Hive - wprowadzenie
Termin „Big Data” jest używany w odniesieniu do zbiorów dużych zbiorów danych, które obejmują olbrzymią ilość, dużą prędkość i różnorodność danych, których liczba rośnie z dnia na dzień. Przy użyciu tradycyjnych systemów zarządzania danymi trudno jest przetwarzać Big Data. Dlatego Apache Software Foundation wprowadziła platformę o nazwie Hadoop, aby rozwiązywać problemy związane z zarządzaniem i przetwarzaniem Big Data.
Hadoop
Hadoop to platforma typu open source do przechowywania i przetwarzania Big Data w środowisku rozproszonym. Zawiera dwa moduły, jeden to MapReduce, a drugi to Hadoop Distributed File System (HDFS).
MapReduce: Jest to równoległy model programowania służący do przetwarzania dużych ilości ustrukturyzowanych, częściowo ustrukturyzowanych i nieustrukturyzowanych danych na dużych klastrach towarowego sprzętu.
HDFS:Rozproszony system plików Hadoop jest częścią struktury Hadoop używanej do przechowywania i przetwarzania zestawów danych. Zapewnia odporny na uszkodzenia system plików do uruchamiania na standardowym sprzęcie.
Ekosystem Hadoop zawiera różne podprojekty (narzędzia), takie jak Sqoop, Pig i Hive, które są używane do pomocy modułom Hadoop.
Sqoop: Służy do importowania i eksportowania danych do i pomiędzy HDFS i RDBMS.
Pig: Jest to proceduralna platforma językowa używana do tworzenia skryptu dla operacji MapReduce.
Hive: Jest to platforma służąca do tworzenia skryptów typu SQL do wykonywania operacji MapReduce.
Note: Istnieją różne sposoby wykonywania operacji MapReduce:
- Tradycyjne podejście z wykorzystaniem programu Java MapReduce do danych ustrukturyzowanych, częściowo ustrukturyzowanych i nieustrukturyzowanych.
- Podejście skryptowe dla MapReduce do przetwarzania ustrukturyzowanych i częściowo ustrukturyzowanych danych przy użyciu Pig.
- Język zapytań Hive (HiveQL lub HQL) dla MapReduce do przetwarzania danych strukturalnych przy użyciu Hive.
Co to jest Hive
Hive to narzędzie infrastruktury hurtowni danych do przetwarzania ustrukturyzowanych danych na platformie Hadoop. Znajduje się na szczycie Hadoop, aby podsumować Big Data i ułatwia wykonywanie zapytań i analizowanie.
Początkowo Hive został opracowany przez Facebooka, później Apache Software Foundation przejęła go i dalej rozwijała jako open source pod nazwą Apache Hive. Jest używany przez różne firmy. Na przykład Amazon używa go w Amazon Elastic MapReduce.
Hive nie jest
- Relacyjna baza danych
- Projekt dla przetwarzania transakcji online (OLTP)
- Język do zapytań w czasie rzeczywistym i aktualizacji na poziomie wiersza
Funkcje ula
- Przechowuje schemat w bazie danych i przetwarzane dane w HDFS.
- Jest przeznaczony dla OLAP.
- Udostępnia język typu SQL do wykonywania zapytań o nazwie HiveQL lub HQL.
- Jest znany, szybki, skalowalny i rozszerzalny.
Architektura ula
Poniższy diagram składników przedstawia architekturę Hive:

Ten schemat komponentów zawiera różne jednostki. W poniższej tabeli opisano każdą jednostkę:
| Nazwa jednostki | Operacja |
|---|---|
| Interfejs użytkownika | Hive to oprogramowanie infrastruktury hurtowni danych, które może tworzyć interakcje między użytkownikiem a systemem plików HDFS. Interfejsy użytkownika obsługiwane przez Hive to Hive Web UI, Hive Command Line i Hive HD Insight (na serwerze Windows). |
| Meta Store | Hive wybiera odpowiednie serwery baz danych do przechowywania schematu lub metadanych tabel, baz danych, kolumn w tabeli, ich typów danych i mapowania HDFS. |
| Silnik procesów HiveQL | HiveQL jest podobny do SQL do wykonywania zapytań dotyczących informacji o schemacie w Metastore. Jest to jeden z zamienników tradycyjnego podejścia do programu MapReduce. Zamiast pisać program MapReduce w Javie, możemy napisać zapytanie do zadania MapReduce i przetworzyć je. |
| Silnik wykonawczy | Częścią będącą połączeniem mechanizmu HiveQL Process Engine i MapReduce jest Hive Execution Engine. Silnik wykonawczy przetwarza zapytanie i generuje takie same wyniki, jak wyniki MapReduce. Wykorzystuje smak MapReduce. |
| HDFS lub HBASE | Rozproszony system plików Hadoop lub HBASE to techniki przechowywania danych służące do przechowywania danych w systemie plików. |
Działanie ula
Poniższy diagram przedstawia przepływ pracy między Hive i Hadoop.
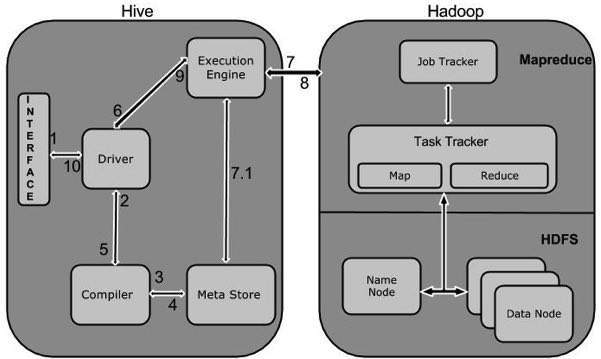
W poniższej tabeli zdefiniowano, jak Hive współdziała z platformą Hadoop:
| Krok nr | Operacja |
|---|---|
| 1 | Execute Query
Interfejs Hive, taki jak wiersz poleceń lub interfejs użytkownika sieci Web, wysyła zapytanie do sterownika (dowolnego sterownika bazy danych, takiego jak JDBC, ODBC itp.) W celu wykonania. |
| 2 | Get Plan
Sterownik korzysta z pomocy kompilatora zapytań, który analizuje zapytanie w celu sprawdzenia składni i planu zapytania lub wymagań zapytania. |
| 3 | Get Metadata
Kompilator wysyła żądanie metadanych do Metastore (dowolnej bazy danych). |
| 4 | Send Metadata
Metastore wysyła metadane jako odpowiedź do kompilatora. |
| 5 | Send Plan
Kompilator sprawdza wymagania i ponownie przesyła plan do sterownika. Do tej pory analizowanie i kompilowanie zapytania zostało zakończone. |
| 6 | Execute Plan
Kierowca przesyła plan wykonania do silnika wykonawczego. |
| 7 | Execute Job
Wewnętrznie proces wykonania zadania jest zadaniem MapReduce. Silnik wykonawczy wysyła zadanie do JobTracker, który znajduje się w węźle Nazwa i przypisuje to zadanie do TaskTracker, który znajduje się w węźle danych. Tutaj zapytanie wykonuje zadanie MapReduce. |
| 7.1 | Metadata Ops
W międzyczasie silnik wykonawczy może wykonywać operacje na metadanych za pomocą Metastore. |
| 8 | Fetch Result
Silnik wykonawczy otrzymuje wyniki z węzłów danych. |
| 9 | Send Results
Silnik wykonawczy wysyła te wynikowe wartości do sterownika. |
| 10 | Send Results
Sterownik wysyła wyniki do interfejsów Hive. |