HBase - szybki przewodnik
Od 1970 roku RDBMS jest rozwiązaniem do przechowywania danych i problemów związanych z konserwacją. Po pojawieniu się dużych zbiorów danych firmy zdały sobie sprawę z korzyści płynących z przetwarzania dużych zbiorów danych i zaczęły wybierać rozwiązania takie jak Hadoop.
Hadoop używa rozproszonego systemu plików do przechowywania dużych zbiorów danych, a MapReduce do ich przetwarzania. Hadoop wyróżnia się w przechowywaniu i przetwarzaniu ogromnych danych w różnych formatach, takich jak arbitralne, pół- lub nawet nieustrukturyzowane.
Ograniczenia Hadoop
Hadoop może wykonywać tylko przetwarzanie wsadowe, a dostęp do danych będzie możliwy tylko w sposób sekwencyjny. Oznacza to, że trzeba przeszukać cały zbiór danych, nawet dla najprostszych zadań.
Ogromny zbiór danych po przetworzeniu skutkuje kolejnym ogromnym zestawem danych, który również powinien być przetwarzany sekwencyjnie. W tym momencie potrzebne jest nowe rozwiązanie, aby uzyskać dostęp do dowolnego punktu danych w jednej jednostce czasu (dostęp swobodny).
Bazy danych o dostępie swobodnym Hadoop
Aplikacje takie jak HBase, Cassandra, couchDB, Dynamo i MongoDB to tylko niektóre z baz danych, które przechowują ogromne ilości danych i uzyskują do nich dostęp w sposób losowy.
Co to jest HBase?
HBase to rozproszona, zorientowana na kolumny baza danych zbudowana na bazie systemu plików Hadoop. Jest to projekt typu open source, który można skalować w poziomie.
HBase to model danych, który jest podobny do dużego stołu Google, zaprojektowanego w celu zapewnienia szybkiego losowego dostępu do ogromnych ilości ustrukturyzowanych danych. Wykorzystuje odporność na uszkodzenia zapewnianą przez system plików Hadoop (HDFS).
Jest częścią ekosystemu Hadoop, który zapewnia losowy dostęp do odczytu / zapisu w czasie rzeczywistym do danych w systemie plików Hadoop.
Dane można przechowywać w HDFS bezpośrednio lub przez HBase. Konsument danych odczytuje / uzyskuje dostęp do danych w HDFS losowo przy użyciu HBase. HBase znajduje się na szczycie systemu plików Hadoop i zapewnia dostęp do odczytu i zapisu.

HBase i HDFS
| HDFS | HBase |
|---|---|
| HDFS to rozproszony system plików odpowiedni do przechowywania dużych plików. | HBase to baza danych zbudowana na bazie HDFS. |
| HDFS nie obsługuje szybkiego wyszukiwania pojedynczych rekordów. | HBase zapewnia szybkie wyszukiwanie większych tabel. |
| Zapewnia przetwarzanie wsadowe z dużym opóźnieniem; brak koncepcji przetwarzania wsadowego. | Zapewnia małe opóźnienia w dostępie do pojedynczych wierszy z miliardów rekordów (dostęp losowy). |
| Zapewnia tylko sekwencyjny dostęp do danych. | HBase wewnętrznie używa tabel skrótów i zapewnia dostęp losowy oraz przechowuje dane w indeksowanych plikach HDFS w celu szybszego wyszukiwania. |
Mechanizm przechowywania w HBase
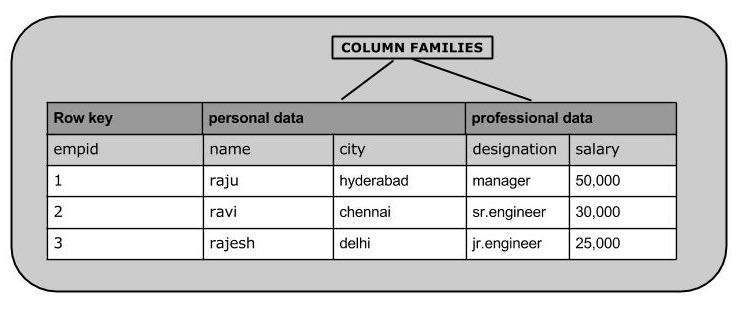
HBase to plik column-oriented databasea zawarte w nim tabele są sortowane według wierszy. Schemat tabeli definiuje tylko rodziny kolumn, które są parami klucz-wartość. Tabela ma wiele rodzin kolumn, a każda rodzina kolumn może mieć dowolną liczbę kolumn. Kolejne wartości kolumn są zapisywane w sposób ciągły na dysku. Każda wartość komórki w tabeli ma sygnaturę czasową. Krótko mówiąc, w HBase:
- Tabela to zbiór wierszy.
- Wiersz to zbiór rodzin kolumn.
- Rodzina kolumn to zbiór kolumn.
- Kolumna to zbiór par klucz-wartość.
Poniżej podano przykładowy schemat tabeli w HBase.
| Rowid | Rodzina kolumn | Rodzina kolumn | Rodzina kolumn | Rodzina kolumn | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
Zorientowany na kolumnę i zorientowany na wiersz
Bazy danych zorientowane na kolumny to takie, które przechowują tabele danych jako sekcje kolumn danych, a nie jako wiersze danych. Wkrótce będą mieli rodziny kolumn.
| Baza danych zorientowana wierszowo | Baza danych zorientowana kolumnowo |
|---|---|
| Nadaje się do procesu transakcji online (OLTP). | Nadaje się do przetwarzania analitycznego online (OLAP). |
| Takie bazy danych są przeznaczone dla niewielkiej liczby wierszy i kolumn. | Bazy danych zorientowane na kolumny są przeznaczone dla dużych tabel. |
Poniższy rysunek przedstawia rodziny kolumn w bazie danych zorientowanej na kolumny:
HBase i RDBMS
| HBase | RDBMS |
|---|---|
| HBase jest bez schematu, nie ma koncepcji schematu stałych kolumn; definiuje tylko rodziny kolumn. | RDBMS jest zarządzany przez swój schemat, który opisuje całą strukturę tabel. |
| Jest przeznaczony do szerokich stołów. HBase jest skalowalna w poziomie. | Jest cienki i przeznaczony do małych stołów. Trudne do skalowania. |
| W HBase nie ma żadnych transakcji. | RDBMS jest transakcyjny. |
| Ma zdenormalizowane dane. | Będzie miał znormalizowane dane. |
| Sprawdza się zarówno w przypadku danych częściowo ustrukturyzowanych, jak i ustrukturyzowanych. | To jest dobre dla danych strukturalnych. |
Cechy HBase
- HBase jest skalowalna liniowo.
- Posiada automatyczną obsługę awarii.
- Zapewnia spójne odczytywanie i zapisywanie.
- Integruje się z Hadoop, zarówno jako źródło, jak i miejsce docelowe.
- Posiada łatwe API java dla klienta.
- Zapewnia replikację danych w klastrach.
Gdzie używać HBase
Apache HBase służy do losowego dostępu w czasie rzeczywistym do odczytu / zapisu do Big Data.
Obsługuje bardzo duże tabele na klastrach standardowego sprzętu.
Apache HBase to nierelacyjna baza danych wzorowana na Bigtable firmy Google. Bigtable działa w systemie plików Google, podobnie jak Apache HBase działa na Hadoop i HDFS.
Zastosowania HBase
- Jest używany wszędzie tam, gdzie istnieje potrzeba pisania ciężkich aplikacji.
- HBase jest używana wszędzie tam, gdzie potrzebujemy szybkiego losowego dostępu do dostępnych danych.
- Firmy takie jak Facebook, Twitter, Yahoo i Adobe używają HBase wewnętrznie.
Historia HBase
| Rok | Zdarzenie |
|---|---|
| Listopad 2006 | Google opublikował artykuł w BigTable. |
| Luty 2007 | Wstępny prototyp HBase został stworzony jako wkład Hadoop. |
| Paź 2007 | Został wydany pierwszy użyteczny HBase wraz z Hadoopem 0.15.0. |
| Styczeń 2008 | HBase stał się podprojektem Hadoop. |
| Paź 2008 | Uwolniono HBase 0.18.1. |
| Sty 2009 | Udostępniono HBase 0.19.0. |
| Wrzesień 2009 | Udostępniono HBase 0.20.0. |
| Maj 2010 | HBase stał się projektem najwyższego poziomu Apache. |
W HBase tabele są podzielone na regiony i są obsługiwane przez serwery regionów. Regiony są podzielone pionowo rodzinami kolumn na „Magazyny”. Sklepy są zapisywane jako pliki w HDFS. Poniżej przedstawiono architekturę HBase.
Note: Termin „magazyn” jest używany w odniesieniu do regionów w celu wyjaśnienia struktury pamięci.
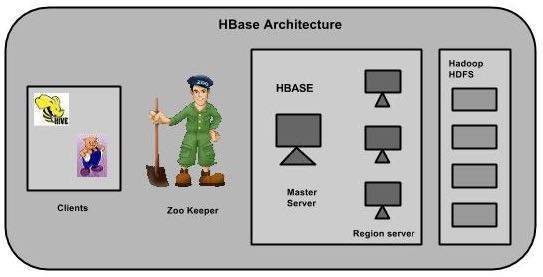
HBase ma trzy główne składniki: bibliotekę klienta, serwer główny i serwery regionalne. Serwery regionalne można dodawać lub usuwać zgodnie z wymaganiami.
MasterServer
Serwer główny -
Przypisuje regiony do serwerów regionalnych i korzysta z pomocy Apache ZooKeeper w tym zadaniu.
Obsługuje równoważenie obciążenia regionów na serwerach regionalnych. Odciąża zajęte serwery i przenosi regiony do mniej zajętych serwerów.
Utrzymuje stan klastra poprzez negocjowanie równoważenia obciążenia.
Odpowiada za zmiany schematu i inne operacje na metadanych, takie jak tworzenie tabel i rodzin kolumn.
Regiony
Regiony to nic innego jak tabele, które są podzielone i rozmieszczone na serwerach regionu.
Serwer regionalny
Serwery regionu mają regiony, które -
- Komunikuj się z klientem i obsługuj operacje związane z danymi.
- Obsługuj żądania odczytu i zapisu dla wszystkich regionów pod nim.
- Zdecyduj o wielkości regionu, postępując zgodnie z progami wielkości regionu.
Kiedy przyjrzymy się dokładniej serwerowi regionu, zawiera on regiony i sklepy, jak pokazano poniżej:
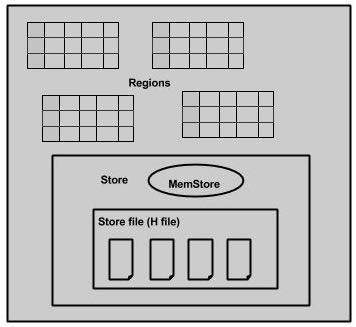
Sklep zawiera magazyn pamięci i HFiles. Memstore jest jak pamięć podręczna. Wszystko, co jest wprowadzane do HBase, jest tutaj początkowo przechowywane. Później dane są przesyłane i zapisywane w Hfiles jako bloki, a memstore jest opróżniany.
Zookeeper
Zookeeper to projekt typu open source, który zapewnia usługi takie jak utrzymywanie informacji konfiguracyjnych, nazewnictwo, zapewnianie rozproszonej synchronizacji itp.
Zookeeper ma efemeryczne węzły reprezentujące różne serwery regionu. Serwery główne używają tych węzłów do wykrywania dostępnych serwerów.
Oprócz dostępności węzły są również używane do śledzenia awarii serwerów lub partycji sieciowych.
Klienci komunikują się z serwerami regionalnymi za pośrednictwem zookeepera.
W trybach pseudo i samodzielnych, HBase sam zajmie się zookeeperem.
W tym rozdziale wyjaśniono, jak instaluje się i konfiguruje HBase. Java i Hadoop są wymagane do kontynuowania HBase, więc musisz pobrać i zainstalować Javę i Hadoop w swoim systemie.
Konfiguracja przed instalacją
Przed zainstalowaniem Hadoopa w środowisku Linux musimy skonfigurować Linuksa przy użyciu ssh(Bezpieczna powłoka). Wykonaj poniższe czynności, aby skonfigurować środowisko Linux.
Tworzenie użytkownika
Przede wszystkim zaleca się utworzenie oddzielnego użytkownika dla Hadoop, aby odizolować system plików Hadoop od systemu plików Unix. Wykonaj poniższe czynności, aby utworzyć użytkownika.
- Otwórz root za pomocą polecenia „su”.
- Utwórz użytkownika z konta root za pomocą polecenia „useradd username”.
- Teraz możesz otworzyć istniejące konto użytkownika za pomocą polecenia „su nazwa użytkownika”.
Otwórz terminal Linux i wpisz następujące polecenia, aby utworzyć użytkownika.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdKonfiguracja SSH i generowanie klucza
Konfiguracja SSH jest wymagana do wykonywania różnych operacji w klastrze, takich jak uruchamianie, zatrzymywanie i rozproszone operacje powłoki demona. Aby uwierzytelnić różnych użytkowników Hadoop, wymagane jest podanie pary kluczy publiczny / prywatny dla użytkownika Hadoop i udostępnienie go różnym użytkownikom.
Poniższe polecenia służą do generowania pary klucz-wartość przy użyciu protokołu SSH. Skopiuj klucze publiczne z formularza id_rsa.pub do Authorized_keys i zapewnij właścicielowi, odpowiednio, uprawnienia do odczytu i zapisu do pliku authorised_keys.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keysZweryfikuj ssh
ssh localhostInstalowanie Java
Java jest głównym wymaganiem wstępnym dla Hadoop i HBase. Przede wszystkim powinieneś zweryfikować istnienie javy w twoim systemie używając “java -version”. Składnia polecenia wersji java jest podana poniżej.
$ java -versionJeśli wszystko działa dobrze, otrzymasz następujący wynik.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Jeśli java nie jest zainstalowana w twoim systemie, wykonaj poniższe kroki, aby zainstalować java.
Krok 1
Pobierz java (JDK <najnowsza wersja> - X64.tar.gz), odwiedzając poniższy link Oracle Java .
Następnie jdk-7u71-linux-x64.tar.gz zostaną pobrane do twojego systemu.
Krok 2
Pobrany plik java znajdziesz zazwyczaj w folderze Pobrane. Sprawdź go i wyodrębnij plikjdk-7u71-linux-x64.gz plik za pomocą następujących poleceń.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzKrok 3
Aby udostępnić Javę wszystkim użytkownikom, musisz przenieść ją do lokalizacji „/ usr / local /”. Otwórz root i wpisz następujące polecenia.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitKrok 4
Do konfiguracji PATH i JAVA_HOME zmienne, dodaj następujące polecenia do ~/.bashrc plik.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH= $PATH:$JAVA_HOME/binTeraz zastosuj wszystkie zmiany w aktualnie działającym systemie.
$ source ~/.bashrcKrok 5
Użyj następujących poleceń, aby skonfigurować alternatywy Java:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarTeraz zweryfikuj java -version polecenie z terminala, jak wyjaśniono powyżej.
Pobieranie Hadoop
Po zainstalowaniu javy musisz zainstalować Hadoop. Przede wszystkim sprawdź istnienie Hadoop za pomocą polecenia „Wersja Hadoop”, jak pokazano poniżej.
hadoop versionJeśli wszystko działa dobrze, otrzymasz następujący wynik.
Hadoop 2.6.0
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using
/home/hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jarJeśli Twój system nie może zlokalizować Hadoop, pobierz Hadoop w swoim systemie. Aby to zrobić, postępuj zgodnie z poleceniami podanymi poniżej.
Pobierz i wyodrębnij hadoop-2.6.0 z Apache Software Foundation, używając następujących poleceń.
$ su
password:
# cd /usr/local
# wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-
2.6.0/hadoop-2.6.0-src.tar.gz
# tar xzf hadoop-2.6.0-src.tar.gz
# mv hadoop-2.6.0/* hadoop/
# exitInstalowanie Hadoop
Zainstaluj Hadoop w dowolnym wymaganym trybie. Tutaj demonstrujemy funkcjonalności HBase w trybie pseudo rozproszonym, dlatego zainstaluj Hadoop w trybie pseudo rozproszonym.
Podczas instalacji wykonywane są następujące kroki Hadoop 2.4.1.
Krok 1 - Konfiguracja Hadoop
Możesz ustawić zmienne środowiskowe Hadoop, dołączając następujące polecenia do ~/.bashrc plik.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOMETeraz zastosuj wszystkie zmiany w aktualnie działającym systemie.
$ source ~/.bashrcKrok 2 - Konfiguracja Hadoop
Wszystkie pliki konfiguracyjne Hadoop można znaleźć w lokalizacji „$ HADOOP_HOME / etc / hadoop”. Musisz wprowadzić zmiany w tych plikach konfiguracyjnych zgodnie z infrastrukturą Hadoop.
$ cd $HADOOP_HOME/etc/hadoopAby tworzyć programy Hadoop w Javie, musisz zresetować zmienną środowiskową Java w hadoop-env.sh plik, zastępując JAVA_HOME wartość z lokalizacją Java w systemie.
export JAVA_HOME=/usr/local/jdk1.7.0_71Będziesz musiał edytować następujące pliki, aby skonfigurować Hadoop.
core-site.xml
Plik core-site.xml plik zawiera informacje, takie jak numer portu używanego dla wystąpienia Hadoop, pamięć przydzielona dla systemu plików, limit pamięci do przechowywania danych oraz rozmiar buforów do odczytu / zapisu.
Otwórz plik core-site.xml i dodaj następujące właściwości między tagami <configuration> i </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
Plik hdfs-site.xml Plik zawiera informacje, takie jak wartość danych replikacji, ścieżka nazwy i ścieżki danych lokalnych systemów plików, w których chcesz przechowywać infrastrukturę Hadoop.
Załóżmy następujące dane.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeOtwórz ten plik i dodaj następujące właściwości między tagami <configuration>, </configuration>.
<configuration>
<property>
<name>dfs.replication</name >
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note: W powyższym pliku wszystkie wartości właściwości są zdefiniowane przez użytkownika i można wprowadzać zmiany zgodnie z infrastrukturą Hadoop.
yarn-site.xml
Ten plik służy do konfigurowania przędzy w Hadoop. Otwórz plik yarn-site.xml i dodaj następującą właściwość między <configuration $ gt ;, </ configuration $ gt; tagi w tym pliku.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Ten plik jest używany do określenia, której platformy MapReduce używamy. Domyślnie Hadoop zawiera szablon yarn-site.xml. Przede wszystkim należy skopiować plik zmapred-site.xml.template do mapred-site.xml plik za pomocą następującego polecenia.
$ cp mapred-site.xml.template mapred-site.xmlotwarty mapred-site.xml file i dodaj następujące właściwości między tagami <configuration> i </configuration>.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Weryfikacja instalacji Hadoop
Poniższe kroki służą do weryfikacji instalacji Hadoop.
Krok 1 - Konfiguracja nazwy węzła
Skonfiguruj namenode za pomocą polecenia „hdfs namenode -format” w następujący sposób.
$ cd ~ $ hdfs namenode -formatOczekiwany wynik jest następujący.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Krok 2 - Weryfikacja plików dfs na platformie Hadoop
Następujące polecenie służy do uruchamiania dfs. Wykonanie tego polecenia spowoduje uruchomienie systemu plików Hadoop.
$ start-dfs.shOczekiwany wynik jest następujący.
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Krok 3 - weryfikacja skryptu przędzy
Następujące polecenie służy do uruchamiania skryptu przędzy. Wykonanie tego polecenia spowoduje uruchomienie demonów przędzy.
$ start-yarn.shOczekiwany wynik jest następujący.
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outKrok 4 - Dostęp do Hadoop w przeglądarce
Domyślny numer portu dostępu do Hadoop to 50070. Użyj następującego adresu URL, aby pobrać usługi Hadoop w przeglądarce.
http://localhost:50070
Krok 5 - Sprawdź wszystkie aplikacje klastra
Domyślny numer portu dostępu do wszystkich aplikacji klastra to 8088. Aby odwiedzić tę usługę, użyj następującego adresu URL.
http://localhost:8088/
Instalowanie HBase
Możemy zainstalować HBase w dowolnym z trzech trybów: trybie autonomicznym, trybie pseudo rozproszonym i trybie pełnej dystrybucji.
Instalowanie HBase w trybie autonomicznym
Pobierz najnowszą stabilną wersję formularza HBase http://www.interior-dsgn.com/apache/hbase/stable/używając polecenia „wget” i wyodrębnij go za pomocą polecenia tar „zxvf”. Zobacz następujące polecenie.
$cd usr/local/ $wget http://www.interior-dsgn.com/apache/hbase/stable/hbase-0.98.8-
hadoop2-bin.tar.gz
$tar -zxvf hbase-0.98.8-hadoop2-bin.tar.gzPrzejdź do trybu superużytkownika i przenieś folder HBase do / usr / local, jak pokazano poniżej.
$su
$password: enter your password here
mv hbase-0.99.1/* Hbase/Konfigurowanie HBase w trybie autonomicznym
Przed kontynuowaniem z HBase, musisz edytować następujące pliki i skonfigurować HBase.
hbase-env.sh
Ustaw java Home dla HBase i otwórz hbase-env.shplik z folderu conf. Edytuj zmienną środowiskową JAVA_HOME i zmień istniejącą ścieżkę do bieżącej zmiennej JAVA_HOME, jak pokazano poniżej.
cd /usr/local/Hbase/conf
gedit hbase-env.shSpowoduje to otwarcie pliku env.sh HBase. Teraz zamień istniejąceJAVA_HOME wartość z aktualną wartością, jak pokazano poniżej.
export JAVA_HOME=/usr/lib/jvm/java-1.7.0hbase-site.xml
To jest główny plik konfiguracyjny HBase. Ustaw katalog danych na odpowiednią lokalizację, otwierając folder domowy HBase w / usr / local / HBase. W folderze conf znajdziesz kilka plików, otwórz plikhbase-site.xml plik, jak pokazano poniżej.
#cd /usr/local/HBase/
#cd conf
# gedit hbase-site.xmlW środku hbase-site.xmlpliku, znajdziesz tagi <configuration> i </configuration>. W nich ustaw katalog HBase pod kluczem właściwości o nazwie „hbase.rootdir”, jak pokazano poniżej.
<configuration>
//Here you have to set the path where you want HBase to store its files.
<property>
<name>hbase.rootdir</name>
<value>file:/home/hadoop/HBase/HFiles</value>
</property>
//Here you have to set the path where you want HBase to store its built in zookeeper files.
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper</value>
</property>
</configuration>Dzięki temu część instalacji i konfiguracji HBase została pomyślnie zakończona. Możemy uruchomić HBase za pomocąstart-hbase.shskrypt znajdujący się w folderze bin HBase. W tym celu otwórz folder domowy HBase i uruchom skrypt startowy HBase, jak pokazano poniżej.
$cd /usr/local/HBase/bin
$./start-hbase.shJeśli wszystko pójdzie dobrze, przy próbie uruchomienia skryptu startowego HBase pojawi się komunikat informujący, że HBase został uruchomiony.
starting master, logging to /usr/local/HBase/bin/../logs/hbase-tpmaster-localhost.localdomain.outInstalowanie HBase w trybie pseudo-rozproszonym
Sprawdźmy teraz, jak HBase jest instalowana w trybie pseudo-rozproszonym.
Konfigurowanie HBase
Przed kontynuowaniem z HBase skonfiguruj Hadoop i HDFS w systemie lokalnym lub w systemie zdalnym i upewnij się, że działają. Zatrzymaj HBase, jeśli jest uruchomiona.
hbase-site.xml
Edytuj plik hbase-site.xml, aby dodać następujące właściwości.
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>Wspomni w którym trybie należy uruchomić HBase. W tym samym pliku z lokalnego systemu plików zmień hbase.rootdir, adres instancji HDFS, używając składni hdfs: //// URI. Używamy HDFS na lokalnym hoście na porcie 8030.
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:8030/hbase</value>
</property>Uruchamianie HBase
Po zakończeniu konfiguracji przejdź do folderu domowego HBase i uruchom HBase za pomocą następującego polecenia.
$cd /usr/local/HBase
$bin/start-hbase.shNote: Przed uruchomieniem HBase upewnij się, że Hadoop jest uruchomiony.
Sprawdzanie katalogu HBase w HDFS
HBase tworzy swój katalog w HDFS. Aby wyświetlić utworzony katalog, przejdź do bin Hadoop i wpisz następujące polecenie.
$ ./bin/hadoop fs -ls /hbaseJeśli wszystko pójdzie dobrze, otrzymasz następujący wynik.
Found 7 items
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs
drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data
-rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id
-rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALsUruchamianie i zatrzymywanie mistrza
Korzystając z „local-master-backup.sh” możesz uruchomić do 10 serwerów. Otwórz folder domowy HBase, master i wykonaj następujące polecenie, aby go uruchomić.
$ ./bin/local-master-backup.sh 2 4Aby zabić serwer kopii zapasowej, potrzebujesz jego identyfikatora procesu, który będzie przechowywany w pliku o nazwie “/tmp/hbase-USER-X-master.pid.” możesz zabić master kopii zapasowej za pomocą następującego polecenia.
$ cat /tmp/hbase-user-1-master.pid |xargs kill -9Uruchamianie i zatrzymywanie serwerów RegionServers
Możesz uruchomić wiele serwerów regionalnych z jednego systemu za pomocą następującego polecenia.
$ .bin/local-regionservers.sh start 2 3Aby zatrzymać serwer regionu, użyj następującego polecenia.
$ .bin/local-regionservers.sh stop 3
Uruchamianie HBaseShell
Po pomyślnym zainstalowaniu HBase możesz uruchomić HBase Shell. Poniżej podano sekwencję kroków, które należy wykonać, aby uruchomić powłokę HBase. Otwórz terminal i zaloguj się jako superużytkownik.
Uruchom system plików Hadoop
Przejrzyj katalog domowy sbin Hadoop i uruchom system plików Hadoop, jak pokazano poniżej.
$cd $HADOOP_HOME/sbin
$start-all.shUruchom HBase
Przejrzyj folder bin katalogu głównego HBase i uruchom HBase.
$cd /usr/local/HBase
$./bin/start-hbase.shUruchom serwer główny HBase
To będzie ten sam katalog. Uruchom go, jak pokazano poniżej.
$./bin/local-master-backup.sh start 2 (number signifies specific
server.)Region początkowy
Uruchom serwer regionalny, jak pokazano poniżej.
$./bin/./local-regionservers.sh start 3Uruchom HBase Shell
Możesz uruchomić powłokę HBase za pomocą następującego polecenia.
$cd bin
$./hbase shellSpowoduje to wyświetlenie monitu powłoki HBase, jak pokazano poniżej.
2014-12-09 14:24:27,526 INFO [main] Configuration.deprecation:
hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri
Nov 14 18:26:29 PST 2014
hbase(main):001:0>Interfejs sieciowy HBase
Aby uzyskać dostęp do interfejsu internetowego HBase, wpisz następujący adres URL w przeglądarce.
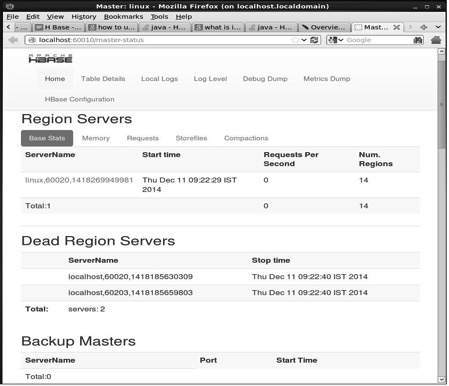
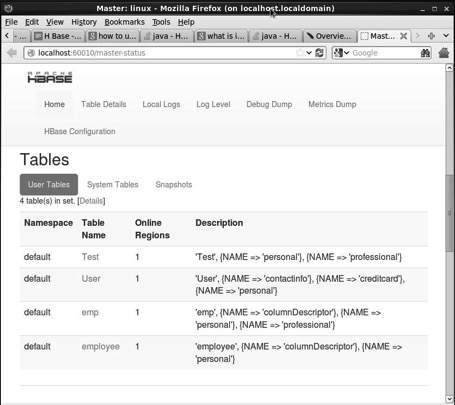
http://localhost:60010Ten interfejs wyświetla aktualnie uruchomione serwery Region, główne kopie zapasowe i tabele HBase.
Serwery HBase Region i Backup Masters
Tabele HBase
Ustawianie środowiska Java
Możemy również komunikować się z HBase za pomocą bibliotek Java, ale przed uzyskaniem dostępu do HBase za pomocą Java API należy ustawić ścieżkę klas dla tych bibliotek.
Ustawianie ścieżki klas
Przed przystąpieniem do programowania ustaw ścieżkę klasy na biblioteki HBase w .bashrcplik. otwarty.bashrc w dowolnym z edytorów, jak pokazano poniżej.
$ gedit ~/.bashrcUstaw w nim ścieżkę klas dla bibliotek HBase (folder lib w HBase), jak pokazano poniżej.
export CLASSPATH = $CLASSPATH://home/hadoop/hbase/lib/*Ma to zapobiec wystąpieniu wyjątku „nie znaleziono klasy” podczas uzyskiwania dostępu do bazy danych HBase przy użyciu interfejsu API języka Java.
W tym rozdziale wyjaśniono, jak uruchomić interaktywną powłokę HBase, która jest dostarczana wraz z HBase.
Powłoka HBase
HBase zawiera powłokę, za pomocą której możesz komunikować się z HBase. HBase używa systemu plików Hadoop do przechowywania danych. Będzie miał serwer główny i serwery regionalne. Przechowywanie danych będzie miało postać regionów (tabel). Regiony te zostaną podzielone i przechowywane na serwerach regionalnych.
Serwer główny zarządza tymi serwerami regionu i wszystkie te zadania odbywają się na HDFS. Poniżej podano niektóre polecenia obsługiwane przez HBase Shell.
Ogólne polecenia
status - Podaje stan HBase, na przykład liczbę serwerów.
version - Udostępnia używaną wersję HBase.
table_help - Zapewnia pomoc dotyczącą poleceń odwołań do tabeli.
whoami - Zawiera informacje o użytkowniku.
Język definicji danych
To są polecenia, które działają na tabelach w HBase.
create - Tworzy tabelę.
list - Wyświetla wszystkie tabele w HBase.
disable - Wyłącza stół.
is_disabled - Sprawdza, czy tabela jest wyłączona.
enable - Włącza tabelę.
is_enabled - Sprawdza, czy tabela jest włączona.
describe - Zawiera opis tabeli.
alter - Zmienia stół.
exists - Sprawdza, czy istnieje tabela.
drop - Upuszcza tabelę z HBase.
drop_all - Usuwa tabele zgodne z „wyrażeniem regularnym” podanym w poleceniu.
Java Admin API- Przed wszystkimi powyższymi poleceniami Java udostępnia interfejs API administratora umożliwiający osiągnięcie funkcji DDL poprzez programowanie. Podorg.apache.hadoop.hbase.client package, HBaseAdmin i HTableDescriptor to dwie ważne klasy w tym pakiecie, które zapewniają funkcje DDL.
Język manipulacji danymi
put - Umieszcza wartość komórki w określonej kolumnie w określonym wierszu w określonej tabeli.
get - Pobiera zawartość wiersza lub komórki.
delete - Usuwa wartość komórki w tabeli.
deleteall - usuwa wszystkie komórki w danym wierszu.
scan - Skanuje i zwraca dane tabeli.
count - Zlicza i zwraca liczbę wierszy w tabeli.
truncate - Wyłącza, upuszcza i odtwarza określoną tabelę.
Java client API - Przed wszystkimi powyższymi poleceniami Java udostępnia API klienta do osiągnięcia funkcjonalności DML, CRUD (Create Retrieve Update Delete) i nie tylko poprzez programowanie, w pakiecie org.apache.hadoop.hbase.client. HTable Put i Get to ważne klasy w tym pakiecie.
Uruchamianie powłoki HBase
Aby uzyskać dostęp do powłoki HBase, musisz przejść do folderu domowego HBase.
cd /usr/localhost/
cd HbaseMożesz uruchomić interaktywną powłokę HBase za pomocą “hbase shell” polecenie, jak pokazano poniżej.
./bin/hbase shellJeśli pomyślnie zainstalowałeś HBase w swoim systemie, wyświetli się monit powłoki HBase, jak pokazano poniżej.
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.94.23, rf42302b28aceaab773b15f234aa8718fff7eea3c, Wed Aug 27
00:54:09 UTC 2014
hbase(main):001:0>Aby w dowolnym momencie wyjść z polecenia powłoki interaktywnej, wpisz exit lub użyj <ctrl + c>. Sprawdź działanie powłoki, zanim przejdziesz dalej. Użyjlist polecenie w tym celu. Listto polecenie używane do pobierania listy wszystkich tabel w HBase. Przede wszystkim sprawdź instalację i konfigurację HBase w systemie za pomocą tego polecenia, jak pokazano poniżej.
hbase(main):001:0> listPo wpisaniu tego polecenia otrzymasz następujące dane wyjściowe.
hbase(main):001:0> list
TABLEOgólne polecenia w HBase to status, wersja, table_help i whoami. W tym rozdziale opisano te polecenia.
status
Ta komenda zwraca stan systemu, w tym szczegółowe informacje o serwerach działających w systemie. Jego składnia jest następująca:
hbase(main):009:0> statusJeśli wykonasz to polecenie, zwraca następujące dane wyjściowe.
hbase(main):009:0> status
3 servers, 0 dead, 1.3333 average loadwersja
To polecenie zwraca wersję HBase używaną w systemie. Jego składnia jest następująca:
hbase(main):010:0> versionJeśli wykonasz to polecenie, zwraca następujące dane wyjściowe.
hbase(main):009:0> version
0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri Nov 14
18:26:29 PST 2014table_help
To polecenie prowadzi cię, co i jak używać poleceń odwołujących się do tabeli. Poniżej podano składnię używaną w tym poleceniu.
hbase(main):02:0> table_helpUżycie tego polecenia powoduje wyświetlenie tematów pomocy dotyczących poleceń związanych z tabelami. Poniżej podano częściowe dane wyjściowe tego polecenia.
hbase(main):002:0> table_help
Help for table-reference commands.
You can either create a table via 'create' and then manipulate the table
via commands like 'put', 'get', etc.
See the standard help information for how to use each of these commands.
However, as of 0.96, you can also get a reference to a table, on which
you can invoke commands.
For instance, you can get create a table and keep around a reference to
it via:
hbase> t = create 't', 'cf'…...kim jestem
To polecenie zwraca szczegóły użytkownika HBase. Jeśli wykonasz to polecenie, zwraca bieżącego użytkownika HBase, jak pokazano poniżej.
hbase(main):008:0> whoami
hadoop (auth:SIMPLE)
groups: hadoopHBase jest napisany w Javie, dlatego zapewnia API java do komunikacji z HBase. Java API to najszybszy sposób komunikacji z HBase. Poniżej podano przywoływany interfejs Java Admin API, który obejmuje zadania używane do zarządzania tabelami.
Klasa HBaseAdmin
HBaseAdminto klasa reprezentująca Admin. Ta klasa należy doorg.apache.hadoop.hbase.clientpakiet. Korzystając z tej klasy, możesz wykonywać zadania administratora. Możesz uzyskać instancję administratora za pomocąConnection.getAdmin() metoda.
Metody i opis
| S.No. | Metody i opis |
|---|---|
| 1 | void createTable(HTableDescriptor desc) Tworzy nową tabelę. |
| 2 | void createTable(HTableDescriptor desc, byte[][] splitKeys) Tworzy nową tabelę z początkowym zestawem pustych regionów zdefiniowanych przez określone klucze podziału. |
| 3 | void deleteColumn(byte[] tableName, String columnName) Usuwa kolumnę z tabeli. |
| 4 | void deleteColumn(String tableName, String columnName) Usuń kolumnę z tabeli. |
| 5 | void deleteTable(String tableName) Usuwa tabelę. |
Deskryptor klasy
Ta klasa zawiera szczegółowe informacje o tabeli HBase, takie jak:
- deskryptory wszystkich rodzin kolumn,
- jeśli tabela jest tabelą katalogową,
- jeśli tabela jest tylko do odczytu,
- maksymalny rozmiar magazynu pamięci,
- kiedy powinien nastąpić podział regionu,
- powiązanych z nim koprocesorów itp.
Konstruktorzy
| S.No. | Konstruktor i podsumowanie |
|---|---|
| 1 | HTableDescriptor(TableName name) Konstruuje deskryptor tabeli określający obiekt TableName. |
Metody i opis
| S.No. | Metody i opis |
|---|---|
| 1 | HTableDescriptor addFamily(HColumnDescriptor family) Dodaje rodzinę kolumn do podanego deskryptora |
Tworzenie tabeli przy użyciu powłoki HBase
Możesz utworzyć tabelę za pomocą createpolecenie, w tym miejscu należy określić nazwę tabeli i nazwę rodziny kolumn. Pliksyntax Tworzenie tabeli w powłoce HBase jest pokazane poniżej.
create ‘<table name>’,’<column family>’Przykład
Poniżej podano przykładowy schemat tabeli o nazwie emp. Zawiera dwie rodziny kolumn: „dane osobowe” i „dane zawodowe”.
| Klucz wiersza | dane osobiste | dane zawodowe |
|---|---|---|
Możesz utworzyć tę tabelę w powłoce HBase, jak pokazano poniżej.
hbase(main):002:0> create 'emp', 'personal data', 'professional data'I da ci następujący wynik.
0 row(s) in 1.1300 seconds
=> Hbase::Table - empWeryfikacja
Możesz sprawdzić, czy tabela została utworzona przy użyciu listpolecenie, jak pokazano poniżej. Tutaj możesz obserwować utworzoną tabelę emp.
hbase(main):002:0> list
TABLE
emp
2 row(s) in 0.0340 secondsTworzenie tabeli przy użyciu interfejsu API języka Java
Możesz utworzyć tabelę w HBase przy użyciu createTable() metoda HBaseAdminklasa. Ta klasa należy doorg.apache.hadoop.hbase.clientpakiet. Poniżej podano kroki, aby utworzyć tabelę w HBase przy użyciu Java API.
Krok 1: Utwórz wystąpienie HBaseAdmin
Ta klasa wymaga obiektu Configuration jako parametru, dlatego początkowo utwórz wystąpienie klasy Configuration i przekaż to wystąpienie do HBaseAdmin.
Configuration conf = HBaseConfiguration.create();
HBaseAdmin admin = new HBaseAdmin(conf);Krok 2: Utwórz TableDescriptor
HTableDescriptor to klasa należąca do klasy org.apache.hadoop.hbaseklasa. Ta klasa jest jak kontener nazw tabel i rodzin kolumn.
//creating table descriptor
HTableDescriptor table = new HTableDescriptor(toBytes("Table name"));
//creating column family descriptor
HColumnDescriptor family = new HColumnDescriptor(toBytes("column family"));
//adding coloumn family to HTable
table.addFamily(family);Krok 3: Wykonaj przez administratora
Używając createTable() metoda HBaseAdmin możesz wykonać utworzoną tabelę w trybie administratora.
admin.createTable(table);Poniżej znajduje się kompletny program do tworzenia tabeli przez administratora.
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.conf.Configuration;
public class CreateTable {
public static void main(String[] args) throws IOException {
// Instantiating configuration class
Configuration con = HBaseConfiguration.create();
// Instantiating HbaseAdmin class
HBaseAdmin admin = new HBaseAdmin(con);
// Instantiating table descriptor class
HTableDescriptor tableDescriptor = new
HTableDescriptor(TableName.valueOf("emp"));
// Adding column families to table descriptor
tableDescriptor.addFamily(new HColumnDescriptor("personal"));
tableDescriptor.addFamily(new HColumnDescriptor("professional"));
// Execute the table through admin
admin.createTable(tableDescriptor);
System.out.println(" Table created ");
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac CreateTable.java
$java CreateTableWynik powinien być następujący:
Table createdWyświetlanie tabeli przy użyciu powłoki HBase
list to polecenie używane do wyświetlania listy wszystkich tabel w HBase. Poniżej podano składnię polecenia list.
hbase(main):001:0 > listPo wpisaniu tego polecenia i wykonaniu w wierszu polecenia HBase wyświetli się lista wszystkich tabel w HBase, jak pokazano poniżej.
hbase(main):001:0> list
TABLE
empTutaj możesz obserwować tabelę o nazwie emp.
Listing Tables przy użyciu Java API
Postępuj zgodnie z instrukcjami podanymi poniżej, aby pobrać listę tabel z HBase przy użyciu interfejsu API Java.
Krok 1
Masz metodę o nazwie listTables() w klasie HBaseAdminaby uzyskać listę wszystkich tabel w HBase. Ta metoda zwraca tablicęHTableDescriptor obiekty.
//creating a configuration object
Configuration conf = HBaseConfiguration.create();
//Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);
//Getting all the list of tables using HBaseAdmin object
HTableDescriptor[] tableDescriptor = admin.listTables();Krok 2
Możesz uzyskać długość pliku HTableDescriptor[] tablicy przy użyciu zmiennej długości pliku HTableDescriptorklasa. Uzyskaj nazwę tabel z tego obiektu za pomocągetNameAsString()metoda. Uruchom pętlę „for”, korzystając z nich i pobierz listę tabel w HBase.
Poniżej podano program do wyświetlania listy wszystkich tabel w HBase przy użyciu Java API.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class ListTables {
public static void main(String args[])throws MasterNotRunningException, IOException{
// Instantiating a configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Getting all the list of tables using HBaseAdmin object
HTableDescriptor[] tableDescriptor = admin.listTables();
// printing all the table names.
for (int i=0; i<tableDescriptor.length;i++ ){
System.out.println(tableDescriptor[i].getNameAsString());
}
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac ListTables.java
$java ListTablesWynik powinien być następujący:
User
empWyłączanie tabeli przy użyciu powłoki HBase
Aby usunąć tabelę lub zmienić jej ustawienia, musisz najpierw wyłączyć tabelę za pomocą polecenia disable. Możesz go ponownie włączyć za pomocą polecenia enable.
Poniżej podano składnię wyłączania tabeli:
disable ‘emp’Przykład
Poniżej podano przykład, który pokazuje, jak wyłączyć tabelę.
hbase(main):025:0> disable 'emp'
0 row(s) in 1.2760 secondsWeryfikacja
Po wyłączeniu stołu nadal możesz wyczuć jego istnienie list i existspolecenia. Nie możesz go zeskanować. To da następujący błąd.
hbase(main):028:0> scan 'emp'
ROW COLUMN + CELL
ERROR: emp is disabled.jest niepełnosprawny
To polecenie służy do sprawdzania, czy tabela jest wyłączona. Jego składnia jest następująca.
hbase> is_disabled 'table name'Poniższy przykład sprawdza, czy tabela o nazwie emp jest wyłączona. Jeśli jest wyłączona, zwróci wartość true, a jeśli nie, zwróci wartość false.
hbase(main):031:0> is_disabled 'emp'
true
0 row(s) in 0.0440 secondsWyłącz wszystkie
To polecenie służy do wyłączania wszystkich tabel pasujących do podanego wyrażenia regularnego. Składniadisable_all polecenie podano poniżej.
hbase> disable_all 'r.*'Załóżmy, że w HBase jest 5 tabel, mianowicie raja, rajani, rajendra, rajesh i raju. Poniższy kod wyłączy wszystkie tabele zaczynające się odraj.
hbase(main):002:07> disable_all 'raj.*'
raja
rajani
rajendra
rajesh
raju
Disable the above 5 tables (y/n)?
y
5 tables successfully disabledWyłącz tabelę za pomocą interfejsu API języka Java
Aby sprawdzić, czy tabela jest wyłączona, isTableDisabled() metoda jest używana i wyłącza tabelę, disableTable()metoda jest używana. Te metody należą doHBaseAdminklasa. Wykonaj kroki podane poniżej, aby wyłączyć tabelę.
Krok 1
Utwórz instancję HBaseAdmin klasa, jak pokazano poniżej.
// Creating configuration object
Configuration conf = HBaseConfiguration.create();
// Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);Krok 2
Sprawdź, czy tabela jest wyłączona za pomocą isTableDisabled() metoda, jak pokazano poniżej.
Boolean b = admin.isTableDisabled("emp");Krok 3
Jeśli tabela nie jest wyłączona, wyłącz ją, jak pokazano poniżej.
if(!b){
admin.disableTable("emp");
System.out.println("Table disabled");
}Poniżej podano kompletny program do weryfikacji, czy tabela jest wyłączona; jeśli nie, jak to wyłączyć.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DisableTable{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying weather the table is disabled
Boolean bool = admin.isTableDisabled("emp");
System.out.println(bool);
// Disabling the table using HBaseAdmin object
if(!bool){
admin.disableTable("emp");
System.out.println("Table disabled");
}
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac DisableTable.java
$java DsiableTableWynik powinien być następujący:
false
Table disabledWłączanie tabeli przy użyciu powłoki HBase
Składnia włączająca tabelę:
enable ‘emp’Przykład
Poniżej podano przykład włączenia tabeli.
hbase(main):005:0> enable 'emp'
0 row(s) in 0.4580 secondsWeryfikacja
Po włączeniu tabeli zeskanuj ją. Jeśli widzisz schemat, Twoja tabela została pomyślnie włączona.
hbase(main):006:0> scan 'emp'
ROW COLUMN + CELL
1 column = personal data:city, timestamp = 1417516501, value = hyderabad
1 column = personal data:name, timestamp = 1417525058, value = ramu
1 column = professional data:designation, timestamp = 1417532601, value = manager
1 column = professional data:salary, timestamp = 1417524244109, value = 50000
2 column = personal data:city, timestamp = 1417524574905, value = chennai
2 column = personal data:name, timestamp = 1417524556125, value = ravi
2 column = professional data:designation, timestamp = 14175292204, value = sr:engg
2 column = professional data:salary, timestamp = 1417524604221, value = 30000
3 column = personal data:city, timestamp = 1417524681780, value = delhi
3 column = personal data:name, timestamp = 1417524672067, value = rajesh
3 column = professional data:designation, timestamp = 14175246987, value = jr:engg
3 column = professional data:salary, timestamp = 1417524702514, value = 25000
3 row(s) in 0.0400 secondsjest włączony
To polecenie służy do sprawdzania, czy tabela jest włączona. Jego składnia jest następująca:
hbase> is_enabled 'table name'Poniższy kod sprawdza, czy tabela o nazwie empjest włączony. Jeśli jest włączona, zwróci wartość true, a jeśli nie, zwróci wartość false.
hbase(main):031:0> is_enabled 'emp'
true
0 row(s) in 0.0440 secondsWłącz tabelę za pomocą interfejsu API języka Java
Aby sprawdzić, czy tabela jest włączona, isTableEnabled()stosowana jest metoda; i włączyć tabelę,enableTable()metoda jest używana. Te metody należą doHBaseAdminklasa. Wykonaj czynności podane poniżej, aby włączyć tabelę.
Krok 1
Utwórz instancję HBaseAdmin klasa, jak pokazano poniżej.
// Creating configuration object
Configuration conf = HBaseConfiguration.create();
// Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);Krok 2
Sprawdź, czy tabela jest włączona przy użyciu isTableEnabled() metoda, jak pokazano poniżej.
Boolean bool = admin.isTableEnabled("emp");Krok 3
Jeśli tabela nie jest wyłączona, wyłącz ją, jak pokazano poniżej.
if(!bool){
admin.enableTable("emp");
System.out.println("Table enabled");
}Poniżej podano kompletny program do sprawdzenia, czy tablica jest włączona, a jeśli nie, to jak ją włączyć.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class EnableTable{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying whether the table is disabled
Boolean bool = admin.isTableEnabled("emp");
System.out.println(bool);
// Enabling the table using HBaseAdmin object
if(!bool){
admin.enableTable("emp");
System.out.println("Table Enabled");
}
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac EnableTable.java
$java EnableTableWynik powinien być następujący:
false
Table Enabledopisać
To polecenie zwraca opis tabeli. Jego składnia jest następująca:
hbase> describe 'table name'Poniżej podano wynik działania polecenia opisującego w pliku emp stół.
hbase(main):006:0> describe 'emp'
DESCRIPTION
ENABLED
'emp', {NAME ⇒ 'READONLY', DATA_BLOCK_ENCODING ⇒ 'NONE', BLOOMFILTER
⇒ 'ROW', REPLICATION_SCOPE ⇒ '0', COMPRESSION ⇒ 'NONE', VERSIONS ⇒
'1', TTL true
⇒ 'FOREVER', MIN_VERSIONS ⇒ '0', KEEP_DELETED_CELLS ⇒ 'false',
BLOCKSIZE ⇒ '65536', IN_MEMORY ⇒ 'false', BLOCKCACHE ⇒ 'true'}, {NAME
⇒ 'personal
data', DATA_BLOCK_ENCODING ⇒ 'NONE', BLOOMFILTER ⇒ 'ROW',
REPLICATION_SCOPE ⇒ '0', VERSIONS ⇒ '5', COMPRESSION ⇒ 'NONE',
MIN_VERSIONS ⇒ '0', TTL
⇒ 'FOREVER', KEEP_DELETED_CELLS ⇒ 'false', BLOCKSIZE ⇒ '65536',
IN_MEMORY ⇒ 'false', BLOCKCACHE ⇒ 'true'}, {NAME ⇒ 'professional
data', DATA_BLO
CK_ENCODING ⇒ 'NONE', BLOOMFILTER ⇒ 'ROW', REPLICATION_SCOPE ⇒ '0',
VERSIONS ⇒ '1', COMPRESSION ⇒ 'NONE', MIN_VERSIONS ⇒ '0', TTL ⇒
'FOREVER', K
EEP_DELETED_CELLS ⇒ 'false', BLOCKSIZE ⇒ '65536', IN_MEMORY ⇒
'false', BLOCKCACHE ⇒ 'true'}, {NAME ⇒ 'table_att_unset',
DATA_BLOCK_ENCODING ⇒ 'NO
NE', BLOOMFILTER ⇒ 'ROW', REPLICATION_SCOPE ⇒ '0', COMPRESSION ⇒
'NONE', VERSIONS ⇒ '1', TTL ⇒ 'FOREVER', MIN_VERSIONS ⇒ '0',
KEEP_DELETED_CELLS
⇒ 'false', BLOCKSIZE ⇒ '6zmieniać
Alter to polecenie używane do wprowadzania zmian w istniejącej tabeli. Za pomocą tego polecenia można zmienić maksymalną liczbę komórek w rodzinie kolumn, ustawić i usunąć operatory zakresu tabeli oraz usunąć rodzinę kolumn z tabeli.
Zmiana maksymalnej liczby komórek w rodzinie kolumn
Poniżej podano składnię zmiany maksymalnej liczby komórek w rodzinie kolumn.
hbase> alter 't1', NAME ⇒ 'f1', VERSIONS ⇒ 5W poniższym przykładzie maksymalna liczba komórek jest ustawiona na 5.
hbase(main):003:0> alter 'emp', NAME ⇒ 'personal data', VERSIONS ⇒ 5
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.3050 secondsOperatory zakresu tabeli
Za pomocą alter można ustawiać i usuwać operatory zakresu tabeli, takie jak MAX_FILESIZE, READONLY, MEMSTORE_FLUSHSIZE, DEFERRED_LOG_FLUSH itp.
Ustawienie tylko do odczytu
Poniżej podana jest składnia, aby tabela była tylko do odczytu.
hbase>alter 't1', READONLY(option)W poniższym przykładzie utworzyliśmy plik emp tabela tylko do odczytu.
hbase(main):006:0> alter 'emp', READONLY
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.2140 secondsUsuwanie operatorów zakresu tabeli
Możemy również usunąć operatory zakresu tabeli. Poniżej podano składnię usuwania „MAX_FILESIZE” z tabeli emp.
hbase> alter 't1', METHOD ⇒ 'table_att_unset', NAME ⇒ 'MAX_FILESIZE'Usuwanie rodziny kolumn
Używając alter, możesz również usunąć rodzinę kolumn. Poniżej podano składnię usuwania rodziny kolumn za pomocą funkcji alter.
hbase> alter ‘ table name ’, ‘delete’ ⇒ ‘ column family ’Poniżej podano przykład usuwania rodziny kolumn z tabeli „emp”.
Załóżmy, że w HBase istnieje tabela o nazwie pracownik. Zawiera następujące dane:
hbase(main):006:0> scan 'employee'
ROW COLUMN+CELL
row1 column = personal:city, timestamp = 1418193767, value = hyderabad
row1 column = personal:name, timestamp = 1418193806767, value = raju
row1 column = professional:designation, timestamp = 1418193767, value = manager
row1 column = professional:salary, timestamp = 1418193806767, value = 50000
1 row(s) in 0.0160 secondsTeraz usuńmy nazwaną rodzinę kolumn professional używając polecenia alter.
hbase(main):007:0> alter 'employee','delete'⇒'professional'
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.2380 secondsTeraz zweryfikuj dane w tabeli po zmianie. Zauważ, że rodzina kolumn „profesjonalny” już nie istnieje, ponieważ ją usunęliśmy.
hbase(main):003:0> scan 'employee'
ROW COLUMN + CELL
row1 column = personal:city, timestamp = 14181936767, value = hyderabad
row1 column = personal:name, timestamp = 1418193806767, value = raju
1 row(s) in 0.0830 secondsDodawanie rodziny kolumn za pomocą Java API
Za pomocą tej metody można dodać rodzinę kolumn do tabeli addColumn() z HBAseAdminklasa. Wykonaj czynności podane poniżej, aby dodać rodzinę kolumn do tabeli.
Krok 1
Utwórz wystąpienie HBaseAdmin klasa.
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);Krok 2
Plik addColumn() metoda wymaga nazwy tabeli i obiektu HColumnDescriptorklasa. Dlatego utwórz wystąpienieHColumnDescriptorklasa. KonstruktorHColumnDescriptorz kolei wymaga dodania nazwy rodziny kolumn. Tutaj dodajemy rodzinę kolumn o nazwie „contactDetails” do istniejącej tabeli „pracownik”.
// Instantiating columnDescriptor object
HColumnDescriptor columnDescriptor = new
HColumnDescriptor("contactDetails");Krok 3
Dodaj rodzinę słupów za pomocą addColumnmetoda. Podaj nazwę tabeli iHColumnDescriptor class jako parametry tej metody.
// Adding column family
admin.addColumn("employee", new HColumnDescriptor("columnDescriptor"));Poniżej podano kompletny program dodawania rodziny kolumn do istniejącej tabeli.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class AddColoumn{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class.
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class.
HBaseAdmin admin = new HBaseAdmin(conf);
// Instantiating columnDescriptor class
HColumnDescriptor columnDescriptor = new HColumnDescriptor("contactDetails");
// Adding column family
admin.addColumn("employee", columnDescriptor);
System.out.println("coloumn added");
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac AddColumn.java
$java AddColumnPowyższa kompilacja działa tylko wtedy, gdy ustawiłeś ścieżkę klas w „ .bashrc”. Jeśli nie, postępuj zgodnie z procedurą podaną poniżej, aby skompilować plik .java.
//if "/home/home/hadoop/hbase " is your Hbase home folder then.
$javac -cp /home/hadoop/hbase/lib/*: Demo.javaJeśli wszystko pójdzie dobrze, wygeneruje następujący wynik:
column addedUsuwanie rodziny kolumn za pomocą Java API
Za pomocą tej metody można usunąć rodzinę kolumn z tabeli deleteColumn() z HBAseAdminklasa. Wykonaj czynności podane poniżej, aby dodać rodzinę kolumn do tabeli.
Krok 1
Utwórz wystąpienie HBaseAdmin klasa.
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);Krok 2
Dodaj rodzinę słupów za pomocą deleteColumn()metoda. Przekaż nazwę tabeli i nazwę rodziny kolumn jako parametry do tej metody.
// Deleting column family
admin.deleteColumn("employee", "contactDetails");Poniżej podano kompletny program do usuwania rodziny kolumn z istniejącej tabeli.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DeleteColoumn{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class.
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class.
HBaseAdmin admin = new HBaseAdmin(conf);
// Deleting a column family
admin.deleteColumn("employee","contactDetails");
System.out.println("coloumn deleted");
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac DeleteColumn.java $java DeleteColumnWynik powinien być następujący:
column deletedIstnienie tabeli przy użyciu powłoki HBase
Możesz zweryfikować istnienie tabeli za pomocą existsKomenda. Poniższy przykład pokazuje, jak używać tego polecenia.
hbase(main):024:0> exists 'emp'
Table emp does exist
0 row(s) in 0.0750 seconds
==================================================================
hbase(main):015:0> exists 'student'
Table student does not exist
0 row(s) in 0.0480 secondsWeryfikacja istnienia tabeli przy użyciu interfejsu API języka Java
Możesz zweryfikować istnienie tabeli w HBase przy użyciu tableExists() metoda HBaseAdmin klasa. Wykonaj czynności podane poniżej, aby zweryfikować istnienie tabeli w HBase.
Krok 1
Instantiate the HBaseAdimn class
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);Krok 2
Sprawdź istnienie tabeli przy użyciu tableExists( ) metoda.
Poniżej podano program java do testowania istnienia tabeli w HBase przy użyciu java API.
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class TableExists{
public static void main(String args[])throws IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying the existance of the table
boolean bool = admin.tableExists("emp");
System.out.println( bool);
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac TableExists.java $java TableExistsWynik powinien być następujący:
trueUpuszczanie tabeli przy użyciu powłoki HBase
Używając droppolecenie, możesz usunąć tabelę. Przed upuszczeniem stołu musisz go wyłączyć.
hbase(main):018:0> disable 'emp'
0 row(s) in 1.4580 seconds
hbase(main):019:0> drop 'emp'
0 row(s) in 0.3060 secondsSprawdź, czy tabela została usunięta za pomocą polecenia istnieje.
hbase(main):020:07gt; exists 'emp'
Table emp does not exist
0 row(s) in 0.0730 secondsdrop_all
To polecenie służy do usuwania tabel pasujących do „wyrażenia regularnego” podanego w poleceniu. Jego składnia jest następująca:
hbase> drop_all ‘t.*’Note: Przed upuszczeniem stołu musisz go wyłączyć.
Przykład
Załóżmy, że istnieją tabele o nazwach raja, rajani, rajendra, rajesh i raju.
hbase(main):017:0> list
TABLE
raja
rajani
rajendra
rajesh
raju
9 row(s) in 0.0270 secondsWszystkie te tabele zaczynają się od liter raj. Przede wszystkim wyłączmy wszystkie te tabele za pomocą rozszerzeniadisable_all polecenie, jak pokazano poniżej.
hbase(main):002:0> disable_all 'raj.*'
raja
rajani
rajendra
rajesh
raju
Disable the above 5 tables (y/n)?
y
5 tables successfully disabledTeraz możesz usunąć je wszystkie za pomocą drop_all polecenie, jak podano poniżej.
hbase(main):018:0> drop_all 'raj.*'
raja
rajani
rajendra
rajesh
raju
Drop the above 5 tables (y/n)?
y
5 tables successfully droppedUsuwanie tabeli za pomocą Java API
Możesz usunąć tabelę za pomocą deleteTable() metoda w HBaseAdminklasa. Wykonaj poniższe czynności, aby usunąć tabelę za pomocą interfejsu API języka Java.
Krok 1
Utwórz wystąpienie klasy HBaseAdmin.
// creating a configuration object
Configuration conf = HBaseConfiguration.create();
// Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);Krok 2
Wyłącz tabelę za pomocą disableTable() metoda HBaseAdmin klasa.
admin.disableTable("emp1");Krok 3
Teraz usuń tabelę za pomocą deleteTable() metoda HBaseAdmin klasa.
admin.deleteTable("emp12");Poniżej podano kompletny program java do usuwania tabeli w HBase.
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DeleteTable {
public static void main(String[] args) throws IOException {
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// disabling table named emp
admin.disableTable("emp12");
// Deleting emp
admin.deleteTable("emp12");
System.out.println("Table deleted");
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac DeleteTable.java $java DeleteTableWynik powinien być następujący:
Table deletedwyjście
Wychodzisz z powłoki, wpisując exit Komenda.
hbase(main):021:0> exitZatrzymywanie HBase
Aby zatrzymać HBase, przejdź do folderu domowego HBase i wpisz następujące polecenie.
./bin/stop-hbase.shZatrzymywanie HBase przy użyciu Java API
Możesz zamknąć HBase za pomocą shutdown() metoda HBaseAdminklasa. Wykonaj kroki podane poniżej, aby zamknąć HBase:
Krok 1
Utwórz wystąpienie klasy HbaseAdmin.
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);Krok 2
Zamknij HBase za pomocą shutdown() metoda HBaseAdmin klasa.
admin.shutdown();Poniżej podano program zatrzymania HBase.
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class ShutDownHbase{
public static void main(String args[])throws IOException {
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Shutting down HBase
System.out.println("Shutting down hbase");
admin.shutdown();
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac ShutDownHbase.java $java ShutDownHbaseWynik powinien być następujący:
Shutting down hbaseW tym rozdziale opisano interfejs API klienta Java dla HBase, który jest używany do wykonywania CRUDoperacje na tabelach HBase. HBase jest napisany w języku Java i ma natywny interfejs API języka Java. Dlatego zapewnia programistyczny dostęp do języka manipulacji danymi (DML).
Konfiguracja klasy HBase
Dodaje pliki konfiguracyjne HBase do pliku Configuration. Ta klasa należy doorg.apache.hadoop.hbase pakiet.
Metody i opis
| S.No. | Metody i opis |
|---|---|
| 1 | static org.apache.hadoop.conf.Configuration create() Ta metoda tworzy konfigurację z zasobami HBase. |
Klasa HTable
HTable to wewnętrzna klasa HBase, która reprezentuje tabelę HBase. Jest to implementacja tabeli używanej do komunikacji z pojedynczą tabelą HBase. Ta klasa należy doorg.apache.hadoop.hbase.client klasa.
Konstruktorzy
| S.No. | Konstruktorzy i opis |
|---|---|
| 1 | HTable() |
| 2 | HTable(TableName tableName, ClusterConnection connection, ExecutorService pool) Korzystając z tego konstruktora, możesz utworzyć obiekt, aby uzyskać dostęp do tabeli HBase. |
Metody i opis
| S.No. | Metody i opis |
|---|---|
| 1 | void close() Zwalnia wszystkie zasoby HTable. |
| 2 | void delete(Delete delete) Usuwa określone komórki / wiersz. |
| 3 | boolean exists(Get get) Korzystając z tej metody, możesz przetestować istnienie kolumn w tabeli, zgodnie z instrukcją Get. |
| 4 | Result get(Get get) Pobiera określone komórki z danego wiersza. |
| 5 | org.apache.hadoop.conf.Configuration getConfiguration() Zwraca obiekt Configuration używany przez to wystąpienie. |
| 6 | TableName getName() Zwraca instancję nazwy tabeli dla tej tabeli. |
| 7 | HTableDescriptor getTableDescriptor() Zwraca deskryptor tabeli dla tej tabeli. |
| 8 | byte[] getTableName() Zwraca nazwę tej tabeli. |
| 9 | void put(Put put) Korzystając z tej metody, możesz wstawić dane do tabeli. |
Klasa Put
Ta klasa służy do wykonywania operacji wysyłania dla jednego wiersza. Należy doorg.apache.hadoop.hbase.client pakiet.
Konstruktorzy
| S.No. | Konstruktorzy i opis |
|---|---|
| 1 | Put(byte[] row) Korzystając z tego konstruktora, możesz utworzyć operację wysyłania dla określonego wiersza. |
| 2 | Put(byte[] rowArray, int rowOffset, int rowLength) Korzystając z tego konstruktora, możesz utworzyć kopię przekazanego klucza wiersza, aby zachować lokalny. |
| 3 | Put(byte[] rowArray, int rowOffset, int rowLength, long ts) Korzystając z tego konstruktora, możesz utworzyć kopię przekazanego klucza wiersza, aby zachować lokalny. |
| 4 | Put(byte[] row, long ts) Korzystając z tego konstruktora, możemy utworzyć operację Put dla określonego wiersza, używając podanego znacznika czasu. |
Metody
| S.No. | Metody i opis |
|---|---|
| 1 | Put add(byte[] family, byte[] qualifier, byte[] value) Dodaje określoną kolumnę i wartość do tej operacji wysyłania. |
| 2 | Put add(byte[] family, byte[] qualifier, long ts, byte[] value) Dodaje określoną kolumnę i wartość z określoną sygnaturą czasową jako wersją do tej operacji Put. |
| 3 | Put add(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value) Dodaje określoną kolumnę i wartość z określoną sygnaturą czasową jako wersją do tej operacji Put. |
| 4 | Put add(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value) Dodaje określoną kolumnę i wartość z określoną sygnaturą czasową jako wersją do tej operacji Put. |
Klasa Get
Ta klasa jest używana do wykonywania operacji Get na jednym wierszu. Ta klasa należy doorg.apache.hadoop.hbase.client pakiet.
Konstruktor
| S.No. | Konstruktor i opis |
|---|---|
| 1 | Get(byte[] row) Korzystając z tego konstruktora, możesz utworzyć operację Get dla określonego wiersza. |
| 2 | Get(Get get) |
Metody
| S.No. | Metody i opis |
|---|---|
| 1 | Get addColumn(byte[] family, byte[] qualifier) Pobiera kolumnę z określonej rodziny z określonym kwalifikatorem. |
| 2 | Get addFamily(byte[] family) Pobiera wszystkie kolumny z określonej rodziny. |
Klasa Usuń
Ta klasa służy do wykonywania operacji usuwania w jednym wierszu. Aby usunąć cały wiersz, utwórz wystąpienie obiektu Delete z wierszem do usunięcia. Ta klasa należy doorg.apache.hadoop.hbase.client pakiet.
Konstruktor
| S.No. | Konstruktor i opis |
|---|---|
| 1 | Delete(byte[] row) Tworzy operację usuwania dla określonego wiersza. |
| 2 | Delete(byte[] rowArray, int rowOffset, int rowLength) Tworzy operację usuwania dla określonego wiersza i sygnatury czasowej. |
| 3 | Delete(byte[] rowArray, int rowOffset, int rowLength, long ts) Tworzy operację usuwania dla określonego wiersza i sygnatury czasowej. |
| 4 | Delete(byte[] row, long timestamp) Tworzy operację usuwania dla określonego wiersza i sygnatury czasowej. |
Metody
| S.No. | Metody i opis |
|---|---|
| 1 | Delete addColumn(byte[] family, byte[] qualifier) Usuwa najnowszą wersję określonej kolumny. |
| 2 | Delete addColumns(byte[] family, byte[] qualifier, long timestamp) Usuwa wszystkie wersje określonej kolumny z sygnaturą czasową mniejszą lub równą podanej sygnaturze czasowej. |
| 3 | Delete addFamily(byte[] family) Usuwa wszystkie wersje wszystkich kolumn z określonej rodziny. |
| 4 | Delete addFamily(byte[] family, long timestamp) Usuwa wszystkie kolumny z określonej rodziny z datownikiem mniejszym lub równym podanej sygnaturze czasowej. |
Wynik klasy
Ta klasa służy do uzyskiwania wyniku pojedynczego wiersza zapytania Get lub Scan.
Konstruktorzy
| S.No. | Konstruktorzy |
|---|---|
| 1 | Result() Za pomocą tego konstruktora można utworzyć pusty wynik Wynik bez ładunku KeyValue; zwraca wartość null, jeśli wywołasz raw Cells (). |
Metody
| S.No. | Metody i opis |
|---|---|
| 1 | byte[] getValue(byte[] family, byte[] qualifier) Ta metoda służy do uzyskania najnowszej wersji określonej kolumny. |
| 2 | byte[] getRow() Ta metoda służy do pobierania klucza wiersza, który odpowiada wierszowi, z którego utworzono ten wynik. |
Wstawianie danych przy użyciu powłoki HBase
W tym rozdziale pokazano, jak tworzyć dane w tabeli HBase. Aby utworzyć dane w tabeli HBase, używane są następujące polecenia i metody:
put Komenda,
add() metoda Put klasa i
put() metoda HTable klasa.
Jako przykład utworzymy następującą tabelę w HBase.
Za pomocą putpolecenie, możesz wstawiać wiersze do tabeli. Jego składnia jest następująca:
put ’<table name>’,’row1’,’<colfamily:colname>’,’<value>’Wstawianie pierwszego rzędu
Wstawmy wartości pierwszego wiersza do tabeli emp, jak pokazano poniżej.
hbase(main):005:0> put 'emp','1','personal data:name','raju'
0 row(s) in 0.6600 seconds
hbase(main):006:0> put 'emp','1','personal data:city','hyderabad'
0 row(s) in 0.0410 seconds
hbase(main):007:0> put 'emp','1','professional
data:designation','manager'
0 row(s) in 0.0240 seconds
hbase(main):007:0> put 'emp','1','professional data:salary','50000'
0 row(s) in 0.0240 secondsWstaw pozostałe wiersze za pomocą polecenia put w ten sam sposób. Jeśli wstawisz całą tabelę, otrzymasz następujący wynik.
hbase(main):022:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:city, timestamp=1417524216501, value=hyderabad
1 column=personal data:name, timestamp=1417524185058, value=ramu
1 column=professional data:designation, timestamp=1417524232601,
value=manager
1 column=professional data:salary, timestamp=1417524244109, value=50000
2 column=personal data:city, timestamp=1417524574905, value=chennai
2 column=personal data:name, timestamp=1417524556125, value=ravi
2 column=professional data:designation, timestamp=1417524592204,
value=sr:engg
2 column=professional data:salary, timestamp=1417524604221, value=30000
3 column=personal data:city, timestamp=1417524681780, value=delhi
3 column=personal data:name, timestamp=1417524672067, value=rajesh
3 column=professional data:designation, timestamp=1417524693187,
value=jr:engg
3 column=professional data:salary, timestamp=1417524702514,
value=25000Wstawianie danych za pomocą Java API
Możesz wstawić dane do Hbase za pomocą add() metoda Putklasa. Możesz go zapisać za pomocąput() metoda HTableklasa. Te klasy należą doorg.apache.hadoop.hbase.clientpakiet. Poniżej podano kroki, aby utworzyć dane w tabeli HBase.
Krok 1: Utwórz wystąpienie klasy konfiguracji
Plik Configurationklasa dodaje pliki konfiguracyjne HBase do swojego obiektu. Możesz utworzyć obiekt konfiguracyjny za pomocącreate() metoda HbaseConfiguration klasa, jak pokazano poniżej.
Configuration conf = HbaseConfiguration.create();Krok 2: Utwórz wystąpienie klasy HTable
Masz klasę o nazwie HTable, implementacja tabeli w HBase. Ta klasa służy do komunikacji z pojedynczą tabelą HBase. Podczas tworzenia instancji tej klasy przyjmuje obiekt konfiguracyjny i nazwę tabeli jako parametry. Możesz utworzyć instancję klasy HTable, jak pokazano poniżej.
HTable hTable = new HTable(conf, tableName);Krok 3: Utwórz wystąpienie PutClass
Aby wstawić dane do tabeli HBase, plik add()metoda i jej warianty. Ta metoda należy doPut, dlatego utwórz wystąpienie klasy put. Ta klasa wymaga nazwy wiersza, do którego chcesz wstawić dane, w formacie ciągu. Możesz utworzyć wystąpieniePut klasa, jak pokazano poniżej.
Put p = new Put(Bytes.toBytes("row1"));Krok 4: InsertData
Plik add() metoda Putklasa służy do wstawiania danych. Wymaga 3-bajtowych tablic reprezentujących odpowiednio rodzinę kolumn, kwalifikator kolumny (nazwę kolumny) i wartość do wstawienia. Wstaw dane do tabeli HBase za pomocą metody add (), jak pokazano poniżej.
p.add(Bytes.toBytes("coloumn family "), Bytes.toBytes("column
name"),Bytes.toBytes("value"));Krok 5: Zapisz dane w tabeli
Po wstawieniu wymaganych wierszy zapisz zmiany, dodając wystąpienie put do pliku put() metoda klasy HTable, jak pokazano poniżej.
hTable.put(p);Krok 6: Zamknij instancję HTable
Po utworzeniu danych w tabeli HBase zamknij plik HTable wystąpienie przy użyciu close() metoda, jak pokazano poniżej.
hTable.close();Poniżej podano kompletny program do tworzenia danych w tabeli HBase.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class InsertData{
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable hTable = new HTable(config, "emp");
// Instantiating Put class
// accepts a row name.
Put p = new Put(Bytes.toBytes("row1"));
// adding values using add() method
// accepts column family name, qualifier/row name ,value
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("name"),Bytes.toBytes("raju"));
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("hyderabad"));
p.add(Bytes.toBytes("professional"),Bytes.toBytes("designation"),
Bytes.toBytes("manager"));
p.add(Bytes.toBytes("professional"),Bytes.toBytes("salary"),
Bytes.toBytes("50000"));
// Saving the put Instance to the HTable.
hTable.put(p);
System.out.println("data inserted");
// closing HTable
hTable.close();
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac InsertData.java $java InsertDataWynik powinien być następujący:
data insertedAktualizowanie danych przy użyciu powłoki HBase
Możesz zaktualizować istniejącą wartość komórki za pomocą putKomenda. Aby to zrobić, po prostu postępuj zgodnie z tą samą składnią i podaj nową wartość, jak pokazano poniżej.
put ‘table name’,’row ’,'Column family:column name',’new value’Nowo podana wartość zastępuje istniejącą wartość, aktualizując wiersz.
Przykład
Załóżmy, że w HBase jest tabela o nazwie emp z następującymi danymi.
hbase(main):003:0> scan 'emp'
ROW COLUMN + CELL
row1 column = personal:name, timestamp = 1418051555, value = raju
row1 column = personal:city, timestamp = 1418275907, value = Hyderabad
row1 column = professional:designation, timestamp = 14180555,value = manager
row1 column = professional:salary, timestamp = 1418035791555,value = 50000
1 row(s) in 0.0100 secondsNastępujące polecenie zaktualizuje wartość miasta pracownika o imieniu „Raju” do Delhi.
hbase(main):002:0> put 'emp','row1','personal:city','Delhi'
0 row(s) in 0.0400 secondsZaktualizowana tabela wygląda następująco, w której można obserwować, że miasto Raju zostało zmienione na „Delhi”.
hbase(main):003:0> scan 'emp'
ROW COLUMN + CELL
row1 column = personal:name, timestamp = 1418035791555, value = raju
row1 column = personal:city, timestamp = 1418274645907, value = Delhi
row1 column = professional:designation, timestamp = 141857555,value = manager
row1 column = professional:salary, timestamp = 1418039555, value = 50000
1 row(s) in 0.0100 secondsAktualizacja danych za pomocą Java API
Możesz zaktualizować dane w określonej komórce za pomocą put()metoda. Wykonaj czynności podane poniżej, aby zaktualizować istniejącą wartość komórki tabeli.
Krok 1: Utwórz wystąpienie klasy konfiguracji
Configurationklasa dodaje pliki konfiguracyjne HBase do swojego obiektu. Możesz utworzyć obiekt konfiguracyjny za pomocącreate() metoda HbaseConfiguration klasa, jak pokazano poniżej.
Configuration conf = HbaseConfiguration.create();Krok 2: Utwórz wystąpienie klasy HTable
Masz klasę o nazwie HTable, implementacja tabeli w HBase. Ta klasa służy do komunikacji z pojedynczą tabelą HBase. Podczas tworzenia instancji tej klasy przyjmuje obiekt konfiguracyjny i nazwę tabeli jako parametry. Możesz utworzyć wystąpienie klasy HTable, jak pokazano poniżej.
HTable hTable = new HTable(conf, tableName);Krok 3: Utwórz wystąpienie klasy Put
Aby wstawić dane do tabeli HBase, plik add()metoda i jej warianty. Ta metoda należy doPut, dlatego utwórz wystąpienie putklasa. Ta klasa wymaga nazwy wiersza, do którego chcesz wstawić dane, w formacie ciągu. Możesz utworzyć wystąpieniePut klasa, jak pokazano poniżej.
Put p = new Put(Bytes.toBytes("row1"));Krok 4: Zaktualizuj istniejącą komórkę
Plik add() metoda Putklasa służy do wstawiania danych. Wymaga 3-bajtowych tablic reprezentujących odpowiednio rodzinę kolumn, kwalifikator kolumny (nazwę kolumny) i wartość do wstawienia. Wstaw dane do tabeli HBase przy użyciu rozszerzeniaadd() metoda, jak pokazano poniżej.
p.add(Bytes.toBytes("coloumn family "), Bytes.toBytes("column
name"),Bytes.toBytes("value"));
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("Delih"));Krok 5: Zapisz dane w tabeli
Po wstawieniu wymaganych wierszy zapisz zmiany, dodając wystąpienie put do pliku put() metoda klasy HTable, jak pokazano poniżej.
hTable.put(p);Krok 6: Zamknij instancję HTable
Po utworzeniu danych w tabeli HBase zamknij plik HTable wystąpienie przy użyciu metody close (), jak pokazano poniżej.
hTable.close();Poniżej podano kompletny program do aktualizacji danych w konkretnej tabeli.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class UpdateData{
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable hTable = new HTable(config, "emp");
// Instantiating Put class
//accepts a row name
Put p = new Put(Bytes.toBytes("row1"));
// Updating a cell value
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("Delih"));
// Saving the put Instance to the HTable.
hTable.put(p);
System.out.println("data Updated");
// closing HTable
hTable.close();
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac UpdateData.java $java UpdateDataWynik powinien być następujący:
data UpdatedOdczytywanie danych przy użyciu powłoki HBase
Plik get polecenie i get() metoda HTableklasy służą do odczytu danych z tabeli w HBase. Za pomocągetpolecenie, możesz uzyskać pojedynczy wiersz danych naraz. Jego składnia jest następująca:
get ’<table name>’,’row1’Przykład
Poniższy przykład pokazuje, jak używać polecenia get. Przeanalizujmy pierwszy wiersz plikuemp stół.
hbase(main):012:0> get 'emp', '1'
COLUMN CELL
personal : city timestamp = 1417521848375, value = hyderabad
personal : name timestamp = 1417521785385, value = ramu
professional: designation timestamp = 1417521885277, value = manager
professional: salary timestamp = 1417521903862, value = 50000
4 row(s) in 0.0270 secondsCzytanie określonej kolumny
Poniżej podano składnię służącą do odczytywania określonej kolumny przy użyciu rozszerzenia get metoda.
hbase> get 'table name', ‘rowid’, {COLUMN ⇒ ‘column family:column name ’}Przykład
Poniżej podano przykład odczytu określonej kolumny w tabeli HBase.
hbase(main):015:0> get 'emp', 'row1', {COLUMN ⇒ 'personal:name'}
COLUMN CELL
personal:name timestamp = 1418035791555, value = raju
1 row(s) in 0.0080 secondsOdczytywanie danych za pomocą Java API
Aby odczytać dane z tabeli HBase, użyj get()metoda klasy HTable. Ta metoda wymaga wystąpieniaGetklasa. Wykonaj czynności podane poniżej, aby pobrać dane z tabeli HBase.
Krok 1: Utwórz wystąpienie klasy konfiguracji
Configurationklasa dodaje pliki konfiguracyjne HBase do swojego obiektu. Możesz utworzyć obiekt konfiguracyjny za pomocącreate() metoda HbaseConfiguration klasa, jak pokazano poniżej.
Configuration conf = HbaseConfiguration.create();Krok 2: Utwórz wystąpienie klasy HTable
Masz klasę o nazwie HTable, implementacja tabeli w HBase. Ta klasa służy do komunikacji z pojedynczą tabelą HBase. Podczas tworzenia instancji tej klasy przyjmuje obiekt konfiguracyjny i nazwę tabeli jako parametry. Możesz utworzyć wystąpienie klasy HTable, jak pokazano poniżej.
HTable hTable = new HTable(conf, tableName);Krok 3: Utwórz wystąpienie klasy Get
Możesz pobrać dane z tabeli HBase przy użyciu get() metoda HTableklasa. Ta metoda wyodrębnia komórkę z danego wiersza. WymagaGetobiekt klasy jako parametr. Utwórz go, jak pokazano poniżej.
Get get = new Get(toBytes("row1"));Krok 4: Przeczytaj dane
Podczas pobierania danych można uzyskać pojedynczy wiersz według identyfikatora lub zestaw wierszy według zestawu identyfikatorów wierszy albo przeskanować całą tabelę lub podzbiór wierszy.
Możesz pobrać dane tabeli HBase przy użyciu wariantów metody Add w Get klasa.
Aby uzyskać określoną kolumnę z określonej rodziny kolumn, użyj następującej metody.
get.addFamily(personal)Aby pobrać wszystkie kolumny z określonej rodziny kolumn, użyj następującej metody.
get.addColumn(personal, name)Krok 5: Uzyskaj wynik
Uzyskaj wynik, przekazując swój Get klasy do metody get klasy HTableklasa. Ta metoda zwracaResultclass, który przechowuje żądany wynik. Poniżej podano sposób użyciaget() metoda.
Result result = table.get(g);Krok 6: Odczytywanie wartości z wystąpienia wyniku
Plik Result klasa zapewnia getValue()metoda odczytywania wartości z jej instancji. Użyj go, jak pokazano poniżej, aby odczytać wartości z plikuResult instancja.
byte [] value = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("name"));
byte [] value1 = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("city"));Poniżej podano kompletny program do odczytu wartości z tabeli HBase.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.util.Bytes;
public class RetriveData{
public static void main(String[] args) throws IOException, Exception{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, "emp");
// Instantiating Get class
Get g = new Get(Bytes.toBytes("row1"));
// Reading the data
Result result = table.get(g);
// Reading values from Result class object
byte [] value = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("name"));
byte [] value1 = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("city"));
// Printing the values
String name = Bytes.toString(value);
String city = Bytes.toString(value1);
System.out.println("name: " + name + " city: " + city);
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac RetriveData.java $java RetriveDataWynik powinien być następujący:
name: Raju city: DelhiUsuwanie określonej komórki w tabeli
Używając deletepolecenie, możesz usunąć określoną komórkę w tabeli. Składniadelete polecenie jest następujące:
delete ‘<table name>’, ‘<row>’, ‘<column name >’, ‘<time stamp>’Przykład
Oto przykład usunięcia określonej komórki. Tutaj usuwamy wynagrodzenie.
hbase(main):006:0> delete 'emp', '1', 'personal data:city',
1417521848375
0 row(s) in 0.0060 secondsUsuwanie wszystkich komórek w tabeli
Za pomocą polecenia „usuń wszystko” możesz usunąć wszystkie komórki w wierszu. Poniżej podano składnię polecenia deleteall.
deleteall ‘<table name>’, ‘<row>’,Przykład
Oto przykład polecenia „deleteall”, w którym usuwamy wszystkie komórki wiersza 1 tabeli emp.
hbase(main):007:0> deleteall 'emp','1'
0 row(s) in 0.0240 secondsSprawdź tabelę za pomocą scanKomenda. Migawka tabeli po usunięciu tabeli znajduje się poniżej.
hbase(main):022:0> scan 'emp'
ROW COLUMN + CELL
2 column = personal data:city, timestamp = 1417524574905, value = chennai
2 column = personal data:name, timestamp = 1417524556125, value = ravi
2 column = professional data:designation, timestamp = 1417524204, value = sr:engg
2 column = professional data:salary, timestamp = 1417524604221, value = 30000
3 column = personal data:city, timestamp = 1417524681780, value = delhi
3 column = personal data:name, timestamp = 1417524672067, value = rajesh
3 column = professional data:designation, timestamp = 1417523187, value = jr:engg
3 column = professional data:salary, timestamp = 1417524702514, value = 25000Usuwanie danych za pomocą Java API
Możesz usunąć dane z tabeli HBase przy użyciu delete() metoda HTableklasa. Wykonaj czynności podane poniżej, aby usunąć dane z tabeli.
Krok 1: Utwórz wystąpienie klasy konfiguracji
Configurationklasa dodaje pliki konfiguracyjne HBase do swojego obiektu. Możesz utworzyć obiekt konfiguracyjny za pomocącreate() metoda HbaseConfiguration klasa, jak pokazano poniżej.
Configuration conf = HbaseConfiguration.create();Krok 2: Utwórz wystąpienie klasy HTable
Masz klasę o nazwie HTable, implementacja tabeli w HBase. Ta klasa służy do komunikacji z pojedynczą tabelą HBase. Podczas tworzenia instancji tej klasy przyjmuje obiekt konfiguracyjny i nazwę tabeli jako parametry. Możesz utworzyć wystąpienie klasy HTable, jak pokazano poniżej.
HTable hTable = new HTable(conf, tableName);Krok 3: Utwórz wystąpienie klasy Usuń
Utwórz wystąpienie Deleteklasę, przekazując identyfikator wiersza wiersza, który ma zostać usunięty, w formacie tablicy bajtów. Możesz również przekazać temu konstruktorowi znacznik czasu i Rowlock.
Delete delete = new Delete(toBytes("row1"));Krok 4: Wybierz dane do usunięcia
Możesz usunąć dane za pomocą metod usuwania pliku Deleteklasa. Ta klasa ma różne metody usuwania. Wybierz kolumny lub rodziny kolumn do usunięcia za pomocą tych metod. Spójrz na poniższe przykłady, które pokazują użycie metod klasy Delete.
delete.deleteColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
delete.deleteFamily(Bytes.toBytes("professional"));Krok 5: Usuń dane
Usuń wybrane dane, przekazując plik delete wystąpienie do delete() metoda HTable klasa, jak pokazano poniżej.
table.delete(delete);Krok 6: Zamknij HTableInstance
Po usunięciu danych zamknij plik HTable Instancja.
table.close();Poniżej podano kompletny program do usuwania danych z tabeli HBase.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.util.Bytes;
public class DeleteData {
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(conf, "employee");
// Instantiating Delete class
Delete delete = new Delete(Bytes.toBytes("row1"));
delete.deleteColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
delete.deleteFamily(Bytes.toBytes("professional"));
// deleting the data
table.delete(delete);
// closing the HTable object
table.close();
System.out.println("data deleted.....");
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac Deletedata.java $java DeleteDataWynik powinien być następujący:
data deletedSkanowanie przy użyciu powłoki HBase
Plik scanpolecenie służy do przeglądania danych w HTable. Za pomocą polecenia skanowania możesz pobrać dane tabeli. Jego składnia jest następująca:
scan ‘<table name>’Przykład
Poniższy przykład pokazuje, jak odczytywać dane z tabeli za pomocą polecenia scan. Tutaj czytamyemp stół.
hbase(main):010:0> scan 'emp'
ROW COLUMN + CELL
1 column = personal data:city, timestamp = 1417521848375, value = hyderabad
1 column = personal data:name, timestamp = 1417521785385, value = ramu
1 column = professional data:designation, timestamp = 1417585277,value = manager
1 column = professional data:salary, timestamp = 1417521903862, value = 50000
1 row(s) in 0.0370 secondsSkanowanie za pomocą Java API
Kompletny program do skanowania całej tabeli danych za pomocą interfejsu API języka Java jest następujący.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
public class ScanTable{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, "emp");
// Instantiating the Scan class
Scan scan = new Scan();
// Scanning the required columns
scan.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
scan.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("city"));
// Getting the scan result
ResultScanner scanner = table.getScanner(scan);
// Reading values from scan result
for (Result result = scanner.next(); result != null; result = Scanner.next())
System.out.println("Found row : " + result);
//closing the scanner
scanner.close();
}
}Skompiluj i wykonaj powyższy program, jak pokazano poniżej.
$javac ScanTable.java $java ScanTableWynik powinien być następujący:
Found row :
keyvalues={row1/personal:city/1418275612888/Put/vlen=5/mvcc=0,
row1/personal:name/1418035791555/Put/vlen=4/mvcc=0}liczyć
Możesz policzyć liczbę wierszy tabeli za pomocą countKomenda. Jego składnia jest następująca:
count ‘<table name>’Po usunięciu pierwszego wiersza tabela emp będzie miała dwa wiersze. Sprawdź, jak pokazano poniżej.
hbase(main):023:0> count 'emp'
2 row(s) in 0.090 seconds
⇒ 2ścięty
To polecenie wyłącza upuszczanie i odtwarza tabelę. Składniatruncate następująco:
hbase> truncate 'table name'Przykład
Poniżej podano przykład polecenia obcięcia. Tutaj obcięliśmyemp stół.
hbase(main):011:0> truncate 'emp'
Truncating 'one' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 1.5950 secondsPo obcięciu tabeli użyj polecenia skanowania, aby zweryfikować. Otrzymasz tabelę z zerowymi wierszami.
hbase(main):017:0> scan ‘emp’
ROW COLUMN + CELL
0 row(s) in 0.3110 secondsW HBase możemy nadawać i cofać uprawnienia użytkownikom. Istnieją trzy polecenia ze względów bezpieczeństwa: grant, revoke i user_permission.
dotacja
Plik grantpolecenie przyznaje określone prawa, takie jak odczyt, zapis, wykonywanie i administrator tabeli dla określonego użytkownika. Składnia polecenia grant jest następująca:
hbase> grant <user> <permissions> [<table> [<column family> [<column; qualifier>]]Możemy nadać zero lub więcej uprawnień użytkownikowi z zestawu RWXCA, gdzie
- R - reprezentuje przywilej czytania.
- W - reprezentuje uprawnienie do zapisu.
- X - reprezentuje uprawnienie do wykonywania.
- C - reprezentuje uprawnienie do tworzenia.
- A - reprezentuje uprawnienia administratora.
Poniżej podano przykład, który przyznaje wszystkie uprawnienia użytkownikowi o nazwie „Tutorialspoint”.
hbase(main):018:0> grant 'Tutorialspoint', 'RWXCA'unieważnić
Plik revokepolecenie służy do unieważnienia praw dostępu użytkownika do tabeli. Jego składnia jest następująca:
hbase> revoke <user>Poniższy kod odwołuje wszystkie uprawnienia od użytkownika o nazwie „Tutorialspoint”.
hbase(main):006:0> revoke 'Tutorialspoint'user_permission
To polecenie służy do wyświetlenia wszystkich uprawnień dla określonej tabeli. Składniauser_permission następująco:
hbase>user_permission ‘tablename’Poniższy kod zawiera listę wszystkich uprawnień użytkownika tabeli „emp”.
hbase(main):013:0> user_permission 'emp'