OOAD - Szybki przewodnik
Krótka historia
Paradygmat obiektowy wziął swój kształt z początkowej koncepcji nowego podejścia do programowania, podczas gdy zainteresowanie metodami projektowania i analizy pojawiło się znacznie później.
Pierwszym językiem zorientowanym obiektowo była Simula (symulacja rzeczywistych systemów), opracowana w 1960 r. Przez naukowców z Norweskiego Centrum Informatycznego.
W 1970 roku Alan Kay i jego grupa badawcza w Xerox PARK stworzyli komputer osobisty o nazwie Dynabook oraz pierwszy całkowicie zorientowany obiektowo język programowania (OOPL) - Smalltalk, do programowania Dynabooka.
W latach 80-tych Grady Booch opublikował artykuł zatytułowany Object Oriented Design, w którym przedstawiono głównie projekt języka programowania Ada. W kolejnych edycjach rozszerzył swoje pomysły na kompletną metodę projektowania obiektowego.
W latach dziewięćdziesiątych Coad włączył koncepcje behawioralne do metod zorientowanych obiektowo.
Inne znaczące innowacje to Object Modeling Techniques (OMT) Jamesa Rumbaugha i Object-Oriented Software Engineering (OOSE) Ivara Jacobsona.
Analiza zorientowana obiektowo
Analiza zorientowana obiektowo (OOA) to procedura identyfikowania wymagań inżynierskich oprogramowania i opracowywania specyfikacji oprogramowania pod względem modelu obiektowego systemu oprogramowania, który obejmuje oddziałujące ze sobą obiekty.
Główna różnica między analizą obiektową a innymi formami analizy polega na tym, że w podejściu zorientowanym obiektowo wymagania są zorganizowane wokół obiektów, które integrują zarówno dane, jak i funkcje. Są one modelowane na podstawie rzeczywistych obiektów, z którymi system oddziałuje. W tradycyjnych metodologiach analizy te dwa aspekty - funkcje i dane - są rozpatrywane oddzielnie.
Grady Booch zdefiniował OOA jako: „Analiza zorientowana obiektowo jest metodą analizy, która bada wymagania z perspektywy klas i obiektów znajdujących się w słowniku domeny problemowej” .
Podstawowe zadania w analizie obiektowej (OOA) to:
- Identyfikowanie obiektów
- Organizowanie obiektów poprzez tworzenie diagramu modelu obiektów
- Definiowanie elementów wewnętrznych obiektów lub atrybutów obiektów
- Definiowanie zachowania obiektów, czyli działań na obiektach
- Opisywanie interakcji obiektów
Typowymi modelami używanymi w OOA są przypadki użycia i modele obiektowe.
Projektowanie zorientowane obiektowo
Projektowanie zorientowane obiektowo (OOD) obejmuje implementację modelu koncepcyjnego powstałego podczas analizy obiektowej. W OOD koncepcje w modelu analizy, które są niezależne od technologii, są mapowane na klasy implementujące, identyfikowane są ograniczenia i projektowane interfejsy, w wyniku czego powstaje model dla dziedziny rozwiązania, tj. Szczegółowy opis sposobu, w jaki system ma być zbudowany w oparciu o konkretne technologie.
Szczegóły implementacji zazwyczaj obejmują -
- Restrukturyzacja danych klasowych (jeśli to konieczne),
- Implementacja metod, czyli wewnętrznych struktur danych i algorytmów,
- Wdrażanie kontroli i
- Wdrażanie stowarzyszeń.
Grady Booch zdefiniował projektowanie zorientowane obiektowo jako „metodę projektowania obejmującą proces dekompozycji obiektowej oraz notację opisującą modele logiczne i fizyczne oraz statyczne i dynamiczne projektowanego systemu” .
Programowanie obiektowe
Programowanie obiektowe (OOP) to paradygmat programowania oparty na obiektach (posiadających zarówno dane, jak i metody), który ma na celu uwzględnienie zalet modułowości i możliwości ponownego wykorzystania. Obiekty, które zwykle są instancjami klas, są używane do interakcji między sobą w celu projektowania aplikacji i programów komputerowych.
Ważnymi cechami programowania obiektowego są -
- Podejście oddolne w projektowaniu programów
- Programy zorganizowane wokół obiektów, pogrupowane w klasy
- Skoncentruj się na danych z metodami do operowania na danych obiektu
- Interakcja między obiektami poprzez funkcje
- Możliwość ponownego wykorzystania projektu poprzez tworzenie nowych klas poprzez dodawanie funkcji do istniejących klas
Niektóre przykłady języków programowania obiektowego to C ++, Java, Smalltalk, Delphi, C #, Perl, Python, Ruby i PHP.
Grady Booch zdefiniował programowanie obiektowe jako „metodę implementacji, w której programy są zorganizowane jako wspólne zbiory obiektów, z których każdy reprezentuje instancję jakiejś klasy i których wszystkie klasy są członkami hierarchii klas połączonych przez relacje dziedziczenia ” .
Model obiektowy wizualizuje elementy w aplikacji w postaci obiektów. W tym rozdziale przyjrzymy się podstawowym koncepcjom i terminologiom systemów obiektowych.
Obiekty i klasy
Pojęcia obiektów i klas są ze sobą nierozerwalnie związane i stanowią podstawę paradygmatu zorientowanego obiektowo.
Obiekt
Obiekt to element świata rzeczywistego w środowisku obiektowym, który może istnieć fizycznie lub koncepcyjnie. Każdy obiekt ma -
Tożsamość, która odróżnia go od innych obiektów w systemie.
Stan, który określa charakterystyczne właściwości obiektu, a także wartości właściwości, które posiada obiekt.
Zachowanie, które reprezentuje widoczne z zewnątrz czynności wykonywane przez obiekt pod względem zmian jego stanu.
Obiekty można modelować zgodnie z potrzebami aplikacji. Obiekt może istnieć fizycznie, jak klient, samochód itp .; lub niematerialne istnienie pojęciowe, takie jak projekt, proces itp.
Klasa
Klasa reprezentuje zbiór obiektów o tych samych charakterystycznych właściwościach, które wykazują typowe zachowanie. Daje plan lub opis obiektów, które można z niego stworzyć. Tworzenie obiektu jako członka klasy nazywa się tworzeniem instancji. Zatem obiekt jest instancją klasy.
Składnikami klasy są -
Zestaw atrybutów obiektów, które mają zostać utworzone z klasy. Ogólnie rzecz biorąc, różne obiekty klasy mają pewne różnice w wartościach atrybutów. Atrybuty są często określane jako dane klas.
Zestaw operacji, które przedstawiają zachowanie obiektów klasy. Operacje są również określane jako funkcje lub metody.
Example
Rozważmy prostą klasę Circle, która reprezentuje geometryczny okrąg figury w dwuwymiarowej przestrzeni. Atrybuty tej klasy można zidentyfikować w następujący sposób -
- x – współrzędna, aby oznaczyć x – współrzędną środka
- y – współrzędna, aby oznaczyć y – współrzędną środka
- a, aby oznaczyć promień okręgu
Niektóre z jego operacji można zdefiniować następująco:
- findArea (), metoda obliczania powierzchni
- findCircumference (), metoda obliczania obwodu
- scale (), metoda zwiększania lub zmniejszania promienia
Podczas tworzenia instancji przypisywane są wartości przynajmniej niektórym atrybutom. Jeśli utworzymy obiekt my_circle, możemy przypisać wartości takie jak x-Coor: 2, Y-Co: 3 i a: 4, aby przedstawić jego stan. Teraz, jeśli operacja scale () jest wykonywana na my_circle ze współczynnikiem skalowania równym 2, wartość zmiennej a wyniesie 8. Ta operacja powoduje zmianę stanu my_circle, tj. Obiekt wykazuje określone zachowanie.
Hermetyzacja i ukrywanie danych
Kapsułkowanie
Hermetyzacja to proces wiązania razem atrybutów i metod w klasie. Dzięki hermetyzacji wewnętrzne szczegóły klasy można ukryć przed zewnętrzem. Pozwala na dostęp do elementów klasy z zewnątrz tylko za pośrednictwem interfejsu udostępnionego przez klasę.
Ukrywanie danych
Zazwyczaj klasa jest zaprojektowana w taki sposób, że jej dane (atrybuty) są dostępne tylko za pomocą metod klasy i są odizolowane od bezpośredniego dostępu z zewnątrz. Ten proces izolowania danych obiektu nazywa się ukrywaniem danych lub ukrywaniem informacji.
Example
W klasie Circle ukrywanie danych można włączyć, czyniąc atrybuty niewidocznymi spoza klasy i dodając do klasy dwie dodatkowe metody dostępu do danych klasy, a mianowicie -
- setValues (), metoda przypisywania wartości do współrzędnych x, współrzędnych yi a
- getValues (), metoda do pobierania wartości współrzędnych x, współrzędnych yi a
Tutaj do prywatnych danych obiektu my_circle nie można uzyskać bezpośredniego dostępu żadną metodą, która nie jest zamknięta w klasie Circle. Zamiast tego powinien być dostępny poprzez metody setValues () i getValues ().
Przekazywanie wiadomości
Każda aplikacja wymaga harmonijnej interakcji wielu obiektów. Obiekty w systemie mogą komunikować się ze sobą za pomocą przekazywania komunikatów. Załóżmy, że system ma dwa obiekty: obj1 i obj2. Obiekt obj1 wysyła komunikat do obiektu obj2, jeśli obiekt obj1 chce, aby obj2 wykonał jedną ze swoich metod.
Cechy przekazywania wiadomości to -
- Komunikat przesyłany między dwoma obiektami jest generalnie jednokierunkowy.
- Przekazywanie wiadomości umożliwia wszystkie interakcje między obiektami.
- Przekazywanie wiadomości zasadniczo obejmuje wywoływanie metod klas.
- Obiekty w różnych procesach mogą być zaangażowane w przekazywanie wiadomości.
Dziedzictwo
Dziedziczenie to mechanizm, który umożliwia tworzenie nowych klas z istniejących klas poprzez rozszerzanie i udoskonalanie jego możliwości. Istniejące klasy nazywane są klasami podstawowymi / klasami nadrzędnymi / superklasami, a nowe klasy nazywane są klasami pochodnymi / klasami potomnymi / podklasami. Podklasa może dziedziczyć lub wyprowadzać atrybuty i metody superklasy (-ów), o ile pozwala na to superklasa. Poza tym podklasa może dodawać własne atrybuty i metody oraz może modyfikować dowolne metody nadklasy. Dziedziczenie definiuje relację „jest - a”.
Example
Z klasy Mammal można wyprowadzić szereg klas, takich jak człowiek, kot, pies, krowa itp. Ludzie, koty, psy i krowy mają odrębne cechy charakterystyczne dla ssaków. Ponadto każdy ma swoje szczególne cechy. Można powiedzieć, że krowa „jest” ssakiem.
Rodzaje dziedziczenia
Single Inheritance - Podklasa pochodzi z jednej nadklasy.
Multiple Inheritance - Podklasa pochodzi z więcej niż jednej nadklasy.
Multilevel Inheritance - Podklasa wywodzi się z superklasy, która z kolei pochodzi od innej klasy i tak dalej.
Hierarchical Inheritance - Klasa ma pewną liczbę podklas, z których każda może mieć kolejne podklasy, kontynuowane na wielu poziomach, tworząc strukturę drzewiastą.
Hybrid Inheritance - Połączenie dziedziczenia wielopoziomowego i wielopoziomowego w celu utworzenia struktury kratowej.
Poniższy rysunek przedstawia przykłady różnych typów dziedziczenia.

Wielopostaciowość
Polimorfizm jest pierwotnie greckim słowem, które oznacza zdolność do przyjmowania wielu form. W paradygmacie zorientowanym obiektowo polimorfizm implikuje używanie operacji na różne sposoby, w zależności od instancji, na której one działają. Polimorfizm umożliwia obiektom o różnych strukturach wewnętrznych posiadanie wspólnego interfejsu zewnętrznego. Polimorfizm jest szczególnie skuteczny przy wdrażaniu dziedziczenia.
Example
Rozważmy dwie klasy, Circle i Square, z których każda ma metodę findArea (). Chociaż nazwa i przeznaczenie metod w klasach są takie same, wewnętrzna implementacja, tj. Procedura obliczania powierzchni, jest inna dla każdej klasy. Gdy obiekt klasy Circle wywołuje swoją metodę findArea (), operacja odnajduje obszar koła bez konfliktu z metodą findArea () klasy Square.
Uogólnienie i specjalizacja
Uogólnienie i specjalizacja reprezentują hierarchię relacji między klasami, w której podklasy dziedziczą po nadklasach.
Uogólnienie
W procesie uogólniania wspólne cechy klas są łączone, aby utworzyć klasę na wyższym poziomie hierarchii, tj. Podklasy są łączone w celu utworzenia uogólnionej nadklasy. Reprezentuje relację „jest - jest - rodzajem -”. Na przykład „samochód jest rodzajem pojazdu lądowego” lub „statek jest rodzajem pojazdu wodnego”.
Specjalizacja
Specjalizacja to odwrotny proces generalizacji. Tutaj cechy wyróżniające grupy obiektów są wykorzystywane do tworzenia wyspecjalizowanych klas z istniejących klas. Można powiedzieć, że podklasy są wyspecjalizowanymi wersjami superklasy.
Poniższy rysunek przedstawia przykład uogólnienia i specjalizacji.

Linki i stowarzyszenie
Połączyć
Łącze reprezentuje połączenie, za pośrednictwem którego obiekt współpracuje z innymi obiektami. Rumbaugh zdefiniował to jako „fizyczne lub konceptualne połączenie między obiektami”. Poprzez łącze jeden obiekt może wywoływać metody lub nawigować po innym obiekcie. Łącze przedstawia związek między dwoma lub więcej obiektami.
Stowarzyszenie
Skojarzenie to grupa połączeń o wspólnej strukturze i wspólnym zachowaniu. Skojarzenie przedstawia związek między obiektami jednej lub kilku klas. Łącze można zdefiniować jako instancję powiązania.
Stopień stowarzyszenia
Stopień asocjacji oznacza liczbę klas zaangażowanych w połączenie. Stopień może być jednoargumentowy, binarny lub trójskładnikowy.
ZA unary relationship łączy obiekty tej samej klasy.
ZA binary relationship łączy obiekty dwóch klas.
ZA ternary relationship łączy obiekty trzech lub więcej klas.
Współczynniki mocy asocjacji
Kardynalność asocjacji binarnej oznacza liczbę wystąpień uczestniczących w asocjacji. Istnieją trzy rodzaje współczynników liczności, a mianowicie -
One–to–One - Pojedynczy obiekt klasy A jest powiązany z pojedynczym obiektem klasy B.
One–to–Many - Pojedynczy obiekt klasy A jest powiązany z wieloma obiektami klasy B.
Many–to–Many - Obiekt klasy A może być powiązany z wieloma obiektami klasy B i odwrotnie, obiekt klasy B może być powiązany z wieloma obiektami klasy A.
Agregacja lub kompozycja
Agregacja lub kompozycja to relacja między klasami, dzięki której klasa może się składać z dowolnej kombinacji obiektów innych klas. Pozwala na umieszczanie obiektów bezpośrednio w treści innych klas. Agregacja jest określana jako relacja „część” lub „ma”, z możliwością przechodzenia od całości do jej części. Obiekt zagregowany to obiekt składający się z co najmniej jednego innego obiektu.
Example
W relacji „samochód ma - silnik”, samochód to cały przedmiot lub agregat, a silnik jest „częścią” samochodu. Agregacja może oznaczać -
Physical containment - Na przykład komputer składa się z monitora, procesora, myszy, klawiatury i tak dalej.
Conceptual containment - Przykład, akcjonariusz ma udział.
Korzyści z modelu obiektowego
Po zapoznaniu się z podstawowymi koncepcjami dotyczącymi orientacji obiektowej, warto byłoby zwrócić uwagę na zalety, jakie ten model ma do zaoferowania.
Korzyści wynikające ze stosowania modelu obiektowego:
Pomaga w szybszym tworzeniu oprogramowania.
Jest łatwy w utrzymaniu. Załóżmy, że w module wystąpił błąd, a następnie programista może naprawić ten konkretny moduł, podczas gdy inne części oprogramowania nadal działają.
Obsługuje stosunkowo bezproblemowe aktualizacje.
Umożliwia ponowne wykorzystanie obiektów, projektów i funkcji.
Zmniejsza ryzyko rozwoju, szczególnie w przypadku integracji złożonych systemów.
Wiemy, że technika Object-Oriented Modeling (OOM) wizualizuje rzeczy w aplikacji przy użyciu modeli zorganizowanych wokół obiektów. Każde podejście do tworzenia oprogramowania przechodzi przez następujące etapy -
- Analysis,
- Projekt i
- Implementation.
W inżynierii oprogramowania zorientowanej obiektowo twórca oprogramowania identyfikuje i organizuje aplikację pod względem pojęć zorientowanych obiektowo, przed ich ostatecznym przedstawieniem w jakimkolwiek określonym języku programowania lub narzędziach programowych.
Fazy w programowaniu zorientowanym obiektowo
Główne fazy tworzenia oprogramowania przy użyciu metodologii zorientowanej obiektowo to analiza zorientowana obiektowo, projektowanie zorientowane obiektowo i implementacja zorientowana obiektowo.
Analiza zorientowana obiektowo
Na tym etapie formułowany jest problem, identyfikowane są wymagania użytkownika, a następnie budowany jest model w oparciu o obiekty ze świata rzeczywistego. Analiza tworzy modele pokazujące, jak powinien funkcjonować pożądany system i jak należy go rozwijać. Modele nie zawierają żadnych szczegółów implementacji, aby mogły być zrozumiane i zbadane przez każdego nietechnicznego eksperta ds. Zastosowań.
Projektowanie zorientowane obiektowo
Projektowanie zorientowane obiektowo obejmuje dwa główne etapy, a mianowicie projektowanie systemu i projektowanie obiektów.
System Design
Na tym etapie projektowana jest pełna architektura żądanego systemu. System jest pomyślany jako zbiór współdziałających podsystemów, który z kolei składa się z hierarchii oddziałujących obiektów, pogrupowanych w klasy. Projekt systemu jest wykonywany zarówno zgodnie z modelem analizy systemu, jak i proponowaną architekturą systemu. Tutaj nacisk kładzie się na obiekty składające się na system, a nie na procesy w systemie.
Object Design
W tej fazie opracowywany jest model projektowy w oparciu zarówno o modele opracowane w fazie analizy systemu, jak i architekturę zaprojektowaną w fazie projektowania systemu. Wszystkie wymagane klasy są określone. Projektant decyduje, czy -
- nowe klasy mają powstać od podstaw,
- dowolne istniejące klasy mogą być używane w ich oryginalnej formie lub
- nowe klasy powinny być dziedziczone z istniejących klas.
Ustala się powiązania między zidentyfikowanymi klasami i identyfikuje hierarchie klas. Poza tym programista projektuje wewnętrzne szczegóły klas i ich powiązań, tj. Strukturę danych dla każdego atrybutu i algorytmy operacji.
Implementacja i testowanie zorientowane obiektowo
Na tym etapie model projektowy opracowany w projekcie obiektu jest tłumaczony na kod w odpowiednim języku programowania lub narzędziu programowym. Tworzone są bazy danych i ustalane są określone wymagania sprzętowe. Gdy kod jest już w formie, jest on testowany przy użyciu specjalistycznych technik w celu zidentyfikowania i usunięcia błędów w kodzie.
Zasady systemów obiektowych
Ramy koncepcyjne systemów zorientowanych obiektowo są oparte na modelu obiektowym. Istnieją dwie kategorie elementów w systemie zorientowanym obiektowo -
Major Elements- Zasadniczo oznacza to, że jeśli model nie zawiera żadnego z tych elementów, przestaje być obiektowy. Cztery główne elementy to -
- Abstraction
- Encapsulation
- Modularity
- Hierarchy
Minor Elements- Drobno rozumie się, że te elementy są użyteczną, ale nie niezbędną częścią modelu obiektu. Trzy drobne elementy to -
- Typing
- Concurrency
- Persistence
Abstrakcja
Abstrakcja oznacza skupienie się na podstawowych cechach elementu lub obiektu w OOP, ignorując jego obce lub przypadkowe właściwości. Podstawowe cechy są związane z kontekstem, w którym obiekt jest używany.
Grady Booch zdefiniował abstrakcję następująco:
„Abstrakcja określa podstawowe cechy obiektu, które odróżniają go od wszystkich innych rodzajów obiektów, a tym samym zapewniają jasno zdefiniowane granice pojęciowe w odniesieniu do perspektywy widza”.
Example - Kiedy projektowana jest klasa Student, atrybuty numer_rejestracji, nazwa, kurs i adres są uwzględniane, podczas gdy cechy takie jak częstość_impulsów i rozmiar_buty są eliminowane, ponieważ są one nieistotne z punktu widzenia instytucji edukacyjnej.
Kapsułkowanie
Hermetyzacja to proces wiązania razem atrybutów i metod w klasie. Dzięki hermetyzacji wewnętrzne szczegóły klasy można ukryć przed zewnętrzem. Klasa zawiera metody udostępniające interfejsy użytkownika, za pomocą których można używać usług udostępnianych przez klasę.
Modułowość
Modułowość to proces dekompozycji problemu (programu) na zestaw modułów w celu zmniejszenia ogólnej złożoności problemu. Booch zdefiniował modułowość jako -
„Modułowość to właściwość systemu, który został rozłożony na zestaw spójnych i luźno powiązanych modułów”.
Modułowość jest nierozerwalnie związana z hermetyzacją. Modułowość można wizualizować jako sposób odwzorowania zamkniętych abstrakcji na rzeczywiste, fizyczne moduły o dużej spójności w obrębie modułów, a ich interakcja lub sprzężenie międzymodułowe jest niskie.
Hierarchia
Jak mówi Grady Booch, „Hierarchia to uszeregowanie lub uporządkowanie abstrakcji”. Dzięki hierarchii system może składać się z powiązanych ze sobą podsystemów, które mogą mieć własne podsystemy i tak dalej, aż do osiągnięcia najmniejszych komponentów poziomu. Wykorzystuje zasadę „dziel i rządź”. Hierarchia umożliwia ponowne wykorzystanie kodu.
Dwa typy hierarchii w OOA to -
“IS–A” hierarchy- Definiuje hierarchiczną zależność w dziedziczeniu, dzięki której z nadklasy można wyprowadzić pewną liczbę podklas, które mogą ponownie mieć podklasy i tak dalej. Na przykład, jeśli wyprowadzimy klasę Rose z klasy Flower, możemy powiedzieć, że róża „jest” kwiatem.
“PART–OF” hierarchy- Definiuje hierarchiczną relację w agregacji, dzięki której klasa może składać się z innych klas. Na przykład kwiat składa się z działek, płatków, pręcików i owocolistka. Można powiedzieć, że płatek jest „częścią” kwiatu.
Pisanie na maszynie
Zgodnie z teoriami abstrakcyjnego typu danych, typ jest charakterystyką zbioru elementów. W OOP klasa jest wizualizowana jako typ o właściwościach odmiennych od innych typów. Wpisywanie jest egzekwowaniem pojęcia, że obiekt jest instancją pojedynczej klasy lub typu. Wymusza również, że obiekty różnych typów nie mogą być zasadniczo wymieniane; i mogą być wymieniane tylko w bardzo ograniczonym zakresie, jeśli jest to absolutnie konieczne.
Dwa rodzaje pisania to -
Strong Typing - Tutaj operacja na obiekcie jest sprawdzana w momencie kompilacji, tak jak w języku programowania Eiffel.
Weak Typing- Tutaj wiadomości mogą być wysyłane do dowolnej klasy. Operacja jest sprawdzana tylko w momencie wykonywania, tak jak w języku programowania Smalltalk.
Konkurencja
Współbieżność w systemach operacyjnych umożliwia jednoczesne wykonywanie wielu zadań lub procesów. Kiedy w systemie istnieje pojedynczy proces, mówi się, że istnieje jeden wątek kontroli. Jednak większość systemów ma wiele wątków, niektóre są aktywne, niektóre czekają na procesor, niektóre są zawieszone, a niektóre zakończone. Systemy z wieloma procesorami z natury umożliwiają współbieżne wątki kontroli; ale systemy działające na jednym procesorze używają odpowiednich algorytmów, aby zapewnić sprawiedliwy czas procesora wątkom, aby umożliwić współbieżność.
W środowisku zorientowanym obiektowo istnieją obiekty aktywne i nieaktywne. Obiekty aktywne mają niezależne wątki kontroli, które mogą być wykonywane równolegle z wątkami innych obiektów. Aktywne obiekty synchronizują się ze sobą, jak również z obiektami czysto sekwencyjnymi.
Trwałość
Obiekt zajmuje miejsce w pamięci i istnieje przez określony czas. W tradycyjnym programowaniu okresem życia obiektu był zwykle czas wykonania programu, który go utworzył. W plikach lub bazach danych żywotność obiektu jest dłuższa niż czas trwania procesu tworzenia obiektu. Ta właściwość, dzięki której obiekt nadal istnieje, nawet gdy jego twórca przestaje istnieć, nazywana jest trwałością.
W fazie analizy systemu lub analizy obiektowej tworzenia oprogramowania określane są wymagania systemowe, identyfikowane są klasy i identyfikowane są relacje między klasami.
Trzy techniki analizy, które są używane w połączeniu ze sobą w analizie zorientowanej obiektowo, to modelowanie obiektowe, modelowanie dynamiczne i modelowanie funkcjonalne.
Modelowanie obiektów
Modelowanie obiektowe rozwija statyczną strukturę systemu oprogramowania w kategoriach obiektów. Identyfikuje obiekty, klasy, do których można je grupować oraz relacje między obiektami. Określa również główne atrybuty i operacje, które charakteryzują każdą klasę.
Proces modelowania obiektów można zwizualizować w następujących krokach -
- Identyfikuj obiekty i grupuj w klasy
- Zidentyfikuj relacje między klasami
- Utwórz diagram modelu obiektów użytkownika
- Zdefiniuj atrybuty obiektu użytkownika
- Zdefiniuj operacje, które powinny zostać wykonane na klasach
- Przejrzyj glosariusz
Modelowanie dynamiczne
Po przeanalizowaniu statycznego zachowania systemu należy zbadać jego zachowanie względem czasu i zmian zewnętrznych. Taki jest cel modelowania dynamicznego.
Modelowanie dynamiczne można zdefiniować jako „sposób opisywania, w jaki sposób pojedynczy obiekt reaguje na zdarzenia, albo zdarzenia wewnętrzne wyzwalane przez inne obiekty, albo zdarzenia zewnętrzne wyzwalane przez świat zewnętrzny”.
Proces modelowania dynamicznego można wizualizować w następujących krokach -
- Zidentyfikuj stany każdego obiektu
- Identyfikuj zdarzenia i analizuj zastosowanie działań
- Skonstruuj diagram modelu dynamicznego, składający się z diagramów przejść stanów
- Wyraź każdy stan za pomocą atrybutów obiektu
- Sprawdź poprawność narysowanych diagramów stanów
Modelowanie funkcjonalne
Modelowanie funkcjonalne jest ostatnim elementem analizy zorientowanej obiektowo. Model funkcjonalny pokazuje procesy, które są wykonywane w obiekcie i jak zmieniają się dane podczas przemieszczania się między metodami. Określa znaczenie operacji modelowania obiektów i działań modelowania dynamicznego. Model funkcjonalny odpowiada schematowi przepływu danych tradycyjnej analizy strukturalnej.
Proces modelowania funkcjonalnego można zwizualizować w następujących krokach -
- Zidentyfikuj wszystkie wejścia i wyjścia
- Skonstruuj diagramy przepływu danych pokazujące zależności funkcjonalne
- Podaj cel każdej funkcji
- Zidentyfikuj ograniczenia
- Określ kryteria optymalizacji
Analiza strukturalna a analiza zorientowana obiektowo
Podejście Structured Analysis / Structured Design (SASD) jest tradycyjnym podejściem do tworzenia oprogramowania opartym na modelu kaskadowym. Fazy rozwoju systemu wykorzystującego SASD to -
- Studium wykonalności
- Analiza wymagań i specyfikacja
- Projekt systemu
- Implementation
- Przegląd powdrożeniowy
Teraz przyjrzymy się względnym zaletom i wadom podejścia do analizy strukturalnej i metody analizy zorientowanej obiektowo.
Zalety / wady analizy zorientowanej obiektowo
| Zalety | Niedogodności |
|---|---|
| Koncentruje się na danych, a nie na procedurach, jak w analizie strukturalnej. | Funkcjonalność jest ograniczona w obrębie obiektów. Może to stanowić problem dla systemów, które są z natury proceduralne lub obliczeniowe. |
| Zasady hermetyzacji i ukrywania danych pomagają programistom w opracowywaniu systemów, które nie mogą być modyfikowane przez inne części systemu. | Nie może zidentyfikować, które obiekty wygenerowałyby optymalny projekt systemu. |
| Zasady hermetyzacji i ukrywania danych pomagają programistom w opracowywaniu systemów, które nie mogą być modyfikowane przez inne części systemu. | Modele zorientowane obiektowo nie pokazują w łatwy sposób komunikacji między obiektami w systemie. |
| Dzięki modułowości umożliwia efektywne zarządzanie złożonością oprogramowania. | Wszystkie interfejsy między obiektami nie mogą być przedstawione na jednym diagramie. |
| Można go rozbudować z małych do dużych systemów z większą łatwością niż w systemach po analizie strukturalnej. |
Zalety / wady analizy strukturalnej
| Zalety | Niedogodności |
|---|---|
| Ponieważ opiera się na podejściu odgórnym, w przeciwieństwie do oddolnego podejścia do analizy obiektowej, może być łatwiejsze do zrozumienia niż OOA. | W tradycyjnych modelach analizy strukturalnej jedna faza powinna zostać zakończona przed następną. Stwarza to problem w projektowaniu, zwłaszcza jeśli pojawiają się błędy lub zmieniają się wymagania. |
| Opiera się na funkcjonalności. Określany jest ogólny cel, a następnie następuje rozkład funkcjonalny w celu opracowania oprogramowania. Nacisk nie tylko daje lepsze zrozumienie systemu, ale także generuje bardziej kompletne systemy. | Początkowy koszt budowy systemu jest wysoki, ponieważ cały system trzeba zaprojektować od razu, pozostawiając bardzo niewiele możliwości późniejszego dodania funkcjonalności. |
| Zawarte w nim specyfikacje są napisane prostym językiem angielskim, dzięki czemu mogą być łatwiej analizowane przez personel nietechniczny. | Nie obsługuje ponownego wykorzystania kodu. Zatem czas i koszt rozwoju są z natury wysokie. |
Model dynamiczny przedstawia zależne od czasu aspekty systemu. Dotyczy czasowych zmian stanów obiektów w systemie. Główne koncepcje to -
Stan, czyli sytuacja w określonym stanie przez cały okres istnienia obiektu.
Przejście, zmiana stanu
Zdarzenie, zdarzenie, które wyzwala przejścia
Akcja, nieprzerwane i atomowe obliczenie, które występuje z powodu jakiegoś zdarzenia i
Współbieżność przejść.
Maszyna stanów modeluje zachowanie obiektu, gdy przechodzi on przez szereg stanów w czasie swojego życia z powodu pewnych zdarzeń, a także działań zachodzących w wyniku zdarzeń. Maszyna stanów jest graficznie reprezentowana przez diagram przejść stanów.
Stany i przejścia między stanami
Stan
Stan jest abstrakcją określoną przez wartości atrybutów, które obiekt posiada w określonym przedziale czasu. Jest to sytuacja występująca przez określony czas w życiu obiektu, w której spełnia on określone warunki, wykonuje określone czynności lub czeka na wystąpienie określonych zdarzeń. Na diagramach przejść stanów stan jest reprezentowany przez zaokrąglone prostokąty.
Części stanu
Name- Ciąg odróżnia jeden stan od drugiego. Stan może nie mieć żadnej nazwy.
Entry/Exit Actions - Oznacza czynności wykonywane przy wejściu i wyjściu z danego państwa.
Internal Transitions - Zmiany w stanie, które nie powodują zmiany stanu.
Sub–states - Stany w stanach.
Stany początkowe i końcowe
Domyślny stan początkowy obiektu nazywany jest jego stanem początkowym. Stan końcowy wskazuje na zakończenie wykonywania automatu stanowego. Stany początkowy i końcowy są pseudostanami i mogą nie zawierać części zwykłego stanu z wyjątkiem nazwy. Na diagramach przejść stanów stan początkowy jest reprezentowany przez wypełnione czarne kółko. Stan końcowy jest reprezentowany przez wypełnione czarne kółko otoczone innym niewypełnionym czarnym kółkiem.
Przejście
Przejście oznacza zmianę stanu obiektu. Jeśli obiekt znajduje się w określonym stanie w momencie wystąpienia zdarzenia, może on wykonać określone czynności w określonych warunkach i zmienić stan. W tym przypadku mówi się, że nastąpiła zmiana stanu. Przejście daje związek między pierwszym stanem a nowym stanem. Przejście jest graficznie reprezentowane przez ciągły, ukierunkowany łuk ze stanu źródłowego do stanu docelowego.
Pięć części przejścia to -
Source State - stan dotknięty przejściem.
Event Trigger - zdarzenie, w wyniku którego obiekt w stanie źródłowym przechodzi przejście, jeśli warunek ochrony jest spełniony.
Guard Condition - Wyrażenie logiczne, które w przypadku wartości True powoduje przejście po otrzymaniu wyzwalacza zdarzenia.
Action - nieprzerywalne i atomowe obliczenia, które występują na obiekcie źródłowym z powodu jakiegoś zdarzenia.
Target State - Stan docelowy po zakończeniu przejścia.
Example
Załóżmy, że osoba jedzie taksówką z miejsca X na miejsce Y. Stany osoby mogą być następujące: Oczekiwanie (czekanie na taksówkę), Jazda (ma taksówkę i jedzie w niej) i Osiągnął (dotarł do Miejsce docelowe). Poniższy rysunek przedstawia zmianę stanu.
Wydarzenia
Zdarzenia to niektóre zdarzenia, które mogą wyzwolić zmianę stanu obiektu lub grupy obiektów. Zdarzenia mają miejsce w czasie i przestrzeni, ale nie mają skojarzonego z nimi okresu czasu. Wydarzenia są generalnie związane z niektórymi działaniami.
Przykłady zdarzeń to kliknięcie myszą, naciśnięcie klawisza, przerwanie, przepełnienie stosu itp.
Zdarzenia wyzwalające przejścia są zapisywane obok łuku przejścia na diagramach stanów.
Example
Biorąc pod uwagę przykład pokazany na powyższym rysunku, przejście ze stanu Oczekiwanie do stanu Jazda ma miejsce, gdy dana osoba wsiada do taksówki. Podobnie, stan końcowy jest osiągany, gdy dociera do celu. Te dwa wystąpienia można określić jako zdarzenia Get_Taxi i Reach_Destination. Poniższy rysunek przedstawia zdarzenia w automacie stanowym.
Zdarzenia zewnętrzne i wewnętrzne
Zdarzenia zewnętrzne to zdarzenia, które przechodzą od użytkownika systemu do obiektów w systemie. Na przykład kliknięcie myszą lub naciśnięcie klawisza przez użytkownika jest zdarzeniem zewnętrznym.
Zdarzenia wewnętrzne to takie, które przechodzą z jednego obiektu do innego obiektu w systemie. Na przykład przepełnienie stosu, błąd dzielenia itp.
Odroczone wydarzenia
Zdarzenia odroczone to takie, które nie są natychmiast obsługiwane przez obiekt w bieżącym stanie, ale są ustawiane w kolejce, aby mogły być obsługiwane przez obiekt w innym stanie w późniejszym czasie.
Klasy wydarzeń
Klasa Event wskazuje grupę zdarzeń o wspólnej strukturze i zachowaniu. Podobnie jak w przypadku klas obiektów, również klasy zdarzeń mogą mieć strukturę hierarchiczną. Z klasami zdarzeń mogą być skojarzone atrybuty, przy czym czas jest atrybutem niejawnym. Na przykład możemy rozważyć zdarzenia odlotu lotu linii lotniczej, które możemy podzielić na następującą klasę -
Flight_Departs (Flight_No, From_City, To_City, Route)
działania
Czynność
Aktywność to operacja na stanach obiektu, która wymaga pewnego czasu. Są to trwające egzekucje w systemie, które można przerwać. Działania są pokazane na diagramach czynności, które przedstawiają przepływ od jednej czynności do drugiej.
Akcja
Akcja to niepodzielna operacja, która jest wykonywana w wyniku określonych zdarzeń. Atomic oznacza, że działania są nieprzerywalne, tj. Jeśli akcja zaczyna się wykonywać, kończy się bez przerywania jej przez żadne zdarzenie. Akcja może działać na obiekcie, na którym zostało wyzwolone zdarzenie, lub na innych obiektach, które są widoczne dla tego obiektu. Na działanie składa się zbiór działań.
Akcje wejścia i wyjścia
Akcja wejścia to akcja wykonywana po wejściu w stan, niezależnie od przejścia, które do niego doprowadziło.
Podobnie akcja wykonywana podczas opuszczania stanu, niezależnie od przejścia, które z niego wyprowadziło, nazywana jest akcją wyjścia.
Scenariusz
Scenariusz to opis określonej sekwencji działań. Przedstawia zachowanie obiektów poddawanych określonej serii akcji. Scenariusze pierwotne przedstawiają podstawowe sekwencje, a scenariusze drugorzędne przedstawiają sekwencje alternatywne.
Diagramy do modelowania dynamicznego
Istnieją dwa podstawowe diagramy używane do modelowania dynamicznego -
Diagramy interakcji
Diagramy interakcji opisują dynamiczne zachowanie różnych obiektów. Składa się z zestawu obiektów, ich relacji oraz wiadomości, którą przedmioty wysyłają i odbierają. Zatem interakcja modeluje zachowanie grupy powiązanych ze sobą obiektów. Dwa rodzaje diagramów interakcji to -
Sequence Diagram - Reprezentuje czasowe uporządkowanie wiadomości w sposób tabelaryczny.
Collaboration Diagram - Reprezentuje strukturalną organizację obiektów, które wysyłają i odbierają wiadomości przez wierzchołki i łuki.
Diagram przejścia stanów
Diagramy przejść stanów lub maszyny stanów opisują dynamiczne zachowanie pojedynczego obiektu. Przedstawia sekwencje stanów, przez które przechodzi obiekt w czasie swojego życia, przejścia stanów, zdarzenia i warunki powodujące przejście oraz reakcje na nie.
Współbieżność wydarzeń
W systemie mogą istnieć dwa typy współbieżności. Oni są -
Współbieżność systemu
Tutaj współbieżność jest modelowana na poziomie systemu. Cały system jest modelowany jako agregacja automatów stanowych, gdzie każda maszyna stanowa działa równolegle z innymi.
Współbieżność w obiekcie
W tym przypadku obiekt może wywoływać współbieżne zdarzenia. Obiekt może mieć stany, które składają się z pod-stanów, a zdarzenia współbieżne mogą wystąpić w każdym ze stanów podrzędnych.
Pojęcia związane ze współbieżnością w obiekcie są następujące -
Stany proste i złożone
Stan prosty nie ma struktury podrzędnej. Stan, w którym są zagnieżdżone prostsze stany, nazywany jest stanem złożonym. Stan podrzędny to stan zagnieżdżony w innym stanie. Zwykle jest używany w celu zmniejszenia złożoności maszyny stanowej. Stany podrzędne można zagnieżdżać na dowolnej liczbie poziomów.
Stany złożone mogą mieć sekwencyjne podstany lub równoczesne podstany.
Sekwencyjne pod-stany
W stanach sekwencyjnych kontrola wykonania przechodzi z jednego podstanu do innego stanu podrzędnego w sposób sekwencyjny. W tych maszynach stanu istnieje co najwyżej jeden stan początkowy i jeden stan końcowy.
Poniższy rysunek ilustruje koncepcję sekwencyjnych stanów podrzędnych.

Współbieżne pod-stany
We współbieżnych stanach podrzędnych, pod-stany są wykonywane równolegle, lub innymi słowy, każdy stan ma w sobie współbieżnie wykonywane maszyny stanów. Każda z maszyn stanowych ma swoje własne stany początkowe i końcowe. Jeśli jeden współbieżny stan podrzędny osiągnie stan końcowy przed drugim, sterowanie oczekuje w stanie końcowym. Kiedy wszystkie zagnieżdżone automaty stanowe osiągną stan końcowy, stany podrzędne łączą się z powrotem w jeden przepływ.
Poniższy rysunek przedstawia koncepcję współbieżnych stanów podrzędnych.

Modelowanie funkcjonalne daje perspektywę procesową modelu analizy zorientowanej obiektowo i przegląd tego, co system ma robić. Definiuje funkcje wewnętrznych procesów w systemie przy pomocy Diagramów Przepływu Danych (DFD). Przedstawia funkcjonalne wyprowadzenie wartości danych bez wskazania, w jaki sposób są one uzyskiwane podczas ich obliczania, ani dlaczego należy je obliczyć.
Diagramy przepływu danych
Modelowanie funkcjonalne jest reprezentowane przez hierarchię DFD. DFD jest graficzną reprezentacją systemu, która pokazuje dane wejściowe do systemu, przetwarzanie na wejściach, wyjścia systemu, a także wewnętrzne magazyny danych. DFD ilustrują serię transformacji lub obliczeń wykonywanych na obiektach lub systemie oraz zewnętrzne elementy sterujące i obiekty, które wpływają na transformację.
Rumbaugh i in. zdefiniowali DFD jako: „Diagram przepływu danych to wykres, który pokazuje przepływ wartości danych z ich źródeł w obiektach poprzez procesy, które przekształcają je w miejsca docelowe w innych obiektach”.
Cztery główne części DFD to:
- Processes,
- Przepływy danych,
- Aktorzy i
- Magazyny danych.
Inne części DFD to -
- Więzy i
- Przepływy sterowania.
Cechy DFD
Procesy
Procesy to czynności obliczeniowe, które przekształcają wartości danych. Cały system można wizualizować jako proces wysokiego poziomu. Proces można dalej podzielić na mniejsze komponenty. Proces najniższego poziomu może być prostą funkcją.
Representation in DFD - Proces jest reprezentowany jako elipsa z wpisaną w nim nazwą i zawiera stałą liczbę wejściowych i wyjściowych wartości danych.
Example - Poniższy rysunek przedstawia proces Compute_HCF_LCM, który przyjmuje dwie liczby całkowite jako dane wejściowe i wyjściowe ich HCF (najwyższy wspólny współczynnik) i LCM (najmniejsza wspólna wielokrotność).
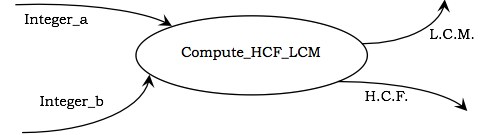
Przepływy danych
Przepływ danych reprezentuje przepływ danych między dwoma procesami. Może znajdować się między aktorem a procesem lub między magazynem danych a procesem. Przepływ danych oznacza wartość elementu danych w pewnym momencie obliczenia. Ta wartość nie jest zmieniana przez przepływ danych.
Representation in DFD - Przepływ danych jest reprezentowany przez skierowany łuk lub strzałkę oznaczoną nazwą przenoszonego elementu danych.
Na powyższym rysunku Integer_a i Integer_b reprezentują przepływy danych wejściowych do procesu, podczas gdy LCM i HCF są wyjściowymi przepływami danych.
Przepływ danych może zostać rozwidlony w następujących przypadkach:
Wartość wyjściowa jest wysyłana w kilka miejsc, jak pokazano na poniższym rysunku. W tym przypadku strzałki wyjściowe nie są oznaczone, ponieważ oznaczają tę samą wartość.
Przepływ danych zawiera zagregowaną wartość, a każdy ze składników jest wysyłany w różne miejsca, jak pokazano na poniższym rysunku. Tutaj każdy z rozwidlonych komponentów jest oznaczony.

Aktorzy
Aktorzy to aktywne obiekty, które wchodzą w interakcję z systemem, tworząc dane i wprowadzając je do systemu lub wykorzystując dane wytworzone przez system. Innymi słowy, aktorzy służą jako źródła i zlewiska danych.
Representation in DFD- Aktor jest reprezentowany przez prostokąt. Aktorzy są podłączeni do wejść i wyjść i leżą na granicy DFD.
Example - Poniższy rysunek przedstawia aktorów, a mianowicie Customer i Sales_Clerk w systemie sprzedaży kasowej.

Magazyny danych
Magazyny danych to pasywne obiekty, które działają jako repozytorium danych. W przeciwieństwie do aktorów nie mogą wykonywać żadnych operacji. Służą do przechowywania danych i pobierania przechowywanych danych. Reprezentują strukturę danych, plik dyskowy lub tabelę w bazie danych.
Representation in DFD- Składnica danych jest reprezentowana przez dwie równoległe linie zawierające nazwę magazynu danych. Każdy magazyn danych jest połączony z co najmniej jednym procesem. Strzałki wejściowe zawierają informacje umożliwiające modyfikację zawartości magazynu danych, natomiast strzałki wyjściowe zawierają informacje pobrane z magazynu danych. Kiedy część informacji ma zostać pobrana, strzałka wyjścia jest oznaczona etykietą. Strzałka bez etykiety oznacza pełne pobranie danych. Strzałka dwukierunkowa oznacza zarówno pobieranie, jak i aktualizację.
Example- Poniższy rysunek przedstawia magazyn danych Sales_Record, który przechowuje szczegóły wszystkich sprzedaży. Dane wejściowe do magazynu danych obejmują szczegóły sprzedaży, takie jak pozycja, kwota faktury, data itp. Aby znaleźć średnią sprzedaż, proces pobiera rekordy sprzedaży i oblicza średnią.

Ograniczenia
Ograniczenia określają warunki lub ograniczenia, które muszą być spełnione w miarę upływu czasu. Pozwalają dodawać nowe reguły lub modyfikować istniejące. Wiązania mogą pojawić się we wszystkich trzech modelach analizy obiektowej.
W modelowaniu obiektów ograniczenia definiują relacje między obiektami. Mogą również określać relacje między różnymi wartościami, które obiekt może przyjmować w różnym czasie.
W modelowaniu dynamicznym więzy definiują relacje między stanami i zdarzeniami różnych obiektów.
W modelowaniu funkcjonalnym ograniczenia definiują ograniczenia dotyczące przekształceń i obliczeń.
Representation - Ograniczenie jest renderowane jako ciąg w nawiasach.
Example- Poniższy rysunek przedstawia część DFD do obliczania wynagrodzeń pracowników firmy, która zdecydowała się wprowadzić zachęty dla wszystkich pracowników działu sprzedaży i podwyższyć wynagrodzenie wszystkich pracowników działu HR. Można zauważyć, że ograniczenie {Dział: Sprzedaż} powoduje, że zachęta jest obliczana tylko wtedy, gdy działem jest dział sprzedaży, a ograniczenie {Dział: HR} powoduje, że przyrost jest obliczany tylko wtedy, gdy działem jest dział HR.

Przepływy sterowania
Proces może być powiązany z pewną wartością logiczną i jest oceniany tylko wtedy, gdy wartość jest prawdziwa, chociaż nie jest bezpośrednim wejściem do procesu. Te wartości logiczne nazywane są przepływami sterowania.
Representation in DFD - Przepływy sterowania są reprezentowane przez przerywany łuk od procesu wytwarzającego wartość logiczną do procesu przez nie sterowanego.
Example- Poniższy rysunek przedstawia DFD dla dzielenia arytmetycznego. Dzielnik jest testowany pod kątem wartości niezerowej. Jeśli nie jest to zero, przepływ sterowania OK ma wartość True, a następnie proces dzielenia oblicza iloraz i resztę.

Opracowanie modelu DFD systemu
W celu opracowania modelu DFD systemu budowana jest hierarchia DFD. DFD najwyższego poziomu składa się z pojedynczego procesu i współdziałających z nim aktorów.
Na każdym kolejnym niższym poziomie stopniowo wprowadzane są dalsze szczegóły. Proces jest rozkładany na podprocesy, identyfikowane są przepływy danych między podprocesami, określane są przepływy sterowania i definiowane są magazyny danych. Podczas dekompozycji procesu, przepływ danych do lub z procesu powinien odpowiadać przepływowi danych na następnym poziomie DFD.
Example- Rozważmy system oprogramowania Wholesaler Software, który automatyzuje transakcje w hurtowni. Sklep sprzedaje w dużych ilościach i ma klientów składających się z kupców i właścicieli sklepów detalicznych. Każdy klient proszony jest o zarejestrowanie się ze swoimi danymi i otrzymuje unikalny kod klienta, C_Code. Po zakończeniu sprzedaży sklep rejestruje swoje dane i wysyła towar do wysyłki. Każdego roku sklep rozdaje klientom prezenty świąteczne, na które składa się srebrna lub złota moneta, w zależności od całkowitej sprzedaży i decyzji właściciela.
Model funkcjonalny oprogramowania hurtowego podano poniżej. Poniższy rysunek przedstawia najwyższy poziom DFD. Pokazuje oprogramowanie jako pojedynczy proces i aktorów, którzy z nim współdziałają.
Aktorzy w systemie to -
- Customers
- Salesperson
- Proprietor

Na następnym poziomie DFD, jak pokazano na poniższym rysunku, identyfikuje się główne procesy systemu, definiuje się magazyny danych i tworzy interakcję procesów z aktorami oraz tworzy się magazyny danych.
W systemie można zidentyfikować trzy procesy, którymi są:
- Zarejestruj klientów
- Sprzedaż procesowa
- Pewne prezenty
Wymagane magazyny danych to:
- Szczegóły klienta
- Szczegóły sprzedaży
- Szczegóły prezentu

Poniższy rysunek przedstawia szczegóły procesu Zarejestruj klienta. Są w nim trzy procesy: Weryfikuj szczegóły, Generuj kod C_Code i Aktualizuj szczegóły klienta. Po wprowadzeniu danych klienta są one weryfikowane. Jeśli dane są poprawne, generowany jest kod C_Code i aktualizowany jest magazyn danych Customer Details.

Poniższy rysunek przedstawia rozszerzenie procesu ustalania prezentów. Ma w sobie dwa procesy, Znajdź całkowitą sprzedaż i Zdecyduj o rodzaju monety upominkowej. Proces Find Total Sales oblicza całkowitą roczną sprzedaż odpowiadającą każdemu klientowi i rejestruje dane. Biorąc ten rekord i decyzję właściciela jako dane wejściowe, monety podarunkowe są przydzielane w procesie Decide Type of Gift Coin.

Zalety i wady DFD
| Zalety | Niedogodności |
|---|---|
| DFD przedstawiają granice systemu i dlatego są pomocne w przedstawianiu relacji między obiektami zewnętrznymi a procesami w systemie. | Tworzenie DFD zajmuje dużo czasu, co może nie być wykonalne ze względów praktycznych. |
| Pomagają użytkownikom w zdobyciu wiedzy o systemie. | DFD nie dostarczają żadnych informacji o zachowaniu zależnym od czasu, tj. Nie określają, kiedy transformacje są wykonywane. |
| Reprezentacja graficzna służy programistom jako plan do opracowania systemu. | Nie rzucają one światła na częstotliwość wykonywania obliczeń ani na powody ich wykonywania. |
| DFD dostarczają szczegółowych informacji o procesach systemowych. | Przygotowanie DFD to złożony proces wymagający dużej wiedzy specjalistycznej. Poza tym jest to trudne do zrozumienia dla osoby nietechnicznej. |
| Są używane jako część dokumentacji systemu. | Metoda przygotowania jest subiektywna i pozostawia wiele miejsca na nieprecyzyjne. |
Związek między modelami obiektowymi, dynamicznymi i funkcjonalnymi
Model obiektowy, model dynamiczny i model funkcjonalny uzupełniają się wzajemnie, zapewniając pełną analizę obiektową.
Modelowanie obiektowe rozwija statyczną strukturę systemu oprogramowania w kategoriach obiektów. W ten sposób ukazuje „wykonawców” systemu.
Modelowanie dynamiczne rozwija czasowe zachowanie obiektów w odpowiedzi na zdarzenia zewnętrzne. Pokazuje sekwencje operacji wykonywanych na obiektach.
Model funkcjonalny daje przegląd tego, co system powinien robić.
Model funkcjonalny i model obiektowy
Cztery główne części modelu funkcjonalnego pod względem modelu obiektowego to:
Process - Procesy implikują metody obiektów, które mają zostać wdrożone.
Actors - Aktorzy to obiekty w modelu obiektowym.
Data Stores - Są to obiekty w modelu obiektowym lub atrybuty obiektów.
Data Flows- Przepływy danych do lub od aktorów reprezentują operacje na obiektach lub przy ich pomocy. Przepływy danych do lub z magazynów danych reprezentują zapytania lub aktualizacje.
Model funkcjonalny i model dynamiczny
Model dynamiczny określa, kiedy operacje są wykonywane, podczas gdy model funkcjonalny określa, jak są one wykonywane i jakie argumenty są potrzebne. Ponieważ aktorzy są aktywnymi obiektami, model dynamiczny musi określać, kiedy działa. Magazyny danych są obiektami pasywnymi i odpowiadają tylko na aktualizacje i zapytania; dlatego model dynamiczny nie musi określać, kiedy działają.
Model obiektowy i model dynamiczny
Model dynamiczny pokazuje stan obiektów i operacje wykonywane na wystąpieniach zdarzeń i późniejsze zmiany stanów. Stan obiektu w wyniku zmian jest pokazany w modelu obiektu.
Unified Modeling Language (UML) to graficzny język dla OOAD, który zapewnia standardowy sposób pisania planu systemu oprogramowania. Pomaga w wizualizacji, określaniu, konstruowaniu i dokumentowaniu artefaktów systemu zorientowanego obiektowo. Służy do przedstawienia struktur i relacji w złożonym systemie.
Krótka historia
Został opracowany w latach 90-tych jako połączenie kilku technik, przede wszystkim techniki OOAD autorstwa Grady'ego Boocha, OMT (Object Modeling Technique) Jamesa Rumbaugha i OOSE (Object Oriented Software Engineering) autorstwa Ivara Jacobsona. UML podjęto próbę ujednolicenia modeli semantycznych, notacji składniowych i diagramów OOAD.
Systemy i modele w UML
System- Zestaw elementów zorganizowanych w celu osiągnięcia określonych celów tworzy system. Systemy są często podzielone na podsystemy i opisane za pomocą zestawu modeli.
Model - Model to uproszczona, kompletna i spójna abstrakcja systemu, stworzona w celu lepszego zrozumienia systemu.
View - Widok to rzutowanie modelu systemu z określonej perspektywy.
Konceptualny model UML
Model konceptualny UML obejmuje trzy główne elementy -
- Podstawowe bloki konstrukcyjne
- Rules
- Wspólne mechanizmy
Podstawowe bloki konstrukcyjne
Trzy elementy składowe UML to -
- Things
- Relationships
- Diagrams
Rzeczy
W UML są cztery rodzaje rzeczy, a mianowicie -
Structural Things- Są to rzeczowniki modeli UML reprezentujących statyczne elementy, które mogą być fizyczne lub koncepcyjne. Elementy strukturalne to klasa, interfejs, współpraca, przypadek użycia, aktywna klasa, komponenty i węzły.
Behavioral Things- Są to czasowniki modeli UML reprezentujących dynamiczne zachowanie w czasie i przestrzeni. Dwa typy rzeczy behawioralnych to interakcja i maszyna stanów.
Grouping Things- Obejmują organizacyjne części modeli UML. Jest tylko jeden rodzaj grupowania, tj. Pakiet.
Annotational Things - To są wyjaśnienia w modelach UML reprezentujące komentarze zastosowane do opisu elementów.
Relacje
Relacje to połączenie między rzeczami. Cztery typy relacji, które można przedstawić w UML, to:
Dependency- To jest semantyczna relacja między dwiema rzeczami, tak że zmiana jednej rzeczy powoduje zmianę drugiej. Pierwsza jest rzeczą niezależną, podczas gdy druga jest rzeczą zależną.
Association - Jest to relacja strukturalna, która reprezentuje grupę połączeń o wspólnej strukturze i wspólnym zachowaniu.
Generalization - Jest to relacja uogólnienia / specjalizacji, w której podklasy dziedziczą strukturę i zachowanie po nadklasach.
Realization - Jest to relacja semantyczna między dwoma lub więcej klasyfikatorami, tak że jeden klasyfikator ustanawia kontrakt, którego przestrzeganie zapewniają pozostali klasyfikatorzy.
Diagramy
Diagram to graficzna reprezentacja systemu. Składa się z grupy elementów ogólnie w postaci wykresu. UML zawiera w sumie dziewięć diagramów, a mianowicie -
- Diagram klas
- Diagram obiektów
- Diagram przypadków użycia
- Diagram sekwencyjny
- Schemat współpracy
- Diagram wykresu stanu
- Diagram aktywności
- Schemat elementów
- Diagram rozmieszczenia
Zasady
UML ma wiele reguł, dzięki czemu modele są semantycznie spójne i harmonijnie powiązane z innymi modelami w systemie. UML ma reguły semantyczne dla następujących -
- Names
- Scope
- Visibility
- Integrity
- Execution
Wspólne mechanizmy
UML ma cztery wspólne mechanizmy -
- Specifications
- Adornments
- Wspólne podziały
- Mechanizmy rozszerzalności
Specyfikacje
W języku UML za każdym zapisem graficznym znajduje się instrukcja tekstowa określająca składnię i semantykę. To są specyfikacje. Specyfikacje zapewniają semantyczną płytę montażową, która zawiera wszystkie części systemu i relacje między różnymi ścieżkami.
Ozdoby
Każdy element w UML ma unikalną notację graficzną. Poza tym istnieją zapisy reprezentujące ważne aspekty elementu, takie jak nazwa, zakres, widoczność itp.
Wspólne podziały
Systemy obiektowe można podzielić na wiele sposobów. Dwa powszechne sposoby podziału to:
Division of classes and objects- Klasa to abstrakcja grupy podobnych obiektów. Obiekt to konkretna instancja, która faktycznie istnieje w systemie.
Division of Interface and Implementation- Interfejs definiuje zasady interakcji. Wdrożenie to konkretna realizacja reguł zdefiniowanych w interfejsie.
Mechanizmy rozszerzalności
UML to język otwarty. Możliwe jest rozszerzenie możliwości UML w sposób kontrolowany w celu dopasowania do wymagań systemu. Mechanizmy rozszerzalności to -
Stereotypes - Poszerza słownictwo języka UML, dzięki któremu można tworzyć nowe bloki budulcowe z już istniejących.
Tagged Values - Rozszerza właściwości bloków konstrukcyjnych UML.
Constraints - Rozszerza semantykę bloków konstrukcyjnych UML.
UML definiuje określone zapisy dla każdego z bloków konstrukcyjnych.
Klasa
Klasa jest reprezentowana przez prostokąt mający trzy sekcje -
- górna sekcja zawierająca nazwę klasy
- środkowa sekcja zawierająca atrybuty klas
- dolna sekcja reprezentująca operacje klasy
Widoczność atrybutów i operacji można przedstawić na następujące sposoby -
Public- Członek publiczny jest widoczny z dowolnego miejsca w systemie. W diagramie klas jest poprzedzony symbolem „+”.
Private- Członek prywatny jest widoczny tylko z poziomu klasy. Nie można uzyskać do niego dostępu spoza zajęć. Członek prywatny jest poprzedzony symbolem „-”.
Protected- Chroniony element członkowski jest widoczny z poziomu klasy i podklas dziedziczonych z tej klasy, ale nie z zewnątrz. Jest poprzedzony symbolem „#”.
Klasa abstrakcyjna ma nazwę klasy zapisaną kursywą.
Example- Rozważmy klasę Circle wprowadzoną wcześniej. Atrybuty okręgu to współrzędna x, współrzędna y i promień. Operacje to findArea (), findCircumference () i scale (). Załóżmy, że x-Coor i Y-Coor są prywatnymi składnikami danych, radius jest chronionym składnikiem danych, a funkcje składowe są publiczne. Poniższy rysunek przedstawia schematyczną reprezentację klasy.

Obiekt
Obiekt jest reprezentowany jako prostokąt z dwiema sekcjami -
Górna sekcja zawiera nazwę obiektu wraz z nazwą klasy lub pakietu, którego jest instancją. Nazwa przyjmuje następujące formy -
object-name - nazwa klasy
object-name - nazwa-klasy :: nazwa-pakietu
class-name - w przypadku obiektów anonimowych
Dolna sekcja przedstawia wartości atrybutów. Ma postać nazwa-atrybutu = wartość.
Czasami obiekty są przedstawiane za pomocą zaokrąglonych prostokątów.
Example- Rozważmy obiekt klasy Circle o nazwie c1. Zakładamy, że środek c1 znajduje się w (2, 3), a promień c1 wynosi 5. Poniższy rysunek przedstawia obiekt.

Składnik
Komponent to fizyczna i wymienna część systemu, która jest zgodna i zapewnia realizację zestawu interfejsów. Reprezentuje fizyczne opakowanie elementów, takich jak klasy i interfejsy.
Notation - W diagramach UML komponent jest reprezentowany przez prostokąt z zakładkami, jak pokazano na poniższym rysunku.

Berło
Interfejs to zbiór metod klasy lub składnika. Określa zestaw usług, które mogą być świadczone przez klasę lub komponent.
Notation- Ogólnie interfejs jest rysowany jako okrąg wraz z jego nazwą. Interfejs jest prawie zawsze dołączony do klasy lub komponentu, który go realizuje. Poniższy rysunek przedstawia zapis interfejsu.

Pakiet
Pakiet to zorganizowana grupa elementów. Pakiet może zawierać elementy strukturalne, takie jak klasy, komponenty i inne pakiety.
Notation- Graficznie pakiet jest reprezentowany przez folder z zakładkami. Pakiet jest generalnie rysowany tylko z nazwą. Może jednak zawierać dodatkowe szczegóły dotyczące zawartości opakowania. Zobacz poniższe rysunki.

Związek
Notacje dla różnych typów relacji są następujące -

Zwykle elementy w związku odgrywają w związku określone role. Nazwa roli oznacza zachowanie elementu uczestniczącego w określonym kontekście.
Example- Poniższe rysunki przedstawiają przykłady różnych relacji między klasami. Pierwszy rysunek przedstawia powiązanie między dwiema klasami, działem i pracownikiem, przy czym dział może mieć wielu pracowników. Pracownik to nazwa roli. „1” obok działu i „*” obok pracownika oznacza, że współczynnik kardynalności wynosi jeden do wielu. Drugi rysunek przedstawia zależność agregacji, uniwersytet to „całość” wielu wydziałów.

Diagramy strukturalne UML są podzielone na następujące kategorie: diagram klas, diagram obiektów, diagram komponentów i diagram wdrożenia.
Diagram klas
Diagram klas modeluje statyczny widok systemu. Obejmuje klasy, interfejsy i współpracę systemu; i relacje między nimi.
Diagram klas systemu
Rozważmy uproszczony system bankowy.
Bank ma wiele oddziałów. W każdej strefie jeden oddział jest wyznaczony jako strefowa centrala, która nadzoruje pozostałe oddziały w tej strefie. Każdy oddział może mieć wiele kont i pożyczek. Konto może być kontem oszczędnościowym lub rachunkiem bieżącym. Klient może otworzyć zarówno rachunek oszczędnościowy, jak i rachunek bieżący. Jednak klient nie może mieć więcej niż jednego rachunku oszczędnościowego lub rachunku bieżącego. Klient może również zaciągnąć kredyt w banku.
Poniższy rysunek przedstawia odpowiedni diagram klas.

Zajęcia w systemie
Bank, oddział, konto, konto oszczędnościowe, rachunek bieżący, pożyczka i klient.
Relacje
A Bank “has–a” number of Branches - kompozycja, jeden do wielu
A Branch with role Zonal Head Office supervises other Branches - asocjacja jednoargumentowa, jeden do wielu
A Branch “has–a” number of accounts - agregacja, jeden do wielu
Z klasy Konto odziedziczyły dwie klasy, a mianowicie Rachunek Oszczędnościowy i Rachunek Bieżący.
A Customer can have one Current Account - skojarzenie, jeden do jednego
A Customer can have one Savings Account - skojarzenie, jeden do jednego
A Branch “has–a” number of Loans - agregacja, jeden do wielu
A Customer can take many loans - stowarzyszenie, jeden do wielu
Diagram obiektów
Diagram obiektów modeluje grupę obiektów i ich połączenia w określonym momencie. Pokazuje instancje rzeczy na diagramie klas. Diagram obiektowy to statyczna część diagramu interakcji.
Example - Poniższy rysunek przedstawia diagram obiektów części diagramu klas systemu bankowego.

Schemat elementów
Diagramy komponentów pokazują organizację i zależności między grupą komponentów.
Schematy komponentów obejmują -
- Components
- Interfaces
- Relationships
- Pakiety i podsystemy (opcjonalnie)
Schematy komponentów są używane do -
konstruowanie systemów poprzez inżynierię naprzód i odwrotną.
modelowanie zarządzania konfiguracją plików kodu źródłowego podczas tworzenia systemu z wykorzystaniem obiektowego języka programowania.
reprezentowanie schematów w modelowaniu baz danych.
modelowanie zachowań systemów dynamicznych.
Example
Poniższy rysunek przedstawia diagram komponentów służący do modelowania kodu źródłowego systemu opracowanego przy użyciu języka C ++. Pokazuje cztery pliki z kodem źródłowym, a mianowicie myheader.h, otherheader.h, priority.cpp i other.cpp. Pokazane są dwie wersje myheader.h, pochodzące od najnowszej wersji do jej przodka. Plik priority.cpp ma zależność kompilacji od other.cpp. Plik other.cpp ma zależność kompilacji od otherheader.h.
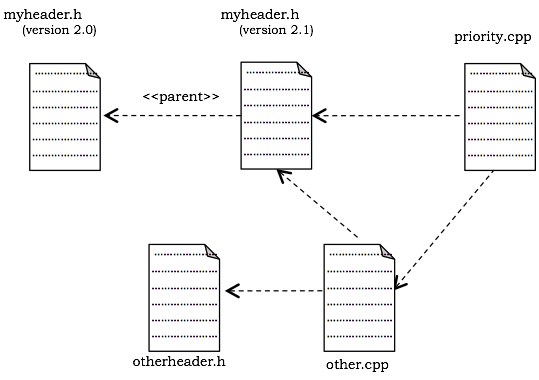
Diagram rozmieszczenia
Diagram wdrożenia kładzie nacisk na konfigurację węzłów przetwarzania środowiska wykonawczego i ich komponentów, które na nich żyją. Zwykle składają się z węzłów i zależności lub skojarzeń między węzłami.
Diagramy rozmieszczenia służą do -
modelować urządzenia w systemach wbudowanych, które zazwyczaj obejmują kolekcję sprzętu wymagającego dużej ilości oprogramowania.
reprezentują topologie systemów klient / serwer.
modelować systemy w pełni rozproszone.
Example
Poniższy rysunek przedstawia topologię systemu komputerowego zgodnego z architekturą klient / serwer. Rysunek przedstawia węzeł stereotypowy jako serwer składający się z procesorów. Rysunek wskazuje, że w systemie wdrożono cztery lub więcej serwerów. Z serwerem połączone są węzły klienckie, gdzie każdy węzeł reprezentuje urządzenie końcowe, takie jak stacja robocza, laptop, skaner lub drukarka. Węzły są reprezentowane za pomocą ikon, które wyraźnie przedstawiają ich odpowiednik w świecie rzeczywistym.

Diagramy behawioralne UML wizualizują, określają, konstruują i dokumentują dynamiczne aspekty systemu. Diagramy behawioralne są podzielone na następujące kategorie: diagramy przypadków użycia, diagramy interakcji, diagramy wykresów stanu i diagramy aktywności.
Model przypadku użycia
Przypadek użycia
Przypadek użycia opisuje sekwencję działań, które system wykonuje, przynosząc widoczne rezultaty. Pokazuje interakcję rzeczy poza systemem z samym systemem. Przypadki użycia mogą dotyczyć całego systemu, jak również jego części.
Aktor
Aktor reprezentuje role, które odgrywają użytkownicy przypadków użycia. Aktor może być osobą (np. Student, klient), urządzenie (np. Stacja robocza) lub inny system (np. Bank, instytucja).
Poniższy rysunek przedstawia notacje aktora o imieniu Student i przypadek użycia o nazwie Generuj raport wydajności.

Diagramy przypadków użycia
Diagramy przypadków użycia przedstawiają zewnętrzne spojrzenie na sposób, w jaki zachowują się elementy w systemie i jak można je wykorzystać w kontekście.
Diagramy przypadków użycia obejmują -
- Przypadków użycia
- Actors
- Relacje, takie jak zależność, uogólnienie i skojarzenie
Diagramy przypadków użycia są używane -
Modelowanie kontekstu systemu poprzez zamknięcie wszystkich działań systemu w prostokącie i skupienie się na aktorach poza systemem poprzez interakcję z nim.
Modelowanie wymagań systemu z zewnętrznego punktu widzenia.
Example
Rozważmy zautomatyzowany system giełdowy. Zakładamy następujące cechy systemu -
Izba handlowa prowadzi transakcje z dwoma typami klientów, klientami indywidualnymi i klientami korporacyjnymi.
Po złożeniu zamówienia przez klienta jest ono przetwarzane przez dział sprzedaży, a klient otrzymuje rachunek.
System umożliwia menadżerowi zarządzanie kontami klientów i odpowiadanie na wszelkie zapytania przesłane przez klienta.

Diagramy interakcji
Diagramy interakcji przedstawiają interakcje obiektów i ich relacje. Zawierają również wiadomości przekazywane między nimi. Istnieją dwa rodzaje diagramów interakcji -
- Diagramy sekwencji
- Diagramy współpracy
Diagramy interakcji służą do modelowania -
przepływ sterowania według porządku czasu przy użyciu diagramów sekwencji.
kontrola przepływu organizacji za pomocą diagramów współpracy.
Diagramy sekwencji
Diagramy sekwencji to diagramy interakcji, które ilustrują kolejność komunikatów według czasu.
Notations- Diagramy te mają postać dwuwymiarowych wykresów. Obiekty inicjujące interakcję są umieszczane na osi x. Wiadomości wysyłane i odbierane przez te obiekty są umieszczane wzdłuż osi y, w kolejności rosnącej w czasie od góry do dołu.
Example - Diagram sekwencji dla systemu Automated Trading House przedstawiono na poniższym rysunku.

Diagramy współpracy
Diagramy współpracy to diagramy interakcji, które ilustrują strukturę obiektów, które wysyłają i odbierają wiadomości.
Notations- Na tych diagramach obiekty uczestniczące w interakcji są pokazane za pomocą wierzchołków. Łącza łączące obiekty służą do wysyłania i odbierania wiadomości. Wiadomość jest wyświetlana jako oznaczona strzałka.
Example - Schemat współpracy dla systemu Automated Trading House przedstawiono na poniższym rysunku.

Diagramy stanu-wykresu
Diagram wykresu stanu przedstawia maszynę stanów, która przedstawia przepływ sterowania obiektu z jednego stanu do drugiego. Maszyna stanów przedstawia sekwencje stanów, którym podlega obiekt w wyniku zdarzeń, oraz ich reakcje na zdarzenia.
Diagramy Stan-Wykres składają się z -
- Stany: proste lub złożone
- Przejścia między stanami
- Zdarzenia powodujące przejścia
- Działania związane z wydarzeniami
Diagramy wykresów stanu służą do modelowania obiektów o charakterze reaktywnym.
Example
W systemie Automated Trading House zamodelujmy zamówienie jako obiekt i prześledźmy jego sekwencję. Poniższy rysunek przedstawia odpowiedni diagram stanu.

Diagramy aktywności
Diagram aktywności przedstawia przepływ działań, które są trwającymi operacjami nieatomowymi w maszynie stanu. Działania prowadzą do działań, które są operacjami atomowymi.
Diagramy aktywności składają się z -
- Stany aktywności i stany akcji
- Transitions
- Objects
Diagramy aktywności są używane do modelowania -
- przepływy pracy widziane przez aktorów, wchodzące w interakcję z systemem.
- szczegóły operacji lub obliczeń przy użyciu schematów blokowych.
Example
Poniższy rysunek przedstawia diagram aktywności części systemu Automated Trading House.

Po fazie analizy model koncepcyjny jest dalej rozwijany w model zorientowany obiektowo przy użyciu projektowania zorientowanego obiektowo (OOD). W OOD koncepcje niezależne od technologii w modelu analizy są mapowane na klasy implementujące, identyfikowane są ograniczenia i projektowane są interfejsy, w wyniku czego powstaje model domeny rozwiązania. Krótko mówiąc, skonstruowano szczegółowy opis określający sposób budowy systemu w oparciu o technologie betonowe
Etapy projektowania zorientowanego obiektowo można określić jako -
- Definicja kontekstu systemu
- Projektowanie architektury systemu
- Identyfikacja obiektów w systemie
- Budowa modeli projektowych
- Specyfikacja interfejsów obiektów
Projekt systemu
Projekt systemu obiektowego obejmuje zdefiniowanie kontekstu systemu, a następnie zaprojektowanie architektury systemu.
Context- Kontekst systemu ma część statyczną i dynamiczną. Kontekst statyczny systemu jest projektowany za pomocą prostego schematu blokowego całego systemu, który jest rozszerzany do hierarchii podsystemów. Model podsystemu jest reprezentowany przez pakiety UML. Dynamiczny kontekst opisuje, w jaki sposób system współdziała ze swoim otoczeniem. Jest modelowany za pomocąuse case diagrams.
System Architecture- Architektura systemu jest projektowana w oparciu o kontekst systemu, zgodnie z zasadami projektowania architektonicznego oraz wiedzy dziedzinowej. Zazwyczaj system jest podzielony na warstwy, a każda warstwa jest rozkładana w celu utworzenia podsystemów.
Rozkład obiektowy
Dekompozycja oznacza podzielenie dużego złożonego systemu na hierarchię mniejszych komponentów o mniejszych złożoności, na zasadzie dziel i rządź. Każdy główny składnik systemu nazywany jest podsystemem. Dekompozycja obiektowa identyfikuje poszczególne autonomiczne obiekty w systemie i komunikację między tymi obiektami.
Zalety rozkładu to -
Poszczególne komponenty są mniej skomplikowane, a więc bardziej zrozumiałe i łatwiejsze w zarządzaniu.
Umożliwia podział kadr o specjalistycznych umiejętnościach.
Umożliwia wymianę lub modyfikację podsystemów bez wpływu na inne podsystemy.
Identyfikacja współbieżności
Współbieżność umożliwia jednoczesne odbieranie zdarzeń przez więcej niż jeden obiekt i jednoczesne wykonywanie więcej niż jednego działania. Współbieżność jest identyfikowana i reprezentowana w modelu dynamicznym.
Aby włączyć współbieżność, do każdego współbieżnego elementu jest przypisany oddzielny wątek kontroli. Jeśli współbieżność jest na poziomie obiektu, dwa współbieżne obiekty mają przypisane dwa różne wątki kontroli. Jeśli dwie operacje na jednym obiekcie są z natury współbieżne, obiekt ten jest dzielony na różne wątki.
Współbieżność wiąże się z problemami związanymi z integralnością danych, impasem i głodem. Dlatego zawsze, gdy wymagana jest współbieżność, należy opracować jasną strategię. Poza tym współbieżność wymaga identyfikacji na samym etapie projektowania i nie można jej pozostawić na etapie wdrożenia.
Identyfikowanie wzorców
Projektując aplikacje, przyjmuje się powszechnie przyjęte rozwiązania dla pewnych kategorii problemów. To są wzorce projektowania. Wzorzec można zdefiniować jako udokumentowany zestaw bloków konstrukcyjnych, które mogą być używane w niektórych typach problemów związanych z tworzeniem aplikacji.
Niektóre powszechnie używane wzorce projektowe to -
- Wzór elewacji
- Wzór separacji widoku modelu
- Wzorzec obserwatora
- Wzorzec kontrolera widoku modelu
- Opublikuj wzorzec subskrypcji
- Wzorzec proxy
Kontrolowanie wydarzeń
Podczas projektowania systemu należy zidentyfikować zdarzenia, które mogą wystąpić w obiektach systemu i odpowiednio się nimi zająć.
Zdarzenie to specyfikacja znaczącego zdarzenia, które ma miejsce w czasie i przestrzeni.
Istnieją cztery typy zdarzeń, które można modelować, a mianowicie:
Signal Event - Nazwany obiekt rzucony przez jeden obiekt i przechwycony przez inny obiekt.
Call Event - Zdarzenie synchroniczne reprezentujące wysłanie operacji.
Time Event - Wydarzenie reprezentujące upływ czasu.
Change Event - zdarzenie reprezentujące zmianę stanu.
Obsługa warunków brzegowych
Faza projektowania systemu musi obejmować inicjalizację i zakończenie systemu jako całości, a także każdego podsystemu. Różne udokumentowane aspekty są następujące:
Uruchomienie systemu, czyli przejście systemu ze stanu niezainicjalizowanego do stanu ustalonego.
Zakończenie systemu, tj. Zamknięcie wszystkich uruchomionych wątków, oczyszczenie zasobów i wysyłanie komunikatów.
Wstępna konfiguracja systemu i rekonfiguracja systemu w razie potrzeby.
Przewidywanie awarii lub niepożądanego zakończenia systemu.
Warunki brzegowe są modelowane przy użyciu przypadków użycia granic.
Projektowanie obiektów
Po opracowaniu hierarchii podsystemów identyfikowane są obiekty w systemie i projektowane są ich szczegóły. Tutaj projektant szczegółowo przedstawia strategię wybraną podczas projektowania systemu. Nacisk przenosi się z koncepcji domeny aplikacji na koncepcje komputerowe. Obiekty zidentyfikowane podczas analizy są wytrawiane do wdrożenia w celu zminimalizowania czasu wykonywania, zużycia pamięci i całkowitego kosztu.
Projekt obiektu obejmuje następujące fazy -
- Identyfikacja obiektu
- Reprezentacja obiektów, czyli budowa modeli projektowych
- Klasyfikacja operacji
- Projektowanie algorytmów
- Projektowanie relacji
- Realizacja kontroli dla interakcji zewnętrznych
- Pakuj klasy i skojarzenia do modułów
Identyfikacja obiektu
Pierwszym krokiem projektowania obiektu jest identyfikacja obiektu. Obiekty zidentyfikowane w fazach analizy obiektowej są pogrupowane w klasy i dopracowane tak, aby nadawały się do rzeczywistej implementacji.
Funkcje tego etapu to -
Identyfikowanie i udoskonalanie klas w każdym podsystemie lub pakiecie
Definiowanie powiązań i powiązań między klasami
Projektowanie hierarchicznych skojarzeń między klasami, tj. Uogólnienie / specjalizacja i dziedziczenie
Projektowanie agregacji
Reprezentacja obiektu
Po zidentyfikowaniu klas należy je przedstawić za pomocą technik modelowania obiektów. Ten etap zasadniczo obejmuje tworzenie diagramów UML.
Istnieją dwa rodzaje modeli projektowych, które należy wyprodukować -
Static Models - Opisywać strukturę statyczną systemu za pomocą diagramów klas i diagramów obiektów.
Dynamic Models - Opisać dynamiczną strukturę systemu i pokazać interakcję między klasami za pomocą diagramów interakcji i diagramów wykresów stanu.
Klasyfikacja operacji
Na tym etapie operacje, które mają zostać wykonane na obiektach, są definiowane poprzez połączenie trzech modeli opracowanych w fazie OOA, a mianowicie modelu obiektowego, modelu dynamicznego i modelu funkcjonalnego. Operacja określa, co należy zrobić, a nie jak należy to zrobić.
Następujące zadania są wykonywane w odniesieniu do operacji -
Opracowywany jest diagram przejść stanów każdego obiektu w systemie.
Operacje są zdefiniowane dla zdarzeń odbieranych przez obiekty.
Identyfikowane są przypadki, w których jedno zdarzenie wyzwala inne zdarzenia w tych samych lub różnych obiektach.
Zidentyfikowano podoperacje w ramach działań.
Główne działania zostały rozszerzone na diagramy przepływu danych.
Projektowanie algorytmów
Operacje na obiektach są definiowane za pomocą algorytmów. Algorytm to krokowa procedura, która rozwiązuje problem związany z operacją. Algorytmy koncentrują się na tym, jak to zrobić.
Danej operacji może odpowiadać więcej niż jeden algorytm. Po zidentyfikowaniu alternatywnych algorytmów wybierany jest optymalny algorytm dla danej dziedziny problemowej. Metryki wyboru optymalnego algorytmu to:
Computational Complexity - Złożoność determinuje wydajność algorytmu pod względem czasu obliczeń i wymagań dotyczących pamięci.
Flexibility - Elastyczność decyduje o tym, czy wybrany algorytm można odpowiednio zaimplementować bez utraty stosowności w różnych środowiskach.
Understandability - To określa, czy wybrany algorytm jest łatwy do zrozumienia i wdrożenia.
Projektowanie relacji
Strategię implementacji relacji należy wyrysować na etapie projektowania obiektu. Główne relacje, które są uwzględniane, obejmują skojarzenia, agregacje i spadki.
Projektant powinien wykonać następujące czynności dotyczące skojarzeń -
Określ, czy skojarzenie jest jednokierunkowe czy dwukierunkowe.
Przeanalizuj ścieżkę skojarzeń i zaktualizuj je, jeśli to konieczne.
Implementuj asocjacje jako odrębny obiekt, w przypadku relacji wiele-do-wielu; lub jako łącze do innego obiektu w przypadku relacji jeden do jednego lub jeden do wielu.
Jeśli chodzi o spadki, projektant powinien wykonać następujące czynności -
Dostosuj klasy i ich skojarzenia.
Zidentyfikuj klasy abstrakcyjne.
Postaraj się, aby zachowania były udostępniane w razie potrzeby.
Wdrażanie kontroli
Projektant obiektów może wprowadzić udoskonalenia do strategii modelu wykresu stanu. W projektowaniu systemu tworzy się podstawową strategię realizacji modelu dynamicznego. Podczas projektowania obiektów strategia ta jest odpowiednio przystrojona do odpowiedniej implementacji.
Podejścia do implementacji modelu dynamicznego są następujące:
Represent State as a Location within a Program- Jest to tradycyjne podejście oparte na procedurze, w którym lokalizacja kontroli określa stan programu. Maszyna skończonych stanów może zostać zaimplementowana jako program. Przejście tworzy instrukcję wejściową, główna ścieżka sterowania tworzy sekwencję instrukcji, gałęzie tworzą warunki, a ścieżki wstecz tworzą pętle lub iteracje.
State Machine Engine- To podejście bezpośrednio reprezentuje automat stanowy poprzez klasę silnika automatu stanowego. Ta klasa wykonuje maszynę stanową za pomocą zestawu przejść i akcji udostępnianych przez aplikację.
Control as Concurrent Tasks- W tym podejściu obiekt jest realizowany jako zadanie w języku programowania lub systemie operacyjnym. Tutaj zdarzenie jest realizowane jako wywołanie między zadaniami. Zachowuje nieodłączną współbieżność rzeczywistych obiektów.
Klasy opakowań
W każdym dużym projekcie ważne jest skrupulatne podzielenie implementacji na moduły lub pakiety. Podczas projektowania obiektów klasy i obiekty są grupowane w pakiety, aby umożliwić wielu grupom wspólną pracę nad projektem.
Różne aspekty pakowania to -
Hiding Internal Information from Outside View - Pozwala na postrzeganie klasy jako „czarnej skrzynki” i pozwala na zmianę implementacji klasy bez konieczności modyfikowania kodu przez klientów klasy.
Coherence of Elements - Element taki jak klasa, operacja czy moduł jest spójny, jeśli jest zorganizowany w spójny plan, a wszystkie jego części są ze sobą nierozerwalnie powiązane, tak aby służyły wspólnemu celowi.
Construction of Physical Modules - Poniższe wskazówki pomagają przy konstruowaniu fizycznych modułów -
Klasy w module powinny reprezentować podobne rzeczy lub komponenty w tym samym obiekcie złożonym.
Ściśle połączone klasy powinny znajdować się w tym samym module.
Klasy niepodłączone lub słabo połączone należy umieścić w osobnych modułach.
Moduły powinny charakteryzować się dobrą spójnością, czyli wysoką współpracą między jego elementami.
Moduł powinien mieć niskie sprzężenie z innymi modułami, tj. Interakcja lub współzależność między modułami powinna być minimalna.
Optymalizacja projektu
Model analityczny przechwytuje logiczne informacje o systemie, podczas gdy model projektowy dodaje szczegóły, aby zapewnić skuteczny dostęp do informacji. Przed wdrożeniem projektu należy go zoptymalizować, aby wdrożenie było bardziej wydajne. Celem optymalizacji jest zminimalizowanie kosztów pod względem czasu, przestrzeni i innych wskaźników.
Jednak optymalizacja projektu nie powinna być przesadna, ponieważ łatwość implementacji, łatwość konserwacji i rozszerzalność są również ważnymi kwestiami. Często widać, że doskonale zoptymalizowany projekt jest bardziej wydajny, ale mniej czytelny i nadaje się do ponownego użycia. Dlatego projektant musi znaleźć równowagę między nimi.
Różne rzeczy, które można zrobić w celu optymalizacji projektu, to:
- Dodaj zbędne powiązania
- Pomiń nieprzydatne skojarzenia
- Optymalizacja algorytmów
- Zapisz atrybuty pochodne, aby uniknąć ponownego obliczania złożonych wyrażeń
Dodanie zbędnych skojarzeń
Podczas optymalizacji projektu sprawdza się, czy wyprowadzenie nowych skojarzeń może obniżyć koszty dostępu. Chociaż te zbędne skojarzenia mogą nie dodawać żadnych informacji, mogą zwiększyć wydajność całego modelu.
Pominięcie nieprzydatnych skojarzeń
Obecność zbyt wielu skojarzeń może spowodować, że system będzie nieczytelny, a tym samym zmniejszy ogólną wydajność systemu. Dlatego podczas optymalizacji wszystkie nieużyteczne skojarzenia są usuwane.
Optymalizacja algorytmów
W systemach zorientowanych obiektowo optymalizacja struktury danych i algorytmów odbywa się w sposób oparty na współpracy. Gdy projekt klasy jest już gotowy, operacje i algorytmy muszą zostać zoptymalizowane.
Optymalizację algorytmów uzyskuje się poprzez -
- Zmiana kolejności zadań obliczeniowych
- Odwrócenie kolejności wykonywania pętli od określonej w modelu funkcjonalnym
- Usuwanie martwych ścieżek w algorytmie
Zapisywanie i przechowywanie atrybutów pochodnych
Atrybuty pochodne to te atrybuty, których wartości są obliczane jako funkcja innych atrybutów (atrybutów podstawowych). Ponowne obliczanie wartości atrybutów pochodnych za każdym razem, gdy są potrzebne, jest procedurą czasochłonną. Aby tego uniknąć, wartości można obliczyć i zapisać w postaci wyliczonej.
Może to jednak powodować anomalie aktualizacji, tj. Zmianę wartości atrybutów podstawowych bez odpowiadającej im zmiany wartości atrybutów pochodnych. Aby tego uniknąć, podejmuje się następujące kroki -
Przy każdej aktualizacji wartości atrybutu podstawowego, atrybut pochodny jest również ponownie obliczany.
Wszystkie atrybuty pochodne są ponownie obliczane i aktualizowane okresowo w grupie, a nie po każdej aktualizacji.
Dokumentacja projektowa
Dokumentacja jest istotną częścią każdego procesu tworzenia oprogramowania, która rejestruje procedurę tworzenia oprogramowania. Decyzje projektowe muszą być udokumentowane dla każdego nietrywialnego systemu oprogramowania do przekazywania projektu innym osobom.
Obszary użytkowania
Chociaż jest to produkt drugorzędny, niezbędna jest dobra dokumentacja, szczególnie w następujących obszarach -
- Podczas projektowania oprogramowania, które jest rozwijane przez wielu programistów
- W iteracyjnych strategiach tworzenia oprogramowania
- Przy opracowywaniu kolejnych wersji projektu oprogramowania
- Do oceny oprogramowania
- Do znajdowania warunków i obszarów testowania
- Do konserwacji oprogramowania.
Zawartość
Korzystna dokumentacja powinna zasadniczo zawierać następującą treść -
High–level system architecture - Diagramy procesów i schematy modułów
Key abstractions and mechanisms - Diagramy klas i diagramy obiektów.
Scenarios that illustrate the behavior of the main aspects - Diagramy behawioralne
funkcje
Cechy dobrej dokumentacji to -
Zwięzłe, a jednocześnie jednoznaczne, spójne i kompletne
Możliwość śledzenia zgodnie ze specyfikacjami wymagań systemu
Well-structured
Schematyczna zamiast opisowa
Wdrażanie projektu zorientowanego obiektowo zwykle wymaga użycia standardowego języka programowania obiektowego (OOPL) lub odwzorowania projektów obiektowych na bazy danych. W większości przypadków dotyczy obu.
Wdrożenie z wykorzystaniem języków programowania
Zwykle zadanie przekształcenia projektu obiektu w kod jest prostym procesem. Dowolny obiektowy język programowania, taki jak C ++, Java, Smalltalk, C # i Python, obejmuje możliwość reprezentowania klas. W tym rozdziale zilustrujemy tę koncepcję w C ++.
Poniższy rysunek przedstawia reprezentację klasy Circle w języku C ++.

Wdrażanie skojarzeń
Większość języków programowania nie udostępnia konstrukcji do bezpośredniej implementacji asocjacji. Dlatego zadanie tworzenia stowarzyszeń wymaga poważnego przemyślenia.
Skojarzenia mogą być jednokierunkowe lub dwukierunkowe. Poza tym każde skojarzenie może mieć charakter „jeden do jednego”, „jeden do wielu” lub „wiele do wielu”.
Skojarzenia jednokierunkowe
Przy wdrażaniu skojarzeń jednokierunkowych należy zachować ostrożność, aby zachować jednokierunkowość. Implementacje dla różnych liczebności są następujące -
Optional Associations- Tutaj może istnieć łącze między uczestniczącymi obiektami lub nie. Na przykład w powiązaniu między klientem a rachunkiem bieżącym na poniższym rysunku klient może mieć lub nie mieć rachunku bieżącego.

W celu wdrożenia obiekt rachunku bieżącego jest dołączany jako atrybut w kliencie, który może mieć wartość NULL. Implementacja w C ++ -
class Customer {
private:
// attributes
Current_Account c; //an object of Current_Account as attribute
public:
Customer() {
c = NULL;
} // assign c as NULL
Current_Account getCurrAc() {
return c;
}
void setCurrAc( Current_Account myacc) {
c = myacc;
}
void removeAcc() {
c = NULL;
}
};One–to–one Associations- W tym przypadku jedno wystąpienie klasy jest powiązane z dokładnie jednym wystąpieniem skojarzonej klasy. Na przykład dział i menedżer mają powiązania jeden do jednego, jak pokazano na poniższym rysunku.

Jest to realizowane przez włączenie do działu obiektu menedżera, który nie powinien mieć wartości NULL. Implementacja w C ++ -
class Department {
private:
// attributes
Manager mgr; //an object of Manager as attribute
public:
Department (/*parameters*/, Manager m) { //m is not NULL
// assign parameters to variables
mgr = m;
}
Manager getMgr() {
return mgr;
}
};One–to–many Associations- W tym przypadku jedno wystąpienie klasy jest powiązane z więcej niż jednym wystąpieniem skojarzonej klasy. Rozważmy na przykład powiązanie między pracownikiem a zależnym na poniższym rysunku.

Jest to realizowane poprzez dołączenie listy osób na utrzymaniu do klasy Pracownik. Implementacja za pomocą kontenera listy C ++ STL -
class Employee {
private:
char * deptName;
list <Dependent> dep; //a list of Dependents as attribute
public:
void addDependent ( Dependent d) {
dep.push_back(d);
} // adds an employee to the department
void removeDeoendent( Dependent d) {
int index = find ( d, dep );
// find() function returns the index of d in list dep
dep.erase(index);
}
};Stowarzyszenia dwukierunkowe
Aby zaimplementować asocjację dwukierunkową, należy zachować połączenia w obu kierunkach.
Optional or one–to–one Associations - Rozważ relację między Projektem a Kierownikiem Projektu, która ma dwukierunkowe powiązanie jeden do jednego, jak pokazano na poniższym rysunku.

Implementacja w C ++ -
Class Project {
private:
// attributes
Project_Manager pmgr;
public:
void setManager ( Project_Manager pm);
Project_Manager changeManager();
};
class Project_Manager {
private:
// attributes
Project pj;
public:
void setProject(Project p);
Project removeProject();
};One–to–many Associations - Rozważ relację między działem a pracownikiem mającą związek jeden do wielu, jak pokazano na poniższym rysunku.

Implementacja z wykorzystaniem kontenera listy C ++ STL
class Department {
private:
char * deptName;
list <Employee> emp; //a list of Employees as attribute
public:
void addEmployee ( Employee e) {
emp.push_back(e);
} // adds an employee to the department
void removeEmployee( Employee e) {
int index = find ( e, emp );
// find function returns the index of e in list emp
emp.erase(index);
}
};
class Employee {
private:
//attributes
Department d;
public:
void addDept();
void removeDept();
};Wdrażanie asocjacji jako klas
Jeśli asocjacja ma powiązane atrybuty, powinna zostać zaimplementowana przy użyciu oddzielnej klasy. Na przykład rozważmy powiązanie jeden do jednego między pracownikiem a projektem, jak pokazano na poniższym rysunku.

Implementacja WorksOn w C ++
class WorksOn {
private:
Employee e;
Project p;
Hours h;
char * date;
public:
// class methods
};Wdrażanie ograniczeń
Ograniczenia w klasach ograniczają zakres i typ wartości, które mogą przyjmować atrybuty. Aby zaimplementować ograniczenia, do atrybutu przypisywana jest prawidłowa wartość domyślna, gdy obiekt jest tworzony z klasy. Za każdym razem, gdy wartość jest zmieniana w czasie wykonywania, sprawdzane jest, czy wartość jest prawidłowa, czy nie. Nieprawidłowa wartość może być obsługiwana przez procedurę obsługi wyjątków lub inne metody.
Example
Rozważmy klasę Employee, w której wiek jest atrybutem, który może mieć wartości z zakresu od 18 do 60. Zawiera ją poniższy kod C ++ -
class Employee {
private: char * name;
int age;
// other attributes
public:
Employee() { // default constructor
strcpy(name, "");
age = 18; // default value
}
class AgeError {}; // Exception class
void changeAge( int a) { // method that changes age
if ( a < 18 || a > 60 ) // check for invalid condition
throw AgeError(); // throw exception
age = a;
}
};Implementowanie wykresów stanu
Istnieją dwie alternatywne strategie implementacji stanów na diagramach wykresów stanów.
Wyliczenia w ramach klasy
W tym podejściu stany są reprezentowane przez różne wartości członka danych (lub zestawu członków danych). Wartości są jawnie definiowane przez wyliczenie w klasie. Przejścia są reprezentowane przez funkcje składowe, które zmieniają wartość danego elementu członkowskiego danych.
Układ klas w hierarchii uogólnień
W tym podejściu stany są ułożone w hierarchię uogólnień w sposób umożliwiający odniesienie do wspólnej zmiennej wskaźnikowej. Poniższy rysunek przedstawia transformację z diagramu wykresu stanu do hierarchii uogólnień.

Mapowanie obiektów do systemu baz danych
Trwałość obiektów
Ważnym aspektem tworzenia systemów obiektowych jest trwałość danych. Dzięki trwałości obiekty mają dłuższą żywotność niż program, który je utworzył. Trwałe dane są zapisywane na dodatkowym nośniku pamięci, skąd można je w razie potrzeby ponownie załadować.
Przegląd RDBMS
Baza danych to uporządkowany zbiór powiązanych danych.
System zarządzania bazą danych (DBMS) to zbiór oprogramowania, który ułatwia procesy definiowania, tworzenia, przechowywania, manipulowania, pobierania, udostępniania i usuwania danych w bazach danych.
W systemach zarządzania relacyjnymi bazami danych (RDBMS) dane są przechowywane jako relacje lub tabele, w których każda kolumna lub pole reprezentuje atrybut, a każdy wiersz lub krotka reprezentuje rekord instancji.
Każdy wiersz jest jednoznacznie identyfikowany przez wybrany zestaw minimalnych atrybutów o nazwie primary key.
ZA foreign key to atrybut będący kluczem podstawowym powiązanej tabeli.
Reprezentowanie klas jako tabel w RDBMS
Aby odwzorować klasę na tabelę bazy danych, każdy atrybut jest reprezentowany jako pole w tabeli. Istniejące atrybuty są przypisywane jako klucz podstawowy lub oddzielne pole identyfikatora jest dodawane jako klucz podstawowy. Klasa może być podzielona poziomo lub pionowo, zgodnie z wymaganiami.
Na przykład klasę Circle można przekonwertować na tabelę, jak pokazano na poniższym rysunku.

Schema for Circle Table: CIRCLE(CID, X_COORD, Y_COORD, RADIUS, COLOR)
Creating a Table Circle using SQL command:
CREATE TABLE CIRCLE (
CID VARCHAR2(4) PRIMARY KEY,
X_COORD INTEGER NOT NULL,
Y_COORD INTEGER NOT NULL,
Z_COORD INTEGER NOT NULL,
COLOR
);Mapowanie skojarzeń do tabel bazy danych
Skojarzenia jeden do jednego
Aby zaimplementować asocjacje 1: 1, klucz podstawowy dowolnej tabeli jest przypisywany jako klucz obcy drugiej tabeli. Weźmy na przykład pod uwagę związek między działem a kierownikiem -

Polecenia SQL do tworzenia tabel
CREATE TABLE DEPARTMENT (
DEPT_ID INTEGER PRIMARY KEY,
DNAME VARCHAR2(30) NOT NULL,
LOCATION VARCHAR2(20),
EMPID INTEGER REFERENCES MANAGER
);
CREATE TABLE MANAGER (
EMPID INTEGER PRIMARY KEY,
ENAME VARCHAR2(50) NOT NULL,
ADDRESS VARCHAR2(70),
);Skojarzenia typu jeden do wielu
Aby zaimplementować asocjacje 1: N, klucz podstawowy tabeli po stronie 1 asocjacji jest przypisywany jako klucz obcy tabeli po stronie N asocjacji. Weźmy na przykład pod uwagę związek między działem a pracownikiem -

Polecenia SQL do tworzenia tabel
CREATE TABLE DEPARTMENT (
DEPT_ID INTEGER PRIMARY KEY,
DNAME VARCHAR2(30) NOT NULL,
LOCATION VARCHAR2(20),
);
CREATE TABLE EMPLOYEE (
EMPID INTEGER PRIMARY KEY,
ENAME VARCHAR2(50) NOT NULL,
ADDRESS VARCHAR2(70),
D_ID INTEGER REFERENCES DEPARTMENT
);Stowarzyszenia wiele do wielu
Aby zaimplementować skojarzenia M: N, tworzona jest nowa relacja, która reprezentuje skojarzenie. Weźmy na przykład pod uwagę następujące powiązanie między pracownikiem a projektem -

Schema for Works_On Table - WORKS_ON (EMPID, PID, HOURS, START_DATE)
SQL command to create Works_On association - UTWÓRZ TABELĘ WORKS_ON
(
EMPID INTEGER,
PID INTEGER,
HOURS INTEGER,
START_DATE DATE,
PRIMARY KEY (EMPID, PID),
FOREIGN KEY (EMPID) REFERENCES EMPLOYEE,
FOREIGN KEY (PID) REFERENCES PROJECT
);Odwzorowanie dziedziczenia na tabele
Aby odwzorować dziedziczenie, klucz podstawowy tabel podstawowych jest przypisywany jako klucz podstawowy, a także klucz obcy w tabelach pochodnych.
Example

Po napisaniu kodu programu należy go przetestować, aby wykryć, a następnie obsłużyć wszystkie zawarte w nim błędy. Do celów testowych wykorzystywanych jest kilka schematów.
Innym ważnym aspektem jest zgodność celu programu, który sprawdza, czy program służy celowi, do którego jest przeznaczony. Sprawność określa jakość oprogramowania.
Testowanie systemów obiektowych
Testowanie to ciągła czynność podczas tworzenia oprogramowania. W systemach zorientowanych obiektowo testowanie obejmuje trzy poziomy, a mianowicie testowanie jednostkowe, testowanie podsystemu i testowanie systemu.
Testów jednostkowych
W testach jednostkowych testowane są poszczególne klasy. Widać, czy atrybuty klas są zaimplementowane zgodnie z projektem i czy metody i interfejsy są wolne od błędów. Za testowanie jednostkowe odpowiedzialny jest inżynier aplikacji, który wdraża strukturę.
Testowanie podsystemów
Obejmuje to testowanie określonego modułu lub podsystemu i jest obowiązkiem lidera podsystemu. Obejmuje testowanie powiązań w ramach podsystemu, a także interakcji podsystemu z otoczeniem. Testy podsystemu mogą służyć jako testy regresji dla każdej nowo wydanej wersji podsystemu.
Testowanie systemu
Testowanie systemu obejmuje testowanie systemu jako całości i jest obowiązkiem zespołu zapewnienia jakości. Zespół często używa testów systemowych jako testów regresyjnych podczas tworzenia nowych wersji.
Techniki testowania zorientowane obiektowo
Testowanie szarej skrzynki
Różne typy przypadków testowych, które można zaprojektować do testowania programów zorientowanych obiektowo, nazywane są przypadkami testowymi szarej skrzynki. Niektóre z ważnych typów testów szarych skrzynek to:
State model based testing - Obejmuje to pokrycie stanu, pokrycie zmiany stanu i pokrycie ścieżki przejścia między stanami.
Use case based testing - Każdy scenariusz w każdym przypadku użycia jest testowany.
Class diagram based testing - Każda klasa, klasa pochodna, asocjacje i agregacje są testowane.
Sequence diagram based testing - Testowane są metody zawarte w komunikatach na diagramach sekwencji.
Techniki testowania podsystemów
Dwa główne podejścia do testowania podsystemów to:
Thread based testing - Wszystkie klasy potrzebne do zrealizowania pojedynczego przypadku użycia w podsystemie są zintegrowane i przetestowane.
Use based testing- Testowane są interfejsy i usługi modułów na każdym poziomie hierarchii. Testowanie zaczyna się od pojedynczych klas do małych modułów składających się z klas, stopniowo do większych modułów, a na końcu do wszystkich głównych podsystemów.
Kategorie testowania systemów
Alpha testing - Jest to wykonywane przez zespół testowy w organizacji, która rozwija oprogramowanie.
Beta testing - Jest to realizowane przez wyselekcjonowaną grupę współpracujących klientów.
Acceptance testing - Jest to wykonywane przez klienta przed przyjęciem przedmiotu dostawy.
Certyfikat Jakości Oprogramowania
Jakość oprogramowania
Schulmeyer i McManus zdefiniowali jakość oprogramowania jako „przydatność całego produktu oprogramowania do użycia”. Dobrej jakości oprogramowanie robi dokładnie to, co powinno i jest interpretowane pod kątem spełnienia specyfikacji wymagań stawianych przez użytkownika.
Zapewnienie jakości
Zapewnianie jakości oprogramowania to metodologia określająca zakres, w jakim oprogramowanie nadaje się do użytku. Czynności uwzględnione w celu określenia jakości oprogramowania to:
- Auditing
- Opracowanie standardów i wytycznych
- Tworzenie raportów
- Przegląd systemu jakości
Czynniki jakości
Correctness - Poprawność określa, czy wymagania oprogramowania są odpowiednio spełnione.
Usability - Użyteczność określa, czy oprogramowanie może być używane przez różne kategorie użytkowników (początkujących, nietechnicznych i ekspertów).
Portability - Przenośność określa, czy oprogramowanie może działać na różnych platformach z różnymi urządzeniami sprzętowymi.
Maintainability - Łatwość konserwacji określa łatwość, z jaką błędy mogą być korygowane, a moduły mogą być aktualizowane.
Reusability - Możliwość ponownego użycia określa, czy moduły i klasy można ponownie wykorzystać do tworzenia innych produktów oprogramowania.
Metryki zorientowane obiektowo
Metryki można ogólnie podzielić na trzy kategorie: metryki projektu, metryki produktu i metryki procesu.
Metryki projektu
Metryki projektu umożliwiają kierownikowi projektu oprogramowania ocenę stanu i wydajności trwającego projektu. Następujące metryki są odpowiednie dla projektów oprogramowania zorientowanego obiektowo -
- Liczba skryptów scenariuszy
- Liczba klas kluczowych
- Liczba klas wsparcia
- Liczba podsystemów
Metryki produktu
Metryki produktu mierzą cechy oprogramowania, które zostało opracowane. Metryki produktu odpowiednie dla systemów zorientowanych obiektowo to -
Methods per Class- Określa złożoność klasy. Jeśli zakłada się, że wszystkie metody klasy są równie złożone, to klasa z większą liczbą metod jest bardziej złożona, a zatem bardziej podatna na błędy.
Inheritance Structure- Systemy z kilkoma małymi sieciami dziedziczenia mają lepszą strukturę niż systemy z pojedynczą dużą siatką dziedziczenia. Z reguły drzewo dziedziczenia nie powinno mieć więcej niż 7 (± 2) poziomów, a drzewo powinno być zrównoważone.
Coupling and Cohesion - Moduły o niskim sprzężeniu i dużej kohezji są uważane za lepiej zaprojektowane, ponieważ zapewniają większą możliwość ponownego użycia i łatwość konserwacji.
Response for a Class - Mierzy efektywność metod wywoływanych przez instancje klasy.
Metryki procesu
Metryki procesu pomagają mierzyć, jak przebiega proces. Są gromadzone we wszystkich projektach przez długi czas. Są używane jako wskaźniki długoterminowych ulepszeń procesów tworzenia oprogramowania. Niektóre metryki procesu to -
- Liczba KLOC (kilogramy linii kodu)
- Skuteczność usuwania wad
- Średnia liczba błędów wykrytych podczas testowania
- Liczba wad ukrytych na KLOC