OBIEE - Schemat
Schemat to logiczny opis całej bazy danych. Zawiera nazwę i opis rekordów wszystkich typów, w tym wszystkie powiązane pozycje danych i agregaty. Podobnie jak baza danych, DW również wymaga utrzymywania schematu. Baza danych korzysta z modelu relacyjnego, podczas gdy DW używa schematu Gwiazda, Płatek śniegu i Konstelacja faktów (schemat Galaxy).
Schemat gwiazdy
W schemacie gwiaździstym istnieje wiele tabel wymiarów w postaci zdenormalizowanej, które są połączone tylko z jedną tabelą faktów. Tabele te są połączone w logiczny sposób, aby spełnić pewne wymagania biznesowe do celów analizy. Te schematy są wielowymiarowymi strukturami, które są używane do tworzenia raportów przy użyciu narzędzi raportowania BI.
Wymiary w schematach gwiaździstych zawierają zestaw atrybutów, a tabele faktów zawierają klucze obce dla wszystkich wymiarów i wartości pomiarów.
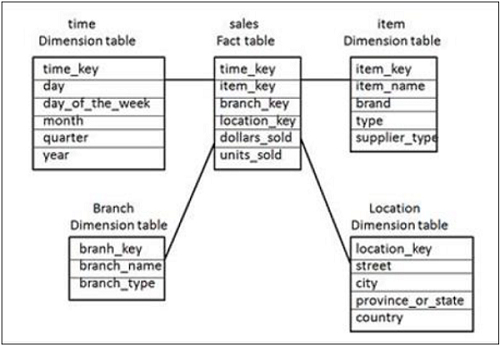
W powyższym schemacie gwiazdkowym na środku znajduje się tabela faktów „Fakt sprzedaży” połączona z 4 tabelami wymiarów za pomocą kluczy głównych. Tabele wymiarów nie są dalej normalizowane, a to łączenie tabel jest znane jako schemat gwiazdy w DW.
Tabela faktów zawiera również wartości miar - sprzedane_ dolara i sprzedane_jednostki.
Schemat płatków śniegu
W schemacie płatków śniegu istnieje wiele tabel wymiarów w znormalizowanej formie, które są połączone tylko z jedną tabelą faktów. Tabele te są połączone w logiczny sposób, aby spełnić pewne wymagania biznesowe do celów analizy.
Jedyną różnicą między schematem Gwiazda i Płatki śniegu jest dalsza normalizacja tabel wymiarów. Normalizacja dzieli dane na dodatkowe tabele. Dzięki normalizacji w schemacie Snowflake redundancja danych jest zmniejszona bez utraty jakichkolwiek informacji, a zatem staje się łatwa w utrzymaniu i oszczędza przestrzeń dyskową.

W powyższym przykładzie schematu płatków śniegu tabela produktów i klientów jest dalej znormalizowana w celu zaoszczędzenia miejsca w magazynie. Czasami zapewnia również optymalizację wydajności podczas wykonywania zapytania, które wymaga przetwarzania wierszy bezpośrednio w znormalizowanej tabeli, więc nie przetwarza wierszy w podstawowej tabeli wymiarów i przechodzi bezpośrednio do znormalizowanej tabeli w schemacie.
Ziarnistość
Ziarnistość w tabeli reprezentuje poziom informacji przechowywanych w tabeli. Wysoka szczegółowość danych oznacza, że dane są na poziomie transakcji lub w jego pobliżu, co jest bardziej szczegółowe. Niska szczegółowość oznacza, że dane mają niski poziom informacji.
Tabela faktów jest zwykle projektowana na niskim poziomie szczegółowości. Oznacza to, że musimy znaleźć najniższy poziom informacji, które można przechowywać w tabeli faktów. W wymiarze daty poziom szczegółowości może obejmować rok, miesiąc, kwartał, okres, tydzień i dzień.
Proces definiowania szczegółowości składa się z dwóch etapów -
- Określenie wymiarów, które mają zostać uwzględnione.
- Określenie lokalizacji w celu umieszczenia hierarchii każdego wymiaru informacji.
Powoli zmieniające się wymiary
Wolno zmieniające się wymiary odnoszą się do zmieniającej się wartości atrybutu w czasie. Jest to jedna z powszechnych koncepcji w DW.
Przykład
Andy jest pracownikiem XYZ Inc. Po raz pierwszy przebywał w Nowym Jorku w lipcu 2015 r. Oryginalny wpis w tabeli wyszukiwania pracowników ma następujący rekord -
| numer identyfikacyjny pracownika | 10001 |
|---|---|
| Nazwa | Andy |
| Lokalizacja | Nowy Jork |
Później przeniósł się do Los Angeles w Kalifornii. W jaki sposób firma XYZ Inc. powinna teraz zmodyfikować swoją tabelę pracowników, aby odzwierciedlić tę zmianę?
Jest to znane jako koncepcja „wolno zmieniającego się wymiaru”.
Istnieją trzy sposoby rozwiązania tego typu problemu -
Rozwiązanie 1
Nowy rekord zastępuje oryginalny rekord. Nie ma śladu starej płyty.
Powoli zmieniający się wymiar, nowe informacje po prostu zastępują oryginalne informacje. Innymi słowy, żadna historia nie jest przechowywana.
| numer identyfikacyjny pracownika | 10001 |
|---|---|
| Nazwa | Andy |
| Lokalizacja | LA, Kalifornia |
Benefit - Jest to najłatwiejszy sposób rozwiązania problemu wolno zmieniającego się wymiaru, ponieważ nie ma potrzeby śledzenia starych informacji.
Disadvantage - Wszystkie informacje historyczne zostaną utracone.
Use - Rozwiązanie 1 należy stosować, gdy DW nie jest zobowiązane do śledzenia informacji historycznych.
Rozwiązanie 2
Nowy rekord jest wprowadzany do tabeli wymiarów pracownika. Tak więc pracownik, Andy, jest traktowany jak dwie osoby.
Do tabeli zostanie dodany nowy rekord, który będzie reprezentował nowe informacje. Obecny będzie zarówno rekord oryginalny, jak i nowy. Nowy rekord otrzymuje własny klucz podstawowy w następujący sposób -
| numer identyfikacyjny pracownika | 10001 | 10002 |
|---|---|---|
| Nazwa | Andy | Andy |
| Lokalizacja | Nowy Jork | LA, Kalifornia |
Benefit - Ta metoda pozwala nam przechowywać wszystkie informacje historyczne.
Disadvantage- Rozmiar stołu rośnie szybciej. Gdy liczba wierszy tabeli jest bardzo duża, problemem może być miejsce i wydajność tabeli.
Use - Rozwiązanie 2 należy stosować, gdy konieczne jest przechowywanie przez DW danych historycznych.
Rozwiązanie 3
Oryginalny rekord w wymiarze Pracownik jest modyfikowany, aby odzwierciedlić zmianę.
Będą dwie kolumny wskazujące konkretny atrybut, jedna wskazuje oryginalną wartość, a druga wskazuje nową wartość. Pojawi się również kolumna wskazująca, kiedy bieżąca wartość stanie się aktywna.
| numer identyfikacyjny pracownika | Nazwa | Oryginalna lokalizacja | Nowa lokalizacja | Data przeniesiona |
|---|---|---|---|---|
| 10001 | Andy | Nowy Jork | LA, Kalifornia | Lipiec 2015 |
Benefits- Nie zwiększa to rozmiaru tabeli, ponieważ aktualizowane są nowe informacje. To pozwala nam zachować informacje historyczne.
Disadvantage - Ta metoda nie zachowuje całej historii, gdy wartość atrybutu jest zmieniana więcej niż raz.
Use - Rozwiązanie 3 powinno być używane tylko wtedy, gdy jest to wymagane od DW do przechowywania informacji o zmianach historycznych.
Normalizacja
Normalizacja to proces dekompozycji tabeli na mniej nadmiarowe mniejsze tabele bez utraty jakichkolwiek informacji. Zatem normalizacja bazy danych to proces organizowania atrybutów i tabel bazy danych w celu zminimalizowania nadmiarowości danych (duplikatów danych).
Cel normalizacji
Służy do eliminacji niektórych typów danych (redundancja / replikacja) w celu poprawy spójności.
Zapewnia maksymalną elastyczność, aby sprostać przyszłym potrzebom informacyjnym, utrzymując tabele odpowiadające typom obiektów w ich uproszczonej formie.
Tworzy jaśniejszy i czytelny model danych.
Zalety
- Integralność danych.
- Zwiększa spójność danych.
- Zmniejsza nadmiarowość danych i wymaganą przestrzeń.
- Zmniejsza koszt aktualizacji.
- Maksymalna elastyczność w odpowiadaniu na zapytania ad hoc.
- Zmniejsza całkowitą liczbę wierszy na blok.
Niedogodności
Niska wydajność zapytań w bazie danych, ponieważ połączenia muszą być wykonywane w celu pobrania odpowiednich danych z kilku znormalizowanych tabel.
Musisz zrozumieć model danych, aby wykonać prawidłowe połączenia między kilkoma tabelami.
Przykład

W powyższym przykładzie tabela wewnątrz zielonego bloku reprezentuje znormalizowaną tabelę znajdującą się wewnątrz czerwonego bloku. Tabela w zielonym bloku jest mniej zbędna, a także ma mniejszą liczbę wierszy bez utraty jakichkolwiek informacji.