MuleSoft - procesor wiadomości i składniki skryptów
Moduły skryptowe ułatwiają użytkownikom korzystanie z języka skryptowego w Mule. Krótko mówiąc, moduł skryptowy może wymieniać niestandardową logikę napisaną w języku skryptowym. Skrypty mogą służyć jako implementacje lub transformatory. Mogą być używane do oceny wyrażeń, tj. Do sterowania routingiem komunikatów.
Mule ma następujące obsługiwane języki skryptowe -
- Groovy
- Python
- JavaScript
- Ruby
Jak zainstalować moduły skryptów?
Właściwie Anypoint Studio zawiera moduły skryptowe. Jeśli nie znajdziesz modułu w Mule Palette, możesz go dodać za pomocą+Add Module. Po dodaniu możemy skorzystać z operacji modułu skryptowego w naszej aplikacji Mule.
Przykład implementacji
Jak już wspomniano, musimy przeciągnąć i upuścić moduł na kanwę w celu stworzenia obszaru roboczego i użyć go w naszej aplikacji. Oto przykład -
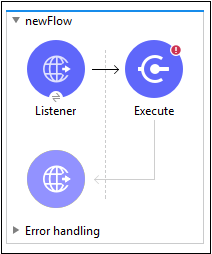
Wiemy już, jak skonfigurować komponent HTTP Listener; dlatego zamierzamy omówić konfigurację modułów skryptów. Musimy postępować zgodnie z poniższymi krokami, aby skonfigurować moduł skryptów -
Step 1
Wyszukaj moduł skryptów z palety Mule i przeciągnij plik EXECUTE działanie modułu skryptów w przepływie, jak pokazano powyżej.
Step 2
Teraz otwórz kartę Wykonaj konfigurację, klikając dwukrotnie to samo.
Step 3
Pod General musimy podać kod w Code text window jak pokazano poniżej -
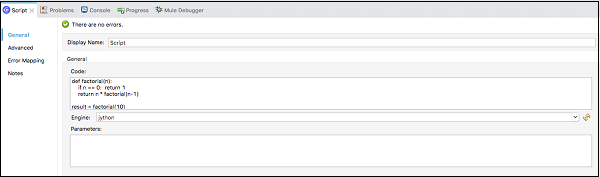
Step 4
W końcu musimy wybrać Enginez komponentu wykonania. Lista silników jest jak poniżej -
- Groovy
- Nashorn(javaScript)
- jython(Python)
- jRuby(Ruby)
XML powyższego przykładu wykonania w edytorze XML konfiguracji wygląda następująco -
<scripting:execute engine="jython" doc:name = "Script">
<scripting:code>
def factorial(n):
if n == 0: return 1
return n * factorial(n-1)
result = factorial(10)
</scripting:code>
</scripting:execute>Źródła wiadomości
Mule 4 ma uproszczony model niż komunikat Mule 3, co ułatwia pracę z danymi w spójny sposób w łącznikach bez nadpisywania informacji. W modelu wiadomości Mule 4 każde zdarzenie Mule składa się z dwóch rzeczy:a message and variables associated with it.
Wiadomość Mule ma ładunek i jego atrybuty, gdzie atrybutem są głównie metadane, takie jak rozmiar pliku.
Zmienna przechowuje dowolne informacje o użytkowniku, takie jak wynik operacji, wartości pomocnicze itp.
Przychodzące
Właściwości przychodzące w Mule 3 stają się teraz atrybutami w Mule 4. Ponieważ wiemy, że właściwości przychodzące przechowują dodatkowe informacje o ładunku uzyskanym za pośrednictwem źródła wiadomości, ale teraz w Mule 4 odbywa się to za pomocą atrybutów. Atrybuty mają następujące zalety -
Za pomocą atrybutów możemy łatwo sprawdzić, które dane są dostępne, ponieważ atrybuty są silnie wpisane.
Mamy łatwy dostęp do informacji zawartych w atrybutach.
Poniżej znajduje się przykład typowej wiadomości w Mule 4:
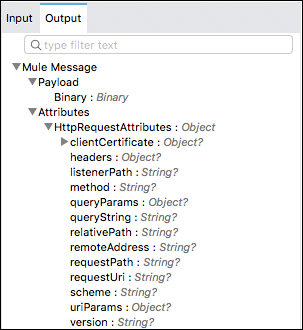
Wychodzący
Właściwości wychodzące w Mule 3 muszą być wyraźnie określone przez złącza i transporty Mule, aby można było wysyłać dodatkowe dane. Ale w Mule 4 każdy z nich można ustawić osobno, używając wyrażenia DataWeave dla każdego z nich. Nie powoduje żadnych skutków ubocznych w głównym przepływie.
Na przykład poniżej wyrażenie DataWeave wykona żądanie HTTP i wygeneruje nagłówki oraz parametry zapytania bez konieczności ustawiania właściwości wiadomości. Pokazuje to poniższy kod -
<http:request path = "M_issue" config-ref="http" method = "GET">
<http:headers>#[{'path':'input/issues-list.json'}]</http:headers>
<http:query-params>#[{'provider':'memory-provider'}]</http:query-params>
</http:request>Message Processor
Gdy Mule otrzyma wiadomość ze źródła wiadomości, rozpoczyna się praca procesora wiadomości. Mule używa co najmniej jednego procesora wiadomości do przetwarzania wiadomości przez przepływ. Głównym zadaniem procesora wiadomości jest transformacja, filtrowanie, wzbogacanie i przetwarzanie wiadomości, gdy przechodzi ona przez przepływ Mule.
Kategoryzacja procesora Mule
Poniżej znajdują się kategorie procesorów Mule, oparte na funkcjach -
Connectors- Te procesory wiadomości wysyłają i odbierają dane. Podłączają również dane do zewnętrznych źródeł danych za pośrednictwem standardowych protokołów lub zewnętrznych interfejsów API.
Components - Te procesory wiadomości są z natury elastyczne i wykonują logikę biznesową zaimplementowaną w różnych językach, takich jak Java, JavaScript, Groovy, Python lub Ruby.
Filters - Filtrują wiadomości i pozwalają na dalsze przetwarzanie tylko określonych wiadomości w przepływie w oparciu o określone kryteria.
Routers - Ten procesor komunikatów jest używany do sterowania przepływem komunikatów do trasowania, ponownego sekwencjonowania lub dzielenia.
Scopes - hej, po prostu zawijaj fragmenty kodu w celu zdefiniowania drobnoziarnistego zachowania w przepływie.
Transformers - Rolą transformatorów jest konwersja typu ładunku wiadomości i formatu danych w celu ułatwienia komunikacji między systemami.
Business Events - Zasadniczo przechwytują dane związane z kluczowymi wskaźnikami wydajności.
Exception strategies - Te procesory komunikatów obsługują wszelkiego rodzaju błędy, które występują podczas przetwarzania komunikatów.