Python zorientowany obiektowo - biblioteki
Żądania - moduł żądań języka Python
Requests to moduł Pythona, który jest elegancką i prostą biblioteką HTTP dla Pythona. Dzięki temu możesz wysyłać wszelkiego rodzaju żądania HTTP. Dzięki tej bibliotece możemy dodawać nagłówki, dane formularzy, pliki wieloczęściowe i parametry oraz uzyskiwać dostęp do danych odpowiedzi.
Ponieważ Requests nie jest wbudowanym modułem, musimy go najpierw zainstalować.
Możesz go zainstalować, uruchamiając następujące polecenie w terminalu -
pip install requestsPo zainstalowaniu modułu możesz sprawdzić, czy instalacja się powiodła, wpisując poniższe polecenie w powłoce Pythona.
import requestsJeśli instalacja przebiegła pomyślnie, nie zostanie wyświetlony żaden komunikat o błędzie.
Składanie żądania GET
Jako przykład użyjemy „pokeapi”
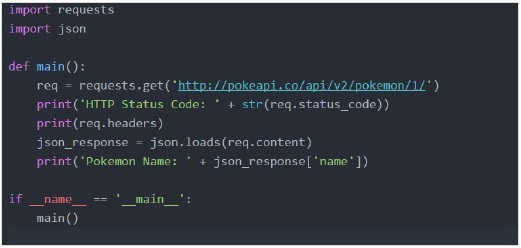
Wyjście -

Dokonywanie żądań POST
Metody biblioteki żądań dla wszystkich aktualnie używanych zleceń HTTP. Jeśli chcesz wykonać proste żądanie POST do punktu końcowego API, możesz to zrobić w ten sposób -
req = requests.post(‘http://api/user’, data = None, json = None)Działałoby to dokładnie w taki sam sposób, jak nasze poprzednie żądanie GET, jednak zawiera dwa dodatkowe parametry słów kluczowych -
dane, które mogą być wypełnione powiedzmy słownikiem, plikiem lub bajtami, które zostaną przekazane w treści HTTP naszego żądania POST.
json, który można wypełnić obiektem json, który również zostanie przekazany w treści naszego żądania HTTP.
Pandy: Pandy z biblioteki Pythona
Pandas to biblioteka Python o otwartym kodzie źródłowym, zapewniająca wydajne narzędzie do manipulacji i analizy danych przy użyciu potężnych struktur danych. Pandy to jedna z najczęściej używanych bibliotek Pythona w nauce o danych. Jest używany głównie do łączenia danych i nie bez powodu: potężna i elastyczna grupa funkcji.
Zbudowany na pakiecie Numpy, a kluczowa struktura danych nosi nazwę DataFrame. Te ramki danych pozwalają nam przechowywać i manipulować danymi tabelarycznymi w wierszach obserwacji i kolumnach zmiennych.
Istnieje kilka sposobów tworzenia ramki DataFrame. Jednym ze sposobów jest użycie słownika. Na przykład -
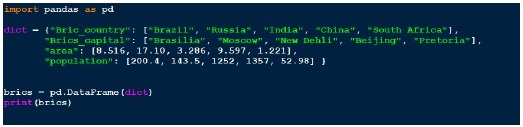
Wynik
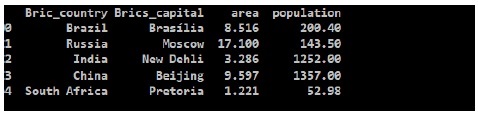
Z danych wyjściowych możemy zobaczyć nowe brics DataFrame, Pandas przypisał klucz dla każdego kraju jako wartości liczbowe od 0 do 4.
Jeśli zamiast podawać wartości indeksowania od 0 do 4, chcielibyśmy mieć różne wartości indeksu, powiedzmy dwuliterowy kod kraju, również możesz to łatwo zrobić -
Dodanie poniżej jednej linii w powyższym kodzie daje
brics.index = ['BR', 'RU', 'IN', 'CH', 'SA']
Wynik

Indeksowanie ramek danych
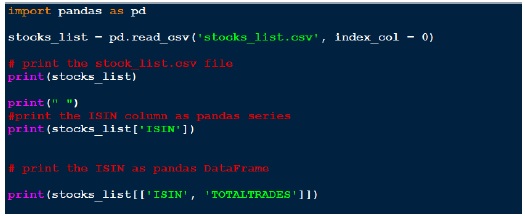
Wynik

Pygame
Pygame to biblioteka typu open source i wieloplatformowa służąca do tworzenia aplikacji multimedialnych, w tym gier. Zawiera biblioteki grafiki komputerowej i dźwięków przeznaczone do użytku z językiem programowania Python. W Pygame możesz stworzyć wiele fajnych gier ”.
Przegląd
Pygame składa się z różnych modułów, z których każdy zajmuje się określonym zestawem zadań. Na przykład moduł wyświetlania zajmuje się oknem wyświetlania i ekranem, moduł rysowania zapewnia funkcje do rysowania kształtów, a moduł klawiszy współpracuje z klawiaturą. To tylko niektóre z modułów biblioteki.
Dom biblioteki Pygame znajduje się pod adresem https://www.pygame.org/news
Aby stworzyć aplikację Pygame, wykonaj następujące kroki -
Zaimportuj bibliotekę Pygame
import pygameZainicjuj bibliotekę Pygame
pygame.init()Utwórz okno.
screen = Pygame.display.set_mode((560,480))
Pygame.display.set_caption(‘First Pygame Game’)Initialize game objects
Na tym etapie ładujemy obrazy, ładujemy dźwięki, ustawiamy obiekty, ustawiamy zmienne stanu itp.
Start the game loop.
To po prostu pętla, w której nieustannie obsługujemy zdarzenia, sprawdzamy dane wejściowe, przesuwamy obiekty i rysujemy je. Każda iteracja pętli nazywana jest ramką.
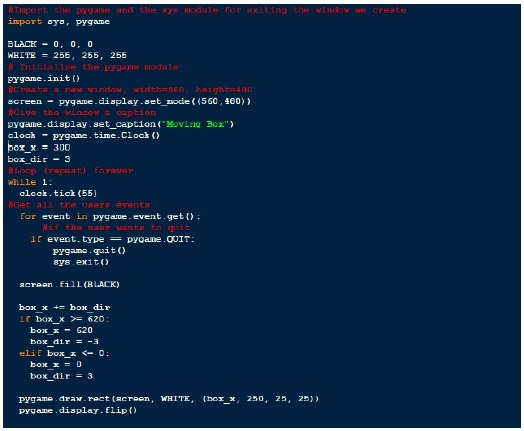
Umieśćmy całą powyższą logikę w jednym poniższym programie,
Pygame_script.py
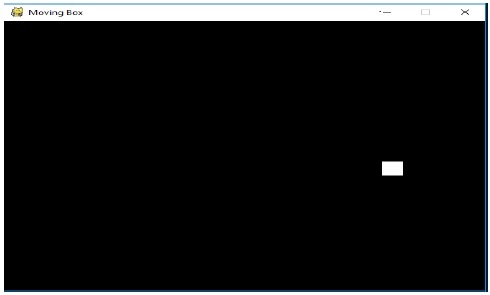
Wynik
Piękna zupa: skrobanie sieci z piękną zupą
Ogólną ideą skrobania sieci jest pobranie danych znajdujących się w witrynie internetowej i przekonwertowanie ich na format, który można wykorzystać do analizy.
Jest to biblioteka Pythona do pobierania danych z plików HTML lub XML. Wraz z twoim ulubionym parserem zapewnia idiomatyczne sposoby nawigacji, wyszukiwania i modyfikowania drzewa parsowania.
Ponieważ BeautifulSoup nie jest wbudowaną biblioteką, musimy ją zainstalować, zanim spróbujemy z niej skorzystać. Aby zainstalować BeautifulSoup, uruchom poniższe polecenie
$ apt-get install Python-bs4 # For Linux and Python2
$ apt-get install Python3-bs4 # for Linux based system and Python3.
$ easy_install beautifulsoup4 # For windows machine,
Or
$ pip instal beatifulsoup4 # For window machinePo zakończeniu instalacji jesteśmy gotowi do uruchomienia kilku przykładów i szczegółowego zbadania Beautifulsoup,
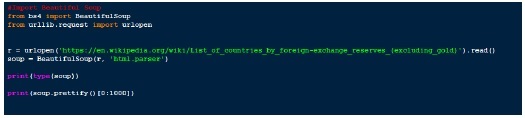
Wynik
Poniżej znajduje się kilka prostych sposobów poruszania się po tej strukturze danych -

Jednym z typowych zadań jest wyodrębnienie wszystkich adresów URL znalezionych w tagach <a> na stronie -

Innym typowym zadaniem jest wyodrębnienie całego tekstu ze strony -