System operacyjny - pamięć wirtualna
Komputer może adresować więcej pamięci niż ilość fizycznie zainstalowana w systemie. Ta dodatkowa pamięć jest faktycznie nazywanavirtual memory i jest to sekcja dysku twardego, która jest skonfigurowana do emulacji pamięci RAM komputera.
Główną widoczną zaletą tego schematu jest to, że programy mogą być większe niż pamięć fizyczna. Pamięć wirtualna służy dwóm celom. Po pierwsze, pozwala nam rozszerzyć wykorzystanie pamięci fizycznej za pomocą dysku. Po drugie, zapewnia nam ochronę pamięci, ponieważ każdy adres wirtualny jest tłumaczony na adres fizyczny.
Poniżej przedstawiono sytuacje, w których nie jest wymagane pełne załadowanie całego programu do pamięci głównej.
Procedury obsługi błędów napisane przez użytkownika są używane tylko wtedy, gdy wystąpił błąd w danych lub obliczeniach.
Niektóre opcje i funkcje programu mogą być używane rzadko.
Wiele tabel ma przypisaną stałą ilość przestrzeni adresowej, mimo że w rzeczywistości używana jest tylko niewielka część tabeli.
Możliwość wykonania programu, który jest tylko częściowo w pamięci, niweczy wiele korzyści.
Do załadowania lub zamiany każdego programu użytkownika w pamięci potrzebna byłaby mniejsza liczba operacji we / wy.
Program nie byłby już ograniczony ilością dostępnej pamięci fizycznej.
Każdy program użytkownika może zajmować mniej pamięci fizycznej, więcej programów może być uruchomionych w tym samym czasie, z odpowiednim wzrostem wykorzystania procesora i przepustowości.
W sprzęt wbudowane są nowoczesne mikroprocesory przeznaczone do użytku ogólnego, jednostka zarządzania pamięcią lub MMU. Zadaniem MMU jest tłumaczenie adresów wirtualnych na adresy fizyczne. Poniżej podano podstawowy przykład -
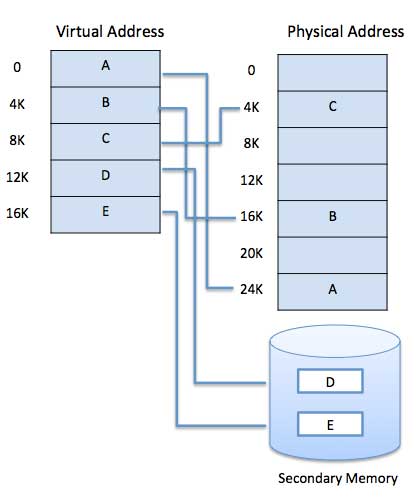
Pamięć wirtualna jest powszechnie implementowana przez stronicowanie na żądanie. Może być również wdrożony w systemie segmentacji. Segmentacja popytu może również służyć do udostępniania pamięci wirtualnej.
Paging na żądanie
System stronicowania na żądanie jest dość podobny do systemu stronicowania z wymianą, w którym procesy znajdują się w pamięci dodatkowej, a strony są ładowane tylko na żądanie, a nie z wyprzedzeniem. Kiedy następuje przełączenie kontekstu, system operacyjny nie kopiuje żadnej ze stron starego programu na dysk ani żadnej ze stron nowego programu do pamięci głównej. Zamiast tego po prostu rozpoczyna wykonywanie nowego programu po załadowaniu pierwszej strony i pobiera strony programu w postaci przywołania.
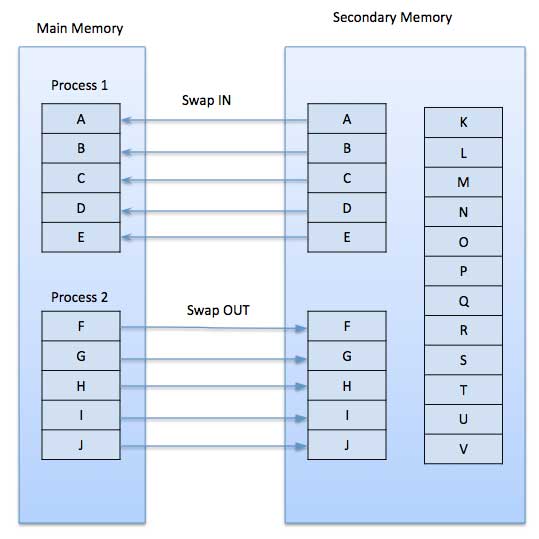
Podczas wykonywania programu, jeśli program odwołuje się do strony, która nie jest dostępna w pamięci głównej, ponieważ została niedawno wymieniona, procesor traktuje to nieprawidłowe odwołanie do pamięci jako page fault i przekazuje kontrolę z programu do systemu operacyjnego w celu zażądania powrotu strony do pamięci.
Zalety
Oto zalety stronicowania na żądanie -
- Duża pamięć wirtualna.
- Bardziej efektywne wykorzystanie pamięci.
- Nie ma ograniczeń co do stopnia wieloprogramowania.
Niedogodności
Liczba tabel i ilość narzutów procesora na obsługę przerwań stron są większe niż w przypadku prostych technik zarządzania stronicowaniem.
Algorytm zamiany stron
Algorytmy zastępowania stron to techniki, za pomocą których system operacyjny decyduje, które strony pamięci zamienić, zapisać na dysku, gdy trzeba przydzielić stronę pamięci. Stronicowanie ma miejsce za każdym razem, gdy wystąpi błąd strony, a bezpłatna strona nie może zostać użyta do rozliczenia celu alokacji, ponieważ strony są niedostępne lub liczba bezpłatnych stron jest mniejsza niż wymagana.
Kiedy strona, która została wybrana do zastąpienia i została wymieniona na stronie, jest ponownie przywoływana, musi zostać odczytana z dysku, co wymaga zakończenia operacji we / wy. Ten proces określa jakość algorytmu zastępowania stron: im krótszy czas oczekiwania na załadowania stron, tym lepszy algorytm.
Algorytm zastępowania stron analizuje ograniczone informacje o dostępie do stron dostarczanych przez sprzęt i próbuje wybrać, które strony powinny zostać zastąpione, aby zminimalizować całkowitą liczbę pominięć stron, jednocześnie równoważąc ją z kosztami podstawowej pamięci i czasem procesora algorytmu samo. Istnieje wiele różnych algorytmów zastępowania stron. Oceniamy algorytm, uruchamiając go na określonym ciągu odwołań do pamięci i obliczając liczbę błędów stronicowania,
Ciąg odniesienia
Ciąg odwołań do pamięci nazywany jest ciągiem referencyjnym. Ciągi referencyjne są generowane sztucznie lub przez śledzenie danego systemu i zapisywanie adresu każdego odwołania do pamięci. Ten ostatni wybór daje dużą liczbę danych, w których zauważamy dwie rzeczy.
Dla danego rozmiaru strony musimy brać pod uwagę tylko numer strony, a nie cały adres.
Jeśli mamy odniesienie do strony p, a następnie wszelkie bezpośrednio następujące odniesienia do strony pnigdy nie spowoduje błędu strony. Strona p będzie w pamięci po pierwszym odwołaniu; następujące bezpośrednio odniesienia nie będą obarczone błędem.
Weźmy na przykład pod uwagę następującą sekwencję adresów - 123,215,600,1234,76,96
Jeśli rozmiar strony wynosi 100, ciąg odniesienia to 1, 2, 6, 12, 0, 0
Algorytm FIFO (First In First Out)
Najstarsza strona w pamięci głównej to ta, która zostanie wybrana do wymiany.
Łatwy do wdrożenia, prowadź listę, zamień strony od ogona i dodaj nowe strony na czele.
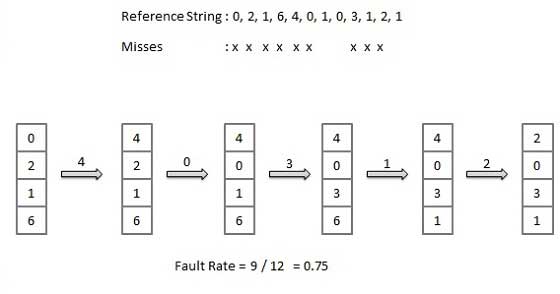
Optymalny algorytm strony
Optymalny algorytm zastępowania stron ma najniższy wskaźnik błędów stronicowania spośród wszystkich algorytmów. Istnieje optymalny algorytm zastępowania stron i został nazwany OPT lub MIN.
Zastąp stronę, która nie będzie używana przez najdłuższy czas. Wykorzystaj czas, kiedy strona ma być używana.

Algorytm najmniej ostatnio używany (LRU)
Strona, która najdłużej nie była używana w pamięci głównej, zostanie wybrana do wymiany.
Łatwość implementacji, prowadzenie listy, zastępowanie stron przez spoglądanie w przeszłość.

Algorytm buforowania strony
- Aby szybko rozpocząć proces, zachowaj pulę wolnych ramek.
- W przypadku błędu strony wybierz stronę do zastąpienia.
- Napisz nową stronę w ramce wolnej puli, zaznacz tabelę stron i zrestartuj proces.
- Teraz wypisz brudną stronę z dysku i umieść ramkę zawierającą zastąpioną stronę w wolnej puli.
Najrzadziej używany algorytm (LFU)
Strona o najmniejszej liczbie to ta, która zostanie wybrana do wymiany.
Ten algorytm cierpi z powodu sytuacji, w której strona jest intensywnie wykorzystywana w początkowej fazie procesu, ale potem nigdy nie jest używana ponownie.
Najczęściej używany algorytm (MFU)
Algorytm ten opiera się na argumencie, że strona o najmniejszej liczbie została prawdopodobnie właśnie pobrana i nie została jeszcze użyta.