Apache Solr - Guia rápido
Solr é uma plataforma de pesquisa de código aberto que é usada para construir search applications. Foi construído em cima deLucene(motor de pesquisa de texto completo). Solr está pronto para a empresa, rápido e altamente escalável. Os aplicativos desenvolvidos com o Solr são sofisticados e oferecem alto desempenho.
isso foi Yonik Seelyque criou o Solr em 2004 para adicionar recursos de pesquisa ao site da empresa da CNET Networks. Em janeiro de 2006, foi transformado em um projeto de código aberto sob a Apache Software Foundation. Sua última versão, Solr 6.0, foi lançada em 2016 com suporte para execução de consultas SQL paralelas.
Solr pode ser usado junto com o Hadoop. Como o Hadoop lida com uma grande quantidade de dados, o Solr nos ajuda a encontrar as informações necessárias de uma fonte tão grande. Além de pesquisar, o Solr também pode ser usado para fins de armazenamento. Como outros bancos de dados NoSQL, é umnon-relational data storage e processing technology.
Resumindo, o Solr é um mecanismo de pesquisa / armazenamento escalável e pronto para implantar, otimizado para pesquisar grandes volumes de dados centrados em texto.
Recursos do Apache Solr
Solr envolve a API Java do Lucene. Portanto, usando o Solr, você pode aproveitar todos os recursos do Lucene. Vamos dar uma olhada em algumas das características mais importantes do Solr -
Restful APIs- Para se comunicar com o Solr, não é obrigatório ter conhecimentos de programação Java. Em vez disso, você pode usar serviços de descanso para se comunicar com ele. Entramos documentos no Solr em formatos de arquivo como XML, JSON e .CSV e obtemos resultados nos mesmos formatos de arquivo.
Full text search - Solr fornece todos os recursos necessários para uma pesquisa de texto completo, como tokens, frases, verificação ortográfica, curinga e preenchimento automático.
Enterprise ready - De acordo com a necessidade da organização, o Solr pode ser implantado em qualquer tipo de sistema (grande ou pequeno) como autônomo, distribuído, nuvem, etc.
Flexible and Extensible - Ao estender as classes Java e configurar de acordo, podemos personalizar os componentes do Solr facilmente.
NoSQL database - Solr também pode ser usado como banco de dados NOSQL de big data scale, onde podemos distribuir as tarefas de pesquisa ao longo de um cluster.
Admin Interface - Solr fornece uma interface de usuário fácil de usar, amigável e com recursos, com a qual podemos realizar todas as tarefas possíveis, como gerenciar logs, adicionar, excluir, atualizar e pesquisar documentos.
Highly Scalable - Ao usar o Solr com Hadoop, podemos dimensionar sua capacidade adicionando réplicas.
Text-Centric and Sorted by Relevance - Solr é usado principalmente para pesquisar documentos de texto e os resultados são entregues de acordo com a relevância com a consulta do usuário na ordem.
Ao contrário do Lucene, você não precisa ter habilidades de programação Java ao trabalhar com o Apache Solr. Ele fornece um serviço maravilhoso pronto para implantar para construir uma caixa de pesquisa com preenchimento automático, que o Lucene não fornece. Usando o Solr, podemos dimensionar, distribuir e gerenciar índices para aplicativos de grande escala (Big Data).
Lucene em aplicativos de pesquisa
Lucene é uma biblioteca de pesquisa simples, mas poderosa, baseada em Java. Ele pode ser usado em qualquer aplicativo para adicionar capacidade de pesquisa. Lucene é uma biblioteca escalável e de alto desempenho usada para indexar e pesquisar virtualmente qualquer tipo de texto. A biblioteca Lucene fornece as operações principais que são exigidas por qualquer aplicativo de pesquisa, comoIndexing e Searching.
Se tivermos um portal da web com um grande volume de dados, provavelmente precisaremos de um mecanismo de pesquisa em nosso portal para extrair informações relevantes do enorme pool de dados. O Lucene funciona como o coração de qualquer aplicativo de pesquisa e fornece as operações vitais relativas à indexação e pesquisa.
Um mecanismo de pesquisa se refere a um enorme banco de dados de recursos da Internet, como páginas da web, grupos de notícias, programas, imagens, etc. Ajuda a localizar informações na rede mundial de computadores.
Os usuários podem pesquisar informações passando consultas no mecanismo de pesquisa na forma de palavras-chave ou frases. O Search Engine então pesquisa em seu banco de dados e retorna links relevantes para o usuário.
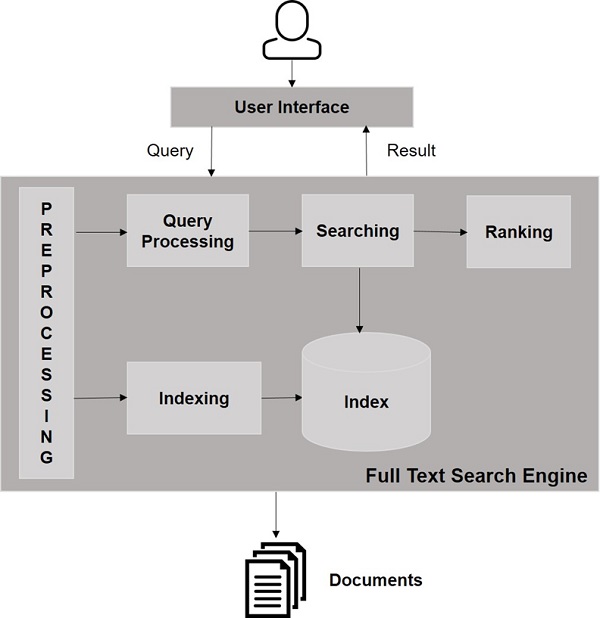
Componentes do Search Engine
Geralmente, existem três componentes básicos de um mecanismo de pesquisa, conforme listado abaixo -
Web Crawler - Os rastreadores da web também são conhecidos como spiders ou bots. É um componente de software que percorre a web para coletar informações.
Database- Todas as informações da Web são armazenadas em bancos de dados. Eles contêm um grande volume de recursos da web.
Search Interfaces- Este componente é uma interface entre o usuário e o banco de dados. Ajuda o usuário a pesquisar no banco de dados.
Como funcionam os motores de busca?
Qualquer aplicativo de pesquisa é necessário para realizar algumas ou todas as operações a seguir.
| Degrau | Título | Descrição |
|---|---|---|
1 |
Adquirir conteúdo bruto |
A primeira etapa de qualquer aplicativo de pesquisa é coletar o conteúdo de destino no qual a pesquisa deve ser realizada. |
2 |
Construir o documento |
A próxima etapa é construir o (s) documento (s) a partir do conteúdo bruto que o aplicativo de pesquisa pode entender e interpretar facilmente. |
3 |
Analise o documento |
Antes de iniciar a indexação, o documento deve ser analisado. |
4 |
Indexando o documento |
Uma vez que os documentos são construídos e analisados, o próximo passo é indexá-los para que este documento possa ser recuperado com base em certas chaves, ao invés de todo o conteúdo do documento. A indexação é semelhante aos índices que temos no final de um livro, onde palavras comuns são mostradas com seus números de página para que essas palavras possam ser rastreadas rapidamente, em vez de pesquisar o livro completo. |
5 |
Interface do usuário para pesquisa |
Assim que um banco de dados de índices estiver pronto, o aplicativo pode realizar operações de pesquisa. Para ajudar o usuário a fazer uma pesquisa, o aplicativo deve fornecer uma interface de usuário onde o usuário pode inserir texto e iniciar o processo de pesquisa |
6 |
Build Query |
Depois que o usuário faz uma solicitação para pesquisar um texto, o aplicativo deve preparar um objeto de consulta usando esse texto, que pode ser usado para consultar o banco de dados de índice para obter detalhes relevantes. |
7 |
Consulta de pesquisa |
Usando o objeto de consulta, o banco de dados de índice é verificado para obter os detalhes relevantes e os documentos de conteúdo. |
8 |
Resultados de renderização |
Assim que o resultado necessário for recebido, o aplicativo deve decidir como exibir os resultados para o usuário usando sua interface de usuário. |
Dê uma olhada na ilustração a seguir. Ele mostra uma visão geral de como funcionam os motores de busca.
Além dessas operações básicas, os aplicativos de pesquisa também podem fornecer interface de usuário de administração para ajudar os administradores a controlar o nível de pesquisa com base nos perfis de usuário. A análise do resultado da pesquisa é outro aspecto importante e avançado de qualquer aplicativo de pesquisa.
Neste capítulo, discutiremos como configurar o Solr no ambiente Windows. Para instalar o Solr em seu sistema Windows, você precisa seguir os passos abaixo -
Visite a página inicial do Apache Solr e clique no botão de download.
Selecione um dos espelhos para obter um índice do Apache Solr. De lá, baixe o arquivo chamadoSolr-6.2.0.zip.
Mova o arquivo do downloads folder para o diretório necessário e descompacte-o.
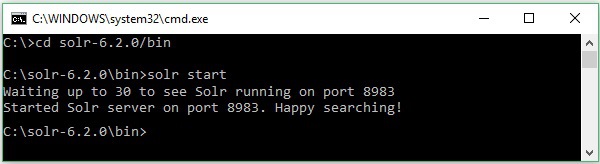
Suponha que você baixou o arquivo Solr e o extraiu para a unidade C. Nesse caso, você pode iniciar o Solr conforme mostrado na imagem a seguir.
Para verificar a instalação, use o seguinte URL em seu navegador.
http://localhost:8983/
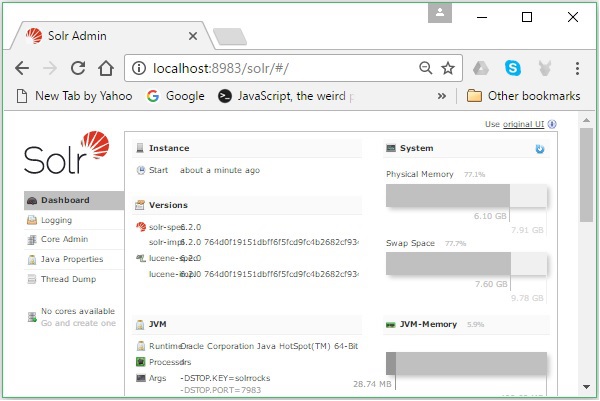
Se o processo de instalação for bem-sucedido, você verá o painel da interface do usuário do Apache Solr conforme mostrado abaixo.
Configurando o ambiente Java
Também podemos nos comunicar com o Apache Solr usando bibliotecas Java; mas antes de acessar o Solr usando a API Java, você precisa definir o classpath para essas bibliotecas.
Configurando o Classpath
Colocou o classpath para bibliotecas Solr no .bashrcArquivo. Abrir.bashrc em qualquer um dos editores conforme mostrado abaixo.
$ gedit ~/.bashrcDefinir classpath para bibliotecas Solr (lib pasta no HBase) conforme mostrado abaixo.
export CLASSPATH = $CLASSPATH://home/hadoop/Solr/lib/*Isso evita a exceção “classe não encontrada” ao acessar o HBase usando a API Java.
Solr pode ser usado junto com o Hadoop. Como o Hadoop lida com uma grande quantidade de dados, o Solr nos ajuda a encontrar as informações necessárias de uma fonte tão grande. Nesta seção, vamos entender como você pode instalar o Hadoop em seu sistema.
Baixando Hadoop
A seguir, estão as etapas a serem seguidas para baixar o Hadoop em seu sistema.
Step 1- Vá para a página inicial do Hadoop. Você pode usar o link - www.hadoop.apache.org/ . Clique no linkReleases, conforme destacado na captura de tela a seguir.
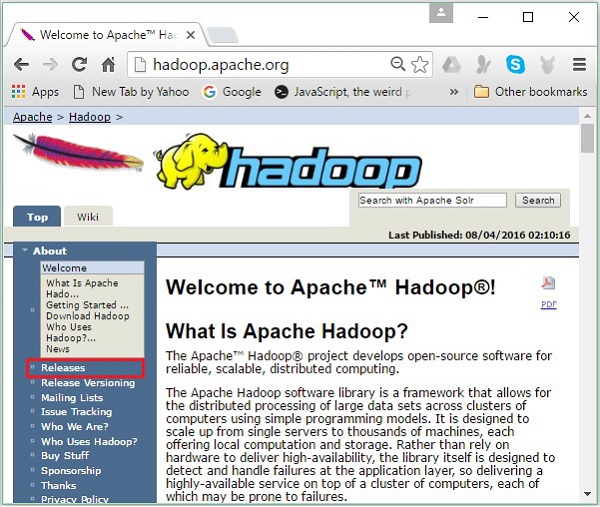
Ele irá redirecioná-lo para o Apache Hadoop Releases página que contém links para espelhos de arquivos de origem e binários de várias versões do Hadoop como segue -
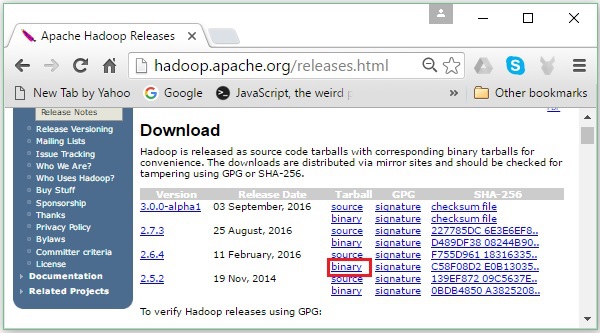
Step 2 - Selecione a versão mais recente do Hadoop (em nosso tutorial, é 2.6.4) e clique em seu binary link. Isso o levará a uma página onde os espelhos para o binário do Hadoop estão disponíveis. Clique em um desses mirrors para baixar o Hadoop.
Baixe o Hadoop no prompt de comando
Abra o terminal Linux e faça login como superusuário.
$ su
password:Vá para o diretório onde você precisa instalar o Hadoop e salve o arquivo usando o link copiado anteriormente, conforme mostrado no bloco de código a seguir.
# cd /usr/local
# wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop-
2.6.4/hadoop-2.6.4.tar.gzDepois de baixar o Hadoop, extraia-o usando os comandos a seguir.
# tar zxvf hadoop-2.6.4.tar.gz
# mkdir hadoop
# mv hadoop-2.6.4/* to hadoop/
# exitInstalando o Hadoop
Siga as etapas abaixo para instalar Hadoop no modo pseudo-distribuído.
Etapa 1: Configurando o Hadoop
Você pode definir as variáveis de ambiente Hadoop anexando os seguintes comandos a ~/.bashrc Arquivo.
export HADOOP_HOME = /usr/local/hadoop export
HADOOP_MAPRED_HOME = $HADOOP_HOME export
HADOOP_COMMON_HOME = $HADOOP_HOME export
HADOOP_HDFS_HOME = $HADOOP_HOME export
YARN_HOME = $HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native
export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL = $HADOOP_HOMEEm seguida, aplique todas as alterações no sistema em execução atual.
$ source ~/.bashrcEtapa 2: configuração do Hadoop
Você pode encontrar todos os arquivos de configuração do Hadoop no local “$ HADOOP_HOME / etc / hadoop”. É necessário fazer alterações nesses arquivos de configuração de acordo com sua infraestrutura Hadoop.
$ cd $HADOOP_HOME/etc/hadoopPara desenvolver programas Hadoop em Java, você deve redefinir as variáveis de ambiente Java em hadoop-env.sh arquivo substituindo JAVA_HOME valor com a localização do Java em seu sistema.
export JAVA_HOME = /usr/local/jdk1.7.0_71A seguir está a lista de arquivos que você deve editar para configurar o Hadoop -
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
o core-site.xml arquivo contém informações como o número da porta usado para a instância do Hadoop, memória alocada para o sistema de arquivos, limite de memória para armazenar os dados e tamanho dos buffers de leitura / gravação.
Abra o core-site.xml e adicione as seguintes propriedades dentro das tags <configuration>, </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
o hdfs-site.xml arquivo contém informações como o valor dos dados de replicação, namenode caminho, e datanodecaminhos de seus sistemas de arquivos locais. Significa o local onde você deseja armazenar a infraestrutura do Hadoop.
Vamos supor os seguintes dados.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeAbra este arquivo e adicione as seguintes propriedades dentro das marcas <configuration>, </configuration>.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note - No arquivo acima, todos os valores de propriedade são definidos pelo usuário e você pode fazer alterações de acordo com sua infraestrutura Hadoop.
yarn-site.xml
Este arquivo é usado para configurar o yarn no Hadoop. Abra o arquivo yarn-site.xml e adicione as seguintes propriedades entre as marcas <configuration>, </configuration> neste arquivo.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Este arquivo é usado para especificar qual estrutura MapReduce estamos usando. Por padrão, o Hadoop contém um modelo de yarn-site.xml. Em primeiro lugar, é necessário copiar o arquivo demapred-site,xml.template para mapred-site.xml arquivo usando o seguinte comando.
$ cp mapred-site.xml.template mapred-site.xmlAbrir mapred-site.xml arquivo e adicione as seguintes propriedades dentro das marcas <configuration>, </configuration>.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Verificando a instalação do Hadoop
As etapas a seguir são usadas para verificar a instalação do Hadoop.
Etapa 1: configuração do nó de nome
Configure o namenode usando o comando "hdfs namenode –format" da seguinte maneira.
$ cd ~
$ hdfs namenode -formatO resultado esperado é o seguinte.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Etapa 2: verificar o dfs do Hadoop
O comando a seguir é usado para iniciar o Hadoop dfs. A execução desse comando iniciará seu sistema de arquivos Hadoop.
$ start-dfs.shA saída esperada é a seguinte -
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Etapa 3: Verificar o script do Yarn
O seguinte comando é usado para iniciar o script Yarn. Executar este comando iniciará seus demônios Yarn.
$ start-yarn.shA saída esperada da seguinte forma -
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.6.4/logs/yarn-hadoop-nodemanager-localhost.outEtapa 4: Acessando o Hadoop no navegador
O número da porta padrão para acessar o Hadoop é 50070. Use a seguinte URL para obter serviços Hadoop no navegador.
http://localhost:50070/
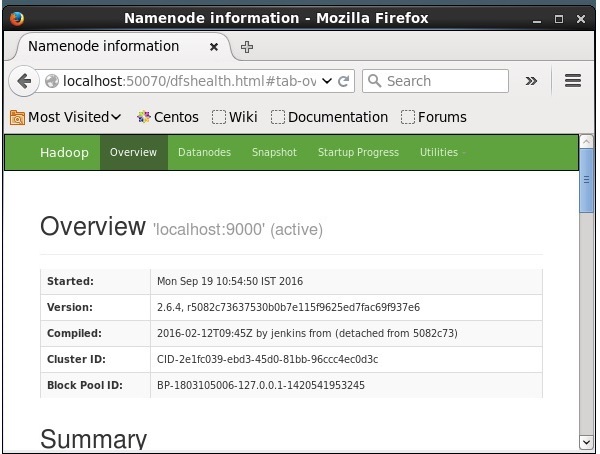
Instalando Solr no Hadoop
Siga as etapas abaixo para baixar e instalar o Solr.
Passo 1
Abra a página inicial do Apache Solr clicando no seguinte link - https://lucene.apache.org/solr/
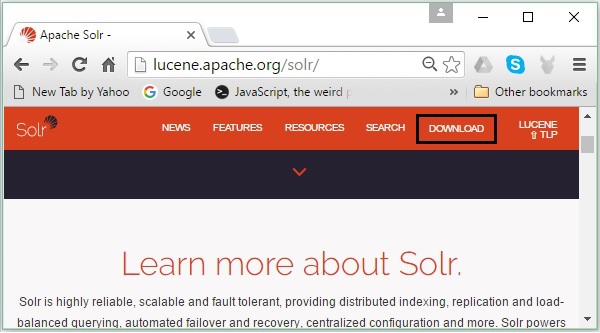
Passo 2
Clique no download button(destacado na imagem acima). Ao clicar, você será redirecionado para a página onde você tem vários mirrors do Apache Solr. Selecione um espelho e clique nele, que o redirecionará para uma página onde você pode baixar os arquivos fonte e binários do Apache Solr, como mostrado na imagem a seguir.
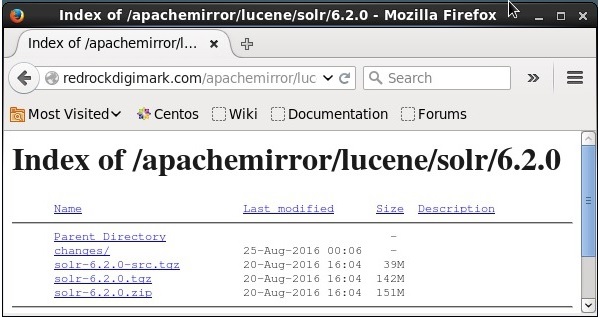
etapa 3
Ao clicar, uma pasta chamada Solr-6.2.0.tqzserá baixado na pasta de downloads do seu sistema. Extraia o conteúdo da pasta baixada.
Passo 4
Crie uma pasta chamada Solr no diretório inicial do Hadoop e mova o conteúdo da pasta extraída para ela, conforme mostrado abaixo.
$ mkdir Solr
$ cd Downloads
$ mv Solr-6.2.0 /home/Hadoop/Verificação
Navegue pelo bin pasta do diretório Home do Solr e verifique a instalação usando o version opção, conforme mostrado no seguinte bloco de código.
$ cd bin/
$ ./Solr version
6.2.0Definindo casa e caminho
Abra o .bashrc arquivo usando o seguinte comando -
[Hadoop@localhost ~]$ source ~/.bashrcAgora defina os diretórios home e path para o Apache Solr da seguinte maneira -
export SOLR_HOME = /home/Hadoop/Solr
export PATH = $PATH:/$SOLR_HOME/bin/Abra o terminal e execute o seguinte comando -
[Hadoop@localhost Solr]$ source ~/.bashrcAgora, você pode executar os comandos do Solr de qualquer diretório.
Neste capítulo, discutiremos a arquitetura do Apache Solr. A ilustração a seguir mostra um diagrama de blocos da arquitetura do Apache Solr.
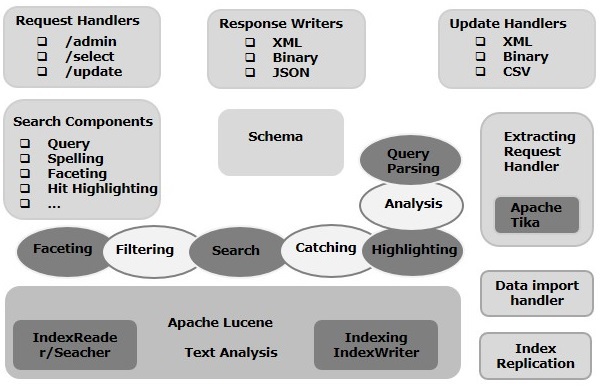
Arquitetura Solr ─ Blocos de Construção
A seguir estão os principais blocos de construção (componentes) do Apache Solr -
Request Handler- As solicitações que enviamos ao Apache Solr são processadas por esses gerenciadores de solicitações. As solicitações podem ser solicitações de consulta ou solicitações de atualização de índice. Com base em nossos requisitos, precisamos selecionar o manipulador de solicitações. Para passar uma solicitação ao Solr, geralmente mapearemos o manipulador para um determinado ponto de extremidade de URI e a solicitação especificada será atendida por ele.
Search Component- Um componente de pesquisa é um tipo (recurso) de pesquisa fornecido no Apache Solr. Pode ser verificação ortográfica, consulta, facetação, destaque de hit, etc. Esses componentes de pesquisa são registrados comosearch handlers. Vários componentes podem ser registrados em um manipulador de pesquisa.
Query Parser- O analisador de consultas Apache Solr analisa as consultas que passamos para o Solr e verifica as consultas em busca de erros sintáticos. Depois de analisar as consultas, ele as traduz para um formato que Lucene entende.
Response Writer- Um escritor de resposta no Apache Solr é o componente que gera a saída formatada para as consultas do usuário. Solr oferece suporte a formatos de resposta como XML, JSON, CSV, etc. Temos diferentes escritores de resposta para cada tipo de resposta.
Analyzer/tokenizer- Lucene reconhece dados na forma de tokens. O Apache Solr analisa o conteúdo, divide-o em tokens e passa esses tokens para o Lucene. Um analisador no Apache Solr examina o texto dos campos e gera um fluxo de token. Um tokenizer divide o fluxo de tokens preparado pelo analisador em tokens.
Update Request Processor - Sempre que enviamos uma solicitação de atualização para Apache Solr, a solicitação é executada por meio de um conjunto de plug-ins (assinatura, registro, indexação), conhecidos coletivamente como update request processor. Este processador é responsável por modificações como eliminar um campo, adicionar um campo, etc.
Neste capítulo, tentaremos entender o significado real de alguns dos termos que são freqüentemente usados ao trabalhar no Solr.
Terminologia Geral
A seguir está uma lista de termos gerais que são usados em todos os tipos de configurações Solr -
Instance - Como um tomcat instance ou um jetty instance, este termo se refere ao servidor de aplicativos, que é executado dentro de uma JVM. O diretório inicial do Solr fornece referência a cada uma dessas instâncias do Solr, nas quais um ou mais núcleos podem ser configurados para execução em cada instância.
Core - Ao executar vários índices em seu aplicativo, você pode ter vários núcleos em cada instância, em vez de várias instâncias, cada uma com um núcleo.
Home - O termo $ SOLR_HOME se refere ao diretório inicial que contém todas as informações sobre os núcleos e seus índices, configurações e dependências.
Shard - Em ambientes distribuídos, os dados são particionados entre várias instâncias do Solr, onde cada bloco de dados pode ser chamado de Shard. Ele contém um subconjunto de todo o índice.
Terminologia SolrCloud
Em um capítulo anterior, discutimos como instalar o Apache Solr no modo autônomo. Observe que também podemos instalar o Solr no modo distribuído (ambiente de nuvem), onde o Solr é instalado em um padrão mestre-escravo. No modo distribuído, o índice é criado no servidor mestre e replicado para um ou mais servidores escravos.
Os principais termos associados ao Solr Cloud são os seguintes -
Node - Na nuvem Solr, cada instância única do Solr é considerada como um node.
Cluster - Todos os nós do ambiente combinados formam um cluster.
Collection - Um cluster tem um índice lógico conhecido como collection.
Shard - Um fragmento é a parte da coleção que possui uma ou mais réplicas do índice.
Replica - No Solr Core, uma cópia do fragmento que é executado em um nó é conhecido como replica.
Leader - Também é uma réplica do shard, que distribui as solicitações do Solr Cloud para as réplicas restantes.
Zookeeper - É um projeto Apache que Solr Cloud usa para configuração e coordenação centralizadas, para gerenciar o cluster e para eleger um líder.
Arquivos de configuração
Os principais arquivos de configuração no Apache Solr são os seguintes -
Solr.xml- É o arquivo no diretório $ SOLR_HOME que contém informações relacionadas ao Solr Cloud. Para carregar os núcleos, o Solr faz referência a este arquivo, que ajuda a identificá-los.
Solrconfig.xml - Este arquivo contém as definições e configurações específicas do núcleo relacionadas ao tratamento da solicitação e formatação da resposta, junto com a indexação, configuração, gerenciamento de memória e confirmação.
Schema.xml - Este arquivo contém todo o esquema junto com os campos e tipos de campo.
Core.properties- Este arquivo contém as configurações específicas do núcleo. É referido paracore discovery, pois contém o nome do núcleo e o caminho do diretório de dados. Ele pode ser usado em qualquer diretório, que será então tratado como ocore directory.
Solr inicial
Depois de instalar o Solr, navegue até o bin pasta no diretório inicial do Solr e inicie o Solr usando o seguinte comando.
[Hadoop@localhost ~]$ cd
[Hadoop@localhost ~]$ cd Solr/
[Hadoop@localhost Solr]$ cd bin/
[Hadoop@localhost bin]$ ./Solr startEste comando inicia o Solr em segundo plano, ouvindo na porta 8983 exibindo a seguinte mensagem.
Waiting up to 30 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid = 6035). Happy searching!Iniciando Solr em primeiro plano
Se você começar Solr usando o startcomando, o Solr será iniciado em segundo plano. Em vez disso, você pode iniciar o Solr em primeiro plano usando o–f option.
[Hadoop@localhost bin]$ ./Solr start –f
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/extraction/lib/xmlbeans-2.6.0.jar' to
classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/dist/Solr-cell-6.2.0.jar' to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/carrot2-guava-18.0.jar'
to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/attributes-binder1.3.1.jar'
to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/simple-xml-2.7.1.jar'
to classloader
……………………………………………………………………………………………………………………………………………………………………………………………………………
………………………………………………………………………………………………………………………………………………………………………………………………….
12901 INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample] o.a.s.u.UpdateLog
Took 24.0ms to seed version buckets with highest version 1546058939881226240 12902
INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample]
o.a.s.c.CoreContainer registering core: Solr_sample
12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.u.UpdateLog Took
16.0ms to seed version buckets with highest version 1546058939894857728
12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.c.CoreContainer
registering core: my_coreIniciando Solr em outra porta
Usando –p option do start , podemos iniciar o Solr em outra porta, conforme mostrado no bloco de código a seguir.
[Hadoop@localhost bin]$ ./Solr start -p 8984
Waiting up to 30 seconds to see Solr running on port 8984 [-]
Started Solr server on port 8984 (pid = 10137). Happy searching!Parando Solr
Você pode parar o Solr usando o stop comando.
$ ./Solr stopEste comando para o Solr, exibindo uma mensagem conforme mostrado abaixo.
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to
allow Jetty process 6035 to stop gracefully.Reiniciando o Solr
o restartO comando do Solr interrompe o Solr por 5 segundos e o inicia novamente. Você pode reiniciar o Solr usando o seguinte comando -
./Solr restartEste comando reinicia o Solr, exibindo a seguinte mensagem -
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to
allow Jetty process 6671 to stop gracefully.
Waiting up to 30 seconds to see Solr running on port 8983 [|] [/]
Started Solr server on port 8983 (pid = 6906). Happy searching!Solr ─ comando de ajuda
o help O comando do Solr pode ser usado para verificar o uso do prompt do Solr e suas opções.
[Hadoop@localhost bin]$ ./Solr -help
Usage: Solr COMMAND OPTIONS
where COMMAND is one of: start, stop, restart, status, healthcheck,
create, create_core, create_collection, delete, version, zk
Standalone server example (start Solr running in the background on port 8984):
./Solr start -p 8984
SolrCloud example (start Solr running in SolrCloud mode using localhost:2181
to connect to Zookeeper, with 1g max heap size and remote Java debug options enabled):
./Solr start -c -m 1g -z localhost:2181 -a "-Xdebug -
Xrunjdwp:transport = dt_socket,server = y,suspend = n,address = 1044"
Pass -help after any COMMAND to see command-specific usage information,
such as: ./Solr start -help or ./Solr stop -helpSolr ─ comando de status
este statusO comando do Solr pode ser usado para pesquisar e descobrir as instâncias do Solr em execução no seu computador. Ele pode fornecer informações sobre uma instância do Solr, como sua versão, uso de memória, etc.
Você pode verificar o status de uma instância do Solr, usando o comando de status da seguinte forma -
[Hadoop@localhost bin]$ ./Solr statusAo ser executado, o comando acima exibe o status do Solr da seguinte forma -
Found 1 Solr nodes:
Solr process 6906 running on port 8983 {
"Solr_home":"/home/Hadoop/Solr/server/Solr",
"version":"6.2.0 764d0f19151dbff6f5fcd9fc4b2682cf934590c5 -
mike - 2016-08-20 05:41:37",
"startTime":"2016-09-20T06:00:02.877Z",
"uptime":"0 days, 0 hours, 5 minutes, 14 seconds",
"memory":"30.6 MB (%6.2) of 490.7 MB"
}Solr Admin
Depois de iniciar o Apache Solr, você pode visitar a página inicial do Solr web interface usando o seguinte URL.
Localhost:8983/Solr/A interface do Solr Admin aparece da seguinte forma -
Um Solr Core é uma instância em execução de um índice Lucene que contém todos os arquivos de configuração do Solr necessários para usá-lo. Precisamos criar um Solr Core para realizar operações como indexação e análise.
Um aplicativo Solr pode conter um ou vários núcleos. Se necessário, dois núcleos em um aplicativo Solr podem se comunicar um com o outro.
Criação de um núcleo
Depois de instalar e iniciar o Solr, você pode se conectar ao cliente (interface da web) do Solr.
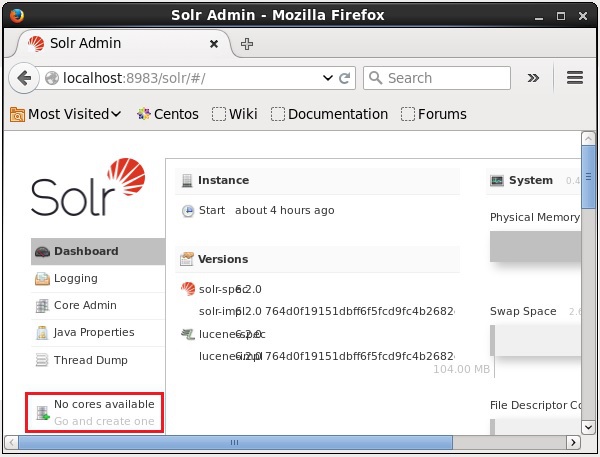
Conforme destacado na captura de tela a seguir, inicialmente não há núcleos no Apache Solr. Agora, veremos como criar um núcleo no Solr.
Usando o comando de criação
Uma maneira de criar um núcleo é criar um schema-less core usando o create comando, como mostrado abaixo -
[Hadoop@localhost bin]$ ./Solr create -c Solr_sampleAqui, estamos tentando criar um núcleo chamado Solr_sampleno Apache Solr. Este comando cria um núcleo exibindo a seguinte mensagem.
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/Solr_sample
Creating new core 'Solr_sample' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=Solr_sample&instanceD
ir = Solr_sample {
"responseHeader":{
"status":0,
"QTime":11550
},
"core":"Solr_sample"
}Você pode criar vários núcleos no Solr. No lado esquerdo do Solr Admin, você pode ver umcore selector onde você pode selecionar o núcleo recém-criado, como mostrado na imagem a seguir.
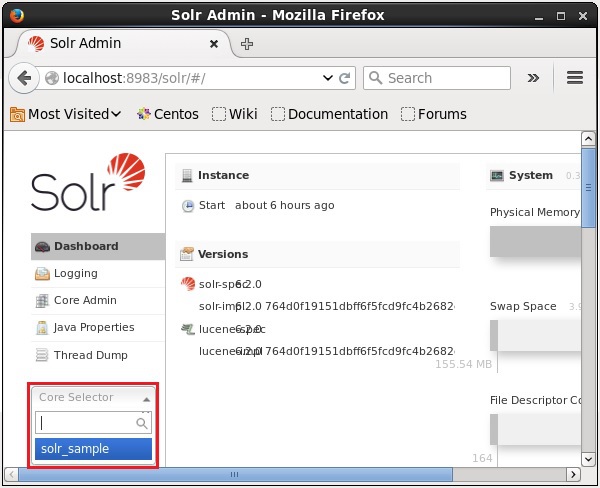
Usando o comando create_core
Alternativamente, você pode criar um núcleo usando o create_corecomando. Este comando tem as seguintes opções -
| –C core_name | Nome do núcleo que você queria criar |
| -p port_name | Porta na qual você deseja criar o núcleo |
| -d conf_dir | Diretório de configuração da porta |
Vamos ver como você pode usar o create_corecomando. Aqui, vamos tentar criar um núcleo chamadomy_core.
[Hadoop@localhost bin]$ ./Solr create_core -c my_coreAo ser executado, o comando acima cria um núcleo exibindo a seguinte mensagem -
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/my_core
Creating new core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=my_core&instanceD
ir = my_core {
"responseHeader":{
"status":0,
"QTime":1346
},
"core":"my_core"
}Excluindo um núcleo
Você pode excluir um núcleo usando o deletecomando do Apache Solr. Vamos supor que temos um núcleo chamadomy_core no Solr, conforme mostrado na captura de tela a seguir.
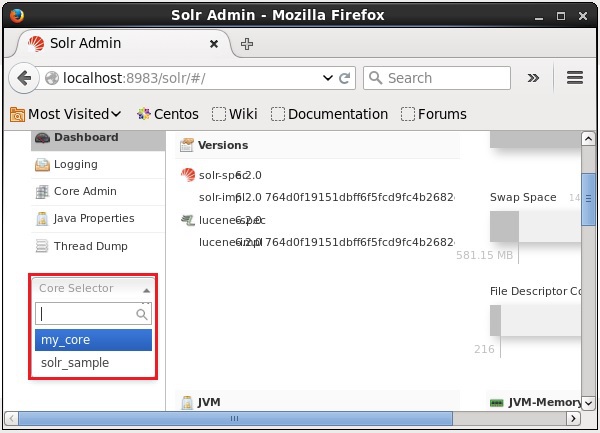
Você pode excluir este núcleo usando o delete comando passando o nome do núcleo para este comando da seguinte forma -
[Hadoop@localhost bin]$ ./Solr delete -c my_coreAo executar o comando acima, o núcleo especificado será excluído exibindo a seguinte mensagem.
Deleting core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=UNLOAD&core = my_core&deleteIndex
= true&deleteDataDir = true&deleteInstanceDir = true {
"responseHeader" :{
"status":0,
"QTime":170
}
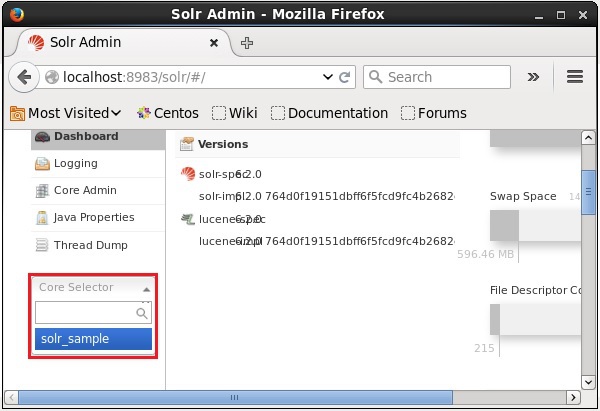
}Você pode abrir a interface da web do Solr para verificar se o núcleo foi excluído ou não.
Em geral, indexingé um arranjo de documentos ou (outras entidades) sistematicamente. A indexação permite que os usuários localizem informações em um documento.
A indexação coleta, analisa e armazena documentos.
A indexação é feita para aumentar a velocidade e o desempenho de uma consulta de pesquisa ao localizar um documento necessário.
Indexação no Apache Solr
No Apache Solr, podemos indexar (adicionar, excluir, modificar) vários formatos de documento, como xml, csv, pdf, etc. Podemos adicionar dados ao índice do Solr de várias maneiras.
Neste capítulo, vamos discutir a indexação -
- Usando a interface da Web do Solr.
- Usando qualquer uma das APIs do cliente, como Java, Python, etc.
- Usando o post tool.
Neste capítulo, discutiremos como adicionar dados ao índice do Apache Solr usando várias interfaces (linha de comando, interface da web e API cliente Java)
Adicionar documentos usando o Post Command
Solr tem um post comando em seu bin/diretório. Usando este comando, você pode indexar vários formatos de arquivos como JSON, XML, CSV no Apache Solr.
Navegue pelo bin diretório do Apache Solr e execute o –h option do comando post, conforme mostrado no bloco de código a seguir.
[Hadoop@localhost bin]$ cd $SOLR_HOME
[Hadoop@localhost bin]$ ./post -hAo executar o comando acima, você obterá uma lista de opções do post command, como mostrado abaixo.
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'Exemplo
Suponha que temos um arquivo chamado sample.csv com o seguinte conteúdo (no bin diretório).
| Identidade estudantil | Primeiro nome | Último nome | telefone | Cidade |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | Hyderabad |
| 002 | Siddharth | Bhattacharya | 9848022338 | Calcutá |
| 003 | Rajesh | Khanna | 9848022339 | Délhi |
| 004 | Preethi | Agarwal | 9848022330 | Pune |
| 005 | Trupthi | Mohanty | 9848022336 | Bhubaneshwar |
| 006 | Archana | Mishra | 9848022335 | Chennai |
O conjunto de dados acima contém detalhes pessoais como id do aluno, nome, sobrenome, telefone e cidade. O arquivo CSV do conjunto de dados é mostrado abaixo. Aqui, você deve observar que precisa mencionar o esquema, documentando sua primeira linha.
id, first_name, last_name, phone_no, location
001, Pruthvi, Reddy, 9848022337, Hyderabad
002, kasyap, Sastry, 9848022338, Vishakapatnam
003, Rajesh, Khanna, 9848022339, Delhi
004, Preethi, Agarwal, 9848022330, Pune
005, Trupthi, Mohanty, 9848022336, Bhubaneshwar
006, Archana, Mishra, 9848022335, ChennaiVocê pode indexar esses dados no núcleo denominado sample_Solr usando o post comando da seguinte forma -
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvAo executar o comando acima, o documento fornecido é indexado no núcleo especificado, gerando a seguinte saída.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files
org.apache.Solr.util.SimplePostTool sample.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file sample.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to
http://localhost:8983/Solr/Solr_sample/update...
Time spent: 0:00:00.228Visite a página inicial do Solr Web UI usando o seguinte URL -
http://localhost:8983/
Selecione o núcleo Solr_sample. Por padrão, o manipulador de solicitação é/selecte a consulta é “:”. Sem fazer nenhuma modificação, clique noExecuteQuery botão na parte inferior da página.
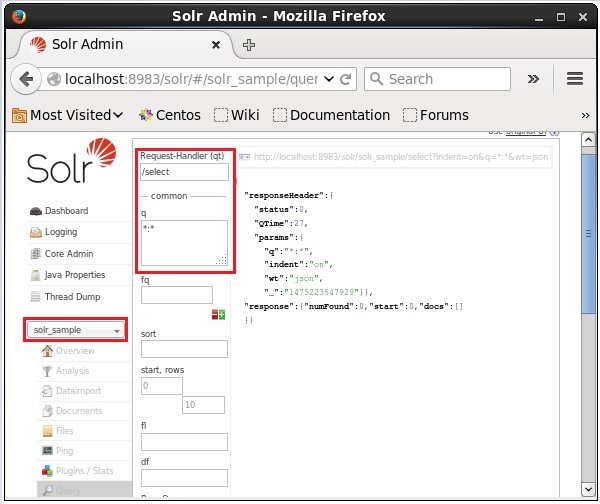
Ao executar a consulta, é possível observar o conteúdo do documento CSV indexado no formato JSON (padrão), conforme mostrado na captura de tela a seguir.
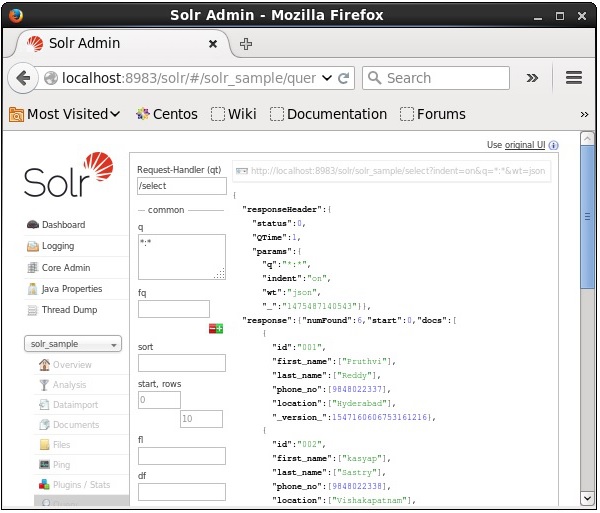
Note - Da mesma forma, você pode indexar outros formatos de arquivo, como JSON, XML, CSV, etc.
Adicionar documentos usando a interface da Web do Solr
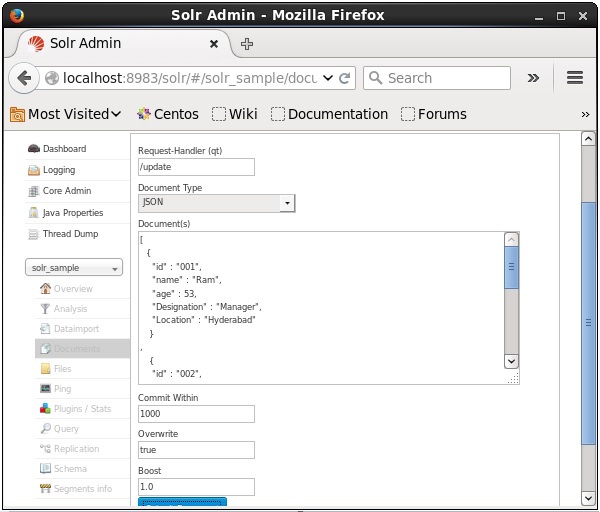
Você também pode indexar documentos usando a interface da web fornecida pelo Solr. Vamos ver como indexar o seguinte documento JSON.
[
{
"id" : "001",
"name" : "Ram",
"age" : 53,
"Designation" : "Manager",
"Location" : "Hyderabad",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "Chennai",
},
{
"id" : "003",
"name" : "Rahim",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "Delhi",
}
]Passo 1
Abra a interface da web do Solr usando o seguinte URL -
http://localhost:8983/
Step 2
Selecione o núcleo Solr_sample. Por padrão, os valores dos campos Request Handler, Common Within, Overwrite e Boost são / update, 1000, true e 1.0 respectivamente, conforme mostrado na captura de tela a seguir.
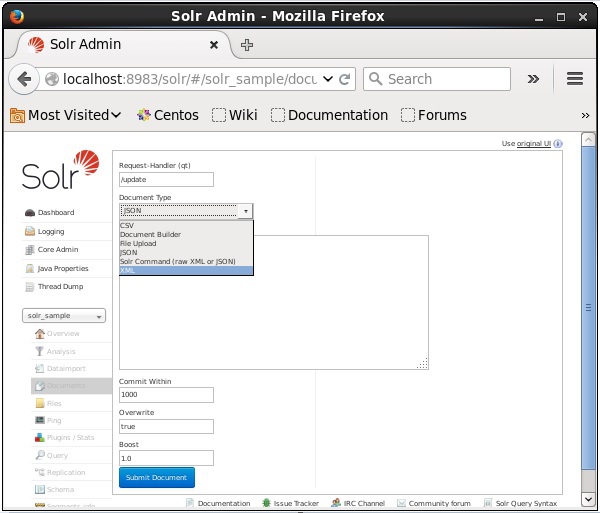
Agora, escolha o formato de documento desejado em JSON, CSV, XML, etc. Digite o documento a ser indexado na área de texto e clique no botão Submit Document botão, como mostrado na imagem a seguir.
Adicionar documentos usando a API do cliente Java
A seguir está o programa Java para adicionar documentos ao índice do Apache Solr. Salve este código em um arquivo com o nomeAddingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Adding fields to the document
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Adding the document to Solr
Solr.add(doc);
//Saving the changes
Solr.commit();
System.out.println("Documents added");
}
}Compile o código acima executando os seguintes comandos no terminal -
[Hadoop@localhost bin]$ javac AddingDocument
[Hadoop@localhost bin]$ java AddingDocumentAo executar o comando acima, você obterá a seguinte saída.
Documents addedNo capítulo anterior, explicamos como adicionar dados ao Solr, que está nos formatos de arquivo JSON e .CSV. Neste capítulo, demonstraremos como adicionar dados no índice Apache Solr usando o formato de documento XML.
Dados de amostra
Suponha que precisamos adicionar os seguintes dados ao índice do Solr usando o formato de arquivo XML.
| Identidade estudantil | Primeiro nome | Último nome | telefone | Cidade |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | Hyderabad |
| 002 | Siddharth | Bhattacharya | 9848022338 | Calcutá |
| 003 | Rajesh | Khanna | 9848022339 | Délhi |
| 004 | Preethi | Agarwal | 9848022330 | Pune |
| 005 | Trupthi | Mohanty | 9848022336 | Bhubaneshwar |
| 006 | Archana | Mishra | 9848022335 | Chennai |
Adicionar documentos usando XML
Para adicionar os dados acima ao índice Solr, precisamos preparar um documento XML, conforme mostrado abaixo. Salve este documento em um arquivo com o nomesample.xml.
<add>
<doc>
<field name = "id">001</field>
<field name = "first name">Rajiv</field>
<field name = "last name">Reddy</field>
<field name = "phone">9848022337</field>
<field name = "city">Hyderabad</field>
</doc>
<doc>
<field name = "id">002</field>
<field name = "first name">Siddarth</field>
<field name = "last name">Battacharya</field>
<field name = "phone">9848022338</field>
<field name = "city">Kolkata</field>
</doc>
<doc>
<field name = "id">003</field>
<field name = "first name">Rajesh</field>
<field name = "last name">Khanna</field>
<field name = "phone">9848022339</field>
<field name = "city">Delhi</field>
</doc>
<doc>
<field name = "id">004</field>
<field name = "first name">Preethi</field>
<field name = "last name">Agarwal</field>
<field name = "phone">9848022330</field>
<field name = "city">Pune</field>
</doc>
<doc>
<field name = "id">005</field>
<field name = "first name">Trupthi</field>
<field name = "last name">Mohanthy</field>
<field name = "phone">9848022336</field>
<field name = "city">Bhuwaeshwar</field>
</doc>
<doc>
<field name = "id">006</field>
<field name = "first name">Archana</field>
<field name = "last name">Mishra</field>
<field name = "phone">9848022335</field>
<field name = "city">Chennai</field>
</doc>
</add>Como você pode observar, o arquivo XML escrito para adicionar dados ao índice contém três marcas importantes, a saber, <add> </add>, <doc> </doc> e <field> </ field>.
add- Esta é a marca raiz para adicionar documentos ao índice. Ele contém um ou mais documentos que devem ser adicionados.
doc- Os documentos que adicionamos devem ser incluídos nas tags <doc> </doc>. Este documento contém os dados na forma de campos.
field - A tag de campo contém o nome e o valor dos campos do documento.
Depois de preparar o documento, você pode adicioná-lo ao índice usando qualquer um dos meios discutidos no capítulo anterior.
Suponha que o arquivo XML exista no bin diretório do Solr e deve ser indexado no núcleo denominado my_core, então você pode adicioná-lo ao índice do Solr usando o post ferramenta da seguinte forma -
[Hadoop@localhost bin]$ ./post -c my_core sample.xmlAo executar o comando acima, você obterá a seguinte saída.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-
core6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool sample.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,
xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file sample.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.201Verificação
Visite a página inicial da interface da web do Apache Solr e selecione o núcleo my_core. Tente recuperar todos os documentos passando a consulta “:” na área de textoqe execute a consulta. Ao executar, você pode observar que os dados desejados são adicionados ao índice do Solr.
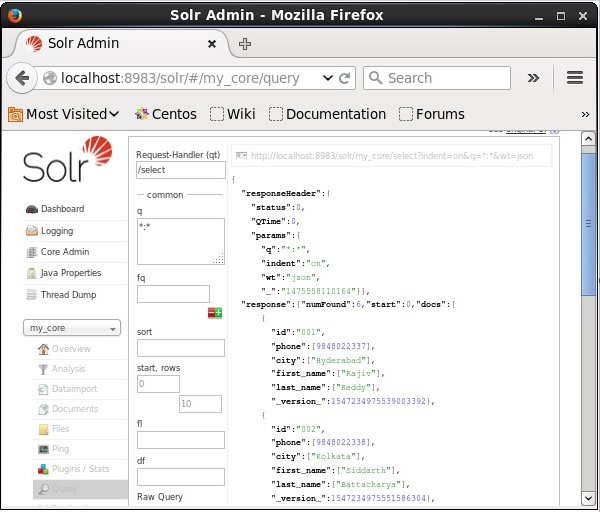
Atualizando o documento usando XML
A seguir está o arquivo XML usado para atualizar um campo no documento existente. Salve isso em um arquivo com o nomeupdate.xml.
<add>
<doc>
<field name = "id">001</field>
<field name = "first name" update = "set">Raj</field>
<field name = "last name" update = "add">Malhotra</field>
<field name = "phone" update = "add">9000000000</field>
<field name = "city" update = "add">Delhi</field>
</doc>
</add>Como você pode observar, o arquivo XML escrito para atualizar os dados é igual ao que usamos para adicionar documentos. Mas a única diferença é que usamos oupdate atributo do campo.
Em nosso exemplo, usaremos o documento acima e tentaremos atualizar os campos do documento com o id 001.
Suponha que o documento XML exista no bindiretório do Solr. Uma vez que estamos atualizando o índice que existe no núcleo denominadomy_core, você pode atualizar usando o post ferramenta da seguinte forma -
[Hadoop@localhost bin]$ ./post -c my_core update.xmlAo executar o comando acima, você obterá a seguinte saída.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool update.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file update.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.159Verificação
Visite a página inicial da interface da web do Apache Solr e selecione o núcleo como my_core. Tente recuperar todos os documentos passando a consulta “:” na área de textoqe execute a consulta. Ao executar, você pode observar que o documento está atualizado.
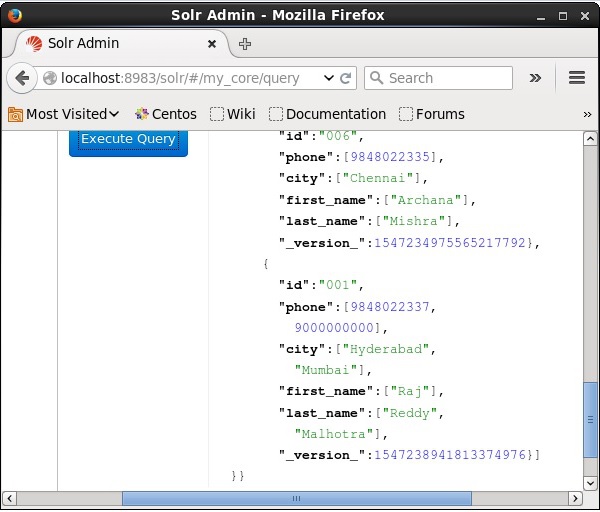
Atualizando o documento usando Java (API do cliente)
A seguir está o programa Java para adicionar documentos ao índice do Apache Solr. Salve este código em um arquivo com o nomeUpdatingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.UpdateRequest;
import org.apache.Solr.client.Solrj.response.UpdateResponse;
import org.apache.Solr.common.SolrInputDocument;
public class UpdatingDocument {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.setAction( UpdateRequest.ACTION.COMMIT, false, false);
SolrInputDocument myDocumentInstantlycommited = new SolrInputDocument();
myDocumentInstantlycommited.addField("id", "002");
myDocumentInstantlycommited.addField("name", "Rahman");
myDocumentInstantlycommited.addField("age","27");
myDocumentInstantlycommited.addField("addr","hyderabad");
updateRequest.add( myDocumentInstantlycommited);
UpdateResponse rsp = updateRequest.process(Solr);
System.out.println("Documents Updated");
}
}Compile o código acima executando os seguintes comandos no terminal -
[Hadoop@localhost bin]$ javac UpdatingDocument
[Hadoop@localhost bin]$ java UpdatingDocumentAo executar o comando acima, você obterá a seguinte saída.
Documents updatedExcluindo o Documento
Para excluir documentos do índice do Apache Solr, precisamos especificar os IDs dos documentos a serem excluídos entre as tags <delete> </delete>.
<delete>
<id>003</id>
<id>005</id>
<id>004</id>
<id>002</id>
</delete>Aqui, este código XML é usado para excluir os documentos com ID's 003 e 005. Salve este código em um arquivo com o nomedelete.xml.
Se você deseja deletar os documentos do índice que pertence ao núcleo denominado my_core, então você pode postar o delete.xml arquivo usando o post ferramenta, como mostrado abaixo.
[Hadoop@localhost bin]$ ./post -c my_core delete.xmlAo executar o comando acima, você obterá a seguinte saída.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool delete.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log
POSTing file delete.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.179Verificação
Visite a página inicial da interface da web do Apache Solr e selecione o núcleo como my_core. Tente recuperar todos os documentos passando a consulta “:” na área de textoqe execute a consulta. Ao executar, você pode observar que os documentos especificados são excluídos.
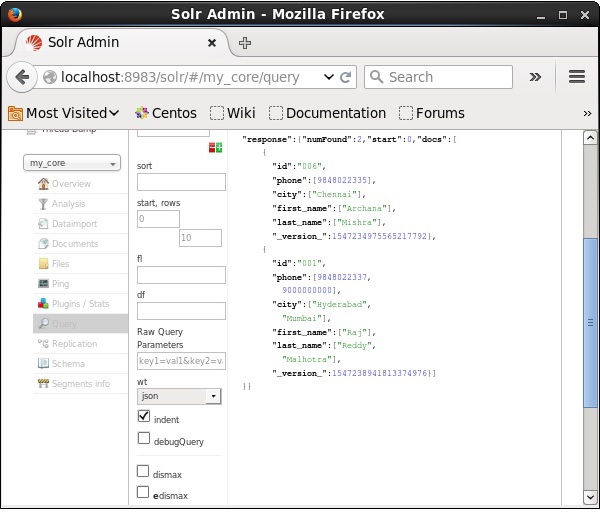
Excluindo um Campo
Às vezes, precisamos excluir documentos com base em campos diferentes do ID. Por exemplo, podemos ter que excluir os documentos onde a cidade é Chennai.
Nesses casos, você precisa especificar o nome e o valor do campo no par de tags <query> </query>.
<delete>
<query>city:Chennai</query>
</delete>Salvar como delete_field.xml e execute a operação de exclusão no núcleo chamado my_core usando o post ferramenta do Solr.
[Hadoop@localhost bin]$ ./post -c my_core delete_field.xmlAo executar o comando acima, ele produz a seguinte saída.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool delete_field.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log
POSTing file delete_field.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.084Verificação
Visite a página inicial da interface da web do Apache Solr e selecione o núcleo como my_core. Tente recuperar todos os documentos passando a consulta “:” na área de textoqe execute a consulta. Na execução, você pode observar que os documentos que contêm o par de valores de campo especificado são excluídos.
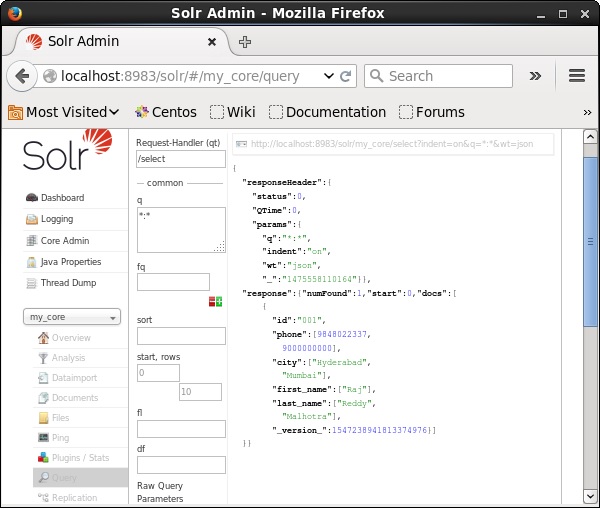
Apagando todos os documentos
Assim como na exclusão de um campo específico, se você deseja excluir todos os documentos de um índice, basta passar o símbolo “:” entre as tags <consulta> </ consulta>, conforme mostrado abaixo.
<delete>
<query>*:*</query>
</delete>Salvar como delete_all.xml e execute a operação de exclusão no núcleo chamado my_core usando o post ferramenta do Solr.
[Hadoop@localhost bin]$ ./post -c my_core delete_all.xmlAo executar o comando acima, ele produz a seguinte saída.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool deleteAll.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file deleteAll.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
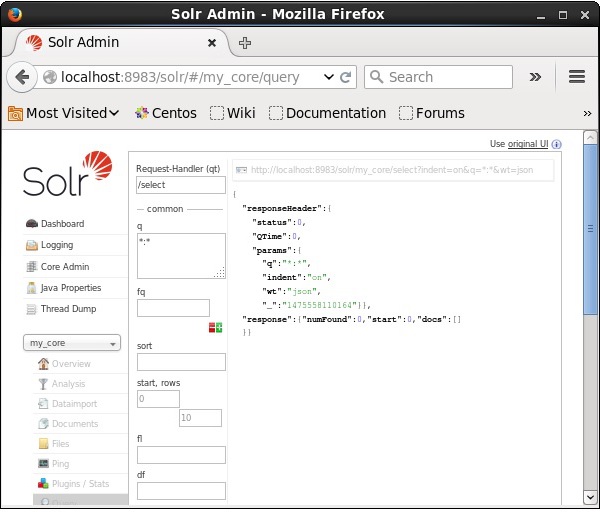
Time spent: 0:00:00.138Verificação
Visite a página inicial da interface da web do Apache Solr e selecione o núcleo como my_core. Tente recuperar todos os documentos passando a consulta “:” na área de textoqe execute a consulta. Na execução, você pode observar que os documentos que contêm o par de valores de campo especificado são excluídos.
Excluindo todos os documentos usando Java (API do cliente)
A seguir está o programa Java para adicionar documentos ao índice do Apache Solr. Salve este código em um arquivo com o nomeUpdatingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class DeletingAllDocuments {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Deleting the documents from Solr
Solr.deleteByQuery("*");
//Saving the document
Solr.commit();
System.out.println("Documents deleted");
}
}Compile o código acima executando os seguintes comandos no terminal -
[Hadoop@localhost bin]$ javac DeletingAllDocuments
[Hadoop@localhost bin]$ java DeletingAllDocumentsAo executar o comando acima, você obterá a seguinte saída.
Documents deletedNeste capítulo, discutiremos como recuperar dados usando a API do cliente Java. Suponha que temos um documento .csv chamadosample.csv com o seguinte conteúdo.
001,9848022337,Hyderabad,Rajiv,Reddy
002,9848022338,Kolkata,Siddarth,Battacharya
003,9848022339,Delhi,Rajesh,KhannaVocê pode indexar esses dados no núcleo denominado sample_Solr usando o post comando.
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvA seguir está o programa Java para adicionar documentos ao índice do Apache Solr. Salve este código em um arquivo com nomeRetrievingData.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrDocumentList;
public class RetrievingData {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing Solr query
SolrQuery query = new SolrQuery();
query.setQuery("*:*");
//Adding the field to be retrieved
query.addField("*");
//Executing the query
QueryResponse queryResponse = Solr.query(query);
//Storing the results of the query
SolrDocumentList docs = queryResponse.getResults();
System.out.println(docs);
System.out.println(docs.get(0));
System.out.println(docs.get(1));
System.out.println(docs.get(2));
//Saving the operations
Solr.commit();
}
}Compile o código acima executando os seguintes comandos no terminal -
[Hadoop@localhost bin]$ javac RetrievingData
[Hadoop@localhost bin]$ java RetrievingDataAo executar o comando acima, você obterá a seguinte saída.
{numFound = 3,start = 0,docs = [SolrDocument{id=001, phone = [9848022337],
city = [Hyderabad], first_name = [Rajiv], last_name = [Reddy],
_version_ = 1547262806014820352}, SolrDocument{id = 002, phone = [9848022338],
city = [Kolkata], first_name = [Siddarth], last_name = [Battacharya],
_version_ = 1547262806026354688}, SolrDocument{id = 003, phone = [9848022339],
city = [Delhi], first_name = [Rajesh], last_name = [Khanna],
_version_ = 1547262806029500416}]}
SolrDocument{id = 001, phone = [9848022337], city = [Hyderabad], first_name = [Rajiv],
last_name = [Reddy], _version_ = 1547262806014820352}
SolrDocument{id = 002, phone = [9848022338], city = [Kolkata], first_name = [Siddarth],
last_name = [Battacharya], _version_ = 1547262806026354688}
SolrDocument{id = 003, phone = [9848022339], city = [Delhi], first_name = [Rajesh],
last_name = [Khanna], _version_ = 1547262806029500416}Além de armazenar dados, o Apache Solr também fornece a facilidade de consultá-los como e quando necessário. Solr fornece certos parâmetros com os quais podemos consultar os dados armazenados nele.
Na tabela a seguir, listamos os vários parâmetros de consulta disponíveis no Apache Solr.
| Parâmetro | Descrição |
|---|---|
| q | Este é o principal parâmetro de consulta do Apache Solr, os documentos são pontuados por sua similaridade com os termos neste parâmetro. |
| fq | Este parâmetro representa a consulta de filtro do Apache Solr que restringe o conjunto de resultados aos documentos que correspondem a este filtro. |
| começar | O parâmetro inicial representa os deslocamentos iniciais para os resultados de uma página, o valor padrão deste parâmetro é 0. |
| filas | Este parâmetro representa o número de documentos que devem ser recuperados por página. O valor padrão deste parâmetro é 10. |
| ordenar | Este parâmetro especifica a lista de campos, separados por vírgulas, com base na qual os resultados da consulta devem ser classificados. |
| fl | Este parâmetro especifica a lista dos campos a serem retornados para cada documento no conjunto de resultados. |
| wt | Este parâmetro representa o tipo de redator de resposta que desejamos ver o resultado. |
Você pode ver todos esses parâmetros como opções para consultar o Apache Solr. Visite a página inicial do Apache Solr. No lado esquerdo da página, clique na opção Consulta. Aqui, você pode ver os campos para os parâmetros de uma consulta.
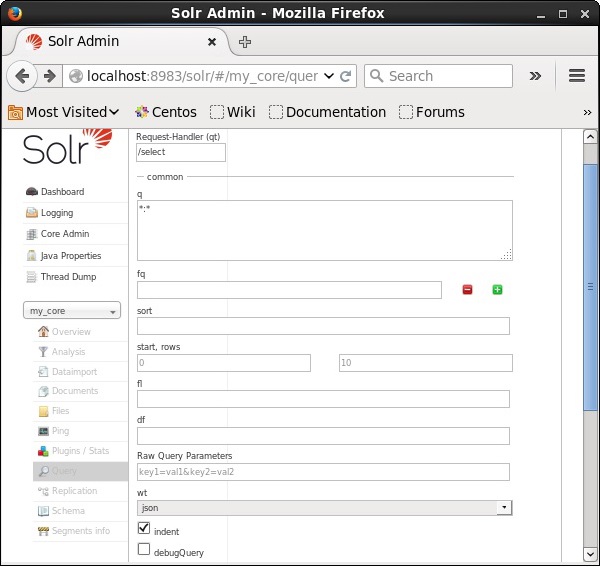
Recuperando os Registros
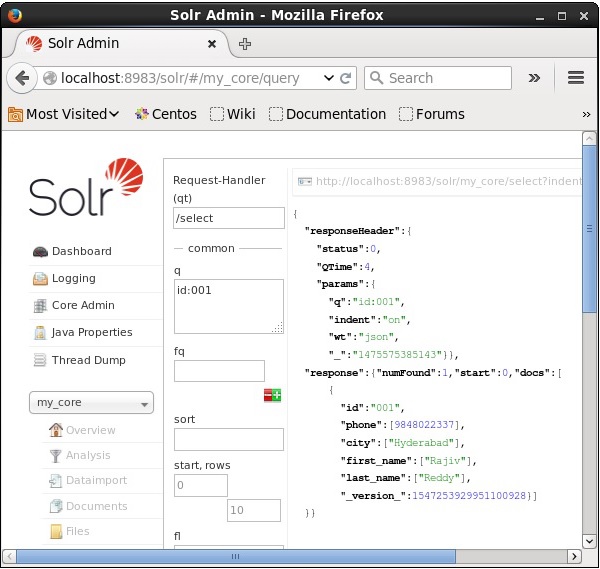
Suponha que temos 3 registros no núcleo nomeado my_core. Para recuperar um determinado registro do núcleo selecionado, você precisa passar os pares de nome e valor dos campos de um documento específico. Por exemplo, se você deseja recuperar o registro com o valor do campoid, você precisa passar o par nome-valor do campo como - Id:001 como valor para o parâmetro q e execute a consulta.
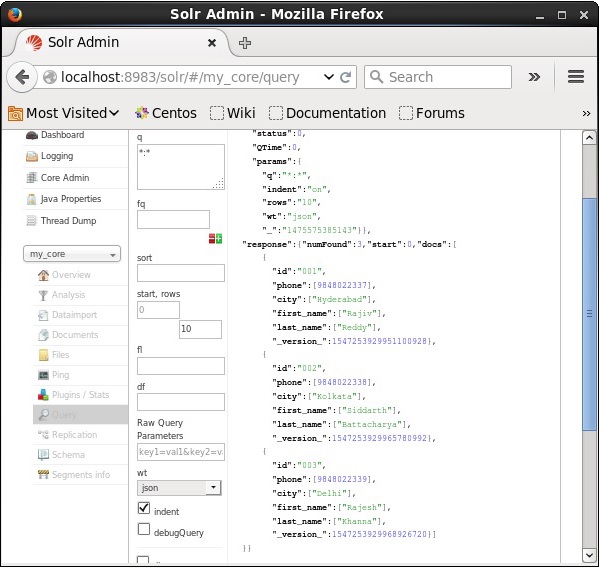
Da mesma forma, você pode recuperar todos os registros de um índice passando *: * como um valor para o parâmetro q, conforme mostrado na imagem a seguir.
Recuperando do 2º registro
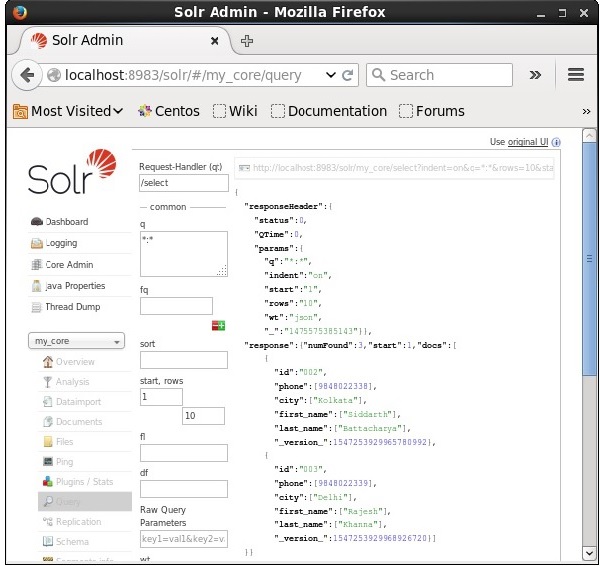
Podemos recuperar os registros do segundo registro, passando 2 como um valor para o parâmetro start, conforme mostrado na imagem a seguir.
Restringindo o número de registros
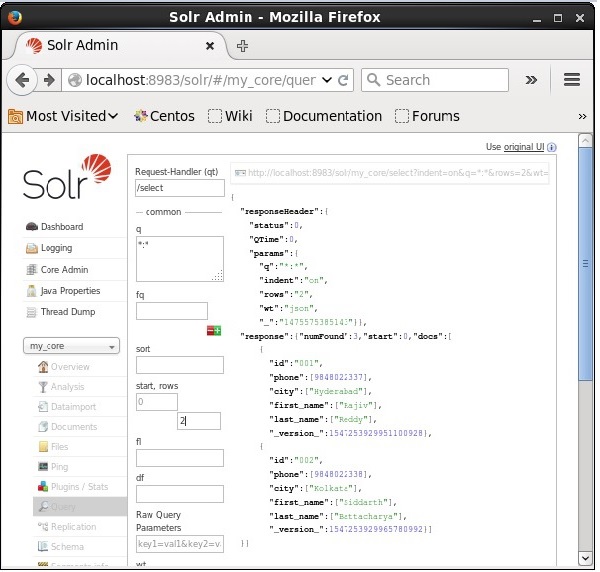
Você pode restringir o número de registros, especificando um valor no rowsparâmetro. Por exemplo, podemos restringir o número total de registros no resultado da consulta a 2, passando o valor 2 para o parâmetrorows, conforme mostrado na imagem a seguir.
Tipo de redator de resposta
Você pode obter a resposta no tipo de documento necessário, selecionando um dos valores fornecidos do parâmetro wt.
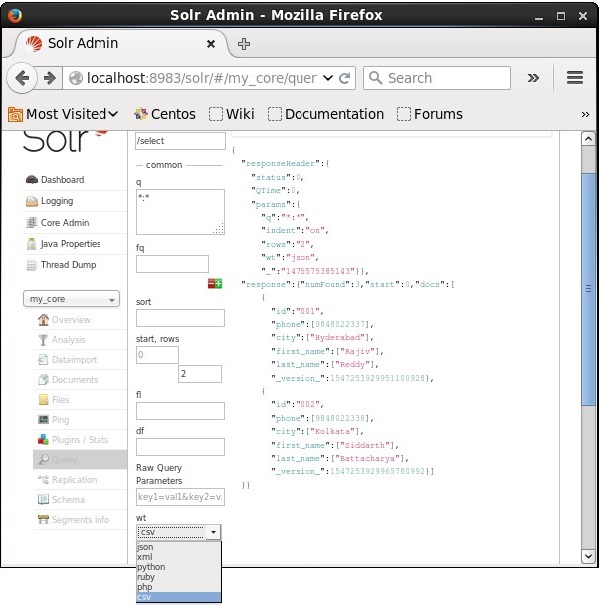
No caso acima, escolhemos o .csv formato para obter a resposta.
Lista dos Campos
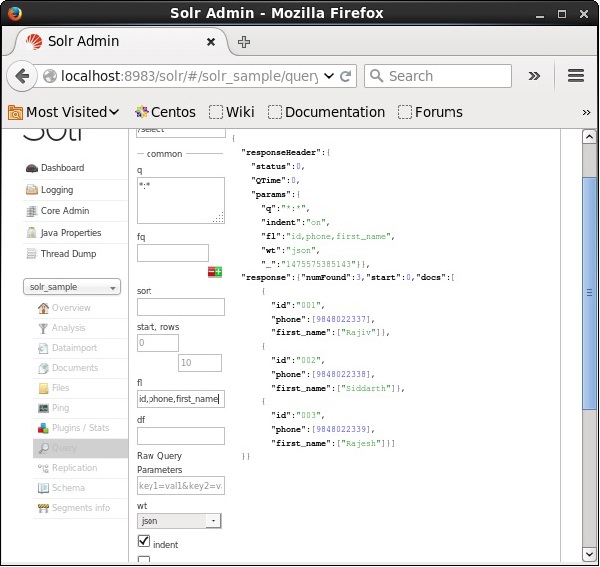
Se quisermos ter campos particulares nos documentos resultantes, precisamos passar a lista dos campos obrigatórios, separados por vírgulas, como um valor para a propriedade fl.
No exemplo a seguir, estamos tentando recuperar os campos - id, phone, e first_name.
Facetar no Apache Solr refere-se à classificação dos resultados da pesquisa em várias categorias. Neste capítulo, discutiremos os tipos de facetamento disponíveis no Apache Solr -
Query faceting - Retorna o número de documentos nos resultados da pesquisa atual que também correspondem à consulta fornecida.
Date faceting - Ele retorna o número de documentos que se enquadram em determinados intervalos de datas.
Comandos de facetação são adicionados a qualquer solicitação de consulta Solr normal e as contagens de facetação voltam na mesma resposta de consulta.
Exemplo de consulta de facetação
Usando o campo faceting, podemos recuperar as contagens de todos os termos ou apenas os termos principais em qualquer campo.
Como exemplo, vamos considerar o seguinte books.csv arquivo que contém dados sobre vários livros.
id,cat,name,price,inStock,author,series_t,sequence_i,genre_s
0553573403,book,A Game of Thrones,5.99,true,George R.R. Martin,"A Song of Ice
and Fire",1,fantasy
0553579908,book,A Clash of Kings,10.99,true,George R.R. Martin,"A Song of Ice
and Fire",2,fantasy
055357342X,book,A Storm of Swords,7.99,true,George R.R. Martin,"A Song of Ice
and Fire",3,fantasy
0553293354,book,Foundation,7.99,true,Isaac Asimov,Foundation Novels,1,scifi
0812521390,book,The Black Company,4.99,false,Glen Cook,The Chronicles of The
Black Company,1,fantasy
0812550706,book,Ender's Game,6.99,true,Orson Scott Card,Ender,1,scifi
0441385532,book,Jhereg,7.95,false,Steven Brust,Vlad Taltos,1,fantasy
0380014300,book,Nine Princes In Amber,6.99,true,Roger Zelazny,the Chronicles of
Amber,1,fantasy
0805080481,book,The Book of Three,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,1,fantasy
080508049X,book,The Black Cauldron,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,2,fantasyDeixe-nos postar este arquivo no Apache Solr usando o post ferramenta.
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvAo executar o comando acima, todos os documentos mencionados no dado .csv arquivo será carregado no Apache Solr.
Agora vamos executar uma consulta facetada no campo author com 0 linhas na coleção / núcleo my_core.
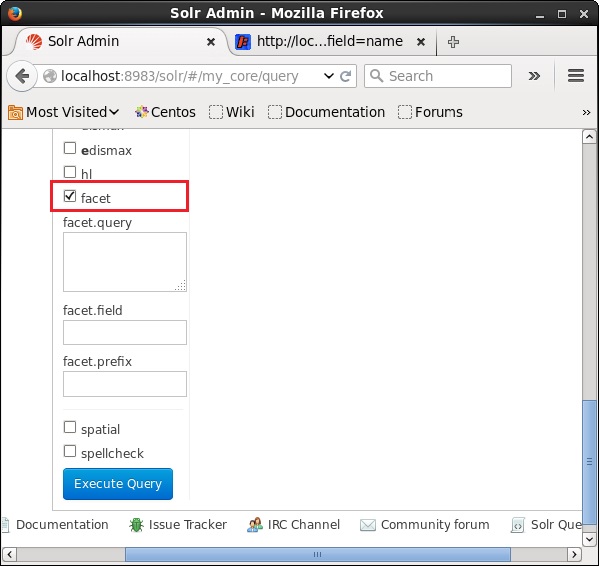
Abra a IU da web do Apache Solr e, no lado esquerdo da página, marque a caixa de seleção facet, conforme mostrado na imagem a seguir.
Ao marcar a caixa de seleção, você terá mais três campos de texto para passar os parâmetros da pesquisa de faceta. Agora, como parâmetros da consulta, passe os seguintes valores.
q = *:*, rows = 0, facet.field = authorFinalmente, execute a consulta clicando no Execute Query botão.
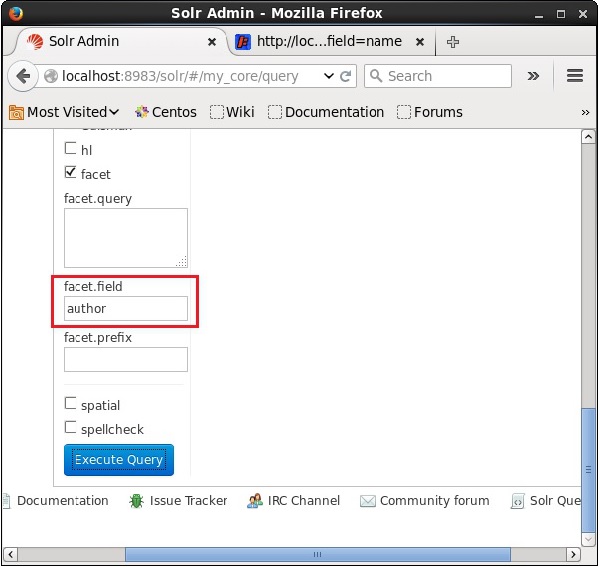
Ao executar, ele produzirá o seguinte resultado.
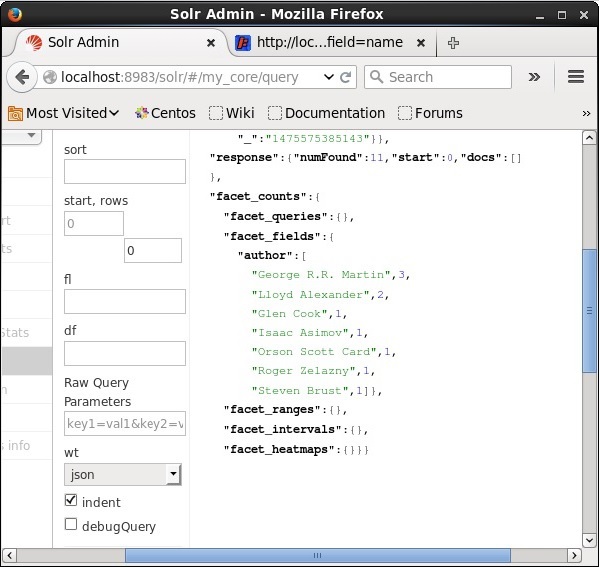
Ele categoriza os documentos no índice com base no autor e especifica o número de livros contribuídos por cada autor.
Facetamento usando a API do cliente Java
A seguir está o programa Java para adicionar documentos ao índice do Apache Solr. Salve este código em um arquivo com o nomeHitHighlighting.java.
import java.io.IOException;
import java.util.List;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.QueryRequest;
import org.apache.Solr.client.Solrj.response.FacetField;
import org.apache.Solr.client.Solrj.response.FacetField.Count;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrInputDocument;
public class HitHighlighting {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//String query = request.query;
SolrQuery query = new SolrQuery();
//Setting the query string
query.setQuery("*:*");
//Setting the no.of rows
query.setRows(0);
//Adding the facet field
query.addFacetField("author");
//Creating the query request
QueryRequest qryReq = new QueryRequest(query);
//Creating the query response
QueryResponse resp = qryReq.process(Solr);
//Retrieving the response fields
System.out.println(resp.getFacetFields());
List<FacetField> facetFields = resp.getFacetFields();
for (int i = 0; i > facetFields.size(); i++) {
FacetField facetField = facetFields.get(i);
List<Count> facetInfo = facetField.getValues();
for (FacetField.Count facetInstance : facetInfo) {
System.out.println(facetInstance.getName() + " : " +
facetInstance.getCount() + " [drilldown qry:" +
facetInstance.getAsFilterQuery());
}
System.out.println("Hello");
}
}
}Compile o código acima executando os seguintes comandos no terminal -
[Hadoop@localhost bin]$ javac HitHighlighting
[Hadoop@localhost bin]$ java HitHighlightingAo executar o comando acima, você obterá a seguinte saída.
[author:[George R.R. Martin (3), Lloyd Alexander (2), Glen Cook (1), Isaac
Asimov (1), Orson Scott Card (1), Roger Zelazny (1), Steven Brust (1)]]