Apache Storm - conceitos básicos
O Apache Storm lê o fluxo bruto de dados em tempo real de uma extremidade e os passa por uma sequência de pequenas unidades de processamento e produz as informações processadas / úteis na outra extremidade.
O diagrama a seguir descreve o conceito central do Apache Storm.

Vamos agora dar uma olhada mais de perto nos componentes do Apache Storm -
| Componentes | Descrição |
|---|---|
| Tupla | Tupla é a estrutura de dados principal do Storm. É uma lista de elementos ordenados. Por padrão, uma Tupla oferece suporte a todos os tipos de dados. Geralmente, ele é modelado como um conjunto de valores separados por vírgula e passado para um cluster do Storm. |
| Corrente | Stream é uma sequência não ordenada de tuplas. |
| Bicos | Fonte de fluxo. Geralmente, Storm aceita dados de entrada de fontes de dados brutos como Twitter Streaming API, fila Apache Kafka, fila Kestrel, etc. Caso contrário, você pode escrever spouts para ler dados de fontes de dados. “ISpout" é a interface principal para a implementação de spouts. Algumas das interfaces específicas são IRichSpout, BaseRichSpout, KafkaSpout, etc. |
| Parafusos | Os parafusos são unidades lógicas de processamento. Spouts passam os dados para os parafusos e parafusos e produzem um novo fluxo de saída. Bolts podem executar as operações de filtragem, agregação, junção, interação com fontes de dados e bancos de dados. Bolt recebe dados e emite para um ou mais parafusos. “IBolt” é a interface principal para a implementação de parafusos. Algumas das interfaces comuns são IRichBolt, IBasicBolt, etc. |
Vamos dar um exemplo em tempo real de “Análise do Twitter” e ver como ele pode ser modelado no Apache Storm. O diagrama a seguir descreve a estrutura.

A entrada para a “Análise do Twitter” vem da API de streaming do Twitter. Spout lerá os tweets dos usuários usando a API de streaming do Twitter e produzirá como um fluxo de tuplas. Uma única tupla do spout terá um nome de usuário do Twitter e um único tweet como valores separados por vírgula. Em seguida, esse fluxo de tuplas será encaminhado para o Bolt e o Bolt dividirá o tweet em palavras individuais, calculará a contagem de palavras e manterá as informações em uma fonte de dados configurada. Agora, podemos obter facilmente o resultado consultando a fonte de dados.
Topologia
Bicos e parafusos são conectados entre si e formam uma topologia. A lógica do aplicativo em tempo real é especificada na topologia do Storm. Em palavras simples, uma topologia é um gráfico direcionado onde os vértices são cálculos e as arestas são fluxos de dados.
Uma topologia simples começa com spouts. O bico emite os dados para um ou mais parafusos. Bolt representa um nó na topologia com a menor lógica de processamento e a saída de um bolt pode ser emitida para outro bolt como entrada.
Storm mantém a topologia sempre em execução, até que você elimine a topologia. A principal tarefa do Apache Storm é executar a topologia e executará qualquer número de topologia em um determinado momento.
Tarefas
Agora você tem uma ideia básica sobre bicos e parafusos. Eles são a menor unidade lógica da topologia e uma topologia é construída usando um único spout e uma matriz de parafusos. Eles devem ser executados adequadamente em uma ordem específica para que a topologia seja executada com êxito. A execução de cada bica e parafuso por Storm é chamada de “Tarefas”. Em palavras simples, uma tarefa é a execução de um bico ou de um parafuso. Em um determinado momento, cada bico e parafuso podem ter várias instâncias em execução em vários segmentos separados.
Trabalhadores
Uma topologia é executada de maneira distribuída, em vários nós de trabalho. Storm distribui as tarefas uniformemente em todos os nós de trabalho. A função do nó de trabalho é escutar trabalhos e iniciar ou interromper os processos sempre que chega um novo trabalho.
Agrupamento de fluxo
O fluxo de dados flui de bicos para parafusos ou de um parafuso para outro. O agrupamento de fluxos controla como as tuplas são roteadas na topologia e nos ajuda a entender o fluxo das tuplas na topologia. Existem quatro agrupamentos embutidos, conforme explicado abaixo.
Agrupamento aleatório
No agrupamento aleatório, um número igual de tuplas é distribuído aleatoriamente entre todos os trabalhadores que executam os parafusos. O diagrama a seguir descreve a estrutura.

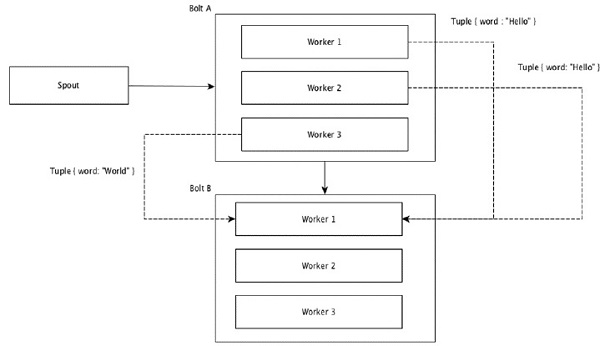
Agrupamento de Campo
Os campos com os mesmos valores nas tuplas são agrupados e as tuplas restantes mantidas fora. Em seguida, as tuplas com os mesmos valores de campo são enviadas para o mesmo trabalhador que executa os bolts. Por exemplo, se o fluxo for agrupado pelo campo “palavra”, então as tuplas com a mesma string, “Olá” serão movidas para o mesmo trabalhador. O diagrama a seguir mostra como funciona o agrupamento de campos.

Agrupamento Global
Todos os fluxos podem ser agrupados e encaminhados para um parafuso. Esse agrupamento envia tuplas geradas por todas as instâncias da origem para uma única instância de destino (especificamente, escolha o trabalhador com o menor ID).
Todos os agrupamentos
O All Grouping envia uma única cópia de cada tupla para todas as instâncias do bolt receptor. Este tipo de agrupamento é usado para enviar sinais aos parafusos. Todo o agrupamento é útil para operações de junção.
