Apache Solr - no Hadoop
Solr pode ser usado junto com o Hadoop. Como o Hadoop lida com uma grande quantidade de dados, o Solr nos ajuda a encontrar as informações necessárias de uma fonte tão grande. Nesta seção, vamos entender como você pode instalar o Hadoop em seu sistema.
Baixando Hadoop
A seguir, estão as etapas a serem seguidas para baixar o Hadoop em seu sistema.
Step 1- Vá para a página inicial do Hadoop. Você pode usar o link - www.hadoop.apache.org/ . Clique no linkReleases, conforme destacado na captura de tela a seguir.
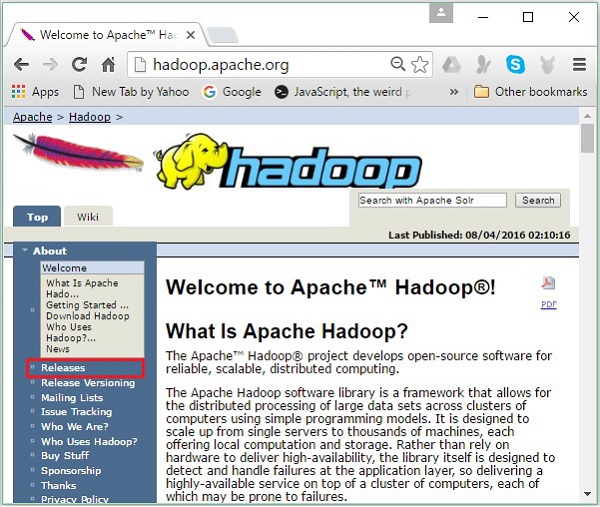
Ele irá redirecioná-lo para o Apache Hadoop Releases página que contém links para espelhos de arquivos de origem e binários de várias versões do Hadoop como segue -
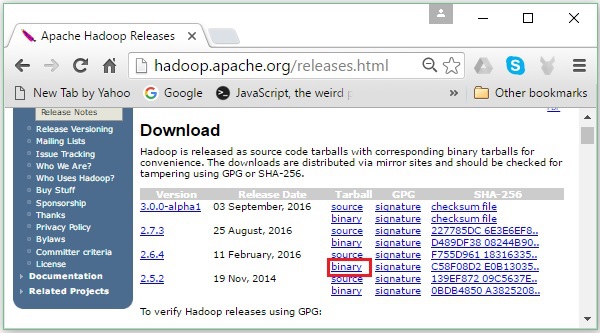
Step 2 - Selecione a versão mais recente do Hadoop (em nosso tutorial, é 2.6.4) e clique em seu binary link. Isso o levará a uma página onde os espelhos para o binário do Hadoop estão disponíveis. Clique em um desses mirrors para baixar o Hadoop.
Baixe o Hadoop no prompt de comando
Abra o terminal Linux e faça login como superusuário.
$ su
password:Vá para o diretório onde você precisa instalar o Hadoop e salve o arquivo usando o link copiado anteriormente, conforme mostrado no bloco de código a seguir.
# cd /usr/local
# wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop-
2.6.4/hadoop-2.6.4.tar.gzDepois de baixar o Hadoop, extraia-o usando os comandos a seguir.
# tar zxvf hadoop-2.6.4.tar.gz
# mkdir hadoop
# mv hadoop-2.6.4/* to hadoop/
# exitInstalando o Hadoop
Siga as etapas abaixo para instalar Hadoop no modo pseudo-distribuído.
Etapa 1: Configurando o Hadoop
Você pode definir as variáveis de ambiente Hadoop anexando os seguintes comandos a ~/.bashrc Arquivo.
export HADOOP_HOME = /usr/local/hadoop export
HADOOP_MAPRED_HOME = $HADOOP_HOME export
HADOOP_COMMON_HOME = $HADOOP_HOME export
HADOOP_HDFS_HOME = $HADOOP_HOME export
YARN_HOME = $HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native
export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL = $HADOOP_HOMEEm seguida, aplique todas as alterações no sistema em execução atual.
$ source ~/.bashrcEtapa 2: configuração do Hadoop
Você pode encontrar todos os arquivos de configuração do Hadoop no local “$ HADOOP_HOME / etc / hadoop”. É necessário fazer alterações nesses arquivos de configuração de acordo com sua infraestrutura Hadoop.
$ cd $HADOOP_HOME/etc/hadoopPara desenvolver programas Hadoop em Java, você deve redefinir as variáveis de ambiente Java em hadoop-env.sh arquivo substituindo JAVA_HOME valor com a localização do Java em seu sistema.
export JAVA_HOME = /usr/local/jdk1.7.0_71A seguir está a lista de arquivos que você deve editar para configurar o Hadoop -
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
o core-site.xml arquivo contém informações como o número da porta usado para a instância do Hadoop, memória alocada para o sistema de arquivos, limite de memória para armazenar os dados e tamanho dos buffers de leitura / gravação.
Abra o core-site.xml e adicione as seguintes propriedades dentro das tags <configuration>, </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
o hdfs-site.xml arquivo contém informações como o valor dos dados de replicação, namenode caminho, e datanodecaminhos de seus sistemas de arquivos locais. Significa o local onde você deseja armazenar a infraestrutura do Hadoop.
Vamos supor os seguintes dados.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeAbra este arquivo e adicione as seguintes propriedades dentro das marcas <configuration>, </configuration>.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note - No arquivo acima, todos os valores de propriedade são definidos pelo usuário e você pode fazer alterações de acordo com sua infraestrutura Hadoop.
yarn-site.xml
Este arquivo é usado para configurar o yarn no Hadoop. Abra o arquivo yarn-site.xml e adicione as seguintes propriedades entre as marcas <configuration>, </configuration> neste arquivo.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Este arquivo é usado para especificar qual estrutura MapReduce estamos usando. Por padrão, o Hadoop contém um modelo de yarn-site.xml. Em primeiro lugar, é necessário copiar o arquivo demapred-site,xml.template para mapred-site.xml arquivo usando o seguinte comando.
$ cp mapred-site.xml.template mapred-site.xmlAbrir mapred-site.xml arquivo e adicione as seguintes propriedades dentro das marcas <configuration>, </configuration>.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Verificando a instalação do Hadoop
As etapas a seguir são usadas para verificar a instalação do Hadoop.
Etapa 1: configuração do nó de nome
Configure o namenode usando o comando "hdfs namenode –format" da seguinte maneira.
$ cd ~
$ hdfs namenode -formatO resultado esperado é o seguinte.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Etapa 2: verificar o dfs do Hadoop
O seguinte comando é usado para iniciar o Hadoop dfs. A execução desse comando iniciará seu sistema de arquivos Hadoop.
$ start-dfs.shA saída esperada é a seguinte -
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Etapa 3: Verificar o script do Yarn
O seguinte comando é usado para iniciar o script Yarn. Executar este comando iniciará seus demônios Yarn.
$ start-yarn.shA saída esperada da seguinte forma -
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.6.4/logs/yarn-hadoop-nodemanager-localhost.outEtapa 4: Acessando o Hadoop no navegador
O número da porta padrão para acessar o Hadoop é 50070. Use a seguinte URL para obter serviços Hadoop no navegador.
http://localhost:50070/
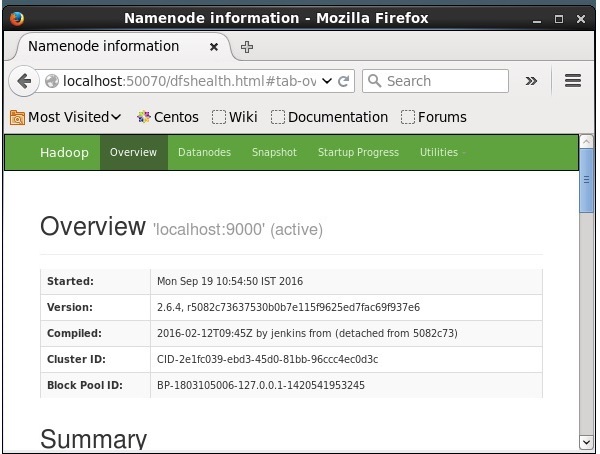
Instalando Solr no Hadoop
Siga as etapas abaixo para baixar e instalar o Solr.
Passo 1
Abra a página inicial do Apache Solr clicando no seguinte link - https://lucene.apache.org/solr/
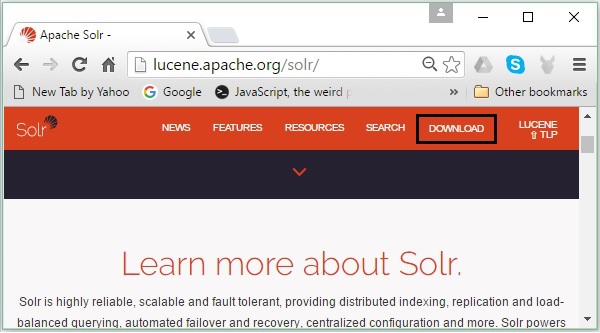
Passo 2
Clique no download button(destacado na imagem acima). Ao clicar, você será redirecionado para a página onde você tem vários mirrors do Apache Solr. Selecione um espelho e clique nele, que o redirecionará para uma página onde você pode baixar os arquivos fonte e binários do Apache Solr, como mostrado na imagem a seguir.
etapa 3
Ao clicar, uma pasta chamada Solr-6.2.0.tqzserá baixado na pasta de downloads do seu sistema. Extraia o conteúdo da pasta baixada.
Passo 4
Crie uma pasta chamada Solr no diretório inicial do Hadoop e mova o conteúdo da pasta extraída para ela, conforme mostrado abaixo.
$ mkdir Solr
$ cd Downloads
$ mv Solr-6.2.0 /home/Hadoop/Verificação
Navegue pelo bin pasta do diretório Home do Solr e verifique a instalação usando o version opção, conforme mostrado no seguinte bloco de código.
$ cd bin/
$ ./Solr version
6.2.0Definindo casa e caminho
Abra o .bashrc arquivo usando o seguinte comando -
[Hadoop@localhost ~]$ source ~/.bashrcAgora defina os diretórios home e path para o Apache Solr da seguinte maneira -
export SOLR_HOME = /home/Hadoop/Solr
export PATH = $PATH:/$SOLR_HOME/bin/Abra o terminal e execute o seguinte comando -
[Hadoop@localhost Solr]$ source ~/.bashrcAgora, você pode executar os comandos do Solr de qualquer diretório.