Weka - klastrowanie
Algorytm grupowania znajduje grupy podobnych wystąpień w całym zbiorze danych. WEKA obsługuje kilka algorytmów klastrowania, takich jak EM, FilteredClusterer, HierarchicalClusterer, SimpleKMeans i tak dalej. Powinieneś całkowicie zrozumieć te algorytmy, aby w pełni wykorzystać możliwości WEKA.
Podobnie jak w przypadku klasyfikacji, WEKA umożliwia graficzną wizualizację wykrytych klastrów. Aby zademonstrować klastrowanie, użyjemy dostarczonej bazy danych tęczówki. Zestaw danych zawiera trzy klasy po 50 instancji każda. Każda klasa odnosi się do rodzaju rośliny tęczówki.
Ładowanie danych
W eksploratorze WEKA wybierz plik Preprocesspatka. Kliknij naOpen file ... opcję i wybierz iris.arffplik w oknie dialogowym wyboru pliku. Po załadowaniu danych ekran wygląda jak poniżej -
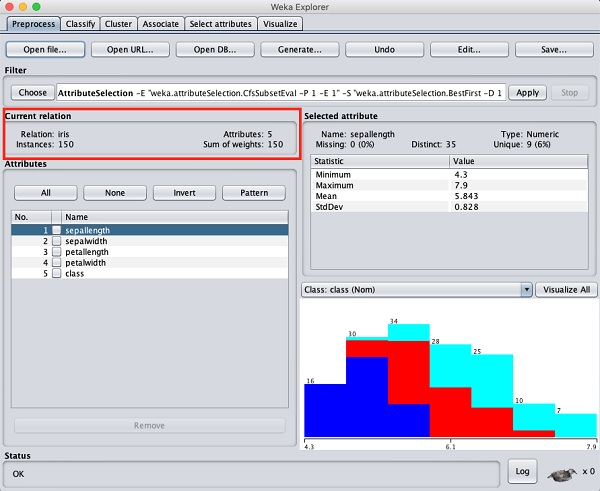
Możesz zauważyć, że istnieje 150 instancji i 5 atrybutów. Nazwy atrybutów są wymienione jakosepallength, sepalwidth, petallength, petalwidth i class. Pierwsze cztery atrybuty są typu liczbowego, podczas gdy klasa jest typem nominalnym z 3 różnymi wartościami. Sprawdź każdy atrybut, aby zrozumieć funkcje bazy danych. Nie będziemy dokonywać żadnego wstępnego przetwarzania tych danych i od razu przystąpimy do budowania modelu.
Grupowanie
Kliknij na ClusterTAB, aby zastosować algorytmy klastrowania do naszych załadowanych danych. Kliknij naChooseprzycisk. Zobaczysz następujący ekran -

Teraz wybierz EMjako algorytm grupowania. wCluster mode okno podrzędne, wybierz plik Classes to clusters evaluation opcja, jak pokazano na zrzucie ekranu poniżej -

Kliknij na Startprzycisk do przetwarzania danych. Po chwili wyniki zostaną wyświetlone na ekranie.
Następnie przeanalizujmy wyniki.
Badanie wyników
Wynik przetwarzania danych pokazano na poniższym ekranie -
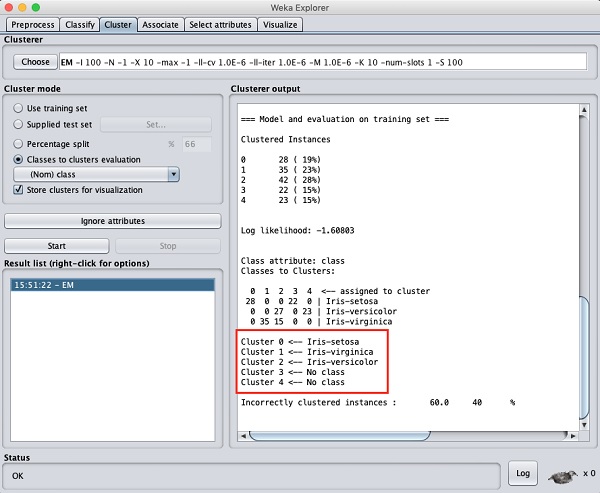
Na ekranie wyjściowym można zauważyć, że -
W bazie danych wykryto 5 instancji klastrowych.
Plik Cluster 0 reprezentuje setosę, Cluster 1 reprezentuje dziewicę, Cluster 2 reprezentuje versicolor, podczas gdy ostatnie dwie klastry nie mają przypisanej żadnej klasy.
Jeśli przewiniesz okno wyników w górę, zobaczysz również statystyki, które podają średnią i odchylenie standardowe dla każdego z atrybutów w różnych wykrytych skupieniach. Jest to pokazane na zrzucie ekranu podanym poniżej -
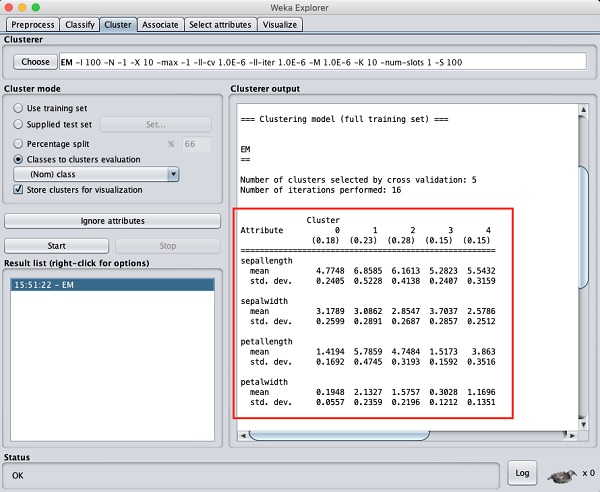
Następnie przyjrzymy się wizualnej reprezentacji klastrów.
Wizualizacja klastrów
Aby zwizualizować klastry, kliknij prawym przyciskiem myszy plik EM wynik w Result list. Zobaczysz następujące opcje -
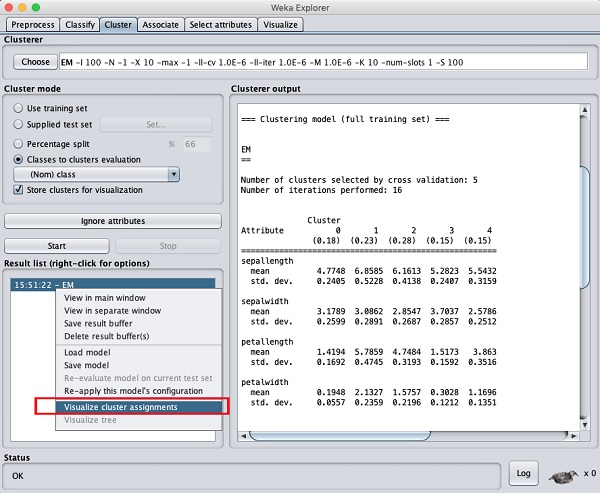
Wybierz Visualize cluster assignments. Zobaczysz następujący wynik -
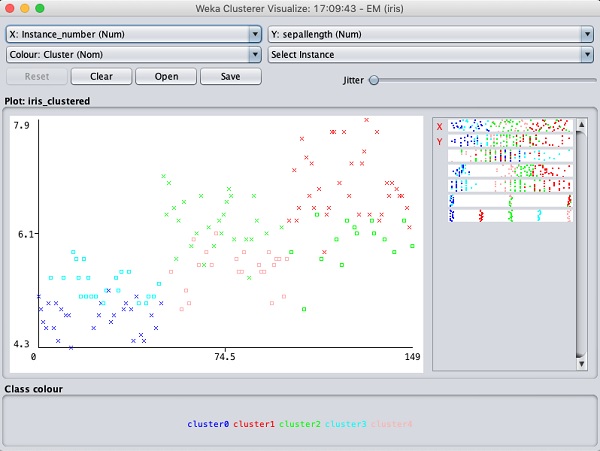
Podobnie jak w przypadku klasyfikacji, zauważysz różnicę między poprawnie a nieprawidłowo zidentyfikowanymi instancjami. Możesz bawić się, zmieniając osie X i Y, aby przeanalizować wyniki. Możesz użyć jittera, tak jak w przypadku klasyfikacji, aby znaleźć koncentrację prawidłowo zidentyfikowanych instancji. Operacje na wykresie wizualizacji są podobne do tych, które badałeś w przypadku klasyfikacji.
Stosowanie klastra hierarchicznego
Aby zademonstrować moc WEKA, przyjrzyjmy się teraz zastosowaniu innego algorytmu klastrowania. W eksploratorze WEKA wybierz plikHierarchicalClusterer jako algorytm ML, jak pokazano na zrzucie ekranu pokazanym poniżej -
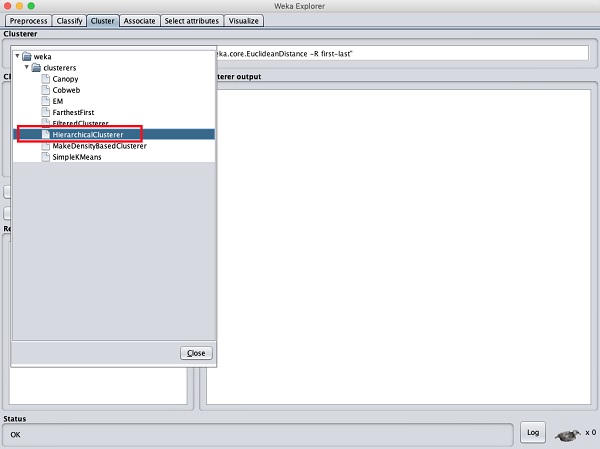
Wybierz Cluster mode wybór do Classes to cluster evaluationi kliknij Startprzycisk. Zobaczysz następujący wynik -
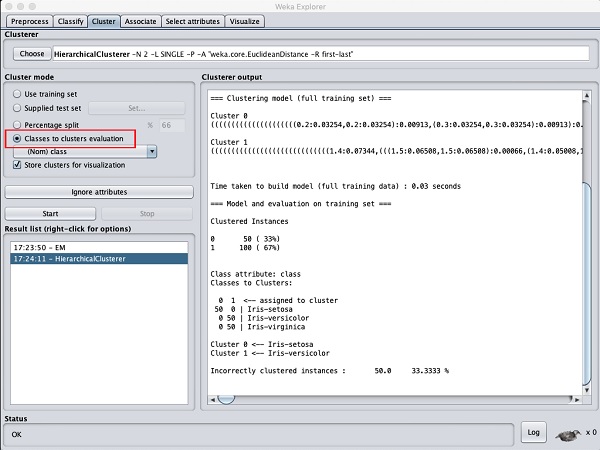
Zauważ, że w Result list, na liście są dwa wyniki: pierwszy to wynik EM, a drugi to bieżąca hierarchia. Podobnie można zastosować wiele algorytmów ML do tego samego zbioru danych i szybko porównać ich wyniki.
Jeśli zbadasz drzewo utworzone przez ten algorytm, zobaczysz następujący wynik -
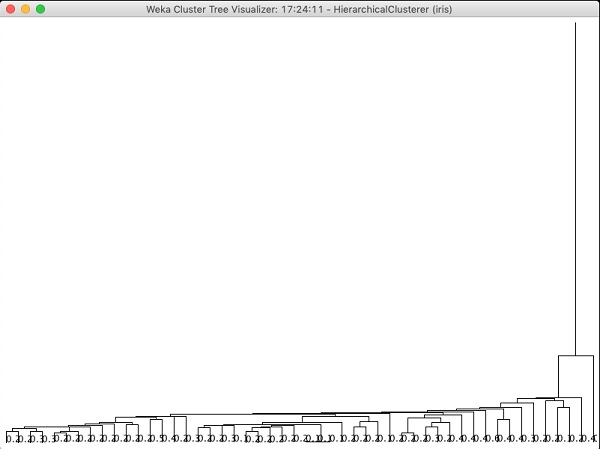
W następnym rozdziale nauczysz się Associate rodzaj algorytmów ML.