w którym trybie należy uruchomić HBase. W tym samym pliku z lokalnego systemu plików zmień hbase.rootdir, adres instancji HDFS, używając składni hdfs: //// URI. Używamy HDFS na lokalnym hoście na porcie 8030.
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:8030/hbase</value>
</property>Uruchamianie HBase
Po zakończeniu konfiguracji przejdź do folderu domowego HBase i uruchom HBase za pomocą następującego polecenia.
$cd /usr/local/HBase
$bin/start-hbase.shNote: Przed uruchomieniem HBase upewnij się, że Hadoop jest uruchomiony.
Sprawdzanie katalogu HBase w HDFS
HBase tworzy swój katalog w HDFS. Aby wyświetlić utworzony katalog, przejdź do bin Hadoop i wpisz następujące polecenie.
$ ./bin/hadoop fs -ls /hbaseJeśli wszystko pójdzie dobrze, otrzymasz następujący wynik.
Found 7 items
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs
drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data
-rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id
-rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALsUruchamianie i zatrzymywanie mistrza
Korzystając z „local-master-backup.sh” możesz uruchomić do 10 serwerów. Otwórz folder domowy HBase, master i wykonaj następujące polecenie, aby go uruchomić.
$ ./bin/local-master-backup.sh 2 4Aby zabić mastera kopii zapasowej, potrzebujesz jego identyfikatora procesu, który zostanie zapisany w pliku o nazwie “/tmp/hbase-USER-X-master.pid.” możesz zabić master kopii zapasowej za pomocą następującego polecenia.
$ cat /tmp/hbase-user-1-master.pid |xargs kill -9Uruchamianie i zatrzymywanie serwerów RegionServers
Możesz uruchomić wiele serwerów regionalnych z jednego systemu za pomocą następującego polecenia.
$ .bin/local-regionservers.sh start 2 3Aby zatrzymać serwer regionu, użyj następującego polecenia.
$ .bin/local-regionservers.sh stop 3
Uruchamianie HBaseShell
Po pomyślnym zainstalowaniu HBase możesz uruchomić HBase Shell. Poniżej podano sekwencję kroków, które należy wykonać, aby uruchomić powłokę HBase. Otwórz terminal i zaloguj się jako superużytkownik.
Uruchom system plików Hadoop
Przejrzyj katalog domowy sbin Hadoop i uruchom system plików Hadoop, jak pokazano poniżej.
$cd $HADOOP_HOME/sbin
$start-all.shUruchom HBase
Przejrzyj folder bin katalogu głównego HBase i uruchom HBase.
$cd /usr/local/HBase
$./bin/start-hbase.shUruchom serwer główny HBase
To będzie ten sam katalog. Uruchom go, jak pokazano poniżej.
$./bin/local-master-backup.sh start 2 (number signifies specific
server.)Region początkowy
Uruchom serwer regionalny, jak pokazano poniżej.
$./bin/./local-regionservers.sh start 3Uruchom HBase Shell
Możesz uruchomić powłokę HBase za pomocą następującego polecenia.
$cd bin
$./hbase shellSpowoduje to wyświetlenie monitu powłoki HBase, jak pokazano poniżej.
2014-12-09 14:24:27,526 INFO [main] Configuration.deprecation:
hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri
Nov 14 18:26:29 PST 2014
hbase(main):001:0>Interfejs sieciowy HBase
Aby uzyskać dostęp do interfejsu internetowego HBase, wpisz następujący adres URL w przeglądarce.
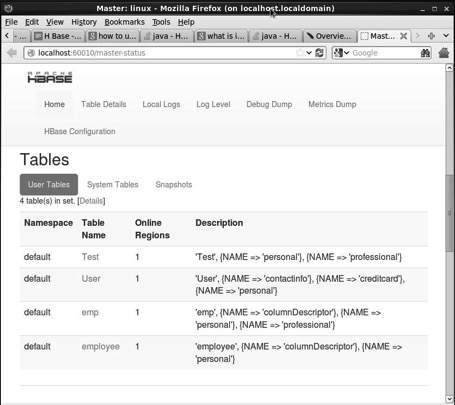
http://localhost:60010Ten interfejs zawiera listę aktualnie uruchomionych serwerów regionu, kopii zapasowych głównych i tabel HBase.
Serwery HBase Region i Backup Masters
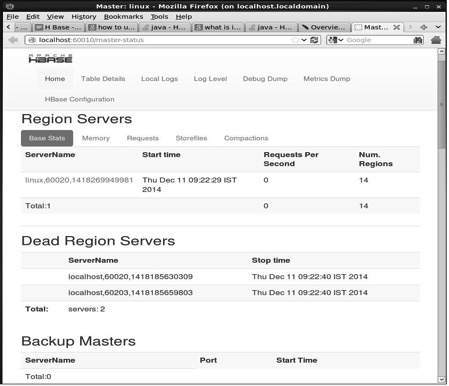
Tabele HBase
Ustawianie środowiska Java
Możemy również komunikować się z HBase za pomocą bibliotek Java, ale przed uzyskaniem dostępu do HBase za pomocą Java API należy ustawić ścieżkę klas dla tych bibliotek.
Ustawianie ścieżki klas
Przed przystąpieniem do programowania ustaw ścieżkę klasy na biblioteki HBase w .bashrcplik. otwarty.bashrc w dowolnym z edytorów, jak pokazano poniżej.
$ gedit ~/.bashrcUstaw w nim ścieżkę klasy dla bibliotek HBase (folder lib w HBase), jak pokazano poniżej.
export CLASSPATH = $CLASSPATH://home/hadoop/hbase/lib/*Ma to zapobiec wystąpieniu wyjątku „nie znaleziono klasy” podczas uzyskiwania dostępu do bazy danych HBase przy użyciu interfejsu API języka Java.