Weka - Szybki przewodnik
Podstawą każdej aplikacji uczenia maszynowego są dane - nie tylko małe dane, ale ogromne dane, które są określane jako Big Data w aktualnej terminologii.
Aby nauczyć maszynę analizować duże zbiory danych, należy wziąć pod uwagę kilka kwestii -
- Dane muszą być czyste.
- Nie powinien zawierać wartości null.
Poza tym nie wszystkie kolumny w tabeli danych byłyby przydatne do analizy, którą próbujesz osiągnąć. Nieistotne kolumny danych lub „funkcje” zgodnie z terminologią uczenia maszynowego należy usunąć, zanim dane zostaną wprowadzone do algorytmu uczenia maszynowego.
Krótko mówiąc, duże zbiory danych wymagają dużo wstępnego przetwarzania, zanim będą mogły zostać użyte do uczenia maszynowego. Gdy dane będą gotowe, możesz zastosować różne algorytmy uczenia maszynowego, takie jak klasyfikacja, regresja, grupowanie w klastry itd., Aby rozwiązać problem na końcu.
Rodzaj stosowanych algorytmów zależy w dużej mierze od wiedzy o Twojej domenie. Nawet w ramach tego samego typu, na przykład klasyfikacji, dostępnych jest kilka algorytmów. Możesz chcieć przetestować różne algorytmy w tej samej klasie, aby zbudować wydajny model uczenia maszynowego. Preferujesz przy tym wizualizację przetwarzanych danych, dlatego potrzebujesz również narzędzi do wizualizacji.
W kolejnych rozdziałach dowiesz się o Weka, oprogramowaniu, które z łatwością wykonuje wszystkie powyższe czynności i umożliwia wygodną pracę z dużymi zbiorami danych.
WEKA - oprogramowanie typu open source dostarcza narzędzi do wstępnego przetwarzania danych, implementacji kilku algorytmów uczenia maszynowego oraz narzędzi do wizualizacji, dzięki czemu można rozwijać techniki uczenia maszynowego i stosować je do rzeczywistych problemów eksploracji danych. To, co oferuje WEKA, podsumowano na poniższym schemacie -
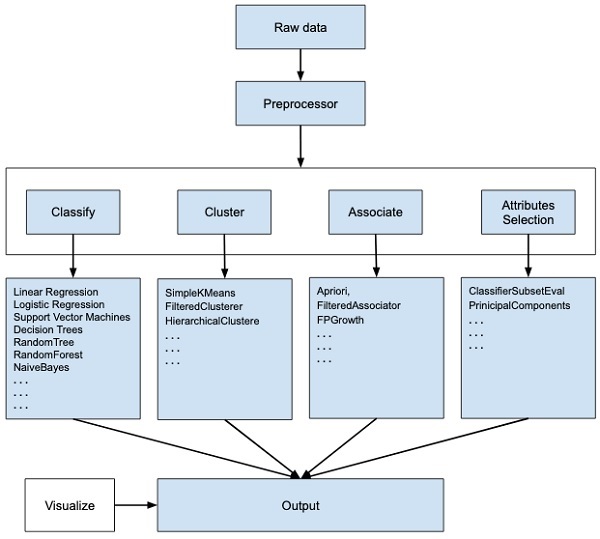
Jeśli obserwujesz początek przepływu obrazu, zrozumiesz, że istnieje wiele etapów radzenia sobie z Big Data, aby uczynić go odpowiednim do uczenia maszynowego -
Najpierw zaczniesz od surowych danych zebranych z pola. Te dane mogą zawierać kilka wartości null i nieistotnych pól. Korzystasz z narzędzi do wstępnego przetwarzania danych dostępnych w WEKA w celu oczyszczenia danych.
Następnie można zapisać wstępnie przetworzone dane w lokalnym magazynie w celu zastosowania algorytmów ML.
Następnie, w zależności od rodzaju modelu ML, który próbujesz opracować, wybierz jedną z opcji, takich jak Classify, Clusterlub Associate. PlikAttributes Selection umożliwia automatyczny wybór funkcji w celu utworzenia zredukowanego zbioru danych.
Należy zauważyć, że w każdej kategorii WEKA zapewnia implementację kilku algorytmów. Należy wybrać wybrany algorytm, ustawić żądane parametry i uruchomić go na zbiorze danych.
Następnie WEKA poda statystyczny wynik przetwarzania modelu. Zapewnia narzędzie wizualizacji do inspekcji danych.
Różne modele można zastosować do tego samego zbioru danych. Następnie możesz porównać wyniki różnych modeli i wybrać najlepszy, który spełnia Twój cel.
W ten sposób zastosowanie WEKA skutkuje szybszym generowaniem modeli uczenia maszynowego.
Teraz, gdy już widzieliśmy, czym jest WEKA i co robi, w następnym rozdziale nauczmy się, jak zainstalować WEKA na komputerze lokalnym.
Aby zainstalować WEKA na swoim komputerze, odwiedź oficjalną witrynę WEKA i pobierz plik instalacyjny. WEKA obsługuje instalację w systemach Windows, Mac OS X i Linux. Wystarczy postępować zgodnie z instrukcjami na tej stronie, aby zainstalować WEKA dla swojego systemu operacyjnego.
Kroki instalacji na komputerze Mac są następujące -
- Pobierz plik instalacyjny dla komputerów Mac.
- Kliknij dwukrotnie pobrany plik weka-3-8-3-corretto-jvm.dmg file.
Po pomyślnej instalacji zobaczysz następujący ekran.
- Kliknij na weak-3-8-3-corretto-jvm ikona, aby uruchomić Weka.
- Opcjonalnie możesz uruchomić go z wiersza poleceń -
java -jar weka.jarUruchomi się aplikacja WEKA GUI Chooser i zobaczysz następujący ekran -
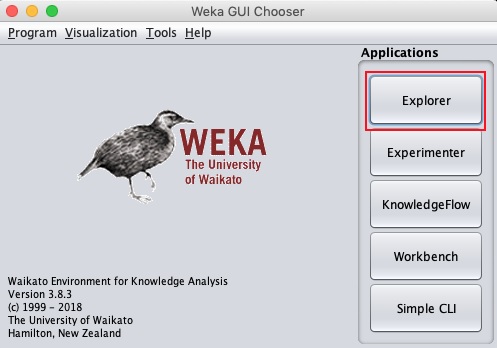
Aplikacja GUI Chooser umożliwia uruchamianie pięciu różnych typów aplikacji wymienionych tutaj -
- Explorer
- Experimenter
- KnowledgeFlow
- Workbench
- Prosty interfejs CLI
Będziemy używać Explorer w tym samouczku.
W tym rozdziale przyjrzyjmy się różnym funkcjonalnościom, które oferuje eksplorator do pracy z dużymi zbiorami danych.
Po kliknięciu pliku Explorer przycisk w Applications selektor, otwiera następujący ekran -
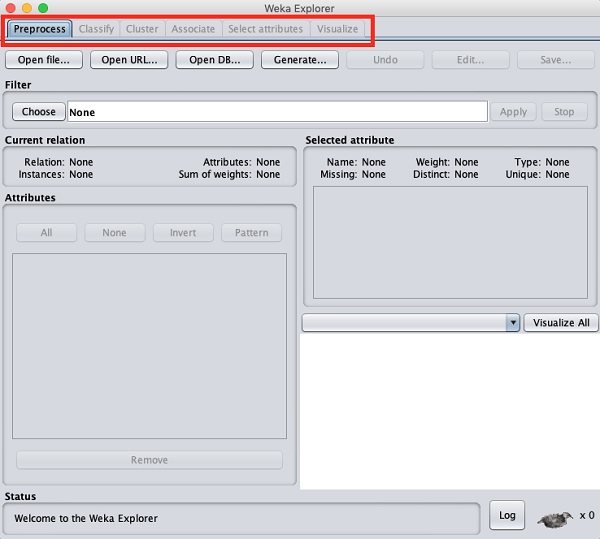
U góry zobaczysz kilka kart wymienionych tutaj -
- Preprocess
- Classify
- Cluster
- Associate
- Wybierz Atrybuty
- Visualize
Na tych kartach znajduje się kilka wstępnie zaimplementowanych algorytmów uczenia maszynowego. Przyjrzyjmy się teraz szczegółowo każdemu z nich.
Karta Preprocess
Początkowo po otwarciu eksploratora tylko plik Preprocesskarta jest włączona. Pierwszym krokiem w uczeniu maszynowym jest wstępne przetwarzanie danych. Tak więc wPreprocess wybierzesz plik danych, przetworzysz go i dostosujesz do zastosowania różnych algorytmów uczenia maszynowego.
Zakładka Klasyfikuj
Plik Classifytab zawiera kilka algorytmów uczenia maszynowego do klasyfikacji danych. Aby wymienić kilka, możesz zastosować algorytmy, takie jak regresja liniowa, regresja logistyczna, maszyny wektorów nośnych, drzewa decyzyjne, drzewo losowe, RandomForest, NaiveBayes i tak dalej. Lista jest bardzo wyczerpująca i zawiera zarówno nadzorowane, jak i nienadzorowane algorytmy uczenia maszynowego.
Zakładka Cluster
Pod Cluster dostępnych jest kilka algorytmów klastrowania - takich jak SimpleKMeans, FilteredClusterer, HierarchicalClusterer i tak dalej.
Skojarz zakładkę
Pod Associate znajdziesz Apriori, FilteredAssociator i FPGrowth.
Wybierz kartę Atrybuty
Select Attributes umożliwia wybór funkcji na podstawie kilku algorytmów, takich jak ClassifierSubsetEval, PrinicipalComponents itp.
Karta wizualizacji
Wreszcie Visualize opcja umożliwia wizualizację przetworzonych danych do analizy.
Jak zauważyłeś, WEKA udostępnia kilka gotowych do użycia algorytmów do testowania i budowania aplikacji do uczenia maszynowego. Aby skutecznie używać WEKA, musisz mieć solidną wiedzę na temat tych algorytmów, ich działania, które wybrać w jakich okolicznościach, czego szukać w przetwarzanych przez nie danych wyjściowych i tak dalej. Krótko mówiąc, musisz mieć solidne podstawy do uczenia maszynowego, aby efektywnie wykorzystywać WEKA do tworzenia aplikacji.
W kolejnych rozdziałach szczegółowo przeanalizujesz każdą kartę w eksploratorze.
W tym rozdziale zaczynamy od pierwszej karty, której używasz do wstępnego przetwarzania danych. Jest to wspólne dla wszystkich algorytmów, które zastosowałbyś do swoich danych w celu zbudowania modelu i jest wspólnym krokiem dla wszystkich kolejnych operacji w WEKA.
Aby algorytm uczenia maszynowego zapewniał akceptowalną dokładność, ważne jest, aby najpierw wyczyścić dane. Dzieje się tak, ponieważ nieprzetworzone dane zebrane z pola mogą zawierać wartości null, nieistotne kolumny i tak dalej.
W tym rozdziale dowiesz się, jak wstępnie przetwarzać surowe dane i tworzyć czysty, zrozumiały zbiór danych do dalszego wykorzystania.
Najpierw nauczysz się ładować plik danych do eksploratora WEKA. Dane można załadować z następujących źródeł -
- Lokalny system plików
- Web
- Database
W tym rozdziale omówimy szczegółowo wszystkie trzy opcje ładowania danych.
Ładowanie danych z lokalnego systemu plików
Tuż pod kartami uczenia maszynowego, które studiowałeś w poprzedniej lekcji, znajdziesz następujące trzy przyciski -
- Otwórz plik …
- Otwórz URL …
- Otwórz bazę danych…
Kliknij na Open file... przycisk. Otworzy się okno nawigatora katalogów, jak pokazano na poniższym ekranie -
Teraz przejdź do folderu, w którym przechowywane są pliki danych. Instalacja WEKA zawiera wiele przykładowych baz danych do eksperymentowania. Są one dostępne wdata folder instalacji WEKA.
W celach edukacyjnych wybierz dowolny plik danych z tego folderu. Zawartość pliku zostanie załadowana w środowisku WEKA. Wkrótce dowiemy się, jak sprawdzać i przetwarzać te załadowane dane. Wcześniej przyjrzyjmy się, jak załadować plik danych z Internetu.
Ładowanie danych z sieci
Po kliknięciu Open URL … przycisk, możesz zobaczyć następujące okno -
Otworzymy plik z publicznego adresu URL Wpisz następujący adres URL w wyskakującym okienku -
https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff
Możesz podać dowolny inny adres URL, pod którym przechowywane są Twoje dane. PlikExplorer załaduje dane ze zdalnego miejsca do swojego środowiska.
Ładowanie danych z DB
Po kliknięciu Open DB ..., możesz zobaczyć następujące okno -
Ustaw parametry połączenia z bazą danych, skonfiguruj zapytanie o wybór danych, przetwórz zapytanie i załaduj wybrane rekordy do WEKA.
WEKA obsługuje wiele formatów plików danych. Oto pełna lista -
- arff
- arff.gz
- bsi
- csv
- dat
- data
- json
- json.gz
- libsvm
- m
- names
- xrff
- xrff.gz
Obsługiwane typy plików są wymienione na liście rozwijanej u dołu ekranu. Pokazuje to poniższy zrzut ekranu.
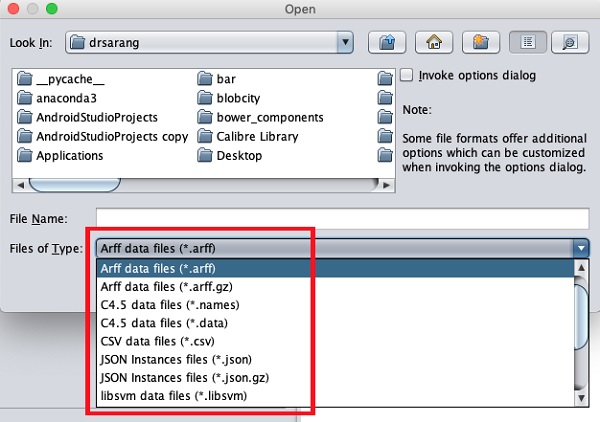
Jak można zauważyć, obsługuje kilka formatów, w tym CSV i JSON. Domyślnym typem pliku jest Arff.
Arff Format
Na Arff plik zawiera dwie sekcje - nagłówek i dane.
- Nagłówek opisuje typy atrybutów.
- Sekcja danych zawiera listę danych oddzielonych przecinkami.
Jako przykład dla formatu Arff, plik Weather plik danych załadowany z przykładowych baz danych WEKA pokazano poniżej -

Ze zrzutu ekranu można wywnioskować następujące punkty -
Znacznik @relation definiuje nazwę bazy danych.
Znacznik @attribute definiuje atrybuty.
Znacznik @data rozpoczyna listę wierszy danych, z których każdy zawiera pola oddzielone przecinkami.
Atrybuty mogą przyjmować wartości nominalne, jak w przypadku pokazanej tutaj perspektywy -
@attribute outlook (sunny, overcast, rainy)Atrybuty mogą przyjmować wartości rzeczywiste, tak jak w tym przypadku -
@attribute temperature realMożesz także ustawić zmienną Target lub Class o nazwie play, jak pokazano tutaj -
@attribute play (yes, no)Cel zakłada dwie wartości nominalne: tak lub nie.
Inne formaty
Eksplorator może załadować dane w każdym z wcześniej wymienionych formatów. Ponieważ arff jest preferowanym formatem w WEKA, możesz załadować dane z dowolnego formatu i zapisać je w formacie arff do późniejszego wykorzystania. Po wstępnym przetworzeniu danych po prostu zapisz je w formacie arff do dalszej analizy.
Teraz, gdy nauczyłeś się ładować dane do WEKA, w następnym rozdziale dowiesz się, jak wstępnie przetwarzać dane.
Dane zbierane z terenu zawierają wiele niepożądanych elementów, które prowadzą do błędnej analizy. Na przykład dane mogą zawierać puste pola, mogą zawierać kolumny, które nie mają znaczenia dla bieżącej analizy i tak dalej. W związku z tym dane muszą zostać wstępnie przetworzone, aby spełnić wymagania typu analizy, której szukasz. Jest to wykonywane w module przetwarzania wstępnego.
Aby zademonstrować dostępne funkcje w przetwarzaniu wstępnym, użyjemy Weather baza danych dostarczona podczas instalacji.
Używając Open file ... opcja pod Preprocess wybierz tag weather-nominal.arff plik.
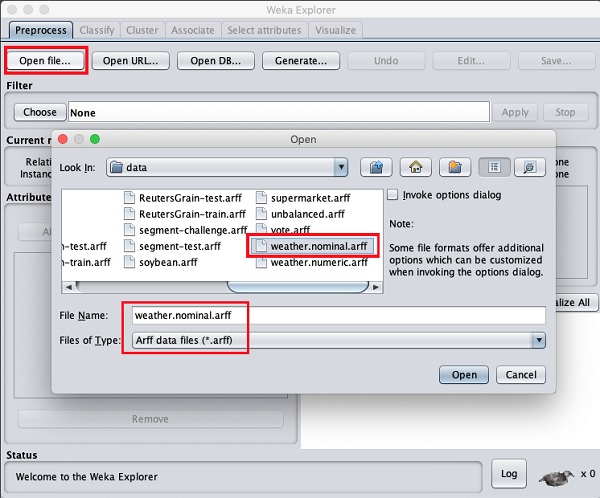
Po otwarciu pliku ekran wygląda tak, jak pokazano tutaj -
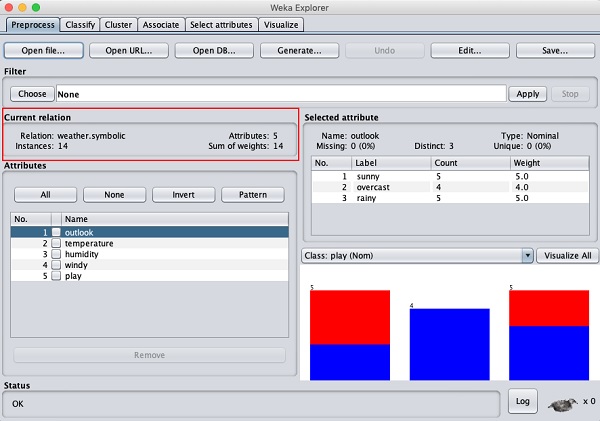
Ten ekran zawiera kilka informacji na temat załadowanych danych, które są omówione w dalszej części tego rozdziału.
Zrozumienie danych
Spójrzmy najpierw na podświetlone Current relationokno podrzędne. Pokazuje nazwę aktualnie załadowanej bazy danych. Z tego okna podrzędnego można wywnioskować dwa punkty -
Istnieje 14 instancji - liczba wierszy w tabeli.
Tabela zawiera 5 atrybutów - pól, które zostaną omówione w kolejnych rozdziałach.
Po lewej stronie zwróć uwagę na Attributes okno podrzędne, które wyświetla różne pola w bazie danych.
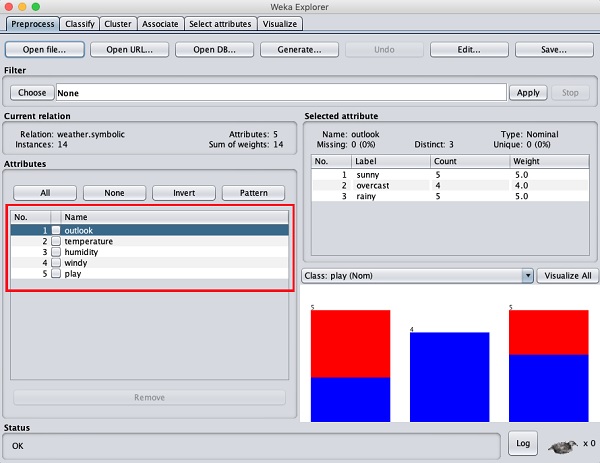
Plik weatherBaza danych zawiera pięć pól - perspektywy, temperaturę, wilgotność, wietrzność i zabawę. Po wybraniu atrybutu z tej listy, klikając go, dalsze szczegóły dotyczące samego atrybutu są wyświetlane po prawej stronie.
Najpierw wybierzmy atrybut temperatury. Po kliknięciu zobaczysz następujący ekran -
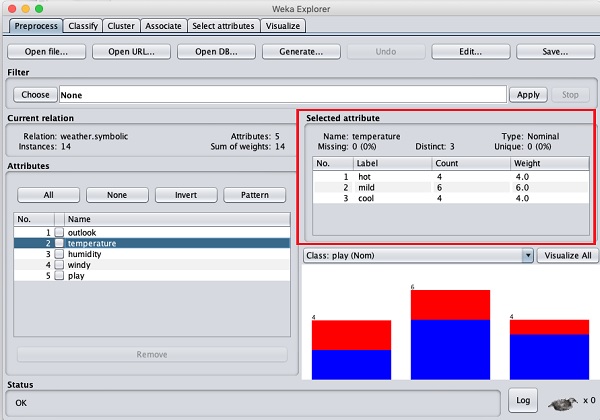
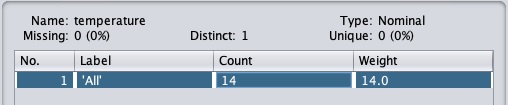
w Selected Attribute podokno, możesz zaobserwować następujące -
Wyświetlana jest nazwa i typ atrybutu.
Typ dla temperature atrybutem jest Nominal.
Liczba Missing wartości są równe zero.
Istnieją trzy różne wartości bez unikalnej wartości.
W tabeli poniżej tych informacji podano wartości nominalne dla tego pola, jako gorące, łagodne i zimne.
Pokazuje również liczbę i wagę w procentach dla każdej wartości nominalnej.
W dolnej części okna zobaczysz wizualną reprezentację pliku class wartości.
Jeśli klikniesz plik Visualize All przycisk, będziesz mógł zobaczyć wszystkie funkcje w jednym oknie, jak pokazano tutaj -
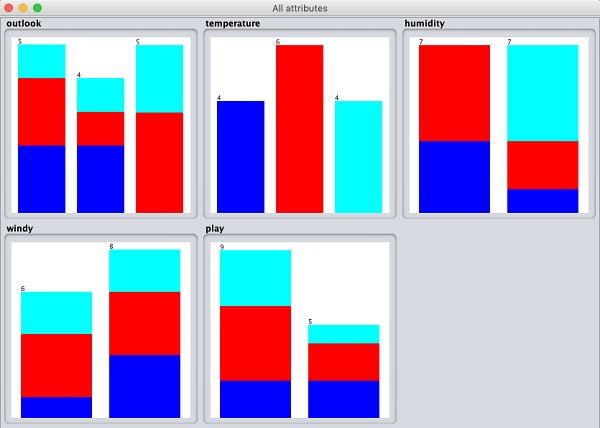
Usuwanie atrybutów
Często dane, których chcesz użyć do budowania modelu, zawierają wiele nieistotnych pól. Na przykład baza danych klientów może zawierać jego numer telefonu komórkowego, który jest istotny dla analizy jego zdolności kredytowej.
Aby usunąć atrybut / y, wybierz je i kliknij Remove przycisk na dole.
Wybrane atrybuty zostaną usunięte z bazy danych. Po całkowitym wstępnym przetworzeniu danych można je zapisać w celu zbudowania modelu.
Następnie nauczysz się wstępnie przetwarzać dane, stosując filtry do tych danych.
Stosowanie filtrów
Niektóre techniki uczenia maszynowego, takie jak eksploracja reguł asocjacji, wymagają danych kategorialnych. Aby zilustrować użycie filtrów, użyjemyweather-numeric.arff baza danych zawierająca dwa pliki numeric atrybuty - temperature i humidity.
Przekonwertujemy je na nominalstosując filtr do naszych surowych danych. Kliknij naChoose przycisk w Filter podokno i wybierz następujący filtr -
weka→filters→supervised→attribute→Discretize

Kliknij na Apply i zbadaj plik temperature i / lub humidityatrybut. Zauważysz, że zmieniły się one z typów numerycznych na nominalne.
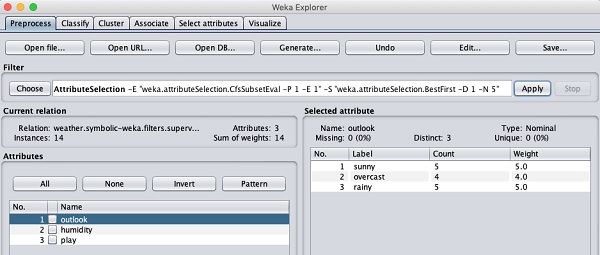
Przyjrzyjmy się teraz innemu filtrowi. Załóżmy, że chcesz wybrać najlepsze atrybuty do decydowania oplay. Wybierz i zastosuj następujący filtr -
weka→filters→supervised→attribute→AttributeSelection
Zauważysz, że usuwa atrybuty temperatury i wilgotności z bazy danych.
Gdy jesteś zadowolony z wstępnego przetwarzania danych, zapisz dane, klikając Save... przycisk. Będziesz używał tego zapisanego pliku do budowania modelu.
W następnym rozdziale zajmiemy się budowaniem modelu przy użyciu kilku predefiniowanych algorytmów ML.
Wiele aplikacji do uczenia maszynowego jest powiązanych z klasyfikacją. Na przykład możesz chcieć sklasyfikować guz jako złośliwy lub łagodny. Możesz zdecydować, czy zagrać w grę na zewnątrz, w zależności od warunków pogodowych. Ogólnie rzecz biorąc, decyzja ta zależy od kilku cech / warunków pogodowych. Więc może wolisz użyć klasyfikatora drzewka, aby podjąć decyzję, czy grać, czy nie.
W tym rozdziale dowiemy się, jak zbudować taki klasyfikator drzewkowy na podstawie danych pogodowych, aby decydować o warunkach gry.
Ustawianie danych testowych
Wykorzystamy wstępnie przetworzony plik danych pogodowych z poprzedniej lekcji. Otwórz zapisany plik przy użyciu rozszerzeniaOpen file ... opcja pod Preprocess kliknij kartę Classify i zobaczysz następujący ekran -
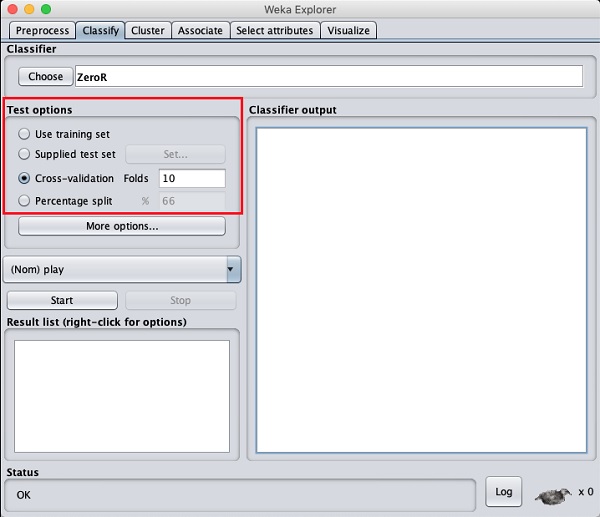
Zanim poznasz dostępne klasyfikatory, przyjrzyjmy się opcjom testu. Zauważysz cztery opcje testowania wymienione poniżej -
- Zestaw treningowy
- Dostarczony zestaw testowy
- Cross-validation
- Podział procentowy
Jeśli nie masz własnego zestawu treningowego lub zestawu testowego dostarczonego przez klienta, możesz użyć opcji walidacji krzyżowej lub podziału procentowego. W ramach walidacji krzyżowej można ustawić liczbę fałd, w których całe dane zostaną podzielone i użyte podczas każdej iteracji uczenia. W przypadku podziału procentowego dane zostaną podzielone między uczenie i testowanie przy użyciu ustawionego procentu podziału.
Teraz zachowaj domyślne play opcja dla klasy wyjściowej -
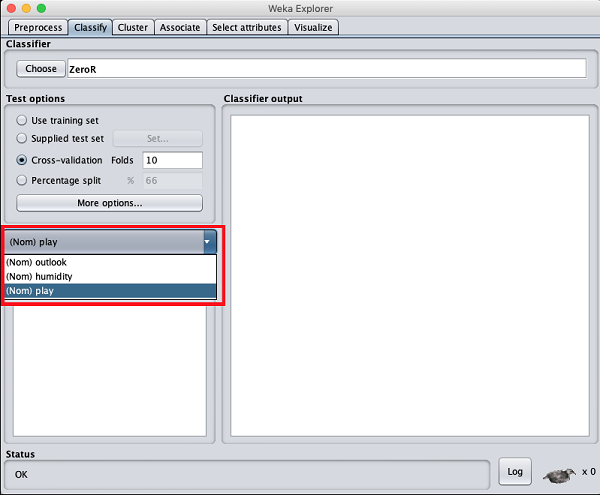
Następnie wybierzesz klasyfikator.
Wybieranie klasyfikatora
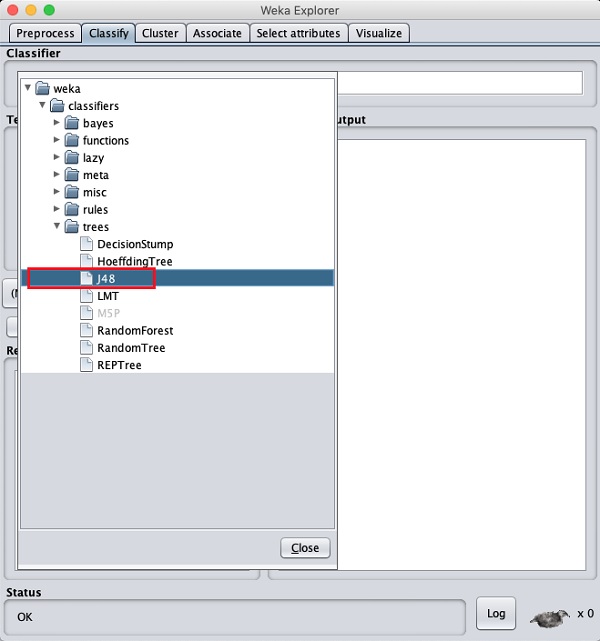
Kliknij przycisk Wybierz i wybierz następujący klasyfikator -
weka→classifiers>trees>J48
Jest to pokazane na poniższym zrzucie ekranu -
Kliknij na Startprzycisk, aby rozpocząć proces klasyfikacji. Po chwili wyniki klasyfikacji zostaną wyświetlone na ekranie, jak pokazano tutaj -
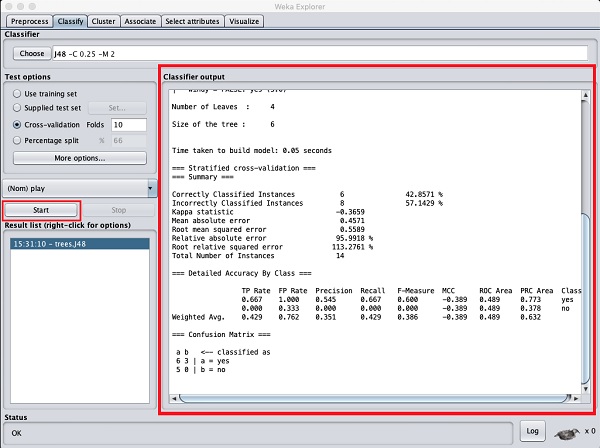
Przyjrzyjmy się wynikowi pokazanemu po prawej stronie ekranu.
Mówi, że rozmiar drzewa to 6. Wkrótce zobaczysz wizualną reprezentację drzewa. W Podsumowaniu jest napisane, że poprawnie sklasyfikowane instancje jako 2, a niepoprawnie sklasyfikowane jako 3, mówi również, że względny błąd bezwzględny wynosi 110%. Pokazuje również macierz zamieszania. Analiza tych wyników wykracza poza zakres tego samouczka. Jednak na podstawie tych wyników można łatwo wywnioskować, że klasyfikacja jest nie do przyjęcia i będziesz potrzebować więcej danych do analizy, aby udoskonalić wybór cech, przebudować model i tak dalej, aż będziesz zadowolony z dokładności modelu. W każdym razie o to chodzi w WEKA. Pozwala szybko przetestować swoje pomysły.
Wizualizuj wyniki
Aby zobaczyć wizualną reprezentację wyników, kliknij prawym przyciskiem myszy wynik w pliku Result listpudełko. Na ekranie pojawi się kilka opcji, jak pokazano tutaj -
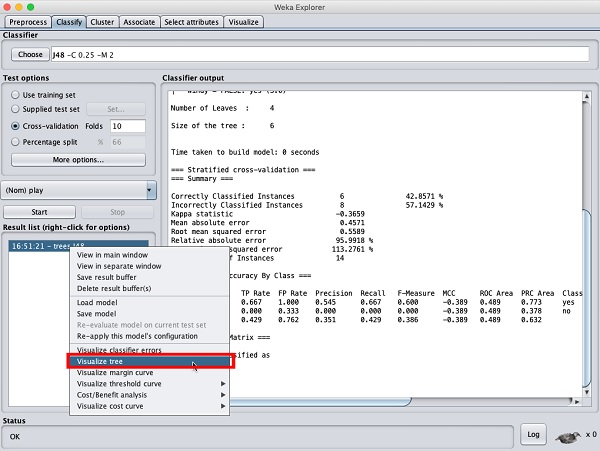
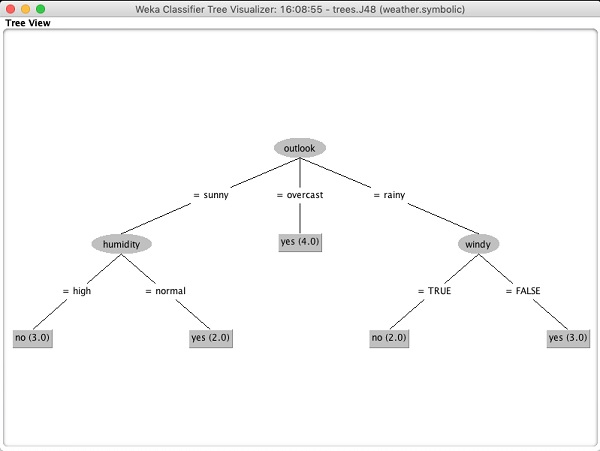
Wybierz Visualize tree aby uzyskać wizualną reprezentację drzewa przejścia, jak pokazano na zrzucie ekranu poniżej -
Wybieranie Visualize classifier errors wykreśli wyniki klasyfikacji, jak pokazano tutaj -
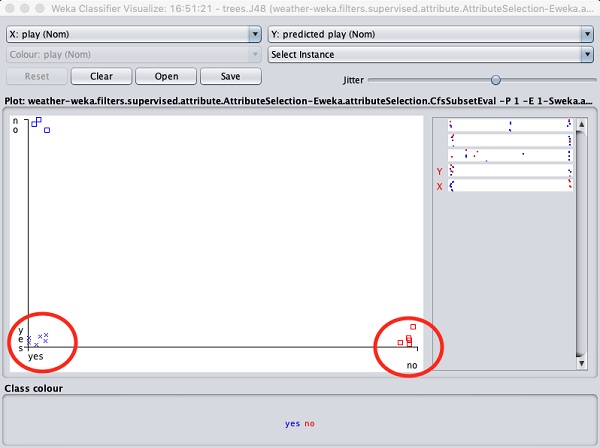
ZA cross reprezentuje poprawnie sklasyfikowaną instancję while squaresreprezentuje nieprawidłowo sklasyfikowane instancje. W lewym dolnym rogu wykresu widać znakcross to wskazuje, czy outlook jest wtedy słonecznie playgra. Więc to jest poprawnie sklasyfikowana instancja. Aby zlokalizować instancje, możesz wprowadzić do niej jitter, przesuwającjitter suwak.
Obecna fabuła to outlook przeciw play. Są one wskazywane przez dwa rozwijane pola listy u góry ekranu.
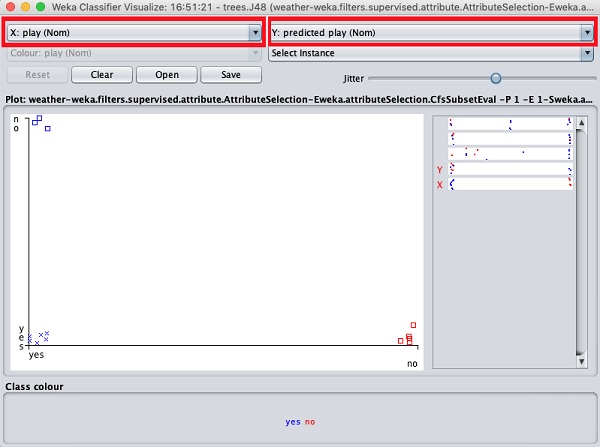
Teraz spróbuj innego wyboru w każdym z tych pól i zwróć uwagę, jak zmieniają się osie X i Y. To samo można osiągnąć, używając poziomych pasów po prawej stronie działki. Każdy pasek reprezentuje atrybut. Kliknięcie lewym przyciskiem myszy ustawia wybrany atrybut na osi X, natomiast prawym przyciskiem myszy ustawia go na osi Y.
Istnieje kilka innych wykresów do głębszej analizy. Używaj ich rozważnie, aby dostroić swój model. Jedna taka fabułaCost/Benefit analysis jest pokazany poniżej w celu szybkiego odniesienia.
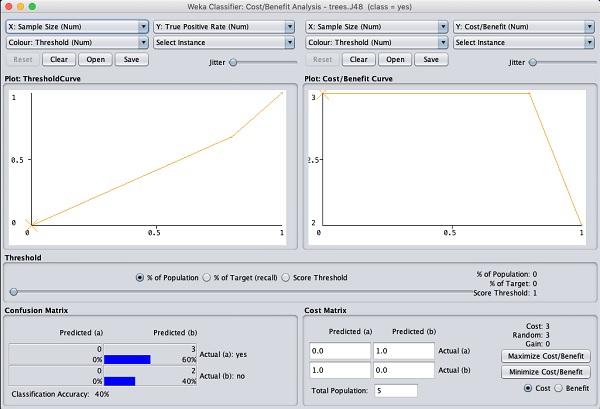
Wyjaśnienie analizy na tych wykresach wykracza poza zakres tego samouczka. Zachęcamy czytelników do odświeżenia wiedzy na temat analizy algorytmów uczenia maszynowego.
W kolejnym rozdziale poznamy kolejny zestaw algorytmów uczenia maszynowego, czyli grupowanie.
Algorytm grupowania znajduje grupy podobnych wystąpień w całym zbiorze danych. WEKA obsługuje kilka algorytmów klastrowania, takich jak EM, FilteredClusterer, HierarchicalClusterer, SimpleKMeans i tak dalej. Aby w pełni wykorzystać możliwości WEKA, należy całkowicie zrozumieć te algorytmy.
Podobnie jak w przypadku klasyfikacji, WEKA umożliwia graficzną wizualizację wykrytych klastrów. Aby zademonstrować klastrowanie, użyjemy dostarczonej bazy danych tęczówki. Zestaw danych zawiera trzy klasy po 50 instancji każda. Każda klasa odnosi się do rodzaju rośliny tęczówki.
Ładowanie danych
W eksploratorze WEKA wybierz plik Preprocesspatka. Kliknij naOpen file ... opcję i wybierz iris.arffplik w oknie dialogowym wyboru pliku. Po załadowaniu danych ekran wygląda jak poniżej -
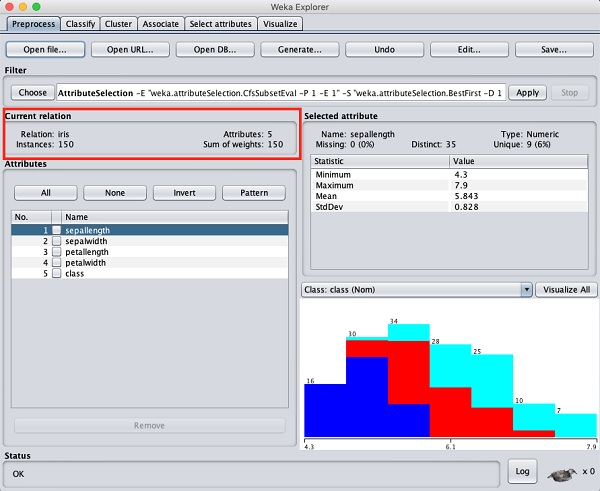
Możesz zauważyć, że istnieje 150 instancji i 5 atrybutów. Nazwy atrybutów są wymienione jakosepallength, sepalwidth, petallength, petalwidth i class. Pierwsze cztery atrybuty są typu liczbowego, podczas gdy klasa jest typem nominalnym z 3 różnymi wartościami. Sprawdź każdy atrybut, aby zrozumieć funkcje bazy danych. Nie będziemy dokonywać żadnego wstępnego przetwarzania tych danych i od razu przystąpimy do budowania modelu.
Grupowanie
Kliknij na ClusterTAB, aby zastosować algorytmy klastrowania do naszych załadowanych danych. Kliknij naChooseprzycisk. Zobaczysz następujący ekran -

Teraz wybierz EMjako algorytm grupowania. wCluster mode okno podrzędne, wybierz plik Classes to clusters evaluation opcja, jak pokazano na zrzucie ekranu poniżej -

Kliknij na Startprzycisk do przetwarzania danych. Po chwili wyniki zostaną wyświetlone na ekranie.
Następnie przeanalizujmy wyniki.
Badanie wyników
Wynik przetwarzania danych pokazano na poniższym ekranie -
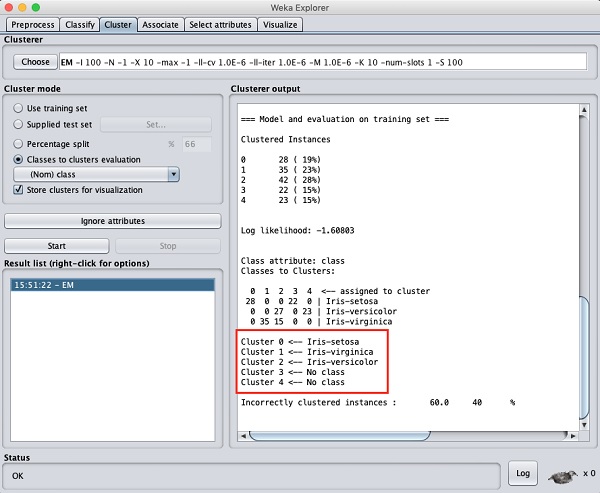
Na ekranie wyjściowym można zauważyć, że -
W bazie danych wykryto 5 instancji klastrowych.
Plik Cluster 0 reprezentuje setosę, Cluster 1 reprezentuje dziewicę, Cluster 2 reprezentuje versicolor, podczas gdy ostatnie dwie klastry nie mają skojarzonej z nimi żadnej klasy.
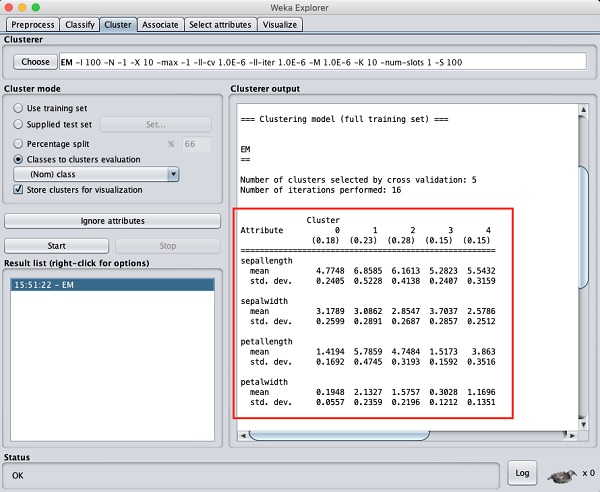
Jeśli przewiniesz okno wyników w górę, zobaczysz również statystyki, które przedstawiają średnią i odchylenie standardowe dla każdego z atrybutów w różnych wykrytych skupieniach. Jest to pokazane na zrzucie ekranu podanym poniżej -
Następnie przyjrzymy się wizualnej reprezentacji klastrów.
Wizualizacja klastrów
Aby zwizualizować klastry, kliknij prawym przyciskiem myszy plik EM wynik w Result list. Zobaczysz następujące opcje -
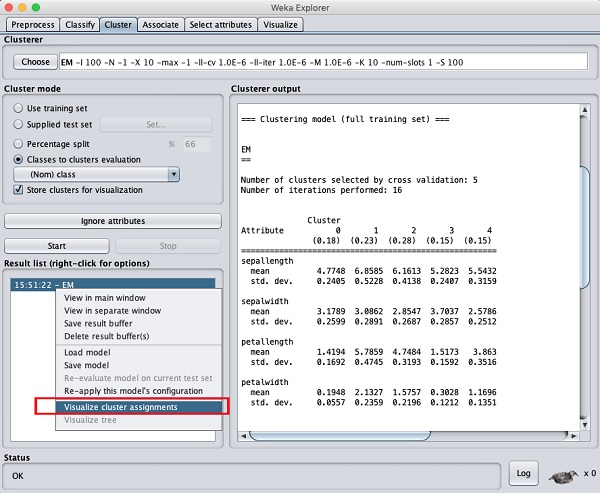
Wybierz Visualize cluster assignments. Zobaczysz następujący wynik -
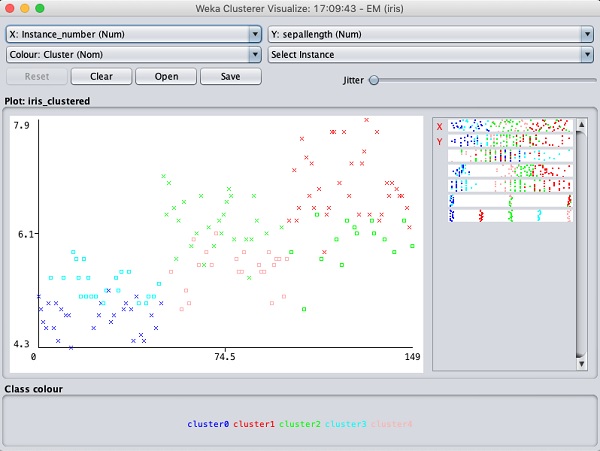
Podobnie jak w przypadku klasyfikacji, zauważysz różnicę między poprawnie a nieprawidłowo zidentyfikowanymi instancjami. Możesz bawić się, zmieniając osie X i Y, aby przeanalizować wyniki. Możesz użyć jittera, tak jak w przypadku klasyfikacji, aby sprawdzić stężenie poprawnie zidentyfikowanych instancji. Operacje na wykresie wizualizacji są podobne do tych, które badałeś w przypadku klasyfikacji.
Stosowanie klastra hierarchicznego
Aby zademonstrować siłę WEKA, przyjrzyjmy się teraz zastosowaniu innego algorytmu grupowania. W eksploratorze WEKA wybierz plikHierarchicalClusterer jako algorytm ML, jak pokazano na zrzucie ekranu pokazanym poniżej -
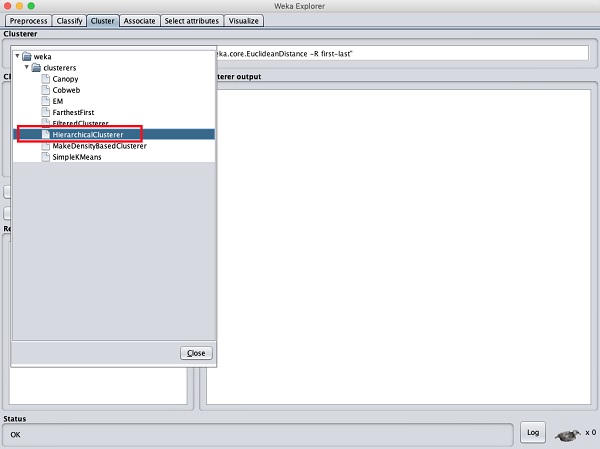
Wybierz Cluster mode wybór do Classes to cluster evaluationi kliknij Startprzycisk. Zobaczysz następujący wynik -
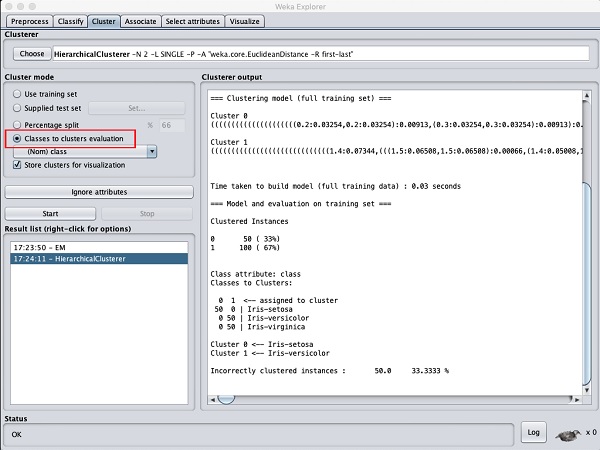
Zauważ, że w Result list, na liście są dwa wyniki: pierwszy to wynik EM, a drugi to bieżąca hierarchia. Podobnie można zastosować wiele algorytmów ML do tego samego zbioru danych i szybko porównać ich wyniki.
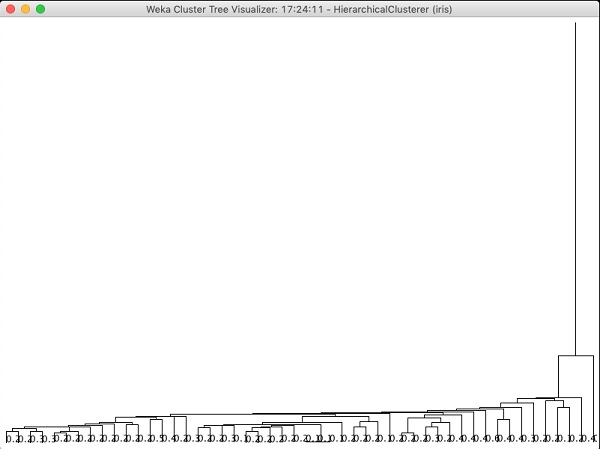
Jeśli zbadasz drzewo utworzone przez ten algorytm, zobaczysz następujący wynik -
W następnym rozdziale nauczysz się Associate rodzaj algorytmów ML.
Zaobserwowano, że osoby kupujące piwo kupują jednocześnie pieluchy. To znaczy, że istnieje stowarzyszenie kupujące razem piwo i pieluchy. Chociaż nie wydaje się to zbyt przekonujące, ta reguła stowarzyszenia została wydobyta z ogromnych baz danych supermarketów. Podobnie można znaleźć związek między masłem orzechowym a chlebem.
Znalezienie takich skojarzeń staje się istotne dla supermarketów, ponieważ obok piwa sprzedawaliby pieluchy, aby klienci mogli łatwo zlokalizować oba produkty, co skutkuje zwiększoną sprzedażą w supermarkecie.
Plik AprioriAlgorytm jest jednym z takich algorytmów w ML, który wyszukuje prawdopodobne skojarzenia i tworzy reguły asocjacyjne. WEKA zapewnia implementację algorytmu Apriori. Podczas obliczania tych reguł można zdefiniować minimalne wsparcie i akceptowalny poziom ufności. ZastosujeszApriori algorytm do supermarket dane podane w instalacji WEKA.
Ładowanie danych
W eksploratorze WEKA otwórz plik Preprocess kliknij kartę Open file ... i wybierz supermarket.arffbaza danych z folderu instalacyjnego. Po załadowaniu danych zobaczysz następujący ekran -
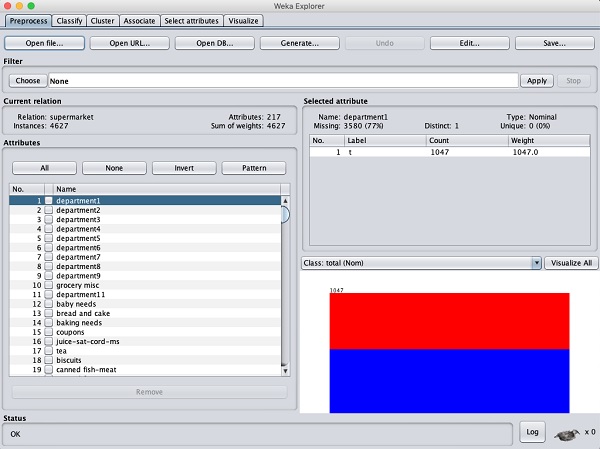
Baza danych zawiera 4627 instancji i 217 atrybutów. Możesz łatwo zrozumieć, jak trudne byłoby wykrycie związku między tak dużą liczbą atrybutów. Na szczęście zadanie to jest zautomatyzowane przy pomocy algorytmu Apriori.
Associator
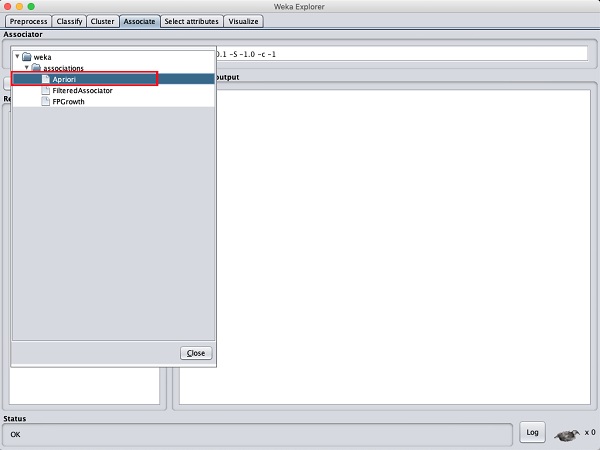
Kliknij na Associate TAB i kliknij Chooseprzycisk. WybierzApriori skojarzenie, jak pokazano na zrzucie ekranu -
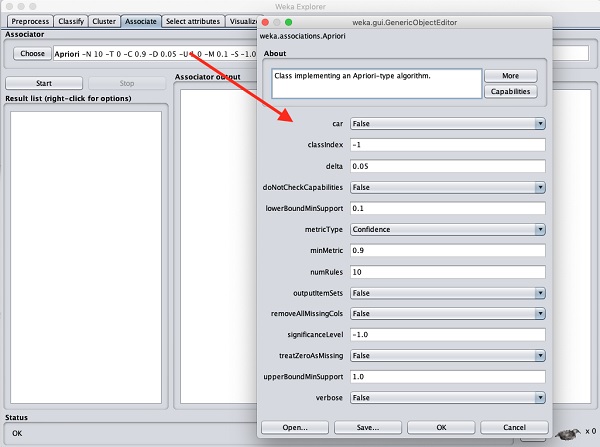
Aby ustawić parametry algorytmu Apriori, kliknij jego nazwę, pojawi się okno pokazane poniżej, w którym można ustawić parametry -
Po ustawieniu parametrów kliknij plik Startprzycisk. Po chwili zobaczysz wyniki, jak pokazano na poniższym zrzucie ekranu -
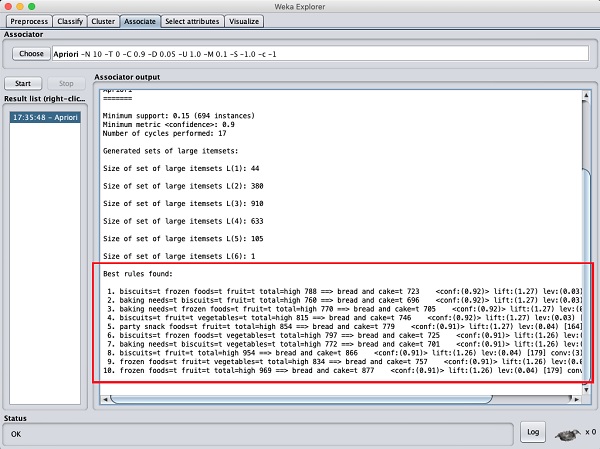
U dołu znajdziesz wykryte najlepsze reguły asocjacji. Pomoże to supermarketowi w magazynowaniu produktów na odpowiednich półkach.
Gdy baza danych zawiera dużą liczbę atrybutów, będzie kilka atrybutów, które nie będą miały znaczenia w analizie, której aktualnie szukasz. W związku z tym usuwanie niepożądanych atrybutów ze zbioru danych staje się ważnym zadaniem w tworzeniu dobrego modelu uczenia maszynowego.
Możesz wizualnie zbadać cały zbiór danych i zdecydować o nieistotnych atrybutach. Może to być ogromne zadanie w przypadku baz danych zawierających dużą liczbę atrybutów, takich jak przypadek supermarketu, który widziałeś na wcześniejszej lekcji. Na szczęście WEKA udostępnia zautomatyzowane narzędzie do wyboru cech.
W tym rozdziale przedstawiono tę funkcję w bazie danych zawierającej dużą liczbę atrybutów.
Ładowanie danych
w Preprocess w eksploratorze WEKA, wybierz plik labor.arffplik do załadowania do systemu. Po załadowaniu danych zobaczysz następujący ekran -
Zauważ, że istnieje 17 atrybutów. Naszym zadaniem jest stworzenie zredukowanego zbioru danych poprzez wyeliminowanie niektórych atrybutów, które nie mają znaczenia dla naszej analizy.
Funkcje ekstrakcji
Kliknij na Select attributesTAB. Pojawi się następujący ekran -
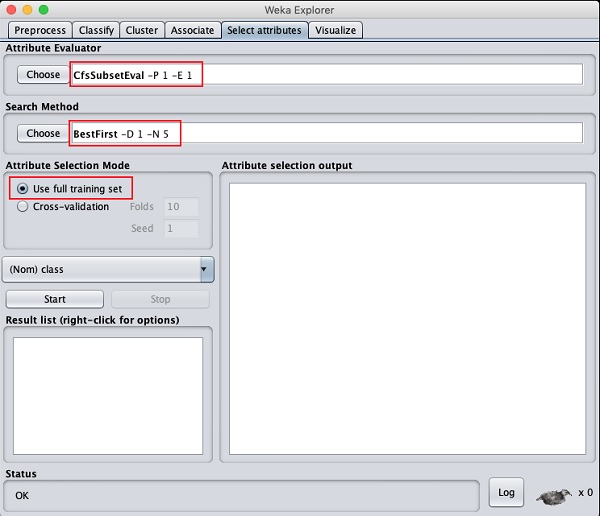
Pod Attribute Evaluator i Search Methodznajdziesz kilka opcji. Użyjemy tutaj tylko wartości domyślnych. wAttribute Selection Modeużyj opcji pełnego zestawu treningowego.
Kliknij przycisk Start, aby przetworzyć zbiór danych. Zobaczysz następujący wynik -

U dołu okna wyników pojawi się lista Selectedatrybuty. Aby uzyskać reprezentację wizualną, kliknij prawym przyciskiem myszy wynik w plikuResult lista.
Dane wyjściowe pokazano na poniższym zrzucie ekranu -
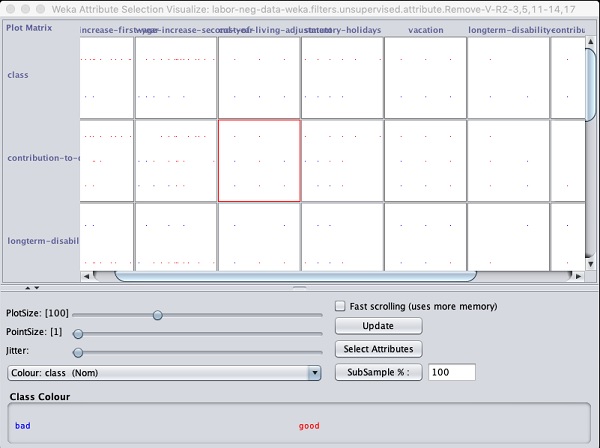
Kliknięcie dowolnego kwadratu spowoduje wyświetlenie wykresu danych do dalszej analizy. Poniżej przedstawiono typowy wykres danych -
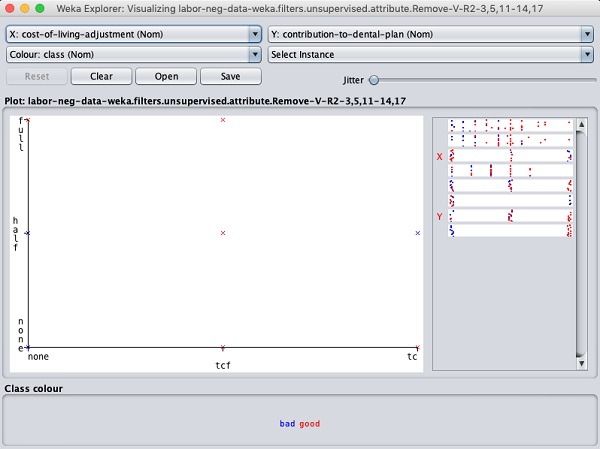
Jest to podobne do tych, które widzieliśmy we wcześniejszych rozdziałach. Baw się różnymi dostępnymi opcjami, aby analizować wyniki.
Co dalej?
Do tej pory widzieliście siłę WEKA w szybkim tworzeniu modeli uczenia maszynowego. Użyliśmy narzędzia graficznego o nazwieExplorerdo opracowania tych modeli. WEKA zapewnia również interfejs wiersza poleceń, który zapewnia więcej możliwości niż w eksploratorze.
Kliknięcie Simple CLI przycisk w GUI Chooser aplikacja uruchamia ten interfejs wiersza poleceń, który pokazano na zrzucie ekranu poniżej -
Wpisz swoje polecenia w polu wprowadzania na dole. Będziesz mógł zrobić wszystko, co zrobiłeś do tej pory w eksploratorze, a także znacznie więcej. Więcej informacji można znaleźć w dokumentacji WEKA (https://www.cs.waikato.ac.nz/ml/weka/documentation.html).
Wreszcie WEKA jest rozwijana w Javie i zapewnia interfejs dla swojego API. Jeśli więc jesteś programistą Java i chcesz włączyć implementacje WEKA ML do swoich własnych projektów Java, możesz to łatwo zrobić.
Wniosek
WEKA to potężne narzędzie do tworzenia modeli uczenia maszynowego. Zapewnia implementację kilku najczęściej używanych algorytmów ML. Przed zastosowaniem tych algorytmów do zbioru danych można również wstępnie przetworzyć dane. Typy obsługiwanych algorytmów są sklasyfikowane w atrybutach Klasyfikuj, Klaster, Skojarz i Wybierz. Rezultat na różnych etapach przetwarzania można wizualizować za pomocą pięknej i potężnej reprezentacji wizualnej. Ułatwia to analitykowi danych szybkie zastosowanie różnych technik uczenia maszynowego w swoim zbiorze danych, porównanie wyników i stworzenie najlepszego modelu do ostatecznego wykorzystania.