KNIME - budowanie własnego modelu
W tym rozdziale zbudujesz własny model uczenia maszynowego, aby sklasyfikować rośliny na podstawie kilku obserwowanych funkcji. Skorzystamy z dobrze znanegoiris zbiór danych z UCI Machine Learning Repositoryw tym celu. Zbiór danych zawiera trzy różne klasy roślin. Będziemy trenować nasz model, aby zaklasyfikować nieznaną roślinę do jednej z tych trzech klas.
Zaczniemy od stworzenia nowego przepływu pracy w KNIME do tworzenia naszych modeli uczenia maszynowego.
Tworzenie przepływu pracy
Aby utworzyć nowy przepływ pracy, wybierz następującą opcję menu w środowisku roboczym KNIME.
File → NewZobaczysz następujący ekran -

Wybierz New KNIME Workflow opcję i kliknij Nextprzycisk. Na następnym ekranie zostaniesz poproszony o wybraną nazwę przepływu pracy i folder docelowy do jego zapisania. Wprowadź żądane informacje i kliknijFinish aby utworzyć nowy obszar roboczy.
Nowy obszar roboczy o podanej nazwie zostałby dodany do pliku Workspace zobacz jak tutaj -
Teraz dodasz różne węzły w tym obszarze roboczym, aby utworzyć model. Przed dodaniem węzłów musisz pobrać i przygotować plikiris zbiór danych do naszego użytku.
Przygotowywanie zbioru danych
Pobierz zestaw danych tęczówki z witryny repozytorium UCI Machine Learning. Pobierz zestaw danych Iris . Pobrany plik iris.data jest w formacie CSV. Wprowadzimy w nim pewne zmiany, aby dodać nazwy kolumn.
Otwórz pobrany plik w swoim ulubionym edytorze tekstu i dodaj na początku następujący wiersz.
sepal length, petal length, sepal width, petal width, classKiedy nasz File Reader node czyta ten plik, automatycznie przyjmie powyższe pola jako nazwy kolumn.
Teraz zaczniesz dodawać różne węzły.
Dodawanie czytnika plików
Przejdź do Node Repository widoku, wpisz „plik” w polu wyszukiwania, aby zlokalizować plik File Readerwęzeł. Widać to na poniższym zrzucie ekranu -

Wybierz i kliknij dwukrotnie plik File Readeraby dodać węzeł do obszaru roboczego. Alternatywnie możesz użyć funkcji przeciągnij i upuść, aby dodać węzeł do obszaru roboczego. Po dodaniu węzła będziesz musiał go skonfigurować. Kliknij prawym przyciskiem myszy węzeł i wybierz plikConfigureopcja menu. Zrobiłeś to na poprzedniej lekcji.
Po załadowaniu pliku danych ekran ustawień wygląda następująco.

Aby załadować zestaw danych, kliknij plik Browsei wybierz lokalizację pliku iris.data. Węzeł załaduje zawartość pliku, która jest wyświetlana w dolnej części okna konfiguracyjnego. Po upewnieniu się, że plik danych jest prawidłowo zlokalizowany i załadowany, kliknij plikOK aby zamknąć okno konfiguracji.
Teraz dodasz adnotację do tego węzła. Kliknij prawym przyciskiem myszy węzeł i wybierzNew Workflow Annotationopcja menu. Na ekranie pojawi się pole adnotacji, jak pokazano na zrzucie ekranu:
Kliknij w polu i dodaj następującą adnotację -
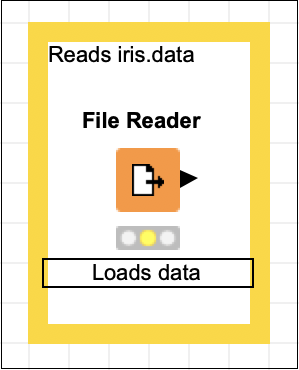
Reads iris.dataKliknij w dowolnym miejscu poza polem, aby wyjść z trybu edycji. Zmień rozmiar i umieść ramkę wokół węzła według potrzeb. Na koniec kliknij dwukrotnie plikNode 1 tekst pod węzłem, aby zmienić ten ciąg na następujący -
Loads dataW tym momencie ekran wyglądałby następująco -
Dodamy teraz nowy węzeł do partycjonowania załadowanego zestawu danych na szkolenia i testy.
Dodawanie węzła partycjonowania
w Node Repository okno wyszukiwania, wpisz kilka znaków, aby zlokalizować plik Partitioning węzeł, jak widać na poniższym zrzucie ekranu -
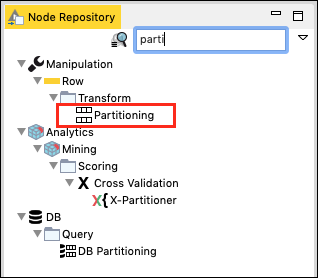
Dodaj węzeł do naszego obszaru roboczego. Ustaw jego konfigurację w następujący sposób -
Relative (%) : 95
Draw RandomlyPoniższy zrzut ekranu przedstawia parametry konfiguracyjne.

Następnie wykonaj połączenie między dwoma węzłami. Aby to zrobić, kliknij dane wyjściowe plikuFile Reader Węzeł, przytrzymaj przycisk myszy, pojawi się gumka, przeciągnij ją do wejścia Partitioningwęzeł, zwolnij przycisk myszy. Połączenie między dwoma węzłami jest teraz ustanawiane.
Dodaj adnotację, zmień opis, umieść węzeł i widok adnotacji według potrzeb. Na tym etapie ekran powinien wyglądać następująco -

Następnie dodamy k-Means węzeł.
Dodawanie węzła k-Means
Wybierz k-Meanswęzeł z repozytorium i dodaj go do obszaru roboczego. Jeśli chcesz odświeżyć swoją wiedzę na temat algorytmu k-Means, po prostu sprawdź jego opis w widoku opisu w środowisku roboczym. Jest to pokazane na poniższym zrzucie ekranu -

Nawiasem mówiąc, możesz przejrzeć opis różnych algorytmów w oknie opisu, zanim podejmiesz ostateczną decyzję, którego użyć.
Otwórz okno dialogowe konfiguracji węzła. Użyjemy wartości domyślnych dla wszystkich pól, jak pokazano tutaj -

Kliknij OK aby zaakceptować ustawienia domyślne i zamknąć okno dialogowe.
Ustaw następującą adnotację i opis -
Adnotacja: klasyfikuj klastry
Opis: wykonaj grupowanie
Podłącz górne wyjście Partitioning węzeł do wejścia k-Meanswęzeł. Zmień położenie przedmiotów, a ekran powinien wyglądać następująco -

Następnie dodamy plik Cluster Assigner węzeł.
Dodawanie przypisania klastra
Plik Cluster Assignerprzypisuje nowe dane do istniejącego zestawu prototypów. Wymaga dwóch danych wejściowych - modelu prototypowego i bazy danych zawierającej dane wejściowe. Sprawdź opis węzła w oknie opisu pokazanym na zrzucie ekranu poniżej -

Dlatego dla tego węzła musisz wykonać dwa połączenia -
Wynik modelu klastra PMML w programie Partitioning węzeł → Prototypy Wejście Cluster Assigner
Wyjście drugiej partycji Partitioning węzeł → Dane wejściowe Cluster Assigner
Te dwa połączenia pokazano na poniższym zrzucie ekranu -

Plik Cluster Assignernie wymaga specjalnej konfiguracji. Po prostu zaakceptuj wartości domyślne.
Teraz dodaj adnotację i opis do tego węzła. Zmień rozmieszczenie węzłów. Twój ekran powinien wyglądać następująco -

W tym momencie nasze grupowanie jest zakończone. Musimy wizualizować dane wyjściowe graficznie. W tym celu dodamy wykres punktowy. Na wykresie punktowym inaczej ustawimy kolory i kształty dla trzech klas. W ten sposób będziemy filtrować dane wyjściowek-Means węzeł najpierw przez Color Manager węzeł, a następnie przez Shape Manager węzeł.
Dodawanie menedżera kolorów
Znajdź plik Color Managerwęzeł w repozytorium. Dodaj go do obszaru roboczego. Pozostaw konfigurację do ustawień domyślnych. Zauważ, że musisz otworzyć okno konfiguracji i nacisnąćOKaby zaakceptować wartości domyślne. Ustaw tekst opisu dla węzła.
Nawiąż połączenie z wyjścia k-Means do wejścia Color Manager. Na tym etapie Twój ekran wyglądałby następująco -

Dodawanie menedżera kształtów
Znajdź plik Shape Managerw repozytorium i dodaj go do obszaru roboczego. Pozostaw konfigurację domyślną. Podobnie jak w poprzednim, musisz otworzyć okno konfiguracji i nacisnąćOKustawić wartości domyślne. Nawiąż połączenie z danych wyjściowych programuColor Manager do wejścia Shape Manager. Ustaw opis węzła.
Twój ekran powinien wyglądać następująco -
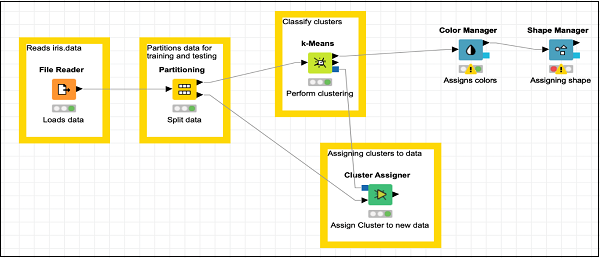
Teraz dodasz ostatni węzeł w naszym modelu, a jest to wykres punktowy.
Dodawanie wykresu punktowego
Znajdź Scatter Plotwęzeł w repozytorium i dodaj go do obszaru roboczego. Podłącz wyjścieShape Manager do wejścia Scatter Plot. Pozostaw konfigurację domyślną. Ustaw opis.
Na koniec dodaj adnotację grupy do ostatnio dodanych trzech węzłów
Adnotacja: wizualizacja
Zmień położenie węzłów według potrzeb. Na tym etapie Twój ekran powinien wyglądać następująco.
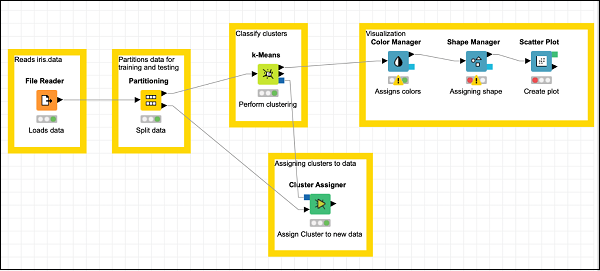
To kończy zadanie budowania modelu.