Spring Batch - Szybki przewodnik
Batch processingjest trybem przetwarzania, który obejmuje wykonywanie serii zautomatyzowanych złożonych zadań bez interakcji z użytkownikiem. Proces wsadowy obsługuje dane zbiorcze i działa przez długi czas.
Kilka aplikacji korporacyjnych wymaga przetwarzania ogromnych danych w celu wykonywania operacji obejmujących:
Zdarzenia zależne od czasu, takie jak okresowe obliczenia.
Okresowe aplikacje, które są wielokrotnie przetwarzane na dużych zbiorach danych.
Aplikacje zajmujące się przetwarzaniem i walidacją danych dostępnych w drodze transakcyjnej.
Dlatego przetwarzanie wsadowe jest używane w aplikacjach korporacyjnych do wykonywania takich transakcji.
Co to jest Spring Batch
Partia wiosenna to lightweight framework który jest używany do rozwoju Batch Applications które są używane w aplikacjach korporacyjnych.
Oprócz przetwarzania zbiorczego ta struktura zapewnia funkcje:
- W tym rejestrowanie i śledzenie
- Zarządzanie transakcjami
- Statystyki przetwarzania pracy
- Ponowne uruchomienie zadania
- Pomiń i zarządzanie zasobami
Możesz także skalować aplikacje wsadowe sprężyn, używając technik porcjowania.
Cechy Spring Batch
Oto godne uwagi funkcje Spring Batch -
Flexibility- Aplikacje Spring Batch są elastyczne. Wystarczy zmienić plik XML, aby zmienić kolejność przetwarzania w aplikacji.
Maintainability- Aplikacje Spring Batch są łatwe w utrzymaniu. Zadanie Spring Batch obejmuje kroki, a każdy krok można odłączyć, przetestować i zaktualizować bez wpływu na pozostałe kroki.
Scalability- Korzystając z technik porcjowania, można skalować aplikacje Spring Batch. Te techniki pozwalają -
Wykonuj kroki zadania równolegle.
Wykonaj pojedynczy wątek równolegle.
Reliability - W przypadku awarii można ponownie uruchomić zadanie od miejsca, w którym zostało zatrzymane, oddzielając kroki.
Support for multiple file formats - Spring Batch zapewnia obsługę dużego zestawu czytników i pisarzy, takich jak XML, płaski plik, CSV, MYSQL, Hibernate, JDBC, Mongo, Neo4j itp.
Multiple ways to launch a job - Możesz uruchomić zadanie Spring Batch za pomocą aplikacji internetowych, programów Java, wiersza poleceń itp.
Oprócz tego aplikacje Spring Batch obsługują -
Automatyczne ponowienie po niepowodzeniu.
Status śledzenia i statystyki w trakcie realizacji partii i po zakończeniu przetwarzania partii.
Uruchamianie współbieżnych zadań.
Usługi, takie jak rejestrowanie, zarządzanie zasobami, pomijanie i ponowne uruchamianie przetwarzania.
W tym rozdziale wyjaśnimy, jak ustawić środowisko Spring Batch w Eclipse IDE. Przed przystąpieniem do instalacji upewnij się, że zainstalowałeś Eclipse w swoim systemie. Jeśli nie, pobierz i zainstaluj Eclipse w swoim systemie.
Więcej informacji na temat Eclipse można znaleźć w naszym samouczku dotyczącym środowiska Eclipse.
Ustawianie Spring Batch na Eclipse
Wykonaj poniższe czynności, aby ustawić środowisko Spring Batch na Eclipse.
Step 1 - Zainstaluj Eclipse i otwórz nowy projekt, jak pokazano na poniższym zrzucie ekranu.

Step 2 - Utwórz przykładowy projekt partii sprężyn, jak pokazano poniżej.
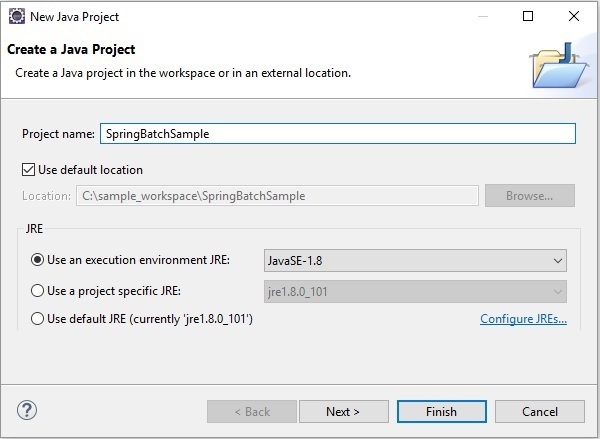
Step 3- Kliknij projekt prawym przyciskiem myszy i przekonwertuj go na projekt Maven, jak pokazano poniżej. Po przekształceniu go w projekt Maven da ci plikPom.xmlgdzie trzeba wspomnieć o wymaganych zależnościach. Następniejar ich pliki zostaną automatycznie pobrane do twojego projektu.

Step 4 - Teraz w pom.xml projektu skopiuj i wklej następującą zawartość (zależności dla aplikacji wsadowej wiosny) i odśwież projekt.
<project xmlns = "http://maven.apache.org/POM/4.0.0"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0
http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tutorialspoint</groupId>
<artifactId>SpringBatchSample</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>SpringBatchExample</name>
<url>http://maven.apache.org</url>
<properties>
<jdk.version>1.8</jdk.version>
<spring.version>4.3.8.RELEASE</spring.version>
<spring.batch.version>3.0.7.RELEASE</spring.batch.version>
<mysql.driver.version>5.1.25</mysql.driver.version>
<junit.version>4.11</junit.version>
</properties>
<dependencies>
<!-- Spring Core -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- Spring jdbc, for database -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- Spring XML to/back object -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-oxm</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- MySQL database driver -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.driver.version}</version>
</dependency>
<!-- Spring Batch dependencies -->
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-core</artifactId>
<version>${spring.batch.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-infrastructure</artifactId>
<version>${spring.batch.version}</version>
</dependency>
<!-- Spring Batch unit test -->
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<version>${spring.batch.version}</version>
</dependency>
<!-- Junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<finalName>spring-batch</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<version>2.9</version>
<configuration>
<downloadSources>true</downloadSources>
<downloadJavadocs>false</downloadJavadocs>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>${jdk.version}</source>
<target>${jdk.version}</target>
</configuration>
</plugin>
</plugins>
</build>
</project>Wreszcie, jeśli zaobserwujesz zależności Mavena, możesz zauważyć, że wszystkie wymagane jar pliki zostały pobrane.
Poniżej przedstawiono schematyczne przedstawienie architektury Spring Batch. Jak pokazano na rysunku, architektura zawiera trzy główne komponenty, a mianowicie:Application, Batch Core, i Batch Infrastructure.
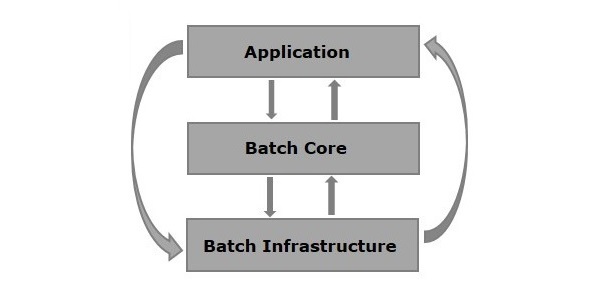
Application - Ten komponent zawiera wszystkie zadania i kod, który piszemy przy użyciu frameworka Spring Batch.
Batch Core - Ten komponent zawiera wszystkie klasy API, które są potrzebne do kontrolowania i uruchamiania zadania wsadowego.
Batch Infrastructure - Ten składnik zawiera czytniki, programy piszące i usługi używane zarówno przez aplikacje, jak i podstawowe składniki usługi Batch.
Składniki partii sprężyn
Poniższa ilustracja przedstawia różne komponenty Spring Batch i sposób ich połączenia.
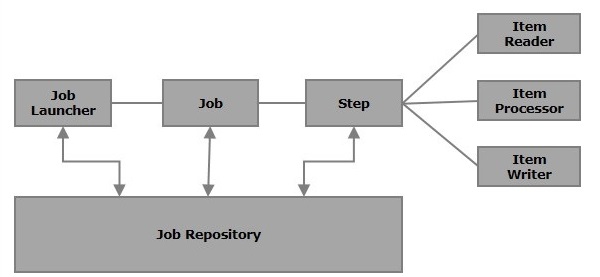
Praca
W aplikacji Spring Batch zadanie to proces wsadowy, który ma zostać wykonany. Działa od początku do końca bez przerwy. To zadanie jest dalej podzielone na etapy (lub zadanie zawiera kroki).
Skonfigurujemy zadanie w Spring Batch za pomocą pliku XML lub klasy Java. Poniżej przedstawiono konfigurację XML zadania w usłudze Spring Batch.
<job id = "jobid">
<step id = "step1" next = "step2"/>
<step id = "step2" next = "step3"/>
<step id = "step3"/>
</job>Zadanie wsadowe jest konfigurowane w tagach <job> </job>. Posiada atrybut o nazwieid. W ramach tych tagów definiujemy definicję i kolejność kroków.
Restartable - Ogólnie rzecz biorąc, gdy praca jest uruchomiona i próbujemy rozpocząć ją od nowa, jest to traktowane jako restarti zostanie ponownie uruchomiony. Aby tego uniknąć, musisz ustawićrestartable wartość do false jak pokazano niżej.
<job id = "jobid" restartable = "false" >
</job>Krok
ZA step to niezależna część zadania, która zawiera informacje niezbędne do zdefiniowania i wykonania zadania (jego część).
Jak określono na diagramie, każdy krok składa się z ItemReader, ItemProcessor (opcjonalnie) i ItemWriter. A job may contain one or more steps.
Czytelnicy, autorzy i procesorzy
Na item reader odczytuje dane do aplikacji Spring Batch z określonego źródła, podczas gdy plik item writer zapisuje dane z aplikacji Spring Batch do określonego miejsca docelowego.
Na Item processorto klasa zawierająca kod przetwarzający, który przetwarza dane wczytane do partii sprężynowej. Jeśli aplikacja czyta"n" rekordy, to kod w procesorze zostanie wykonany na każdym rekordzie.
Gdy nie podano czytelnika ani pisarza, a taskletdziała jako procesor dla SpringBatch. Przetwarza tylko jedno zadanie. Na przykład, jeśli piszemy zadanie z prostym krokiem, w którym czytamy dane z bazy danych MySQL, przetwarzamy je i zapisujemy do pliku (na płasko), to nasz krok używa -
ZA reader który czyta z bazy danych MySQL.
ZA writer który pisze do płaskiego pliku.
ZA custom processor który przetwarza dane zgodnie z naszym życzeniem.
<job id = "helloWorldJob">
<step id = "step1">
<tasklet>
<chunk reader = "mysqlReader" writer = "fileWriter"
processor = "CustomitemProcessor" ></chunk>
</tasklet>
</step>
</ job>Spring Batch zawiera długą listę plików readers i writers. Korzystając z tych predefiniowanych klas, możemy zdefiniować dla nich ziarna. Omówimyreaders i writers bardziej szczegółowo w kolejnych rozdziałach.
JobRepository
Repozytorium zadań w Spring Batch zapewnia operacje tworzenia, pobierania, aktualizowania i usuwania (CRUD) dla implementacji JobLauncher, Job i Step. Zdefiniujemy repozytorium zadań w pliku XML, jak pokazano poniżej.
<job-repository id = "jobRepository"/>Oprócz id, dostępnych jest więcej opcji (opcjonalnie). Poniżej przedstawiono konfigurację repozytorium zadań ze wszystkimi opcjami i ich wartościami domyślnymi.
<job-repository id = "jobRepository"
data-source = "dataSource"
transaction-manager = "transactionManager"
isolation-level-for-create = "SERIALIZABLE"
table-prefix = "BATCH_"
max-varchar-length = "1000"/>In-Memory Repository - W przypadku, gdy nie chcesz utrwalać obiektów domeny Spring Batch w bazie danych, możesz skonfigurować wersję jobRepository w pamięci, jak pokazano poniżej.
<bean id = "jobRepository"
class = "org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean ">
<property name = "transactionManager" ref = "transactionManager"/>
</bean>JobLauncher
JobLauncher to interfejs, który uruchamia zadanie Spring Batch z rozszerzeniem given set of parameters. SampleJoblauncher to klasa, która implementuje JobLauncherberło. Poniżej przedstawiono konfigurację JobLauncher.
<bean id = "jobLauncher"
class = "org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name = "jobRepository" ref = "jobRepository" />
</bean>JobInstance
ZA JobInstancereprezentuje logiczne wykonanie zadania; powstaje, gdy wykonujemy pracę. Każda instancja zadania różni się nazwą zadania i parametrami przekazanymi do niego podczas działania.
Jeśli wykonanie JobInstance nie powiedzie się, ta sama JobInstance może zostać wykonana ponownie. W związku z tym każda JobInstance może mieć wiele wykonań zadań.
JobExecution i StepExecution
JobExecution i StepExecution są reprezentacją wykonania zadania / kroku. Zawierają informacje o przebiegu zadania / kroku, takie jak czas rozpoczęcia (zadania / kroku), czas zakończenia (zadania / kroku).
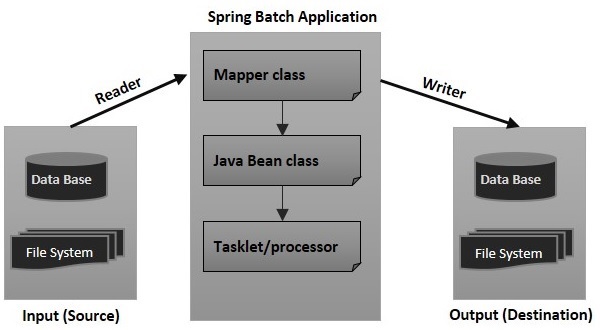
Prawie wszystkie przykłady w tym samouczku zawierają następujące pliki -
- Plik konfiguracyjny (plik XML)
- Tasklet / Processor (klasa Java)
- Klasa Java z ustawieniami i pobierającymi (klasa Java (bean))
- Klasa Mapper (klasa Java)
- Klasa uruchamiająca (klasa Java)
Plik konfiguracyjny
Plik konfiguracyjny (XML) zawiera następujące elementy -
Plik job i step definicje.
Fasola definiująca readers i writers.
Definicja komponentów, takich jak JobLauncher, JobRepository, Transaction Manager i Data Source.
W naszych przykładach, dla lepszego zrozumienia, podzieliliśmy to na dwa pliki job.xml plik (definiuje zadanie, krok, czytnik i pisarz) i context.xml plik (program uruchamiający zadania, repozytorium zadań, menedżer transakcji i źródło danych).
Mapper Class
Klasa Mapper, w zależności od czytnika, implementuje interfejsy, takie jak row mapper, field set mapper, itp. Zawiera kod, aby pobrać dane z czytnika i ustawić je na klasę Java za pomocą setter i getter metody (Java Bean).
Klasa Java Bean
Klasa Java z setters i getters(Java bean) reprezentuje dane z wieloma wartościami. Działa jako klasa pomocnicza. Przekażemy dane z jednego komponentu (czytnika, pisarza, procesora) do drugiego w postaci obiektu tej klasy.
Tasklet / procesor
Klasa Tasklet / Processor zawiera kod przetwarzania aplikacji Spring Batch. Procesor to klasa, która przyjmuje obiekt zawierający odczytane dane, przetwarza je i zwraca przetworzone dane (w postaci obiektu formularza).
Klasa programu uruchamiającego
Ta klasa (App.java) zawiera kod do uruchamiania aplikacji Spring Batch.
Pisząc aplikację Spring Batch, skonfigurujemy zadanie, krok, JobLauncher, JobRepository, Transaction Manager, czytelników i pisarzy za pomocą tagów XML dostarczonych w przestrzeni nazw Spring Batch. Dlatego musisz uwzględnić tę przestrzeń nazw w swoim pliku XML, jak pokazano poniżej.
<beans xmlns = "http://www.springframework.org/schema/beans"
xmlns:batch = "http://www.springframework.org/schema/batch"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.2.xsd
http://www.springframework.org/schema/bean
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd">W kolejnych sekcjach omówimy różne tagi, ich atrybuty i przykłady, dostępne w przestrzeni nazw Spring Batch.
Praca
Ten tag służy do definiowania / konfigurowania zadania SpringBatch. Zawiera zestaw kroków i można go uruchomić za pomocą JobLauncher.
Ten tag ma 2 atrybuty wymienione poniżej -
| S.Nr | Atrybut i opis |
|---|---|
| 1 | Id Jest to identyfikator zlecenia, podanie wartości tego atrybutu jest obowiązkowe. |
| 2 | restartable Jest to atrybut używany do określenia, czy zadanie można zrestartować, czy nie. Ten atrybut jest opcjonalny. |
Poniżej znajduje się konfiguracja XML zadania SpringBatch.
<job id = "jobid" restartable = "false" >
. . . . . . . .
. . . . . . . .
. . . . . . . . // Step definitions
</job>Krok
Ten tag służy do definiowania / konfigurowania kroków zadania SpringBatch. Ma następujące trzy atrybuty -
| S.Nr | Atrybut i opis |
|---|---|
| 1 | Id Jest to identyfikator zlecenia, podanie wartości tego atrybutu jest obowiązkowe. |
| 2 | next Jest to skrót do określenia następnego kroku. |
| 3 | parent Służy do określenia nazwy nadrzędnego komponentu bean, z którego powinna dziedziczyć konfiguracja. |
Poniżej znajduje się konfiguracja XML kroku w SpringBatch.
<job id = "jobid">
<step id = "step1" next = "step2"/>
<step id = "step2" next = "step3"/>
<step id = "step3"/>
</job>Kawałek
Ten tag służy do definiowania / konfigurowania fragmentu pliku tasklet. Ma następujące cztery atrybuty -
| S.Nr | Atrybut i opis |
|---|---|
| 1 | reader Reprezentuje nazwę fasoli czytnika elementu. Przyjmuje wartość typuorg.springframework.batch.item.ItemReader. |
| 2 | writer Reprezentuje nazwę fasoli czytnika elementu. Przyjmuje wartość typuorg.springframework.batch.item.ItemWriter. |
| 3 | processor Reprezentuje nazwę fasoli czytnika elementu. Przyjmuje wartość typuorg.springframework.batch.item.ItemProcessor. |
| 4 | commit-interval Służy do określenia liczby pozycji do przetworzenia przed dokonaniem transakcji. |
Poniżej znajduje się konfiguracja XML fragmentu SpringBatch.
<batch:step id = "step1">
<batch:tasklet>
<batch:chunk reader = "xmlItemReader"
writer = "mysqlItemWriter" processor = "itemProcessor" commit-interval = "10">
</batch:chunk>
</batch:tasklet>
</batch:step>JobRepository
Fasola JobRepository jest używana do konfigurowania JobRepository przy użyciu relacyjnej bazy danych. Ta fasola jest powiązana z klasą typuorg.springframework.batch.core.repository.JobRepository.
| S.Nr | Atrybut i opis |
|---|---|
| 1 | dataSource Służy do określenia nazwy fasoli, która definiuje źródło danych. |
| 2 | transactionManager Służy do określenia nazwy fasoli, która definiuje menedżera transakcji. |
| 3 | databaseType Określa typ relacyjnej bazy danych używanej w repozytorium zadań. |
Poniżej znajduje się przykładowa konfiguracja JobRepository.
<bean id = "jobRepository"
class = "org.springframework.batch.core.repository.support.JobRepositoryFactoryBean">
<property name = "dataSource" ref = "dataSource" />
<property name = "transactionManager" ref="transactionManager" />
<property name = "databaseType" value = "mysql" />
</bean>JobLauncher
Komponent bean JobLauncher służy do konfigurowania JobLauncher. Jest to związane z klasąorg.springframework.batch.core.launch.support.SimpleJobLauncher(w naszych programach). Ta fasola ma jedną właściwość o nazwiejobrepository, i służy do określenia nazwy ziarna, które definiuje jobrepository.
Poniżej znajduje się przykładowa konfiguracja jobLauncher.
<bean id = "jobLauncher"
class = "org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name = "jobRepository" ref = "jobRepository" />
</bean>TransactionManager
Komponent bean TransactionManager służy do konfigurowania menedżera transakcji przy użyciu relacyjnej bazy danych. Ta fasola jest powiązana z klasą typuorg.springframework.transaction.platform.TransactionManager.
<bean id = "transactionManager"
class = "org.springframework.batch.support.transaction.ResourcelessTransactionManager" />Źródło danych
Komponent bean źródła danych służy do konfigurowania Datasource. Ta fasola jest powiązana z klasą typuorg.springframework.jdbc.datasource.DriverManagerDataSource.
| S.Nr | Atrybut i opis |
|---|---|
| 1 | driverClassName Określa nazwę klasy sterownika używanego do łączenia się z bazą danych. |
| 2 | url Określa adres URL bazy danych. |
| 3 | username Określa nazwę użytkownika do połączenia z bazą danych. |
| 4 | password Określa hasło do połączenia z bazą danych. |
Poniżej znajduje się przykładowa konfiguracja datasource.
<bean id = "dataSource"
class = "org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name = "driverClassName" value = "com.mysql.jdbc.Driver" />
<property name = "url" value = "jdbc:mysql://localhost:3306/details" />
<property name = "username" value = "myuser" />
<property name = "password" value = "password" />
</bean>Na Item Reader odczytuje dane do aplikacji wsadowej sprężyny z określonego źródła, podczas gdy plik Item Writer zapisuje dane z aplikacji Spring Batch do określonego miejsca docelowego.
Na Item processorto klasa zawierająca kod przetwarzający, który przetwarza dane wczytane do partii sprężyn. Jeśli aplikacja odczyta n rekordów, kod w procesorze zostanie wykonany na każdym rekordzie.
ZA chunk jest elementem podrzędnym tasklet. Służy do wykonywania operacji odczytu, zapisu i przetwarzania. Możemy skonfigurować czytnik, program zapisujący i procesory za pomocą tego elementu, w ramach kroku, jak pokazano poniżej.
<batch:job id = "helloWorldJob">
<batch:step id = "step1">
<batch:tasklet>
<batch:chunk reader = "cvsFileItemReader" writer = "xmlItemWriter"
processor = "itemProcessor" commit-interval = "10">
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>Spring Batch zapewnia czytelnikom i pisarzom możliwość odczytu i zapisu danych z różnych systemów plików / baz danych, takich jak MongoDB, Neo4j, MySQL, XML, flatfile, CSV itp.
Aby dołączyć czytnik do swojej aplikacji, musisz zdefiniować komponent bean dla tego czytnika, podać wartości dla wszystkich wymaganych właściwości w tym komponencie i przekazać id takiej fasoli jako wartość atrybutu elementu chunk reader (to samo dla writer).
ItemReader
Jest to jednostka kroku (procesu wsadowego), który odczytuje dane. ItemReader czyta jeden element na raz. Spring Batch zapewnia interfejsItemReader. Wszystkiereaders wdrożyć ten interfejs.
Poniżej przedstawiono niektóre z predefiniowanych klas ItemReader udostępnionych przez Spring Batch do odczytu z różnych źródeł.
| Czytelnik | Cel, powód |
|---|---|
| FlatFIleItemReader | Do odczytu danych z plików płaskich. |
| StaxEventItemReader | Aby odczytać dane z plików XML. |
| StoredProcedureItemReader | Aby odczytać dane z procedur składowanych bazy danych. |
| JDBCPagingItemReader | Odczytywanie danych z relacyjnych baz danych. |
| MongoItemReader | Aby odczytać dane z MongoDB. |
| Neo4jItemReader | Aby odczytać dane z Neo4jItemReader. |
Musimy skonfigurować ItemReaderstworząc fasolę. Poniżej znajduje się przykładStaxEventItemReader który czyta dane z pliku XML.
<bean id = "mysqlItemWriter"
class = "org.springframework.batch.item.xml.StaxEventItemWriter">
<property name = "resource" value = "file:xml/outputs/userss.xml" />
<property name = "marshaller" ref = "reportMarshaller" />
<property name = "rootTagName" value = "Tutorial" />
</bean>
<bean id = "reportMarshaller"
class = "org.springframework.oxm.jaxb.Jaxb2Marshaller">
<property name = "classesToBeBound">
<list>
<value>Tutorial</value>
</list>
</property>
</bean>Jak zaobserwowano, podczas konfigurowania musimy określić odpowiednią nazwę klasy wymaganego czytnika i musimy podać wartości dla wszystkich wymaganych właściwości.
ItemWriter
Jest to element stepprocesu wsadowego, który zapisuje dane. ItemWriter zapisuje jeden element na raz. Spring Batch zapewnia interfejsItemWriter. Wszyscy autorzy implementują ten interfejs.
Poniżej przedstawiono niektóre z predefiniowanych klas ItemWriter udostępnianych przez Spring Batch do odczytu z różnych źródeł.
| Pisarz | Cel, powód |
|---|---|
| FlatFIleItemWriter | Zapisywanie danych do plików płaskich. |
| StaxEventItemWriter | Zapisywanie danych w plikach XML. |
| StoredProcedureItemWriter | Zapisywanie danych w procedurach składowanych bazy danych. |
| JDBCPagingItemWriter | Zapisywanie danych w relacyjnych bazach danych. |
| MongoItemWriter | Zapisywanie danych w MongoDB. |
| Neo4jItemWriter | Zapisywanie danych w Neo4j. |
W ten sam sposób musimy skonfigurować ItemWriters, tworząc komponenty bean. Poniżej znajduje się przykładJdbcCursorItemReader który zapisuje dane w bazie danych MySQL.
<bean id = "dbItemReader"
class = "org.springframework.batch.item.database.JdbcCursorItemReader" scope = "step">
<property name = "dataSource" ref = "dataSource" />
<property name = "sql" value = "select * from tutorialsdata" />
<property name = "rowMapper">
<bean class = "TutorialRowMapper" />
</property>
</bean>Procesor pozycji
ItemProcessor: Do przetwarzania danych używany jest ItemProcessor. Gdy podany przedmiot jest nieprawidłowy, zwracanull, w przeciwnym razie przetwarza dany element i zwraca przetworzony wynik. InterfejsItemProcessor<I,O> reprezentuje procesor.
Tasklet class - Kiedy nie reader i writersą podane, Tasklet działa jako procesor dla SpringBatch. Przetwarza tylko jedno zadanie.
Możemy zdefiniować niestandardowy procesor elementów, implementując interfejs ItemProcessor pakietu org.springframework.batch.item.ItemProcessor. Ta klasa ItemProcessor przyjmuje obiekt i przetwarza dane oraz zwraca przetworzone dane jako inny obiekt.
Jeśli w procesie wsadowym "n"rekordy lub elementy danych są odczytywane, a następnie dla każdego rekordu odczytuje dane, przetwarza je i zapisuje dane w programie zapisującym. Aby przetworzyć dane, przekazuje dane procesora.
Na przykład załóżmy, że napisałeś kod, aby załadować określony dokument PDF, utworzyć nową stronę, zapisać element danych do pliku PDF w formacie tabelarycznym. Jeśli uruchomisz tę aplikację, odczytuje ona wszystkie elementy danych z dokumentu XML, przechowuje je w bazie danych MySQL i drukuje je w danym dokumencie PDF na poszczególnych stronach.
Przykład
Poniżej znajduje się przykładowa klasa ItemProcessor.
import org.springframework.batch.item.ItemProcessor;
public class CustomItemProcessor implements ItemProcessor<Tutorial, Tutorial> {
@Override
public Tutorial process(Tutorial item) throws Exception {
System.out.println("Processing..." + item);
return item;
}
}Ten rozdział przedstawia podstawową aplikację Spring Batch. Po prostu wykona pliktasklet wyświetla komunikat.
Nasza aplikacja Spring Batch zawiera następujące pliki -
Configuration file- To jest plik XML, w którym definiujemy zadanie i etapy zadania. (Jeśli aplikacja obejmuje również czytelników i pisarzy, konfiguracjareaders i writers jest również zawarty w tym pliku).
Context.xml - W tym pliku zdefiniujemy komponenty bean, takie jak repozytorium zadań, program uruchamiający zadania i menedżer transakcji.
Tasklet class - W tej klasie napiszemy zadanie przetwarzania kodu (w tym przypadku wyświetla prosty komunikat)
Launcher class - w tej klasie uruchomimy aplikację Batch poprzez uruchomienie programu uruchamiającego zadanie.
jobConfig.xml
Poniżej znajduje się plik konfiguracyjny naszej przykładowej aplikacji Spring Batch.
<beans xmlns = "http://www.springframework.org/schema/beans"
xmlns:batch = "http://www.springframework.org/schema/batch"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.2.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd ">
<import resource="context.xml" />
<!-- Defining a bean -->
<bean id = "tasklet" class = "a_sample.MyTasklet" />
<!-- Defining a job-->
<batch:job id = "helloWorldJob">
<!-- Defining a Step -->
<batch:step id = "step1">
<tasklet ref = "tasklet"/>
</batch:step>
</batch:job>
</beans>Context.xml
Poniżej znajduje się context.xml naszej aplikacji Spring Batch.
<beans xmlns = "http://www.springframework.org/schema/beans"
xmlns:xsi = http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd">
<bean id = "jobRepository"
class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean">
<property name = "transactionManager" ref = "transactionManager" />
</bean>
<bean id = "transactionManager"
class = "org.springframework.batch.support.transaction.ResourcelessTransactionManager" />
<bean id = "jobLauncher"
class = "org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name = "jobRepository" ref = "jobRepository" />
</bean>
</beans>Tasklet.java
Poniżej znajduje się klasa Tasklet, która wyświetla prosty komunikat.
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
public class MyTasklet implements Tasklet {
@Override
public RepeatStatus execute(StepContribution arg0, ChunkContext arg1) throws Exception {
System.out.println("Hello This is a sample example of spring batch");
return RepeatStatus.FINISHED;
}
}App.java
Poniżej znajduje się kod uruchamiający proces wsadowy.
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class App {
public static void main(String[] args)throws Exception {
// System.out.println("hello");
String[] springConfig = {"a_sample/job_hello_world.xml"};
// Creating the application context object
ApplicationContext context = new ClassPathXmlApplicationContext(springConfig);
// Creating the job launcher
JobLauncher jobLauncher = (JobLauncher) context.getBean("jobLauncher");
// Creating the job
Job job = (Job) context.getBean("helloWorldJob");
// Executing the JOB
JobExecution execution = jobLauncher.run(job, new JobParameters());
System.out.println("Exit Status : " + execution.getStatus());
}
}Podczas wykonywania powyższego programu SpringBatch wygeneruje następujący wynik -
Apr 24, 2017 4:40:54 PM org.springframework.context.support.AbstractApplicationContext prepareRefresh
INFO:Refreshing org.springframework.context.support.ClassPathXmlApplicationContext@2ef1e4fa: startup date [Mon Apr 24 16:40:54 IST 2017]; root of context hierarchy
Apr 24, 2017 4:40:54 PM org.springframework.beans.factory.xml.XmlBeanDefinitionReader loadBeanDefinitions INFO: Loading XML bean definitions
Apr 24, 2017 4:40:54 PM org.springframework.beans.factory.xml.XmlBeanDefinitionReader loadBeanDefinitions
INFO: Loading XML bean definitions
Apr 24, 2017 4:40:54 PM org.springframework.beans.factory.support.DefaultListableBeanFactory preInstantiateSingletons
Apr 24, 2017 4:40:55 PM org.springframework.batch.core.launch.support.SimpleJobLauncher afterPropertiesSet
INFO: No TaskExecutor has been set, defaulting to synchronous executor.
Apr 24, 2017 4:40:55 PM org.springframework.batch.core.launch.support.SimpleJobLauncher$1 run
INFO: Job: [FlowJob: [name=helloWorldJob]] launched with the following parameters: [{}]
Apr 24, 2017 4:40:55 PM org.springframework.batch.core.job.SimpleStepHandler handleStep INFO: Executing step: [step1]
Hello This is a sample example of spring batch
Apr 24, 2017 4:40:55 PM org.springframework.batch.core.launch.support.SimpleJobLauncher$1 run
INFO: Job: [FlowJob: [name=helloWorldJob]] completed with the following parameters: [{}] and the following status: [COMPLETED]
Exit Status : COMPLETEDW tym rozdziale stworzymy aplikację Spring Batch, która korzysta z czytnika XML i pisarza MySQL.
Reader - Czytnik, którego używamy w aplikacji, to StaxEventItemReader do odczytu danych z dokumentów XML.
Poniżej znajduje się wejściowy dokument XML, którego używamy w tej aplikacji. Ten dokument zawiera rekordy danych, które określają szczegóły, takie jak identyfikator samouczka, jego autor, tytuł samouczka, data przesłania, ikona samouczka i opis samouczka.
<?xml version="1.0" encoding="UTF-8"?>
<tutorials>
<tutorial>
<tutorial_id>1001</tutorial_id>
<tutorial_author>Sanjay</tutorial_author>
<tutorial_title>Learn Java</tutorial_title>
<submission_date>06-05-2007</submission_date>
<tutorial_icon>https://www.tutorialspoint.com/java/images/java-minilogo.jpg</tutorial_icon>
<tutorial_description>Java is a high-level programming language originally
developed by Sun Microsystems and released in 1995.
Java runs on a variety of platforms.
This tutorial gives a complete understanding of Java.');</tutorial_description>
</tutorial>
<tutorial>
<tutorial_id>1002</tutorial_id>
<tutorial_author>Abdul S</tutorial_author>
<tutorial_title>Learn MySQL</tutorial_title>
<submission_date>19-04-2007</submission_date>
<tutorial_icon>https://www.tutorialspoint.com/mysql/images/mysql-minilogo.jpg</tutorial_icon>
<tutorial_description>MySQL is the most popular
Open Source Relational SQL database management system.
MySQL is one of the best RDBMS being used for developing web-based software applications.
This tutorial will give you quick start with MySQL
and make you comfortable with MySQL programming.</tutorial_description>
</tutorial>
<tutorial>
<tutorial_id>1003</tutorial_id>
<tutorial_author>Krishna Kasyap</tutorial_author>
<tutorial_title>Learn JavaFX</tutorial_title>
<submission_date>06-07-2017</submission_date>
<tutorial_icon>https://www.tutorialspoint.com/javafx/images/javafx-minilogo.jpg</tutorial_icon>
<tutorial_description>JavaFX is a Java library used to build Rich Internet Applications.
The applications developed using JavaFX can run on various devices
such as Desktop Computers, Mobile Phones, TVs, Tablets, etc.
This tutorial, discusses all the necessary elements of JavaFX that are required
to develop effective Rich Internet Applications</tutorial_description>
</tutorial>
</tutorials>Writer - The writer używamy w aplikacji JdbcBatchItemWriterzapisywanie danych do bazy danych MySQL. Załóżmy, że utworzyliśmy tabelę w MySQL wewnątrz bazy danych o nazwie"details".
CREATE TABLE details.TUTORIALS(
tutorial_id int(10) NOT NULL,
tutorial_author VARCHAR(20),
tutorial_title VARCHAR(50),
submission_date VARCHAR(20),
tutorial_icon VARCHAR(200),
tutorial_description VARCHAR(1000)
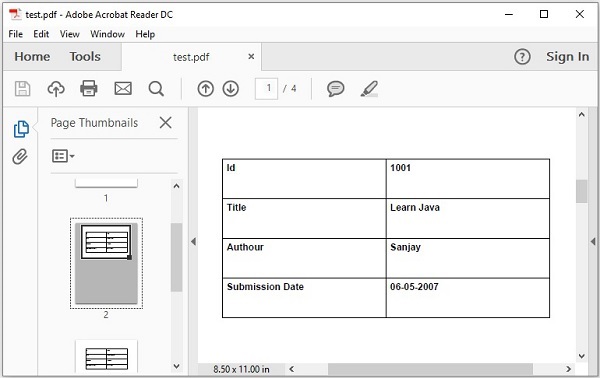
);Processor - Procesor, którego używamy w aplikacji, to niestandardowy procesor, który zapisuje dane każdego rekordu w dokumencie PDF.
W procesie wsadowym, jeśli "n"rekordy lub elementy danych zostały odczytane, a następnie dla każdego rekordu odczyta dane, przetworzy je i zapisze dane w programie Writer. Aby przetworzyć dane, przekazuje dane procesorowi. W tym przypadku w klasie niestandardowych procesorów napisaliśmy kod, aby załadować określony dokument PDF, utworzyć nową stronę, zapisać element danych do pliku PDF w formacie tabelarycznym.
Wreszcie, jeśli uruchomisz tę aplikację, odczytuje ona wszystkie elementy danych z dokumentu XML, przechowuje je w bazie danych MySQL i drukuje je w danym dokumencie PDF na poszczególnych stronach.
jobConfig.xml
Poniżej znajduje się plik konfiguracyjny naszej przykładowej aplikacji Spring Batch. W tym pliku zdefiniujemy zadanie i kroki. Oprócz tego definiujemy również komponenty bean dla ItemReader, ItemProcessor i ItemWriter. (Tutaj kojarzymy je z odpowiednimi klasami i przekazujemy wartości wymaganych właściwości, aby je skonfigurować).
<beans xmlns = "http://www.springframework.org/schema/beans"
xmlns:batch = "http://www.springframework.org/schema/batch"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xmlns:util = "http://www.springframework.org/schema/util"
xsi:schemaLocation = "http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.2.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util-3.0.xsd ">
<import resource = "../jobs/context.xml" />
<bean id = "itemProcessor" class = "CustomItemProcessor" />
<batch:job id = "helloWorldJob">
<batch:step id = "step1">
<batch:tasklet>
<batch:chunk reader = "xmlItemReader" writer = "mysqlItemWriter" processor = "itemProcessor">
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>
<bean id = "xmlItemReader"
class = "org.springframework.batch.item.xml.StaxEventItemReader">
<property name = "fragmentRootElementName" value = "tutorial" />
<property name = "resource" value = "classpath:resources/tutorial.xml" />
<property name = "unmarshaller" ref = "customUnMarshaller" />
</bean>
<bean id = "customUnMarshaller" class = "org.springframework.oxm.xstream.XStreamMarshaller">
<property name = "aliases">
<util:map id = "aliases">
<entry key = "tutorial" value = "Tutorial" />
</util:map>
</property>
</bean>
<bean id = "mysqlItemWriter" class = "org.springframework.batch.item.database.JdbcBatchItemWriter">
<property name = "dataSource" ref = "dataSource" />
<property name = "sql">
<value>
<![CDATA[insert into details.tutorials (tutorial_id, tutorial_author, tutorial_title,
submission_date, tutorial_icon, tutorial_description)
values (:tutorial_id, :tutorial_author, :tutorial_title, :submission_date,
:tutorial_icon, :tutorial_description);]]>
</value>
</property>
<property name = "itemSqlParameterSourceProvider">
<bean class = "org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider" />
</property>
</bean>
</beans>Context.xml
Poniżej znajduje się context.xmlnaszej aplikacji Spring Batch. W tym pliku zdefiniujemy komponenty bean, takie jak repozytorium zadań, program uruchamiający zadania i menedżer transakcji.
<beans xmlns = "http://www.springframework.org/schema/beans"
xmlns:jdbc = "http://www.springframework.org/schema/jdbc"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/jdbc
http://www.springframework.org/schema/jdbc/spring-jdbc-3.2.xsd">
<!-- stored job-meta in database -->
<bean id = "jobRepository"
class = "org.springframework.batch.core.repository.support.JobRepositoryFactoryBean">
<property name = "dataSource" ref = "dataSource" />
<property name = "transactionManager" ref = "transactionManager" />
<property name = "databaseType" value = "mysql" />
</bean>
<bean id = "transactionManager"
class = "org.springframework.batch.support.transaction.ResourcelessTransactionMana ger" />
<bean id = "jobLauncher"
class = "org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name = "jobRepository" ref = "jobRepository" />
</bean>
<!-- connect to MySQL database -->
<bean id = "dataSource"
class = "org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name = "driverClassName" value = "com.mysql.jdbc.Driver" />
<property name = "url" value = "jdbc:mysql://localhost:3306/details" />
<property name = "username" value = "myuser" />
<property name = "password" value = "password" />
</bean>
<!-- create job-meta tables automatically -->
<jdbc:initialize-database data-source = "dataSource">
<jdbc:script location = "org/springframework/batch/core/schema-drop-mysql.sql"/>
<jdbc:script location = "org/springframework/batch/core/schema-mysql.sql"/>
</jdbc:initialize-database>
</beans>CustomItemProcessor.java
Poniżej znajduje się processorklasa. W tej klasie piszemy kod przetwarzania w aplikacji. Tutaj ładujemy dokument PDF, tworzymy nową stronę, tworzymy tabelę i wstawiamy następujące wartości dla każdego rekordu: id samouczka, nazwa samouczka, autor, data przesłania do tabeli.
import java.io.File;
import java.io.IOException;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDPageContentStream;
import org.apache.pdfbox.pdmodel.font.PDType1Font;
import org.springframework.batch.item.ItemProcessor;
public class CustomItemProcessor implements ItemProcessor<Tutorial, Tutorial> {
public static void drawTable(PDPage page, PDPageContentStream contentStream,
float y, float margin, String[][] content) throws IOException {
final int rows = content.length;
final int cols = content[0].length;
final float rowHeight = 50;
final float tableWidth = page.getMediaBox().getWidth()-(2*margin);
final float tableHeight = rowHeight * rows;
final float colWidth = tableWidth/(float)cols;
final float cellMargin=5f;
// draw the rows
float nexty = y ;
for (int i = 0; i <= rows; i++) {
contentStream.drawLine(margin,nexty,margin+tableWidth,nexty);
nexty-= rowHeight;
}
//draw the columns
float nextx = margin;
for (int i = 0; i <= cols; i++) {
contentStream.drawLine(nextx,y,nextx,y-tableHeight);
nextx += colWidth;
}
// now add the text
contentStream.setFont(PDType1Font.HELVETICA_BOLD,12);
float textx = margin+cellMargin;
float texty = y-15;
for(int i = 0; i < content.length; i++){
for(int j = 0 ; j < content[i].length; j++){
String text = content[i][j];
contentStream.beginText();
contentStream.moveTextPositionByAmount(textx,texty);
contentStream.drawString(text);
contentStream.endText();
textx += colWidth;
}
texty-=rowHeight;
textx = margin+cellMargin;
}
}
@Override
public Tutorial process(Tutorial item) throws Exception {
System.out.println("Processing..." + item);
// Creating PDF document object
PDDocument doc = PDDocument.load(new File("C:/Examples/test.pdf"));
// Creating a blank page
PDPage page = new PDPage();
doc.addPage( page );
PDPageContentStream contentStream = new PDPageContentStream(doc, page);
String[][] content = {{"Id",""+item.getTutorial_id()},
{"Title", item.getTutorial_title()},
{"Authour", item.getTutorial_author()},
{"Submission Date", item.getSubmission_date()}} ;
drawTable(page, contentStream, 700, 100, content);
contentStream.close();
doc.save("C:/Examples/test.pdf" );
System.out.println("Hello");
return item;
}
}TutorialFieldSetMapper.java
Poniżej znajduje się klasa ReportFieldSetMapper, która ustawia dane na klasę Tutorial.
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.validation.BindException;
public class TutorialFieldSetMapper implements FieldSetMapper<Tutorial> {
@Override
public Tutorial mapFieldSet(FieldSet fieldSet) throws BindException {
// instantiating the Tutorial class
Tutorial tutorial = new Tutorial();
// Setting the fields from XML
tutorial.setTutorial_id(fieldSet.readInt(0));
tutorial.setTutorial_title(fieldSet.readString(1));
tutorial.setTutorial_author(fieldSet.readString(2));
tutorial.setTutorial_icon(fieldSet.readString(3));
tutorial.setTutorial_description(fieldSet.readString(4));
return tutorial;
}
}Tutorial.java
Poniżej znajduje się Tutorialklasa. To jest prosta klasa zsetter i getter metody.
public class Tutorial {
private int tutorial_id;
private String tutorial_author;
private String tutorial_title;
private String submission_date;
private String tutorial_icon;
private String tutorial_description;
@Override
public String toString() {
return " [id=" + tutorial_id + ", author=" + tutorial_author
+ ", title=" + tutorial_title + ", date=" + submission_date + ", icon ="
+tutorial_icon +", description = "+tutorial_description+"]";
}
public int getTutorial_id() {
return tutorial_id;
}
public void setTutorial_id(int tutorial_id) {
this.tutorial_id = tutorial_id;
}
public String getTutorial_author() {
return tutorial_author;
}
public void setTutorial_author(String tutorial_author) {
this.tutorial_author = tutorial_author;
}
public String getTutorial_title() {
return tutorial_title;
}
public void setTutorial_title(String tutorial_title) {
this.tutorial_title = tutorial_title;
}
public String getSubmission_date() {
return submission_date;
}
public void setSubmission_date(String submission_date) {
this.submission_date = submission_date;
}
public String getTutorial_icon() {
return tutorial_icon;
}
public void setTutorial_icon(String tutorial_icon) {
this.tutorial_icon = tutorial_icon;
}
public String getTutorial_description() {
return tutorial_description;
}
public void setTutorial_description(String tutorial_description) {
this.tutorial_description = tutorial_description;
}
}App.java
Poniżej znajduje się kod uruchamiający proces wsadowy. W tej klasie uruchomimy aplikację wsadową, uruchamiając JobLauncher.
public class App {
public static void main(String[] args) throws Exception {
String[] springConfig = { "jobs/job_hello_world.xml" };
// Creating the application context object
ApplicationContext context = new ClassPathXmlApplicationContext(springConfig);
// Creating the job launcher
JobLauncher jobLauncher = (JobLauncher) context.getBean("jobLauncher");
// Creating the job
Job job = (Job) context.getBean("helloWorldJob");
// Executing the JOB
JobExecution execution = jobLauncher.run(job, new JobParameters());
System.out.println("Exit Status : " + execution.getStatus());
}
}Podczas wykonywania tej aplikacji wygeneruje następujące dane wyjściowe.
May 05, 2017 4:39:22 PM org.springframework.context.support.ClassPathXmlApplicationContext
prepareRefresh
INFO: Refreshing org.springframework.context.support.ClassPathXmlApplicationContext@306a30c7:
startup date [Fri May 05 16:39:22 IST 2017]; root of context hierarchy
May 05, 2017 4:39:23 PM org.springframework.beans.factory.xml.XmlBeanDefinitionReader loadBeanDefinitions
May 05, 2017 4:39:32 PM org.springframework.batch.core.job.SimpleStepHandler handleStep
INFO: Executing step: [step1]
Processing... [id=1001, author=Sanjay, title=Learn Java, date=06-05-2007,
icon =https://www.tutorialspoint.com/java/images/java-mini-logo.jpg,
description = Java is a high-level programming language originally developed by Sun Microsystems
and released in 1995. Java runs on a variety of platforms.
This tutorial gives a complete understanding of Java.');]
Hello
Processing.. [id=1002, author=Abdul S, title=Learn MySQL, date=19-04-2007,
icon =https://www.tutorialspoint.com/mysql/images/mysql-mini-logo.jpg,
description = MySQL is the most popular Open Source Relational SQL database management system.
MySQL is one of the best RDBMS being used for developing web-based software applications.
This tutorial will give you quick start with MySQL and make you comfortable with MySQL programming.]
Hello
Processing... [id=1003, author=Krishna Kasyap, title=Learn JavaFX, date=06-072017,
icon =https://www.tutorialspoint.com/javafx/images/javafx-mini-logo.jpg,
description = JavaFX is a Java library used to build Rich Internet Applications.
The applications developed using JavaFX can run on various devices
such as Desktop Computers, Mobile Phones, TVs, Tablets, etc.
This tutorial, discusses all the necessary elements of JavaFX
that are required to develop effective Rich Internet Applications]
Hello
May 05, 2017 4:39:36 PM org.springframework.batch.core.launch.support.SimpleJobLauncher run
INFO: Job: [FlowJob: [name=helloWorldJob]] completed with the following parameters: [{}]
and the following status: [COMPLETED]
Exit Status : COMPLETEDJeśli zweryfikujesz details.tutorial tabeli w bazie danych, pokaże ci następujące dane wyjściowe -
| tutorial _id | samouczek _author | tutorial _title | termin składania | tutorial _icon | tutorial _description |
|---|---|---|---|---|---|
| 1001 | Sanjay | Dowiedz się Java | 06-05-2007 | https: //www.tutorials point.com / java / images / java-mini-logo.jpg | Java to język programowania wysokiego poziomu, pierwotnie opracowany przez Sun Microsystems i wydany w 1995 r. Java działa na różnych platformach. Ten samouczek zapewnia pełne zrozumienie języka Java. |
| 1002 | Abdul S | Naucz się MySQL | 19-04-2007 | https: // www. tutorialspoint.com / mysql / images /mysql-minilogo.jpg | MySQL to najpopularniejszy system zarządzania relacyjnymi bazami danych SQL typu Open Source. MySQL jest jednym z najlepszych RDBMS używanych do tworzenia aplikacji internetowych. Ten samouczek pozwoli Ci szybko rozpocząć pracę z MySQL i zaznajomić się z programowaniem MySQL. |
| 1003 | Dowiedz się JavaFX | Krishna Kasyap | 06-07-2017 | https: // www. tutorialspoint.com / javafx / images / javafx-minilogo.jpg | MySQL to najpopularniejszy system zarządzania relacyjnymi bazami danych SQL typu Open Source. MySQL jest jednym z najlepszych RDBMS używanych do tworzenia aplikacji internetowych. Ten samouczek pozwoli Ci szybko rozpocząć pracę z MySQL i zaznajomić się z programowaniem MySQL. |
Spowoduje to wygenerowanie pliku PDF z rekordami na każdej stronie, jak pokazano poniżej.
W tym rozdziale utworzymy prostą aplikację Spring Batch, która używa czytnika CSV i modułu zapisującego XML.
Reader - The reader używamy w aplikacji FlatFileItemReader do odczytu danych z plików CSV.
Poniżej znajduje się wejściowy plik CSV, którego używamy w tej aplikacji. Ten dokument zawiera rekordy danych, które określają szczegóły, takie jak identyfikator samouczka, jego autor, tytuł samouczka, data przesłania, ikona samouczka i opis samouczka.
1001, "Sanjay", "Learn Java", 06/05/2007
1002, "Abdul S", "Learn MySQL", 19/04/2007
1003, "Krishna Kasyap", "Learn JavaFX", 06/07/2017Writer - Writer, którego używamy w aplikacji, to StaxEventItemWriter aby zapisać dane do pliku XML.
Processor - Procesor, którego używamy w aplikacji to niestandardowy procesor, który po prostu drukuje rekordy odczytane z pliku CSV.
jobConfig.xml
Poniżej znajduje się plik konfiguracyjny naszej przykładowej aplikacji Spring Batch. W tym pliku zdefiniujemy zadanie i kroki. Oprócz tego definiujemy również komponenty bean dla ItemReader, ItemProcessor i ItemWriter. (Tutaj kojarzymy je z odpowiednimi klasami i przekazujemy wartości wymaganych właściwości, aby je skonfigurować).
<beans xmlns = " http://www.springframework.org/schema/beans"
xmlns:batch = "http://www.springframework.org/schema/batch"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.2.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd">
<import resource = "../jobs/context.xml" />
<bean id = "report" class = "Report" scope = "prototype" />
<bean id = "itemProcessor" class = "CustomItemProcessor" />
<batch:job id = "helloWorldJob">
<batch:step id = "step1">
<batch:tasklet>
<batch:chunk reader = "cvsFileItemReader" writer = "xmlItemWriter"
processor = "itemProcessor" commit-interval = "10">
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>
<bean id = "cvsFileItemReader"
class = "org.springframework.batch.item.file.FlatFileItemReader">
<property name = "resource" value = "classpath:resources/report.csv" />
<property name = "lineMapper">
<bean
class = "org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name = "lineTokenizer">
<bean
class = "org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<property name = "names" value = "tutorial_id,
tutorial_author, Tutorial_title, submission_date" />
</bean>
</property>
<property name = "fieldSetMapper">
<bean class = "ReportFieldSetMapper" />
</property>
</bean>
</property>
</bean>
<bean id = "xmlItemWriter"
class = "org.springframework.batch.item.xml.StaxEventItemWriter">
<property name = "resource" value = "file:xml/outputs/tutorials.xml" />
<property name = "marshaller" ref = "reportMarshaller" />
<property name = "rootTagName" value = "tutorials" />
</bean>
<bean id = "reportMarshaller"
class = "org.springframework.oxm.jaxb.Jaxb2Marshaller">
<property name = "classesToBeBound">
<list>
<value>Tutorial</value>
</list>
</property>
</bean>
</beans>Context.xml
Poniżej znajduje się context.xmlnaszej aplikacji Spring Batch. W tym pliku zdefiniujemy komponenty bean, takie jak repozytorium zadań, program uruchamiający zadania i menedżer transakcji.
<beans xmlns = "http://www.springframework.org/schema/beans"
xmlns:jdbc = "http://www.springframework.org/schema/jdbc"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/jdbc
http://www.springframework.org/schema/jdbc/spring-jdbc-3.2.xsd">
<!-- stored job-meta in database -->
<bean id = "jobRepository"
class = "org.springframework.batch.core.repository.support.JobRepositoryFactoryBean">
<property name = "dataSource" ref = "dataSource" />
<property name = "transactionManager" ref = "transactionManager" />
<property name = "databaseType" value = "mysql" />
</bean>
<bean id = "transactionManager"
class = "org.springframework.batch.support.transaction.ResourcelessTransactionManager" />
<bean id = "jobLauncher"
class = "org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name = "jobRepository" ref = "jobRepository" />
</bean>
<bean id = "dataSource" class = "org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name = "driverClassName" value = "com.mysql.jdbc.Driver" />
<property name = "url" value = "jdbc:mysql://localhost:3306/details" />
<property name = "username" value = "myuser" />
<property name = "password" value = "password" />
</bean>
<!-- create job-meta tables automatically -->
<jdbc:initialize-database data-source = "dataSource">
<jdbc:script location = "org/springframework/batch/core/schema-drop-mysql.sql" />
<jdbc:script location = "org/springframework/batch/core/schema-mysql.sql" />
</jdbc:initialize-database>
</beans>CustomItemProcessor.java
Poniżej znajduje się klasa Processor. W tej klasie piszemy kod przetwarzania w aplikacji. Tutaj drukujemy zawartość każdego rekordu.
import org.springframework.batch.item.ItemProcessor;
public class CustomItemProcessor implements ItemProcessor<Tutorial, Tutorial> {
@Override
public Tutorial process(Tutorial item) throws Exception {
System.out.println("Processing..." + item);
return item;
}
}TutorialFieldSetMapper.java
Poniżej znajduje się klasa TutorialFieldSetMapper, która ustawia dane na klasę Tutorial.
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.validation.BindException;
public class TutorialFieldSetMapper implements FieldSetMapper<Tutorial> {
@Override
public Tutorial mapFieldSet(FieldSet fieldSet) throws BindException {
//Instantiating the report object
Tutorial tutorial = new Tutorial();
//Setting the fields
tutorial.setTutorial_id(fieldSet.readInt(0));
tutorial.setTutorial_author(fieldSet.readString(1));
tutorial.setTutorial_title(fieldSet.readString(2));
tutorial.setSubmission_date(fieldSet.readString(3));
return tutorial;
}
}Klasa Tutorial.java
Poniżej znajduje się Tutorialklasa. Jest to prosta klasa Java zsetter i gettermetody. W tej klasie używamy adnotacji, aby powiązać metody tej klasy ze znacznikami pliku XML.
import javax.xml.bind.annotation.XmlAttribute;
import javax.xml.bind.annotation.XmlElement;
import javax.xml.bind.annotation.XmlRootElement;
@XmlRootElement(name = "tutorial")
public class Tutorial {
private int tutorial_id;
private String tutorial_author;
private String tutorial_title;
private String submission_date;
@XmlAttribute(name = "tutorial_id")
public int getTutorial_id() {
return tutorial_id;
}
public void setTutorial_id(int tutorial_id) {
this.tutorial_id = tutorial_id;
}
@XmlElement(name = "tutorial_author")
public String getTutorial_author() {
return tutorial_author;
}
public void setTutorial_author(String tutorial_author) {
this.tutorial_author = tutorial_author;
}
@XmlElement(name = "tutorial_title")
public String getTutorial_title() {
return tutorial_title;
}
public void setTutorial_title(String tutorial_title) {
this.tutorial_title = tutorial_title;
}
@XmlElement(name = "submission_date")
public String getSubmission_date() {
return submission_date;
}
public void setSubmission_date(String submission_date) {
this.submission_date = submission_date;
}
@Override
public String toString() {
return " [Tutorial id=" + tutorial_id + ",
Tutorial Author=" + tutorial_author + ",
Tutorial Title=" + tutorial_title + ",
Submission Date=" + submission_date + "]";
}
}App.java
Poniżej znajduje się kod, który uruchamia proces wsadowy. W tej klasie uruchomimy aplikację wsadową, uruchamiając JobLauncher.
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class App {
public static void main(String[] args) throws Exception {
String[] springConfig = { "jobs/job_hello_world.xml" };
// Creating the application context object
ApplicationContext context = new ClassPathXmlApplicationContext(springConfig);
// Creating the job launcher
JobLauncher jobLauncher = (JobLauncher) context.getBean("jobLauncher");
// Creating the job
Job job = (Job) context.getBean("helloWorldJob");
// Executing the JOB
JobExecution execution = jobLauncher.run(job, new JobParameters());
System.out.println("Exit Status : " + execution.getStatus());
}
}Podczas wykonywania tej aplikacji wygeneruje następujące dane wyjściowe.
May 08, 2017 10:10:12 AM org.springframework.context.support.ClassPathXmlApplicationContext prepareRefresh
INFO: Refreshing
org.springframework.context.support.ClassPathXmlApplicationContext@3d646c37: startup date
[Mon May 08 10:10:12 IST 2017]; root of context hierarchy
May 08, 2017 10:10:12 AM org.springframework.beans.factory.xml.XmlBeanDefinitionReader loadBeanDefinitions
May 08, 2017 10:10:15 AM org.springframework.jdbc.datasource.init.ScriptUtils executeSqlScript
INFO: Executing step: [step1]
Processing... [Tutorial id=1001, Tutorial Author=Sanjay,
Tutorial Title=Learn Java, Submission Date=06/05/2007]
Processing... [Tutorial id=1002, Tutorial Author=Abdul S,
Tutorial Title=Learn MySQL, Submission Date=19/04/2007]
Processing... [Tutorial id=1003, Tutorial Author=Krishna Kasyap,
Tutorial Title=Learn JavaFX, Submission Date=06/07/2017]
May 08, 2017 10:10:21 AM org.springframework.batch.core.launch.support.SimpleJobLauncher run
INFO: Job: [FlowJob: [name=helloWorldJob]] completed with the following parameters:
[{}] and the following status: [COMPLETED]
Exit Status : COMPLETEDSpowoduje to wygenerowanie pliku XML o następującej zawartości.
<?xml version = "1.0" encoding = "UTF-8"?>
<tutorials>
<tutorial tutorial_id = "1001">
<submission_date>06/05/2007</submission_date>
<tutorial_author>Sanjay</tutorial_author>
<tutorial_title>Learn Java</tutorial_title>
</tutorial>
<tutorial tutorial_id = "1002">
<submission_date>19/04/2007</submission_date>
<tutorial_author>Abdul S</tutorial_author>
<tutorial_title>Learn MySQL</tutorial_title>
</tutorial>
<tutorial tutorial_id = "1003">
<submission_date>06/07/2017</submission_date>
<tutorial_author>Krishna Kasyap</tutorial_author>
<tutorial_title>Learn JavaFX</tutorial_title>
</tutorial>
</tutorials>W tym rozdziale utworzymy aplikację Spring Batch, która korzysta z czytnika MySQL i modułu zapisującego XML.
Reader - Czytnik, którego używamy w aplikacji, to JdbcCursorItemReader do odczytu danych z bazy danych MySQL.
Załóżmy, że utworzyliśmy tabelę w bazie danych MySQL, jak pokazano poniżej -
CREATE TABLE details.xml_mysql(
person_id int(10) NOT NULL,
sales VARCHAR(20),
qty int(3),
staffName VARCHAR(20),
date VARCHAR(20)
);Załóżmy, że wstawiliśmy do niego następujące rekordy.
mysql> select * from tutorialsdata;
+-------------+-----------------+----------------+-----------------+
| tutorial_id | tutorial_author | tutorial_title | submission_date |
+-------------+-----------------+----------------+-----------------+
| 101 | Sanjay | Learn Java | 06-05-2007 |
| 102 | Abdul S | Learn MySQL | 19-04-2007 |
| 103 | Krishna Kasyap | Learn JavaFX | 06-07-2017 |
+-------------+-----------------+----------------+-----------------+
3 rows in set (0.00 sec)Writer - Writer, którego używamy w aplikacji, to StaxEventItemWriter aby zapisać dane do pliku XML.
Processor - Procesor, którego używamy w aplikacji to niestandardowy procesor, który po prostu drukuje rekordy odczytane z pliku CSV.
jobConfig.xml
Poniżej znajduje się plik konfiguracyjny naszej przykładowej aplikacji Spring Batch. W tym pliku zdefiniujemy zadanie i kroki. Oprócz tego definiujemy również komponenty bean dla ItemReader, ItemProcessor i ItemWriter. (Tutaj kojarzymy je z odpowiednimi klasami i przekazujemy wartości wymaganych właściwości, aby je skonfigurować).
<beans xmlns = "http://www.springframework.org/schema/beans"
xmlns:batch = "http://www.springframework.org/schema/batch"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xmlns:util = "http://www.springframework.org/schema/util"
xsi:schemaLocation = " http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.2.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd">
<import resource = "../jobs/context.xml" />
<bean id = "report" class = "Report" scope = "prototype" />
<bean id = "itemProcessor" class = "CustomItemProcessor" />
<batch:job id = "helloWorldJob">
<batch:step id = "step1">
<batch:tasklet>
<batch:chunk reader = "dbItemReader"
writer = "mysqlItemWriter" processor = "itemProcessor" commit-interval = "10">
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>
<bean id = "dbItemReader"
class = "org.springframework.batch.item.database.JdbcCursorItemReader" scope = "step">
<property name = "dataSource" ref = "dataSource" />
<property name = "sql" value = "select * from tutorials_data" />
<property name = "rowMapper">
<bean class = "TutorialRowMapper" />
</property>
</bean>
<bean id = "mysqlItemWriter"
class = "org.springframework.batch.item.xml.StaxEventItemWriter">
<property name = "resource" value = "file:xml/outputs/tutorials.xml" />
<property name = "marshaller" ref = "reportMarshaller" />
<property name = "rootTagName" value = "Tutorial" />
</bean>
<bean id = "reportMarshaller" class = "org.springframework.oxm.jaxb.Jaxb2Marshaller">
<property name = "classesToBeBound">
<list>
<value>Tutorial</value>
</list>
</property>
</bean>
</beans>Context.xml
Poniżej znajduje się context.xmlnaszej aplikacji Spring Batch. W tym pliku zdefiniujemy komponenty bean, takie jak repozytorium zadań, program uruchamiający zadania i menedżer transakcji.
<beans xmlns = " http://www.springframework.org/schema/beans"
xmlns:jdbc = "http://www.springframework.org/schema/jdbc"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/jdbc
http://www.springframework.org/schema/jdbc/spring-jdbc-3.2.xsd ">
<!-- stored job-meta in database -->
<bean id = "jobRepository"
class = "org.springframework.batch.core.repository.support.JobRepositoryFactoryBean">
<property name = "dataSource" ref = "dataSource" />
<property name = "transactionManager" ref = "transactionManager" />
<property name = "databaseType" value = "mysql" />
</bean>
<bean id = "transactionManager"
class = "org.springframework.batch.support.transaction.ResourcelessTransactionMana ger" />
<bean id = "jobLauncher"
class = "org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name = "jobRepository" ref = "jobRepository" />
</bean>
<!-- connect to MySQL database -->
<bean id = "dataSource"
class = "org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name = "driverClassName" value = "com.mysql.jdbc.Driver" />
<property name = "url" value = "jdbc:mysql://localhost:3306/details" />
<property name = "username" value = "myuser" />
<property name = "password" value = "password" />
</bean>
<!-- create job-meta tables automatically -->
<jdbc:initialize-database data-source = "dataSource">
<jdbc:script location = "org/springframework/batch/core/schema-drop-mysql.sql" />
<jdbc:script location = "org/springframework/batch/core/schema-mysql.sql" />
</jdbc:initialize-database>
</beans>CustomItemProcessor.java
Poniżej znajduje się klasa Processor. W tej klasie piszemy kod przetwarzania w aplikacji. Tutaj drukujemy zawartość każdego rekordu.
import org.springframework.batch.item.ItemProcessor;
public class CustomItemProcessor implements ItemProcessor<Tutorial, Tutorial> {
@Override
public Tutorial process(Tutorial item) throws Exception {
System.out.println("Processing..." + item);
return item;
}
}TutorialRowMapper.java
Poniżej znajduje się TutorialRowMapper klasa, która ustawia dane na Tutorial klasa.
import java.sql.ResultSet;
import java.sql.SQLException;
import org.springframework.jdbc.core.RowMapper;
public class TutorialRowMapper implements RowMapper<Tutorial> {
@Override
public Tutorial mapRow(ResultSet rs, int rowNum) throws SQLException {
Tutorial tutorial = new Tutorial();
tutorial.setTutorial_id(rs.getInt("tutorial_id"));
tutorial.setTutorial_author(rs.getString("tutorial_author"));
tutorial.setTutorial_title(rs.getString("tutorial_title"));
tutorial.setSubmission_date(rs.getString("submission_date"));
return tutorial;
}
}Tutorial.java
Poniżej znajduje się Tutorialklasa. Jest to prosta klasa Java zsetter i gettermetody. W tej klasie używamy adnotacji, aby powiązać metody tej klasy ze znacznikami pliku XML.
import javax.xml.bind.annotation.XmlAttribute;
import javax.xml.bind.annotation.XmlElement;
import javax.xml.bind.annotation.XmlRootElement;
@XmlRootElement(name = "details")
public class Tutorial {
int tutorial_id;
String tutorial_author;
String submission_date;
@XmlAttribute(name = "tutorial_id")
public int getTutorial_id() {
return tutorial_id;
}
public void setTutorial_id(int tutorial_id) {
this.tutorial_id = tutorial_id;
}
@XmlElement(name = "tutorial_author")
public String getTutorial_author() {
return tutorial_author;
}
public void setTutorial_author(String tutorial_author) {
this.tutorial_author = tutorial_author;
}
@XmlElement(name = "tutorial_title")
public String getTutorial_title() {
return tutorial_title;
}
public void setTutorial_title(String tutorial_title) {
this.tutorial_title = tutorial_title;
}
@XmlElement(name = "submission_date")
public String getSubmission_date() {
return submission_date;
}
public void setSubmission_date(String submission_date) {
this.submission_date = submission_date;
}
public String toString() {
return " [Tutorial Id=" + tutorial_id + ",
Tutorial Author =" + tutorial_author + ",
Tutorial Title =" + tutorial_title + ",
Submission Date =" + submission_date + "]";
}
}App.java
Poniżej znajduje się kod uruchamiający proces wsadowy. W tej klasie uruchomimy aplikację wsadową, uruchamiając JobLauncher.
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class App {
public static void main(String[] args) throws Exception {
String[] springConfig = { "jobs/job_hello_world.xml" };
// Creating the application context object
ApplicationContext context = new ClassPathXmlApplicationContext(springConfig);
// Creating the job launcher
JobLauncher jobLauncher = (JobLauncher) context.getBean("jobLauncher");
// Creating the job
Job job = (Job) context.getBean("helloWorldJob");
// Executing the JOB
JobExecution execution = jobLauncher.run(job, new JobParameters());
System.out.println("Exit Status : " + execution.getStatus());
}
}Podczas wykonywania tej aplikacji wygeneruje następujące dane wyjściowe.
May 08, 2017 11:32:06 AM org.springframework.context.support.ClassPathXmlApplicationContext prepareRefresh
INFO: Refreshing org.springframework.context.support.ClassPathXmlApplicationContext@3d646c37:
startup date [Mon May 08 11:32:06 IST 2017]; root of context hierarchy
May 08, 2017 11:32:06 AM org.springframework.beans.factory.xml.XmlBeanDefinitionReader loadBeanDefinitions
INFO: Loading XML bean definitions from class path resource [jobs/job_hello_world.xml]
May 08, 2017 11:32:07 AM org.springframework.beans.factory.xml.XmlBeanDefinitionReader loadBeanDefinitions
May 08, 2017 11:32:14 AM org.springframework.batch.core.job.SimpleStepHandler handleStep
INFO: Executing step: [step1]
Processing... [Tutorial Id=101, Tutorial Author=Sanjay,
Tutorial Title=Learn Java, Submission Date=06-05-2007]
Processing... [Tutorial Id=102, Tutorial Author=Abdul S,
Tutorial Title=Learn MySQL, Submission Date=19-04-2007]
Processing... [Tutorial Id=103, Tutorial Author=Krishna Kasyap,
Tutorial Title=Learn JavaFX, Submission Date=06-07-2017]
May 08, 2017 11:32:14 AM org.springframework.batch.core.launch.support.SimpleJobLauncher run
INFO: Job: [FlowJob: [name=helloWorldJob]] completed with the following parameters:
[{}] and the following status: [COMPLETED]
Exit Status : COMPLETEDSpowoduje to wygenerowanie pliku XML o następującej zawartości.
<?xml version = "1.0" encoding = "UTF-8"?>
<Tutorial>
<details tutorial_id = "101">
<submission_date>06-05-2007</submission_date>
<tutorial_author>Sanjay</tutorial_author>
<tutorial_title>Learn Java</tutorial_title>
</details>
<details tutorial_id = "102">
<submission_date>19-04-2007</submission_date>
<tutorial_author>Abdul S</tutorial_author>
<tutorial_title>Learn MySQL</tutorial_title>
</details>
<details tutorial_id = "103">
<submission_date>06-07-2017</submission_date>
<tutorial_author>Krishna Kasyap</tutorial_author>
<tutorial_title>Learn JavaFX</tutorial_title>
</details>
</Tutorial>W tym rozdziale stworzymy aplikację Spring Batch, która używa czytnika MySQL i pliku Flatfile Writer (.txt).
Reader - Czytnik, którego używamy w aplikacji, to JdbcCursorItemReader do odczytu danych z bazy danych MySQL.
Załóżmy, że utworzyliśmy tabelę w bazie danych MySQL, jak pokazano poniżej.
CREATE TABLE details.xml_mysql(
person_id int(10) NOT NULL,
sales VARCHAR(20),
qty int(3),
staffName VARCHAR(20),
date VARCHAR(20)
);Załóżmy, że wstawiliśmy do niego następujące rekordy.
mysql> select * from tutorialsdata;
+-------------+-----------------+----------------+-----------------+
| tutorial_id | tutorial_author | tutorial_title | submission_date |
+-------------+-----------------+----------------+-----------------+
| 101 | Sanjay | Learn Java | 06-05-2007 |
| 102 | Abdul S | Learn MySQL | 19-04-2007 |
| 103 | Krishna Kasyap | Learn JavaFX | 06-07-2017 |
+-------------+-----------------+----------------+-----------------+
3 rows in set (0.00 sec)Writer - Writer, którego używamy w aplikacji, to FlatFileItemWriter zapisać dane flatfile (.tekst).
Processor - Procesor, którego używamy w aplikacji to niestandardowy procesor, który po prostu drukuje rekordy odczytane z pliku CSV.
jobConfig.xml
Poniżej znajduje się plik konfiguracyjny naszej przykładowej aplikacji Spring Batch. W tym pliku zdefiniujemy zadanie i kroki. Oprócz tego definiujemy również komponenty bean dla ItemReader, ItemProcessor i ItemWriter. (Tutaj kojarzymy je z odpowiednimi klasami i przekazujemy wartości wymaganych właściwości, aby je skonfigurować).
<beans xmlns = "http://www.springframework.org/schema/beans"
xmlns:batch = "http://www.springframework.org/schema/batch"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xmlns:util = "http://www.springframework.org/schema/util"
xsi:schemaLocation = "http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.2.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd">
<import resource = "../jobs/context.xml" />
<bean id = "tutorial" class = "Tutorial" scope = "prototype" />
<bean id = "itemProcessor" class = "CustomItemProcessor" />
<batch:job id = "helloWorldJob">
<batch:step id = "step1">
<batch:tasklet>
<batch:chunk reader = "mysqlItemReader"
writer = "flatFileItemWriter" processor = "itemProcessor"
commit-interval = "10">
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>
<bean id = "mysqlItemReader"
class = "org.springframework.batch.item.database.JdbcCursorItemReader" >
<property name = "dataSource" ref = "dataSource" />
<property name = "sql" value = "select * from details.tutorialsdata" />
<property name = "rowMapper">
<bean class = "TutorialRowMapper" />
</property>
</bean>
<bean id = "flatFileItemWriter"
class = " org.springframework.batch.item.file.FlatFileItemWriter">
<property name = "resource" value = "file:target/outputfiles/employee_output.txt"/>
<property name = "lineAggregator">
<bean class = " org.springframework.batch.item.file.transform.PassThroughLineAggregator"/>
</property>
</bean>
</beans>Context.xml
Poniżej znajduje się context.xmlnaszej aplikacji Spring Batch. W tym pliku zdefiniujemy komponenty bean, takie jak repozytorium zadań, program uruchamiający zadania i menedżer transakcji.
<beans xmlns = "http://www.springframework.org/schema/beans"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xmlns:jdbc = "http://www.springframework.org/schema/jdbc"
xsi:schemaLocation = "http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/jdbc
http://www.springframework.org/schema/jdbc/spring-jdbc-3.2.xsd ">
<!-- stored job-meta in database -->
<bean id = "jobRepository"
class = "org.springframework.batch.core.repository.support.JobRepositoryFactoryBean">
<property name = "dataSource" ref = "dataSource" />
<property name = "transactionManager" ref = "transactionManager" />
<property name = "databaseType" value = "mysql" />
</bean>
<bean id = "transactionManager"
class = "org.springframework.batch.support.transaction.ResourcelessTransactionManager" />
<bean id = "dataSource"
class = "org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name = "driverClassName" value = "com.mysql.jdbc.Driver" />
<property name = "url" value = "jdbc:mysql://localhost:3306/details" />
<property name = "username" value = "myuser" />
<property name = "password" value = "password" />
</bean>
<bean id = "jobLauncher"
class = "org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name = "jobRepository" ref = "jobRepository" />
</bean>
<!-- create job-meta tables automatically -->
<jdbc:initialize-database data-source = "dataSource">
<jdbc:script location = "org/springframework/batch/core/schema-drop-mysql.sql" />
<jdbc:script location = "org/springframework/batch/core/schema-mysql.sql" />
</jdbc:initialize-database>
</beans>CustomItemProcessor.java
Poniżej znajduje się klasa Processor. W tej klasie piszemy kod przetwarzania w aplikacji. Tutaj drukujemy zawartość każdego rekordu.
import org.springframework.batch.item.ItemProcessor;
// Implementing the ItemProcessor interface
public class CustomItemProcessor implements ItemProcessor<Tutorial, Tutorial> {
@Override
public Tutorial process(Tutorial item) throws Exception {
System.out.println("Processing..." + item);
return item;
}
}TutorialRowMapper.java
Poniżej znajduje się TutorialRowMapper klasa, która ustawia dane na Tutorial klasa.
public class TutorialRowMapper implements RowMapper<Tutorial> {
@Override
public Tutorial mapRow(ResultSet rs, int rowNum) throws SQLException {
Tutorial tutorial = new Tutorial();
tutorial.setTutorial_id(rs.getInt("tutorial_id"));
tutorial.setTutorial_title(rs.getString("tutorial_title"));
tutorial.setTutorial_author(rs.getString("tutorial_author"));
tutorial.setSubmission_date(rs.getString("submission_date"));
return tutorial;
}
}Tutorial.java
Poniżej znajduje się Tutorialklasa. Jest to prosta klasa Java zsetter i gettermetody. W tej klasie używamy adnotacji, aby powiązać metody tej klasy ze znacznikami pliku XML.
public class Tutorial {
private int tutorial_id;
private String tutorial_title;
private String tutorial_author;
private String submission_date;
public int getTutorial_id() {
return tutorial_id;
}
public void setTutorial_id(int tutorial_id) {
this.tutorial_id = tutorial_id;
}
public String getTutorial_title() {
return tutorial_title;
}
public void setTutorial_title(String tutorial_title) {
this.tutorial_title = tutorial_title;
}
public String getTutorial_author() {
return tutorial_author;
}
public void setTutorial_author(String tutorial_author) {
this.tutorial_author = tutorial_author;
}
public String getSubmission_date() {
return submission_date;
}
public void setSubmission_date(String submission_date) {
this.submission_date = submission_date;
}
@Override
public String toString() {
return " [id=" + tutorial_id + ", title=" +
tutorial_title + ",
author=" + tutorial_author + ", date=" +
submission_date + "]";
}
}App.java
Poniżej znajduje się kod uruchamiający proces wsadowy. W tej klasie uruchomimy aplikację wsadową, uruchamiając JobLauncher.
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class App {
public static void main(String[] args) throws Exception {
String[] springConfig = { "jobs/job_hello_world.xml" };
// Creating the application context object
ApplicationContext context = new ClassPathXmlApplicationContext(springConfig);
// Creating the job launcher
JobLauncher jobLauncher = (JobLauncher) context.getBean("jobLauncher");
// Creating the job
Job job = (Job) context.getBean("helloWorldJob");
// Executing the JOB
JobExecution execution = jobLauncher.run(job, new JobParameters());
System.out.println("Exit Status : " + execution.getStatus());
}
}Podczas wykonywania tej aplikacji wygeneruje następujące dane wyjściowe.
May 09, 2017 5:44:48 PM org.springframework.context.support.ClassPathXmlApplicationContext prepareRefresh
INFO: Refreshing org.springframework.context.support.ClassPathXml
ApplicationContext@3d646c37: startup date [Tue May
09 17:44:48 IST 2017]; root of context hierarchy
May 09, 2017 5:44:48 PM org.springframework.beans.factory.xml.XmlBeanDefinitionReader loadBeanDefinitions
May 09, 2017 5:44:56 PM org.springframework.batch.core.launch.support.SimpleJobLauncher run
INFO: Job: [FlowJob: [name=helloWorldJob]] launched
with the following parameters: [{}]
May 09, 2017 5:44:56 PM org.springframework.batch.core.job.SimpleStepHandler handleStep
INFO: Executing step: [step1]
Processing...Report [id=101, title=Learn Java, author=Sanjay, date=06-05-2007]
Processing...Report [id=102, title=Learn MySQL, author=Abdul S, date=19-04-2007]
Processing...Report [id=103, title=Learn JavaFX, author=Krishna Kasyap, date=0607-2017]
May 09, 2017 5:44:57 PM org.springframework.batch.core.launch.support.SimpleJobLauncher run
INFO: Job: [FlowJob: [name=helloWorldJob]] completed with the following parameters:
[{}] and the following status: [COMPLETED]
Hello
Exit Status : COMPLETEDSpowoduje to wygenerowanie pliku .txt plik z następującą zawartością.
Report [id=101, title=Learn Java, author=Sanjay, date=06-05-2007]
Report [id=102, title=Learn MySQL, author=Abdul S, date=19-04-2007]
Report [id=103, title=Learn JavaFX, author=Krishna Kasyap, date=06-07-2017]