Kibana - Agregacja i metryki
Dwa terminy, które często napotykasz podczas nauki języka Kibana, to Bucket i Metrics Aggregation. W tym rozdziale omówiono rolę, jaką odgrywają w Kibanie, oraz więcej szczegółów na ich temat.
Co to jest Kibana Aggregation?
Agregacja odnosi się do zbioru dokumentów lub zestawu dokumentów uzyskanych z określonego zapytania wyszukiwania lub filtru. Agregacja stanowi główną koncepcję budowania pożądanej wizualizacji w Kibanie.
Za każdym razem, gdy wykonujesz jakąkolwiek wizualizację, musisz zdecydować o kryteriach, czyli w jaki sposób chcesz pogrupować dane, aby wykonać na nich metrykę.
W tej sekcji omówimy dwa typy agregacji -
- Agregacja segmentów
- Agregacja danych
Agregacja segmentów
Wiadro składa się głównie z klucza i dokumentu. Po wykonaniu agregacji dokumenty są umieszczane w odpowiednim segmencie. Na koniec powinieneś mieć listę segmentów, z których każdy zawiera listę dokumentów. Lista agregacji segmentów, którą zobaczysz podczas tworzenia wizualizacji w Kibanie, jest pokazana poniżej -
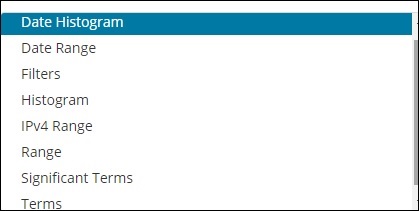
Agregacja zasobników ma następującą listę -
- Data Histogram
- Zakres dat
- Filters
- Histogram
- Zakres IPv4
- Range
- Znaczące warunki
- Terms
Podczas tworzenia musisz wybrać jeden z nich do agregacji segmentów, tj. Zgrupować dokumenty wewnątrz segmentów.
Jako przykład do analizy weźmy pod uwagę dane krajów, które przesłaliśmy na początku tego samouczka. Pola dostępne w indeksie krajów to nazwa kraju, obszar, ludność, region. W danych o krajach mamy nazwę kraju wraz z jego ludnością, regionem i obszarem.
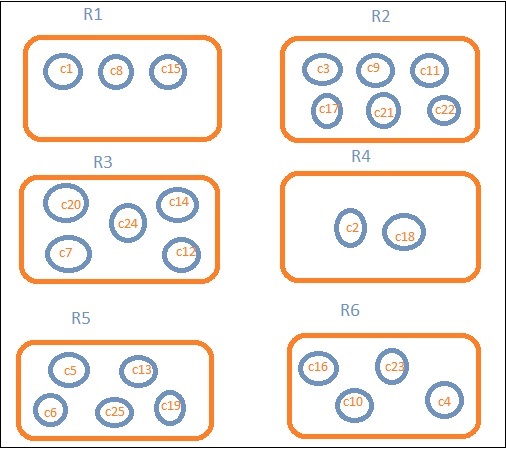
Załóżmy, że chcemy danych regionalnych. Następnie kraje dostępne w każdym regionie stają się naszym zapytaniem wyszukiwania, więc w tym przypadku region utworzy nasze koszyki. Poniższy schemat blokowy pokazuje, że R1, R2, R3, R4, R5 i R6 to pojemniki, które otrzymaliśmy, a c1, c2 ..c25 to lista dokumentów, które są częścią segmentów R1 do R6.
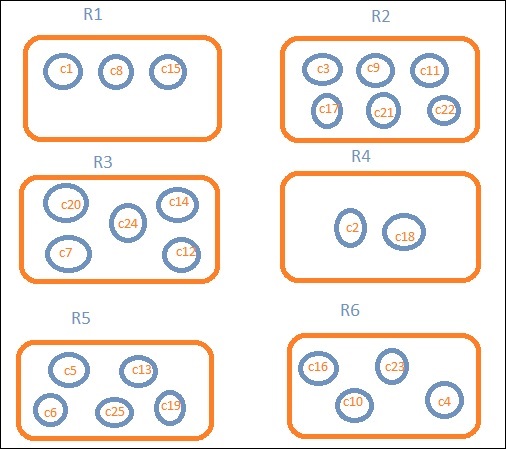
Widzimy, że w każdym z wiader są kółka. Są to zestawy dokumentów oparte na kryteriach wyszukiwania i uważane za mieszczące się w każdym z segmentów. W wiadrze R1 mamy dokumenty c1, c8 i c15. Te dokumenty to kraje, które należą do tego regionu, takie same dla innych. Jeśli więc policzymy kraje w Bucket R1, to będzie to 3, 6 dla R2, 6 dla R3, 2 dla R4, 5 dla R5 i 4 dla R6.
Zatem poprzez agregację zasobników możemy zagregować dokument w zasobnikach i mieć listę dokumentów w tych zasobnikach, jak pokazano powyżej.
Lista agregacji segmentów, którą mamy do tej pory, to -
- Data Histogram
- Zakres dat
- Filters
- Histogram
- Zakres IPv4
- Range
- Znaczące warunki
- Terms
Omówmy teraz szczegółowo, jak utworzyć te segmenty jeden po drugim.
Data Histogram
Data Agregacja histogramu jest używana w polu daty. Tak więc indeks, którego używasz do wizualizacji, jeśli masz pole daty w tym indeksie, można użyć tylko tego typu agregacji. Jest to agregacja z wieloma zasobnikami, co oznacza, że niektóre dokumenty mogą być częścią więcej niż 1 zasobnika. Istnieje przedział czasu, który ma być użyty do tej agregacji, a szczegóły są pokazane poniżej -
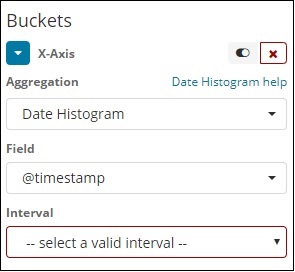
Po wybraniu agregacji segmentów jako histogramu daty wyświetli się opcja Pole, która będzie zawierała tylko pola związane z datą. Po wybraniu pola należy wybrać przedział, który zawiera następujące szczegóły -
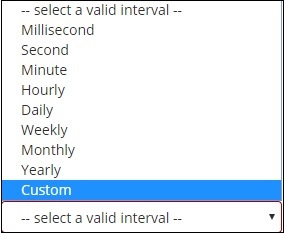
Zatem dokumenty z wybranego indeksu i na podstawie wybranego pola i przedziału będą klasyfikować dokumenty w segmentach. Na przykład, jeśli wybierzesz interwał miesięczny, dokumenty na podstawie daty zostaną przekonwertowane na segmenty i na podstawie miesiąca, tj. Styczeń-grudzień, dokumenty zostaną umieszczone w segmentach. Tutaj Jan, Luty ... Grudzień będzie wiadrami.
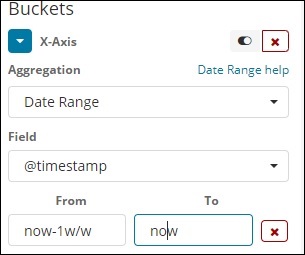
Zakres dat
Aby użyć tego typu agregacji, potrzebujesz pola daty. Tutaj będziemy mieli zakres dat, czyli od daty do daty do daty. Wiadra będą miały swoje dokumenty na podstawie podanej formy i daty.
Filtry
W przypadku agregacji typu Filtry kosze zostaną utworzone na podstawie filtra. Tutaj otrzymasz multi-zasobnik utworzony na podstawie kryteriów filtrowania, w którym jeden dokument może istnieć w jednym lub kilku zasobnikach.
Korzystając z filtrów, użytkownicy mogą zapisywać swoje zapytania w opcji filtru, jak pokazano poniżej -
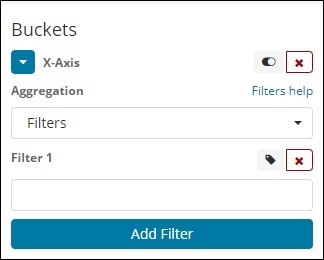
Możesz dodać wiele wybranych filtrów za pomocą przycisku Dodaj filtr.
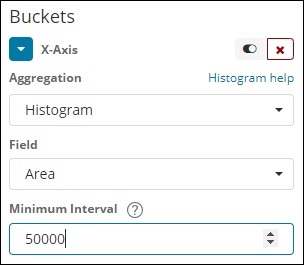
Histogram
Ten typ agregacji jest stosowany w polu liczbowym i grupuje dokumenty w segmencie na podstawie zastosowanego interwału. Na przykład 0-50,50-100,100-150 itd.
Zakres IPv4
Ten typ agregacji jest używany i używany głównie w przypadku adresów IP.
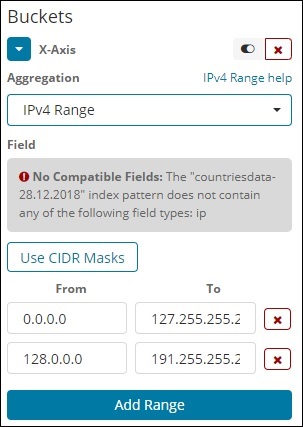
Indeks, który mamy, czyli contriesdata-28.12.2018 nie ma pola typu IP, więc wyświetla komunikat, jak pokazano powyżej. Jeśli masz pole IP, możesz określić w nim wartości From i To, jak pokazano powyżej.
Zasięg
Ten typ agregacji wymaga, aby pola były typu numer. Musisz określić zakres, a dokumenty zostaną wymienione w segmentach mieszczących się w zakresie.
W razie potrzeby możesz dodać większy zakres, klikając przycisk Dodaj zakres.
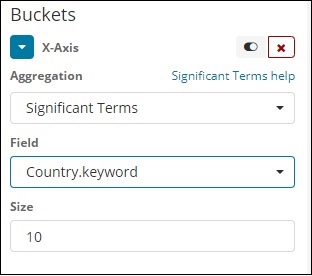
Znaczące warunki
Ten typ agregacji jest najczęściej używany w polach ciągów.
Warunki
Ten typ agregacji jest używany we wszystkich dostępnych polach, a mianowicie numer, ciąg znaków, data, wartość logiczna, adres IP, znacznik czasu itp. Zauważ, że jest to agregacja, której będziemy używać w całej naszej wizualizacji, nad którą będziemy pracować instruktaż.
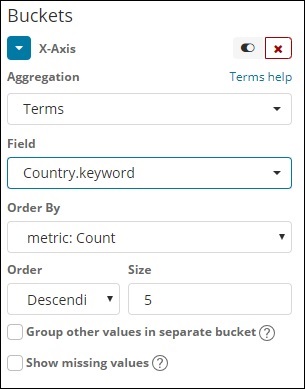
Mamy kolejność opcji, według której pogrupujemy dane na podstawie wybranej przez nas metryki. Rozmiar odnosi się do liczby segmentów, które chcesz wyświetlić w wizualizacji.
Następnie porozmawiajmy o agregacji danych.
Agregacja danych
Agregacja metryczna odnosi się głównie do obliczeń matematycznych wykonanych na dokumentach znajdujących się w zasobniku. Na przykład, jeśli wybierzesz pole liczbowe, obliczenia metryki, które możesz na nim wykonać, to COUNT, SUMA, MIN, MAX, AVERAGE itd.
Lista agregacji metryk, które omówimy, jest podana tutaj -
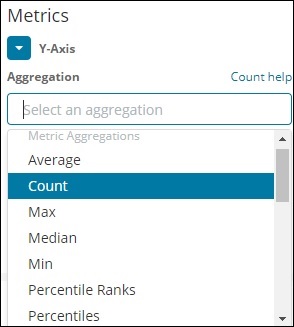
W tej sekcji omówmy te ważne, z których będziemy często korzystać -
- Average
- Count
- Max
- Min
- Sum
Metryka zostanie zastosowana do indywidualnej agregacji zasobników, którą omówiliśmy już powyżej.
Następnie omówmy tutaj listę agregacji wskaźników -
Średni
To da średnią wartości dokumentów obecnych w koszykach. Na przykład -
R1 do R6 to łyżki. W R1 mamy c1, c8 i c15. Rozważmy, że wartość c1 to 300, c8 to 500, a c15 to 700. Teraz, aby uzyskać średnią wartość segmentu R1
R1 = wartość c1 + wartość c8 + wartość c15 / 3 = 300 + 500 + 700/3 = 500.
Średnia dla łyżki R1 wynosi 500. Tutaj wartość dokumentu może być podobna, jeśli wziąć pod uwagę dane dotyczące krajów, może to być obszar kraju w tym regionie.
Liczyć
To da liczbę dokumentów obecnych w Bucket. Załóżmy, że chcesz policzyć kraje obecne w regionie, będzie to całkowita liczba dokumentów obecnych w zasobnikach. Na przykład R1 będzie wynosić 3, R2 = 6, R3 = 5, R4 = 2, R5 = 5 i R6 = 4.
Maks
To da maksymalną wartość dokumentu obecnego w zasobniku. Biorąc pod uwagę powyższy przykład, jeśli w segmencie regionu mamy dane dotyczące krajów według obszaru. Maksymalna wartość dla każdego regionu to kraj o maksymalnej powierzchni. Będzie więc mieć jeden kraj z każdego regionu, tj. Od R1 do R6.
w
To da minimalną wartość dokumentu obecnego w wiadrze. Biorąc pod uwagę powyższy przykład, jeśli mamy dane dotyczące krajów według obszaru w segmencie regionu. Minimalnym dla każdego regionu będzie kraj o minimalnej powierzchni. Będzie więc mieć jeden kraj z każdego regionu, tj. Od R1 do R6.
Suma
To da sumę wartości dokumentu obecnego w koszyku. Na przykład, jeśli weźmiesz pod uwagę powyższy przykład, jeśli chcemy uzyskać całkowitą powierzchnię lub kraje w regionie, będzie to suma dokumentów obecnych w regionie.
Na przykład, aby poznać wszystkie kraje w regionie R1 będzie to 3, R2 = 6, R3 = 5, R4 = 2, R5 = 5 i R6 = 4.
W przypadku, gdy mamy dokumenty z obszarem w regionie, od R1 do R6 zostanie zsumowany obszar kraju dla regionu.