Algorytmy planowania systemu operacyjnego
Harmonogram procesów planuje przypisanie różnych procesów do procesora w oparciu o określone algorytmy planowania. Istnieje sześć popularnych algorytmów planowania procesów, które omówimy w tym rozdziale -
- Planowanie „kto pierwszy, ten lepszy” (FCFS)
- Planowanie najkrótszego zadania-następnego (SJN)
- Planowanie priorytetowe
- Najkrótszy pozostały czas
- Planowanie okrężne (RR)
- Planowanie kolejek wielopoziomowych
Te algorytmy też są non-preemptive or preemptive. Algorytmy nie wywłaszczające są zaprojektowane w taki sposób, że gdy proces wejdzie w stan działania, nie można go wywłaszczyć, dopóki nie zakończy wyznaczonego czasu, podczas gdy planowanie z wywłaszczaniem jest oparte na priorytecie, w którym harmonogram może wywłaszczać działający proces o niskim priorytecie w dowolnym momencie, gdy ma wysoki priorytet proces przechodzi w stan gotowości.
Kto pierwszy, ten lepszy (FCFS)
- Zlecenia są wykonywane na zasadzie kto pierwszy, ten lepszy.
- Jest to nie wywłaszczający, wywodzący algorytm planowania.
- Łatwe do zrozumienia i wdrożenia.
- Jego realizacja oparta jest na kolejce FIFO.
- Słaba wydajność, ponieważ średni czas oczekiwania jest długi.
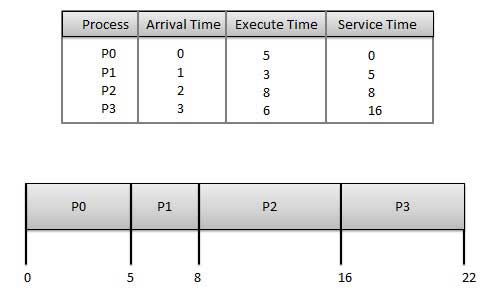
Wait time każdego procesu wygląda następująco -
| Proces | Czas oczekiwania: czas obsługi - czas przybycia |
|---|---|
| P0 | 0 - 0 = 0 |
| P1 | 5 - 1 = 4 |
| P2 | 8-2 = 6 |
| P3 | 16-3 = 13 |
Średni czas oczekiwania: (0 + 4 + 6 + 13) / 4 = 5,75
Najkrótsza następna praca (SJN)
Jest to również znane jako shortest job firstlub SJF
Jest to nie wywłaszczający, wywłaszczający algorytm planowania.
Najlepsze podejście, aby zminimalizować czas oczekiwania.
Łatwe do wdrożenia w systemach wsadowych, w których wymagany czas procesora jest znany z góry.
Niemożliwe do wdrożenia w systemach interaktywnych, gdzie wymagany czas procesora nie jest znany.
Podmiot przetwarzający powinien wiedzieć z wyprzedzeniem, ile czasu zajmie ten proces.
Dane: Tabela procesów i ich czas przybycia, czas wykonania
| Proces | Czas przybycia | Czas egzekucji | Czas naprawy |
|---|---|---|---|
| P0 | 0 | 5 | 0 |
| P1 | 1 | 3 | 5 |
| P2 | 2 | 8 | 14 |
| P3 | 3 | 6 | 8 |

Waiting time każdego procesu wygląda następująco -
| Proces | Czas oczekiwania |
|---|---|
| P0 | 0 - 0 = 0 |
| P1 | 5 - 1 = 4 |
| P2 | 14-2 = 12 |
| P3 | 8 - 3 = 5 |
Średni czas oczekiwania: (0 + 4 + 12 + 5) / 4 = 21/4 = 5,25
Planowanie oparte na priorytetach
Szeregowanie priorytetowe to algorytm bez wywłaszczania i jeden z najpowszechniejszych algorytmów planowania w systemach wsadowych.
Każdy proces ma przypisany priorytet. Proces o najwyższym priorytecie ma zostać wykonany jako pierwszy i tak dalej.
Procesy o tym samym priorytecie są wykonywane na zasadzie kto pierwszy, ten lepszy.
O priorytecie można decydować na podstawie wymagań dotyczących pamięci, wymagań czasowych lub innych wymagań dotyczących zasobów.
Biorąc pod uwagę: Tabela procesów i ich czas przybycia, czas wykonania i priorytet. Tutaj rozważamy, że 1 jest najniższym priorytetem.
| Proces | Czas przybycia | Czas egzekucji | Priorytet | Czas naprawy |
|---|---|---|---|---|
| P0 | 0 | 5 | 1 | 0 |
| P1 | 1 | 3 | 2 | 11 |
| P2 | 2 | 8 | 1 | 14 |
| P3 | 3 | 6 | 3 | 5 |

Waiting time każdego procesu wygląda następująco -
| Proces | Czas oczekiwania |
|---|---|
| P0 | 0 - 0 = 0 |
| P1 | 11 - 1 = 10 |
| P2 | 14-2 = 12 |
| P3 | 5 - 3 = 2 |
Średni czas oczekiwania: (0 + 10 + 12 + 2) / 4 = 24/4 = 6
Najkrótszy pozostały czas
Najkrótszy pozostały czas (SRT) to wywłaszczająca wersja algorytmu SJN.
Procesor jest przydzielany do zadania znajdującego się najbliżej ukończenia, ale może zostać wywłaszczone przez nowsze, gotowe zadanie z krótszym czasem do zakończenia.
Niemożliwe do wdrożenia w systemach interaktywnych, gdzie wymagany czas procesora nie jest znany.
Jest często używany w środowiskach wsadowych, w których pierwszeństwo mają krótkie prace.
Planowanie okrężne
Round Robin to zapobiegawczy algorytm szeregowania procesów.
Każdy proces ma ustalony czas na wykonanie, nazywany jest quantum.
Gdy proces jest wykonywany przez określony czas, jest wywłaszczany, a inny proces jest wykonywany przez określony czas.
Przełączanie kontekstu służy do zapisywania stanów wywłaszczonych procesów.
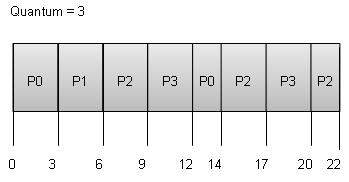
Wait time każdego procesu wygląda następująco -
| Proces | Czas oczekiwania: czas obsługi - czas przybycia |
|---|---|
| P0 | (0 - 0) + (12 - 3) = 9 |
| P1 | (3 - 1) = 2 |
| P2 | (6 - 2) + (14 - 9) + (20 - 17) = 12 |
| P3 | (9 - 3) + (17 - 12) = 11 |
Średni czas oczekiwania: (9 + 2 + 12 + 11) / 4 = 8,5
Planowanie kolejek wielopoziomowych
Kolejki wielopoziomowe nie są niezależnym algorytmem planowania. Korzystają z innych istniejących algorytmów do grupowania i planowania zadań o wspólnych cechach.
- Dla procesów o wspólnych cechach jest utrzymywanych wiele kolejek.
- Każda kolejka może mieć własne algorytmy planowania.
- Priorytety są przypisane do każdej kolejki.
Na przykład zadania związane z procesorem można zaplanować w jednej kolejce, a wszystkie zadania związane z we / wy w innej kolejce. Harmonogram procesów następnie na przemian wybiera zadania z każdej kolejki i przypisuje je do procesora na podstawie algorytmu przypisanego do kolejki.